15-445/645 Intro to Database Systems/Fall 2019 2강을 보고 정리한 내용입니다.
링크: https://www.youtube.com/watch?v=6VCHuLqfmV8&list=PLSE8ODhjZXjbohkNBWQs_otTrBTrjyohi&index=2
1. Relational Languages
지난 강의에서 relational algebra는 procedural language인 반면에 SQL은 declaritive language이기 때문에 DBMS로 더 좋은 선택지라고 결론을 내렸었다. 또 다른 차이는 relational algebra는 set으로, SQL은 bags로 데이터가 저장된다. 잠시 데이터셋을 저장하는 자료구조를 정리하고 넘어가자.
dataset
- list: 중복 가능, 순서가 중요
- set: 중복 불가능, 정렬되어있지 않음
- bags: 중복 가능, 정렬되어 있지 않음
SQL은 bags 자료구조로 데이터셋이 저장되어 있기 때문에 중복이 가능하고 기본적으로 정렬되지 않은 형태이다. 따라서 중복을 제거하거나, 정렬하기 위해선 별도로 명령어를 입력해야 한다.
2. SQL History
SQL은 여러 데이터베이스 언어의 합집합으로, 다음과 같은 언어의 특성을 가진다.
- data manipulation language(DML): 데이터를 검색하고 수정하는 기능으로 SELECT, INSERT, UPDATE, DELETE가 이에 해당된다.
- data definition language(DDL): 테이블, 인덱스, 뷰 및 다른 객체를 정의하는 스키마를 정의한다.
- data control language(DCL): 접근 권한을 부여하여 보안 기능을 한다.
SQL은 기본적으로 위와 같은 기능을 하고 끊임없이 발전중이다.
3. 사용할 테이블 생성
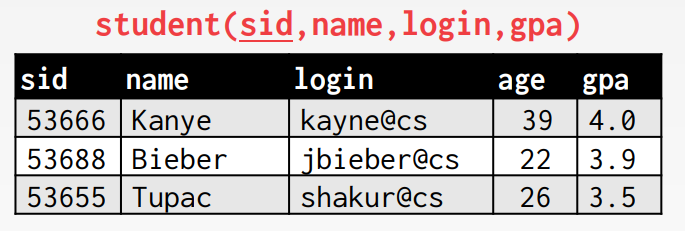
CREATE TABLE student (
sid INT PRIMARY KEY,
name VARCHAR(16),
login VARCHAR(32) UNIQUE,
age SMALLINT,
gpa FLOAT
);
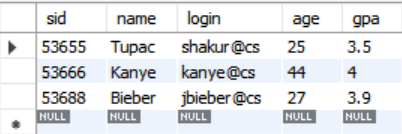
INSERT INTO student VALUES (53666, 'Kanye', 'kanye@cs', 44, 4.0);
INSERT INTO student VALUES (53688, 'Bieber', 'jbieber@cs', 27, 3.9);
INSERT INTO student VALUES (53655, 'Tupac', 'shakur@cs', 25, 3.5);SELECT * FROM student;의 결과
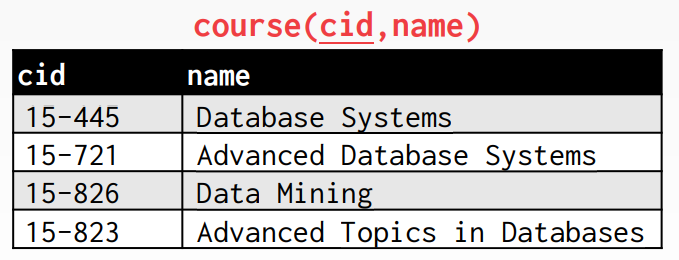
CREATE TABLE course (
cid VARCHAR(32) PRIMARY KEY,
name VARCHAR(32) NOT NULL
);
INSERT INTO course VALUES ('15-445', 'Database Systems');
INSERT INTO course VALUES ('15-721', 'Advanced Database Systems');
INSERT INTO course VALUES ('15-826', 'Data Mining');
INSERT INTO course VALUES ('15-823', 'Advanced Topics in Databases');SELECT * FROM course;의 결과

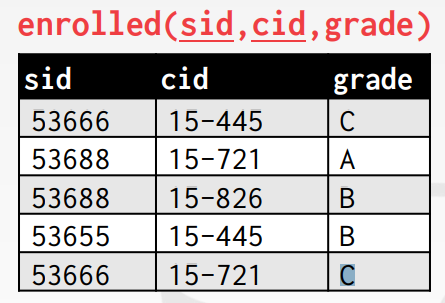
CREATE TABLE enrolled (
sid INT REFERENCES student (sid),
cid VARCHAR(32) REFERENCES course (cid),
grade CHAR(1)
);
INSERT INTO enrolled VALUES (53666, '15-445', 'C');
INSERT INTO enrolled VALUES (53688, '15-721', 'A');
INSERT INTO enrolled VALUES (53688, '15-826', 'B');
INSERT INTO enrolled VALUES (53655, '15-445', 'B');
INSERT INTO enrolled VALUES (53666, '15-721', 'C');SELECT * FROM enrolled;의 결과
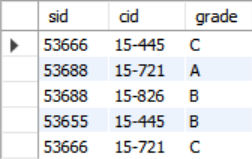
4. Joins
Join은 여러 개의 테이블에 널려있는 데이터를 종합한다. 그 방법으로, 한 개 이상의 테이블에 있는 칼럼들을 결합하여 새로운 테이블을 생성한다.
- Q: Which student got an A in 15-721?
- 해설: enrolled 테이블에서 cid가 15-721이고 grade가 A인 학생의 sid를 구하여 그 sid와 일치하는 학생의 이름을 student 테이블로부터 구한다.
SELECT s.name
FROM enrolled AS e, student AS s
WHERE e.grade = 'A' AND e.cid = '15-721'
AND e.sid = s.sid;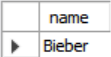
마지막 AND e.sid = s.sid; 구문을 없애서 돌려보니 enrolled 테이블과 student 테이블을 이어주는 키값이 없으므로 결과값은 enrolled 테이블과 독립적으로 student 테이블에 있는 모든 이름이 반환되었다.
SELECT s.name
FROM enrolled AS e, student AS s
WHERE e.grade = 'A' AND e.cid = '15-721';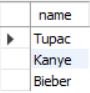
5. Aggregates
5-1. Aggregates
Aggregation function은 bags 형태로 저장된 튜플들을 입력으로 받아 하나의 스칼라 값을 출력한다. 거의 SELECT문의 출력에 쓰이며, 대표적인 aggregation function을 살펴보면 다음과 같다.
- AVG(col): col 값의 평균을 반환
- MIN(col): col 값의 최솟값을 반환
- MAX(col): col 값의 최댓값을 반환
- SUM(col): col 값의 합을 반환
- COUNT(col): col 값의 갯수를 반환
- Q: Get # of students with a "@cs" login.
SELECT COUNT(*) FROM student WHERE login LIKE '%@CS';SELECT COUNT(login) FROM student WHERE login LIKE '%@CS';SELECT COUNT(1) FROM student WHERE login LIKE '%@CS';위의 3 쿼리의 결과는 모두 같다. Login 값이 무엇인지가 중요한게 아니라 존재유무가 중요하다. 여기서 DBMS가 위의 모든 쿼리가 같다는 것을 최적화 단계에서 알 수 있기 때문이다. 다시 한 번 SQL은 declaritive language로 많은 부분들을 언어 내부에서 최적화 한다는 점을 확인하였다.
5-2. Multiple Aggregates
한번에 여러 개의 aggregate function을 선택할 수도 있다.
- Q: Get the number of students and their average GPA that have a “@cs” login.
SELECT AVG(gpa), COUNT(sid)
FROM student WHERE login LIKE '%@cs';
5-3. Distinct Aggregates
중복되지 않는 값만 추출해내기 위해 aggregate function과 함께 distinct 키워드를 사용한다. COUNT, SUM, AVG와 함께 DISTINCT를 사용할 수 있다.
SELECT COUNT(DISTINCT login)
FROM student WHERE login LIKE '%@cs';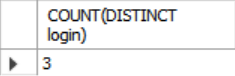
5-4. GROUP BY
Aggregate와 다른 칼럼의 출력이 섞여있을 때, 나머지 칼럼의 출력을 정의할 수 없다.
- Q: Get the average GPA of students enrolled in each course.
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid;- Error Code: 1140. In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'cmu.e.cid'; this is incompatible with sql_mode=only_full_group_by 0.000 sec
AVG(s.gpa)의 경우 enrolled와 student 테이블의 sid가 일치하는 모든 학생들의 gpa의 평균을 구한다. Enrolled의 cid가 모두 다르므로 반환을 하지 못한다. 이때, 만약 cid별로 묶어서 AVG(s.gpa)를 구한다면 cid와 해당 강좌에 대한 평균 gpa를 구할 수 있을 것이다. 다시 말해서, 튜플들을 부분 집합으로 나눠서 aggregate를 각 부분 집합에 대해서 수행하면 된다. 이러한 기능을 해주는 명령어가 GROUP BY이다. 마지막에 GROUP BY e.cid;를 추가해주었다.
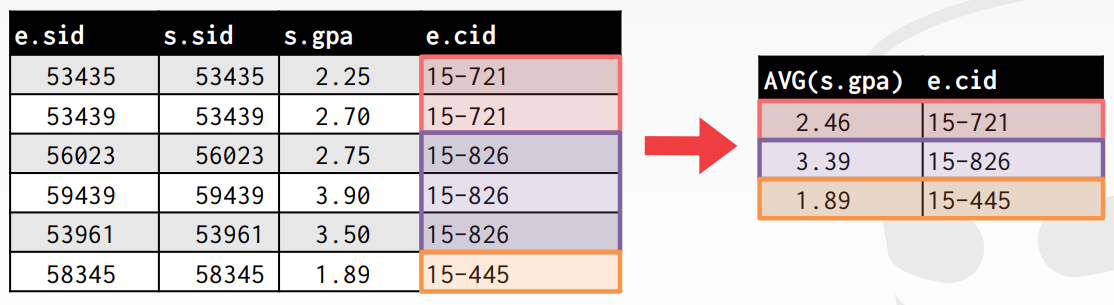
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid;
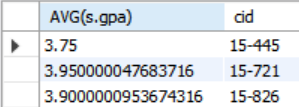
e.cid뿐만 아니라 SELECT 출력 구문에서 aggregate가 되지 않은 다른 값에 대해서도 GROUP BY로 묶어줘야 한다. 아래의 구문의 경우 SELECT 출력 구문에 aggregate가 되지 않은 s.name에 대하여 GROUP BY로 묶여있지 않기 때문에 오류가 난다.

- Error Code: 1055. Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'cmu.s.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by 0.000 sec

5-5. HAVING
칼럼에 대한 필터가 아닌 aggregation function의 결과에 대한 필터링을 수행하기 위해선 HAVING 절을 사용한다. WHERE 절은 GROUP BY를 수행하기 전에 확인하므로 WHERE 절에 aggregation function의 결과에 대한 필터링을 수행할 수 없다. WHERE 절에 AND로 aggregation function의 결과에 대한 필터링을 다음과 같이 수행했을 때 avg_gpa가 칼럼이 아니라는 에러가 발생한다.
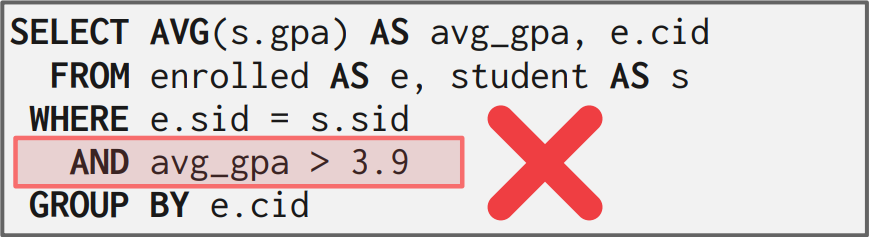
- Error Code: 1054. Unknown column 'avg_gpa' in 'where clause' 0.000 sec

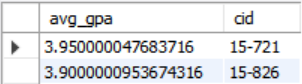
참고로 MySQL에 HAVING avg_gpa > 3.9이 돌아가지만 표준 SQL에 따르는 더 좋은 표현법은 HAVING AVG(s.gpa) > 3.9이다.
6. String Operations
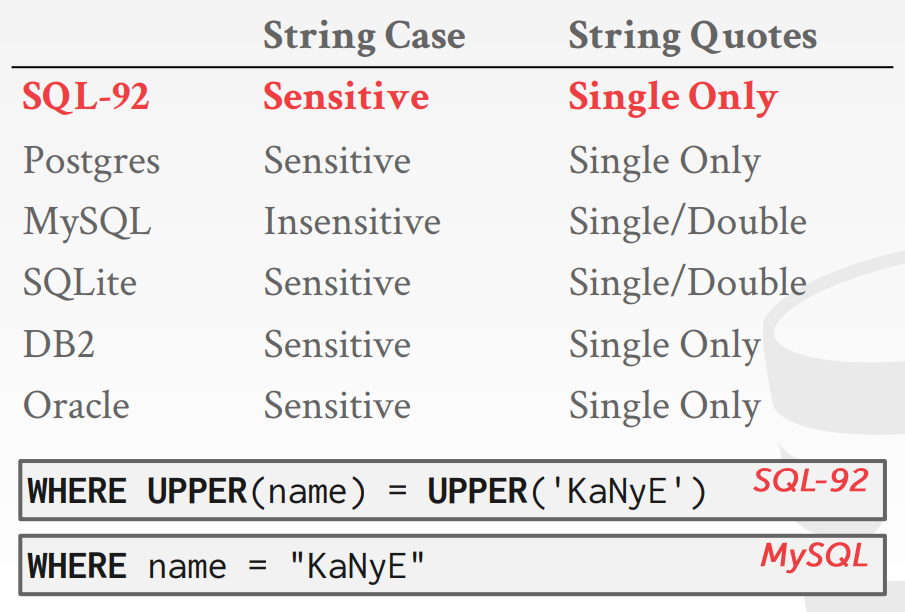
String 연산에 대하여 알파벳 대소문자를 대부분의 SQL 언어에선 구분하지만, MySQL의 경우 구분하지 못한다. 또한 문자열을 나타낼 때 ''가 아닌 '을 사용하는 것이 언어를 불문하고 통용되므로 '를 사용하도록 하자.
6-1. LIKE
LIKE 구문은 문자열 일치여부를 확인할 때 쓰인다.
%는 빈 하위 문자열을 포함한 모든 하위 문자열과 일치한다.
SELECT * FROM enrolled AS e
WHERE e.cid LIKE '15-%'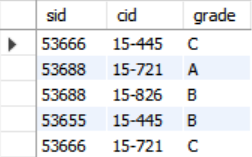
_는 하나의 문자와 일치한다.
SELECT * FROM student AS s
WHERE s.login LIKE '%@c_';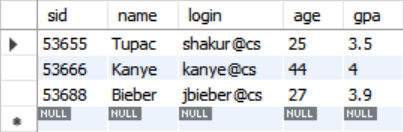
6-2. SUBSTRING
문자열의 부분 집합을 구하는 SUBSTRING 연산은 다음과 같이 작동한다.
SELECT SUBSTRING(name,1,5) AS abbrv_name
FROM student WHERE sid = 53688;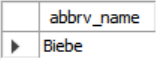
6-3. ||
표준 SQL은 문자열을 합칠 때 ||을 사용하지만, MySQL의 경우 CONCAT 명령어를 사용한다.
표준 SQL
SELECT name FROM student
WHERE login = LOWER(name) || '@cs';MySQL
SELECT name FROM student
WHERE login = CONCAT(LOWER(name), '@cs');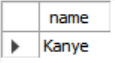
7. Date and Time
날짜/시간 속성을 조작하고 수정하는 작업도 sql에서 가능하다. 다음 출력값들은 모두 MySQL에 돌려본 결과다.
7-1. 현재 시간
Q: 현재 날짜와 시각을 구하시오.
SELECT NOW();postgress,MySQL에서 돌아간다.

SELECT CURRENT_TIMESTAMP;sqlite,postgress,MySQL에서 돌아간다.
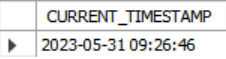
SELECT CURRENT_TIMESTAMP();MySQL에서 돌아간다.
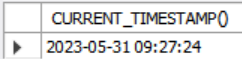
7-2. 경과된 시간
- Q: Get the # of days since 2021-09-01
SELECT EXTRACT(DAY FROM DATE('2021-09-01'));MySQL에서는 엉뚱한 결과가 나오지만postgress에서는 정확한 결과가 나온다.

SELECT DATE('2021-09-01')-DATE('2021-01-01') AS DAYS;MySQL에서는 엉뚱한 결과가 나오지만postgress에서는 정확한 결과가 나온다.
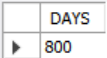
SELECT ROUND((UNIX_TIMESTAMP(DATE('2021-09-01')) - UNIX_TIMESTAMP(DATE('2021-01-01')))/(60*60*24),0) AS days;MySQL에서 돌아간다.
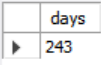
SELECT DATEDIFF(DATE('2021-09-01'), DATE('2021-01-01')) AS days;MySQL에서 돌아갈 수 있는 쿼리를 조금 더 간단하게 표현하였다.
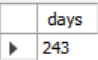
SELECT julianday(CURRENT_TIMESTAMP) - julianday('2021-01-01');postgress에서 돌아간다.
8. Output Redirection
터미널에 쿼리 결과 확인에서 더 나아가, 다른 테이블에 쿼리의 결과를 저장해둬서 추후에 활용할 수 있다.
8-1. 새로운 테이블
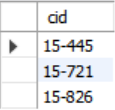
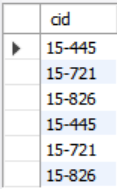
SELECT DISTINCT cid INTO CourseIds FROM enrolled; -- SQL 표준CREATE TABLE CourseIds (
SELECT DISTINCT cid FROM enrolled); -- MySQLSELECT * from CourseIds;의 결과를 보면 칼럼이 cid인 테이블이 잘 생성되어있다는 것을 확인하였다.
8-2. 이미 존재하는 테이블
이미 존재하는 테이블에 튜플들을 추가하려면 두 개의 테이블의 칼럼이 같아야 한다.
INSERT INTO CourseIds (SELECT DISTINCT cid FROM enrolled);- 앞서 생성한
CourseIds테이블에 똑같은cid값들이 추가된 것을 확인하였다.
9. Output Control
SQL의 쿼리문의 결과값을 원하는 형태로 출력되게 할 수 있다. 앞서 말했던 대로 SQL의 데이터베이스의 튜플은 bags이기 때문에 정렬되어있지 않다. 따라서, 정렬을 원하면 별도로 쿼리문의 명령문에 해당 내용을 명시해야 한다.
9-1. ORDER BY
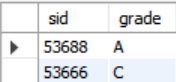
SELECT sid, grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade;SELECT sid, grade FROM enrolled WHERE cid = '15-721'
ORDER BY 1;sid와grade두 가지 요소를 선택했는데 둘 중grade를 기준으로 정렬을 진행했다. 또한ORDER BY grade=ORDER BY 1과 같다. 두 번째 표현은 칼럼의 이름 대신 칼럼의 위치로 정렬의 기준을 지정해줬을 뿐이다.
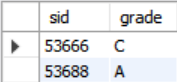
SELECT sid, grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade DESC;- 위에서 확인한 바와 같이
ORDER BY는 기본적으로 오름차순으로 정렬한다. 따라서, 내림차순으로 결과값이 정렬되도록 하려면DESC명령어를 써야 한다.
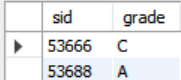
SELECT sid, grade FROM enrolled WHERE cid='15-721'
ORDER BY grade DESC, sid ASC;sid와grade두 가지 요소를 선택했는데 하나의 칼럼만으로 정렬을 할 필요가 없다. 먼저grade로 정렬을 진행한 후, 같은grade내에sid로 정렬을 진행할 수 있다.
9-2. LIMIT
DBMS는 기본적으로 쿼리의 결과에 해당되는 모든 결과값을 반환하는데 LIMIT을 통해 튜플의 결과 갯수를 한정시킬 수 있다. ORDER BY와 주로 같이 사용하는데, 그 이유는 정렬을 하지 않은 후 LIMIT를 사용하면 OFFSET을 통해 예를 들어 시작 지점을 정해 10개씩 반환한다고 할 때 겹치는 튜플이 반환될 수 있기 때문이다.
LIMIT
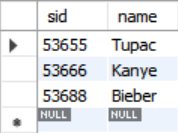
SELECT sid, name FROM student WHERE login LIKE '%@cs'
LIMIT 10;- 위의 쿼리문의 경우 10개의 튜플을 상한선으로 정했는데 3개의 튜플만 결과에 해당되므로 해당 튜플들만 반환했다.
OFFSET
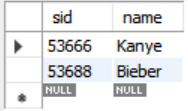
SELECT sid, name FROM student WHERE login LIKE '%@cs'
LIMIT 10 OFFSET 1;OFFSET은 상쇄하다는 뜻으로OFFSET 1이면 1번째 요소까지 상쇄하여 2번째 요소부터 결과같이 출력된다.
10. Nested Queries
SQL에서 더 복잡한 로직을 구현하기 위해 쿼리 안에 쿼리를 포함하는 nested queries를 사용한다. Nested query는 최적화하기 힘들다. nested queries는며 쿼리의 어느 부분에도 포함될 수 있으며 다음과 같은 부분들에 포함될 수 있다.
10-1. SELECT
SELECT (SELECT 1) AS one FROM student;
10-2. FROM
SELECT name
FROM student AS s, (SELECT sid FROM enrolled) AS e
WHERE s.sid = e.sid;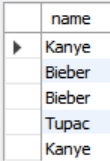
여기서는 그런데 nested query가 필요한지 의문이 든다. 정보의 중복 같다는 생각이 들기 때문이다. 다음과 같이 nested query가 없어도 결과가 같기 때문이다.
SELECT name
FROM student AS s, enrolled AS e
WHERE s.sid = e.sid;10-3. WHERE
SELECT name FROM student
WHERE sid IN (SELECT sid FROM enrolled);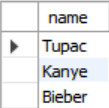
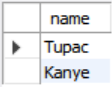
- Q1: Get the names of students in '15-225'
SELECT name FROM student
WHERE sid IN (
SELECT sid FROM enrolled
WHERE cid = '15-445'
);
SELECT (SELECT S.name FROM student AS S
WHERE S.sid = E.sid) AS sname
FROM enrolled AS E
WHERE cid = '15-445';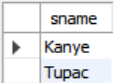
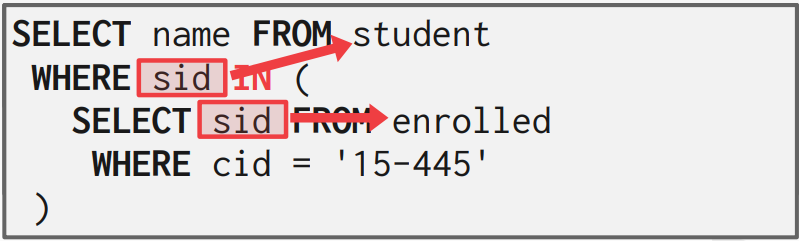
쿼리문을 뜯어보면 inner query로 student id의 집합을 생성한 후, outer query에 있는 모든 튜플에서 그 튜플이 존재하는지 확인하는 방법은 비효율적이다. 그에 반해 outer query에 대하여 inner query를 확인하는 방법은 효율적이다. DBMS는 쿼리 최적화를 위해 이러한 최적화 선택을 한다.
Nested query 표현들
- ALL: 하위 항목의 모든 행에 대한 식을 만족
- ANY: 하위 항목에서 하나 이상의 행에 대한 식을 만족
- IN: ANY()와 같음
- EXISTS: 하나 이상의 행이 반환
- Q2: Find student record with the highest id that is enrolled in at least one course.
SELECT MAX(e.sid), s.name
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid;위의 쿼리는 작동하지 않는데 그 이유는 aggregation function인 MAX와 aggregation function이 아닌 칼럼을 선택하는데 GROUP BY로 묶어주지 않았기 때문이다. 그렇다면 aggregation function인 MAX를 SELECT 구문에서 없애주고 WHERE 문에서 sid의 속성을 구체화해본다.
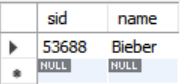
SELECT sid, name FROM student
WHERE sid IN (
SELECT MAX(sid) FROM enrolled
);SELECT student.sid, name
FROM student
JOIN (SELECT MAX(sid) AS sid
FROM enrolled) AS max_e
ON student.sid = max_e.sid;
);For문을 두 번 돌리는 첫 번째 구문보다 enrolled 테이블에선 원하는 값을 뽑고 student 테이블과 enrolled 테이블을 JOIN하는 두 번째 방식이 더 효율적이다.
- Q3: Find all courses that have no students enrolled in it.

SELECT * FROM course
WHERE NOT EXISTS(
SELECT * FROM enrolled
WHERE course.cid = enrolled.cid
);- 위의 쿼리에서 바깥쪽 쿼리는 iterating하며 안쪽 쿼리는 bag이다. 안쪽 쿼리에서 바깥쪽 쿼리를 참조하는 것이 가능한 반면에 outer query는 inner query를 참조할 수 없다. 위의 쿼리에서도 안쪽 쿼리에서 바깥쪽 쿼리의 course.cid를 참조하였다.
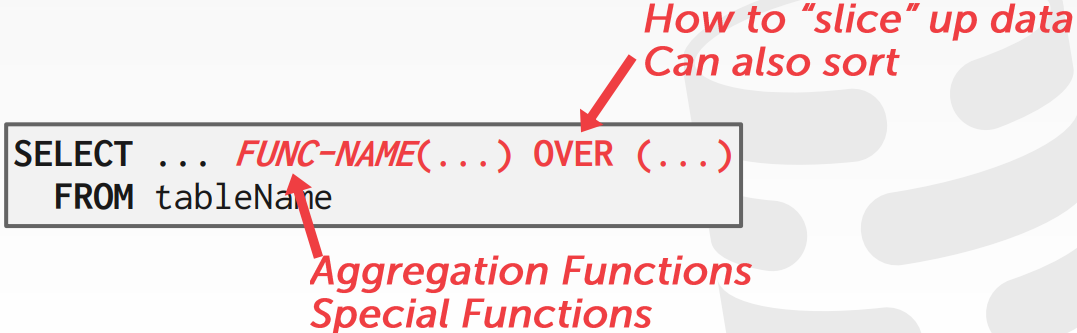
11. Window Functions
Window function은 관련된 튜플 집합에 대하여 sliding 연산을 수행한다. Aggregation과 비슷한 기능을 가지고 있으나, aggregation과 달리 하나의 튜플 결과를 내놓지 않는다. 기본적인 형식은 다음과 같다.
11-1. Functions
Window function은 다음과 같이 3가지 종류가 있다.
1. Aggregation function
2. ROW_NUMBER
ROW_NUMBER는 row_num이라는 새로운 칼럼을 생성하는데 output 튜플들이 생성된 순서대로 순서가 정해진다.
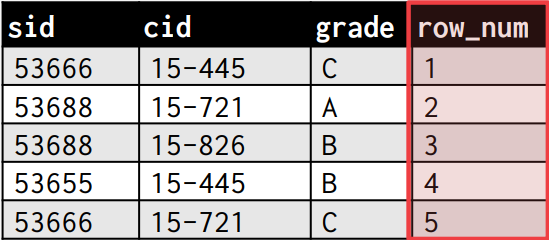
SELECT *, ROW_NUMBER() OVER () AS row_num
FROM enrolled;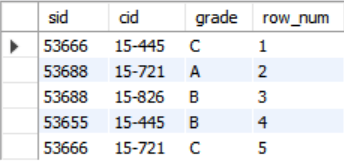
3. RANK
RANK는 정렬을 진행했을 때 그 정렬 내의 튜플의 순서를 나타낸다. 따라서 만약에 ORDER BY를 하지 않는다면 rank는 모두 1이 될 것이다.
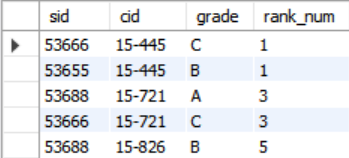
SELECT *, RANK() OVER (ORDER BY cid) AS rank_num
FROM enrolled;- cid에 따라 rank가 부여되었다. 같은 cid라면
rank_num이 같고, 다음 cid인 '15-721'에선rank_num이 2가 아니라 cid가 '15-445'인 튜플이 2개 있으므로 3인 것을 알게 되었다.
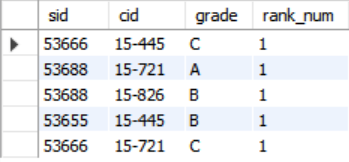
SELECT *, RANK() OVER () AS rank_num
FROM enrolled;OVER구문에ORDER BY로 정렬을 하지 않으니 rank가 모두 1인 것을 확인하였다.
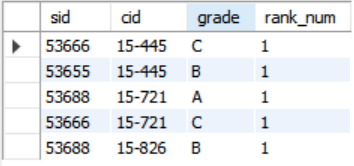
SELECT *, RANK() OVER (PARTITION BY cid) AS rank_num
FROM enrolled;PARTITION BY는 정렬이 아니기 때문에 rank에 영향을 주지 않는다는 것을 확인했다.
참고로, DBMS는 RANK를 정렬 후에 연산하고, ROW_NUMBER를 정렬 전에 연산한다는 점을 알고있으면 위의 결과물들을 이해하기 더 용이하다.
11-2. Grouping
OVER (PARTITION BY)
OVER 절은 window function을 계산할 때 튜플을 그룹화하는 방법을 지정한다. 그룹화하는 대상인 그룹을 구체화하기 위해선 PARTITION BY를 사용한다.
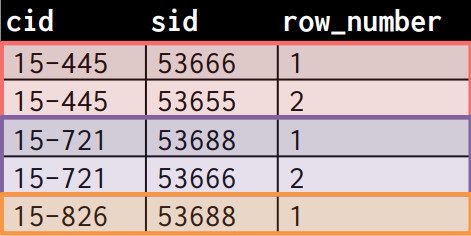
SELECT cid, sid, ROW_NUMBER() OVER (PARTITION BY cid)
FROM enrolled
ORDER BY cid;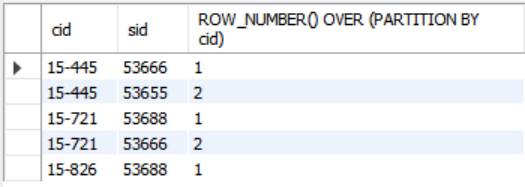
OVER (ORDER BY)
OVER 절을 각 그룹 내에서 정렬할 때는 ORDER BY와 함께 사용한다.
SELECT *, ROW_NUMBER() OVER (ORDER BY cid)
FROM enrolled
ORDER BY cid;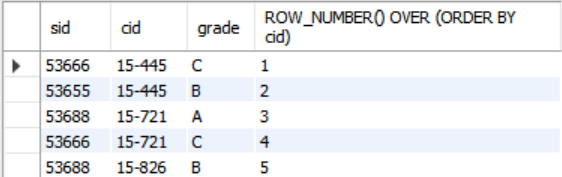
- Q: Find the student with the
secondhighest grade for each course.
SELECT * FROM (
SELECT *, RANK() OVER (PARTITION BY cid
ORDER BY grade ASC) AS rank_num
FROM enrolled) AS ranking
WHERE ranking.rank_num = 2;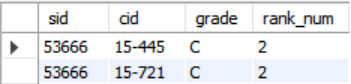
다시 강조하자면, GROUP BY를 사용하면 aggregate function으로 인해 튜플의 정보가 사라지지만 window function을 사용하면 원하는 결과와 더불어 원본의 튜플 요소들도 함께 볼 수 있다는 이점이 있다.
12. Common Table Expressions
Common table expressions는 window function이나 nested query에 대한 대안으로 더 큰 쿼리에서 보조적인 문을 사용하는데에 쓰인다. 다시 말해서, CTE를 단일 쿼리로 범위가 지정된 임시 테이블로 생각할 수 있다. 사용법으로는, WITH 구문이 내부 쿼리의 결과를 명시된 이름으로 임시적인 결과로 지정한다.
12-1. WITH ~ AS
- Q1: Generate a CTE called cteName that contains a single tuple with a single attribute set to "1". Select all attributes from cteName.
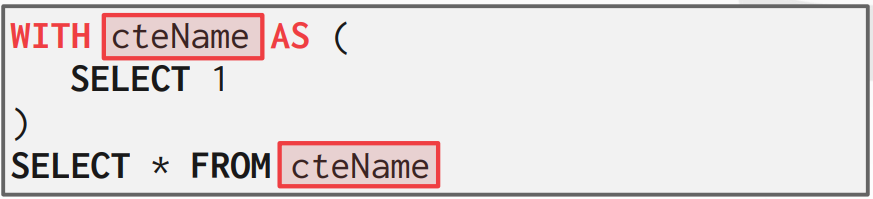
AS 구문 앞에 칼럼 이름으로 묶을 수도 있다.
WITH cteName (col1, col2) AS (
SELECT 1,2
)
SELECT col1 + col2 FROM cteName;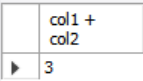
WITH cteName (col1, col2) AS (
SELECT 1,2
)
SELECT * FROM cteName;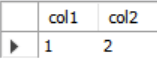
- Q2: Find student record with the highest id that is enrolled in at least one course.
WITH cteSource (maxId) AS (
SELECT MAX(sid) FROM enrolled)
SELECT name FROM student, cteSource
WHERE student.sid = cteSource.maxId;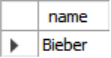
12-2. WITH RECURSIVE ~ AS
RECURSIVE 명령어는 스스로를 참조할 수 있게하여 재귀를 SQL문으로 작성할 수 있도록 한다. 이는 nested query로는 불가능한 기능이다.
- Q3: Print the sequence of numbers from 1 to 10.
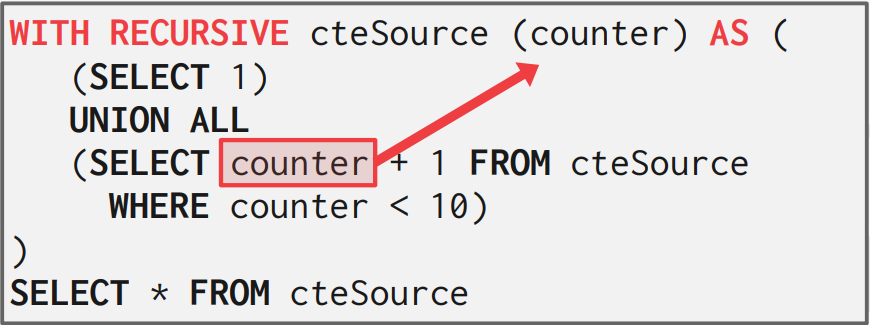
WITH RECURSIVE cteSource (counter) AS (
(SELECT 1)
UNION ALL
(SELECT counter + 1 FROM cteSource
WHERE counter < 10)
)
SELECT * FROM cteSource;
SQL의 기본 문법과 더불어 복잡한 쿼리를 작성할 때 쓰이는 window function, nested query, common table expression을 배웠다. 아직 익숙하지 않으므로 내가 원하는 쿼리문을 자유자재로 쓸 때까지는 많이 연습을 해야겠다.😁
