스탠포드 강의의 CS231n 6강을 보고 정리한 내용입니다.
링크 : https://www.youtube.com/watch?v=wEoyxE0GP2M&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=6
[1. ConvNet Architecture]
5강에서 Convolutional Neural network의 전체적인 구조를 정리해보았다.
- Input - convolutional layer - batch normalization - relu activation - pooling layer - fully connected layer
이 중 가능한 적은 parameter로 신경망을 깊게 쌓아주기 위한 downsampling와 dimension 유지라는 관점으로 convolutional layer, pooling layer, fully connected layer를 이해했다. 이번 강의에서는 5강에서 다루지 않았던 batch normalization과 activation function에 대한 설명을 바탕으로 ConvNet을 구성하는 주요 요소들에 대한 이해를 마치겠다.
[2. Setting up the data and the model]
기본적인 ConvNet 뼈대를 만들었으면 이제 살을 붙여서 모델이 최고의 성능을 뽑아낼 수 있도록 한다. 가장 먼저 해줘야 할 것은 학습을 하기 전에 데이터와 모델에 대한 초기 설정 작업이다. 데이터의 경우, zero centering, normalization으로 데이터를 정제한다.
모델을 학습한다는 것은 곧 가장 좋은 weight를 찾는 과정이다. 3강에서 loss function의 전체 모양을 알 수 없으므로 global minima를 찾는 것이 사실상 불가능하다는 것을 배웠었다. 이 때 차선으로 취한 방법이 무작위의 초기값을 여러 개 설정해서 여러 개의 local minima 중 가장 작은 지점을 찾는 방법이었다. Weight initialization이란 loss function의 어느 지점에서 출발할지를 정해주는 작업이다. 비록 무작위로 초기값을 설정해준다고 했지만 구체적으로 어떤 분포를 띄는 무작위로 weight를 초기화시킬지 자세히 알아볼 것이다.
[3. Training Neural Network]
기본적인 ConvNet 뼈대를 잡아주고 데이터와 모델 초기 상태를 설정해줬다. 이젠 본격적으로 모델을 학습해가면서 hyperparameter tuning 작업을 거치게 된다. 6강에선 구체적으로 regularization에 적합한 learning rate를 고르는 과정에 대한 intuition을 가르쳐준다. 또한 모델을 학습해줬을 때 나오는 loss 그래프나 accuracy 그래프를 해석해서 hyperparameter tuning에 대한 방향성을 알려준다.
1. Convnet Architecture - 2
1-1. Activation function
4강에서 activation function은 Neural network를 쌓을 때 비선형성을 부여하기 위해 사용한다는 점이 이미 소개되었다. 이번 강의에서는 구체적으로 어떤 activation function들이 있는지 장단점을 비교해볼 것이다. 사실 기억에 남겨놔야 할 점은 대부분의 경우 relu 함수를 사용한다는 것이다. 하지만 다른 함수들과의 비교를 해봐야 relu 함수의 진가를 제대로 알 수 있으므로 하나씩 차근차근 살펴보겠다.
1-1.1 Sigmoid 계열
Activation function은 크게 sigmoid 계열과 relu 계열로 나뉘게 된다. Sigmoid 계열은 지수 함수가 연산에 포함되기 때문에 연산량이 많아진다는 특징이 있고 그에 반해 relu계열은 미분을 계산할 필요가 없기 때문에 연산량 측면에서 효율적이다. 0이하의 영역에서의 미분 값이 0이고, 양수 영영에서의 미분 값은 상수이기 때문이다. 이제 연산량을 제외한 장단점들을 각자 비교해보자.
1-1.1/1 Sigmoid
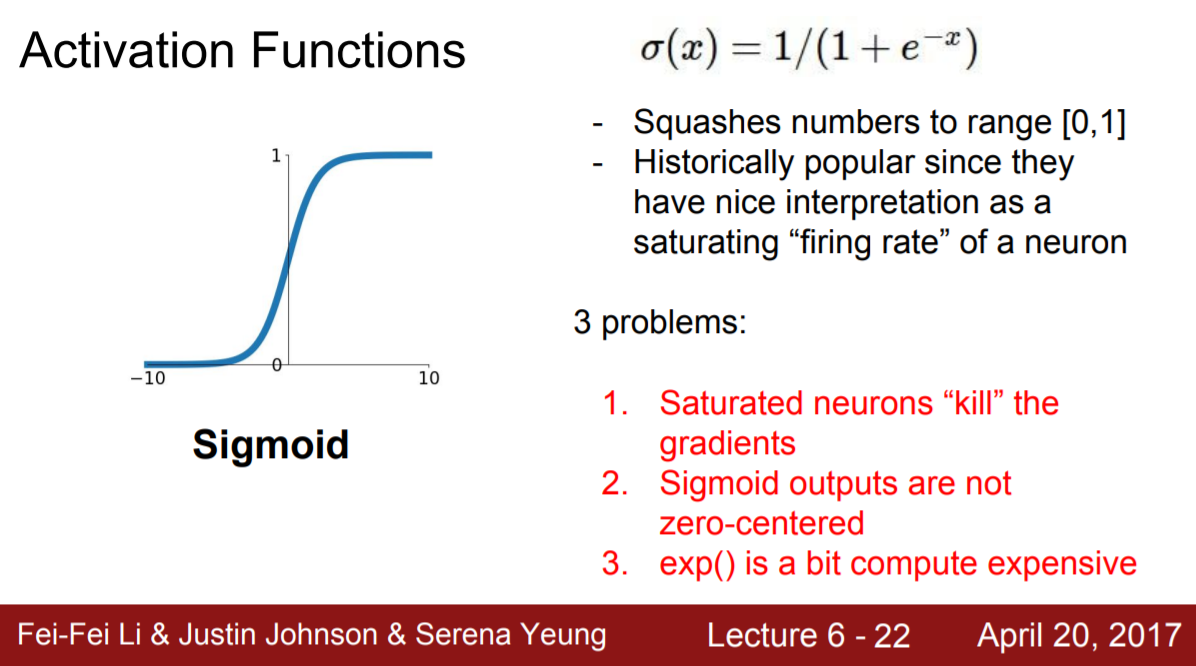
한 개의 layer가 아닌 여러 개의 layer를 쌓아주는 neural network가 만들어지면서 backpropogation을 이용한 weight 수정이 이루어졌다. 이 과정에서 perceptron에서 이용하던 step function과 유사하되 미분 가능한 sigmoid function을 떠올리게 되었다. 하지만 크게 두 가지 단점이 존재했다.
단점
1. gradient saturation
2. not zero centered (= 출력이 항상 양수)
1. gradient saturation
sigmoid function의 경우 0 근처의 영역에선 선형함수에 근사하지만 그 외 부분에선 양쪽의 미분 값이 0이된다. 따라서 입력값이 변하더라도 함숫값이 변하지 않기 때문에 학습이 중단된다.
2. not zero centered
f=wTx+b, J는 loss function, w는 weight이고 σJ/σw = σJ/σf * σf/σw를 계산해야 할 때, σf/σw = x이다.
-
출력 x가 항상 양수인 경우(σf/σw = x > 0)
- σJ/σf > 0
σJ/σf * σf/σw > 0 - σJ/σf < 0
σJ/σf * σf/σw < 0
이므로 학습 경로가 1, 3차분면으로만 이동 가능하다. 따라서, 학습 경로가 진동하면서 속도가 느려지게 된다.
- σJ/σf > 0

1-1.1/2 tanh
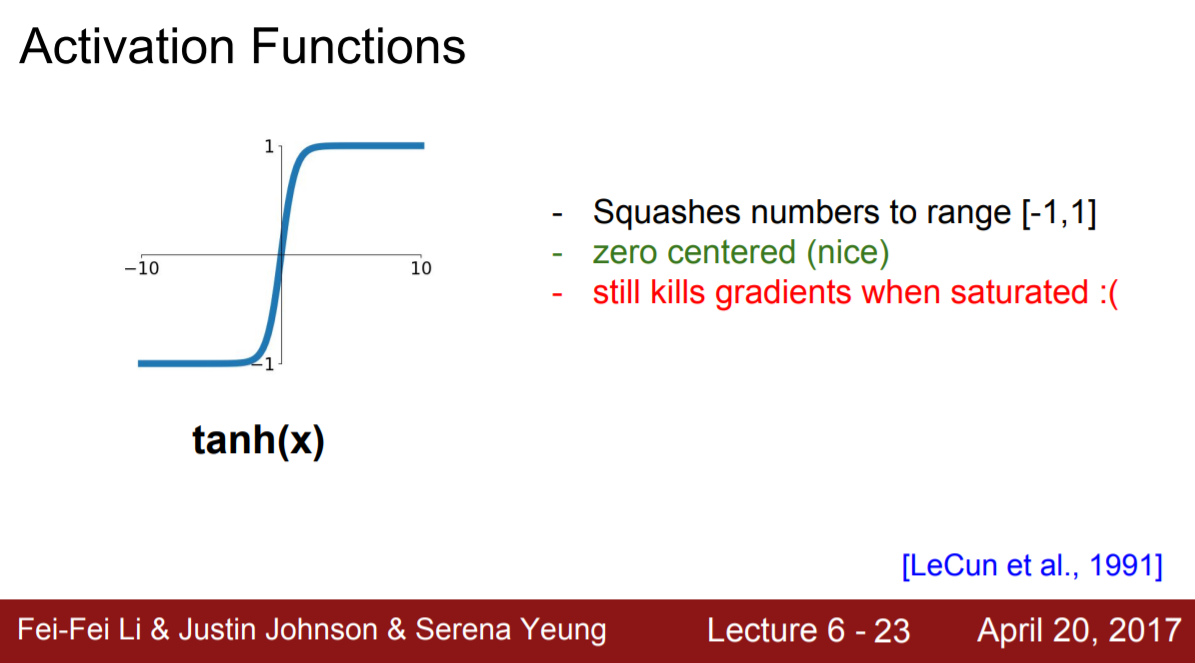
tanh의 경우
sigmoid의 단점
1. gradient saturation > 해결 x
2. not zero centered (= 출력이 항상 양수) > 해결 o
비록 tanh는 zero centered여서 sigmoid의 두 번째 문제점은 해결했으나 0 근처가 아닌 영역에서 양쪽의 미분 값이 0이 되는 것은 여전하다. Tanh(x)=2σ(2x)-1이어서 여전히 sigmoid 계열인데 첫번째 문제점인 gradient saturation 해결을 위해 Sigmoid 계열이 아닌 다른 함수를 생각해보자.
1-1.2 Relu 계열
1-1.2/1 Relu
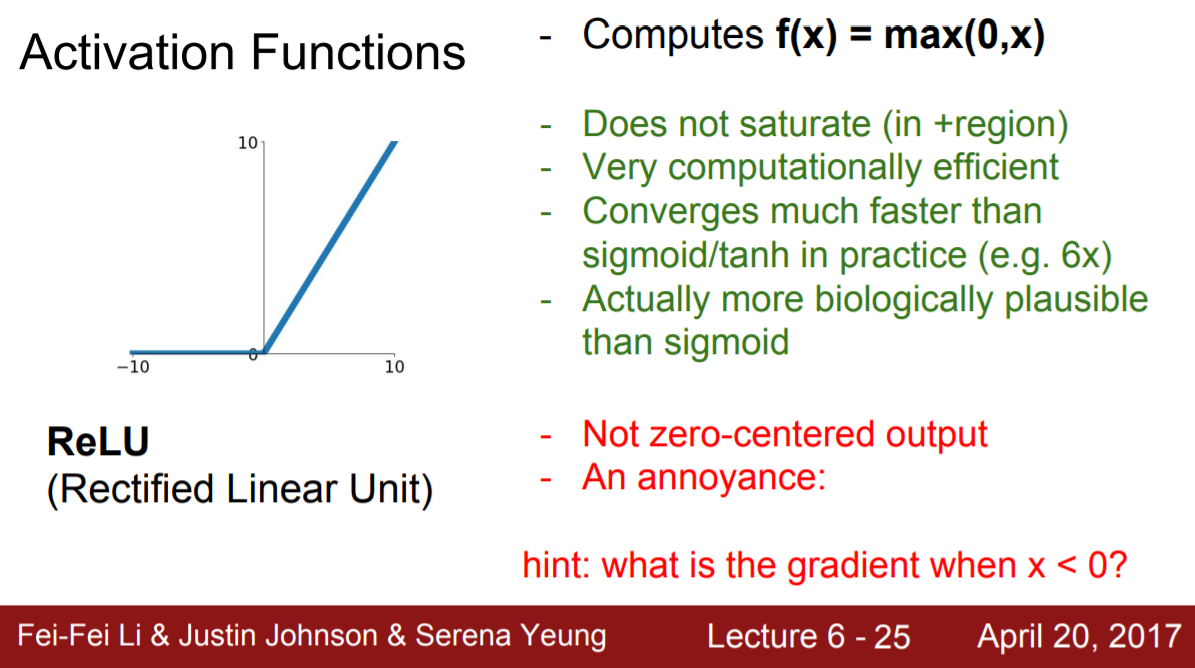
sigmoid의 단점
1. gradient saturation > 해결 o
2. not zero centered (= 출력이 항상 양수) > 해결 x > Dead relu 발생
Relu의 단점
1. Dead Relu 발생
2. 0에서 미분 불가능 (큰 문제 x, 근사로 함수 표현 가능)
1. gradient saturation
Relu 함수의 경우 양수 구간에서 선형함수이다. 따라서, gradient saturation 문제를 해결한다.
2. Dead Relu
하지만 2번 문제를 해결하지 못했다. Relu 함수의 모양에서 볼 수 있듯이 출력이 0이거나 양수이기 때문이다. 이 때 음수 영역에서 출력이 0인 것은 dead relu라는 새로운 문제점을 발생시킨다. Dead relu란 뉴런이 계속 0을 출력하는 상태를 말한다. 가중치를 업데이트하는 식을 다시 보자.
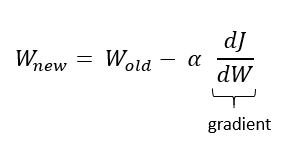
J가 loss function, w는 weight를 뜻하고 f=wTx+b일 때, 여기서 gradient σJ/σw를 구해보자.
- σJ/σw = σJ/σf * σf/σw
- σf/σw = σ(wTx+b)/σw = x
- σJ/σw = σJ/σf * x
따라서 W(new) = W(old) - α * σJ/σw에서 뉴런의 입력 x가 아주 크거나 학습률 α가 크면 새로운 weight 값이 음수가 된다. 이때 Relu 함수는 음수의 값에 대해 항상 0을 출력하므로 Relu의 gradient가 0이 된다. 즉, 학습이 더이상 진행되지 않는다. 따라서, relu 함수를 사용할 땐 뉴런의 입력 x가 너무 크지 않도록 weight initialization에 신경써줘야한다.
Sigmoid 계열 함수는 gradient saturation으로 학습이 중단될 수 있고 relu 계열 함수 역시 dead relu로 인해 학습이 중단 될 수 있다. 하지만 학습 속도는 물론 성능이 relu가 더 좋고, dead relu의 경우 초기 weight를 잘 설정해준다면 어느 정도 해결 가능하다. 그에 반해 gradient saturation 문제를 해결하기엔 어렵다.
1-1.2/2 Leaky Relu, PRelu, Elu
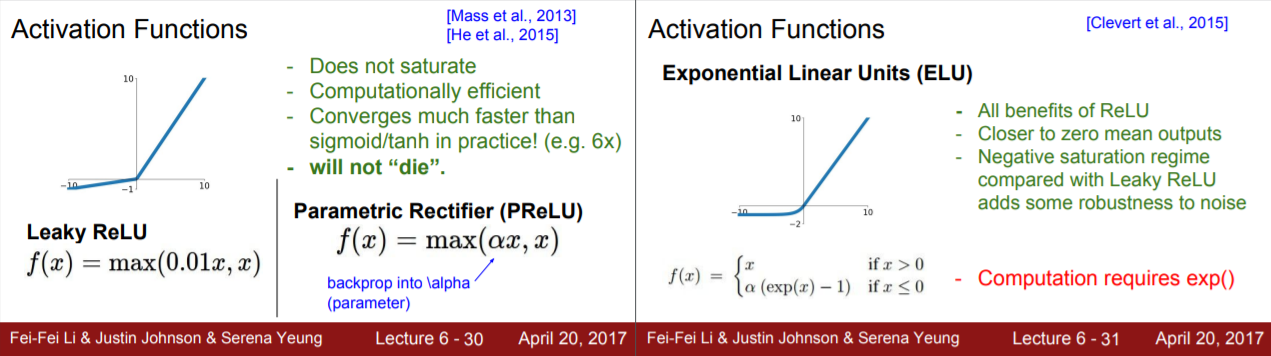
Dead relu가 발생하는 이유는 음수 구간의 값이 0이기 때문이다. 이를 해결하기 위해 leaky relu, prelu, elu와 같은 함수들이 만들어졌다.
- 음수 영역 설정
- leaky relu : 고정된 기울기를 사용한다. 따라서 최적의 성능을 주지 못할 수도 있다. 왜냐하면 큰 음수가 입력되면 함수값이 커져서 노이즈에 민감해지기 때문이다.
- prelu : 기울기를 학습할 수 있도록 해서 성능은 좋아지지만 학습해야 할 parameter들이 많아진다.
- elu : leaky relu의 노이즈에 민감한 것을 보완하기 위해 음수 구간을 exponential 형태로 표현했다. 하지만 지수 함수 때문에 연산량이 많아진다.
결국 prelu, elu는 연산량이 늘어난다. 그리고 성능 면에서도 많은 경우 relu와 큰 차이가 없거나 오히려 안좋을 때도 있어서 activation function으로 relu를 보통 가장 많이 사용한다.
1-1.2/3 Maxout

Maxout 함수는 구간별 선형함수이다. 선형 함수를 여러 개 학습한 후 최댓값을 구하는 것으로 relu계열 함수의 일반화된 형태다. 그 결과 gradient saturation, dead relu 문제를 모두 해결하지만 연산량이 너무 많이 늘어난다는 단점이 있다.
1-2. Batch normalization
앞서 데이터를 모델에 입력하기 전에 zero centering해준다고 했었다. 또한 모델 차원에서는 layer를 지나도 데이터의 고른 분포를 위해 weight initialization을 해준다. 하지만 초기 설정을 잘해줘도 neural network에서 layer를 거듭할수록 데이터의 분포가 왜곡된다. 여기서 말하는 데이터의 왜곡은 구체적으로는 중심이 바뀌는 것인데 이러한 현상을 internal covariant shift라고 한다. 이로 인해 weight initialization 작업이 까다로워지며 효과가 없을 때도 있다. 한번의 초기 설정인 weight initialization을 보충해주기 위해 layer를 지날 때마다 표준 가우시안 분포로 정규화하는 작업이 바로 batch normalization이다.
우선 normalization이란 평균이 0, 분산이 1인 표준 가우시안 분포로 나타내는 것이다. 방법으로는 평균을 빼주고 표준편차로 나눠주면 된다.
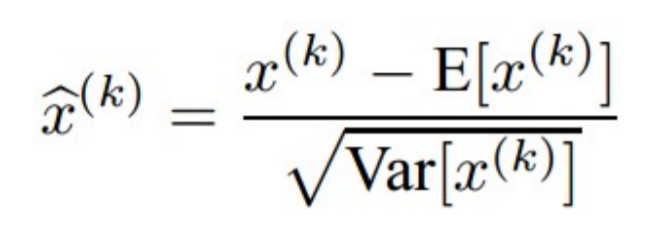
그런데 일반적인 normalization이 아닌 batch normalization이라고 한 이유는 모델이 실행될 때마다 minibatch에 대해 평균과 표준편차를 구해서 정규화를 진행시키기 때문이다. 여기서 batch normalization의 문제점이 생긴다. 원래 각 요소는 independence를 유지하는데, minibatch의 평균화와 분산화 과정에서 dependency가 생긴다. Dependency 문제를 해결하기 위해 training할 때와 testing할 때를 구분한다.
- Training할 때는 학습이 진행될 때의 평균값과 분산값을 batch별로 구해서 그 값을 사용한다.
- Testing할 때는 전체 데이터의 평균값과 분산값을 고정시켜서 사용한다. 이때 전체 데이터에 대해 직접 구하기 보단 training 할 때의 minibatch들에서 구한 값들을 통해 모평균과 모분산을 추정한다.
이로써 testing할 때의 요소들 간의 independency를 보존시켰다.
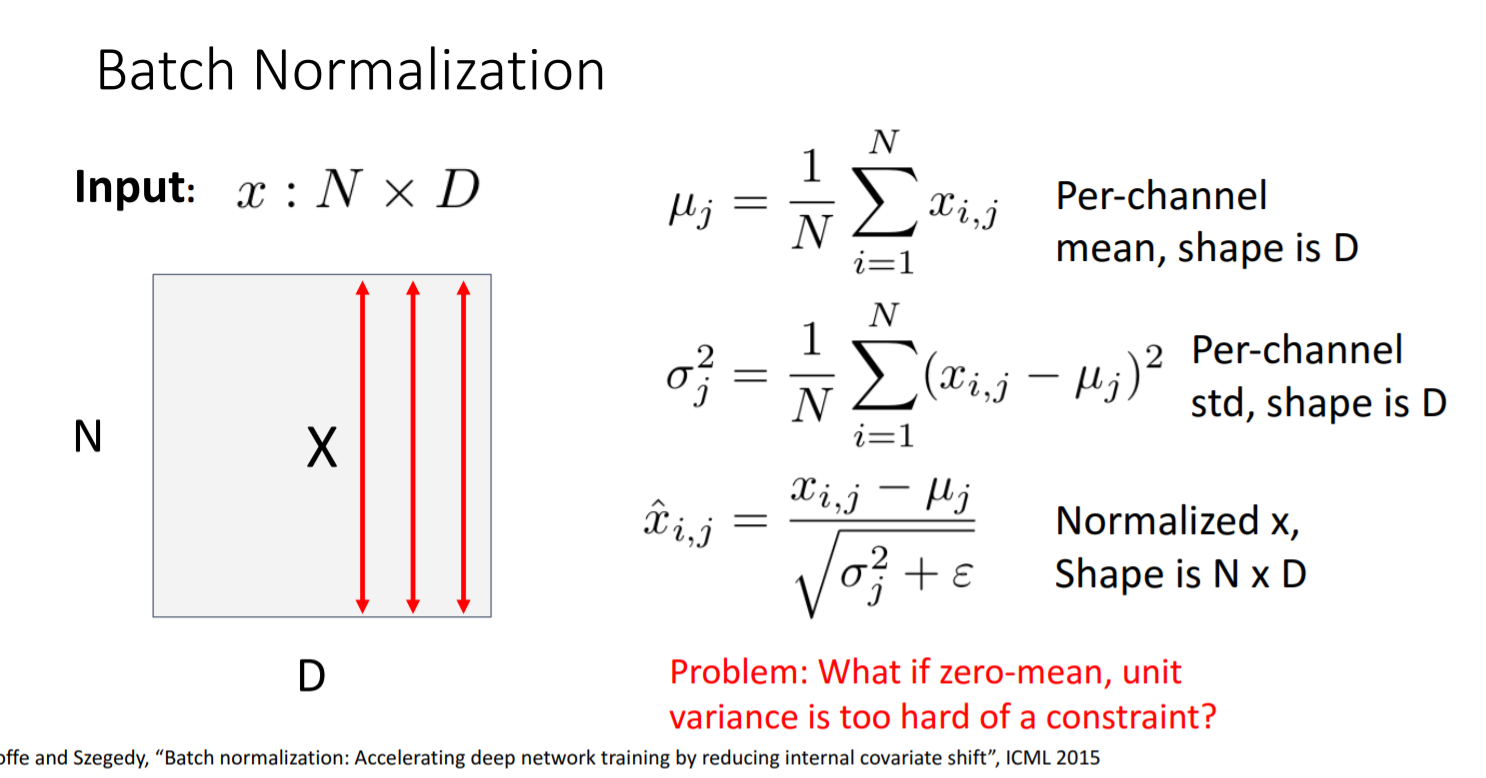
[식에 대한 구체적인 이해]
- N: batch dimension
- D: number of dimensions in each vector
- 연산 과정: batch dimension의 평균과 분산을 구한다. (열의 평균, 분산) 그 후, batch dimension을 또 평균한다.
- epsilon의 의미: 분산이 0일 경우 분모가 0이 되지 않도록 작은 수를 지정해주는 것
[Batch Normalization 적용 위치]
Layer를 통과할 때마다 batch normalization을 적용해준다고 했었는데 정확히 어디에 위치할까? Batch normalization은 fully connected layer/ convolutional layer 뒤, activation function 앞에 위치한다. 왜곡된 데이터에 비선형성을 부여해주면 왜곡이 심해질 것이기 때문이다.

그런데 평균이 0, 분산이 1인 표준 가우시안 분포로 batch normalization을 해준 뒤 activation function에 통과시켜주는 것이 우리가 과연 원하는 상황인지를 돌이켜봐야 한다. 위 슬라이드의 빨간색 글씨에 적혀있는 것처럼 activation function이 tanh인 구제적인 상황을 가정해보자.
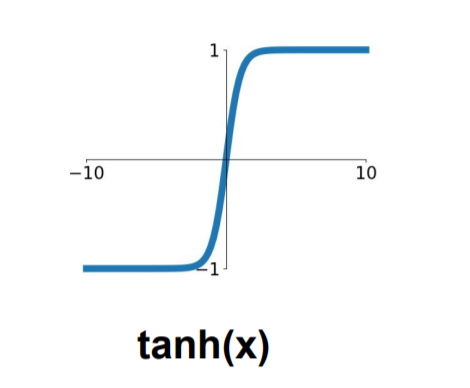
Activation function은 neural network에 부여하기 위해 사용하는데 0 근처에서 tanh 함수는 근사적으로 선형함수이다. 이 경우 activation function을 사용했던 본래의 의미가 퇴색된다. Gradient saturation을 피하기 위해 선형 영역에 통과시키려다가 비선형성을 없애버린 셈이다. 비선형성을 부여하면서도 gradient saturation을 피하기 위한 그 사이의 적당한 지점을 저울질하기 위해 데이터를 원래의 형태로 복구시키는 작업도 필요하다.

식을 변형해서 데이터를 복구시키는 식을 구해보자.
- normalization된 데이터 = (데이터 - 평균) / 표준편차
- 데이터 = 표준편차 * normalization된 데이터 + 평균
- y = Γ * x + β
2. Setting up the data and the model
2-1. Data Preprocessing
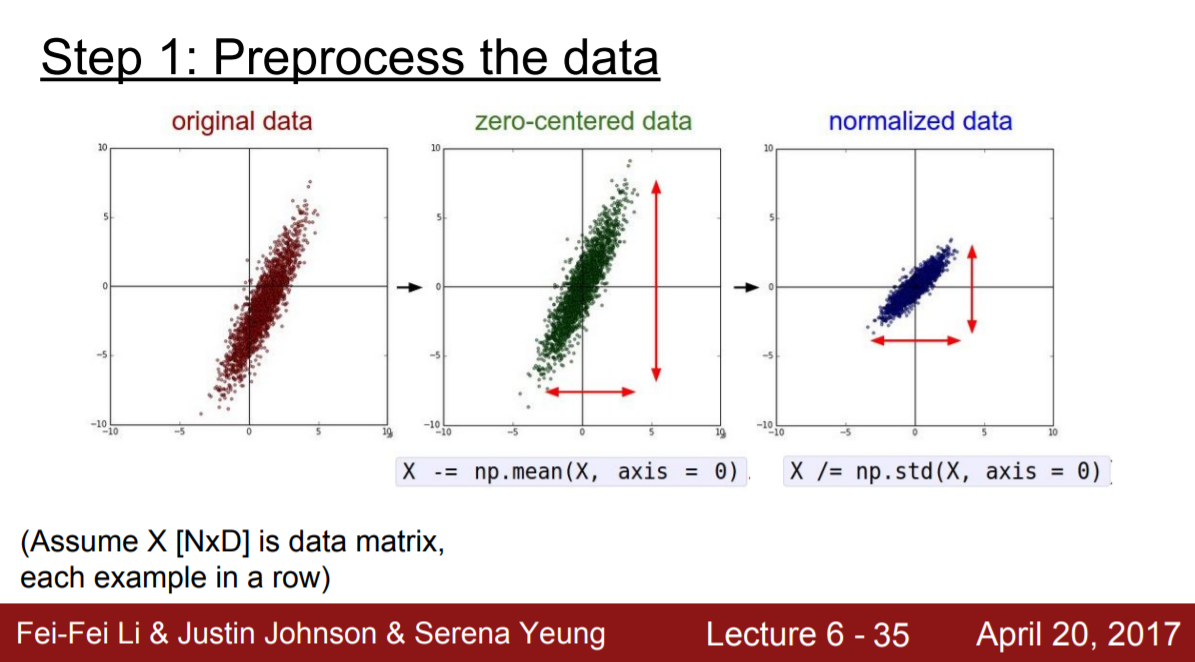
Data Preprocessing은 크게 mean subtraction, normalization 절차로 이루어진다.
- mean subtraction : 모든 특징에 대해 평균을 빼서 모든 차원에서 원점 중심에 데이터를 위치시킨다.
- normalization : feature마다 scale이 다른 경우가 있다. 이럴 때 scale의 차이에 따라 왜곡이 일어나므로 통일시켜주는 작업이 normalization이다. 하지만 이미지의 경우 pixel 값이 0과 255 사이에 분포하므로 feature마다 scale의 차이가 존재하지 않는다. 따라서, 이미지는 normalization 작업을 거치지 않는 경우가 많다.
Data processing하는 절차를 배웠는데 그렇다면 애초에 data processing을 하는 이유가 무엇일까?
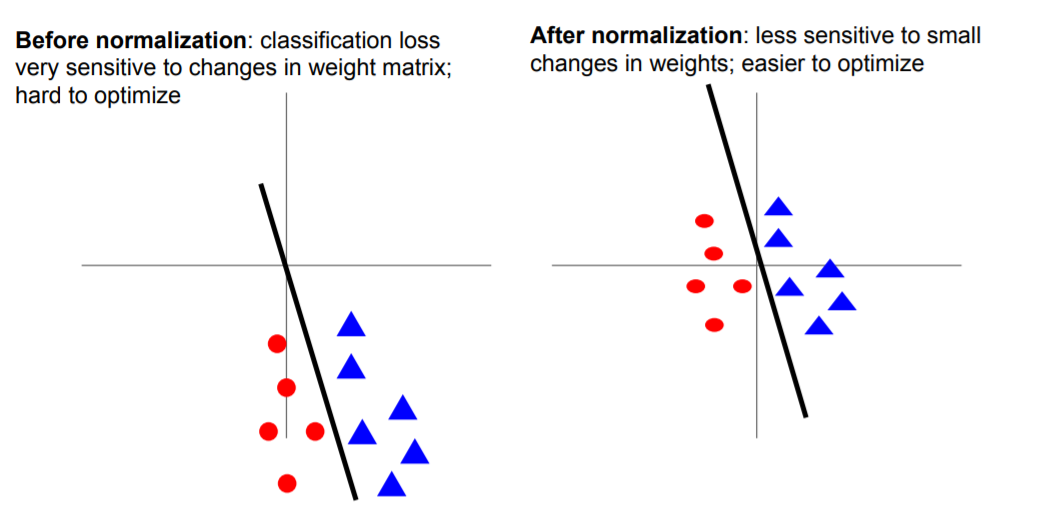
Normalization을 하기 전에는 loss function이 weight matrix의 값들의 작은 변동에도 취약했다. 하지만, normalization을 해준다면 weight matrix 값들의 변동에 조금은 더 robust해진다.
2-2. Weight initialization
Neural network를 학습할 때 loss function의 출발 위치를 지정하는 작업이 weight initialization이다.
[0으로 초기화]
Weight initialization을 한다고 할 때 가장 먼저 떠올릴 수 있는 방법은 weight를 모두 0으로 설정하는 것이다. 하지만 그렇게 되면 f=wTx+b일 때 bias가 0이면 출력이 항상 0이된다. Relu함수에서 0이 입력되면 0이 출력되므로 activation function을 통과하면 0만이 출력되고 gradient 역시 0이 출력되므로 학습이 이루어지지 않는다.
[small random numbers]
N(0, 0.01^2)의 평균은 0, 표준편차가 0.01인 가우시안 분포의 random 숫자들을 생성해보자.

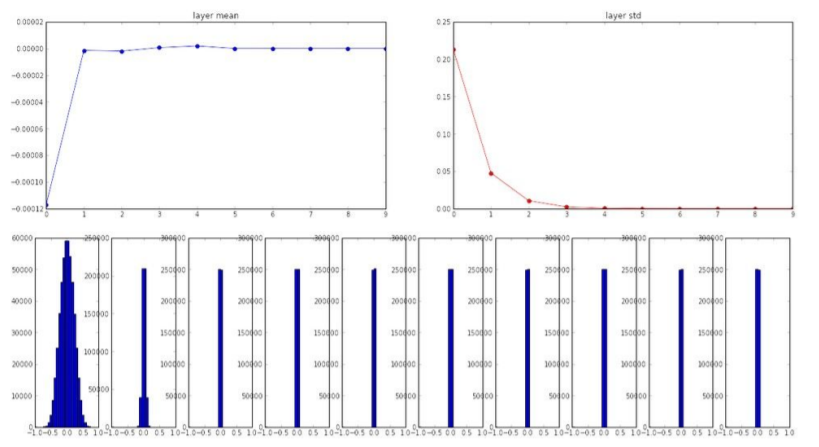
위의 그래프에서 볼 수 있듯이 layer를 통과할 수록 출력 값이 0이 된다. 가중치가 작으면 출력값도 작기 때문에 가중치를 0으로 설정했을 때와 비슷한 상황이 발생한다.
[large random numbers]
그렇다면 표준 편차를 크게 잡아주면 문제가 해결되지 않을까? N(0, 1)의 평균은 0, 표준편차가 1인 가우시안 분포의 random 숫자들을 생성해보자.
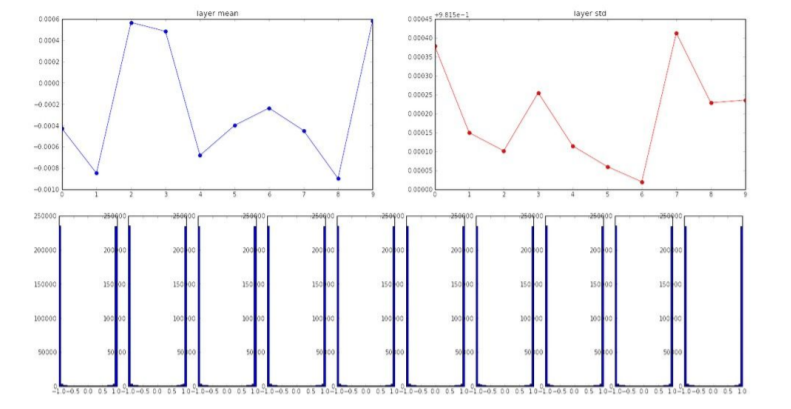
위의 그래프는 activation function으로 tanh를 지정한 후 neural network를 통과시킬 때 layer 별 출력값을 나타낸다. 값들이 -1과 1에 몰려있는 현상을 볼 수 있는데 이는 weight 값이 너무 커서 gradient saturation이 영역으로 weight가 입력되기 때문이다.
2-2.1 Xavier initialization
Weight는 너무 작아도, 너무 커서도 안된다는 것을 위에서 확인했다. 데이터의 분포가 일정하게 유지될 수 있도록 하는 방법을 찾아보자. Xavier initialization은 이러한 고민에서 나온 초기화 방법으로 Sigmoid 계열 activation function을 사용할 때 사용되는 방법이다. Sigmoid 계열 함수에만 적용이 되는 이유는 0근처에서 선형 함수라는 가정하에 이루어지기 때문이다. 선형 함수로 가정하는 이유는 layer를 거듭하여도 gradient saturation이 일어나지 않도록 weight 값들을 설정해주고 싶기 때문이다. Xavier initialization의 핵심 목표는 layer를 거듭하더라도 분산을 유지시키자라는 것이다.
- weight의 가중 합산
(선형함수 가정했기 때문에 linear combination으로 표현)
(각 x는 iid(independent and identically distributed) radom variables)
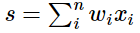
- weight의 가중 합산의 분산
- E(xi) = 0, E(wi) = 0
- Var(s) = Var(x)
(Weight initialization에서 입출력의 분산 같게 만들기 위한 가정)
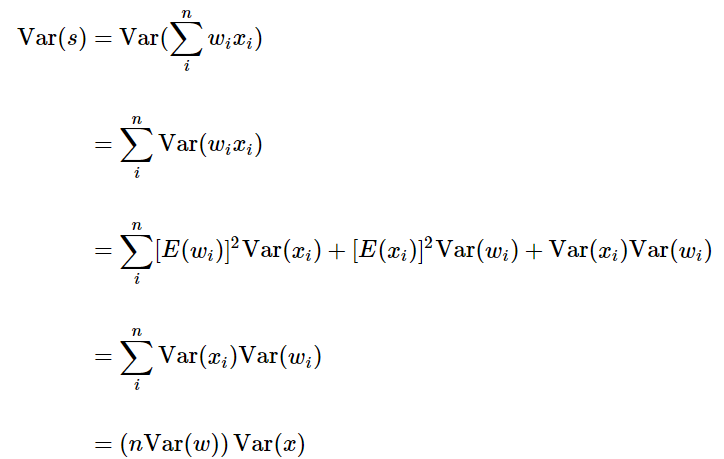
Var(s) = Var(x)이기 때문에 양변에서 소거해주면 weight의 분산 Var(w) = 1/n이다.
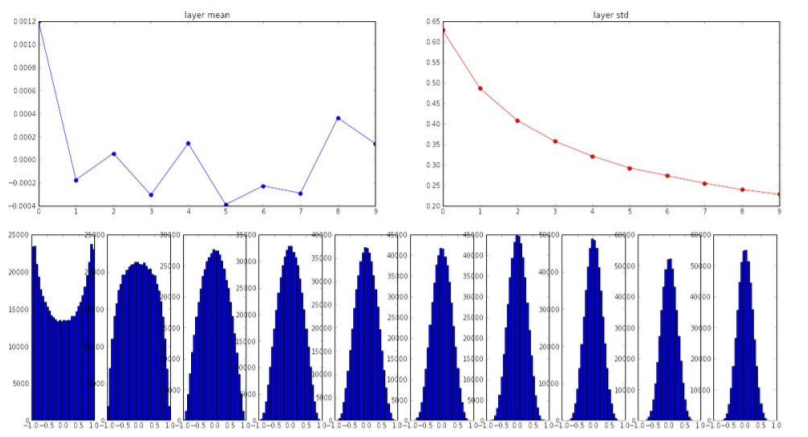
위의 그래프에서 분산이 1/n으로 유지된다.
Xavier initialization에 relu 계열 함수를 적용하면 어떻게 될까? Relu 함수의 경우, tanh와 달리 선형성이 양수인 영역만 성립한다. 따라서 layer를 거듭할수록 분산이 반토막난다.
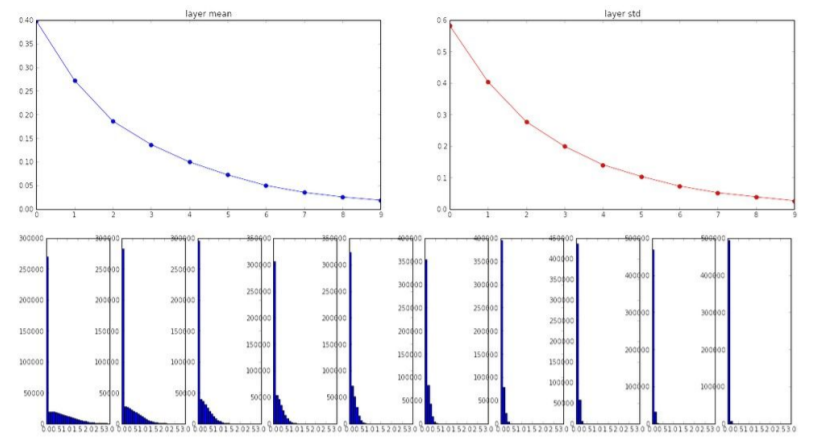
그래프에서도 분산이 계속 반씩 줄어드는 것을 확인할 수 있다. 여기서 잠시 데이터의 분포가 왜 예쁜 가우시안이 나오지 않는지 궁금할 수도 있다. Relu함수는 음수 영역에 대해서 모두 0이 출력하기 때문에 0에 데이터가 몰린채 가우시안 분포에서 오른쪽 부분만 보이는 것이다.
2-2.2 He initialization
Xavier initialization에서 초기 random weight의 분산을 1/n으로 설정하고 relu함수를 사용했을 때 layer를 통과할 때마다 분산이 0.5배된다는 것을 확인하였다. 그렇다면 분산을 두 배로 늘려주면 분산이 유지될 것이다. 따라서, relu 계열의 activation function을 사용할 땐 weight의 분산을 2/n인 random number로 weight initialization을 한다.
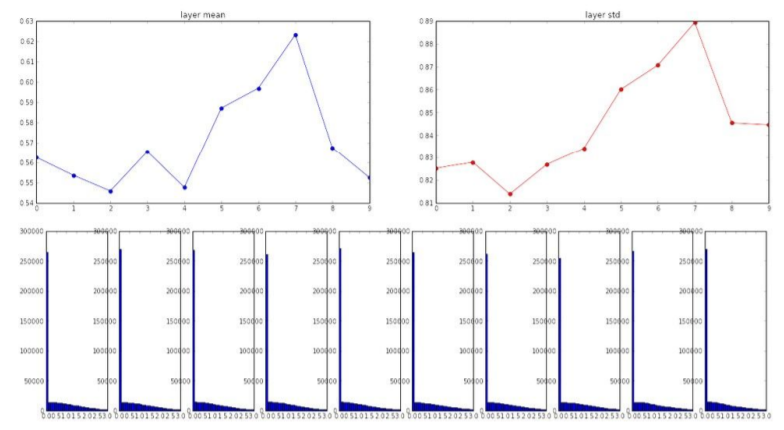
위의 그래프에서 neural network가 깊어지더라도 분산이 일정하게 유지되는 것을 확인할 수 있다.
2-2.3 Relu 함수를 사용할 때 Xavier initialization 적용?
Xavier initialization에서 분산을 1/n을 적용하면 반토막 나는 이유가 양의 영역에서만 linear하기 때문이었다. 그렇다면 만약 relu 함수의 bias를 -1이나 더 큰 음의 값으로 준다면 0 근처에서 linear이 성립될 것인데 이렇게하면 2/n인 분산을 쓰는 He initialization이 아닌 Xavier initialization으로 분산이 일정하게 유지될 것 같다. 추후에 relu 함수를 max(o, x)가 아닌 max(-1,x)이런식으로 음의 bias를 주고 Xavier initialization을 했을 때 분포가 유지되는지 코드로 확인해볼 예정이다.
3. Training Neural Network
모델의 layer를 쌓고 data의 가공, weight의 초기화와 같은 기초 작업을 마치면 모델의 큰 틀을 완성한 셈이다. 이제부터는 모델을 학습하면서 hyperparameter들을 바꿔가며 모델의 성능을 최대한으로 끌어올릴 것이다. CS231n 강의에서는 hyperparameter를 어떻게 바꿔야할지에 대한 방향성을 제시해준다.
3-1. 절차
3-1.1 Preprocess data
Preprocessing data에 대해서는 앞서 설명했다.
3-1.2 Architecture 설계
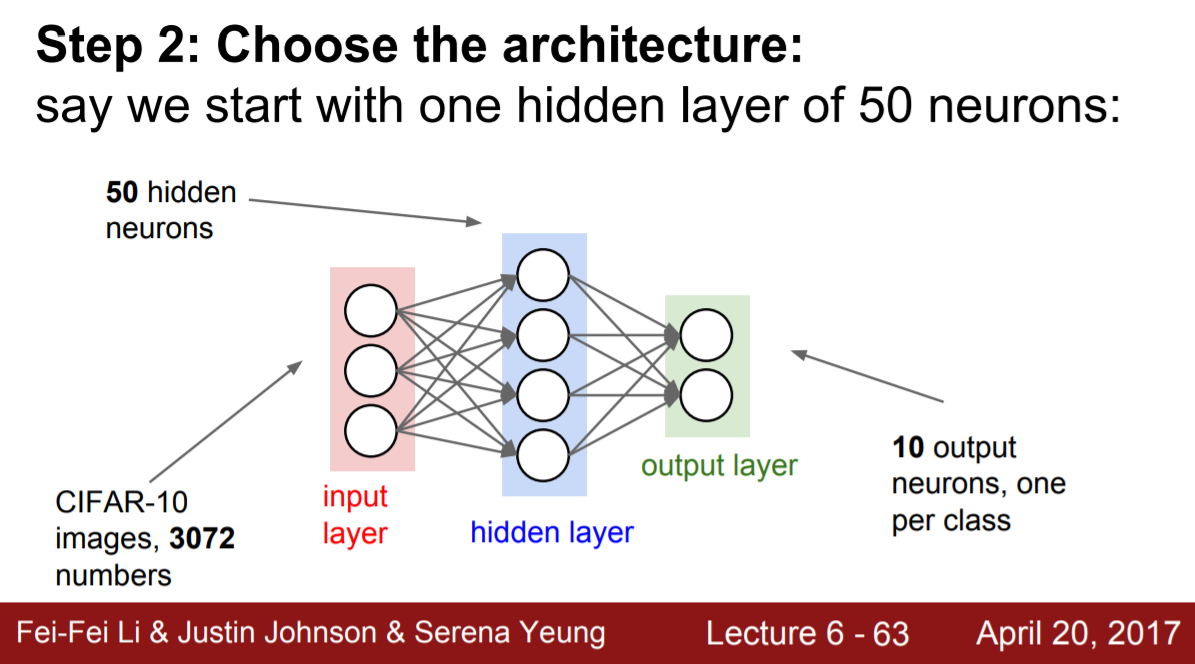
Architecture 설계는 몇개의 hidden layer를 사용할 것인지 각 hidden layer에는 몇 개의 뉴런을 사용할지를 정하는 과정이다.
3-1.3 Hyperparameter tuning
Loss 값이 적합한지 확인해보자
Regularization이 없을 때의 loss 값

Regularization이 없을 때의 loss 값이 예측한 값과 비슷한지 먼저 확인해보자. 만약 loss 값이 예측과 다르다면 weight 초기화가 제대로 이루어지지 않은 것이기 때문이다. 위의 경우 Softmax classifier를 이용해서 CIFAR-10 데이터를 학습시켰다. CIFAR-10 10개의 클래스가 존재하므로 하나의 클래스 당 확률이 0.1이다. Softmax loss 값은 -ln(0.1) = 2.302이이므로 위의 loss 값과 예측 값은 일치한다.
Regularization이 가했을 때의 loss 값

Regularization을 가한다면 training loss 값이 증가할 것이므로 실제로 그런지 확인해보자. 위에서 loss 값이 대략 2.302에서 3.06으로 올라간 것을 확인했다.
Overfit a tiny subset of data
전체 training data를 돌려보기 전에 일부분으로 학습시켜서 overfit이 되는지를 확인하자.
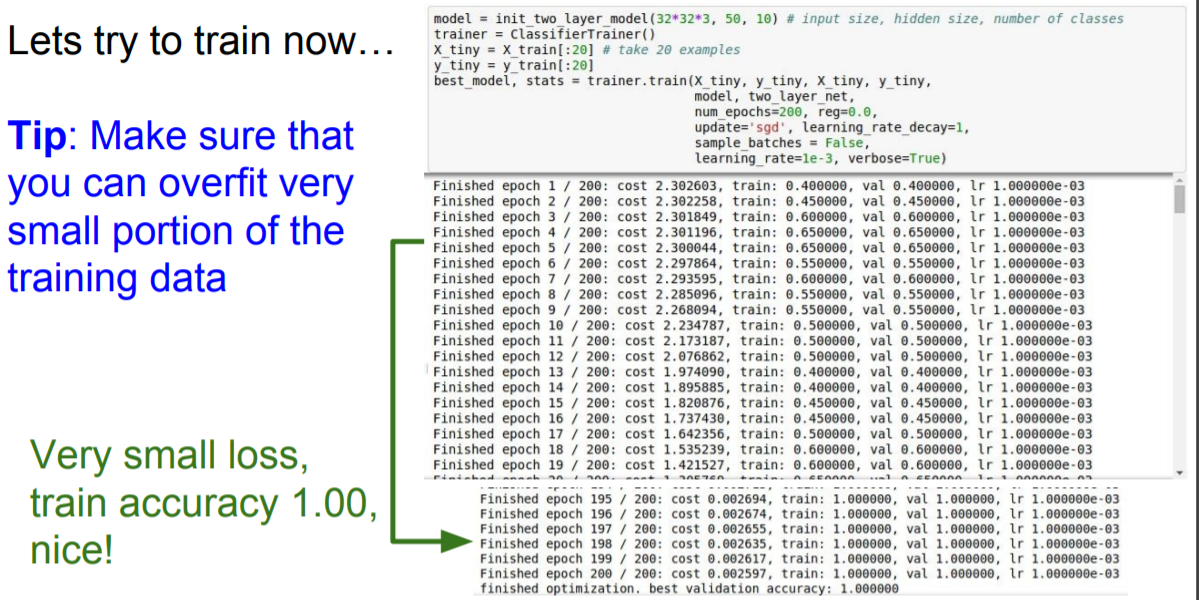
Training loss 값이 0에 근사하고 training accuracy가 1.00이 나오는 것을 통해 overfitting된 것을 알 수 있다.
Learning rate
Training data의 일부분으로 overfitting이 되는지 확인해줬으므로 이제 전체 training data를 이용해서 모델을 돌려보자.
- Learning rate 작게
Learning rate = 1e-6일 때 loss가 잘 내려가지 않으므로 learning rate가 너무 작다는 것을 추측할 수 있다.

- Learning rate 크게
Loss가 잘 내려가지 않았으므로 이번에는 learning rate를 크게 잡아보자. Learning rate = 1e6일 때는 training loss가 NaN이 나온다. 이런. Learning rate를 너무 크게 잡아서도 안되는 것을 알 수 있다.

- 적당한 learning rate
적당한 learning rate는 너무 크지도 작지도 않게 1e-3에서 1e-5정도로 잡아주면 된다고 한다.
Grid vs Random Search
적당한 neural network의 크기는 어떻게 구할까? 마냥 깊게만 layer를 쌓는게 능사는 아니다. Neural network의 크기를 탐색하는 방법으로 grid search와 random search가 있다.
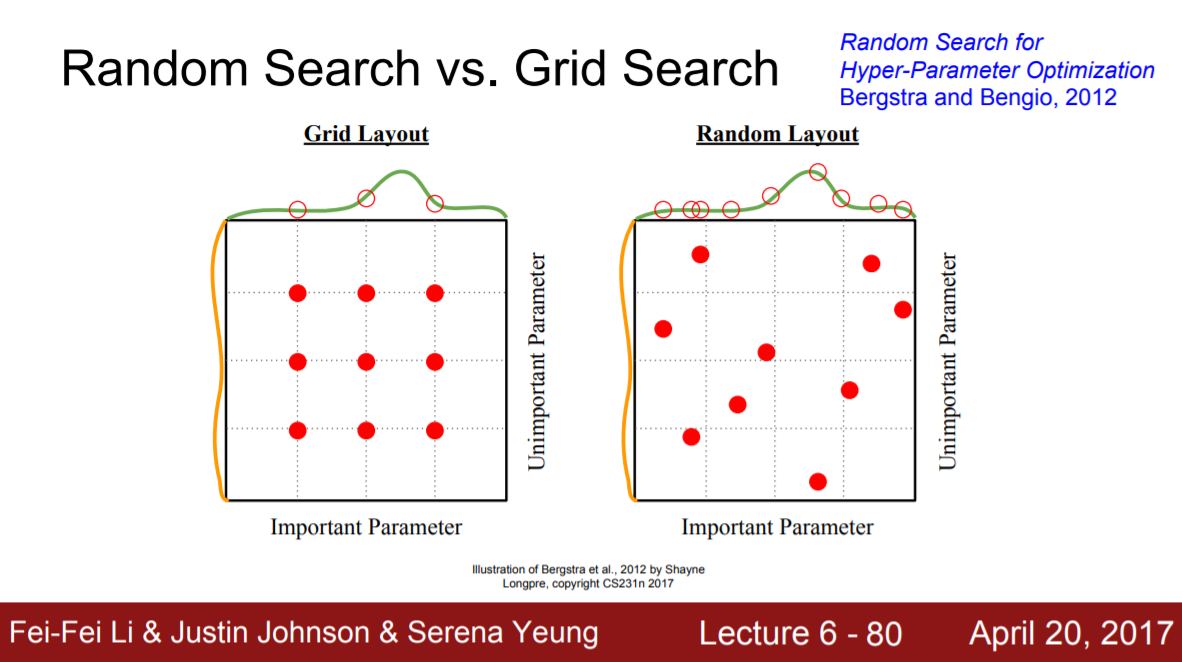
- Grid search
Grid search는 구간을 같은 간격으로 나워서 값을 샘플링하는 방법이다. - Random search
Random search는 랜덤하게 값을 샘플링한다.
보통 random search가 성능이 더 좋다고 한다. 자세한 설명은 https://0902.tistory.com/8 를 참고하자.
그래프 보기
모델을 학습할 때, epoch에 따른 loss와 accuracy 그래프를 통해 learning rate나 batch size와 같은 hyperparameter를 어떻게 바꿀지에 대한 감을 잡을 수 있다.
Loss 그래프
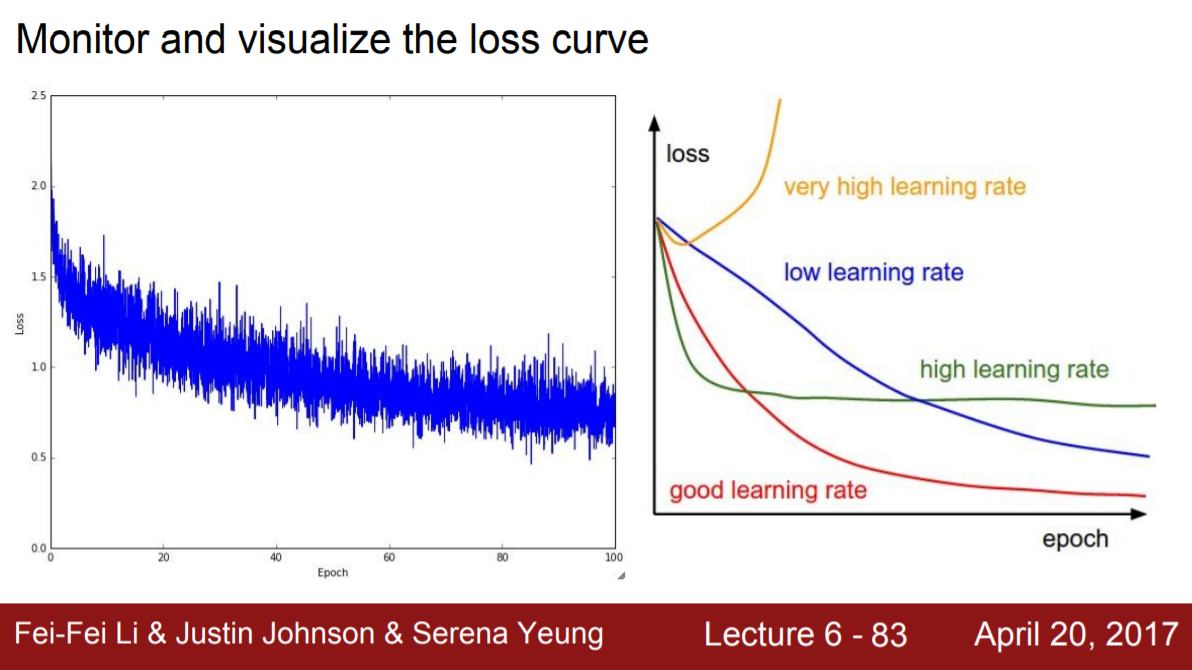
Loss 그래프의 형태에 따라 learning rate가 작은지 큰지를 판단할 수 있다. Learning rate가 크다면 빠르게 loss가 하강하겠지만 힘이 너무 쎄서 local minima에 도달하지 못하고 loss 곡면에서 진동하기 때문에 loss 값이 충분히 감소하지 못한다. 그에 반해 learning rate가 너무 작아도 문제다. 안정적으로 loss 값이 작아지는 것처럼 보이나 속도가 너무 느리다.
왼쪽 그래프의 경우 loss 그래프가 꽤 많이 진동하는 것을 관찰할 수 있는데 batch 크기가 너무 작아서일 수도 있다. Batch 크기가 작을수록 stochastic한 특성이 커지기 때문이다.
Accuracy 그래프

Accuracy 그래프의 경우, training accuracy와 validation accuracy를 함께 봐야 한다. Training accuracy는 validation accuracy보다 항상 더 클 것이다. 다만, 이때 두 정확도의 간격을 통해 overfitting되었는지를 판단한다.
Training accuracy와 validation accuracy의 간격이 너무 큰 것은 너무 데이터가 training data에 fit되게 학습되어 충분히 일반화가 이루어지지 않았다는 뜻이다. 이 경우 Regularization 방법을 통해 일반화를 해주거나 데이터의 수를 늘려준다.
Training accuracy가 validation accuracy의 간격이 너무 작은 경우도 이상적이지 않다. 데이터의 수에 비해 모델이 충분히 크지 않을 때 간격이 좁게 나타나기 때문이다. 성능 개선의 여지가 있으므로 해결방안으로 모델의 크기를 키워주도록 한다.
