특정 위치를 기준으로 특정 반경안의 확보가능한 모든 시설을 DB에 구성하기 위한 작업을 시작하려고 한다. DBMS는 mysql을 사용했으며 kakaomap API를 이용해 크롤링한 데이터를 데이터베이스에 확보하는 것을 목표로 한다.
KaKaoMap API
키발급은 정말 간단하다. 키발급 이후 REST API 키를 활용하여 검색어 입력시 관련 정보들이 어떻게 나오는지 확인했다. 그 결과 정해진 위치 기준으로 15개의 가장 가까운 시설을 나타냈다. 카카오맵에 검색하는 것과 API로 받는 것이 동일한 결과를 가져오는 것으로 나타났다.
랜드마크를 기준으로 반경 n km안의 시설 리스트에 해당하는 모든 시설을 추출하길 원했으며 이것을 DB안의 데이터베이스 속 테이블에 축적시키기를 원했다. 이를 위해 sql서버를 열고 table을 정의해야한다.
DB 정의
CREATE DATABASE mydb; # 데이터베이스 만들기
SHOW DATABASES; # 만들어진 데이터베이스 확인
USE mydatabase; # 데이터베이스 활성화
# 테이블 정의
CREATE TABLE IF NOT EXISTS places (
id INT AUTO_INCREMENT PRIMARY KEY,
address_name VARCHAR(255),
category_group_code VARCHAR(50),
category_group_name VARCHAR(255),
category_name VARCHAR(255),
distance VARCHAR(50),
phone VARCHAR(50),
place_name VARCHAR(255),
place_url VARCHAR(255),
road_address_name VARCHAR(255),
x DECIMAL(10, 6),
y DECIMAL(10, 6)
);카카오맵에서 주는 피처들을 고려하여 데이터베이스를 정의 후 테이블을 정의했다. 우리는 검색어 입력시 카카오맵API를 이용하여 스크립트 파일이 DB로 검색된 데이터를 전달하는 것을 목표로 한다. 자동화와 가독성을 위해 클래스로 제작한다.
DB insert class 제작
import requests
import mysql.connector
class CrawlerPlaceKakao:
def __init__(self, host, user, password, database, auth_key):
self.host = host
self.user = user
self.password = password
self.database = database
self.auth_key = auth_key
def get_connection(self):
return mysql.connector.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database
)
def get_cursor(self, connection):
return connection.cursor(prepared=True)
def close_connection(self, cursor, connection):
cursor.close()
connection.close()
def get_places(self, searching):
url = 'https://dapi.kakao.com/v2/local/search/keyword.json?query={}'.format(searching)
headers = {
"Authorization": self.auth_key
}
data = requests.get(url, headers = headers).json()['documents']
print(data)
connection = self.get_connection()
cursor = self.get_cursor(connection)
for entry in data:
for key in entry:
if entry[key] == '':
entry[key] = None # 빈 문자열을 None으로 대체
query = """
INSERT IGNORE INTO places (address_name, category_group_code, category_group_name, category_name,
distance, id, phone, place_name, place_url, road_address_name, x, y)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
values = (
entry['address_name'],
entry['category_group_code'],
entry['category_group_name'],
entry['category_name'],
entry['distance'],
entry['id'],
entry['phone'],
entry['place_name'],
entry['place_url'],
entry['road_address_name'],
entry['x'],
entry['y']
)
cursor.execute(query, values)
connection.commit()
# 연결 종료
self.close_connection(cursor, connection)
test = CrawlerPlaceKakao(host="호스트_이름",
user="root",
password="비밀번호",
database="mydb",
auth_key="KakaoAK ~")
test.get_places('인계동354-5 메가커피')
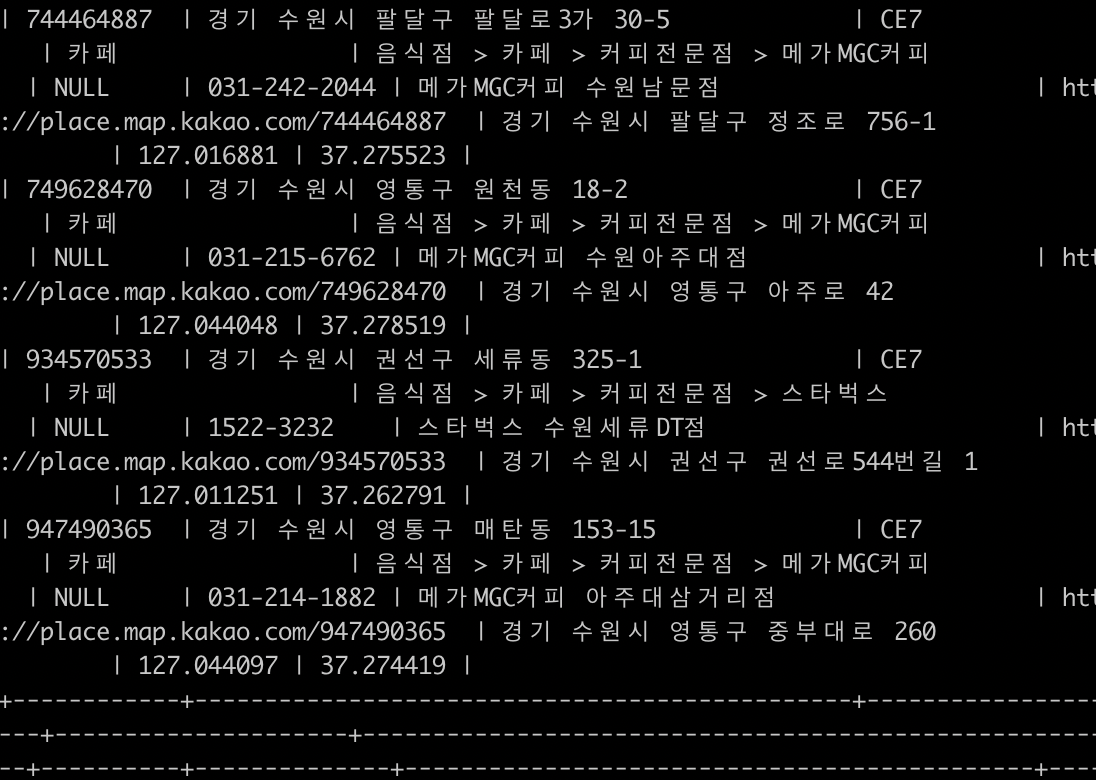
매우 잘 들어오는 것을 확인할 수 있다.
문제해결
문제는 카카오 API가 주소기준 근처 15개만 제공한다는 것이다.
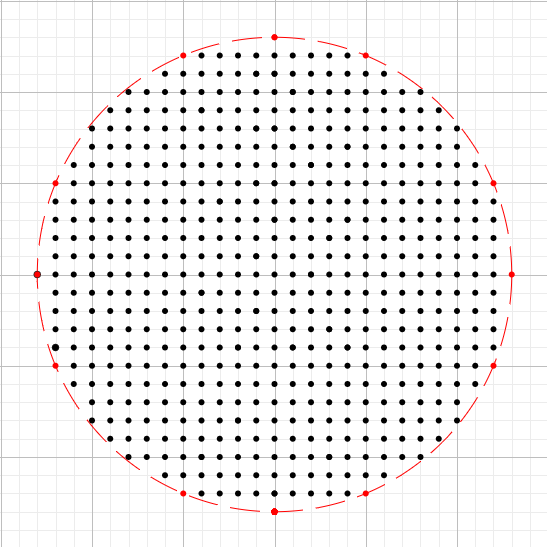
우리가 원하는 영역이 빨간 원 안이라 할 경우 해당 그림처럼 원 안에 여러 주소 포인트를 생성해서 주소 리스트를 만드는 것이다. 주소 리스트를 만들고 하나의 주소마다 검색어 리스트에 대한 crawler를 돌리면 비용이 증가하겠지만 목적을 이룰 수 있다.(비용이 크게 증가하지도 않음)
다만 SQL 쿼리문을 작성할 때 중복에 대한 요소를 고려해야한다. 그렇기에 미리 코드에 IGNORE조건을 추가하여 작성해놨다. 아마 키값으로 부여된 id값 때문에 중복의 걱정은 없지만.
다음 검사할 사항은 점포리스트와 주소리스트를 모두 구성한 후 해당 기능의 시간을 측정하는 테스트가 필요하며, DB구성 후 검색에 대한 알고리즘도 잘 짜야할 것 같다. 업종코드와 같은 서브코드들을 활용하는 것이 좋을 것 같다.
