
머신 러닝 모델은 이미지, 음악, 글의 통계적 잠재 공간을 학습할 수 있다. 그 다음 이 공간에서 샘플을 뽑아 새로운 예술 작품을 만들 수 있다. 예를 들어 독주에서 오케스트라의 모든 악기 조합을 테스트할 수 있다. AI를 활용하는 작곡가는 일종의 파일럿이며, 출발 버튼을. 누르고 좌표를 설정하면 소리의 우주를 항해하는 우주선을 조정한다.
텍스트 생성
순환 신경망으로 시퀀스 데이터를 생성하는 방법을 살펴보도록 한다. 책이 서술될 때를 기준으로 가장 잘 알려진 생성 트랜스포머의 예는 GPT-3이다. 현재 이 글을 서술할 때에는 CHAT-GPT가 새로운 혁신으로서 사람들에게 서비스되고 있다.
Chat-GPT
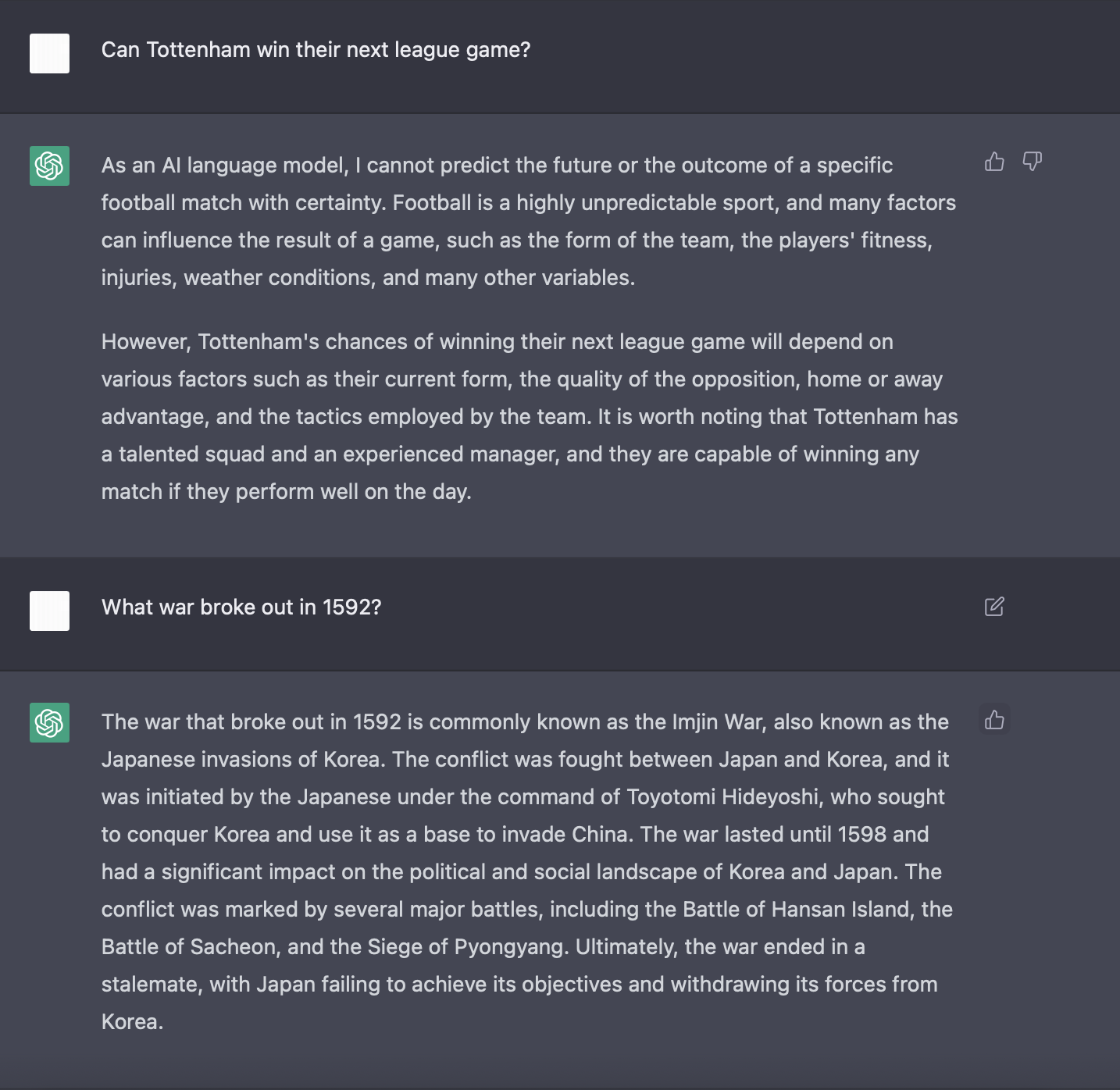
현재 무료로 서비스 되고 있는 구글의 chat-gpt를 활용하여 여러 질문을 던져보았다. 간단한 답변이 아닌 매우 구체적이고 확장적인 답변을 주고있다. 1592년에 어떤 전쟁이 발생하였는지, Tottenham의 다음 리그 경기에 대한 생각또한 물어보았다. 창의성과 정보성을 모두 테스트 해보았다.
시퀀스 데이터를 어떻게 생성할까?
딥러닝에서 시퀀스 데이터를 생성하는 일반적인 방법은 이전 토큰을 입력으로 사용해서 시퀀스의 다음 1개 또는 몇 개의 토큰을 트랜스포머나 RNN으로 예측하는 것이다. 예로 the cat is on the란 입력이 주어지면 다음 단어인 타깃 mat을 예측하도록 모델을 훈련시킬 수 있다.
- 이전 토큰들이 주어졌을 때 다음 토큰의 확률을 모델링할 수 있는 네트워크를
언어 모델(language model)이라고 부른다.
샘플링 전략의 중요성
학습에 있어서 텍스트 생성 시 다음 문자를 선택하는 방법이 아주 중요하게 된다. 단순하게는 항상 가장 높은 확률을 선택하는 탐욕적 샘플링(greedy sampling)이다. 하지만 이 방법은 반복적이고 예상 가능한 문자열을 만들기에 논리적인 언어처럼 보이지 않게 된다. 샘플링 과정에 무작위성을 주입한다면 이는 확률적 샘플링(stochastic sampling)이라고 불리우며 stochastic은 정확히는 무작위하다는 뜻으로 의역될 수 있다. 이렇게 확률적 샘플링을 사용한다면, 새로운 문장은 더 흥미롭게 보일 수 있고 이따금 창의성을 보이나, 샘플링 과정에서 무작위성의 양을 조절할 방법이 없다.
작은 엔트로피는 예상 가능한 구조를 가진 시퀀스를 생성하며, 높은 엔트로피는 놀랍고 창의적인 시퀀스를 만든다. 생성과정에서 무작위성의 양을 여러번 테스트해보는 것이 좋다.
샘플링 과정에서 무작위성의 양을 조절하기 위해 소프트맥스 온도라는 파라미터를 사용한다.
이전 장과 동일하게 IMDB 영화 리뷰 데이터셋을 계속 활용하여 이전에 본 적이 없는 영화 리뷰를 생성하는 방법을 학습시켜보도록 한다.
from tensorflow.keras.layers import TextVectorization
sequence_length = 100 # 시퀀스 길이 설정(각 리뷰에서 처음 100개 단어만 사용, 이보다 길 경우 잘라버림)
vocab_size = 15000 # max_tokens수 그 외 단어 OOV토큰으로 처리
text_vectorization = TextVectorization(
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=sequence_length,
)
text_vectorization.adapt(dataset)def prepare_lm_dataset(text_batch):
vectorized_sequences = text_vectorization(text_batch) # 텍스트 배치를 정수 시퀀스 배치로 변환
x = vectorized_sequences[:, :-1] # 시퀀스의 마지막 단어 제외한 입력 구성
y = vectorized_sequences[:, 1:] # 시퀀스의 마지막 단어로 타깃 구성
return x, y
# dataset에 map()메소드로 적용
lm_dataset = dataset.map(prepare_lm_dataset, num_parallel_calls=4)몇 개의 초기 단어가 주어지면 문장의 다음 단어에 대한 확률 분포를 예측하는 모델을 훈련시킨다. 다음 단어는 다시 초기단어가 되어 그 다음 단어를 예측하는 식응로 짧은 문단을 생성할 때까지 반복한다.
- 이 모델은 N개의 단어로 예측을 만드는 방법을 학습하지만 N개보다 적은단어로 예측을 시작할 수 있어야 한다.
- 훈련에 사용하는 많은 시퀀스는 중복되어 있다.
이러한 두 이슈를 해결하기 위해 시퀀스-투-시퀀스 모델을 사용하도록 한다. 단어 N개의 시퀀스(0~N까지)를 모델에 주입하고 한 스텝 다음의 시퀀스(1~N+1)를 예측한다. 소스 시퀀스를 인코더에 주입하고 인코딩된 시퀀스와 타깃 시퀀스를 디코더로 전달하여 한 스텝 후의 타깃 시퀀스를 예측한다. 텍스트 생성에서는 소스 시퀀스가 없다. 과거 토큰이 주어지면 타깃 시퀀스에 있는 다음 토큰을 예측하는 것뿐이다.
from tensorflow.keras import layers
embed_dim = 256
latent_dim = 2048
num_heads = 2
inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs)
x = TransformerDecoder(embed_dim, latent_dim, num_heads)(x, x)
outputs = layers.Dense(vocab_size, activation="softmax")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="sparse_categorical_crossentropy", optimizer="rmsprop")
import numpy as np
# 단어 인덱스를 문자열로 매핑하는 딕셔너리.
tokens_index = dict(enumerate(text_vectorization.get_vocabulary()))
# 어떤 확률 분포에 대한 가변 온도 샘플링 구현
def sample_next(predictions, temperature=1.0):
predictions = np.asarray(predictions).astype("float64")
predictions = np.log(predictions) / temperature
exp_preds = np.exp(predictions)
predictions = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, predictions, 1)
return np.argmax(probas)
class TextGenerator(keras.callbacks.Callback):
def __init__(self,
prompt, # 시작 문장
generate_length, # 생성할 단어 개수
model_input_length,
temperatures=(1.,), # 샘플링에 사용할 온도 범위
print_freq=1):
self.prompt = prompt
self.generate_length = generate_length
self.model_input_length = model_input_length
self.temperatures = temperatures
self.print_freq = print_freq
def on_epoch_end(self, epoch, logs=None):
if (epoch + 1) % self.print_freq != 0:
return
for temperature in self.temperatures:
print("== Generating with temperature", temperature)
sentence = self.prompt # 시작 단어에서부터 텍스트 생성
for i in range(self.generate_length):
tokenized_sentence = text_vectorization([sentence])
predictions = self.model(tokenized_sentence)
next_token = sample_next(predictions[0, i, :])
sampled_token = tokens_index[next_token]
sentence += " " + sampled_token
print(sentence)
prompt = "This movie"
text_gen_callback = TextGenerator(
prompt,
generate_length=50,
model_input_length=sequence_length,
temperatures=(0.2, 0.5, 0.7, 1., 1.5))콜백을 사용하여 에포크가 끝날 때 마다 다양한 온도로 텍스트를 생성한다. 모델이 수렴하면서 생성된 텍스트가 어떻게 발전하는지와 온도가 샘플링 전략에 미치는 영향을 확인 가능하다.
- 결과에서 볼 수 있듯이 낮은 온도는 매우 단조롭고 반복적인 텍스트를 만든다. 더 높은 온도에서 생성된 텍스트는 아주 흥미롭고 놀라우며 창의적이다.
딥드림(DeepDream)
합성곱 신경망이 학습한 표현을 사용하여 예술적으로 이미지를 조작하는 기법이다. 딥드림 알고리즘은 9장에서 소개한 컨브넷을 거꾸로 실행하는 컨브넷 필터 시각화 기법과 거의 동일하다.
- 인셉션 V3 모델로 하여금 사전 훈련된 컨브넷을 사용한다.
- 딥드림은 네트워크가 학습한 표현을 기반으로 컨브넷을 거꾸로 실행하여 입력 이미지 생성
- 환각제 때문에 시야가 몽롱해진 사람이 만든 이미지 형상
- 음성과 음악에도 적용될 수 있다.
뉴럴 스타일 트랜스퍼
뉴럴 스타일 트랜스퍼는 2015년 처음 소개된 이후 많이 개선되었으며, 여러 변종이 생겼고 스마트폰 사진 앱에서도 쓰인다. 타깃 이미지의 콘텐츠를 보존하면서 참조 이미지의 스타일을 타깃 이미지에 적용한다.

여기에서 스타일은 질감, 색깔, 이미지에 있는 다양한 크기의 시각요소를 의미한다. 콘텐츠는 이미지에 있는 고수준의 대형 구조를 말한다.
핵심 개념
목표를 표현한 손실 함수를 정의하고 이 손실을 최소화한다. 참조 이미지의 스타일을 적용하면서 원본 이미지의 콘텐츠를 보존하는 것이다.loss = distance(style(reference_image) - style(combination_image)) + distance(content(original_image) - content(combination_image))여기서 distance는 L2 노름 같은 노름 함수이다. content함수는 이미지의 콘텐츠 표현을 계산한다. style함수는 이미지의 스타일 표현을 계산한다. loss가 작아지기 위해서는 두 distance가 모두 작아져야한다. 즉 참조와 콤비네이션간의 스타일 거리가 작아지게끔, 본래 이미지의 콘텐츠와 콤비네이션 이미지의 콘텐츠 거리가 작아지게끔 손실함수의 최솟값을 찾아 combination image를 구성하는 것이다.
뉴럴 넷 네트워크의 특징은 입력 데이터가 주입되면 층을 거치면서 추상화되고 압축된다는 점이 있다. 그와 동일하게 네트워크에서 하위 층의 활성화는 이미지에 관한 국부적인, 즉 어느 부분에만 한정되는 구체적인 정보를 담고 있으며 상위층의 활성화는 전역적이고 추상화된 정보를 가진다.
- 콘텐츠는 그림에서 고수준의 대형구조를 뜻한다. 즉 상위 층의 표현을 사용하면 전역적이고 추상적인 그림에서 가장 크게 특징적으로 자리잡은 표현들을 캐치할 수 있다. 또한 하나의 상위 층만 사용하도록 한다.
- 스타일 손실의 경우 컨브넷의 여러 층을 사용한다. 그람 행렬을 스타일 손실로 사용하였는데, 그람 행렬은 층의 특성 맵들의 내적이다. 내적은 층의 특성 사이에 있는 상관관계를 표현한다고 이해하면 될 것이다. ( 겹치는 부분에 대한 압축적 표현)
변이형 오토인코더를 사용한 이미지 생성
잠재 시각 공간(latent visual space)를 학습하고 이 공간에서 샘플링하여 실제 사진에서 보간된 완전히 새로운 이미지를 만든다. GAN과 VAE를 사용하여 소리, 음악 또는 텍스트의 잠재 공간을 만들 수 있다. 실전에서는 사진을 사용했을 때 가장 재미있는 결과를 만들어 낸다.
이미지 생성의 핵심 아이디어는 각 포인트가 실제와 같은 이미지로 매핑될 수 있는 저차원 잠재공간의 표현을 만드는 것이다. VAE는 구조적 잠재 공간을 학습하는 데에 뛰어나며 GAN은 매우 실제 같은 이미지를 만들어낸다.
개념 백터(Concept Vector)
잠재공간이나 임베딩 공간이 주어지면 이 공간의 어떤 방향은 원본 데이터의 흥미로운 변화를 인코딩한 축일 수 있다. 구체적으로 얼굴 이미지에 대한 잠재 공간에 웃음 벡터가 있을 수 있다. 잠재공간의 z포인트가 어떤 얼굴의 임베딩된 표현이라면 z+s 포인트는 같은 얼굴이 웃고 있는 표현을 임베딩한 것이다. 즉 s포인트는 웃음벡터기준으로의 이동이기 때문에 z포인트 기준으로 웃음에 대한 특성을 부여한 것이다.
고전적인 오토인코더는 이미지를 입력받아 인코더 모듈을 사용하여 잠재 벡터 공간으로 매핑한다. 그 다음 디코더 모듈을 사용하여 원본 이미지와 동일한 차원으롤 복원하여 출력한다. 다시 말해 오토인코더는 원본 입력을 압축된 표현으로 재구성하는 방법을 학습하는 것이다. 여기서 여러 제약을 두면(소프트맥스 온도와 같은 느낌)오토인코더는 더 흥미로운 혹은 덜 흥미로운 잠재공간의 표현을 학습한다. 일반적으로는 저차원이고 0이 많도록 제약을 가한다.
현실적으로 이런 오토인코더는 유용하거나 구조화가 잘 된 잠재공간을 잘 만들지 못한다. VAE(변이형 오토인코더)는 약간의 통계기법을 추가하여 연속적이고 구조적인 잠재 공간을 효율적으로 학습하도록 만들었다.
VAE의 특징
VAE는 입력 이미지를 잠재 공간의 고정된 변환이 아닌 어떤 통계 분포의 파라미터로 변환한다. 즉 인코딩과 디코딩 과정에서 무작위성을 부여한다. 구체적으로 VAE는 평균과 분산 파라미터를 통해 이 분포에서 무작위로 하나의 샘플을 추출하여 디코딩하고 원본 입력으로 복원한다.
input_img을 인코딩한 잠재 공간의 위치에 가까운 포인트는 input_img와 비슷한 이미지로 디코딩 될 것이다. 고정된 오토인코더와 달리 이와 같은 과정을 반복한다면 연속적인 어떠한 가상 공간영역을 확보할 수 있는 것이다. 즉 이를 개념벡터로 볼 수 있고 우리는 확률분포화를 통해 이를 획득할 수 있다.
IN KERAS
MNIST 숫자를 생성하는 VAE를 구현한다고 가정할 때,
- 인코더 네트워크는 실제 이미지를 잠재 공간의 평균과 분산으로 변환한다.
( z_mean, z_log_var = encoder(input_img) - 샘플링 층은 이런 평균과 분산을 받아 잠재 공간에서 랜덤한 포인트를 샘플링한다.
(z = z_mean + exp(0.5 * z_log_var) x epsilon) - 디코더 네트워크는 잠재 공간의 z포인트를 이미지로 변환한다.
(reconstructed_img = decoder(z))
Finally, Model( input_img, reconstructed_img)
인코더 네트워크 구성하기
from tensorflow import keras
from tensorflow.keras import layers
latent_dim = 2 # 잠재공간의 차원
encoder_inputs = keras.Input(shape=(28, 28, 1)) #MNIST input shape
# convnet층 구성
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
# 컨브넷 층들을 통해 압축된 특성맵을 입력으로 z_mean, z_log_var에 사용될 벡터 만들기
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
encoder = keras.Model(encoder_inputs, [z_mean, z_log_var], name="encoder")다음은 z_mean, z_log_var를 사용하여 잠재 공간 포인트 z를 만드는 코드이다. 이부분에서 고전적인 오토인코더와 다른 "랜덤성"이 부여된다.
import tensorflow as tf
class Sampler(layers.Layer): # layer층 상속받기
def call(self, z_mean, z_log_var):
batch_size = tf.shape(z_mean)[0]
z_size = tf.shape(z_mean)[1]
epsilon = tf.random.normal(shape=(batch_size, z_size))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon디코더 네트워크 구성하기(업 샘플링)
latent_inputs = keras.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2D(1, 3, activation="sigmoid", padding="same")(x)
decoder = keras.Model(latent_inputs, decoder_outputs, name="decoder")VAE 최종 제작
- 입력으로 encoder와 decoder를 받고 sampler(랜덤화)까지 자동 구현한다. 각종 검증지표를 초기화해둔다
- trainstep에서 역방향 패스를 위한 기록용 tf.GradientTape()를 통해 z_mean, z_log_var를 계산하고, z_mean과 z_log_var에서 평균과 분산으로 하여금 랜덤성을 부여하여 z포인트를 확보하고 decoder로 재구성하고 재구성 손실 함수로 하여금 z포인트와 data의 실제 포인트간의 손실을 확보하여
kl_loss, total_loss를 확보한다. metrics 메서드를 통해 성능향상지표의 흐름을 관찰가능하게 리스트로 구성한다.
class VAE(keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super().__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.sampler = Sampler()
self.total_loss_tracker = keras.metrics.Mean(name="total_loss")
self.reconstruction_loss_tracker = keras.metrics.Mean(
name="reconstruction_loss")
self.kl_loss_tracker = keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker]
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var = self.encoder(data)
z = self.sampler(z_mean, z_log_var)
reconstruction = decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction),
axis=(1, 2)
)
)
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
total_loss = reconstruction_loss + tf.reduce_mean(kl_loss)
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"total_loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}