
Chaper7. 케라스 완전 정복하기
이어지는 장에서 비전, 시계열, 자연어, 생성딥러닝에 대해 자세히 알아보기위해 Sequential 모델과 기본 fit() 루프 이상을 알아야한다. 7장에서는 케라스API를 사용하는 주요 방법을 완전히 마스터하도록 한다.
다양한 워크플로
케라스 API 설계는 복잡성의 단계적 공개(progressive disclosure)원칙을 따른다. 단계적 공개란 단계마다 점진적으로 학습하는 것을 뜻한다.
케라스에서 모델을 만드는 세가지 방법
Sequential 모델: 가장 시작하기 쉬운 API이며 기본적으로 하나의 파이썬 리스트이다.함수형 API: 그래프 같은 모델 구조를 주로 다룬다. 이 API는 사용성과 유연성 사이의 적절한 중간 지점에 해당된다. 가장 널리 사용된다.Model 서브클래싱: 모든 것을 밑바닥부터 만드는 저수준 방법이며 모든 상세한 내용을 완전히 제어하고 싶을 경우 적합하다.
Sequential 모델은 어떤 가중치도 가지고 있지 않다. 가중치를 생성하려면 어떤 데이터로 호출하거나 입력크기를 지정하여 build() 메서드를 호출해야한다.
우리는 이전 장에서 build()메서드를 따로 호출하지 않고 입력데이터를 주입하였다. 이번 장에서는 model의 초기설정에 입력 및 출력에 있어 shape를 구축하는 것이 중요함을 알 수 있다. 실제로 이러한 과정은 다중입력, 다중출력의 모델을 구축할 때 필요한 요소이지만, Sequential 모델로 먼저 실습을 진행해보았다.
이전 장에서의 Sequential Model
우리는 이전 장에서 Sequential model안에 Dense메서드를 주입하여, model을 생성하였다. 하지만 model은 실제로 완성된 형태로 형성된 것이 아니다. 우리는 이 model에 데이터를 주입하여 훈련함으로 써 model이 자동적으로 초기완성되는 모습을 보지 못하고 model이 훈련되는 모습을 볼 수 있었다. 다중입출력 모델을 짤 때는 이 생략된 부분을 설계해줘야만 한다.
- 실제로 훈련이 되지 않은 model객체는 summary메서드 사용시 error가 발생한다.
함수형 API 모델 설계
간단한 모델과 달리 대부분 딥러닝 모델은 리스트와 같은 형태가 아니라 그래프를 닮았다 라는 책의 문구로만 이해가 힘들었다. 그림을 보며 이해해보도록 하자.
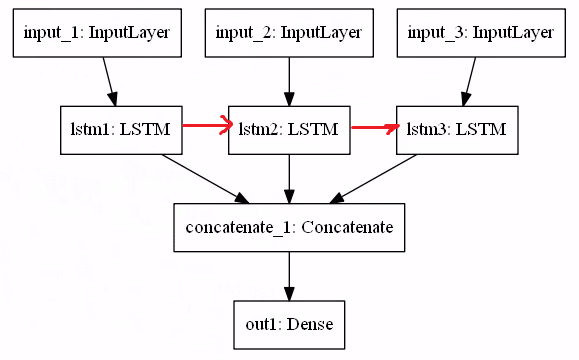
왼쪽의 경우는 리스트와 같은 형태, 즉 이전장에서 우리가 만들던 모델로 보면 될 것이다. 하지만 오른쪽의 경우는 입력데이터가 세가지나 된다. shape가 다른 , 다른 특성을 가진 데이터들이 세가지 인풋데이터로 형성되어 하나로 합쳐지는 과정이 존재한다. 이러한 논리는 출력데이터또한 다중으로 설정가능함을 말하며, 이러한 모델의 경우 함수형API로 설계해야한다.
두개의 층을 가진 다중입력, 다중출력 모델 만들기
- EX - 고객 이슈 티켓에 대한 우선순위를 지정하고 적절한 부서로 전달하는 시스템을 만들기
- input : 이슈티켓의 제목, 이슈티켓의 텍스트본문, 사용자가 추가한 태그
- output : 이슈 티켓의 우선순위 점수(0~1사이의 값), 이슈 티켓을 처리해야할 부서
# 예제 코드
vocavulary_size = 10000
#0과 1로 이루어진 배열로 만들 것임. (인코딩된 텍스트 입력)
num_tags = 100
#0과 1로 이루어진 배열로 만들 것임. (인코딩된 사용자 태그)
num_departments = 4
#0과 1로 이루어진 배열로 만들 것임. (인코딩된 부서)
title = keras.Input(shape=(vocavulary_size, ), name='title')
# 심볼릭 텐서 제작
text_body = keras.Input(shape=(vocavulary_size,), name='text_body')
# 심볼릭 텐서 제작
tags = keras.Input(shape=(num_tags,), name='tags')
# 심볼릭 텐서 제작
inputs = layers.Concatenate()([title, text_body, tags])
# 3가지의 입력 데이터를 하나의 텐서로 수직연결(inputs제작)
features = layers.Dense(64, activation='relu')(inputs)
# 수직연결한 shape대로 Dense층 만들기
priority = layers.Dense(1, activation='sigmoid', name='priority')(features)
# 우선순위 출력층 만들기 features와 연결
department = layers.Dense(num_departments, activation='softmax', name='department')(features)
# 부서 분류 출력층 만들기 features와 연결
model = keras.Model(inputs=[title, text_body, tags],
outputs=[priority, department])
# 입력 심볼릭 텐서들과 출력 심볼릭 텐서들을 인자로 모델 제작
다음과 같이 데이터 주입 전 다중입력, 다중출력 Model을 제작하였다. 그리고 나서 책에서는 랜덤한 데이터를 생성하여 학습을 진행시킨다. 코드는 다음과 같다.
# 훈련
import numpy as np
num_samples = 1280 # 데이터 샘플 수
# 0혹은 1로 이루어진 shape = (num_samples, 입력데이터)로 세개의 입력 데이터를 생성한다.
title_data = np.random.randint(0, 2, size=(num_samples, vocavulary_size))
text_body_data = np.random.randint(0, 2, size=(num_samples, vocavulary_size))
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags))
# 타겟값인 우선순위 데이터와, 부서 데이터를 생성한다.
priority_data = np.random.random(size=(num_samples, 1))
department_data = np.random.randint(0, 2, size=(num_samples, num_departments))
#모델 컴파일
model.compile(optimizer='rmsprop', loss=['mean_squared_error', 'categorical_crossentropy'],
metrics=[['mean_absolute_error'], ['accuracy']])
#모델 훈련
model.fit([title_data, text_body_data, tags_data], [priority_data, department_data], epochs=1)
#모델 평가
model.evaluate([title_data, text_body_data, tags_data], [priority_data, department_data])
#모델 예측
priority_preds, department_preds = model.predict([title_data, text_body_data, tags_data])
이전에 공부했던 부분들이 그대로 코드화 되었고 주석으로 설명을 달았으니, 따로 설명을 추가하지 않도록 하겠다. 특성추출을 수행하여 다른 모델에서 중간 특성을 재사용할 수도 있다. 우리는 이슈 티켓이 해결되는 데 걸리는 시간, 즉 일종의 난이도를 추정하려고 한다. 우리는 이러한 새로운 output을 추가하기 위해 모델을 처음부터 다시 만들고 재훈련할 필요가 없다.
features = model.layers[4].output
difficulty = layers.Dense(3, activation='softmax', name='difficulty')(features)model.layer[4]는 중간 Dense층을 나타낸다. 우리는 중간Dense층과 새로운 output을 연결해야하므로 difficulty라는 출력 레이어 객체를 생성하고 (features)를 통해 중간층과 연결한다.
그리고 new_model에 기존 입출력인자를 그대로 넣고, difficulty만 출력인자 리스트에 추가해주면 된다.
Model 서브클래싱
우리는 3장에서 Layer 클래스를 상속하여 사용자정의 층을 밑바닥부터 구현하였었다. Model 클래스를 상속하는 것 또한 비슷하다. Model서브클래싱은 밑바닥부터 구현한다고 보면 될 것이다. 다음 코드는 모델을 생성하는 클래스 코드이다.
class CustomerTicketModel(keras.Model):
def __init__(self, num_departments):
super().__init__()
# keras.Model상속받기
self.concat_layer = layers.Concatenate()
# 입력데이터 Concat하기
self.mixing_layer = layers.Dense(64, activation='relu')
# 중간층 만들기
self.priority_scorer = layers.Dense(1, activation='sigmoid')
# 우선순위 출력층 만들기(sigmoid로)
self.department_classifier = layers.Dense(num_departments, activation='softmax')
# 부서 범주 출력층 만들기
def call(self, inputs): # callable하게 만들기
# 입력데이터 변수화
title = inputs['title']
text_body = inputs['text_body']
tags = inputs['tags']
# 속성사용하여 출력층 생성 과정
inputs = self.concat_layer([title, text_body, tages])
features = self.mixing_layer(inputs)
priority = self.priority_scorer(features)
department = self.department_classifier(features)
return priority, departmentmodel = CustomerTicketModel(num_departments=4)
priority, department = model(
{'title': title_data,
'text_body': text_body_data,
'tags': tags_data})
# 부서수를 전달하면서 model객체를 생성한 후
# 딕셔너리로 감싸져있는 데이터셋들을 주입하여 출력층을 얻는다.