BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 요약
BERT의 개선점
양방향 학습을 통해서 기존 모델들보다 더 좋은 성능을 냈다.
Pre-train된 BERT모델의 마지막 레이어를 fine-tuning함으로써 높은 성능으로 여러가지 일들을 해결할수 있게 되었다.
BERT 모델
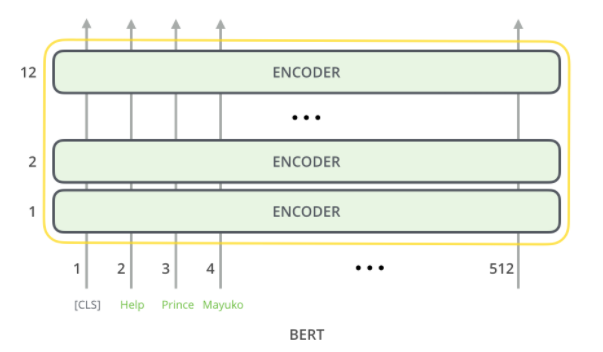
BERT는 기존의 Transformer의 인코더 부분을 여러층으로 쌓음으로써 구현되었다.
BERT는 다중문장에대한 입력을 받을수 있으므로 기존의 Transformer의 임베딩과 다른 차이점을 가진다.
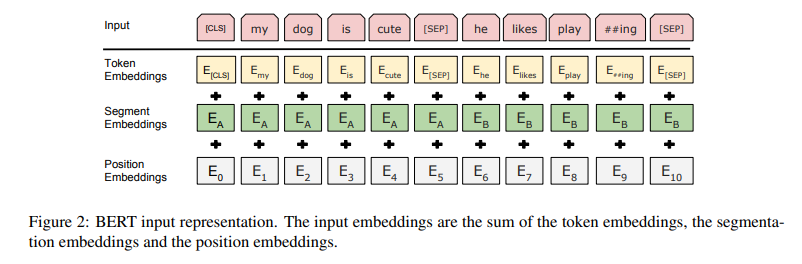
입력 입베딩 값은 token embedding + segment embedding + position embedding으로 정해진다.
token embedding은 기존의 단어 임베딩이고, segment embedding은 각 단어가 어느 문장에 속하는지에 대한 임베딩이다. 그리고 마지막으로 position embedding은 기존 트렌스포머에서의 위치 임베딩이다.
Pre-training
BERT는 2가지의 비지도 과제들을 통해서 사전학습 된다.
1. Masked Language Model(MLM)
기존의 모델들은 단방향으로밖에 학습을 할수밖에 없었지만, [Mask]토큰 을 사용함으로써 양방향 학습을 할수 있도록 개선하였다.
방법
전체의 15%의 단어를 예측을 하게 된다.
그중 80%의 경우 [MASK]로 치환하고,
10%는 랜덤 단어로 바꾸고,
10%의 경우 문장을 그대로 두게 된다.
2. Next Sentence Prediction(NSP)
BERT는 단어상에서의 학습뿐 아니라 다중문장 상에서도 학습을 진행하였다. 이를통해 각 문장의 관계를 파악하게끔 하였다.
방법
문장 A와 B가 있을때에 50%의 확률로 문장 B가 실제로 문장 A다음으로 나오는 문장으로 구성되고(IsNext로 레이블된다) 나머지 50%의 경우는 랜덤으로 아무 문장이 A 다음에 오게된다(NotNext로 레이블된다).
Fine Tuning
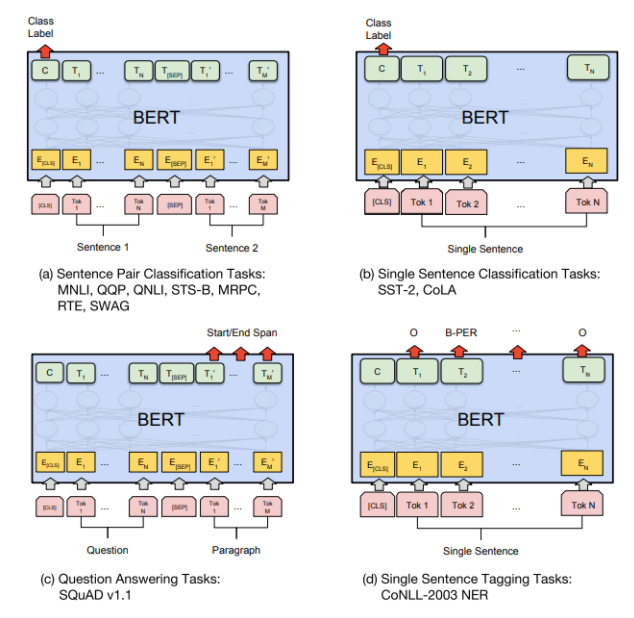
a) 다중문장 분류의 경우 [CLS] 토큰을 사용하여 분류
b) 단일문장 분류의 경우 [CLS] 토큰을 사용하여 분류
c) 질의 응답에 대해서는 답의 시작 끝에 해당하는 스칼라값을 받아서 분류(2개의 다른 FC레이어 사용)
d) 단어 태깅 문제의 경우 각 단어로부터 입력 받아서 분류
즉 하나의 모델로 여러가지 일들을 수행할수 있게 된다. 오직 바꿔야 하는 부분은 마지막에 분류를위한 FC레이어만 fine tuning 해주면 된다.
실험 결과
GLUE 결과
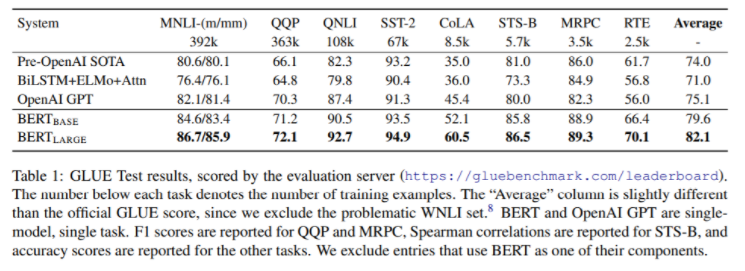
보다시피 이전의 모델들과 비교했을때 성능이 유의미하게 높아졌다.
SQuAD 1.1 결과
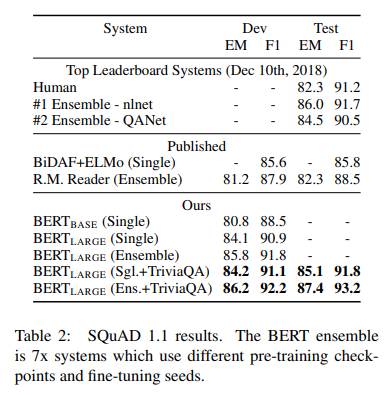
앙상블, TriviaQA에 fine-tuning한 모델을 사용했을시에 성능은 더욱 높아졌다. (EM은 Exact Match score를 뜻함)
SQuAD 1.1은 질문에 대한 답을 주어진 문단에서 찾아내는 형식으로 테스트한다.
예시:

SQuAD 2.0 결과
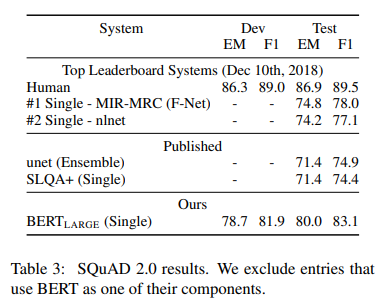
SQuAD 2.0은 질문에 대한 답을 주어진 문단에서 찾아내는 형식으로 테스트 하지만, 답이 문단에 없을수도 있다.
SWAG 결과

SWAG는 해당 문장에대한 4지선다 테스트이다.
예시:

Ablation Studies
NSP, LTR 사용의 효과
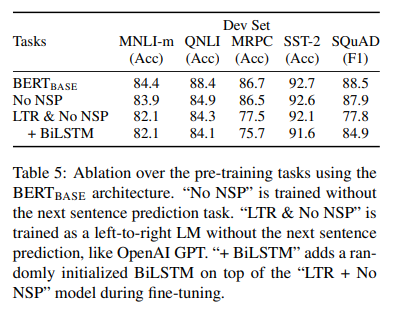
NSP(Next Sentence Prediction), LTR(Left-To-Right)
이것들을 사용해서 훈련시에 해당 테스트들에서 더 나은 결과가 나왔다.
====================================================
NSP학습에 대한 반박:
ALBERT 사용시에는 오히려 NSP가 너무 쉬워서 빼고하니까 성능이 더 좋을때도 있다고 한다.

모델 크기의 효과
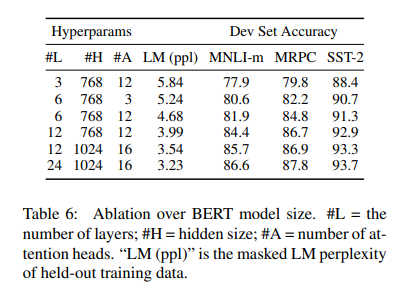
보다시피 레이어가 깊어질수록, 어텐션 헤드의 수가 많아질수록, 히든 차원이 커질수록 성능이 증가했다.
