GPT-2 Language Models are Unsupervised Multitask Learners 논문
개요
-
각각의 세부분야(요약, 기계독해, 기계번역, 등)에 특화된 모델이 아니라, 여러가지 분야를 아무런 추가 학습없이 해낼수 있는 모델이다.
-
데이터 학습시에도 특별한 지도 없이 학습하였다.
-
거대한 양의 데이터와, 모델의 크기가 증가하면서 성능은 계속해서 좋아졌다.
데이터셋
여러가지 분야에서 모델을 사용하기 위해서 최대한 많은 양의 각 분야의 다양한 데이터셋을 사용하였다.
그러기 위해서 인터넷이서 크롤링을 하였으나, 데이터의 질적 문제가 발생하여 Reddit에서 최소한 3개의 karma를 받은것만 스크레이핑 하였다.
8백만건의 문서, 약 40GB의 데이터를 학습하였다.
BPE(Byte Pair Encoding)를 사용하여 토크나이징을 하였다.
실험
여러 테스크에서의 모델사이즈에 따른 성능 향상
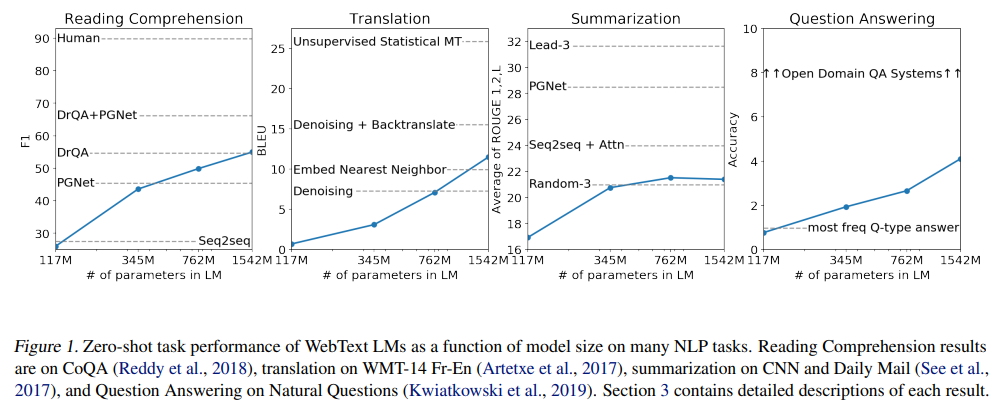
모델 크기가 커짐에 따라서 성능이 좋아짐을 확인할수 있다.
사용된 모델 사이즈들
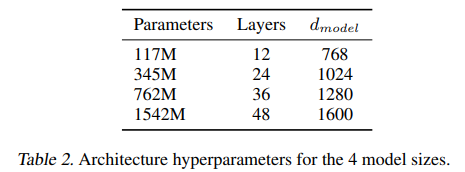
사용된 모델들이다.
LM에서의 성능 평가
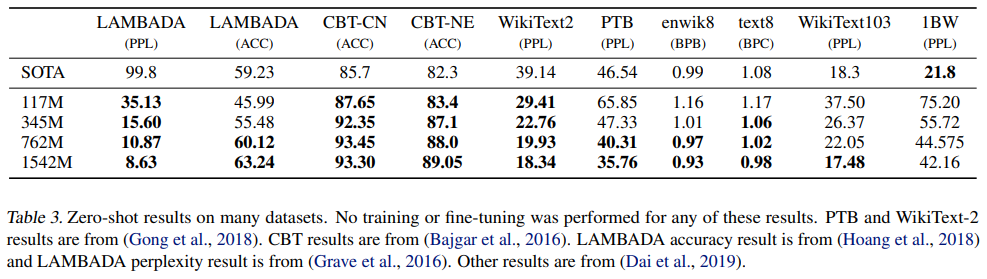
Fine tuning없이 zero-shot을 통해서 여러 데이터셋에서 SOTA를 달성했다.
CBT 테스트
어린이 책에서의 named entity recognition 테스크 이다.
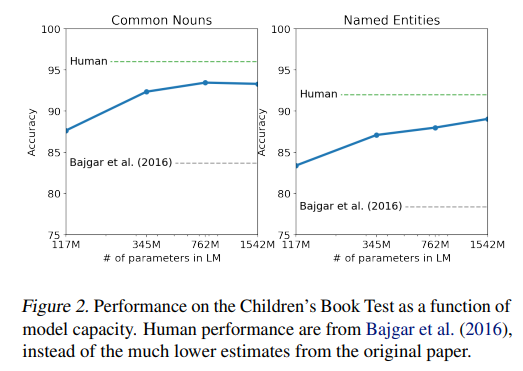
SOTA를 달성했다.
LAMBADA 테스트
문장의 마지막 단어를 예측하는 테스크이다.
GPT-2가 마지막 단어 예측이라는 제약을 제대로 이해하지 못하여서 stop-word 필터를 사용하여 마지막 단어 예측을 수행하였다.
최종적으로 63.24%로 SOTA를 달성하였다.
Winograd Schema Challenge
문장내에서 모호한 부분을 해결하는 테스크이다.
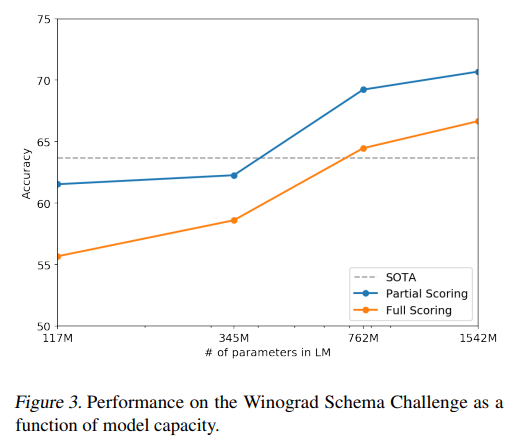
Reading Comprehension
기계독해 테스크이다.
GPT-2는 F1스코어를 55 달성했다.
BERT기반 모델은 F1스코어 89를 달성 했다.
Summarization
요약 테스크이다.
요약 테스크에 동작하기 위해서 TL;DR:을 사용했다.
TL;DR:사용하지 않았을시에 성능이 떨어졌다.
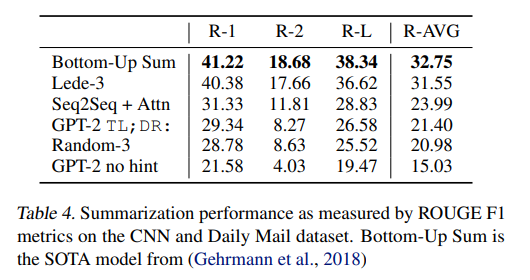
Translation
영어->프랑스어 에서 BLEU 5 달성했다.
프랑스어->영어 에서 BLEU 11.5를 달성했다.
기존 SOTA 비지도학습 모델은 33.5 BLEU 이다.
그렇지만 상대적으로 놀라운 성과였다. 왜냐하면 애초에 훈련 데이터셋에서 영어 이외의 자료를 제거했기 때문이다.
실제 데이터 검사했을때 나온 프랑스어 데이터는 10MB에 불과했고 SOTA모델보다 500배 작은 데이터셋이였다.
Question Answering
SQUAD에서 4.1%의 정확도를 보였다.
가장 작은 모델은 아주 간단한 문제들에서도 1% 미만의 정확도를 보였다.
큰모델에서 5.3배의 정확도 향상이 있었다.
이는 이 테스크에 있어서 모델크기가 중요한 요소라는점을 보여준다.
기존의 open domain question answering system 보다 30~50% 더 낮은 성능을 보였다.
Generalization vs Memorization
데이터셋의 크기가 점점 커지면서 훈련데이터와 테스트데이터가 겹치는 경우가 발생했다. 이로인해서 일반화 성능이 과장되어서 나오게 되었다.
이런 데이터 중복을 검증하기 위해서 Bloom filter를 사용하였다. Bloom filter란 WebText데이터로부터 추출한 8-grams으로 recall 기반 중복검증도구이다.
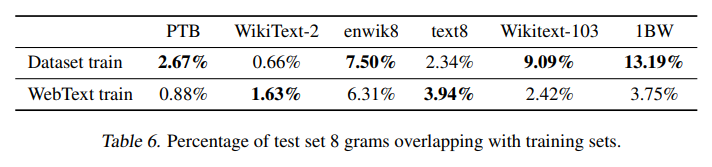
이와같이 WebText와 다른 데이터셋과의 중복은 그렇게 크지 않았다. 오히려 데이터셋 스스로 train과 test사이의 중복이 더 높은 경우도 많았다.
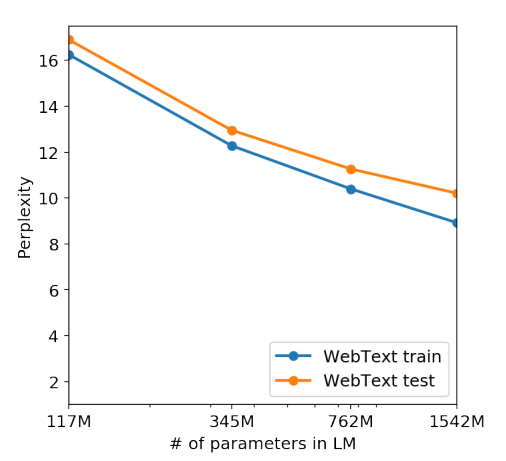
이 그래프는 모델이 커짐에 따라서 지속적인 성능 향상을 보여준다. 즉 모델이 데이터를 외우기를 통해서 성능이 향상되었다는 것에대한 반증이 될수 있다.
결론
GPT-2가 여러 분야에서 비지도학습을 통한 학습이 zero-shot세팅으로도 어느정도의 성능을 보여준다는것을 알려줬다.
비록 Question Answering, Summerization 등의 분야에서 낮은 성능을 보여주었지만, 더 큰 데이터, 더 큰 모델 그리고 만약 fine tuning을 한다면 BERT가 보여주었던 단방향 표현모델의 한계를 넘어설수 있지 않을까 싶다.
논문: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
참고: https://jalammar.github.io/illustrated-gpt2/#part-1-got-and-language-modeling, https://blog.floydhub.com/gpt2/
