
참고자료
1. MySQL로 배우는 데이터베이스 개론과 실습
2. 한양대학교 ERICA 2024-2 오은성 교수님의 데이터베이스 수업
3. 정보처리산업기사
Chatper 01 데이터베이스 시스템
1-1 데이터베이스의 필요성
데이터(data): 단순 관찰 및 측정하여 수집한 값.
정보(information): 의사 결정에 유용히 활용할 수 있도록 데이터를 처리한 결과물.
지식: 사물이나 현상에 대한 이해
정보 처리(information processing): 데이터에서 정보를 추출하는 방법
정보 시스템(information system): 데이터를 수집하여 저장해두었다가 필요할 때 유용한 정보를 만들어 주는 수단
1-2 데이터베이스의 정의와 특징
1) 데이터베이스의 정의
데이터베이스(DataBase, DB)
- 여러 사용자가 공유하여 사용할 수 있도록 통합하여 저장한 운영 데이터의 집합
- 데이터를 저장하는 공간
- 공유 데이터: 여러 사용자가 함께 소유하고 이용
- 통합 데이터: 최소의 중복
- 저장 데이터: 접근 가능 저장 데이터
- 운영 데이터: 기능 수행을 위해 필요한 데이터.
2) 데이터베이스의 특징
- 실시간 접근: 사용자의 데이터 요구에 실시간 응답
- 계속 변화: 계속적인 삽입, 삭제, 수정을 통해 현재의 정확한 데이터 유지
- 동시 공유: 데이터의 동시 사용 지원
- 내용 기반 참조: 데이터의 주소나 위치가 아닌 내용으로 참조 가능. 즉, 순서가 아닌 key 값을 통한 참조.
- 데이터의 무결성: 데이터베이스에 저장된 데이터는 오류가 있으면 안된다는 성질
- 데이터의 독립성: 데이터 파일의 저장소를 변경하더라도 기존에 작성된 응용 프로그램은 영향을 받지 않는 성질.
1-3 데이터 과학 시대의 데이터
1) 형태에 따른 데이터 분류
-
정형 데이터
구조화된 데이터.
ex. 액셀의 스프레드시트, 관계 데이터베이스의 테이블, 회사의 인사 기록 -
반정형 데이터
구조에 따라 저장된 데이터이지만, 데이터 내용 안에 구조에 대한 설명이 함께 존재.
ex. HTML, XML, JSON, 센서 데이터 -
비정형 데이터
정해진 구조가 없이 저장된 데이터
ex. 소셜 데이터의 텍스트, 영상, 이미지, 음성, 멀티미디어 데이터(word, pdf), 이메일
2) 특성에 따른 데이터 분류
- 범주형 데이터(정성적 데이터): 종류 데이터
- 명목형 데이터: 순서가 없는 값 데이터
ex. 성별, 혈액형, 학과명, 거주 지역, 음식메뉴 - 순서형 데이터: 순서가 있는 값 데이터
ex. 학년, 학점, 회원 등급
- 명목형 데이터: 순서가 없는 값 데이터
- 수치형 데이터(정량적 데이터): 숫자 데이터
- 이산형 데이터: 갯수를 셀 수 있는 단절된 숫자 데이터
ex. 고객수, 판매량, 합격자 수 - 연속형 데이터: 측정을 통한 연속적인 숫자 데이터
ex. 키, 몸무게, 온도, 점수
- 이산형 데이터: 갯수를 셀 수 있는 단절된 숫자 데이터
1-3 데이터베이스 관리 시스템
1) DBMS의 등장 배경
파일 시스템(File system)
- 데이터를 파일로 관리하기 위해 파일을 생성, 삭제, 수정, 검색하는 기능을 제공하는 소프트웨어.
- 응용 프로그램 별로 데이터를 별도의 파일로 관리.
파일 시스템의 문제점
- 데이터의 중복성: 같은 데이터가 여러 파일에 중복 저장
- 데이터의 중속성: 응용 프로그램이 데이터 파일에 종속
- 데이터 파일에 대한 공유, 보안 회복 기능 부족
- 응용 프로그램 연동의 어려움.
2) DBMS의 정의
데이터베이스 관리 시스템
- DBMS(DataBase Management System)
- 데이터를 데이터베이스에 통합하여 저장 및 관리하는 소프트웨어.
DBMS의 주요 기능
- 정의 기능: 데이터베이스 구조 정의 및 수정
- 조작 기능: 데이터 삽입, 삭제, 수정, 검색
- 제어 기능: 데이터를 정확하고 안전히 유지
3) DBMS의 장단점
장점
- 데이터 중복 통제
- 데이터 독립성 확보
- 데이터 동시 공유
- 데이터 보안 향상
- 데이터 무결성 유지
- Data Type에 맞지 않는 데이터가 들어갈 수 없다.
- 기본 key가 겹치면 안된다.
- 표준화 가능
- 장애 회복 가능(복구)
- 응용 프로그램 개발 용이 및 비용 감소
단점
- 비용(구매 비용 및 트레픽)
- 장애 회복이 복잡함.
- 중앙 집중 관리의 취약점
4) 데이터 베이스의 종류
- 계층형 데이터베이스
- 부모-자식 형태의 트리 구조를 기반
- 개체가 링크로 연결되어 있어 관계 변경, 추가, 삭제 되면 구조 변경의 어려움.
- 네트워크형 데이터베이스
- 그래프 형태로 vertex와 edge로 이루어져 있다.
- 주소를 지정해야 한다.
- 구조 복잡
- 관계형 데이터베이스
- 테이블 간 기본 key로 연결
- 중복 최소화
- 주소 저장을 하지 않음.
- 현재까지 가장 안정적이고 효율적인 데이터베이스.
- 객체 지향형 데이터베이스
- 객체 관계형 데이터베이스
5) 데이터베이스 관리 시스템의 발전 과정
2세대: 관계 DBMS
관계 DBMS: 데이터베이스를 테이블 형태로 구성
ex. 오라클(Oracle), MS SQL, 액세스(Access), 인포믹스(informix), mySQL, 마리아DB(MariaDB)
3세대: 객체지향 DBMS, 객체관계 DBMS
- 객체 지향 DBMS: 객체를 이용한 데이터베이스 구성
- 객체 관계 DBMS: 객체지향 DBMS + 관계 DBMS
4세대: NoSQL, NewSQL DBMS
- NoSQL DBMS: 비정형 데이터를 처리하는데 적합. 따라서, Big Data에 활용
- NewSQL DBMS: 관계 DBMS + NoSQL
- 정형 및 비정형 데이터를 안정적이고 빠르게 처리.
1-4 데이터베이스 시스템의 정의
1) 데이터베이스 시스템(DBS; DataBase System)
- 데이터베이스에 데이터를 저장 및 관리하여 필요한 정보를 생성하는 시스템.
- 데이터베이스를 관리하는 소프트웨어 프로그램.
- 사용자에게 편리하고 효율적인 데이터베이스 사용 환경 제공
- 주기억 장치에 상주
1-5 데이터베이스의 구조
1) 스키마와 인스턴스
-
스키마(schema): DB에 저장되는 데이터 구조 및 제약조건을 정의한 것.
ex. Data Type. -
인스턴스(instance): 스키마에 따라 DB에 실제로 저장된 값.
2) 3단계 DB구조
- 외부 스키마(External Schema)
- 사용자 관점
- 하나의 DB에 여러 외부 스키마 존재 가능
- 서브 스키마(sub schema)라고도 불림.
- 개념 스키마(Comnceptual Schema)
- 조직의 관점
- DB의 논리적 구조 정의
- 데이터 종류, 관계, 제약조건, 보안, 권한 등의 정의
- 하나의 DB에 하나만 존재.
- 내부 스키마(Internal Schema)
- 저장 장치의 관점
- 하나의 DB에 하나만 존재
- 레코드 구조, 필드 크기, 레코드 접근 경로 등의 물리적 저장 구조 정의
3) 스키마 사이의 대응 관계
- 응용 인터페이스(Application Interface): 외부 - 개념 스키마 대응 관계
- 저장 인터페이스(Storage Interface): 개념 - 내부 스키마 대응 관계
DB 3단계 구조로 나누고 단계별 스키마를 유지하며 스키마 사이의 대응 관계를 정의하는 것은 궁극적으로 데이터 독립성의 실현을 위함.
4) 데이터 독립성(Data Independency)
하위 스키마를 변경하더라도 상위 스키마가 영향을 받지 않는 특성.
| 스키마 | 범주 |
|---|---|
| 외부 스키마 | 상위 |
| 개념 스키마 | ↓ |
| 내부 스키마 | 하위 |
- 논리적 데이터 독립성
- 개념 스키마 변경 → 외부 스키마 영향 x
- 물리적 데이터 독립성
- 내부 스키마 변경 → 개념 스키마 영향 x
5) 데이터 사전(Data Dictionary)
- DB에 저장되는 메타 데이터 를 유지하는 시스템 DB.
- 스키마, 사상 정보, 다양한 제약 조건 등 저장
- DBMS가 스스로 생성 및 유지
- 일반 사용자도 검색 가능.
메타 데이터(meta data): 데이터에 관한 정보
6) 데이터 디렉터리(Data Directory)
- 데이터 사전의 데이터에 접근시 필요한 위치 정보를 저장하는 시스템 DB
- 사용자 접근 비허용
7) 사용자 데이터베이스(User Database)
- 사용자가 실제 이요한느 데이터가 저장되어 있는 일반 DB.
1-6 데이터베이스 사용자
1) 데이터베이스 사용자
- DB를 이용하기 위해 접근하는 모든 사람
이용 목적에 따른 구분(4가지)
- 데이터베이스 관리자(DBA; DataBase Administrator)
- DBS를 운영 및 관리함으로써 데이터를 총괄.
- 주로 DDL, DCL 사용
- 최종 사용자(end user, 일반 사용자)
- DB에 접근하여 데이터를 조작(삽입, 삭제, 수정, 검색)
- 주로 DML 이용
- 응용 프로그래머
- DML 이용
- SQL 관리자
1-7 데이터 언어
1) 데이터 언어
사용자와 DBMS 간의 통신 수단.
2) 데이터 정의어(DDL; Data Definition Language)
- 스키마의 정의, 수정, 삭제
ex. create, alter, drop
3) 데이터 조작어(DML; Data Manipulation Language)
- 데이터의 삽입, 삭제, 수정, 검색
- 절차적 데이터 조작어(procedural DML)
- 어떤 데이터를 원하고, 어떻게 처리하는지 설명
- 비절차적 데이터 조작어(nonprocedural DML)
- 어떤 데이터를 원하는지만 설명
- 선언적 언어(declarative language)
ex. select, insert, update, delete
4) 데이터 제어어(DCL; Data Control Language)
- 내부적 규칙 및 기법 정의
- 사용 목적
- 무결성
- 보안
- 회복
- 동시성 제어(데이터의 동시 공유)
ex. grant, commit, revoke, rollback
1-8 데이터베이스 관리 시스템의 구성
1) 데이터베이스 관리 시스템
데이터베이스 관리와 사용자 데이터 처리 수행
- 구성 요소
- 질의 처리기(query processor)
- 데이터 처리 요구 해석 후 처리
ex. DDL 컴파일러, DML 프리 컴파일러, DML 컴파일러, 런타임 데이터베이스 처리기, 트랜잭션 관리자 등
- 저장 데이터 관리자(stored data manager)
- 저장된 DB와 데이터 사전을 관리 및 접근
- 질의 처리기(query processor)
Chapter 02 관계 데이터 모델
2-1 관계 데이터 모델의 개념
1) 관계 데이터 모델
- 하나의 개체에 관한 데이터를 하나의 릴레이션에 저장
2) 관계 데이터 모델의 기본 용어 정리
- 릴레이션(Relation)
- 관계형 DB에서의 Table
- 파일 시스템에서 파일(file)
- 속성(Attribute)
- 열
- 파일 시스템에서 필드(field)
- 투플(tuple)
- 행
- 파일 시스템의 레코드(record)
- 도메인(Domain): 데이터 타입
- 널(Null): 값이 없음
- 차수(Degree): attribute의 갯수
- 카디널리티(Cardinality): tuple의 갯수
- 키(Key): 릴레이션에서 투플들을 유일하게 구별하는 속성
카디널리티는 0일 수 있음.
튜플은 자주 바뀔 수 있다.
attribute는 자주 바뀌지 않는다.
3) 릴레이션 구성
- 릴레이션 인스턴스
- 릴레이션 스키마
4) 릴레이션의 특성
- 투플의 유일성
- 투플의 무순서
- 속성의 무순서
- 속성의 원자성: 속성 값으로 원자 값만 사용 가능.
원자 값: 속성값이 더 이상 논리적으로 분해될 수 없는 값
5) 데이터베이스의 구성
- 데이터베이스 스키마(Database Schema)
- 릴레이션 스키마의 모음
- 데이터베이스 인스턴스(Database instance)
- 릴레이션 인스턴스의 모음
6) 키의 특성
- 유일성(uniqueness): 하나의 릴레이션에서 모든 투플은 서로 다른 키 값을 가져야한다.
- 최소성(minimality): 꼭 필요한 최소한의 속성들로만 키를 구성해야한다.
슈퍼키는 유일성만 만족한다.
7) 키의 종류
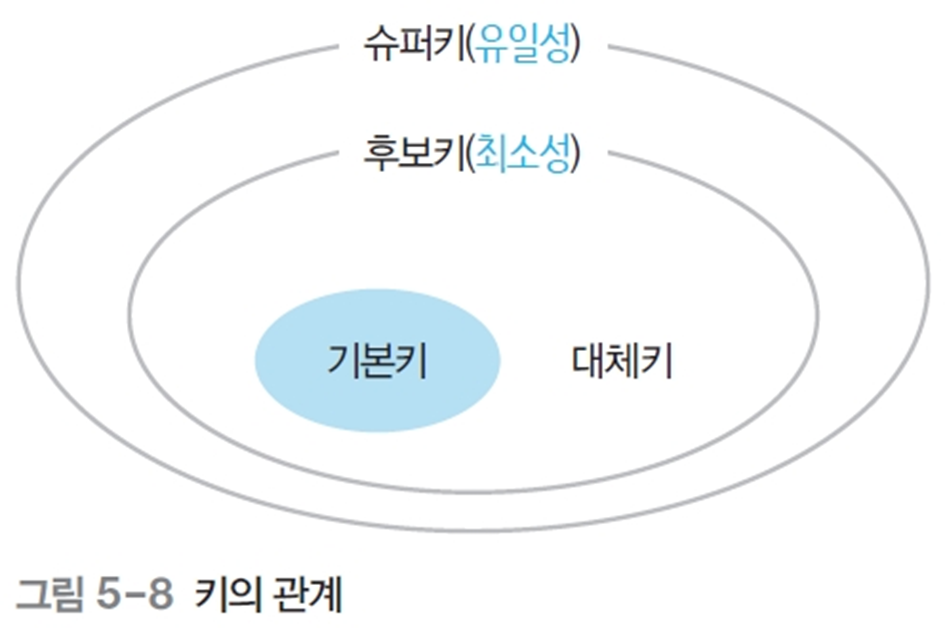
- 기본키(Primary Key)
- 후보키 중 기본적 사용을 위해 선택한 키
- 외래키(Foreign Key)
- 다른 릴레이션의 기본키를 참조(reference)하는 속성의 집합
- 참조하는 릴레이션: 외래키를 가진 릴레이션
- 참조되는 릴레이션: 외래키가 참조하는 기본키를 가진 릴레이션
- 참조한 기본키과 도메인이 같아야한다.
- 같은 릴레이션의 기본키를 참조할 수 있다.
- nullable
- 하나의 릴레이션에 여러 개 존재할 수 있다.
- 기본키로 사용할 수 있다.
- 대체키(Alternate Key)
- 기본키로 선택되지 못한 후보키
- 후보키(Canidate Key)
- 유일성과 최소성을 만족하는 속성의 집합
- 슈퍼키(Super Key)
- 유일성을 충족하는 속성의 집합. (최소성을 만족하지 않아도 된다.)
- 기본키, 대체키, 후보키를 포함
8) 데이터 타입의 종류
- INT
- CHAR(n): n자리 수의 문자을 받으나, 남는 공간에 빈칸 할당.
- VARCHAR(n): n자리 수의 문자를 받으나, 남는 공간을 없애서 유동적으로 할당.
- FLOAT
- DATETIME: 날짜 데이터
- ENUM
- TEXT
아무것도 입력하지 않으면 null값이 들어간다.
9) 옵션의 종류
- not null: null 이 들어갈 수 없음.
- unique: 중복 불가
- check: 범위 제한
- default: 기본값
2-2 관계 데이터 모델의 제약
1) 무결성 제약 조건(Integrity Constraint)
무결성: 데이터에 결함이 없어 정확하고 유효하게 유지된 상태.
- 개체 무결성 제약 조건(Entitiy Integrity Contraint): 기본키를 구성하는 모든 속성은 null 값을 가질 수 없다.
- 도메인 무결성 제약조건: 각 속성들의 값은 정의된 도메인에 속한 값이어야 한다.
ex. 나이 속성에는 음수가 들어가면 안된다.
- 참조 무결성 제약조건(Referential Integrity Contstraint): 외래키는 참조할 수 없는 값을 가질 수 없다.
ex. 참조하려는 기본키가 null인 경우(기본키는 non-nullable 하기 때문), 없는 값을 참조하려고 하는 경우.
Chapter 03 SQL 기초
3-1 데이터베이스 만들기
create database db이름
use db이름3-2 데이터 정의어
1) create 문
테이블 구성, 속성과 속성에 관한 제약 정의, 기본키 및 외래키를 정의하는 명령.
create table 테이블 이름
(
속성이름 데이터타입 not null|unique|default 기본값|check 체크조건|primary key|auto_increment
foreign key 속성이름 references 테이블이름(속성이름) on delete cascade | set null
[constraint 제약조건명][check (조건식)];
);테이터 타입 종류
| 데이터 타입 | 설명 |
|---|---|
| int, integer | 4바이트 정수형 |
| numberic(m, d), decimal(m, d) | 전체자리수 m, 소수점이하 자리수 d를 가진 숫자형 |
| char(n) | 문자형 고정길이, 문자를 저장하고 남은 공간은 공백으로 채운다. |
| varchar(n) | 문자형 가변길이 |
| date | 날짜형, 연도, 월, 날, 시간 저장 |
2) alter 문
생성된 테이블의 속성과 속성에 관한 제약을 변경하며, 기본키 및 외래키를 변경한다.
alter table 테이블 이름
add 속성이름 데이터타입
drop column 속성이름
modify 속성이름 데이터아입
modify 속성이름 null | not null
add primary key(속성이름)
add | drop 제약이름3) drop 문
테이블을 삭제하는 명령
drop table 테이블 이름 [cascade | restrict];restrict: 다른 개체가 제거할 요소를 참조중일 때 제거 취소
4) rename 문
rename table 기존테이블명 새로운테이블명3-3 데이터 조작어
1) select 문
select 문법
select all | distinct 속성이름
from 테이블이름
where 검색조건
group by 속성이름 | window 함수 over (partition by 속성명, ... order by 속성명, ...) as 별칙
having 검색조건
order by 속성이름 asc | descwhere 조건
| 술어 | 연산자 |
|---|---|
| 비교 | =, <>, <, <=, >, >= |
| 범위 | between A and B |
| 집합 | in, not in |
| 패턴 | like |
| null | is null, is not null |
| 복합조건 | and, or, not |
join
두 개 이상의 테이블에서 sql 질의를 할 때 사용한다.
| 명령 | 문법 |
|---|---|
| 일반 조인 |
SELECT <속성들> FROM 테이블1, 테이블2 WHERE <조인조건> AND <검색조건> SELECT <속성들> FROM 테이블1 INNER JOIN 테이블2 ON <조인조건> WHERE <검색조건> |
| 외부조인 |
SELECT <속성들> FROM 테이블1 {LEFT | RIGHT | FULL [OUTER]} JOIN 테이블2 ON <조인조건> WHERE <검색조건> |
inner join을 natural join으로 바꾸고, 조인조건을 안줄 수 있음.
from t1 join t2 using (속성명); 의 형태로도 inner 조인 가능
부질의 (subquery)
sql 문 내에 또 다른 sql 문 작성.
주 질의(main query)와 부속질의(sub query)로 구성되어 있다. 주 질의의 where 검색조건에 들어간다.
select ~
from ~
where 검색조건 연산자 (select ~ from ~ where)집합 연산
합집합 union
select 문 1
union
select 문 2집계 함수
| 집계 함수 | 문법 |
|---|---|
| sum | sum(all | distinct 속성이름) |
| avg | avg(all | distinct 속성이름) |
| count | count(all | discinct 속성이름 | *) |
| max | max(all | distinct 속성이름) |
| min | min(all | distinct 속성이름) |
2) insert 문
테이블에 새로운 투플을 삽입하는 명령.
insert into 테이블이름 (속성 리스트) values (값 리스트)속성 리스트 생략시 모든 속성에 대한 삽입.
3) update 문
특정 속성 값을 수정하는 명령.
update 테이블이름
set 속성이름1 = 값1, 속성이름2 = 값2, ...
where 검색조건4) delete 문
테이블에 있는 기존 투플을 삭제하는 명령
delete from 테이블이름
where 검색조건Chapter 04 SQL 고급
4-1 내장 함수
1) 숫자 함수
| 함수 | 설명 |
|---|---|
| abs(숫자) | 숫자 절댓값 계산 |
| ceil(숫자) | 숫자보다 크거나 같은 최소의 정수 |
| floor(숫자) | 숫자보다 작거나 같은 최소의 정수 |
| round(숫자, m) | m 자릿수 기준 숫자의 반올림 |
| log(n, 숫자) | 숫자의 자연로그 값 반환 |
| power(숫자, n) | 숫자의 n제곱 값 계산 |
| sqrt(숫자) | 숫자의 제곱근 값 계산 |
| sign(숫자) | 숫자가 음수면 -1, 0이면 0, 양수면 1 |
2) 문자 함수
| 함수 | 설명 |
|---|---|
| upper(s) | 문자열을 모두 대문자로 변환 |
| lower(s) | 문자열을 모두 소문자로 변환 |
| lpad(s, n, c) | 문자열의 왼쪽부터 지정한 자리수가 될 때까지 지정한 문자로 채움 |
| rpad(s, n, c) | 문자열의 오른쪽부터 지정한 자리수가 될 때까지 지정한 문자로 채움 |
| trim(c from s) | s의 양쪽에서 c를 삭제. c가 주어지지 않으면 공백 제거 |
| replace(s1, s2, s3) | s1에서 s2에 해당하는 부분을 s3로 변경 |
| substr(s, n, k) | s에서 n번째 문자에서 k개를 잘라서 반환 |
| concat(s1, s2) | s1+s2 |
| length(s) | 문자열의 byte 반환 |
| char_length(s) | 문자열의 문자 수 반환 |
| ascii(c) | 문자를 아스키 코드 값 반환 |
(s: 문자열, c: 문자, n: 정수, k: 정수)
3) 날짜 시간 함수
| 함수 | 반환형 | 설명 |
|---|---|---|
| str_to_date(string, format) | date | 문자열 데이터를 date형으로 변환 |
| date_format(date, format) | string | date형 데이터를 varchar로 변환 |
| adddate(date, interval) | date | date형 날짜에서 interval 만큼 더함 |
| date(date) | date | date 형의 날짜 반환 |
| datediff(date1, date2) | integer | date1 - date2 날짜 차이 반환 |
| sysdate | date | dbms 시스템상의 오늘 날짜 반환 |
ex.
format: '%Y-%m-%d', interval: interval 10 day
format 지정자
| 인자 | 설명 |
|---|---|
| %w | 요일 순서(0~6, sunday=0) |
| %W | 요일 순서(Sunday~Saturday) |
| %a | 요일 약자(Sun~Sat) |
| %d | 1달 중 날짜(00~31) |
| %j | 1년 중 날짜(001~366) |
| %h | 12시간 (01~12) |
| %H | 24시간 (00~23) |
| %i | 분 (0~59) |
| %m | 월 순서(01~12, January=01) |
| %b | 월 이름 약어(Jan~Dec) |
| %M | 월 이름(January ~ December) |
| %s | 초(0~59) |
| %Y | 4자리 연도 |
| %y | 4자리 연도의 마지막 2자리 |
4-2 NULL 처리
1) ifnull
null값을 다른 갑승로 대치하여 연산하거나 다른 값으로 출력
ifnull(속성 ,값)4-3 행번호 출력
set @seq := 0; -- 변수 정의
select (@seq:=@seq+1) '순번' ~
from ~4-4 뷰(view)
하나 이상의 테이블을 합하여 만든 가상의 테이블.
1) 뷰의 장점
- 편리성 및 재사용성: 자주 사용되는 복잡한 질의를 뷰로 미리 정의.
- 보안성: 중요한 질의의 내용을 암호화.
- 독립성: 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있기 때문에 필요한 정보만 뷰로 만들어 사용.
2) 뷰의 특징
- 원본 데이터 값에 따라 같이 변함
(뷰변경 → 원본 변경 | 원본 변경 → 뷰변경) - 독립적인 인덱스 생성이 어려움
- 삽입, 삭제, 갱신 연산에 많은 제약이 따름.
(기본키를 안가져오면 null로 정의되기 때문에 연산에 제약이 생긴다.) - 테이블에 연동해 뷰를 생성했을 때, 관련 뷰를 모두 지워야 테이블을 삭제할 수 있다.
3) 뷰의 제약조건
- 기본키나 not null 속성의 필드값을 가져오지 않는 뷰는 변경할 수 없다.
- 계산된 뷰나 집단함수를 정의한 뷰는 수정할 수 없다.
- 조인된 뷰도 수정할 수 없다.
3) 뷰의 생성
create view 뷰이름 (열이름)
as select 문
with check option열이름 생략 가능
with check option 사용시 view의 where 조건에 만족하는 값만 view의 삽입 및 수정을 허용하도록 한다.
4) 뷰의 수정
create or replace view 뷰이름 (열이름)
as select 문 alter view 뷰이름
as select 문 5) 뷰의 삭제
drop view 뷰이름4-5 인덱스(Index)
1) 인덱스 생성
create unique index 인덱스이름
on 테이블이름 (칼럼 asc | desc, ...)ex. create index ix_book on book(bookname);
2) 인덱스 삭제
drop index 인덱스이름 on 테이블이름4-6 트리거(Trigger)
- 데이터 변경문이 실행될 때 자동으로 따라서 실행되는 프로시저.
- 무결성 제약 조건 유지 혹은 규칙 적용을 위해 사용.
- 행트리거: 행 각각 실행
- 문장 트리거: insert, delete, update 문에 대해 한번만 실행
- 다중 트리거(Multiple Trigger): 하나의 테이블에 동일한 트리거나 여러 개 부착되어 있는 것.
- 중첩 트리거(Nested Trigger): 트리거가 또 다른 트리거를 작동시키는 것.
1) 트리거 생성
delimiter //
create trigger 트리거이름
before|after insert|update|delete on 테이블이름 for each row
begin
SQL 명령문;
end;
// delimiter ;2) 트리거 키워드
트리거 안의 SQL문에서 사용.
old
- delete로 삭제된 데이터
- update로 바뀌기 전 데이터
new
- insert로 삽입된 데이터
- update로 바뀐 후 데이터
3) 트리거 삭제
drop trigger 트리거이름;4) 트리거 보기
show tiggers;5) 트리거 작동 순서 지정
follows|precedes 다른트리거이름- follows: 지정 트리거 이후 현재 트리거 작동
- precedes: 지정 트리거 작동 이전 현재 트리거 작동
Chapter 05 데이터베이스 프로그래밍
5-1 프로시저 (Procedure)
1) 프로시저 정의
미리 작성하여 데이터베이스 안에 저장한 SQL 문장들의 묶음이다.
SQL문을 미리 데이터베이스에 작성해둘 수 있고, 복잡한 SQL문을 전달할 필요가 없어진다.
- 코드 재사용성
- 보안
- 캡슐화
정의
delimiter //
create procedure 프로시저_이름 (
in 변수 변수타입
)
begin
SQL 명령문;
end ;
// delimiter ;호출
call 프로시저_이름(변수);2) 프로시저의 활용
delimiter //.
create procedure 프로시저_이름 (
in 변수명 변수타입
)
begin
declare 변수명 변수타입;
SQL 명령문;
if (조건문) then
SQL 문;
elseif (조건문) then
SQL 문;
else
SQL 문;
end if ;
end ;
// delimiter ;내부 변수의 대입
declare count1 int;
select count(*) into count1
from 전화번호
where id = inid;Chapter 06 데이터 모델링
6-1 데이터베이스 설계
사용자의 다양한 요구 사항을 고려하여 데이터베이스를 생성하는 과정이다.
대표적으로 E-R 모델과 릴레이션 변환 규칙을 이용해 설계한다.
1단계: 요구 사항 분석
- 사용자 요구 사항 수집 및 분석하여 데이터베이스 용도 파악 목적
- 주요 사용자 범위 결정
- 조직 수행 업무 분석
- Entity 도출
- 결과물: 요구 사항 명세서 작성

2단계: 개념적 설계
- DBMS에 독립적 개념적 구조 설계
- 요구 사항 분석 결과물을 개념적 데이터 모델을 이용해 E-R 모델 등의 개념적 구조로 표현 (개념적 모델링)
- 요구 사항 분석 결과에서 중요한 개체를 추출하고, 개체 간 관계를 결정하여 E-R 다이어그램으로 표현
- 결과물: 개념적 스키마(E-R 다이어그램)
① 개체 추출, 각 개체 주요 속성과 키 속성 선별
- 의미 있는 명사를 추출하고, 개체(사각형)와 속성(밑줄)으로 분류

- 개체 및 속성 추출

- E-R 모델로 개체 및 속성 추출 (개체: 직사각형, 속성: 타원, 기본키: 밑줄, 관계: 마름모)
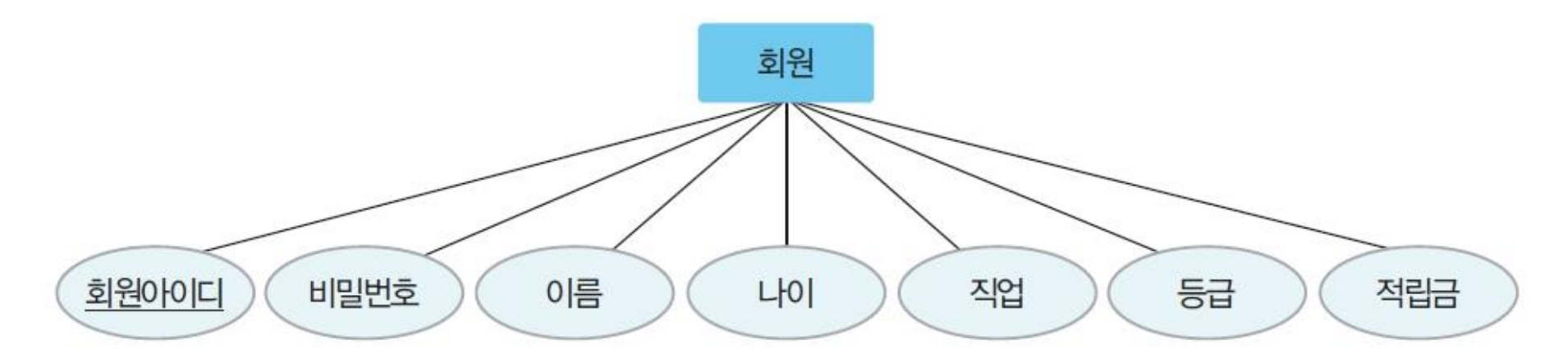
② 개체 간 관계 결정
- 개체 간 연관성을 의미 있는 대표 동사를 추출

- 찾아낸 관계에 대한 매핑 카디널리티와 참여 특정 결정
- 매핑 카디널리티: 1:1, 1:n, n:m
- 참여 특성: 필수 / 선택
- 관계 추출
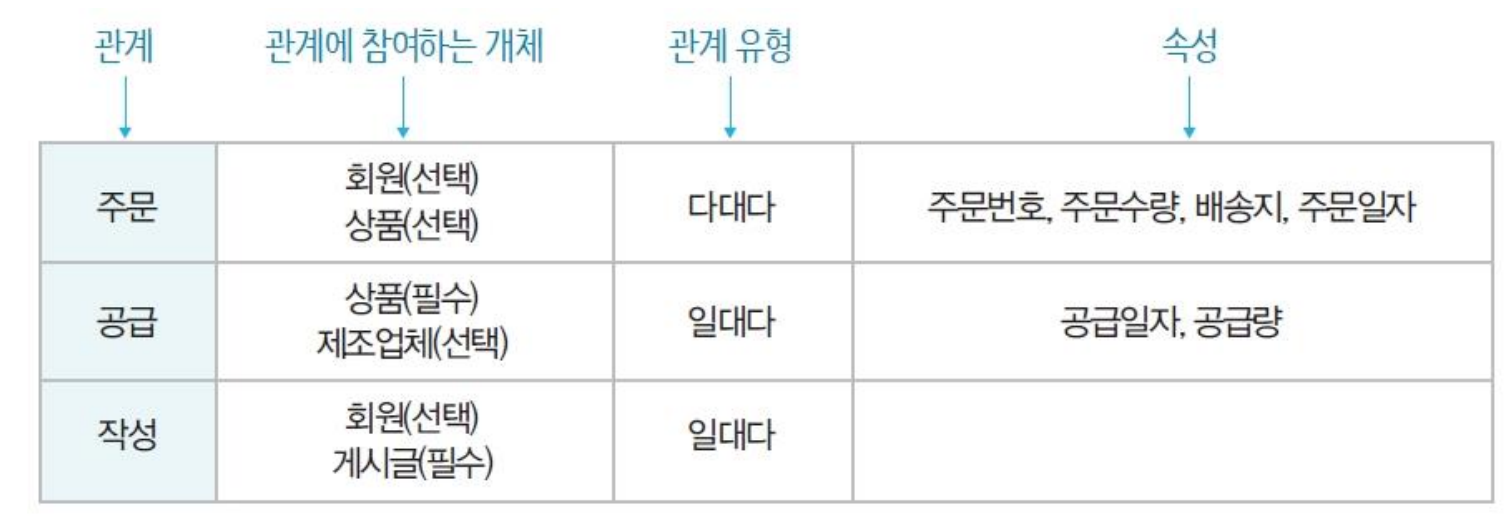
-
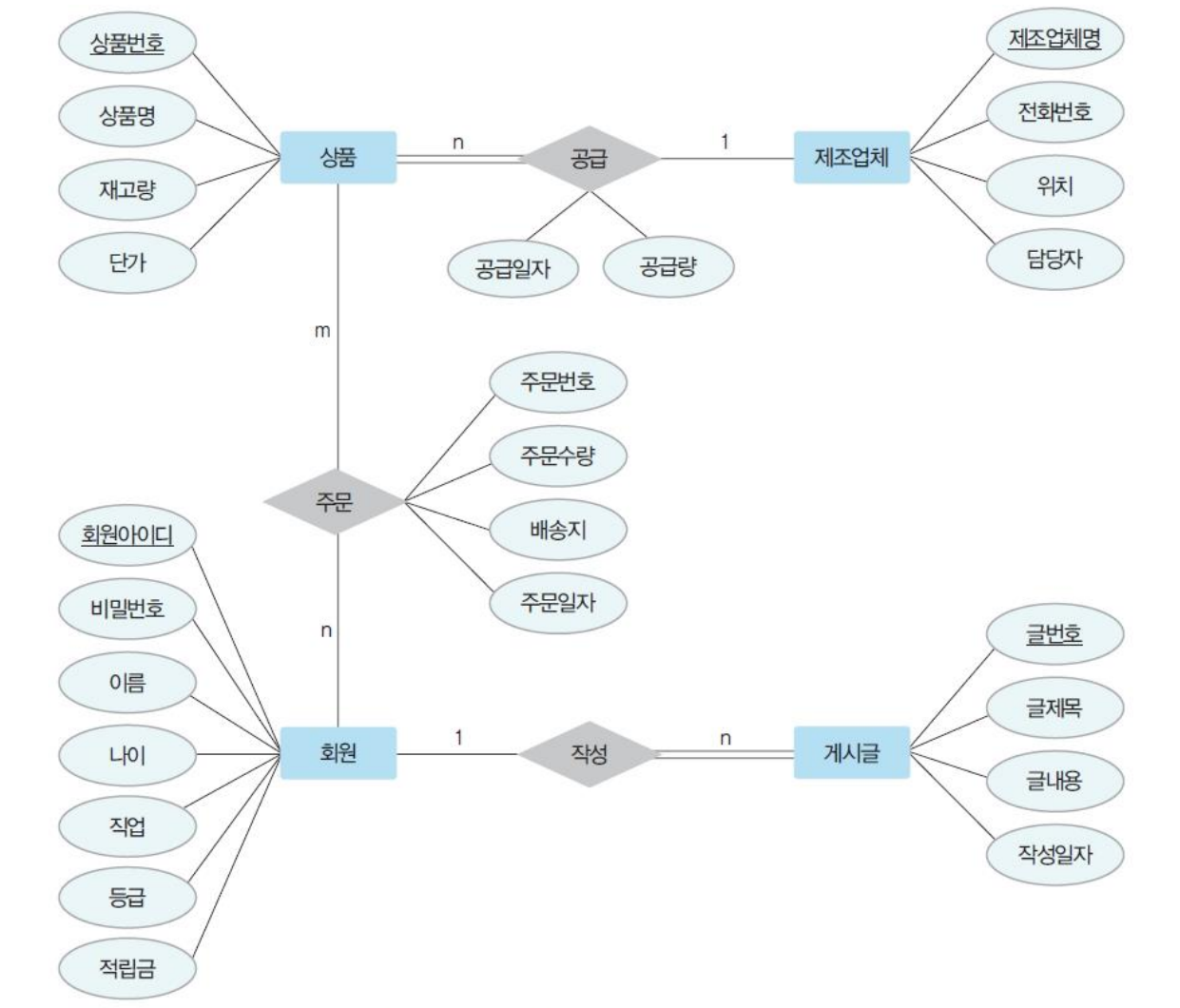
ER 모델 관계 추출 (다대다)
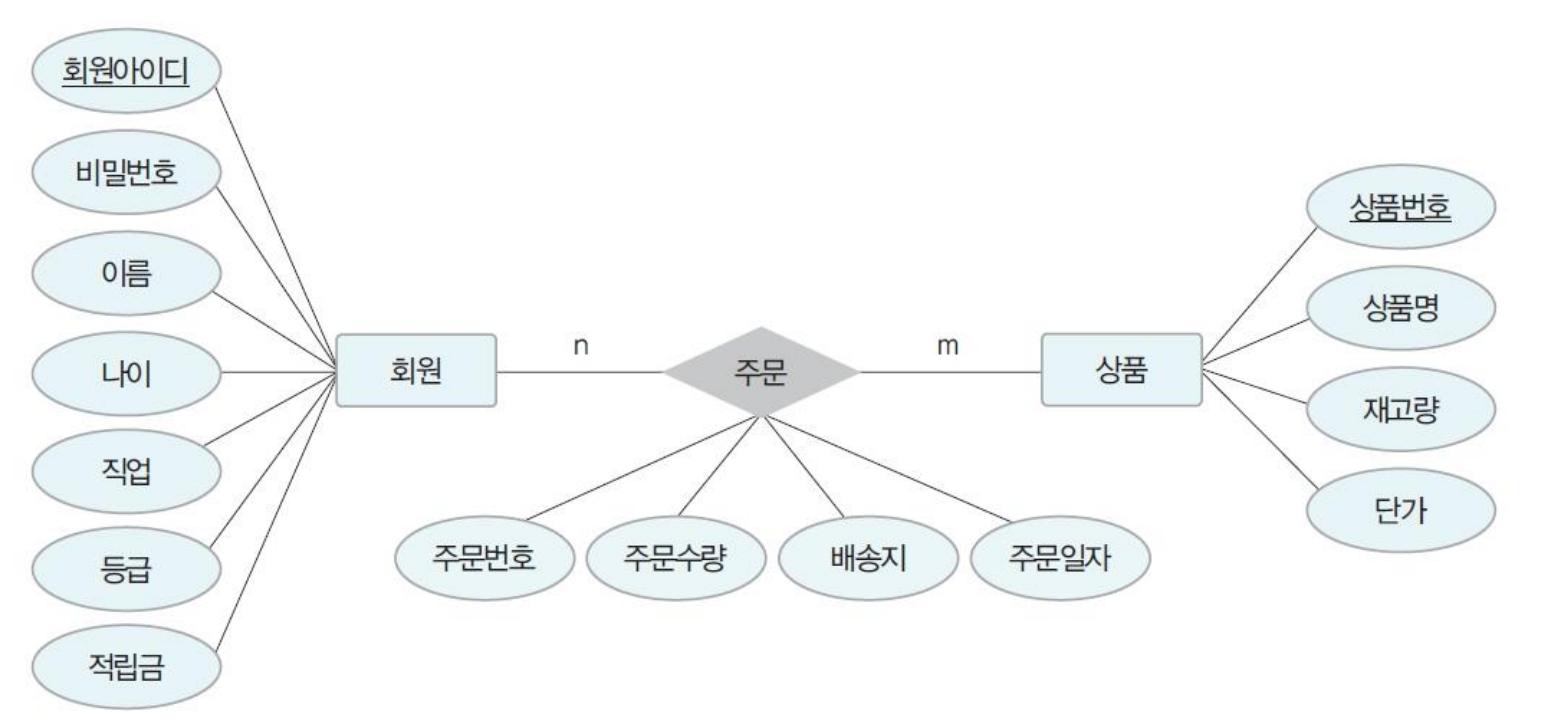
이때, 회원과 상품 릴레이션이 새로운 Entity인 주문이 도출되었다는 점.
- ER 모델 관계 추출 (일대다)

- ER 모델 관계 추출 (일대다)
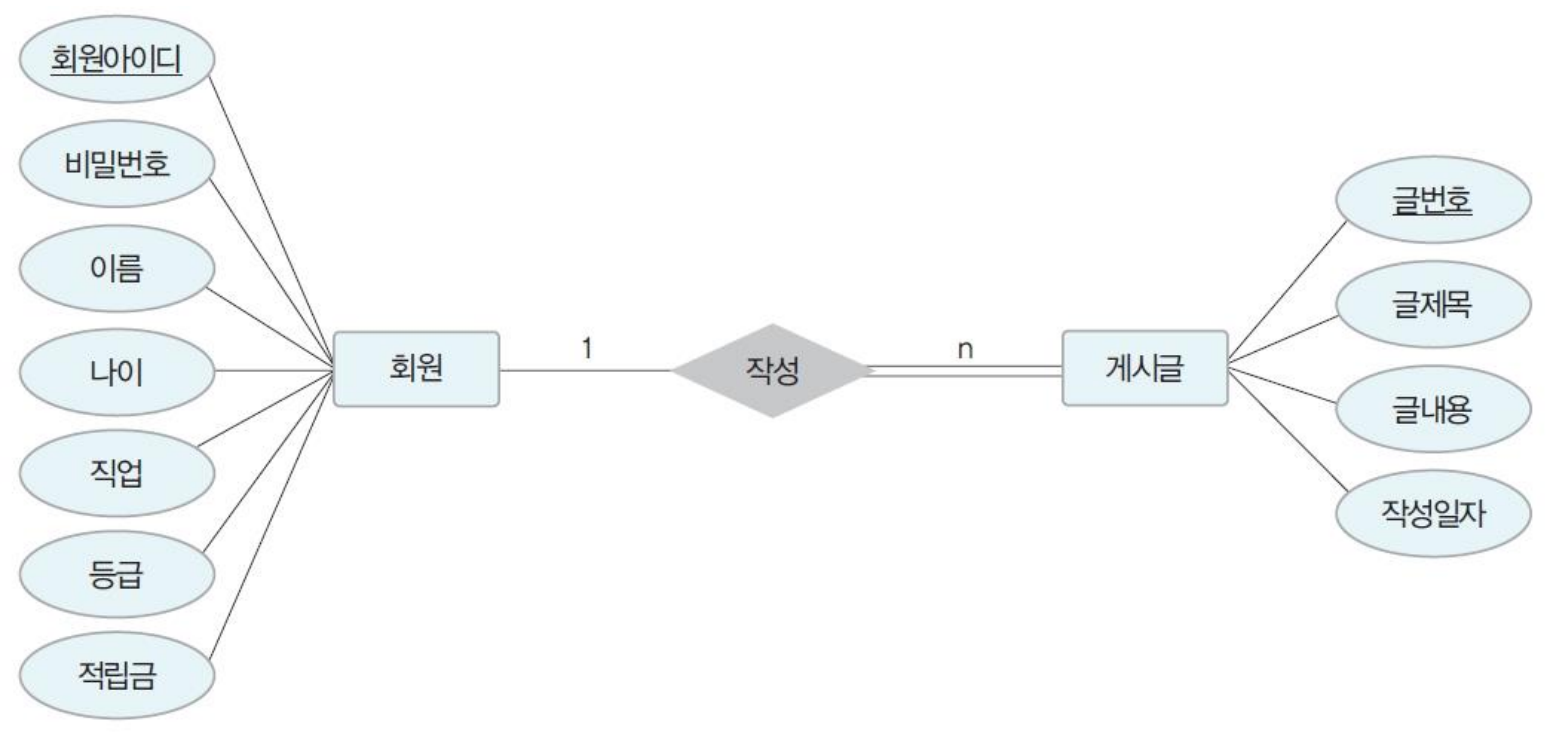
③ E-R 다이어그램 표현
3단계: 논리적 설계
-
DBMS에 적합한 논리적 구조 설계
-
논리적 모델링(데이터 모델링)
- 일반적으로 관계 데이터 모델 이용
- E-R 다이어그램을 릴레이션 스키마로 변환
- 데이터 타입, 길이, 널 허용, 기본 값, 제약조건 등을 결정 후 문서화 (테이블 명세서(릴레이션 스키마 설계 정보 기술 문서 ) 작성)

-
결과물: 논리적 스키마(릴레이션 스키마)
논리적 모델링 규칙
변환 규칙을 순서대로 적용하되, 해당되지 않는 규칙은 제외
- 모든 개체는 릴레이션으로 변환
- 개체 이름 - 릴레이션 이름
- 개체 속성 - 릴레이션 속성
- 개체 키 속성 - 릴레이션 기본키(복합 속성이면, 단순 속성만 변환)
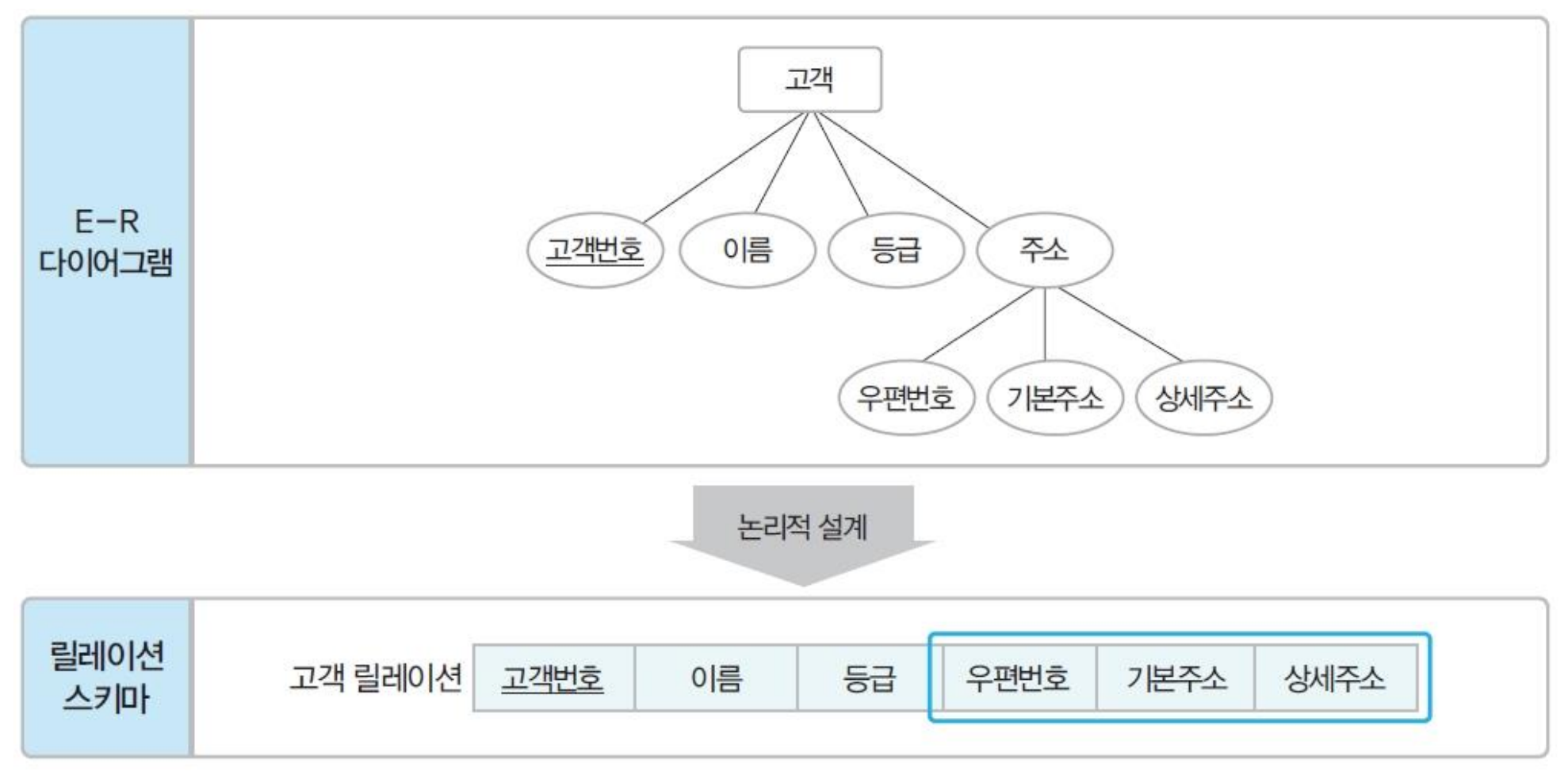
-
다대다(n:m) 관계는 릴레이션으로 변환
- 관계 이름 - 릴레이션 이름
- 관계 속성 - 릴레이션 속성
- 외래키 지정, 기본키 지정
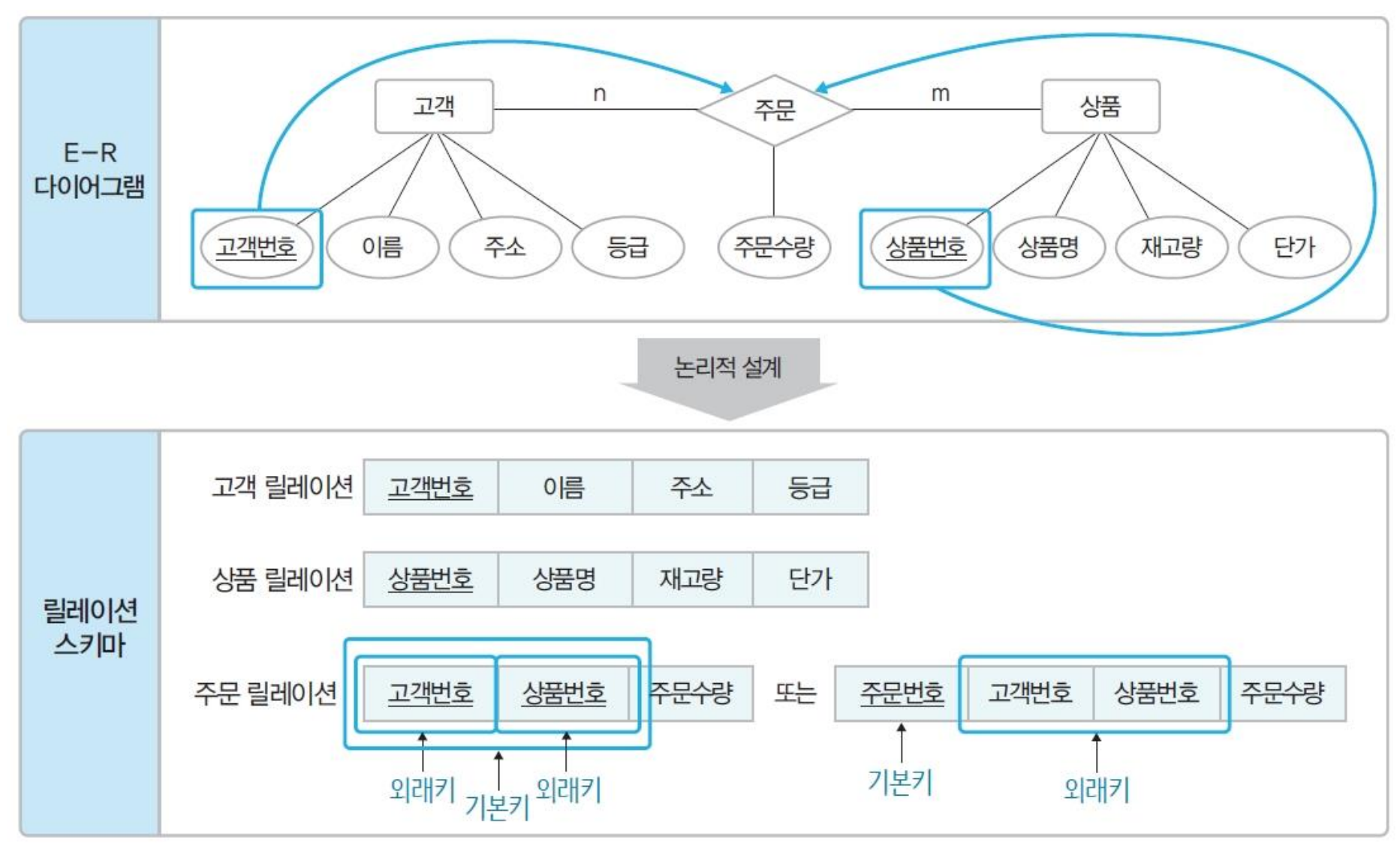
-
일대다(1:n) 관계는 외래키로 표현
- 일반적인 일대다 관계는 외래키로 표현
- 약한 개체가 참여하는 일대다 관계는 외래키를 포함해 기본키로 지정
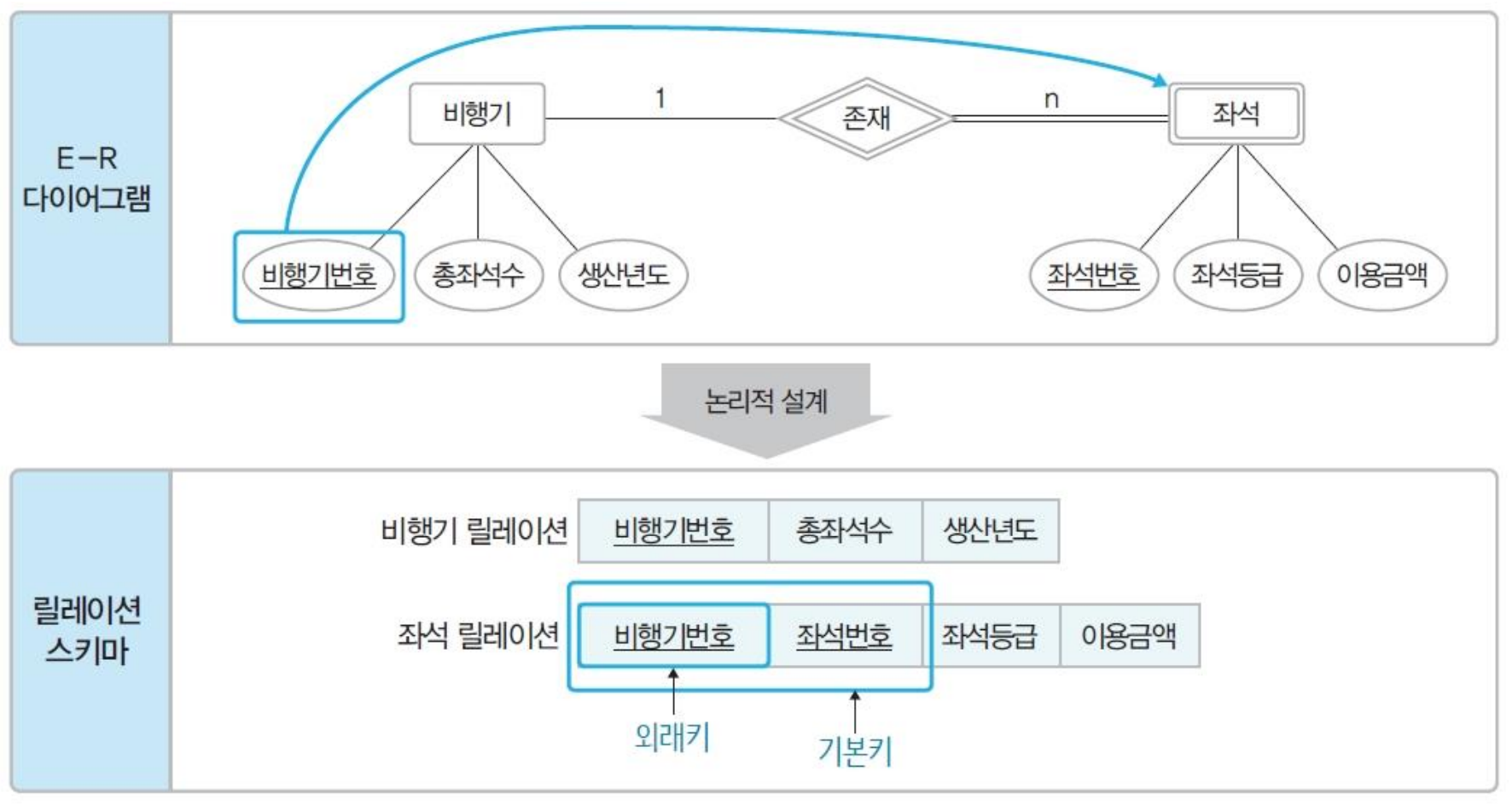
- 일대일(1:1) 관계는 외래키로 표현
- 일반적인 일대일 관계는 외래키를 서로 주고 받는다.
- 일대일 관계에 필수적으로 참여하는 개체의 릴레이션만 외래키를 받는다.
- 모든 개체가 일대일 관계에 필수적으로 참여하면 릴레이션 하나로 합친다.
- 다중 값 속성은 릴레이션을 변환 (원자값)
- 다중 값 속성과 함께 그 속성을 가지고 있던 개체 릴레이션의 기본키를 외래키로 가져와 새로운 릴레이션에 포함시킴
- 새로운 릴레이션 기본키는 다중 값 속성과 외래키를 조합해 지정
4단계: 물리적 설계
- 하드웨어와 운영체제의 특성을 고려해 필요한 인덱스 구조나 내부 저장 구조 등 DBMS로 구현 가능한 물리적 구조 설계
- 결과물: 물리적 스키마
5단계: 구현
- SQL 문을 작성 후 DBMS에 실행하여 데이터베이스 생성
수업 예제 및 확인 학습
1주차 예제
show databases;
use mysql;
show tables;
desc user;
-- 데이터의 조작 기능
select *from user where user='root';
delete from user where user='user';
-- 데이터의 정의기능
-- 구조 생성: create, 구조 변경: alter, 구조 삭제: drop
create user hong@localhost identified by '0000';
select *from user;
-- 데이터 제어 기능
-- 권한 부여: grant, 권한 취소: revoke, 권한 수락: commit
grant all privileges on hdb.* to hong@localhost;2주차 예제
-- member(회원 테이블): id, pwd, name, gender, age, phone, regdate
create database hexamA;
use hexama;
create table member (
id varchar(20) primary key,
pwd varchar(20) not null,
name char(20) not null,
gender char(10) check (gender in('남자', '여자')),
age int,
phone char(14) not null unique,
regdate datetime
);
desc member;
select * from member;
insert into member values (
'id', 'pwd', 'name', '남자', 20, '010-0000-0000', sysdate()
);
-- 기본키 존재 x
insert into member (
pwd, name, gender, age, phone, regdate
) values (
'pwd', 'name', '남자', 20, '010-0000-0001', sysdate()
);
-- 성별 조건 안맞음
insert into member (
id, pwd, name, gender, age, phone, regdate
) values (
'id2', 'pwd', 'name', '남', 20, '010-0000-0002', sysdate()
);
insert into member (
age, pwd, id, name, gender, phone, regdate
) values (
20, 'pwd', 'ohes', 'name', '남자', '010-0000-0004', sysdate()
);
-- guestbook(게시판): num, id(외래키), title, content, writeday
create table guestbook(
num int auto_increment primary key,
id varchar(20),
title char(50),
content text,
writeday datetime,
foreign key(id) references member(id) on update cascade on delete cascade
);
-- 참조 무결성 제약조건 (sub. 외래키의 제약조건)
-- 1. 기본키 없는 값을 삽입할 수 있다.
-- 2. 기본키값을 변경하면 외래키도 연쇄 변경
-- 3. 기본키값을 삭제시 외래키도 연쇄삭제
desc guestbook;
insert into guestbook(id, title, content, writeday)
values ('ohes', '수업', '오늘 좀 힘', sysdate());
select * from guestbook;
select * from member;
select * from guestbook;
select * from member;
update member
set id = 'oh'
where id = 'ohes';
delete from member
where id = 'oh';3주차 예제
-- 데이터 정의어
-- student 테이블 정의 (num, name, tel, addr, age)
show databases;
create database exdb;
use exdb;
create table student (
num char(10) primary key,
name char(20) not null,
tel char(13) not null unique,
addr char(100) default "안산시",
age int check(age >= 19)
);
desc student;
-- 구조 변경 alter
-- 1. attirbute 추가(add column)
alter table student add column handphone char(15) not null;
-- 2. '' 데이터 타입 변경(modify)
alter table student modify handphone varchar(15) not null unique; -- 재정의 -> 옵션 상속 x
-- 3. '' 이름 변경(change)
alter table student change handphone phone char(13) not null unique; -- drop 후 재정의 -> 옵션 다시 지정 필요
-- 4. '' 삭제 (drop column)
alter table student drop column tel;
-- 테이블 이름 변경(rename)
rename table student to stu;
desc stu;
-- 구조 삭제(drop)
drop table stu;
drop database exdb;
show databases;
create database madang;
show tables;
select * from book;
-- 도서 테이블에서 책이름, 책번호, 가격을 책번호가 3, 5, 1번인 책을 검색.
select bookname, bookid, price
from book
where bookid in (3, 5, 1);
-- 도서 테이블에서 책 가격이 1만원 이상 2만원 이하인 책 이름과 가격을 검색.
select bookname, price
from book
where price between 10000 and 20000;
select * from customer;
select *
from customer
where phone is not null;
select bookname
from book
where bookname like '%축구%';
-- 고객의 성씨가 박씨인 고객 전화번호 검색
select phone
from customer
where name like '박%';
-- 도서 테이블에서 출판사 명 검색(단, 중복 제외 (distinct))
select * from book;
select distinct publisher
from book;
-- 도서 테이블에서 출판사 명이 대한미디어 이거나 가격이 2만원 이상인 도서 검색
select bookname, publisher
from book
where publisher = '대한미디어' or price >= 20000;
select * from orders; 4주차 예제
show databases;
use madang;
show tables;
create user abc3279@localhost identified by '0000';
grant all privileges on exdb.* to abc3270@localhost;
-- select
-- 1. = <>, and between A and B or not in(부질의)
-- 2. is null, is not null / like '값%' '%값%' '%값'
-- distinct
select * from customer;
-- 고객의 주소가 서울이거나 대전에 사는 고객의 이름과 주소를 검색
select name, address from customer where address like '%서울%' or address like '%대전%';
-- 고객의 이름이 김씨성이면서 아로 끝나는 고객의 이름 전화번호를 검색
select name, phone from customer where name like "김%아";
-- 주문 테이블에서 책을 구매한 고객을 검색하되, 고객번호 검색. (단, 동일한 고객 번호는 단 한번만 출력.)
select * from orders;
select distinct custid from orders;
-- 전화번호가 있는 고객의 이름과 전화번호를 검색
select name, phone from customer where phone is not null;
-- 정렬 order by 필드명 asc(default)/desc
-- 도서테이블에서 도서 가격이 비싼 순으로 도서 이름, 출판사 이름, 도서 가격을 검색
select * from book;
select bookname, publisher, price from book order by publisher, price desc; -- pub 정렬 후 price 정렬
-- 주문테이블에서 고객에 따라 비싼책을 구매순으로 검색하되, 고객의 이름 도서를 구매한 가격을 검색.
select * from orders;
select custid, saleprice from orders order by custid asc, saleprice desc;
-- 집단함수 sum(필드명), avg(필드명), max(필드명), min(필드명), count(*)(null 포함 count), count(필드명)(null 미포함)
-- 도서테이블에서 가장 비싼 책과 가장 싼 책을 검색
select max(price) as '최고 가격', min(price) as '최소 가격' from book;
-- 주문 테이블에서 총판매된 가격의 합계와 평균을 출력
select * from orders;
select sum(saleprice) as 'sum', avg(saleprice) as 'avg' from orders;
-- 주문 테이블에서 총판매된 가격의 합계와 평균을 출력하되 합계가 20000원 이상인 것만 출력
select bookid, sum(saleprice) as 총계, avg(saleprice) as 평균 from orders group by bookid;
-- 도서테이블에서 출판사별로 도서가격의 합계를 출력
select *from book;
select publisher as 출판사, sum(price) as 합계
from book group by publisher having sum(price) >= 20000;
-- groupby의 조건은 having를 사용한다.
-- 고객별로 책을 주문한 고객의 번호 책을 총가격의 평균을 검색. 단, 합계가 20000원 이상
select *from orders;
select custid, sum(saleprice) as 합계, avg(saleprice) as 평균
from orders
where custid in (1,3)
group by custid
having sum(saleprice) >= 20000;
-- group by 뒤에는 where 절을 쓰지 못하지만, 앞에 사용 가능. 즉, 같이 사용가능.
select * from customer;
select count(*) as 고객의수, count(phone) as 연락처고객수 from customer;
-- 고객 테이블에서 박씨성을 가진 고객의 개수를 검색
select * from customer;
select count(*) from customer where name like "박%";
-- 도서테이블에서 출판사가 굿스포츠이거나 대한미디어인 책의 갯수와 도서가격의 총 합계
select * from book;
select count(*) as '책갯수', sum(price) as '도서가격의 합계' from book
where publisher in ('굿스포츠', '대한미디어');
-- 도서 테이블에서 출판사의 갯수를 검색.
select count(distinct publisher) as "출판사 갯수" from book;
-- 주문테이블에서 한번이라도 책을 주문한 고객의 갯수를 검색
select *from orders;
select count(distinct custid) as "책 주문 고객 갯수" from orders;
-- 주문테이블에서 고객별로 몇번 책을 주문했는지 검색
select custid, count(*) from orders group by custid;
-- 어떤 고객이 어떤 책을 얼마를 구입했는지 고객 이름, 책 이름, 판매 가격 검색.
select name, bookname, saleprice
from customer c, book b, orders o
where c.custid = o.custid and b.bookid = o.bookid;5주차 예제
-- 어떤 고객이 어떤 책을 얼마에 구입했는지 고객이름, 책이름 책번호 구매가격을 검색
use madang;
select name, bookname, b.bookid, saleprice -- bookid가 o, b에 둘 다 존재.
from book b, customer c, orders o
where b.bookid = o.bookid and c.custid = o.custid
and bookname like '%축구%';
-- 공통된 것 가져오고, 세부적인 조건. 순서가 중요.조인 연습문제
--------------------- 조인 연습문제-------------------
use madang;
select *from book;
select *from orders;
select *from customer;
select *from publisher;
-- 1.박지성의 총 구매액 을 검색하시오
select sum(saleprice) as "총 구매액"
from orders o, customer c
where c.custid = o.custid and name = '박지성';
-- 2.김연아가 구매한 도서의 수와 최고금액과 최소금액의 차이를 검색하시오.
select count(saleprice) as "구매 도서수", max(saleprice) - min(saleprice) as "가격차이"
from orders o, customer c
where c.custid = o.custid and name = "김연아";
-- 3. 박지성이 구매한 도서의 출판사 수를 검색하시오
select count(distinct publisher) as 'pub'
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid
and name='박지성';
-- 4. 박지성이 구매한 도서의 이름, 책정가 와 판매금액의 차이를 검색하시오
select bookname, price-saleprice
from book b, orders o, customer c
where c.custid = o.custid and b.bookid = o.bookid
and name='박지성';
-- 5. 김연아가 구매한 도서의 도서명과 출판사명을 검색하시오
select bookname, publisher
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid and name='김연아';
-- 6. 고객의 이름과 고객이 구매한 도서 목록(도서 번호)을 검색하시오
select name, b.bookid
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid;
-- order by name asc;
-- 7. 고객별 도서를 구매한 평균과 합계를 검색하시오
select name, avg(saleprice) as '평균', sum(saleprice) as '합계'
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid
group by name;
-- 8. 도서를 구매한 사람중 영국에 거주하는 고객의 이름과 주소를 검색하시오
select distinct name, address
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid
and address like '%영국%'; -- 주소는 무조건 키워드 포함. not 시작, 끝
-- 9.도서의 판매가격이 10000원 이상인 도서를 주문을 고객의 이름과 도서이름을 검색하시오.
select distinct name, bookname
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid
and saleprice > 10000;
-- 10. 도서명별로 판매된 금액의 합계와 평균을 검색하시오 단, 판매금액이 20000원 이상
select bookname, sum(saleprice) as "합계", avg(saleprice) as "평균"
from book b, orders o
where b.bookid = o.bookid and saleprice >= 20000
group by bookname;
-- 11. 고객의 이름과 고객이 주문한 도서의 판매가격을 검색하되 고객별 금액이 비싼거별로 검색하시오
select name, saleprice
from customer c, orders o
where c.custid = o.custid
order by name asc, saleprice desc;
-- 12.고객별로 책을 구입한 합계를 검색하되 합계가 높은 순으로 검색하시오
-- 13. 박씨 성을 가진 고객이 책을 구매한 고객명,책이름,책번호,출판사명,산가격을 검색하되 가격이 비싼 순으로 검색하시오.
select name, bookname, b.bookid, publisher, saleprice
from book b, customer c, orders o
where b.bookid = o.bookid and c.custid = o.custid and name like "박%"
order by saleprice desc;
-- 14. 출판사별로 책이 팔린 가격의 합계와 평균을 출력하되 평균이 높은 순으로 검색하시오
select publisher, sum(saleprice), avg(saleprice)
from book b, orders o
where b.bookid = o.bookid
group by publisher
order by avg(saleprice) desc;
-- inner join - on(조건)
-- 고객의 이름과 그 고객이 구입할 책의 가격을 검색
select name, sum(saleprice)
from customer c inner join orders o
on c.custid = o.custid
group by name;
select name, saleprice
from customer c inner join orders o
on c.custid = o.custid;
-- left outer join, right outer join
-- 고객이 한번도 물건을 한번도 사지 않아도 고객의 이름과 구매한 책 가격을 검색
select name, saleprice
from customer c left outer join orders o
on c.custid= o.custid;
-- is null -> 실제 존재하는 테이블에 한해서 -> join 은 실제 테이블은 아니라서 불가함.
-- 도서테이블에서 책가격이 가장 비싼책의 책이름 출판사명을 검색
select bookname, publisher
from book
where price in (select max(price) from book);
-- 부질의(subquery): where 절 안에 또다른 select 조건에 만족하는 것을 가져오는 것.
-- 도서테이블에서 도서의 평균보다 비싼 책 이름 가격을 검색
select bookname, price
from book
where price > (select avg(price) from book);
-- 도서번호가 1번 또는 3번과 같지 않은 출판사인 책의 이름, 출판사 이름을 검색
select bookname, publisher
from book
where publisher not in (select publisher from book where bookid in (1, 3));
-- 도서를 구매한 적이 한번이라도 있는 고객 이름과 주소 검색
-- join 사용
select distinct name, address
from book b, orders o, customer c
where b.bookid = o.bookid and c.custid = o.custid ;
-- 부질의 사용
select name, address
from customer
where custid in (select custid from orders);
-- 도서를 구매한 적이 한번이라도 없는 고객 이름과 주소 검색
-- 부질의 사용
select name, address
from customer
where custid not in (select custid from orders);
-- 고객 번호가 3번인 고객과 같은 책을 주문한 고객의 이름, 번호 책 제목을 검색
select name, bookname, b.bookid
from customer c, book b, orders o
where b.bookid = o.bookid and
c.custid = o.custid and
bookname in (select bookname from orders where custid=3);
-- 출판사 별로 출판사의 평균도서가격보다 비싼 도서의 이름을 검색.데이터 정의어 확인학습
create database exdb;
use exdb;
create table publisher(
pubno char(4) primary key, -- 입력형식
pubname char(20) not null,
tel char(14) not null unique,
addr char(100)
);
-- alter table publisher modify pubno char(4); -- primary key는 옵션이 아닌 key이기 때문에 재정의 및 수정할 때 다시 지정해주지 않아도 된다.
desc publisher;
create table NewBook(
bookid int primary key auto_increment, -- 1부터 자동저장 ?
bookname varchar(20) not null default "데이터베이스",
pubno char(4),
price int not null check(price < 40000),
foreign key (pubno) references publisher(pubno)
on update cascade on delete cascade
);
desc newbook;
alter table NewBook add column isbn varchar(13);
alter table NewBook modify isbn int not null;
alter table NewBook change isbn isbn_no int not null;
alter table NewBook drop column isbn_no;
rename table NewBook to Booknew;
show tables;
drop table Booknew;
drop database exdb;6주차 1번 예제
show databases;
use madang;
select * from book;
select * from customer;
select * from orders;
select * from publisher;
-- 책 제목을 검색
select b.bookid, bookname, name
from book b, customer c, orders o
where b.bookid = o.bookid and c.custid = o.custid
and b.bookid in (select bookid from orders where custid = 3);
-- 출판사 별로 출판사의 평균도서가격보다 비싼 도서의 이름을 검색
-- elect 필드명1, 필드명2
-- from 테이블명1, 테이블2, 테이블3
-- where 조건절 (select (부질의))
-- order by 기준1, 기준2
-- group by 항목
-- having group by의 조건
-- group by 항목별
-- 도서테이블에서 전체 도서가격의 평균보다 더 비싼 책들의 도서이름과 도서가격을 검색
select bookname, price
from book
where price > (select avg(price) from book);
-- 출판사별로 출판사의 평균도서가격보다 비싼 도서의 이름, 도서 가격을 검색
select bookname, price
from book b1
where price >
(select avg(price) from book b2 where b1.publisher = b2.publisher);
-- DCL 데이터조작어 select(선택), insert(삽입), update(변경), delete(삭제)
-- 삽입
-- insert into 테이블 (필드명1, 필드명2, ...) values (값1, 값2, ...)
-- 각 필드 데이터 타입과 값 타입과 같아야하며, 갯수가 같아야한다.
-- 도서테이블에 데이터베이스 책을 삽입
select *from book;
insert into book (bookid, bookname, price, publisher)
values (11, '데이터베이스', 30000, '한양출판사');
-- update 테이블명 set 바꿀 필드1= 값1, 바꿀 필드2 = 값2, ...
-- where 절(기본키값으로 수정)
-- 도서번호 11번인 도서의 출판사명을 경기출판사, 가격을 25000원으로 수정
update book
set publisher='경기출판사', price=25000
where bookid = 11;
-- delete from 테이블명 where 조건절
-- 도서테이블에서 도서번호가 11번인 도서를 삭제
delete from book
where bookid=11;6주차 2번 예제
create database companyA;
use companyA;
show databases;
CREATE TABLE DEPARTMENT (
DEPTNO INT NOT NULL,
DEPTNAME CHAR(10),
FLOOR INT,
PRIMARY KEY(DEPTNO)
);
INSERT INTO DEPARTMENT VALUES(1, '영업', 8);
INSERT INTO DEPARTMENT VALUES(2, '기획', 10);
INSERT INTO DEPARTMENT VALUES(3, '개발', 9);
INSERT INTO DEPARTMENT VALUES(4, '총무', 7);
select * from department;
-------------------------------------------------------
CREATE TABLE EMPLOYEE (
EMPNO INT ,
EMPNAME CHAR(10) ,
TITLE CHAR(10) DEFAULT '사원',
MANAGER INT,
SALARY INT CHECK (SALARY < 6000000),
DNO INT ,
PRIMARY KEY(EMPNO),
FOREIGN KEY(DNO) REFERENCES DEPARTMENT(DEPTNO)
ON UPDATE CASCADE on delete cascade) ;
INSERT INTO EMPLOYEE VALUES(2106, '김창섭', '대리', 1003, 2500000, 2);
INSERT INTO EMPLOYEE VALUES(3426, '박영권', '과장', 4377, 3000000, 1);
INSERT INTO EMPLOYEE VALUES(3011, '이수민', '부장', 4377, 4000000, 3);
INSERT INTO EMPLOYEE VALUES(1003, '조민희', '과장', 4377, 3000000, 2);
INSERT INTO EMPLOYEE VALUES(3427, '최종철', '사원', 3011, 1500000, 3);
INSERT INTO EMPLOYEE VALUES(1365, '김상원', '사원', 3426, 1500000, 1);
INSERT INTO EMPLOYEE VALUES(4377, '이성래', '이사', NULL, 5000000, 2);
select * from employee;
-- 사원의 이름, 소속 부서명, 봉급, 직위 검색
select empname, deptname, salary, title
from employee e, department d
where e.dno = d.deptno;
-- 사원의 이름과 그 사원의 직속상사 이름을 검색
select e1.empname as '사원이름', e1.title, e2.empname as '직속상사', e2.title
from employee e1, employee e2
where e1.manager = e2.empno;
-- 1. 이씨 성 을 가진 사원들의 이름 ,직급, 소속부서명을 검색하라.
select empname as 이름, title as 직급, deptname as 소속부서명
from employee e, department d
where e.dno = deptno and empname like '이%';
-- 집단함수?
-- 2. 모든 사원에 대해 부서명 별로 급여의 평균과 급여의 최대 값을 구하되
-- 급여의 평균이 2500000 이상인 부서명, 급여의 평균, 급여의 최대값을 검색하시오.
select deptname as '부서명', avg(salary) as '급여의 평균', max(salary) as '급여읭 최대값'
from employee e, department d
where e.dno = d.deptno
group by deptname
having avg(salary) >= 2500000;
-- 3. 개발부서에 근무하는 사원의 이름과, 부서명, 봉급을 검색하라
select empname as 이름, deptname as 부서명, salary as 봉급
from employee e, department d
where e.dno = d.deptno and deptname = '개발';
-- 4. 김창섭 또는 최종철이 속한 부서이고 부서명이 기획부서인 사원명, 부서명을 검색
select empname as 사원명, deptname as 부서명
from employee e, department d
where e.dno = d.deptno and
deptname = "기획" and (empname = '김창섭' or empname = '최종철') ;
-- ! where 조건 괄호 및 순서 생각
-- 5. 소속된 직원이 한명도 없는 부서의 이름를 검색하라 ?x
select deptname
from department
where deptno not in (select dno from employee);
-- 6. 최종철과 같은 직급을 가진 모든 사원의 이름과 직급을 검색하라
select empname, title
from employee
where title = (select title from employee where empname='최종철');
-- 7. 모든 사원에 대해서 소속부서의 이름, 사원의 이름, 직급, 급여를 검색하라
-- 부서 이름에대해서 오름차순 부서이름이 같은경우에는 SALARY 에 대해서 내림차순으로 정렬하시오
-- ex. 부서 이름별 salary 큰 순서로 출력
select deptname as 소속부서이름, empname as 사원이름, title as 직급, salary as 급여
from employee e, department d
where e.dno = d.deptno
order by deptname asc, salary desc;
-- 8. 자신이 속한 부서의 사원들의 평균 급여보다 많은 급여를 받는 사원들에 대해서 이름 부서번호 급여를 검색하라
select empname as 이름, dno as 부서번호, salary 급여
from employee e1
where salary > (select avg(salary) from employee e2 where e1.dno = e2.dno);
-- 9. 부서명별(부성번호 아님)로 급여의 평균을 구하는 뷰를 작성하시오(단 부서별 급여의 평균이 3000000원 이상인 것만 검색하시오)
select deptname as 부서명, avg(salary) as 급여평균
from employee e, department d
where e.dno = d.deptno
group by deptname
having avg(salary) >= 3000000;
-- 10. 사원의 이름과 그 사원의 직속상사 이름을 검색하시오(다음과 같이 출력해주세요)
select e1.empname as 사원이름, e2.empname as 직속상사이름
from employee e1, employee e2
where e1.manager = e2.empno;
-- 11. 부서 테이블을 기준으로 소속된 사원이 없다 하더라도 모두 나오고
-- 소속 된사원이 없으면 사원이름이 null로 채워지게 출력하시오
-- left outer join, right outer join인 외부 join
select deptname, empname
from department d left outer join employee e
on d.deptno = e.dno;7주차 예제
use madang;
show databases;
show tables;
-- 주문이 있는 고객의 이름과 주소를 검색
select name, address
from customer
where custid in
(select custid from orders);
select name, address
from customer c
where exists
(select * from orders o where c.custid = o.custid);
-- union (합집합)
-- 영국에 거주하는 고객의 '이름'과 / 도서를 구매한적이 없는 고객의 '이름'을 검색
-- 필드가 같아야 한다.
select name from customer
where address like '%영국%'
union
select name from customer
where custid not in (select custid from orders);
select * from customer, orders; -- 카디전 프로덕트
-- 고객의 이름이 박지성이거나 주문한 고객의 번호가 4번인 고객의 번호를 검색
select custid from customer
where name = '박지성'
union
select custid from orders
where custid = 4;
-- 실기 시험 trigger 다음 주 12-13
select abs(-123), abs(123);
-- round(값, n) 소수점 n+1번째에서 반올림하여 소수점 n번째 자리까지 출력
-- round(값, -n) 정수 n번째 자리에서 반올림.
select round(1234.567, 2), round(1234567, -2);
-- 주문 테이블에서 고객번호별 금액평균을 출력하되 평균이 소수점 첫번째 자리 출력
select * from orders;
select custid,
round(avg(saleprice), 1),
round(avg(saleprice), -3),
truncate(avg(saleprice), -3)
from orders
group by custid;
-- replace (필드, 찾을 문자열, 바꿀 문자열) <- not update, 실제로 바뀌는게 아님.
-- 책 제목에 야구를 농구로 변환하여 출력
select bookname, replace(bookname, '야구', '농구') from book;
-- 문자의 길이(공백 포함): char_length 바이트 길이: length
select bookname, char_length(bookname), length(bookname) from book;
-- left(필드, n): 왼쪽에서 문자 n개,
-- right(필드, n): 오른쪽에서 문자 n개,
-- substr(필드, i부터, n개)
select phone, left(phone, 3), substr(phone, 5, 4), right(phone, 4)
from customer;
-- 성씨 인원수 출력
select * from customer;
select left(name, 1) as 성, count(*)
from customer
group by left(name, 1);
-- 날짜 함수
-- sysdate: 현재 날자와 시간
-- date_format(날짜, 형식)
-- adddate(기준점, interval 1 month)
select sysdate();
select orderdate, date_format(orderdate, '%y/%m/%d %M %h:%s') from orders;
-- format %M만 대소문자 구분. %M은 영어 월
-- 책을 주문한 날자로 한달 후가 얼마인지 출력
select orderdate, adddate(orderdate, interval 5 day)
from orders;
-- ifnull(필드명, 대체할 문자)
select name, ifnull(phone, '전화번호 없음') from customer;
-- 번호 매기기
select @num = 0;
-- 실행 때마다 set으로 초기화 해줘야 함. 아니면 저장된 값을 사용한다.
set @num = 0;
select @num := @num+1 as 번호, custid, name, phone
from customer;
select upper('asdfghjkl'), lower('ASDFGHJKL');
-- 고객 테이블에 성만 출력하고 이름은 '*'로 채우기
select name,
rpad(left(name, 1), 3, '*') as 성,
lpad(right(name, 2), 3, '*')as 이름
from customer;10주차 예제
use madang;
-- Book 테이블에서 축구가 포함된 도서의 책 번호, 이름, 가격을 가져오는 뷰 정의
create view v1
as
select bookid, bookname, price
from book
where bookname like "%축구%";
select * from v1;
-- 원본 삽입, 삭제, 변경 시 뷰도 같이 동시 변경
insert into book
values (20, '박지성축구', '굿스포츠', 20000);
-- 뷰 변경 시 원본도 동시 변경
insert into v1
values (21, '운동은 축구', 15000);
select * from book; -- 21번 publisher <- null. => 기본키를 안가져오면 null이 되기에 제약이다.
update book
set price = 10000
where bookid = 20;
-- 뷰 튜플 삭제시 원본도 연쇄 삭제
delete from v1
where bookid = 21;
-- 출판사명별로 도서의 금액의 합계와 평균을 검색하는 뷰를 작성
create view v2 (출판사명, 합계, 평균) -- 3개 어트리뷰트 이름 주기. 뒤에서 as 써도 되고, 아니면 모든 어트리뷰트 갯수만큼의 이름을 지정해줘야한다.
as
select publisher, sum(price), avg(price)
from book
group by publisher;
select *
from v2
where 출판사명 = '나무수'; -- <- 보안.
select * from v2
where 평균 >= 15000;
select * from v2;
insert into book values (22, '스포츠바이블', '굿스포츠', 50000);
-- 뷰의 제약조건
-- 1. 기본키나 not null 속성의 필드값을 가져오지 않는 뷰는 변경할 수 없다.
-- 2. 계산된 뷰나 집단함수를 정의한 뷰는 수정할 수 없다.
-- 3. 조인된 뷰도 수정할 수 없다.
-- 도서 가격이 20000원 이상인 도서의 번호, 도서 이름, 가격을 검색하는 뷰를 작성
create view v3
as
select bookid, bookname, price
from book
where price >= 20000;
select * from v3;
select * from book;
insert into v3 values (23, '농구의 세계', 15000);
-- v3에는 조건이 안맞아 들어가지 않으나, book table에 들어가 있다.
alter view v3
as
select bookid, bookname, price, publisher
from book
where price >= 20000
with check option; -- 조건에 맞는지 본다.
insert into v3 values (24, '스포츠의 세계', 15000); -- 삽입 불가.
-- 어떤 고객이 어떤 책을 얼마에 언제 구매한지 정의된 뷰 작성
select * from orders;
create view v4
as
select name, bookname, saleprice, orderdate
from book b, customer c, orders o
where b.bookid = o.bookid and c.custid = o.custid;
select * from v4;
insert into customer values (6, '홍길동', '010-1111-1234', '경기도 안산시');
insert into orders values (20, 6, 3, 15000, '2024-11-08');
select * from v4
where name = '박지성'; -- 반복 사용시 view가 편리. 함수 같은 형태.
-- 책 이름별 도서를 판매한 합계와 평균을 가져오는 뷰 작성
create view v5 (책이름, 판매합계, 판매평균)
as
select bookname, sum(saleprice), avg(saleprice)
from book b, orders o
where b.bookid = o.bookid
group by bookname;
select * from v5
where 책이름 = "축구의 역사"; -- bookname(x) -> 책이름
select * from v5;
select *
from book
where bookid = '2';
delete from book
where bookid = '2';
show tables; -- <- view 까지
-- view 는 지울 수 있지만, 원본 table은 관련되어 있는 view를 모두 지워야 지울 수 있다.
create index ix_bookname on book(bookname, bookid);
select * from book;
delete from book
where bookname = '박지성축구';
drop index ix_bookname on book; View/Index 확인학습
-- view / index 확인학습
use madang;
show tables;
select * from book;
select * from customer;
select * from orders;
-- 1.customer 테이블에서 박씨성을 가진 고객의 이름 전화번호를 검색하는 뷰를 작성하시오
create view v1 as
select name, phone
from customer
where name like '박%';
drop view v1;
select * from v1;
-- 2. 1번에서 정의한 뷰를 수정하라(고객번호 이름 전화번호를 검색하는 뷰로 수정)
alter view v1 as
select custid, name, phone
from customer
where name like '박%';
select * from v1;
-- 3.book 테이블에서 책번호 책이름 가격을 10% 인상시켜 상시켜 출력하는 뷰를 작성하시오
-- (단 필드명은 책번호 책이름 인상된가격으로 출력한다)
create view v10 (책번호, 책이름, 인상된가격)
as
select bookid, bookname, price*(1 + 0.1)
from book;
select * from v10;
-- 4. 책을 구입한 고객의 고객명별 구입한 책의 평균금액을 검색하는 뷰를 작성하시오( 필드명은 이름, 평균금액 으로 지정한다).
create view v11 (이름, 평균금액)
as
select name, avg(saleprice)
from customer c, orders o
where c.custid = o.custid
group by name;
select * from v11;
-- 5. 어떤고객이 어떤책을 얼마에 구입했는지를 검색하는 뷰를 작성하시오
-- 고객명(name) , bookname, saleprice 검색 하는 뷰 작성
create view v12
as
select name as 고객명, bookname, saleprice
from book b, customer c, orders o
where c.custid = o.custid and b.bookid = o.bookid;
select * from v12;
-- 6. 한번도 책을 구입하지 않은 고객을 검색하는 뷰를 작성하시오
create view v13
as
select distinct name
from customer c
where c.custid not in (select custid from orders);
select * from v13;
drop view v13;
-- 7. orders 테이블에서 팔린 책 가격이 20000원 이상인 주문번호, 책번호,가격(saleprice) 을 검색하는 뷰를 작성하되
-- 범위에 벗어나는 가격은 삽입할 수 없도록 제약하시오.
create view v14
as
select orderid, bookid, saleprice
from orders
where saleprice >= 20000
with check option;
insert into v14 values (30, 10000); -- with cbeck option err
select * from v14;
-- 8. 책이름별 판매된 금액의 합계를 출력하는 뷰를 작성하시오 (단 합계가 20000원 이상인 것만검색)
create view v15
as
select bookname, sum(saleprice)
from book b, orders o
where b.bookid = o.bookid
group by bookname
having sum(saleprice) >= 20000;
select * from v15;
-- 9. customer 테이블에서 고객의 이름으로 검색하기 쉽게 인덱스를 정의하시오
create index ix_name on customer(name);
-- index 사용 이유
-- 1. 기본키가 아닌 값으로 수정 및 삭제를 가능하게 한다.
-- 2. 검색 빠르게 하기 위해.
-- index를 정의함으로써 name 을 기준으로한 수정가능.
update customer
set phone = '010-1111-1111', address ='안산시'
where name='홍길동';
-- 외래키의 제약조건 때문에 삭제 안됨. 외래키에 영향 받지 않는 행이면 index를 통해 삭제 가능.
delete from customer
where name='홍길동';
-- index를 삭제할 때 on table을 해줘야한다.
drop index ix_name on customer;
select * from customer;
11주차 예제
use companyA;
show tables;
select * from department;
select * from employee;
-- 1. EMPLOYEE 릴레이션에 대해서 “3번 부서에 근무하는 사원들의
-- 사원번호, 사원이름, 직책 부서번호로 이루어진 뷰”를 정의해보자.
create view c1
as
select empno, empname, title, dno
from employee
where dno = 3;
select * from c1;
-- 2. 뷰를 수정하라(사원번호, 사원이름, 부서번호 , 봉급을 가져오는 뷰로 수정)
alter view c1
as
select empno, empname, dno, salary
from employee
where dno = 3;
select * from c1;
-- 3. employee 테이블에서, empname(사원이름)과 , 봉급을 10% 인상시켜 뷰를 작성하시오
create view c3
as
select empname as 사원이름, salary*(1 + 0.1) as 봉급
from employee;
drop view c3;
select * from c3;
-- 4. 기획부서에 근무하는 사원의 이름 직책 부서명 봉급을 가져오는 뷰를 작성
create view v4
as
select empname, title, deptname, salary
from employee e, department d
where e.dno = d.deptno and d.deptname = '기획';
select * from v4;
-- 5. 부서명별 급여의 평균을 검색하는 뷰를 작성
create view v5
as
select deptname, avg(salary)
from employee e, department d
where e.dno = d.deptno
group by d.deptname;
drop view v5;
select * from v5;
-- 6. 소속된 직원이 하나도 없는 부서를 검색하는 뷰를 작성
create view v6
as
select distinct deptname
from department
where deptno not in (select dno from employee);
select * from v6;
-- 7. 모든 사원에 대해 같은 부서에서 봉급을 많이 받는 순으로 검색하는 뷰를 작성하시오
-- (필드는 사원의이름, 부서명, 봉급을 검색하는 뷰를 작성)
create view c7(사원의이름, 부서명, 봉급)
as
select empname, deptname, salary
from employee e, department d
where e.dno = d.deptno
order by deptname, salary desc;
drop view c7;
select * from c7;
-- 8. 부서명별로 봉급의 합계와 평균을 검색하는 뷰를 작성하되
-- 봉급의 평균이 3000000원 이상인 뷰 만 작성
create view c8
as
select deptname, sum(salary), avg(salary)
from employee e, department d
where e.dno = d.deptno
group by deptname
having avg(salary) >= 3000000;
drop view c8;
select * from c8;
-- 9. 사원의 이름과 그 사원의 직속상사 이름을 검색하는 뷰를 작성하시오. (다음과 같이 출력해주세요)
create view c9 (사원이름, 직속상사이름)
as
select e1.empname, e2.empname
from employee e1, employee e2
where e1.manager = e2.empno;
-- self join
drop view c9;
select *
from c9
where 직속상사이름 = '박영권';
-- 10. 부서 테이블을 기준으로 소속된 사원이 없다 하더라도 모두 나오고 소속된 사원이 없으면 사원이름이
-- null로 채워지는 뷰를 작성하고 뷰를 검색하여 다음과 같이 출력해주세요
create view c10 (부서명, 사원명)
as
select deptname, empname
from department d left outer join employee e
on d.deptno = e.dno;
drop view c10;
select *
from c10
where 사원명 is null;
-- 11. 자신이 속한 부서의 사원들의 평균 급여보다 많은 급여를 받는 사원들에 대해서
-- 이름 부서이름 급여를 다음과같이 앞에 번호를 붙여 검색하시오.
Set @seq:=0;
select (@seq := @seq+1) as 번호, empname, deptname, salary
from employee e, department d
where e.dno = d.deptno and
salary > (select avg(salary) from employee e1 where e.dno = e1.dno);
-- 12. department 테이블에서 부서명으로 검색하기 쉽게 인덱스를 정의하시오
create index ix_deptname on department(deptname);
-- 13. department 테이블의 인덱스를 삭제하시오
drop index ix_deptname on department;
12주차 예제
use madang;
-- 테이블 복사
create table bookex1
as
select * from book;
select * from bookex1;
create table bookex2
as
select bookid, bookname, price from book;
select * from bookex2;
create database triex;
use triex;
create table triaa (
id int primary key,
name char(20)
);
create table tribb (
id_1 int primary key,
name_1 char(20)
);
show tables;
-- 삽입트리거(triaa 가 insert 후에 tribb도 insert 작업 수행.)
delimiter //
create trigger tri_in
after insert on triaa for each row
begin
insert into tribb -- (id_1, name_1)
values (new.id, new.name); -- triaa의 값을 tirbb에 insert 함.
end; //
delimiter ;
insert into triaa values (1, '홍길동');
insert into triaa values (2, '이순신');
insert into triaa values (3, '김영희');
delete from triaa where id >= 1;
select * from triaa;
select * from tribb;
show triggers;
-- 변경트리거(triaa 가 변경되면 tribb가 변경되는 트리거)
delimiter //
create trigger tri_up
after update on triaa for each row
begin
update tribb
set name_1 = new.name
where id_1 = new.id;
end; //
delimiter ;
show triggers;
update triaa
set name = '홍길순'
where id = 1;
select * from triaa;
select * from tribb;
-- 삭제 트리거 (triaa 를 삭제 후 tribb도 삭제)
delimiter //
create trigger tri_del
after delete on triaa for each row
begin
delete from tribb
where id_1 = old.id;
end;
//
delimiter ;
delete from triaa where id = 1;
select * from triaa;
select * from tribb;
-- product 상품 테이블: prono, proname, account(수량)
-- ordering 구매 테이블: orderno, userid, prono, ordercount
-- deliver 배달 테이블: delno, prono, delcount
create table product (
prono int primary key,
proname char(20),
account int
);
create table ordering (
orderno int auto_increment primary key,
userid varchar(20), -- id, 비번은 varchar
prono int ,
ordercount int,
foreign key (prono) references product(prono)
);
create table deliver (
delno int auto_increment primary key,
prono int,
delcount int,
foreign key (prono) references product(prono)
);
desc product;
desc ordering;
desc deliver;
insert into product values (1, '사과', 100);
insert into product values (2, '배', 100);
insert into product values (3, '감', 100);
select * from product;
-- ordering 구매(insert) 하면 수량을 변경(update)하는 트리거 작업.
delimiter //
create trigger tri_iu
after insert on ordering for each row
begin
update product
set
account = account - new.prono
where prono = new.prono;
end;
// delimiter ;
-- product 수량이 변경(update)되면 deliver 테이블에 삽입(insert).
delimiter //
create trigger tri_ui
after update on product for each row
begin
insert into deliver(prono, delcount)
values (new.prono, old.account - new.account);
end;
// delimiter ;
show triggers;
insert into ordering(userid, prono, ordercount)
values ('hong', 1, 10); -- err
drop trigger tri_ui;13주차 실기 시험
create database db;
use db;
-- 4 회원 테이블
create table member (
id varchar(8) primary key,
pwd varchar(8) not null,
name varchar(10) not null,
addr varchar(20),
tel char(14) not null
);
-- [goods 테이블]
create table goods (
pronum char(4) primary key,
proname varchar(4) not null,
price int check (price > 0),
stock int default 0
);
-- 5 구입 테이블
create table buy (
num int primary key auto_increment,
id varchar(8) not null,
pronum CHAR(4),
account int,
foreign key(id) references member(id) on update cascade on delete cascade,
foreign key(pronum) references goods(pronum) on update cascade on delete cascade
);
-- [입고 테이블]
create table ordering (
num int primary key auto_increment,
pronum char(4),
orderdate date not null,
account int check (account > 0),
orderprice int check (orderprice > 0),
foreign key(pronum) references goods(pronum) on update cascade on delete cascade
);
desc buy;
desc member;
desc ordering;
desc goods;
-- [goods 테이블]
insert into goods (pronum, proname, price) values ('AAAA', '새우깡', 1500);
insert into goods (pronum, proname, price) values ('BBBB', '초코파이', 1200);
insert into goods (pronum, proname, price) values ('CCCC', '짱구', 1500);
-- 4
insert into member values ('hong', '1234', '홍길동', '경기도 성남시', '010-1111-1234');
insert into member values ('hong12', '2222', '홍길순', '경기도 안양시', '010-1234-1234');
insert into member values ('ke12', '4444', '김수진', '서울시 은평구', '010-2222-7853');
insert into member values ('kim', '8888', '김고은', '충북 청주시', '010-3333-8963');
insert into member values ('lee', '7854', '이준기', '경상북도 상주시', '010-8974-1234');
insert into member (id, pwd, name, tel)values ('ohkj', '1111', '오경주', '010-2222-1234');
insert into member values ('park', '1234', '박보검', '서울시 강남구', '010-1456-5555');
insert into member values ('pjy', '7821', '박진영', '경기도 고양시', '010-8888-1234');
select * from member;
-- 1
delimiter //
create trigger tri_in1
after insert on ordering for each row
begin
update goods
set stock = stock + new.account
where pronum = new.pronum;
end;
// delimiter ;
insert ordering(pronum, orderdate ,account, orderprice ) values ('AAAA', '2023-11-21', 10, 1000);
insert ordering(pronum, orderdate ,account, orderprice ) values ('BBBB', '2023-10-11', 15, 1000);
insert ordering(pronum, orderdate ,account, orderprice ) values ('CCCC', '2023-09-11', 10, 1000);
insert ordering(pronum, orderdate ,account, orderprice ) values ('AAAA', '2023-11-21', 10, 1000);
select * from goods;
select * from ordering;
-- 2
delimiter //
create trigger tri_up1
after update on ordering for each row
begin
update goods
set stock = stock + (new.account - old.account)
where pronum = new.pronum;
end;
// delimiter ;
update ordering set account=5 where num=1;
select * from goods;
select * from ordering;
-- 3
delimiter //
create trigger tri_de1
after delete on ordering for each row
begin
update goods
set stock = stock - old.account
where pronum = old.pronum;
end;
// delimiter ;
delete from ordering where num=4;
select * from goods;
select * from ordering;
-- 6
delimiter //
create trigger tri_in2
after insert on buy for each row
begin
update goods
set stock = stock - new.account
where pronum = new.pronum;
end;
// delimiter ;
insert into buy(id, pronum, account) values ('hong', 'BBBB', 1);
select * from goods;
select * from buy;
-- 7
insert into buy(id, pronum, account) values ('hong', 'BBBB', 1);
insert into buy(id, pronum, account) values ('kim', 'AAAA', 1);
insert into buy(id, pronum, account) values ('lee', 'AAAA', 1);
insert into buy(id, pronum, account) values ('hong12', 'CCCC', 2);
insert into buy(id, pronum, account) values ('kim', 'CCCC', 1);
insert into buy(id, pronum, account) values ('hong', 'AAAA', 1);
insert into buy(id, pronum, account) values ('lee', 'BBBB', 1);
insert into buy(id, pronum, account) values ('kim', 'BBBB', 1);
insert into buy(id, pronum, account) values ('pjy', 'CCCC', 1);
-- 7-1
select name, proname, addr
from buy b, goods g, member m
where b.pronum = g.pronum and m.id = b.id and name like '홍%';
-- 7-2
create view v1(이름, 상품번호)
as
select name, null
from member m
where m.id not in (select id from buy);
select * from v1;
-- 7-3
select name, proname, account, rpad(left(tel, 9), 13, '*') as '전화번호'
from buy b, goods g, member m
where b.pronum = g.pronum and m.id = b.id
order by name, account desc;
-- 전체 결과 확인
select * from buy;
select * from goods;
select * from member;
select * from ordering;14주차 예제
create database expro;
use expro;
-- 전화번호 테이블 생성 삽입, 삭제, 변경하는 프로시저 정의 호출
create table 전화번호 (
id int primary key,
name char(20) not null,
phone char(16)
);
select * from 전화번호;
-- 삽입 프로시저 정의
delimiter //
create procedure p_test01 (
in inid int,
in inname char(20),
in inphone char(16)
)
begin
insert into 전화번호 (id, name, phone)
values (inid, inname, inphone);
end ;
// delimiter ;
call p_test01(1, '홍길동', '010-1111-1234');
call p_test01(2, '이순신', '010-2222-1234');
call p_test01(3, '박형식', '010-1234-3333');
-- 2. 수정프로시저
delimiter //
create procedure p_test02 (
in upid int,
in upname char(20),
in upphone char(16)
)
begin
update 전화번호
set name=upname, phone = upphone
where id = upid;
end ;
// delimiter ;
call p_test02(1, '홍길순', '010-9999-1234');
-- 3. 삭제 프로시저
delimiter //
create procedure p_test03 (
in delid int
)
begin
delete from 전화번호
where id = delid;
end ;
// delimiter ;
call p_test03(1);
-- 4. 검색프로시저 (id가 1번이면 모든값을 검색하는 프로시저 정의)
delimiter //
create procedure p_test04 (
in sid int
)
begin
select * from 전화번호 where id = sid;
end ;
// delimiter ;
call p_test04(2);
-- 삽입 변경 프로시저 (아이디가 있으면 변경, 아이디가 없으면 삽입)
delimiter //
create procedure p_test05 (
in inid int,
in inname char(20),
in inphone char(16)
)
begin
declare count1 int;
select count(*) into count1
from 전화번호
where id = inid;
if (count1 = 0) then
insert into 전화번호 (id, name, phone) values (inid, inname, inphone);
else
update 전화번호 set name=inname, phone=inphone where id=inid;
end if;
end ;
// delimiter ;
call p_test05(4, '아이유', '010-5555-1234');
call p_test05(4, '김미영', '010-2222-1234');스키마 정의
create schema 스키마명 authorization 사용자id;
도메인 정의
create domain 도메인명 [as] 데이터타입 [default 기본값] [constraint 제약조건명 check (범위값)];
create domain sex char(1) default '남' constraint valid-sex check(value in ('남', '여'));
like 연산자 문자패턴
- %: 모든 문자 대표
- _: 문자 하나 대표
- #: 숫자 하나 대표
그룹함수 추가
- rollup(속성명, ...): 인수로 주어진 속성을 대상으로 그룹별 소계를 구함.
- cube(속성명, ...): 인수로 주어진 속성을 대상으로 모든 조합의 그룹별 소계를 구함.
window 함수
: groupby 절 사용하지 않고, 함수 인수로 지정한 속성값 집계
- row_number(): 윈도우 별 레코드에 대한 일련번호 반환
- rank(): 윈도우별 순위 반환, 공동 순위 반영
- dense_rank(): 윈도우별 순위 반환, 공동 순위 무시
select 상여내역, 상여금,
row_number() over (partition by 상여내역 order by 상여금 desc) as no
from 상여금;
상여내역 기준 group by 후 order by 상여금인데, 일련변호가 no라는 속성으로 추가됨.
관계대수: 관계형 db에서 원하는 정보를 검색하기 위한 유도를 기술하는 절차적 언어. 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시.
관계대수로 표현한 식은 관계해석으로 표현 가능
- 순수 관계 연산자
- select(): 선택 조건을 만족하는 튜플의 부분 집합을 구해 새 릴레이션을 만드는 연산.
- project(): 속성값 추출해 새 릴레이션을 만드는 연산
- join(⟗): 공통 속성 중심 두 개 릴레이션을 하나로 합쳐 새 릴레이션을 만드는 연산
- Division(): 는 S의 모든 튜플을 만족하는 R을 반환하는 연산
- 일반 집합 연산자
- 합집합(union, )
- 교집합(intersection, )
- 차집합(difference, )
- 교차곱(cartesian product, ): 두 릴레이션 튜플의 순서쌍(모든 경우의 수)를 구하는 연산
R = {a, b}, S = {1, 2}
= (a, 1), (a, 2), (b, 1), (b, 2)
관계해석(Relational Calculus)
- 관계 데이터 연산 표현 방법
- 술어해석(Predicate Calculus) 기반
- 비절차적 특성
- 계산 수식 사용
트랜잭션(Transaction): db상태 변환시키는 한꺼번에 모두 수행되어야하는 일련의 연산. 데이터베이스 시스템에서 병행제어 및 회복 작업시 처리되는 작업의 논리적 단위로 사용.
ACID
- Atomicity(원자성): 트랜잭션 연산은 db에 모두 반영되도록 완료(commit)되든지 아니면 아에 복구(rollback)돼야함.
- Consistency(일관성): 트랜잭션이 성공으로 실행 완료시 언제나 일관성 있는 db상태로 변환함.
- Isolation(독립성): 트랜잭션 실행중에 다른 트랜잭션 연산이 끼어들 수 없음.
- Durability(지속성): 성공적으로 완료된 트랜잭션 결과는 시스템이 고장나더라도 영구적 반영되어야함.
CRUD 분석(Create, Read, Update, Delete): 프로세스와 테이블 간 CRUD 매트릭스를 만들어 트랜잭션을 분석하는 것.
crud matrix: 행에는 프로세스, 열에는 테이블, 행과 열이 만나는 위치에는 프로세스가 테이블에 발생시키는 변화(CRUD)를 표시해 프로세스와 데이터 간 관계를 분석하는 분석표.
