20240907 오늘 한 거
프로젝트를 해봤다.
그 중에서 의미 있는 게 있어서 가져와봤다.
코인가격 등락 예측 프로젝트
목표
- 코인 가격의 등락 맞추기
- 등락 폭에 따라 0, 1, 2, 3 으로 class를 나눈다.
- 많이 하락하면 0 적게 하락 1, ... 이런식으로
lgbm 모델 학습 후 아래 지표로 평가
- accuracy_score, roc_auc_score
- gain(영향력)
- split(예측에 관여한 횟수)
처음에 받은 csv에서 피처는 아래와 같았다.
단순 lgbm모델 학습을 돌렸을 때 아래와 같은 정확도가 나왔다.
acc: 0.4252X..., auroc: 0.6329X...
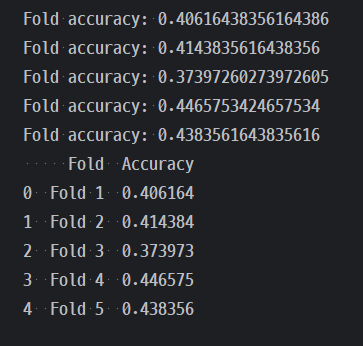
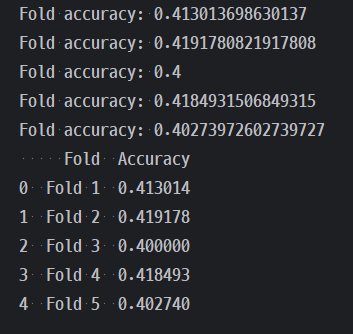
tscv를 사용한 결과는 아래와 같았다.
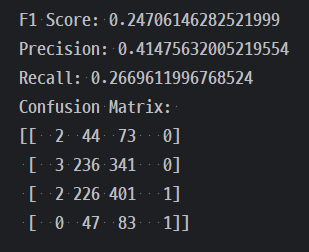
그리고 실제로 대회에 제출해봤을 땐 아래와 같은 정확도가 나왔다.
public: 0.3988
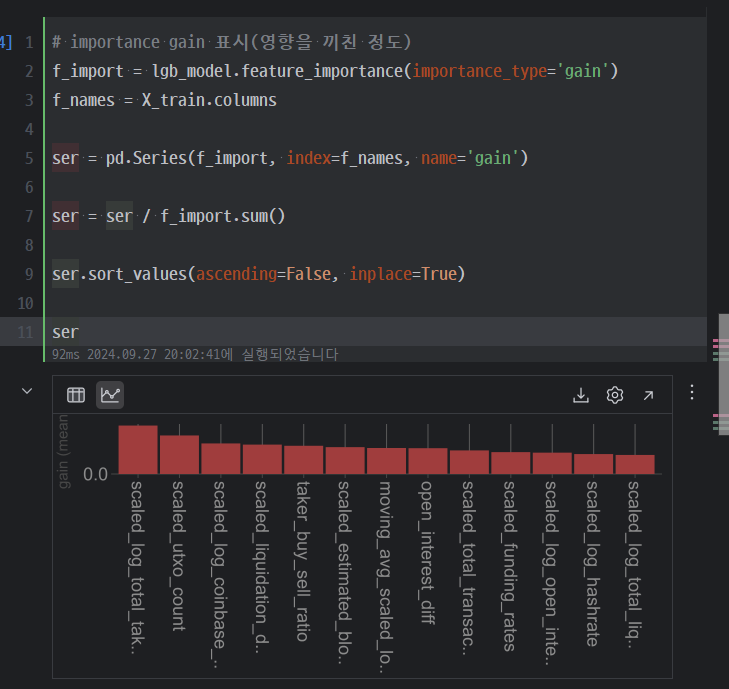
학습 이후 피처 평가를 하기위해 gain과 split 값을 뽑아보았다.
위의 결과에서 scaled_utxo_count, scaled_log_total_taker_volume 값이 좀 영향이 크다고 생각했고 이를 지워봤다.

위와 같이 완만한 그래프가 되었다.
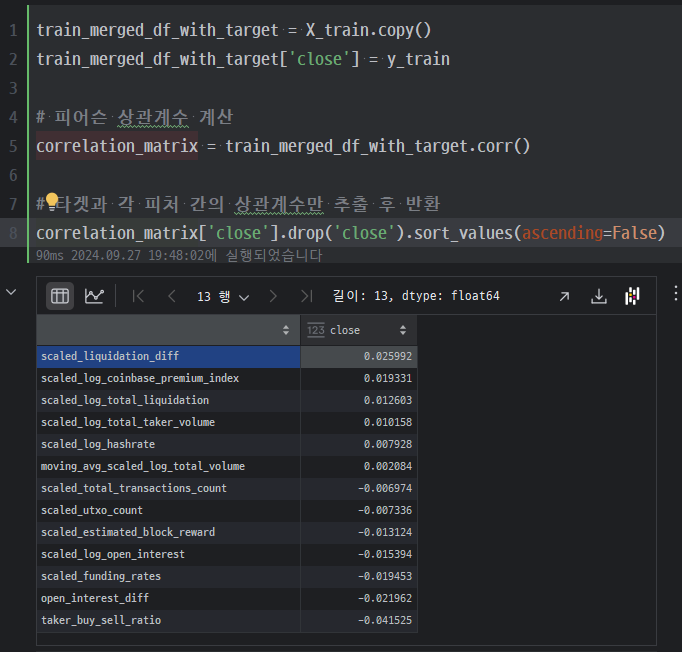
좀 생각해볼 건 close와 상관 계수 자채는 그렇게 튀는 값이 없었다는 거다.
# scaled_utxo_count와 scaled_log_total_taker_volume 제거 train_df = df.loc[df['_type']=='train'].drop(columns=['_type', 'scaled_utxo_count', 'scaled_log_total_taker_volume']) test_df = df.loc[df['_type']=='test'].drop(columns=['_type', 'scaled_utxo_count', 'scaled_log_total_taker_volume'])
위 코드로 제거 후 학습을 진행했다.
정확도는 아래와 같다
acc: 0.4252X..., auroc: 0.6329X...
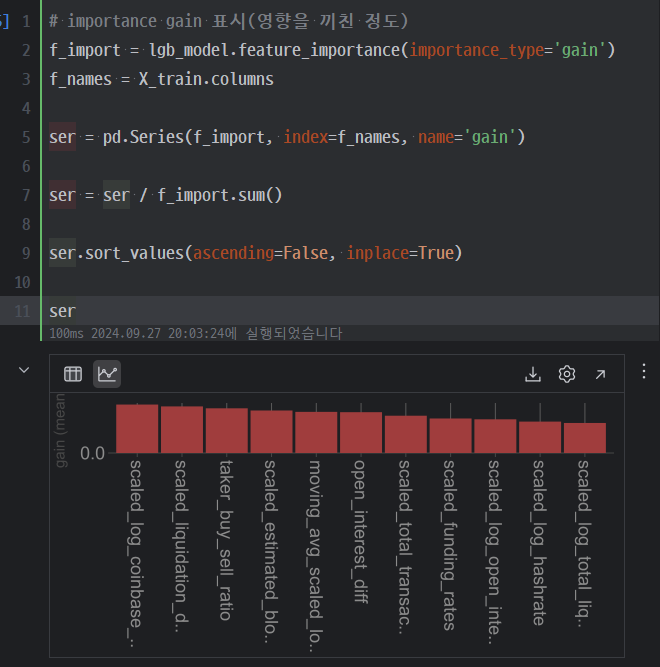
그리고 이번엔 gain값도 크게 튀는 게 없어서 이대로 TSCV 학습도 진행했다.
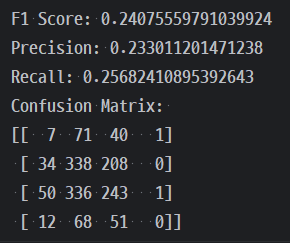
target 0을 예측하는 횟수는 올랐는데 precision 값은 눈에 띄게 떨어졌다.
제출 했을 떄 결과는 아래와 같다.
public: 0.3849
아주 조금이지만 오히려 떨어졌다
이때 든 생각은
- 많은 지표를 담는 거보다 영향도가 높은 지표만 우선해서 골라야하나?
- 아니면 내가 지워버린 지표가 매우 주요한 없어선 안 될 지표였나?
여러 생각이 들었지만 일단 public이 떨어진 가설에는 집중하지 않기로 했다. 그런데 최종 결과에서 이걸 뒤집는 결과가 나왔다.
public -> private(원본사용): 0.3849 -> 0.3988
public -> private(피처삭제): 0.3849 -> 0.4176
저런 점수에 그것도 아주 적은 차이에 집착하면 안 되지만 최대한 많은 지표를 담을수록 성능이 높아지는 건지 확인을 해보고 싶은 결과였다.
이후엔.. 기회가 되면 이런 상황에서 각 피처의 가중치를 부여해보고 싶었는데 그건 학습이 이루어진 다음에 이야기인 거라 그거보다 애초에 학습에 관여 자채를 못하는 피처를 줄이고 싶어서 그 방법을 생각해볼 거 같다.

선생님 정확도 80% 넘으면 저도 알려주십쇼