[논문리뷰] Suggestive Annotation: A deep Active Learning Framework for Biomedical Image Segmentation
paper
MICCAI 2017에 accept된 논문 Suggestive Annotation: A deep Active Learning Framework for Biomedical Image Segmentation에 대해 리뷰해보겠음.
연구실에서 진행중인 MR Angio task에 적용해보려고 읽음. 의료 데이터 특성상 데이터의 양이 적을뿐만 아니라 annotation하기 힘들기 때문에 모델이 직접 annotation area를 제안해주면 expert가 annotation하기 수월하지 않을까? 라는 생각에서 읽어보게 됨.
Abstract
image segmentation은 biomedical image analysis에서 기본적인 문제임. 하지만 biomedical image는 다양한 variation이 존재하기 때문에(modalities, image setting, ibject, noise등) 새로운 application에서 딥러닝을 활용하기 위해서는 새로운 training data set이 필요함.
본 논문에서는 annotation을 효율적으로 하기 위해 FCN과 active learning을 결합하여 uncertainty하고 representative한 annotation area를 제안하는 모델을 제안함.
Introduction
annotation efforts와 cost가 너무 높아서 충분한 training data를 획득하기 어려움.
1) 오직 훈련된 biomedical expert만이 annotate할 수 있어 군중을 활용하기 어려움
2) natural scene image보다 biomedical image에 훨씬 많은 object instance가 포함되어 있음
manual annotation에 대한 부담을 줄이기 위해 약한 supervised 알고리즘들이 제안되었지만 최상의 performance를 위해 어떤 data sample이 annotation되어야 하는지에 대한 문제는 잘 다루지 않았다.
model이 training data를 선택하게 하는 active learning은 이런 필요에 방법을 제공한다.
본 논문은 FCN을 활용해서 domain specific image descriptor를 얻고 region preposal없이 segmentation을 바로 수행한다.
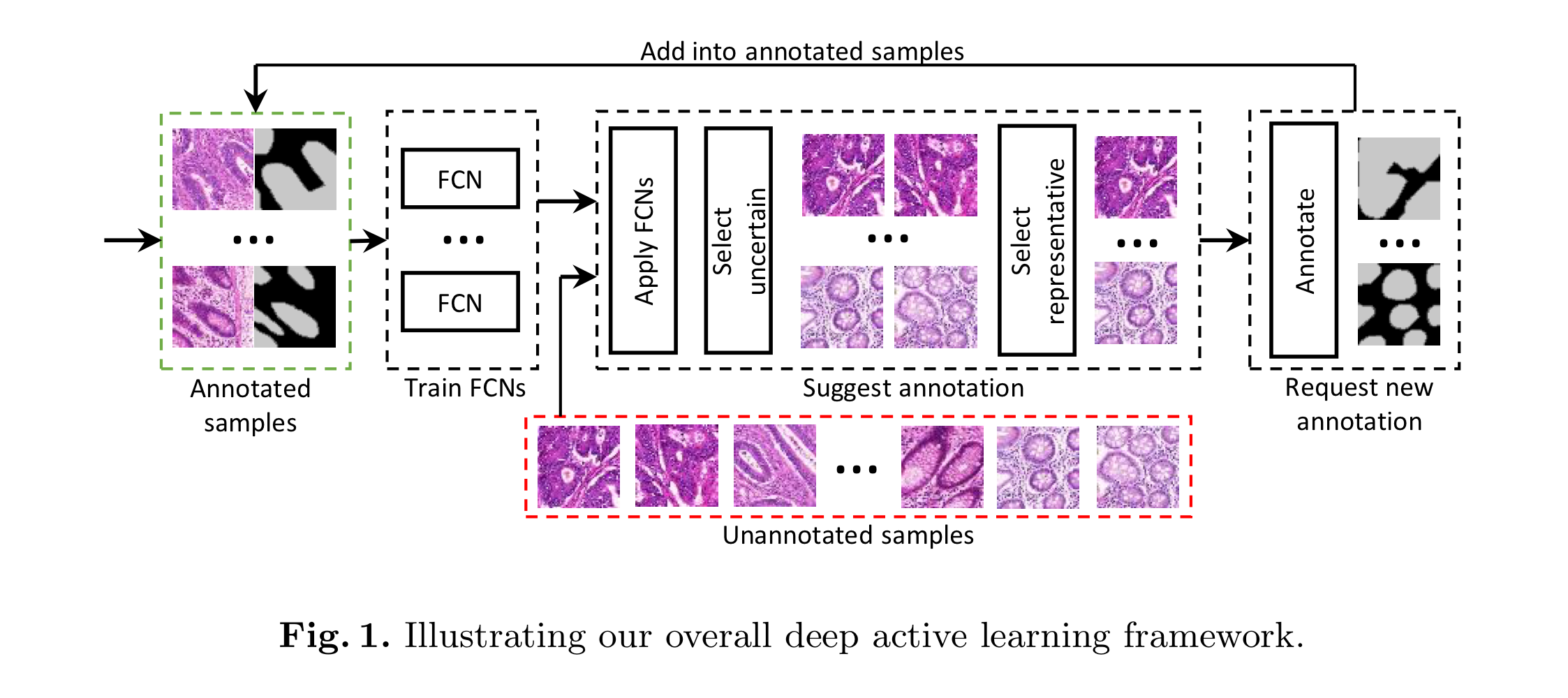
아주 적은 training data를 가지고 FCNs를 반복적으로 학습하고 각 stage의 끝에서 uncertainty와 similarity를 추정하여 다음 annotate batch를 결정한다. 새로운 annotation data를 얻으면 모든 사용가능한 annotated image를 사용해 다음 stage를 수행한다.
FCNs를 deep active learning framework에 적용하기 위해 해결해야 할 몇가지 문제는
FCNs 관점에서
1) 두 annotation stage 간의 시간 간격이 허용될 수 있도록 FCNs는 훈련 속도가 빨라야 함
2) 좋은 generality 성능을 가져야 함
active learning 관점에서
1) bootstrapping 아이디어를 기반으로 FCNs의 uncertainty를 추정하는 방법
2) FCNs의 encoding part의 마지막 layer 이미지들 간의 similarity를 추정하는 방법을 보여줌
Method
1) A new fully convolutional network
더 나은 generality와 속도를 위해 새로운 FCN을 고안함
새로운 FCN은 원래의 버전과 비교했을 때 훨씬 적은 training step으로도 같은 정확도를 보임. 이는 FCNs와 active learning을 결합할 때 필수적임.
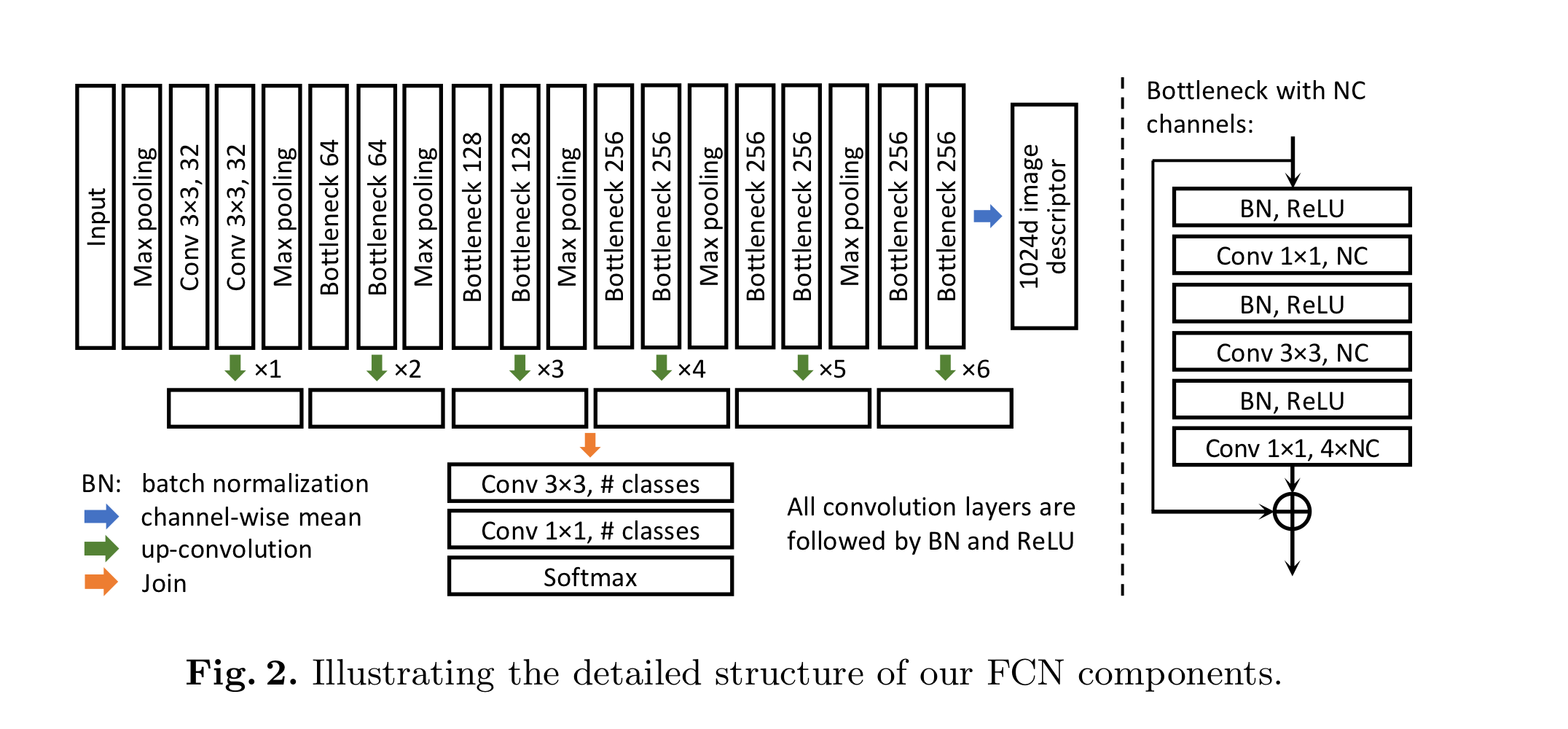
active learning의 시작 부분에 적은 training data 수로 학습을 시작하는데 모델이 너무 많은 parameter를 가지면 학습하는데 어려움을 겪음 -> bottleneck design을 이용해 각 residual module의 feature channel 수는 비슷하게 유지하면서 parameter 수를 줄임
network의 decoding 부분은 smooth result를 위해 feature map의 크기를 점진적으로 커지게 수정함. 다른 scale의 feature map들을 결합하기 위해 3x3 conv와 1x1 conv가 적용됨. -> new FCN은 매우 적은 수의 training data로도 sota 성능에 도달할 수 있음
2) Uncertainty estimation and similarity estimation
가장 valuable한 annotation area를 찾기 위해 uncertainty sampling을 이용함. 하지만 deep learning model은 비슷한 type의 instance에 uncertainty한 경향이 있기 때문에 중복 선택될 가능성이 있음 -> 이 문제를 피하기 위해 uncertain하고 representative한 sample을 선택하고자 함.
bootstrapping은 학습 모델의 uncertainty를 평가하기에 표준화된 방법임. bootstrap은 training data의 각기 다른 subset(복원 추출된)으로 학습한 모델들의 variance를 계산함. 이 과정을 이용해 FCNs의 uncertainty를 계산함. 마지막으로 각 training sample의 전체 uncertainty는 각 픽셀의 uncertainty의 평균값으로 계산함
FCN의 encoding part의 마지막 conv layer output은 입력 이미지 의 high level feature인 임. domain-specific image descriptor로 압축된 feature인 를 생성하기 위해 를 channel-wise mean 해줌.
이 방식의 장점
1) 다른 image descriptor network를 훈련할 필요 없음
2) 두 이미지 간의 cosine similarity만 계산하면 됨
3) Annotation suggestion
annotation data의 효과를 극대화하기 위해 annotation area는 1) uncertainty 2) representativeness 를 가져야 함
- : 모든 unannotated image
- : 중 개 select한 subset(uncertain, representative)
highly uncertain하고 representative한 상위 개의 image subset을 선택하는 방법
step 1. uncertainty score가 상위 개인 image들이 를 구성
step 2. 에서 가장 representative한 image를 찾아냄
를 maximize하는 (에 속하는)를 찾기 위해서
1) 많은 unannotated images와 비슷한 "hub" image를 선택하고
2) 다양한 case를 포함해야 함
=> generalized version of the maximum set cover problem으로 계산
maximum set cover problem은 NP-hard이며, 가장 가능성 높은 polynomial time approximation algorithm은 단순한 greedy algorithm임.(가장 많은 수의 uncovered elements를 포함하는 를 반복적으로 선택하는)
word
- utilize : 활용하다, 이용하다
- incur
- judicious
- leverage
- alleviate : 완화하다
- manual : 손으로 하는, 수동의
- address : 고심하다, 다루다
- exploit : 이용하다
- restrict : 제한하다
- eliminate : 없애다, 제거하다
- condense : 압축하다
- criterion : 기준
- intuitively : 직관적으로
- if and only if : 필요충분조건
- attain : 이루다, 이르다

정리를 정말 깔끔하게 해주신 것 같아요.