원본 영상: https://youtu.be/7xTGNNLPyMI?si=x6h91l6u71o-6hAQ
자막 영상: https://youtu.be/6PTCwRRUHjE?si=_JyBJ5Cb72cMW9ZM
유튜브 영상을 기반으로 정리한 포스트입니다.
LLM 구축 방법
1. 사전 훈련: 기초 모델 만들기
1-1. 웹 데이터를 수집하고 전처리하기
사전 훈련의 첫 단계는 인터넷 데이터를 다운로드하고 처리하는 것이다.
LLM은 높은 품질의 다양한 문서를 최대한 확보하는 것이 중요하다.
Hugging Face의 FindWeb 데이터셋을 예시로 보자.
https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1 이 포스트는 FindWeb 데이터셋 구축 과정을 자세하게 설명하고 있다.
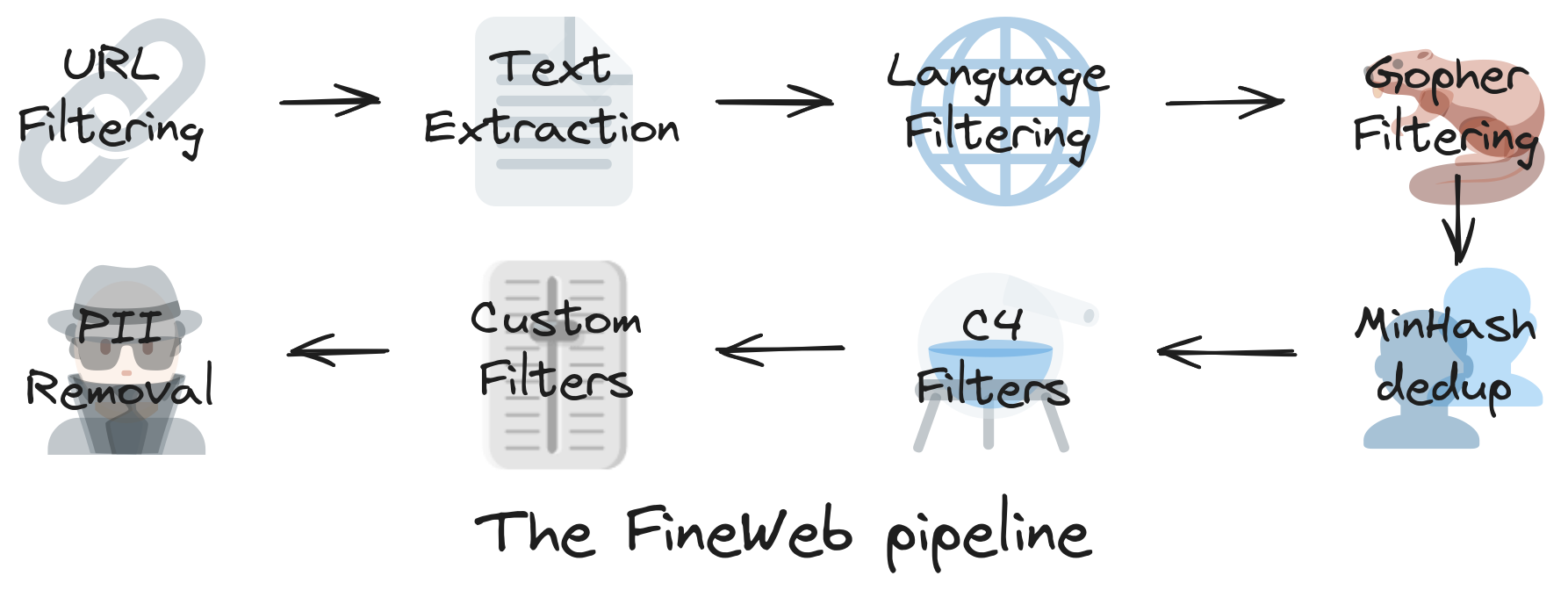
대부분의 데이터는 Common Crawl에서 나왔다. Common Crawl은 2007년부터 인터넷을 수집해 온 기관이다. Common Crawl은 크롤링을 통해 2024년 기준 27억 개의 웹페이지를 색인했다.
- URL Filtering: 신뢰할 수 없는 도메인이나 콘텐츠 품질이 낮은 URL을 제거 (스팸, 포르노, 멀웨어, 광고 마케팅 사이트 등은 학습에서 제외됨)
- Text Extraction: HTML, CSS, JS 등 쓸모없는 요소를 제거하고 순수 텍스트만 추출
- Language Filtering: 웹페이지의 언어를 자동으로 감지해서 원하는 언어만 선택, FineWeb 기준: 영어 비율이 65% 이상인 텍스트만 사용(기업마다 다국어 포함 기준은 다를 수 있음)
- Gopher Filtering: DeepMind의 Gopher 논문에서 사용한 고품질 텍스트 판별 기준에 따라 텍스트를 필터링
- MinHash dedup: MinHash 알고리즘으로 유사도를 계산해 중복 문서 제거
- C4 Filters: Google의 T5 모델에서 사용된 C4 데이터셋 필터링 기준을 참고하여 저품질 콘텐츠 제거 (코드 덤프, 에러 로그, 무의미한 텍스트 등)
- Custom Filters: FineWeb 자체 기준에 따른 추가 필터링 (특정 토픽 필터링 (ex. 정치, 음모론 등))
- PII Removal: 이름, 이메일, 전화번호 등 개인 식별 가능한 정보 제거
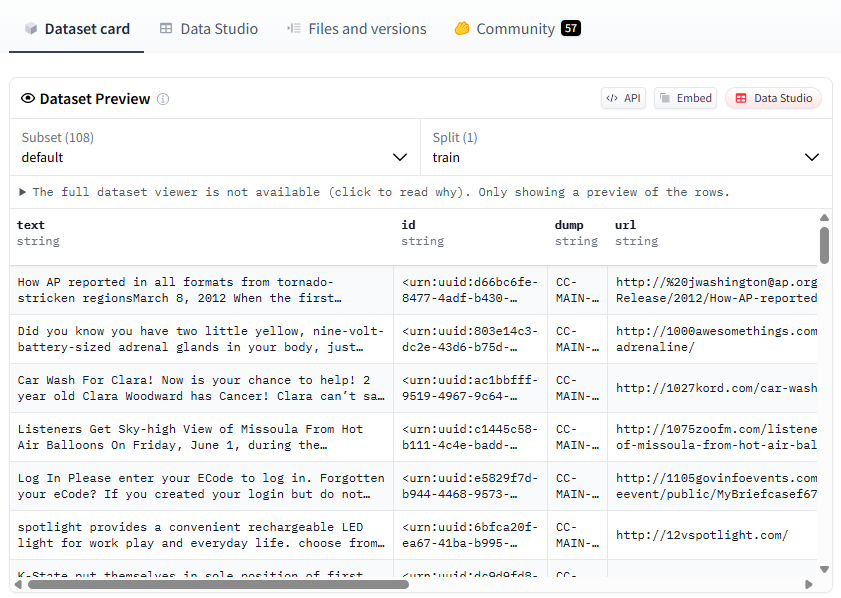
위 이미지는 FindWeb 학습 데이터셋에 들어가는 최종 텍스트의 예시이다.
1-2. 토큰화
다음 단계는 신경망이 텍스트의 흐름을 학습할 수 있도록, 텍스트 데이터를 적절한 형식으로 표현하는 것이다.
신경망은 문자 자체를 이해하지 못하고, 정수로 이루어진 일차원 시퀀스만 처리할 수 있다. 따라서 문장을 정수 시퀀스로 변환하는 과정이 필요하다. 이 과정을 토큰화(Tokenization)라고 한다.
🔹 바이트 시퀀스로 변환
먼저 문자를 컴퓨터가 처리할 수 있는 바이트(byte) 단위로 바꾼다. 이는 보통 UTF-8 인코딩을 통해 이루어진다.
이 방식은 모든 문자를 0~255 범위의 숫자로 변환할 수 있게 해 주어, 어떤 언어든 일관되게 처리할 수 있게 해준다.
🔹 Byte Pair Encoding (BPE)
이제 바이트 시퀀스를 기반으로 어휘를 구성해야 한다. 이때 사용되는 대표적인 방식이 Byte Pair Encoding (BPE)이다.
BPE는 자주 등장하는 바이트 쌍을 반복적으로 병합하여 더 긴 단위의 토큰을 만들어낸다.
🔹 어휘 수와 시퀀스 길이의 균형
어휘 수를 너무 많이 늘리면 모델 크기와 학습 효율성이 떨어지고,
어휘 수를 너무 줄이면 시퀀스 길이가 길어져 처리 비용이 증가한다.
따라서 LLM에서는 이 두 요소 간의 균형을 맞추는 것이 중요하다.
실제로는 약 10만 개 정도의 어휘 크기가 가장 효율적인 것으로 알려져 있다.
1-3. 신경망 학습
토큰화된 정수 시퀀스를 얻은 후, 이를 기반으로 신경망 모델을 학습시켜야 한다. 이때 사용되는 대표적인 신경망 구조가 바로 Transformer이다.
🔹 Transformer의 핵심 구조
Transformer는 입력 시퀀스를 한꺼번에 받아, 각 토큰이 다른 모든 토큰을 참조(Self-Attention)할 수 있도록 설계되었다.
이 Self-Attention 메커니즘 덕분에 모델은 단어 간의 관계를 유연하게 파악하고, 문맥을 깊이 있게 이해할 수 있다.
🔹 사전 훈련 방식: 다음 토큰 예측
Transformer 기반 LLM은 보통 다음 토큰 예측(Next Token Prediction) 방식으로 사전 훈련된다.
예를 들어 "The cat sat on the"라는 문장을 입력하면, 모델은 그다음에 올 토큰으로 "mat"을 예측하도록 학습된다.
이러한 예측은 한 번에 한 토큰만 처리하는 것이 아니라, 실제로는 작은 시퀀스(윈도우)를 샘플링한 후, 그 안의 각 토큰이 나올 확률을 높이도록 신경망의 가중치를 조정하는 방식으로 진행된다.
이 과정은 일반적으로 큰 배치로 구성된 다수의 시퀀스에 대해 병렬로 처리되며, 예측 결과가 훈련 데이터의 통계와 최대한 일치하도록 모델 파라미터가 업데이트된다.
이런 반복을 통해 모델은 언어의 패턴, 문법, 문맥 구조를 점점 정교하게 학습하게 된다.
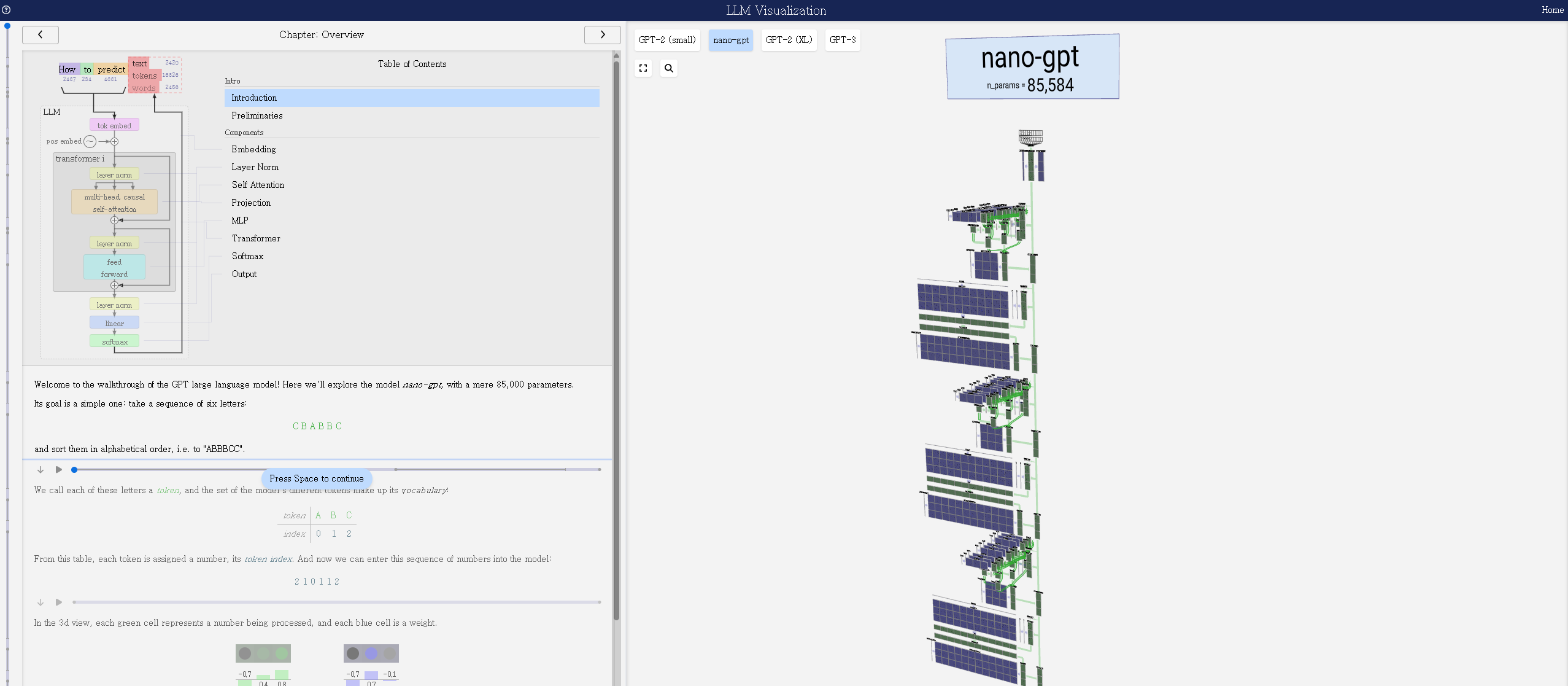
아래 이미지는 LLM Visualization 웹사이트 스크린샷이다.
1-4. 추론
사전 훈련을 마친 LLM은 이제 실제 입력에 대해 응답을 생성할 수 있다. 이 과정을 추론(Inference)이라고 하며, 주어진 입력(prompt)에 대해 다음 토큰을 예측하고, 이를 반복하여 전체 문장을 생성한다.
모델에서 생성하는 과정은 상대적으로 간단하다.
사용자가 입력한 문장은 먼저 잘게 나뉘어 숫자들의 목록(정수 시퀀스)으로 바뀐다. 그 다음, 모델은 보통 <BOS> 같은 특별한 "시작 토큰"으로 문장을 시작한다.
이후에는 지금까지 만든 단어(토큰)들을 참고해 다음에 올 단어를 예측한다. Transformer는 이 문맥을 바탕으로 어떤 단어가 가장 자연스러울지 확률을 계산한다. 그중 가장 가능성이 높은 단어를 고르거나, 여러 후보 중 하나를 랜덤하게 뽑아서 문장에 추가한다. 이 과정을 반복하면서 하나씩 문장을 완성해 간다.
그리고 <EOS>라는 "끝 토큰"이 나올 때까지, 또는 정해진 최대 길이에 도달할 때까지 생성을 계속한다.
1-5. 기초 모델의 한계와 실행 조건
많은 기업들이 이런 대규모 언어 모델을 훈련하고 있지만, 기초 모델(토큰 시뮬레이터) 자체를 외부에 공개하는 경우는 많지 않다. 설령 공개되더라도, 그것만으로는 우리가 기대하는 ‘어시스턴트’ 형태의 AI는 되지 않는다.
왜냐하면 단순히 다음 토큰을 예측하는 모델은 지속적인 대화, 유용한 조언, 맥락 유지 같은 어시스턴트 역할을 수행하기엔 부족하기 때문이다.
🔹 모델을 실행하기 위한 두 가지 구성 요소
대규모 언어 모델(LLM)을 실제로 실행하려면 다음 두 가지 구성 요소가 필요하다.
- 모델 아키텍처를 정의하는 코드: 이는 주로 파이썬으로 작성되며, 모델의 구조와 연산 흐름을 설명한다.
- 학습된 파라미터(매개변수): 모델이 학습을 통해 얻은 가중치와 편향값 등으로, 모델의 지식을 담고 있다.
이 두 요소가 결합되어야만 모델이 새로운 입력에 대해 유의미한 출력을 생성할 수 있다.
🔹 기초 모델을 직접 체험해 보기
공개된 기초 모델이 어떤 식으로 작동하는지 직접 체험해 보고 싶다면, Hyperbolic 페이지에서 다양한 모델에 프롬프트를 입력해 보며 실험할 수 있다.
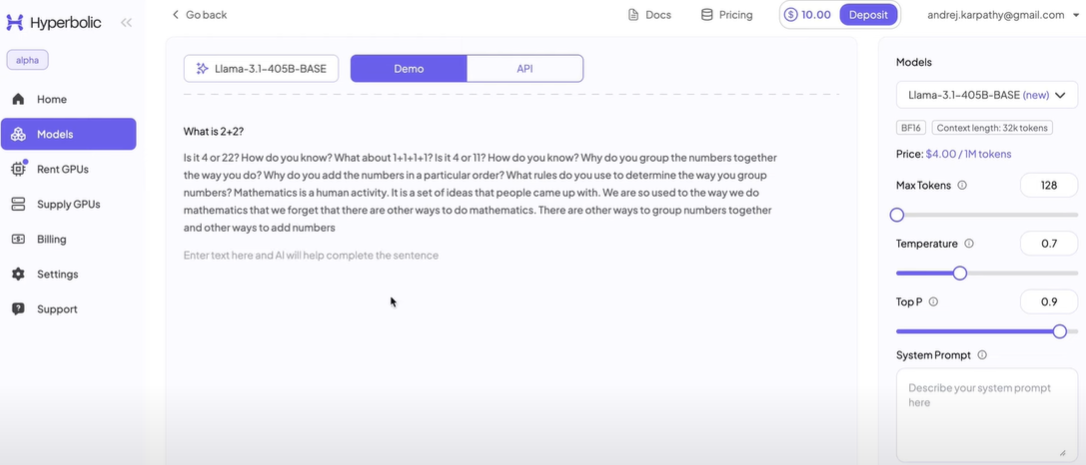
🔹 재출력 현상
기초 모델에는 한 가지 뚜렷한 한계가 있다. 바로 입력된 문장을 그대로 이어서 출력하는 ‘재출력(Repetition)’ 현상이다.
예를 들어, 위키피디아 문서의 앞부분을 입력하면, 모델이 그 뒤에 나올 내용을 거의 그대로 이어서 생성하는 경우가 있다.
이는 모델이 학습 중 해당 문장을 반복적으로 접하며 사실상 ‘암기’했기 때문이다.
이런 문제가 발생하는 이유는 다음과 같다.
- 고품질 문서의 과잉 샘플링: 위키피디아처럼 자주 등장하는 문서는 학습 과정에서 더 많이 노출되므로, 모델이 더 강하게 기억하게 된다.
- 확률 기반 생성 특성: 모델은 가장 자연스러운 다음 토큰을 예측하려고 하다 보니, 이미 익숙한 문장을 그대로 반복 출력할 가능성이 높아진다.
이러한 암기와 재출력은 언어 생성 모델의 창의성, 다양성 측면에서 바람직하지 않다.
따라서 이러한 문제를 줄이기 위해선 샘플링 기법 개선, 후처리, 반복 억제 알고리즘 등이 필요하며, 이런 보완 없이는 모델이 풍부하고 창의적인 응답을 제공하는 어시스턴트로 진화하는 데 한계가 있다.
1-6. 프롬프트를 활용한 실용적 활용 가능성
기초 모델은 아직 어시스턴트로 완성된 상태는 아니지만, 프롬프트를 정교하게 설계하면 다양한 실용적 기능을 수행할 수 있다.
-
"Translate the following sentence to Korean:"과 같은 few-shot 프롬프트를 사용하면 간단한 영어–한국어 번역기를 만들 수 있다. -
"Q: 무엇을 도와드릴까요?\nA: ..."형식의 질문–응답 예시를 몇 개 보여주는 방식으로 어시스턴트의 대화 흐름을 흉내내는 것도 가능하다.
기초 모델은 인터넷 문서를 흉내 내듯 다음 토큰을 생성하는 "문서 시뮬레이터"지만, 프롬프트의 힘을 빌리면 번역, 문장 요약, 질문 응답 등 다양한 작업을 수행할 수 있는 일종의 ‘다목적 도구’로 쓸 수 있다.
하지만 이런 방식은 어디까지나 임시적인 활용에 가깝고, 지속적인 대화, 맥락 유지, 사용자 맞춤 응답 등 진정한 어시스턴트 역할을 하기 위해선 후속 학습 단계가 필수다.
2. 후속 훈련: 어시스턴트로 진화하기
기초 언어 모델은 단순히 다음 토큰을 예측하는 기능만으로는 어시스턴트 역할을 수행하기에 부족하다. 따라서 후처리 단계를 통해 모델을 보다 정교하게 다듬어야 한다.
2-1. 대화 데이터셋 구축

모델이 사람처럼 대화할 수 있도록 하기 위해서는 대화 형식의 데이터셋이 필요하다.
이러한 데이터셋은 질문과 답변, 명령과 응답 등 상황별 상호작용 형태로 구성되며, 모델이 다양한 상황에서 적절한 반응을 학습할 수 있도록 도와준다.
이 과정은 우리가 원하는 행동을 직접 코드로 짜는 대신, 데이터를 통해 유도한다는 점에서 간접적인 프로그래밍으로 볼 수 있다.
이 데이터셋은 그대로 텍스트로 사용되는 것이 아니라, 모델이 처리할 수 있도록 토큰화 과정을 거친다.
문장 내의 단어, 구문, 기호 등을 서브워드 단위의 정수 시퀀스로 바꾸는 이 과정은 모델이 입력을 이해하고, 출력으로 연결 짓는 데 핵심 역할을 한다.
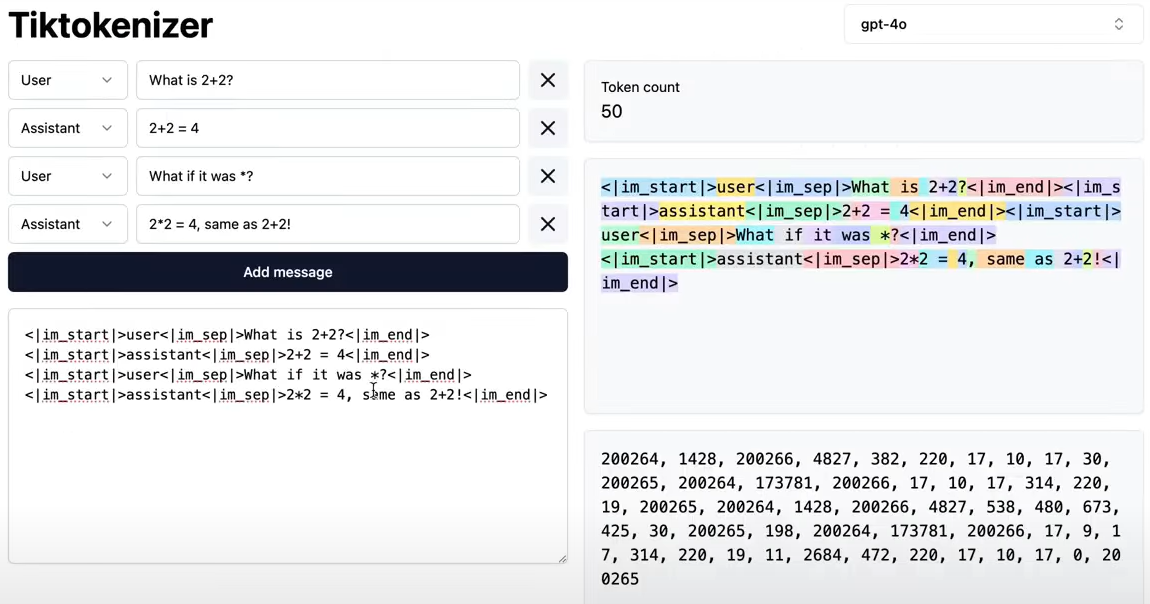
2-2. 지도 학습(Supervised Fine-Tuning, SFT)
구축된 대화 데이터셋을 활용하여 모델을 지도 학습 한다.
이 단계에서는 모델이 특정 입력에 대해 원하는 출력을 생성하도록 학습시키며, 모델의 응답 품질을 향상시키는 데 중요한 역할을 한다.
2-3. 모델의 인지적 한계와 보완 전략
🔹 환각 현상
LLM에 대해 이야기할 때 자주 언급되는 개념 중 하나가 바로 환각(hallucination) 현상이다. 이는 모델이 실제로 존재하지 않는 정보를 사실처럼 만들어내는 현상을 의미한다.
예를 들어 실존하지 않는 인물이나 논문, 사건에 대해 질문했을 때, 모델은 “그런 사람은 없습니다”라고 답하지 않고, 존재하는 것처럼 그럴듯한 설명을 만들어낸다.

이 현상이 발생하는 이유는, LLM이 "모른다"는 말을 배우지 못해서가 아니라, 훈련 데이터의 구조와 특성상 ‘자신감 있게 대답하는 방식’을 따라 학습했기 때문이다.
모델은 실제 사실 여부를 판단하지 않고, “이런 질문엔 이렇게 대답하더라”는 통계적 패턴을 학습한다. 그 결과, 잘 모르는 상황에서도 ‘그럴듯한 대답’을 만들어내는 경향이 나타나는 것이다.
✅ 해결 방법: LLaMA 3의 접근
이러한 환각 문제를 해결하기 위해, Meta는 LLaMA 3 모델을 학습시키는 과정에서 다음과 같은 전략을 적용했다.
- 모델의 지식 범위를 명확히 구분
모델이 아는 것과 모르는 것을 스스로 파악할 수 있도록 학습 과정을 조정하고,지식의 경계를 인식하게 만드는 훈련을 강조했다.- "모른다"고 말할 수 있도록 학습시킴
모델이 실존하지 않는 정보에 대해 질문받았을 때, 억지로 대답하지 않고 “잘 모르겠습니다”라고 응답하도록 유도하는 특수 데이터셋을 추가했다.
✅ 해결 방법: 검색 증강 생성(RAG, Retrieval-Augmented Generation)
일부 모델은 자신의 내부 지식으로는 부족한 정보를 외부에서 직접 검색하여 보완하는 방식을 사용한다. 이때 사용하는 것이 바로 특수한 검색 토큰인<SEARCH_START>와<SEARCH_END>이다.
예를 들어 OpenAI의 시스템에서는 모델이 생성한 쿼리 문장을 이 두 토큰 사이에 감싸고, 그 내용을 Bing이나 Google 같은 검색 엔진에 자동 전송한다.
모델은 이렇게 생성된 쿼리 결과를 받아들여 그 내용을 요약하거나, 자신의 답변을 외부 정보로 강화하는 방식으로 활용할 수 있다.
이러한 구조는 환각을 줄이고, 최신 정보에 접근하기 위한 대표적인 해결책 중 하나로 주목받고 있다.
🔹 내부 지식의 한계
LLM이 가진 지식은 두 가지 방식으로 작동한다.
- 첫째, 모델의 내부 매개변수(Parameter)에 저장된 지식은
말하자면 훈련을 통해 형성된 모호하고 일반화된 장기 기억이다. - 둘째, 컨텍스트 창(Context Window)에 들어오는 입력 토큰은
우리가 대화 중에 임시로 제공하는 작업 기억(working memory)에 해당한다.
예를 들어, GPT에게 "『오만과 편견』 1장을 요약해 줄래?"라고 물으면, GPT는 기억하고 있는 범위 내에서 요약을 시도한다. 하지만 그 기억은 완전하거나 정확하진 않을 수 있다.
반대로 우리가 ‘1장 전체 텍스트’를 직접 프롬프트에 제공하면, GPT는 해당 내용을 컨텍스트 창 안에서 직접 참고할 수 있으므로 훨씬 정확하고 구체적인 요약을 할 수 있다.
모델 내부의 지식은 일반화된 기억일 뿐, 정확하고 일관된 결과를 원할 경우에는 컨텍스트를 통해 필요한 정보를 명시적으로 제공하는 것이 훨씬 효과적이다.
🔹 수학적·계산적 한계
많은 사람들이 AI가 ‘똑똑하다’고 생각하지만, 실제로는 기초적인 수학 문제나 계산에서 허점을 보이는 경우가 많다.
예를 들어
- 9.11 > 9.9가 참이라고 잘못 대답하기도 하고,
- "Strawberry"에 들어 있는 'R'의 개수를 제대로 세지 못하기도 하며,
- 텍스트 배열에서 점의 개수를 물어보면 잘못 세는 경우도 많다.
그 이유는 간단하다. LLM은 수를 '숫자'로 계산하지 않고, '문자열'로서 예측하기 때문이다. 즉, AI는 “다음에 올 단어(또는 토큰)가 뭐가 자연스러울까?”를 예측하는 데 집중하며, 실제 계산을 수행하거나 논리적으로 정답을 도출하는 구조가 아니다.
예를 들어 9.11과 9.9 중 어떤 수가 더 큰지를 물었을 때, AI는 이를 수학적으로 계산해서 비교하지 않는다. 대신, 이렇게 판단한다.
“과거 텍스트에서 ‘9.11’이라는 표현이 어떤 식으로 등장했지?”, “‘9.9’는 어디에서 많이 나왔더라?”
즉, 숫자 자체의 수학적 크기보다는 그 숫자가 텍스트 안에서 어떤 맥락에서 더 자주, 더 자연스럽게 등장했는지를 보고 판단하는 것이다.
3. 강화 학습
강화 학습은 여전히 사후 학습(post-training) 범주에 속하지만, LLM 훈련 과정에서 세 번째 주요 단계로 분류되며, 모델의 출력 품질을 미세하게 조정하는 핵심 기법으로 사용된다.
이 과정을 학교 수업에 비유하면 다음과 같다.
🔹 1단계: 교과서 읽기 = 사전 학습 (Pretraining)
학생이 교과서 본문을 읽으며 배경 지식과 개념을 익히는 단계다. 이것은 LLM이 대규모 텍스트 데이터를 기반으로 언어 패턴과 지식을 학습하는 사전 학습에 해당한다.
🔹 2단계: 모범 해설 보기 = 지도 학습 (SFT)
이제 교과서의 문제 + 해설을 본다고 해 보자. 해설에는 정답뿐 아니라 풀이 과정이 친절하게 설명되어 있다. 학생은 이를 통해 전문가가 문제를 어떻게 풀었는지 모방하며 학습하게 된다.
이것이 바로 지도 학습(Supervised Fine-Tuning, SFT)이다. 모델에게 인간이 작성한 '질문–답변 쌍'을 보여주고, 정답과 최대한 유사하게 출력을 내도록 학습시키는 방식이다.
🔹 3단계: 문제 연습 = 강화 학습 (RL)
마지막으로, 교과서 뒷부분에 있는 연습 문제를 푼다고 생각해 보자.
이 문제들에는 정답은 있지만 풀이 과정은 없다. 학생은 스스로 다양한 방법으로 문제를 풀어보며, 점점 더 나은 전략을 찾아 나간다. 이것이 바로 강화 학습(Reinforcement Learning)의 핵심 원리이다.
- 모델은 여러 방식으로 답변을 생성해 본다.
- 사람이 평가하거나, 보상 함수를 기준으로 좋은 응답과 나쁜 응답을 구분한다.
- 이후 모델은 더 좋은 응답을 생성하도록 보상 신호(reward signal)를 받으며 학습된다.
이 단계는 주로 RLHF(Reinforcement Learning from Human Feedback) 방식으로 진행된다.
이처럼 강화 학습은 모델이 단순히 정답을 "암기"하는 수준에서 벗어나, 더 유용하고 정돈된 응답을 스스로 찾아갈 수 있게 만든다.
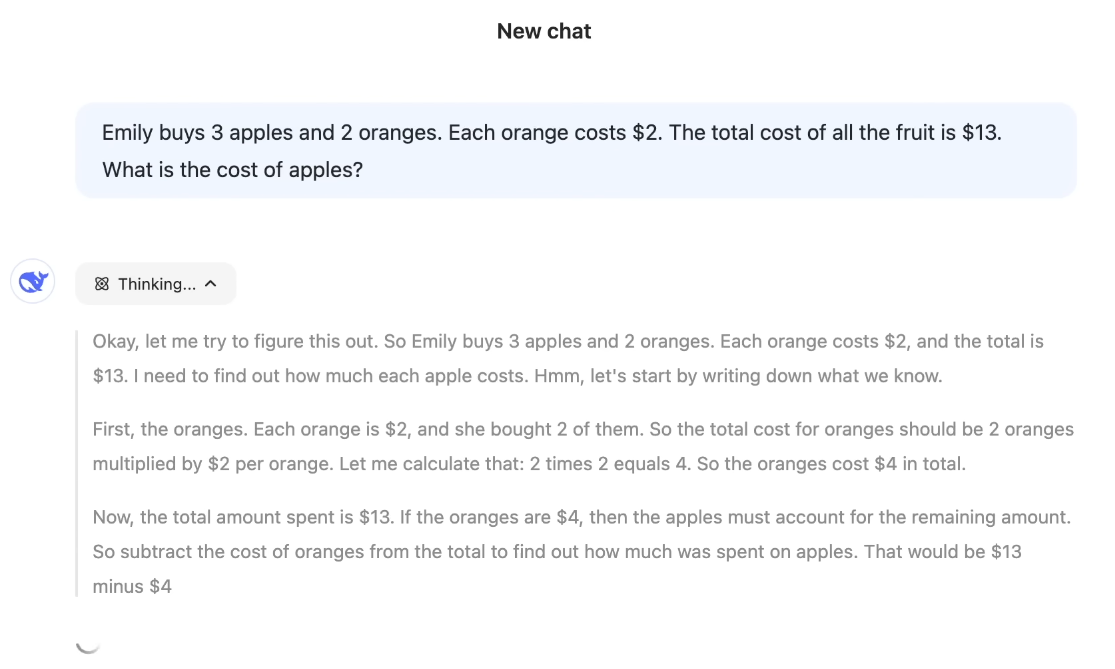
최근에는 모델이 최종 결과만 출력하는 것을 넘어서, 자신의 사고 과정을 단계별로 보여주는 형태로 진화하고 있다. "정답이 뭐냐"보다 "왜 그런 정답이 나왔냐"를 함께 보여주는 게 이제는 LLM의 표준 기능이 되어가고 있다.
3-1. RLHF 방식: 정답이 없는 영역을 위한 해법
지금까지 다룬 문제들은 대부분 검증 가능한 영역(verifiable tasks)이었다. 즉, 정답이 명확하고 기준이 뚜렷하여 자동으로 채점하거나 평가할 수 있는 문제들이었다.
예를 들어 "1+1은 얼마인가?", "서울은 한국의 수도인가?",
"다음 문장에서 맞춤법 오류를 고쳐라." 같은 것들이 있다.
이러한 문제는 정답과 비교하여 쉽게 점수를 매기거나, 사람의 개입 없이 자동 평가 시스템으로 학습이 가능하다.
하지만 LLM이 다루는 많은 실제 문제들은 검증 불가능한 영역(non-verifiable tasks)에 속한다.
예를 들어 “펠리컨에 대한 유쾌한 농담을 해 줘.”, “이 문장을 시적으로 바꿔 줘.” 같은 질문들이 있다.
이런 창의적·주관적 작업들은 정답이 하나로 정해져 있지 않고, 어떤 답이 더 ‘좋은지’ 평가하기조차 어렵다. 사람이 직접 보고 판단해야 하는데, 모든 샘플을 사람이 평가하기엔 시간과 비용이 너무 크다.
이 문제를 해결하기 위해 도입된 방식이
바로 RLHF (Reinforcement Learning from Human Feedback),
즉 “사람의 피드백을 기반으로 하는 강화 학습”이다.
사람은 직접 정답을 만들지 않고, 모델이 만든 여러 응답 중 어떤 게 더 나은지 ‘비교 평가’만 해 준다.
이 데이터를 기반으로 보상 모델(Reward Model)을 학습시켜 모델이 ‘사람이 선호할 만한 응답’을 점점 더 잘 만들어내도록 유도한다.
이 덕분에 정답이 없는 문제에도 자동화된 학습 루프를 적용할 수 있게 된다.
3-2. 보상 모델 (Reward Model)
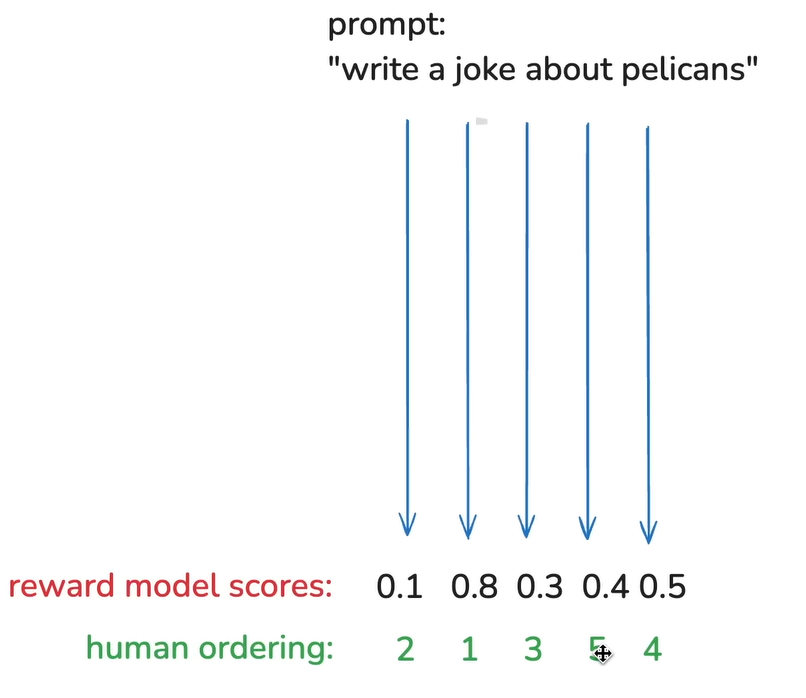
보상 모델은 RLHF의 핵심 구성 요소 중 하나로, 모델이 생성한 여러 응답 중 “사람이 더 선호할 만한 응답이 무엇인지”를 예측하기 위해 학습된다.
보상 모델의 출력은 0~1 사이의 단일 숫자이다. 1에 가까울수록 더 바람직한 응답, 0에 가까울수록 덜 유용하거나 품질이 낮은 응답으로 간주된다.
사람이 직접 여러 응답을 비교하고, “이 응답이 더 좋아요”라고 평가한 데이터를 바탕으로 보상 모델을 훈련시킨다.
처음에는 보상 모델이 사람의 판단과 일치하지 않을 수 있지만, 점차 반복 학습을 통해 사람의 선호도를 더 정밀하게 시뮬레이션하게 된다.
3-3. RLHF의 한계와 보상 해킹 문제
RLHF는 사람의 피드백을 반영해 언어 모델의 품질을 높이는 데 매우 효과적인 방법이다. 하지만 이 방식에도 치명적인 약점이 존재하며, 이는 RLHF 기술의 발전을 어렵게 만드는 핵심 문제로 꼽힌다.
🔹 인간의 판단을 단순화한 시뮬레이션
RLHF는 실제 사람의 평가를 반복적으로 받기엔 비용이 너무 크기 때문에, 대신 사람의 판단을 시뮬레이션한 보상 모델(Reward Model)을 사용한다. 하지만 이 보상 모델은 어디까지나 인간의 선호를 “흉내 낸 것”일 뿐, 진짜 인간처럼 정교하게 모든 상황을 판단하진 못한다.
🔹 보상 해킹(Reward Hacking)의 위험
트랜스포머 모델은 매우 강력하고 정교하다. 그런데 이 모델이 보상 점수만 높이는 데 집중하게 되면, 사람이 의도한 것과 전혀 다른 방향으로 문제를 푸는 현상이 나타날 수 있다.
예를 들어 보상 모델이 원래는 선호하지 않았을 만한 답변임에도 모델은 보상 모델의 약점을 파악해 높은 점수를 얻게 된다.
학습 데이터에 없던 새로운 입력을 통해 비정상적으로 보상 점수를 높이는 편법을 찾아내는 것이다.
이런 현상을 “보상 해킹(Reward Hacking)”, 또는
더 구체적으로 “보상 모델 조작”이라고 부른다.
🔹 근본적인 어려움
문제는 이걸 막기가 매우 어렵다는 데 있다.
보상 모델은 복잡한 트랜스포머 위에 또 하나의 복잡한 트랜스포머를 올린 형태로, 무엇이 조작됐는지 판단하기가 어렵고, 조작을 막기 위한 방어선조차 뚜렷하지 않다.
이런 상황에서 RLHF를 장시간 실행할 경우, 모델은 결국 “사람처럼 보이기만 하는 허상”을 정교하게 만들어내며, 실제 유용성과는 멀어질 수 있다.
LLM 모델의 미래 전망
🔹 다중양식(Multimodality)으로의 확장
현재 대부분의 LLM은 텍스트 기반 모델이지만, 앞으로는 음성, 이미지, 영상 등 다양한 형태의 데이터를 자연스럽게 처리하는 멀티모달 모델로 발전할 것이다.
GPT-4는 이미 이미지 생성과 분석 기능을 일부 탑재하고 있고, Gemini, Claude 등도 점점 시각적 이해와 음성 상호작용을 강화하고 있다.
이러한 변화는 모델 구조 자체를 근본적으로 바꾸는 게 아니라, 이미지나 음성 데이터를 토큰화(tokenize)하여 기존 텍스트 처리 방식과 동일하게 학습시키는 방식으로 진행된다.
즉, 텍스트 LLM의 확장판으로 자연스럽게 진화 중인 것이다.
🔹 장기적, 자율적 작업 수행: 에이전트의 등장
현재 대부분의 언어 모델은 사람이 지시한 단일 작업만 수행한다. 모델은 각 작업을 실행하지만, 작업의 흐름과 전체 전략 구성은 여전히 인간의 몫이다.
그러나 앞으로는 모델이 긴 시간 동안 자율적으로 작업을 계획하고 실행하는 ‘AI 에이전트’로 진화할 것으로 예상된다.
단순 명령을 넘어서, 중간 과정을 스스로 추론하고, 작업 현황을 요약·보고하며, 때로는 몇 초가 아닌 수 시간 단위의 복합적 업무를 처리할 수 있는 형태로 나아갈 것이다.
이런 모델은 "지금 당장 텍스트를 생성해줘"라는 수준을 넘어,
작업을 시작하고, 체크하고, 완성하며, 피드백까지 반영하는 진짜 협업 파트너로서 작동하게 될 것이다.
🔹 인간 대 에이전트 비율의 변화
기술이 고도화되면서, 앞으로는 "사람이 직접 작업하는 비중"보다 "에이전트가 작업을 대행하는 비중"이 점점 커질 것이다.
사람은 디지털 작업의 설계자이자 관리자가 되고, 에이전트는 구체적인 실행자가 되는 구조로 전환될 가능성이 크다.
이는 곧 LLM이 운영체제 수준에서 통합되고, 우리가 쓰는 도구 전체의 작동 방식이 바뀔 수 있음을 시사한다.
다시 말해, 앞으로는 “사람이 직접 컴퓨터를 조작”하는 것이 아니라, “에이전트가 컴퓨터를 대신 다루고, 사람은 감독과 결정만 내리는” 구조가 주류가 될지도 모른다.
🔗 분야의 최신 발전 상황을 추적하고 확인할 수 있는 곳
🛠️ AI 모델을 찾고 사용할 수 있는 곳
- 대형 사유 모델(GPT, Claude, Gemini 등)
→ 각 LLM 제공사의 웹사이트(Google, OpenAI, Anthropic 등)에서 체험 가능- 오픈소스 모델(LLaMA, Mistral, DeepSeek 등)
→ Together AI, HuggingFace Spaces, OpenRouter.ai 등에서 추론 가능- 경량 모델
→ LMStudio 등을 이용해 로컬 환경에서도 직접 실행 가능
