요가자세 데이터셋 preprocessing
요가 자세의 정확도를 측정하는 모델을 만들기 위해 자료를 찾아보던 중 생각보다 캐글 데이터셋에서 제공하는 이미지 갯수가 작고 그 데이터셋을 기반으로 작성한 코드들의 정확도도 낮다는 사실을 발견했다. 이건 프로젝트의 치명적인 결함이 될 수 있으므로 모델의 정확도를 높이기 위한 방법을 찾아야만 했다.
그래서 선택한 수단이 preprocessing이다. 기존의 캐글 데이터셋에 구글링을 통해 발견한 82-yoga 데이터셋을 합쳐 데이터의 수를 늘리고 가능하다면 이미지 세그맨테이션으로 사람으로 대상을 좁혀 지금보다 더 정확도를 높일 수 있을 것이라고 기대해본다.
여러가지 어려움들에 대해서
데이터 받기
82-yoga 데이터셋의 크기가 상당히 큰 것도 있지만 생각보다 없는 데이터도 많고 응답이 없는 이미지에 낭비하는 시간이 꽤 되어서 생각보다 많은 시간을 허비했다. 아무래도 조금은 시간이 지난 데이터셋이고 또 (상업적으로 사용하지 않는 사람에게) 무료로 오픈된 데이터셋이다보니 여러가지 문제에 봉착할 수 밖에 없었다.

kaggle 데이터셋과 합치기
- 기존 데이터 셋과 이름이 일치하지 않는경우
이런 경우는 같은 자세이나 어떤 데이터셋에는 영어로만 이름이 나와있다거나 같은 자세를 강화한 자세를 정확하게 부를 것이냐 같은 레이블에 묶을 것이냐에 대한 해석이 다른 경우에 생겼다.
-
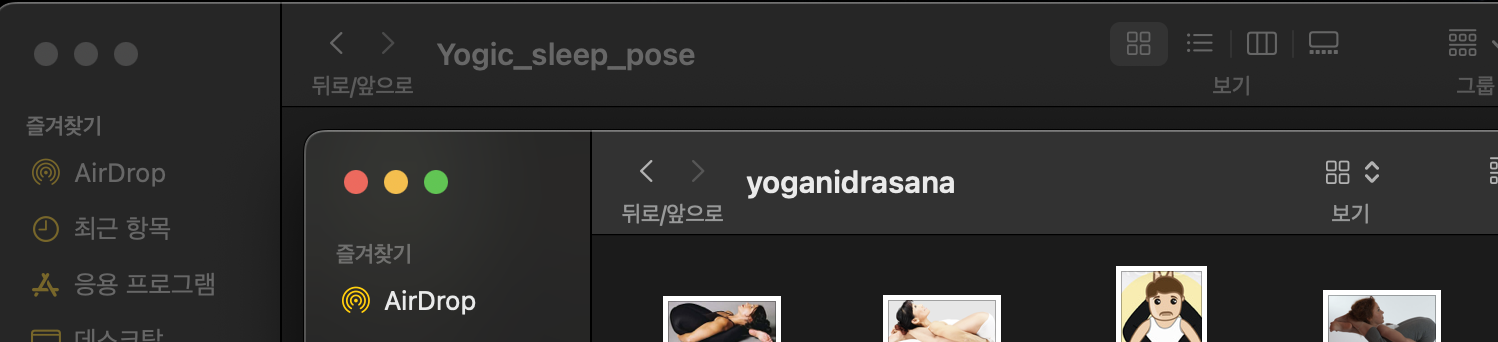
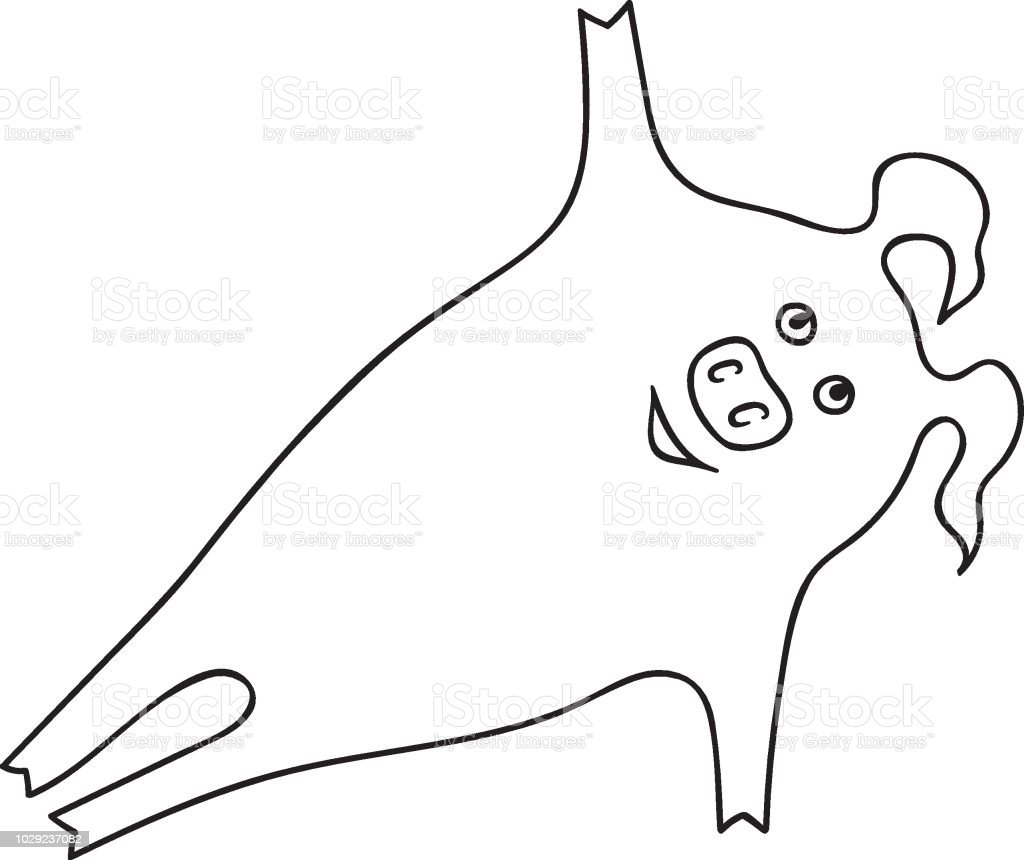
이미지의 신뢰도가 낮은 경우
아래와 같이 돼지 캐릭터가 자세를 취하고 있거나 사람의 실루엣이지만 사람이 아닌 캐릭터가 있는 경우에 신뢰도가 떨어진다고 판단하여 지웠다.

-
동작과 아무 상관이 없을때
아무래도 웹에서 긁어오는 사진들이다보니 요가와는 전혀 상관없는 (yoganada라는 이름만 상관있는) 사진이 나온다거나 웹페이지의 로고가 나온다거나 하는 경우가 꽤 있었다.

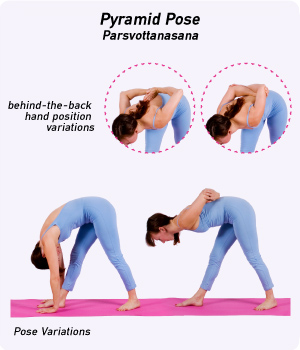
- 레이블이 사진에 나와 있는 경우
레이블이 이렇게 사진에 나와 있는 경우에는 강사님의 비유를 빌리자면 수능시험을 답안지를 외워서 치는 경우가 발생한다고 하셨다. 어떤 feature 값을 좇는게 train에 있는 값을 외워버려 과적합이 생기는 것을 방지하기 위해 이러한 사진들을 추려내 지웠다.
처음에는 세그맨테이션을 생각해서 이런 레이블 값이 있는 사진들을 남길까 고민했으나 일단 데이터셋은 꽤 커졌고 또 프로젝트 진행상황에 따라서 세그맨테이션을 predict하기위한 사진에만 적용할 수도 있기 때문에 지우는 것으로 수정하게 되었다.

-
다른 동작이 섞여있는 경우
cat 동작과 cow 동작은 다른 동작임에도 불구하고 cow 동작에 cat이 같이 묶여있거나 반대인 경우가 많았다.
아무래도 이어지는 동작이다 보니 그런 것 같다.

-
빈 사진 제거
-
각기다른 동작이 하나에 묶여 있는 사진 제거

-
자세에 대한 해석이 다른 경우
위 사진 두가지는 같은 레이블 값으로 묶여 있었다. 해석의 여지를 넓히면 같은 자세라고 볼 수도 있겠지만 정확도에 영향을 끼칠거라고 생각해 지웠다.

- 적절하지않은 사진들
이 부분이 나를 가장 곤경에 빠뜨렸다. 모델에 학습을 시키려고 돌릴 때 마다 이미지를 읽지 못하는 상황이 발생했고 오류메시지를 검색해 구글 여기저기를 돌아다니던 중 스택오버플로우에 있는 글을 발견해 코드를 참조하여 적절하지 않은 사진들을 솎아낼 수 있었다.
참조 : https://stackoverflow.com/questions/65438156/tensorflow-keras-error-unknown-image-file-format-one-of-jpeg-png-gif-bmp-re
여기 적힌 답변 중에 extension에 jpg라고 되어있다고 그 파일이 진짜jpg라고 할 수 없다. 어떻게 그것을 증명할거냐? 라는 문구가 나에게 큰 깨달음을 주었다. 주어진 데이터, 주어진 코드만 받아서 쓰는 개발자 보다 스스로 지평을 넓힐줄 아는 개발자가 되고싶다.
