
CVPR
1. CVPR이란??
- 국제 컴퓨터 비전 및 패턴인식 학술대회
- 국제전기전자공학회(IEEE), 국제컴퓨터비전재단(CVF)가 공동 주최하는 인공지능 대회
- 국제컴퓨터비전학술대회(ICCV), 유럽컴퓨터비전 학술대회(ECCV)같이 컴퓨터 비전분야의 3대 학회로 꼽힘
2. CVPR 2022
- 2022/06/19 ~ 2022/06/24에 미국 루이지애나주 뉴얼리언스에서 열림
링크
(봐볼만한 것들만 뽑아놓음, 자세한건 홈페이지 참조)
우승 논문작

3. 우리나라 논문
구두 발표는 학회에 제출된 논문중 4~5%에 해당되어야 기회가 주어짐
1) 네이버
네이버 클로바
: 총 17편(정규논문 14개, 워크숍논문 3개)
: 이중 구두발표 1편네이버 웹툰 등 계열사 전부 합치면 총 22개 제출
국내 기업 연구조직에서 2자리수 제출은 이번이 처음임
2) LG AI
- LG AI
: 정규논문 6편 워크숍 논문 1편
: 이중 구두발표 1편
3) 서울 대학교
- 서울대
: 논문 25편 채택
: 논문 표절사건
이 외에도 많은듯?
4. 챌린지
1) AI 업스케일링 분야(화질개선)
- 한화 시스템이 1등
2) BMTT분야
가상 데이터만을 활용해 모델의 성능을 높이는 것
비디오 데이터의 3D 렌더링, 게임 등에 존재하는 보행자의 모습을 담은 데이터로 실제 보행자를 추적하는 성능을 높이는 것이 주제였음
쎄트랙 아이가 1등
쎄트랙 아이: 한국의 인공위성 제조회사로 한화 에어로 스페이스가 최대 주주
3) MOT(Multi-Object Tracking) 분야
쎄트랙 아이가 1등



5. 그 외
1) 네이버 논문 관련
- 연속학습에서 학습방법 개선에 관한 연구
- 롱 테일 데이터 학습 관련 연구
연속학습
- 이미 학습이 완료된 모델을 가지고 추가로 학습시키는 것
- ex) MNIST데이터셋을 구분하는 모델을 만든 후, 수 체계를 16진법으로 바꾸고 싶어 A, B, C, D, E, F를 추가로 구분하도록 훈련시키는 것 같은 것
- 이 때, 기존의 성능보다 떨어지게 됨.
위의 경우 1~9까지의 구분 성능이 원래보다 떨어지는 현상이 발생
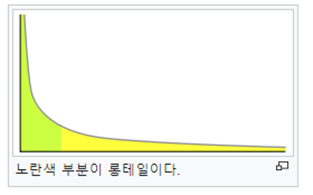
롱 테일 데이터
- 데이터는 보통 고르게 분포되어 있지 않기 때문에 발생 확률이 상대적으로 적은 부분은 학습에서 무시된다.
- (내가 이해한 바에 의하면) 카테고리 A, B, C, D, E가 있을 때, A, B, C, D는 10만개씩 데이터가 존재하지만 E에는 데이터가 1천개 정도 밖에 안되는 경우를 말하는 듯하다?
- 이 부분을 해결하는 것 또한 모델 향상에 도움이 될 것.
롱 테일 데이터에 대한 대표적인 예는 아마존에서는 잘안팔리는 책들에 대한 틈새시장을 공략해 매출을 20~30%정도 올린 경우가 있음

github로 이전 중... (https://uijinee.github.io/)