
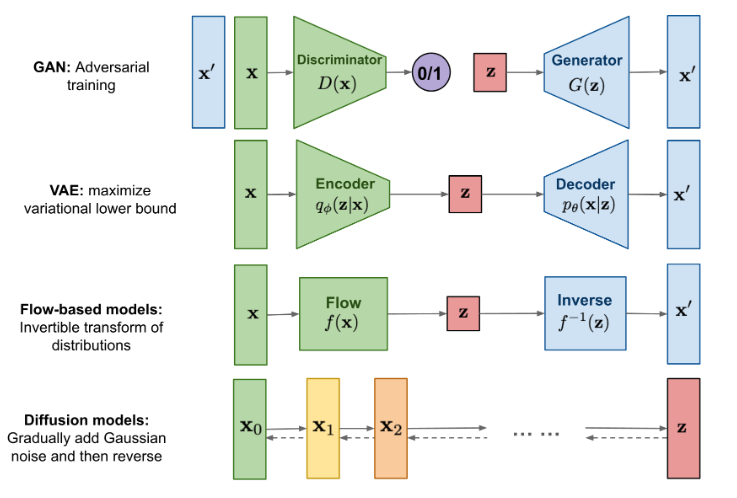
Novel AI
1. Novel AI란?
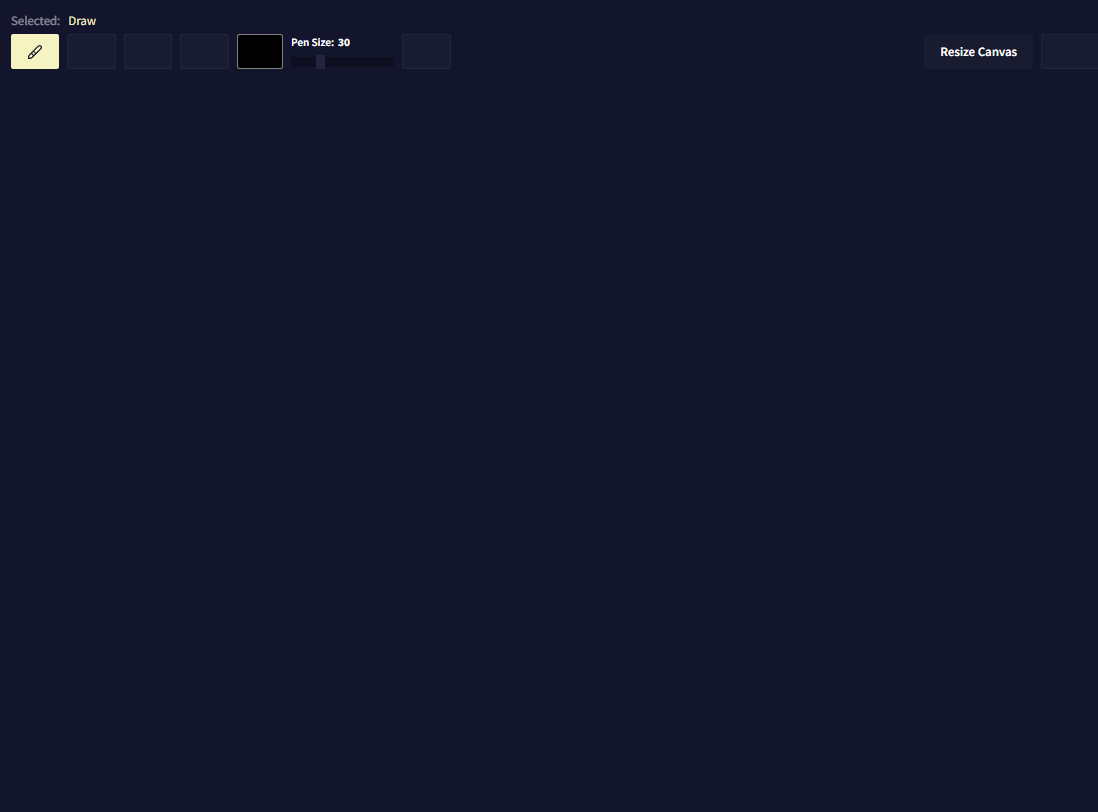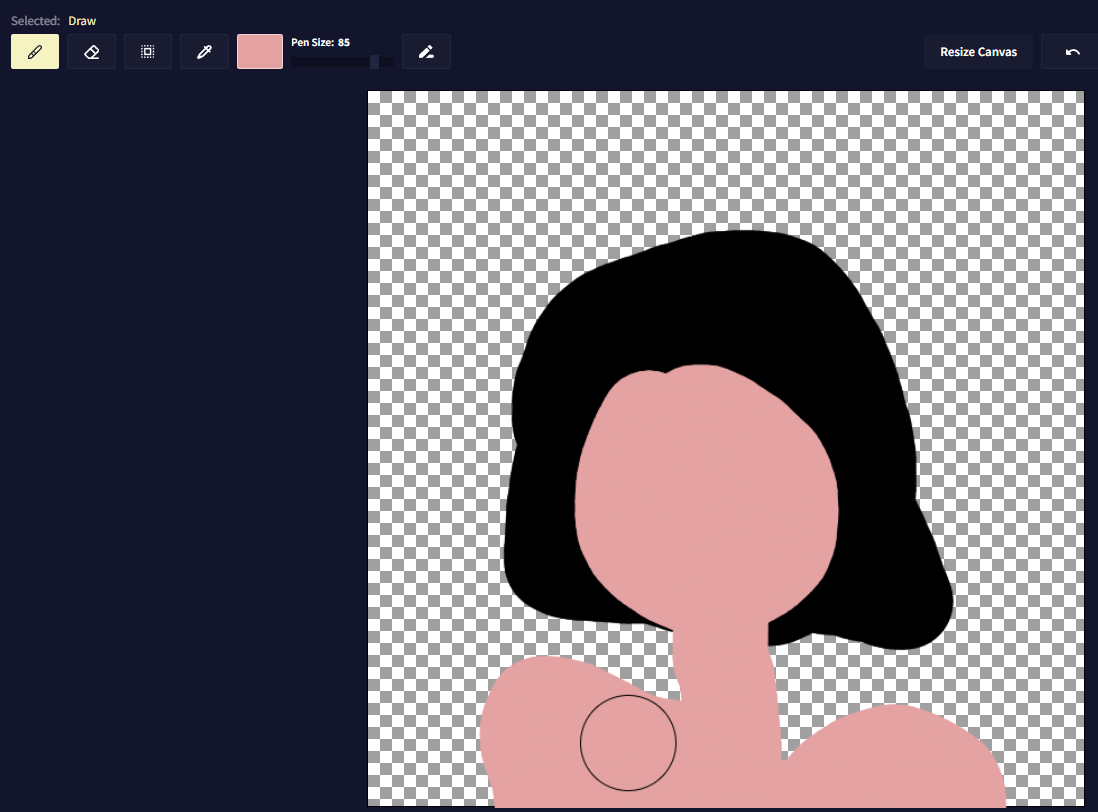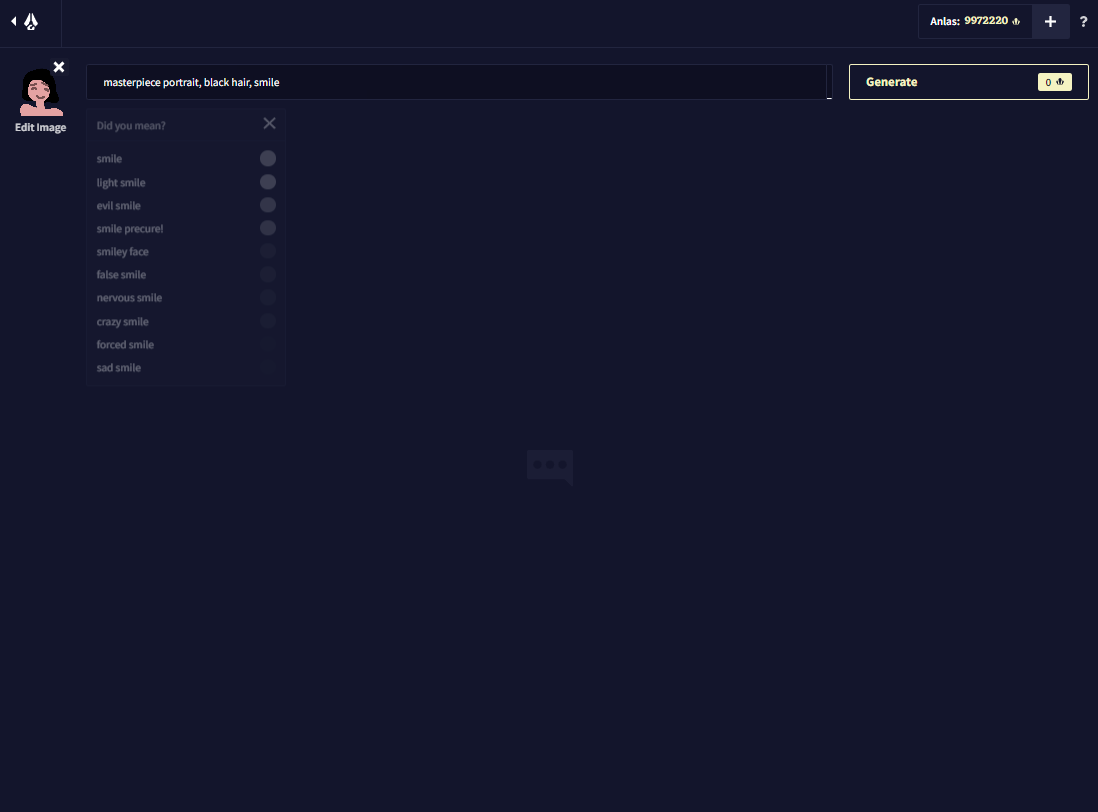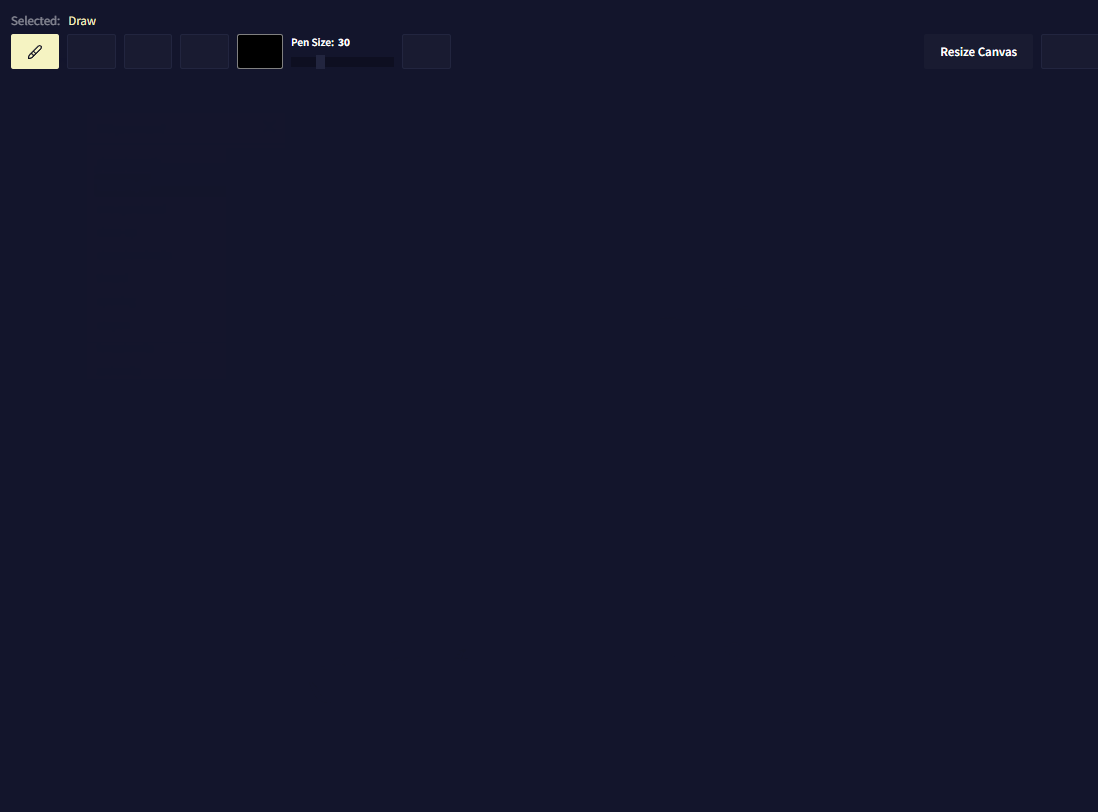
Text-To-Image합성을 위한 모델을 만들어 유료 구독 서비스
Stable Diffusion기반의 이미지 제너레이터를 사용하였다.
기존의 Style GAN기반의 API보다 훨씬 성능이 좋다.
2. 이미지 생성 모델
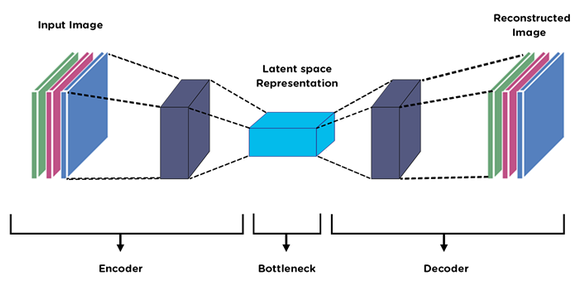
1) AutoEncoder
성능
학습속도가 빠르지만 이미지 퀄리티는 좋지 않다.
2) GAN
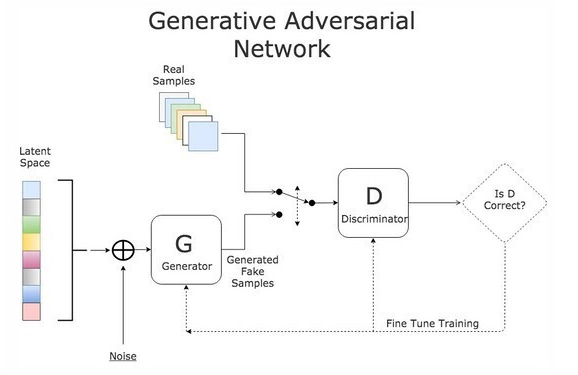
성능
퀄리티는 좋지만 다양한 결과를 만들 수 없다.
DCGAN
일반적인 GAN은 이미지 데이터에 대해 그렇게 좋은 성능을 내지는 못하였다.
DCGAN은 이를 보완하기 위해 GAN에서 Convolution Layer를 활용해 이미지를 생성하도록 해주도록 설계하였다.
ProGAN/PGGAN
전체 Layer를 구성한 후에 학습을 시키는 것이 아니라, 학습 과정에서 Layer를 추가해 나가도록 설계한 논문
즉, 예를들어, 한가지 Layer로 구성되도록 만들어 학습시키고, 이것을 활용해 그 다음에는 한 층을 더 쌓아 두개의 Layer로 구성, .... 이러한 과정을 반복시켜 학습시키게 된다.
위의 과정과 같이 점진적인 과정으로 인해 안정적으로 고해상도의 이미지를 생성할 수 있게 되었다.
(층이 늘어날수록 점진적으로 해상도가 증가된다.)
Style GAN
PGGAN은 이미지의 특징 제어가 어려웠다. 즉, 안경이 없는 이미지에서 안경을 쓰도록 바꾸는 것과 같은 것이 불가능 했다.
Style GAN은 PGGAN의 점진적으로 Layer를 붙여 나가는 방식을 채택하였다.
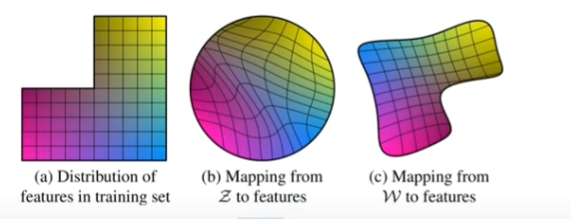
뿐만아니라, 원래 이미지 z를 그대로 넣는 것이 아니라 이것을 Mapping NetWork에 넣어 w벡터로 만든 후 학습시키도록 하자는 방법을 제안하였다.
내생각
- 위의 그림에서 a의 가로축이 머리길이, 세로축이 남/여라고 할 때, 머리가 긴 남자의 데이터는 존재하지 않는 것을 확인할 수 있다.
- 즉, a의 형태를 가지는 z벡터를 그대로 학습시킬 경우 b로 변형되어 입력되기 때문에, 이미지의 특징들이 많이 변형되는 것을 확인할 수 있다.
- 이를 막기위해 별도의 네트워크를 활용해 c로 변형시킨 후 모델에 입력하자는 방법인 것 같다.
(추가 공부: WGAN-GP Loss)
3) Diffusion

성능
퀄리티도 좋고 다양성도 좋다. 하지만 학습 시간이 너무 오래걸린다.
Idea
- 학습용 사진을 준비한다.
- 그 사진에 Noise를 아주 조금 추가한다. (Random한 색을 무작위로 칠하는 작업)
- 위의 과정을 1000번정도 반복하여 이미지를 없애고 Pure한 Noise를 생성한다.
- 딥러닝을 활용해 위에서 생성한 Noise를 원래 이미지로 되돌릴 수 있도록 학습시킨다.
(대표적인 Diffusion Model의 예로는 DALLE가 있다.)
Latent Diffusion Model
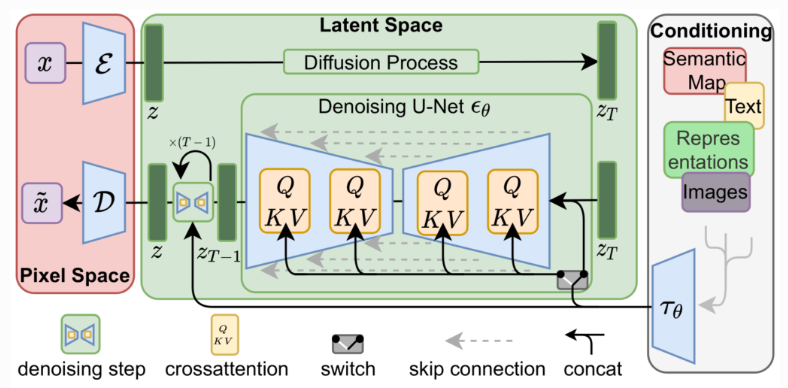
- 학습용 사진을 준비한다.
- 해당 사진을 Latent Space라는 것으로 Encoding한다.
- 이 Encoding Vector를 Difussion모델에 넣어 학습시킨다.
(이 경우 Diffusion모델보다 학습 속도가 월등히 좋아졌다고 한다.)
Stable Diffusion
Stability AI라는 회사에서 Latent Diffusion Model을 활용해 LAION이라는 무료 오픈소스 고퀄리티 이미지 데이터셋을 학습시켜 매우 좋은 퀄리티의 이미지 생성 AI를 만들었다.
그리고 이 학습 완료된 AI모델을 Stable Diffusion이라는 이름의 오픈소스로 공개하였다.
3. 이슈
1) 해킹
2022/10/07 익명의 해커가 제로데이 공격을 통해 해킹하여 Novel Ai의 소스코드가 유출됨
2) 학습 대상
이 모델을 학습시키기 위해 사용한 데이터를 단부루라는 사이트에서 가져왔는데, 이 단부루에 있는 대부분의 이미지들은 원작자의 허가를 받지 않은 불펌 이미지이다.
뿐만 아니라 19금 이미지들도 다수 존재하기 때문에 이 점이 악용될 가능성이 크다.

오 정말 흥미로운 내용이네요!! 잘 읽다 갑니다^^