함수
--함수란?--
데이터를 가공함에 있어서, 특정 동작을 하는 코드를 미리 만들어 놓고 재사용할 수 있도록 도와주고 가독성 또한 높여주는 방법입니다.
--정의와 선언--
우리가 만들 함수에는 두가지 요소가 있습니다.
-
함수의 프로토타입
모양:
리턴값의자료형 함수이름(사용할 매개변수);
ex )int findpath(float clock, int x, int y);설명: 함수의 원형이라고 하기도 하는데요, 함수를 정의하기에 앞서 함수를 호출하기 위해 필요한 정보를 담은 코드를 의미합니다.
-
내용
모양:
{ 동작과정 }설명: 함수가 매개변수를 통해 외부로부터 데이터를 받아 어떻게 처리하고 결과를 내보낼 것인지에 대한 코드를 적으면 됩니다.
1) 정의
위에서 알아보았듯이 함수의 구조는 다음과 같습니다.
int name(int parameter) {
int a = parameter;
return parameter;
}
// int부분에는 리턴값의 자료형, 즉 함수를 호출한 곳으로 돌려줄 값의 자료형을 적어야 합니다.
// name부분에는 함수의 이름을 적습니다. 함수의 기능에 맞게 지어줍시다.
// int parameter부분에는 매개변수를 적어야합니다. 외부로부터 어떤 형태의 데이터를 받아올 것이고,
그 개수가 들어나도록 적어줍시다.( ,(콤마)로 구분)
// { }중괄호 안의 부분에는 함수의 내용을 적어야합니다. 매개변수를받아 리턴값을 내보내기까지의 과정을 적어주시면 되겠습니다.
// return 부분에는 함수가 다 실행되고 외부에 돌려줄 값을 적어 넣습니다.
즉, 컴퓨터는 return키워드를 만나게 되면 뒤에 남은 내용이 있다고 하더라도 함수를 종료합니다.여기까지 함수를 어떻게 만드는지 알아보았고 이제 정의하는 방법에 대해 알아봅시다.
컴파일러는 프로그래밍 코드를 위에서부터 아래로, 왼쪽에서부터 오른쪽으로 차례대로 읽게 됩니다. 이때 함수가 실행되기 전에, 함수의 존재를 알아야할 것입니다. 이에따라 우리는 두가지 정의방법을 사용할 수 있습니다.
내용 정의를 프로토타입과 동시에하는 방법
#include <iostream>
using namespace std;
void printMessage() {
cout << "Hello World" << endl;
}
int main()
{
printMessage();
}- 이와같은 방법은 함수가 길어지면 가독성이 매우 떨어집니다.
프로토타입을 먼저 설정하고 정의를 뒤쪽에서하는 방법.
#include <iostream>
using namespace std;
void printMessage(); //프로토 타입에는 반드시 세미콜론을 붙여줘야합니다.
int main()
{
printMessage();
}
void printMessage() {
cout << "Hello World" << endl;
}-
컴파일러에게 미리 뒤쪽에 함수의 내용에 대한 정의가 존재한다고 알려준다는 식으로 이해하면 좋을것 같습니다.
-
이렇게 작성하면 main함수가 아무리 길어져도 함수를 이해하는데 훨씬 수월할 것입니다.
2) 호출
자료형은 데이터를 저장하기 위한 방법이었으므로 정의와 선언과정을 거쳤지만, 함수는 데이터를받아 가공하기 위한 방법이므로 정의와 호출과정을 거치게 됩니다.
우선 위의 방법으로 함수가 정상적으로 잘 정의되어 있다고 가정해 봅시다.
함수이름( 매개변수에 넣어줄 값 );그러면 이렇게 함수이름과 중괄호, 그리고 그 안에 매개변수에 넣어줄 값을 차례대로 넣어주면 해당 함수를 "호출"하여 잘 실행하고 그 결과를 돌려주게 됩니다.
3) 원리
여태까지는 글로 설명했지만 더이상 말로표현하기 힘들것 같아서, IPAD로 그림을그려 보았습니다.ㅋㅋㅋㅋ
(자료구조 수업을 들으면서 이해한 내용을 바탕으로 써 보았습니다.)
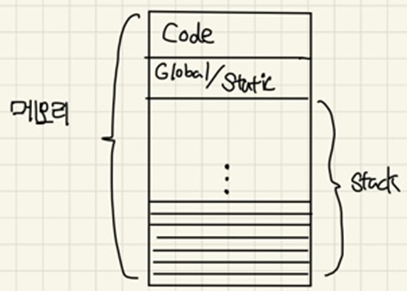
우선, 우리가 프로그램을 실행하면 그림처럼 메모리가 할당되게 됩니다. 우선 맨 위쪽에는 우리가 짠 코드들이 위치하게 되겠고 그 밑에는 Global변수, Static변수에 대한 메모리가 생성되게 되겠죠?
밑의 Stack은 우리가 프로그램을 실행하고 그 과정에서 실제로 사용하게 될 공간입니다. 이 Stack은 아래에서부터 위쪽으로 채워진다는 특징이 있습니다.
자 이제 함수가 실행될 때의 메모리를 보기위해 Stack을 자세히 들여다 봅시다.
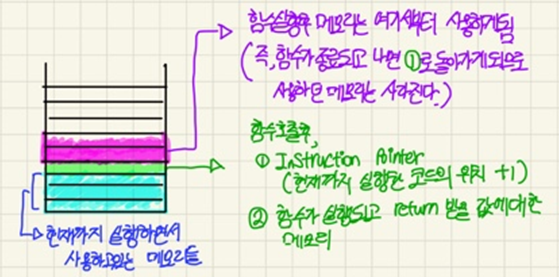
네, 그려놓고보니까 뭔가 난잡..하네요 ㅋㅋㅋ
Stack은 밑에서부터 위로 메모리가 사용된다고 했죠? 밑의 파란글씨는 main()함수에서 함수를 호출하기 전까지 사용하고 있는 메모리들입니다.
그러다가 함수이름()를 만나서 함수를 호출하게 되면
우선 현재까지 실행한 코드가 어디까지인지 그 위치를 저장합니다. 정확히는 함수가 종료되고 리턴값을 받은 후에 실행할 위치가 저장됩니다. 이 공간 또한 포인터의 형식으로 확보가 되겠죠
그리고 그 위에 return값을 받아줄 공간을 확보합니다. 우리가 함수를 정의할 때 Prototype에 return값의 형식을 미리 알려주는것이 이 이유때문입니다.
그리고 마지막으로 그 위의 메모리부터는 함수호출뒤 그 함수실행 중에 사용하는 메모리들이 차례로 쌓이게되고, 마지막으로 return값을 구한뒤 초록색 부분에서 우리가 미리 정해놓은 공간에 복사하여 전달해주게 됩니다.
그리고 그 return받은곳의 위쪽 메모리부터 다시 사용하게 되고, 함수에서 사용하던 메모리들은 덮어씌워 지겠죠.
--사용방법--
1) 매개변수 설정
-
1-1) 전달방법
void sum (매개변수){ ~ }
이와같은 함수가 정의되어 있다고 생각해 봅시다. 매개변수가 다음과 같은 형식일 때 어떻게 작동할까요?-
일반변수 전달:
(int a, int b)-
이 변수(a, b)는 함수와 같은 공간에 생성되어 있습니다.
(sum(c, d)와 같은 방식으로 값을 넘겨주었을 때,
c에 있는값을a에,d에 있는 값을b에 복사하여 넣어주게 됩니다.) -
즉, 함수의 안에서
a=3과 같이 다룰경우 그 값은 함수와 같이 생성된a의 값이기 때문에 원본을 변경하지 않습니다.
-
-
포인터 전달:
(int* a, int* b)-
이 포인터(a, b)는 함수와 같은 공간에 생성되어 있습니다.
(이 포인터에sum(&c, &d)와 같은 방식으로 값을 넘겨주었을 때
c의 주소값을 a에,d의 주소값을 b에 넘겨주게 됩니다) -
즉, 함수의 안에서
(*a)=3같이 다룰경우 그 값은 "주소에 있는 값"이 되므로 원본을 변경할 수 있습니다.
-
-
레퍼런스 전달:
(int& a, int& b)-
레퍼런스는 해당 변수의 별명을 지정하는 것으로 생성시에 별도의 메모리 공간을 차지하지 않습니다.
-
하지만, 함수안에서 그 외부의 값을 부를 "또다른 이름"을 지정하는 것이기 때문에 그 "전달받은 변수 자체"를 변경할수 있습니다.
-
-
배열 전달:
(int a[], int b[][10])-
int a[]와 같은 전달은 실제로int* a와 같이 동작합니다. -
1차원 배열의 경우 그 길이를 설정해 줄 필요가 없습니다.
(그 이유: 어차피 포인터처럼 역할하기 때문에 그 길이에 대한 정보는 저장하지 않아서) -
2차원 이상의 배열의 경우, 맨 첫번째 인자를 제외한 나머지의 값은 설정해 주어야 합니다.
(그 이유: 2차원 이상의 배열이라도 메모리에는 1차원처럼 저장이 된다. 따라서 그 부가적인 정보는 따로 기억해줄 필요가 있다.)
-
-
구조체 전달:
(point& p1, point& p2)-
원본을 변경하고자 할 때에는 &(레퍼런스)를 사용하자.
-
(point p1)과 같이 일반적으로 설정할 경우 위에서 계속 설명했던 이유로 인해p1은 외부값에 대한 단순 사본을 가지고 있게 됩니다.
-
-
주의사항: 포인터나 레퍼런스같이 전달할 경우 원래 데이터의 훼손 가능성이 존재한다.
-> 이 문제를 해결하기 위해 만약 원래 데이터를 변경하지 않을 목적일 경우 const를 사용하여 훼손을 방지할 수 있다.
(const char arr[]),(const int* a),(const int& b)
왜일까?
배열은 왜 일반 변수처럼 사본을 받을수 없을까요? 바로 성능문제가 있을수 있기 때문이라네요. 배열는 다른 변수들에 비해 차지하는 공간이 매우 크기때문에 이 배열의 사본을 만들경우 공간적으로나 시간적으로나 이점이 별로 다고 합니다.
-
1-2) Default값(기본값) 설정
-
디폴트인자란?
- 우리가 함수를 호출할 때 매개변수에 따로 전달해주지 않았을 때 기본적으로 선택하는 값을 의미합니다.
-
사용방법
- 사용방법은 너무 간단하므로 예시로 대체하겠습니다.
void DefaultArgs(int a, int b=2, int c=3); int main() { ~ } void DefaultArgs(int a, int b=2, int c=3){ ~ }
- 사용방법은 너무 간단하므로 예시로 대체하겠습니다.
-
주의점
-
혼동을 피하기 위해 디폴트 인자는 위의 예시처럼 오른쪽에서부터 채워나가야 합니다.
-
중간에 비워놓거나 오른쪽에 비어 있는곳이 있음에도 왼쪽에 디폴트 인자를 주는것은 불가능 합니다.
-
-
-
1-3) Overloading(오버로딩)
-
오버로딩이란?
-
동일한이름을 가진 함수를 단순히 매개변수(인자)의 종류와 개수만 다르게하여 서로 다른 기능을 하도록 만드는 것을 의미합니다.
(함수의 시그니쳐(Signature), 시그니쳐란 함수의 Prototype에서 매개변수 부분을 의미하는 또 다른 단어입니다.)
-
-
왜 사용해야 할까요?
-
사실 이 기능은 C언어에는 존재하지 않는 기능이었습니다. 하지만 비슷한 일을 하지만, 이름을 다르게 지어야 한다는 불편함은 생각보다 많습니다.
(간단하게 예를들어 두 수를 곱해주는 함수를 만들었다고 가정해 봅시다,
이때 매개변수를 int, 즉 정수로 정하였다면 우리는 이 함수를 사용할 때 정수만 전달할 수 있을것입니다.
하지만 Overloading을 사용하면 같은 이름의 함수여도 실수를 받으면 실수끼리 곱하도록 만들수 있겠죠?)
-
-
사용 방법
-
사실 오버로딩또한 사용방법이 너무 간단하므로 예시로 대체하겠습니다.
int max(int a, int b); float max(float a, float b); int main() { max(2,3); max(5.1, 3.2); } int max(int a, int b) { ~ } float max(float a, float b) { ~ }
-
-
원리
-
컴퓨터, 즉 컴파일러가 이 파일을 실행할 때 함수의 이름만 보는것이 아니라 매개변수까지보고 결정해 줍니다.
-
하지만 자동형변환과 같은 요소에 의해 컴퓨터가 어떤 매개변수를 가지는 함수를 호출해야할지 애매한 부분이 있을 수 있습니다.
(이 경우 다음과 같은 순서로 우선순위를 두고 판단합니다.)
1. 정확히 일치한가
2. 승진에 의한 자동 형변환인가
3. 표준 형변환에 의한 자동 형변환인가
4. 사용자에 의한 형변환인가
+ 주의: 디폴트인자로 인해 판단이 불가능 하도록 정의하는것은 불가능 합니다.
-
-
Inline Function
인라인 함수는 함수를 호출하는대신 함수의 내용을 그대로 옮겨 놓는 함수를 의미합니다.
보통의 함수의 경우 함수를 호출하면 그 return값의 공간 마련, 매개변수에 값 복사, ... 등등 많은 일을 해야합니다.
반면에 인라인으로 선언된 함수의 경우 함수를 호출하는 것이 아니라 그 함수의 내용을 그대로 사용하는 자리에 복사&붙여넣기 하게 됩니다.
즉, 호출하는것에 비해 불필요한 작업을 줄여 시간을 단축할 수 있게 됩니다.
-
사용 방법: 일반 함수 앞에
inline키워드를 추가합니다.inline void printx() { cout << x << endl; } -
단점: 위 글만 읽어보면 인라인 함수는 장점만 있는것 같은데 그렇지 않습니다. 인라인 함수로 함수들을 선언하게 된다면, 그 함수를 복사 붙여넣기 해야 하므로 이를 가져오는곳의 함수의 크기가 어마어마하게 커지게 될 것입니다.
즉, 짧고 간단한 함수들은 괜찮지만 긴 함수들을 사용할 때에는 오히려 단점이 더 분명하다는 것입니다.
--주의점--
1) 재귀함수
2)
--활용--
1) 재귀함수
- 재귀함수란?
- 함수안에서 자기자신을 다시 호출하는 함수를 의미합니다.
-
재귀함수는 보통의 함수처럼 작동한다고 보시면 됩니다.
-
주의점
-
별도의 탈출방법을 마련해두지 않으면 자기 자신을 계속 호출하는 무한루프에 빠질 수 있습니다.
-
재귀함수는 대부분 메모리의 공간을 많이 차지하게 되기 때문에 좋은 방법은 아닐 수 있습니다.
-
2) 함수에 대한 포인터
- 재미있게도 포인터는 함수또한 가리킬 수 있다고 합니다.
(포인터부분 참고)
