1. Sementic Segmentation(2)
앞서 배웠던 Sementic Segmentation Model들은 Decoder의 구조를 효율적으로 구성하여 모델의 성능을 올렸었다.
여기서는 Receptive Field를 키우는 방법을 통해 모델의 성능을 올린 방법을 알아보자.
(유의점) DeepLab

DeepLab을 공부할 때 각 version별로 위의 밑줄친 부분들을 유의하여 공부하자
1. DeepLab V1
1) Dilated Convolution
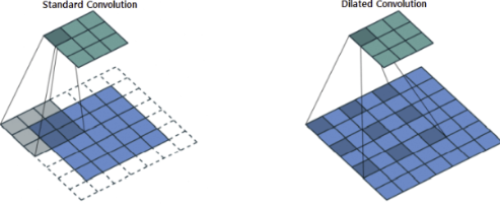
Receptive Field를 키우는 방법는 대표적으로 다음의 두개가 존재한다.
1. Convolution + MaxPooling
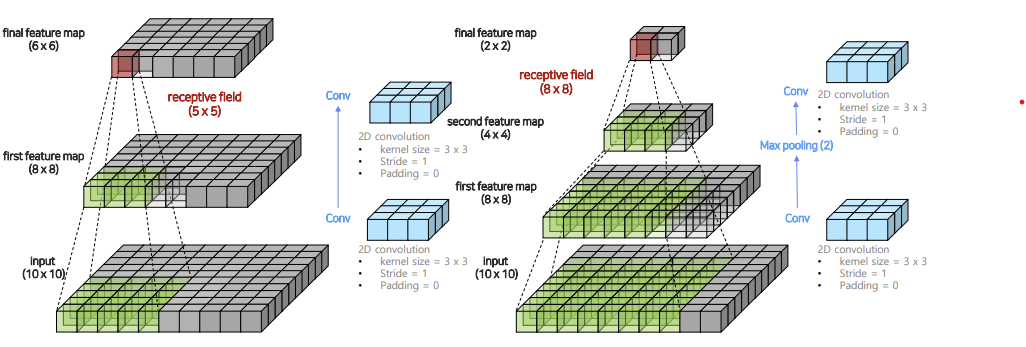
- Convolution -> Convolution 순서로 적용하는 방법
- Convolution -> MaxPooling -> Convolution 순서로 적용하는 방법
위의 그림을 보면 알 수 있듯이 어떤 Feature Map에 대해 1번 방법보다, 2번 방법이 훨씬 더 큰 Receptive Field를 갖게 된다는 것을 볼 수 있다.
문제점
: Receptive Field를 매우 키울 수 있지만, image의 크기가 너무 많이 줄어 UpSampling을 할 때 Low Feature Resolution을 갖게 된다.
2. Dilated(Atrous) Convolution
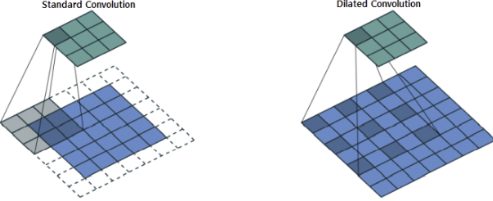
Max Pooing을 이용하는 방법의 단점을 해결한 방법으로, dilated를 이용해 image의 크기를 적게 줄이면서도, Receptive Field를 효과적으로 키운 방법이다.
DeepLab V1에서는 이 Dilated Convolution을 이용하여 기존 모델들의 단점을 해결하고자 하였다.
3. DilatedNet
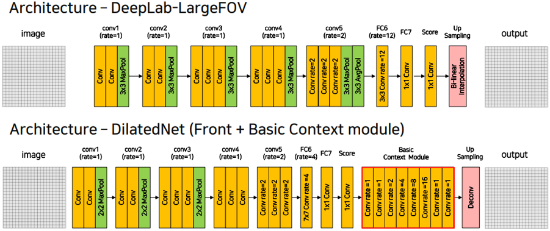
Dilated Convolution을 DeepLab V1보다 조금 더 잘 활용하여 구성한 Architecture이다.
위의 그림을 참고해 보면 알 수 있지만, Dilate비율이 조금 더 다양한 것을 알 있다.특히, 마지막에 하나의 Feature Map에 대해 여러 Dilate비율을 가지고 예측한 후 합치는 Basic Context Module이 가장 큰 특징이다.
2) 모델 구조

1. Conv1, Conv2, Conv3
def Conv(in_ch, out_ch, kernel_size, rate): return nn.Sequential( nn.Conv2d(in_ch, out_ch, kernel_size, stride=1 padding=rate, dilation=rate), nn.ReLU()) ####################################################### def Conv1(in_ch, out_ch, kernel_size, rate): return nn.Sequential( Conv(3, 64, 3, 1), Conv(64, 64, 3, 1), # Conv(64, 128, 3, 1), nn.MaxPool2d(3, stride=2, padding=1))Conv1, Conv2, Conv3에서는 모두 기존의 2x2 MaxPooling을 사용하지 않고 3x3에 Stride와 Padding을 모두 2로 준 것을 확인할 수 있다.
즉, 이미지는 로 줄이면서 Receptive Field를 더 키워 주게 된다.
(참고: Conv4에서는 3x3 MaxPooling을 사용하되, stride와 Padding을 모두 1로 주어 이미지의 크기를 줄이지 않는다.)
2. Conv5
def Conv5(in_ch, out_ch, kernel_size, rate): return nn.Sequential( Conv(512, 512, 3, rate=2), Conv(512, 512, 3, rate=2), Conv(512, 512, 3, rate=2), nn.MaxPool2d(3, stride=1, padding=1), nn.AvgPool2d(3, stride=1, padding=1))Conv5에서는 dilation을 2로 주어 기존의 방법보다 Receptive Field를 훨씬 키워준다.
3. Bilinear Interpolation
from torch.nn import functional as F def UpSampling(feature_map, upSampling_rate): return F.interpolate( feature_map, size=(feature_map.size(0) * upSampling_rate, feature_map.size(1) * upSampling_rate mode='bilinear', align_corners=True)이전에 배웠던 Sementic Segmentation방법들은 Transposed Convolution과 Decoder를 통해 UpSampling을 구현하였었다.
하지만 DeepLab V1에서는 단순히 보간법을 통해 UpSampling을 수행하는 것 같다.
3) Dense CRF

DeepLab V1에서는 Bi-linear Interpolation으로만 UpSampling을 수행하기 때문에 픽셀 단위의 정교한 Segmentation이 불가능했었다.
따라서 DeepLab V1에서는 이 문제를 해결하기 위해 Dense CRF라는 후처리 기법을 도입하였다.
1. 입력과 출력

Dense CRF의 역할은 다음과 같이 정의 할 수 있다.
- 입력
- 이미지
- 각 픽셀에 대한 클래스 확률 예측 값
- 출력
- 조금 더 정교한 Segmentation 결과물
(참고: CRF의 원리)
-이미지의 색상이 유사한 픽셀이 가까이 위치하면 같은 범주에 속함
-이미지의 색상이 유사해도 픽셀 사이의 거리가 멀다면 다른 범주에 속함
위의 정의를 통해 각 픽셀의 확률값을 조절하게 됨
2. 진행과정
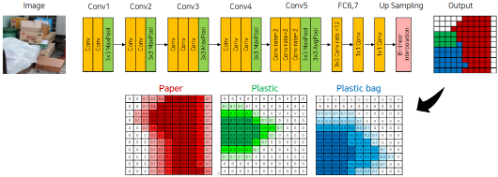
(1) Segmentation Model을 활용해 각 픽셀별 클래스 예측값을 구한다.
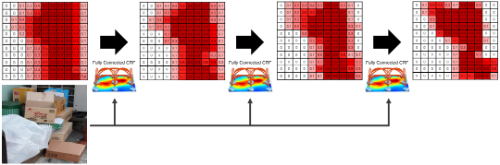
(2) 1에서 구한 확률값과 이미지를 CRF에 입력하고, 해당 과정을 여러번 반복 수행한다.
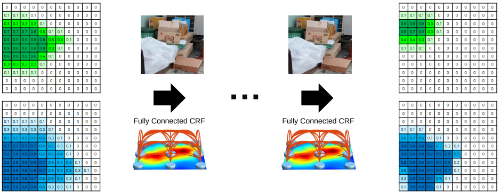
(3) 다른 카테고리들에 대해서도 같은 과정을 수행한다.

(4) 위에서 얻은 확률값에 대해 각 픽셀별로 가장 높은 확률을 갖는 카테고리를 선택해 최종 결과를 만들어 낸다.
2. DeepLab V2
1) 주요 특징
1. BackBone 변경
DeepLab V1에서는 VGG를 BackBone으로 사용하였었지만 DeepLab V2로 넘어오면서 BackBone을 ResNet-101로 변경하였다.
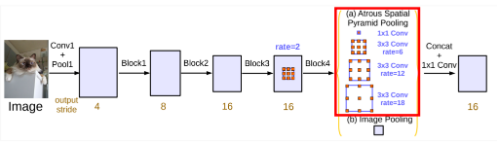
2. Atrous Spatial Pyramid Pooling
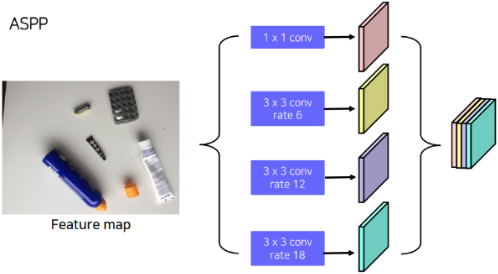
ASPP는 이전 BackBone에서 받아온 Feature Map을 Atrous Convolution을 활용해 다양한 Receptive Field을 가지도록 Feature Map들을 계산하고, 이 Feature Map을 Concat하도록 하는 Layer를 의미한다.
이때 서로 다른 dilation rate와 kernel size를 사용하기 때문에 각각 다른 크기의 Feature Map을 생성하게 되는데, 보통 해당 Feature Map들에 Bi-Linear Interpolate를 통한 Upsampling을 적용해 크기를 맞춰 준 후에 Concatenate해주게 된다.
2) 모델 구조
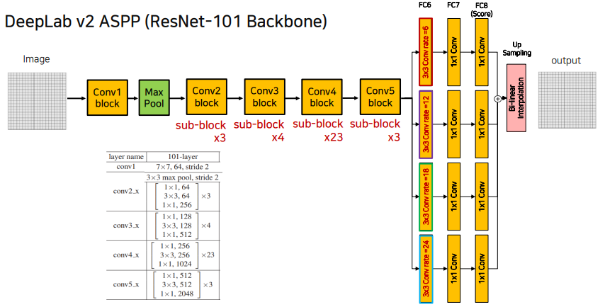
DeepLab V2는 위의 두 변경사항을 적용하여 위의 그림과 같은 모델 구조를 갖게 된다.
3. PSPNet
1) 도입배경
PSPNet에서는 기존 모델의 문제점과 원인을 다음과 같이 정의하였다.
1. Mismatched Relationship
- 문제점
: 기존의 FCN모델들은 이미지에서 맥락을 파악하지 못해 위의 그림과 같이 호수 위에 차가 있다고 판별하는 경우가 있다.
- 해결 방안
: 주변 정보를 통해 판별할 수 있도록 해야한다.
(=Average Pooling 사용)
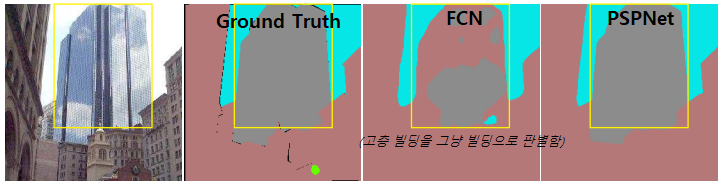
2. Confusion Categories
- 문제점
: 기존의 FCN모델들에서는 위 그림의 빌딩과 고층 빌딩과 같이 외관이 비슷한 클래스들의 경우 혼동하는 경향이 있다.
- 해결방안
: Category간의 관계를 파악한 후에 예측을 수행해야 한다.
(=Average Pooling 사용)
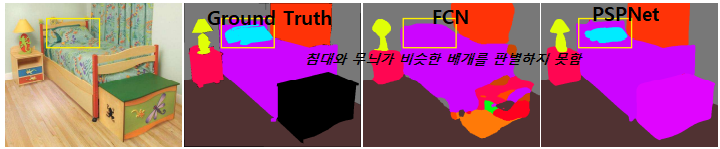
3. Inconspicuous Classes
- 문제점
: 기존의 FCN모델들은 작은 물체나 비슷한 무늬를 가진 물체들을 판별하는데에 한계가 존재한다.
- 해결 방안
: Global Contextual Information을 통해 파악해야 한다.
(=Average Pooling 사용)
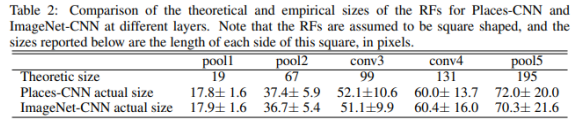
4. 실제와는 다른 Receptive Field
- 문제점
: 선행 연구에 따르면 FCN에서 사용하는 MaxPooing방식은 이론상의 Receptive Field와 실제 Receptive Field는 차이가 존재한다고 한다.
(실제로는 더 작아짐)
- 해결방안
: Average Pooling

2) Average Pooling
1. Convolution VS Global Average Pooling
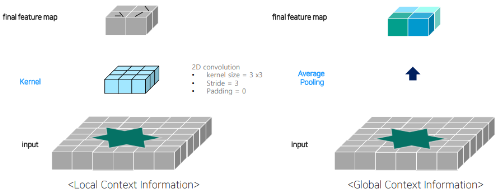
- Convolution
: Local한 Context(문맥) Information을 파악하는데 도움이 된다
- Average Pooling
: Global한 Context(문맥) Information을 파악하는데 도움이 된다.
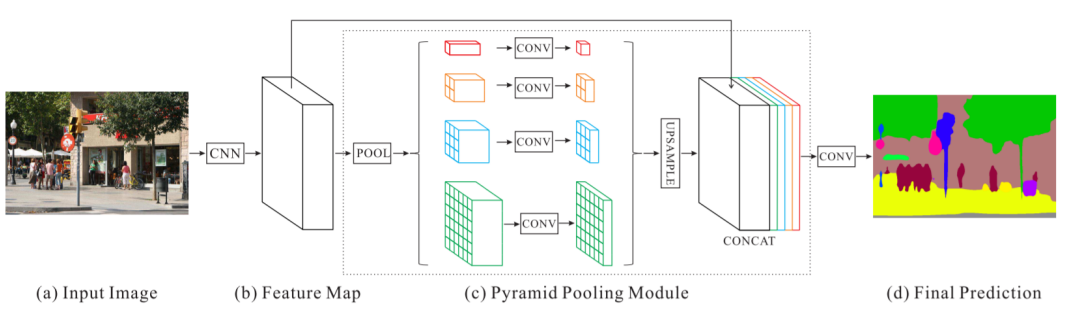
2. Pyramid Pooling Module
위에서 알수 있는 Average Pooling의 장점을 활용하기 위해 PSPNet에서는 위의 그림과 같이 여러 크기의 PoolingSize를 사용한다.
즉, Average Pooling을 통해
1x1xC,2x2xC,3x3xC,6x6xC크기의 FeatureMap을 만든 다음,1x1 Convolution을 통해 Channel을 1로 맞춰주고, 각각의 FeatureMap을 Upsampling한 후에 Concatenate해준다.
4. DeepLab V3
1) 주요 특징
1. ASPP비율의 변경
기존의 DeepLab V2에서는 6, 12, 18, 24의 Dilate Convolution비율을 사용했다면 DeepLab V3에서는 6, 12, 18 3개의 Dilate Convolution만을 선택하고 여기에 1x1 Convolution만을 추가하여 사용하게 된다.
2. Global Average Pooling추가
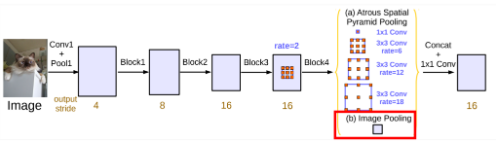
위의 PSPNet의 결과를 참고하여 DeepLab V3에서는 ASPP와 더불어 Global Average Pooling을 함께 적용하게 된다.
3. Sum이 아닌 Concatenate
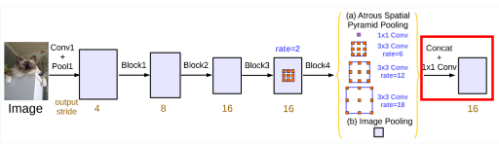
DeepLab V2에서는 ASPP의 결과를 단순 Summation을 통해 더해주었었는데, DeepLab V3에서는 Concatenate해주고 있는 것을 확인할 수 있다.
이때, Global Average Pooling의 결과는 1x1이기 때문에 ASPP의 결과랑 Concatenate를 하는데에 문제가 발생한다.
따라서 이 Pooling의 결과에 Bi-Linear Interpolate를 적용하여 Concatenate해준다.
5. DeepLab V3+
1) 주요 특징
1. BackBone 변경
DeepLab V3와 V2에서 BackBone으로 사용하던 ResNet-101을 (살짝 수정된)Xception으로 변경하였다.
2. Encoder-Decoder구조
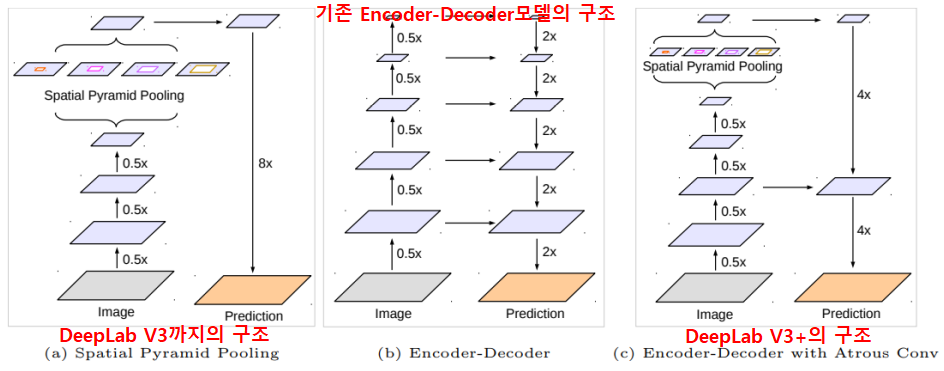
위에서 볼 수 있듯이 DeepLab V3까지는 따로 Decoder구조를 사용하고 있지 않았다.
하지만 이전 페이지에서 보았듯이 Decoder를 통해 손실된 정보를 복원하는 방법이 더 효과적이었기 때문에 DeepLab V3+에서는 Encoder-Decoder의 구조를 채택하여 사용한다.
2) Atrous Separable Convolution
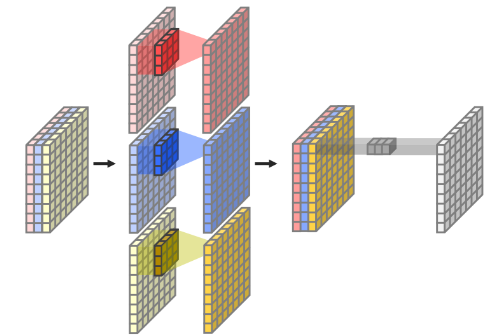
Sementic Segmentation은 Task 특성상 입력 해상도가 워낙 크기 때문에, 연산이 매우 오래 걸리게 된다.
이러한 문제를 해결하기 위해서 나온 방법이 아래에 소개된 Astrous Separable Convolution이고 Xception은 이를 이용해 만든 Architecture이다.
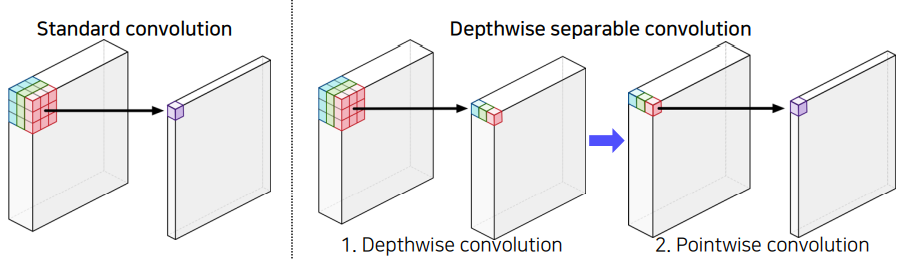
1. Depthwise Seperable Convolution
- Standard Convolution
- 계산 방법
: 3차원 Feature Map과 3차원 kernel을 합성곱하여 하나의 Feature를 뽑아냄.- 계산량
:
- Depthwise Seperable Convolution의 계산량
- 계산 방법
- Depthwise Convolution
: 3차원 Feature Map을 2차원 Feature Map여러개로 나누어, 각 2차원 Feature Map에 대해 2차원 Kernel을 사용하여 각각 하나의 Feature를 뽑는다.- Pointwise Convolution
: Depthwise Convolution의 결과로 얻은 각각의 Feature Vector를 모아 Convolution을 적용해준다.- 계산량
:: Kernel의 크기
: Feature Map의 크기
: Input Channel의 크기
: Output Channel의 크기
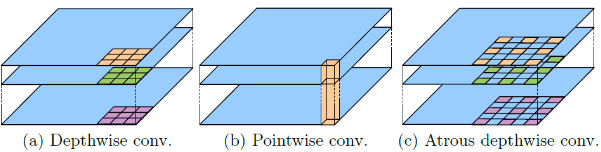
2. Atrous Separable Convolution
Atrous Separable Convolution은 위의 Depthwise Seperable Convolution에서 Convolution연산을 Atrous Convolution연산으로 바꾼 방법이다.
3. 코드
class DepthwiseSeparableConv2d(nn.Module): def __init__(self, in_ch, out_ch, kernel_size, stride, dilation=1): super().__init__() if dilation > kernel_size//2: padding = dilation else: padding = kernel_size//2 self.depthwise_conv = nn.Conv2d( in_channels = in_ch out_channels = in_ch kernel_size = kernel_size stride = stride padding = 1 dilation = dilation groups = in_ch # groups가 in_ch와 같으면 Depthwise ) self.pointwise_conv = nn.Conv2d( in_channels = in_ch out_channels = out_ch kernel_size = 1, stride = 1 ) def forward(self, inputs): outputs = self.depthwise_conv(inputs) outputs = self.batchnorm(outputs) outputs = self.pointwise_conv(outputs)
2) Encoder - Xception
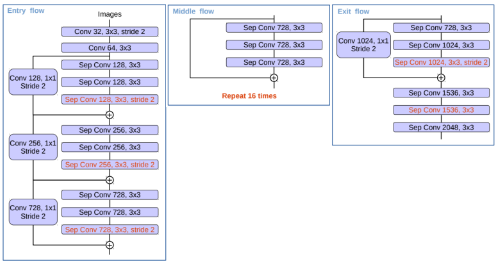
Xception모델은 크게
Entry Flow,Middle Flow,Exit Flow의 3가지 Flow로 나뉘어 진다.이때 DeepLab V3+에서는 Xception모델을 그대로 사용하지 않고 약간의 변형을 주어 사용하게 되고, 여기서는 이 수정된 부분을 중점으로 살펴보자.
1. Entry Flow
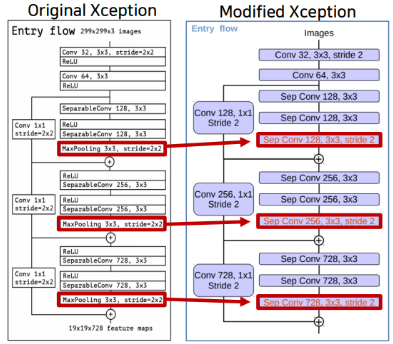
- MaxPooling → Depthwise Separable Convolution
- 기존에는
stride=2인3x3 MaxPlooing을 통해 중요한 부분을 추출해 주었었다.- 수정된 모델에서는
stride=2인3x3 Depthwise Seperable Convolution을 통해 중요한 부분을 학습한 후에 추출하도록 바꾸어 주었다.
2. Middle Flow
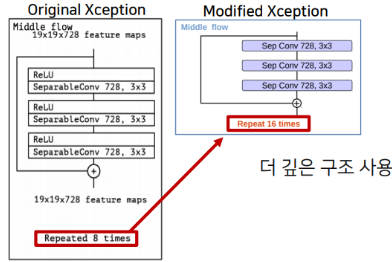
- Repeat 8 → Repeat 16
- 기존에는 Milddle Flow를 8번 반복하여 Layer를 구성하였다면 수정된 Xception에서는 16번 반복하여 더 깊은 Layer를 구성하도록 해 주었다.
3. Exit Flow
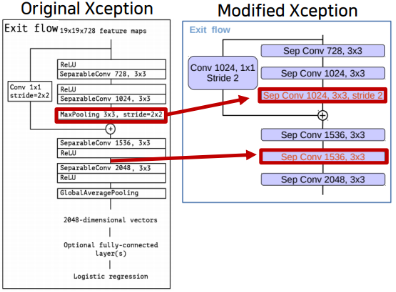
- MaxPooling → Depthwise Separable Convolution
- Entry Flow에서와 같이 MaxPooling이 아닌 Depthwise Separable Convolution을 사용해 주었다.
- Atrous Separable Convolution 2개 → 3개
- 기존에는 MaxPooling이후에 Atrous Separable Convolution Layer 2개와 Global Average Pooling을 적용해 주었다.
(Image Classification에서 사용하기 위해서 Global Average Pooling을 사용해 준듯 하다.)- 수정된 모델에서는 Atrous Separable Convolution Layer를 3개를 쌓아 주었다.
3) Architecture
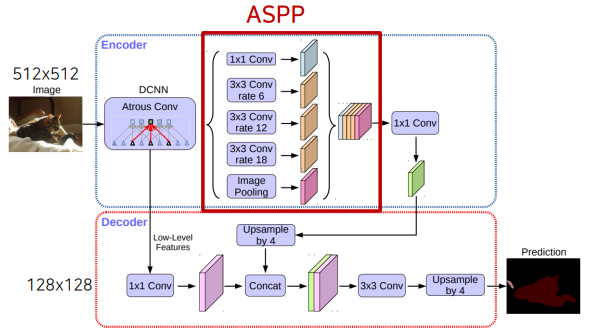
1. Encoder
- 입력
- 이미지
- 출력
- Xception의 Entry Flow안의 첫번째 블록의 출력
- (Low Level의 Feature를 Decoder로 전달하기 위함)
- Xception의 결과에 ASPP를 적용한 출력
- (Encoder부분의 결과를 Decoder로 전달)
2. Decoder
- 입력
- Xception의 Entry Flow안의 첫번째 블록의 출력
- Xception의 결과에 ASPP를 적용한 출력
- 동작
- Low Level의 Feature를 담고있는 입력에 대해서는 1x1 Convolution을 통해 Channel을,
- Encoder의 결과를 담고있는 입력에 대해서는 Bi-Linear Interpolate를 통한 Upsampling을 수행하여 각각의 크기와 Channel을 맞춰준 후에 Concatenate해준다.
3. 참고 이미지

안녕하세요~ 논문 리뷰 너무 잘 봤습니다. 다름이 아니라, v1에서는 backbone으로 VGG-16을 썼다고 쓰여 있는데요, 다른 블로그에서는 feature extractor를 VGG-16로 사용했다고 되어 있어서,, 혹시 backbone과 feature extractor, 그리고 encoder 가 비슷한 맥락으로 통용되는 용어일까요..?