transposed convolution이유
miou
pixel accuracy
Segmentation
1. 종류
2. Background
1. 사용 예시

- Computational Photography
- Medical Images에서 각 Pixel의 클래스 분류
- 자율주행
1. Sementic Segmentation(1)
1. FCN
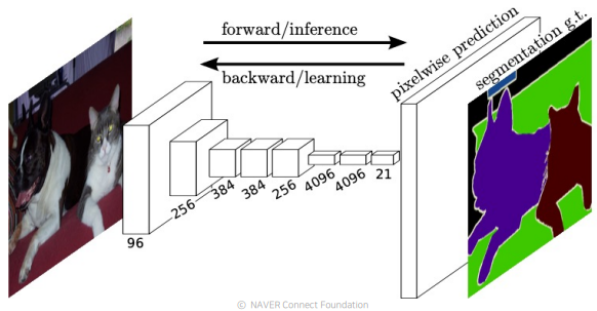
FCN은 Fully Convolutional Networks의 약자로 FC Layer를 사용하지 않고 Convolution Layer만을 사용하여 이미지를 처리하는 Network라는 특징이 있다.
1) Convolutionalization
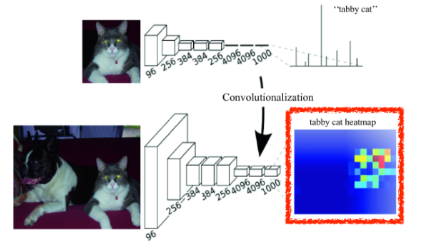
Segmentation에 있어서 Fully Connected Layer의 문제를 해결하기 위해 해당 Layer를 Fully Convolutional Layer로 바꾸는 것을 말한다.
이 Fully Convolutional Network는
1*1 Convolution Layer를 통해 구현할 수 있는데,1*1 Convolution Layer는 이미지의 크기를 줄이지 않고, 채널방향의 크기를 줄여 그 결과로 위치정보를 포함한 Heat Map을 얻도록 만들 수 있기 때문이다.
(참고1. Fully Connected Layer)
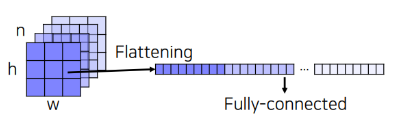
보통의 분류 문제에서는 분류작업을 위해 마지막에 Fully Connected Layer를 사용하였다.
즉, 이미지 데이터를 받아 각 카테고리별로 확률이 얼마나 되는지 계산하여 N * 1개의 행렬로 만들어 주도록 했었다.
이때, Fully Connected Layer는 Segmentation에 있어서 Parameter의 수가 늘어난다는 점외에도 한가지 문제가 더 발생한다.
Segmentation을 위해서는 결과값에 픽셀에 대한 위치 정보 또한 포함되어 있어야 하는데 Fully Connected Layer에서는 이 Flattenening작업 때문에 위치 정보가 사라지게 된다는 점 때문이다.
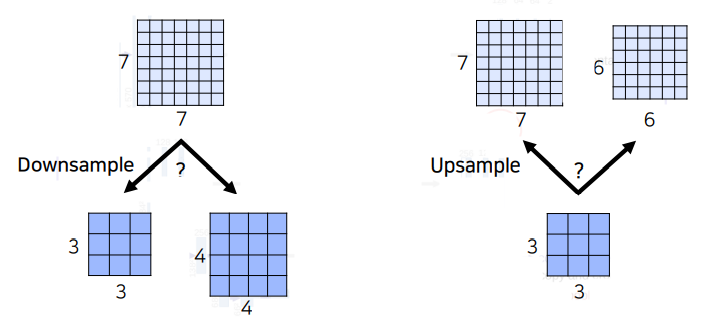
2) Upsampling
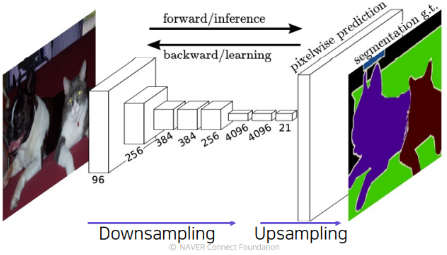
위의 Convolutionalization을 통해 얻은 HeatMap은 그 과정에서 Pooling Layer나 Stride가 2 이상인 Convolution Layer를 지나왔기 때문에, 어쨌거나 원본 이미지보다 작아질 수 밖에 없다.
즉, Segmentation을 하기 위해서는 이 HeatMap을 다시 원래의 이미지 크기만큼 키워주는 것이 필요하다.
이를 Upsampling이라고 하며, 이를 위해 사용할 수 있는 방법은 다음과 같다.
- Transposed Convolution
- Upsampling Convolution
(참고1. DownSampling)
DownSampling의 문제를 아예 만들지 않기 위해 Stride나 Pooling Layer를 사용하지 말고, 원본사이즈 그대로 HeatMap을 만들면 어떨까 라는 생각을 할 수 있다.
하지만 위와 같은 방식으로 DownSampling을 하지 않을 경우에는 같은 수의 Layer대비 Receptive Field의 크기가 작아지기 때문에 모델이 이미지의 전반적인 Context를 파악할 수 없게된다.
(참고2. Transposed Convolution)
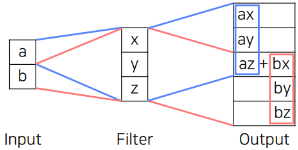
위의 그림과 같이 적절한 Padding과 Stride, 그리고 Convolution을 활용해 다시 그 크기를 늘리는 방법을 말한다.
(transposed convolution이라고 불리는 이유)
(참고3. Upsampling Convolution)

위의 Transposed Convolution을 잘 살펴보면
az + bx부분과 같이 일정 간격마다 값이 추가로 더해져서 결과 이미지 또한 그 밝기가 일정 간격마다 달라진다는 단점이 존재한다.
(Overlap Issue라고 한다.)이 단점을 해결하기 위해 주로 사용하는 방법이 Upsampling을 한 후에 Convolution연산을 수행하는 방법이다.
주로 간단한 영상처리 방법으로 많이 쓰이는 Interpolation과 같은 방법으로 이미지의 크기를 늘린 후에, Convolution Layer를 적용해 준다.
3) Skip Connection
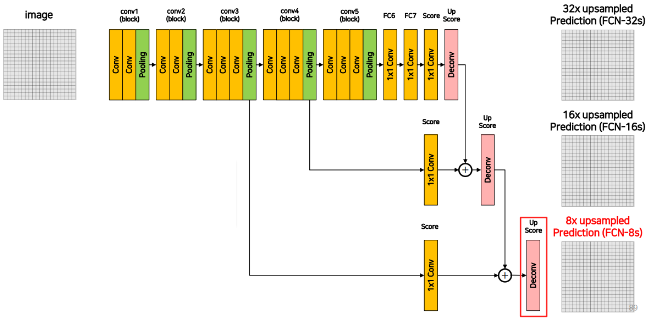

우리가 결과로써 얻게 되는 Feature Map은 큰 Receptive Field를 갖고있기 때문에 그 Detail에 대한 정보가 떨어지게 된다.
FCN에서는 이를 보완하기 위한 방법으로 마지막 결과를 계산할 때 중간 Layer의 값들을 갖히 고려하는 방법을 사용한다.
(위의 그림을 보면 중간 Layer의 값을 많이 고려할 수록 뚜렷한 경계를 가지도록 잘 구분하는 것을 확인할 수 있다.)
4) 한계점
- 객체의 크기가 크거나 작은 경우 예측을 잘 하지 못함
- 객체의 디테일한 모습이 사라지게 됨
2. DeconvNet
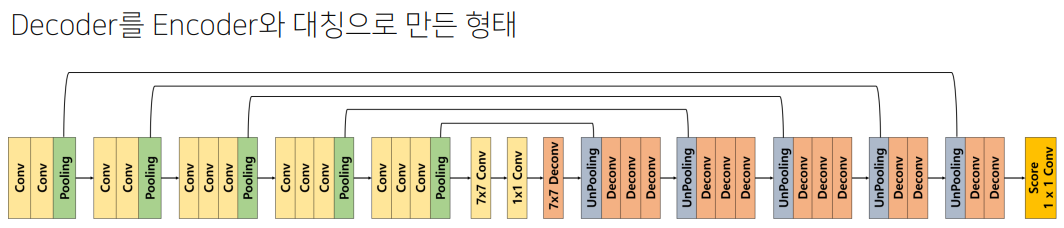
1) Encoder
DeconvNet은 Encoder와 Decoder를 통해 위에서 설명한 FCN의 한계 극복하고자 한 Architecture이다.
FCN은 Encoder를 통해 Feature Map을 추출하고 이후에 바로 Transposed Convolution을 활용해 Upsampling을 진행해 객체의 위치를 파악했지만, DeconvNet에서는 Decoder라는 Layer를 활용해 Upsampling을 차근차근 진행하게 된다.
1. BackBone
Encoder의 전체적인 구조는 앞의 FCN과 마찬가지로 VGG16을 사용하게 된다.
이때, VGG16은 Classification Task를 해결하기 위해 나왔던 Architecture인 만큼 마지막에
1x1 Feature Map을 추출하기 위해7x7 Convolution과1x1 Convolution을 활용하게 되는데 이를 그대로 활용했다는 점을 유의하자.
2. SegNet
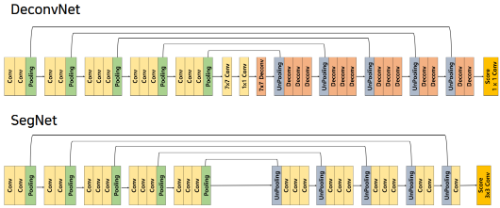
이 DeconvNet의 Encoder-Decoder Architecture를 거의 그대로 활용하고, Real Time Semantic Segmentation을 하기 위해 몇몇 Layer를 변경하도록 고안된 Architecture이다.
(즉, 속도를 위해 정확도를 높여주는 몇몇 요소들을 제거한 것 같다.)
2) Decoder
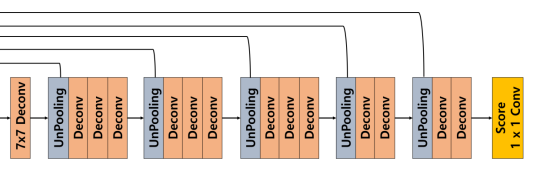
Decoder는 크게 2가지의 작업을 하게 되는데 각 잡업이 하는 일은 다음과 같다.
- UnPooling: 디테일한 경계를 복원
- Transposed Convolution: 전반적인 내용을 복원
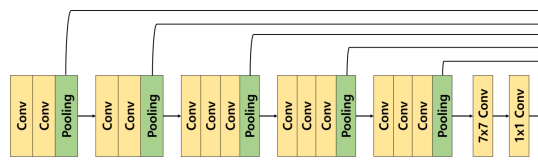
1. UnPooling
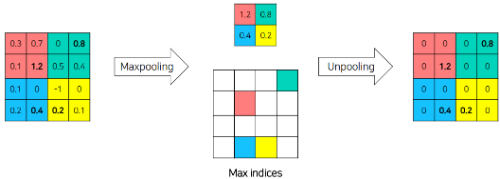
UnPooling은 앞서 수행했던 MaxPooling이전의 값을 복원하는 역할을 한다고 생각하면 된다.
이때, 복원을 위해서는 위의 그림과 같이 Max값의 Indice가 필요하다.
즉, 해당 Indice에 해당하는 곳에 현재 알고있는 Max값을 채워놓고 나머지는 0으로 채워넣게 된다.
즉, UnPooling은 Object의 경계값을 알아내는 역할을 하게된다.
2. Transposed Convolution
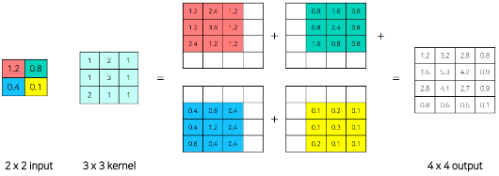
UnPooling의 결과는 어쨌든 0인 값을 가지고 있는 Sparse한 Activation Map을 가지게 된다.
이 부분을 채워주는 역할을 Transposed Convolution이 수행하게 된다.
즉, Transposed Convolution은 UnPooling의 경계값을 활용해 Object의 안의 내용을 복원하는 역할을 하게 된다.
3. Analysis Of Deconvolution Network
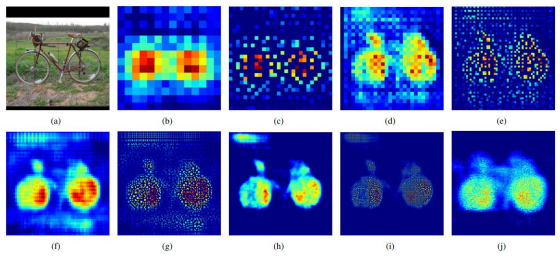
- UnPooling (
(c),(e),(g),(i))
: 위의 해당 그림을 보면 알 수 있듯이 UnPooling작업은 경계값을 포착하고 있는 것을 확인할 수 있다.
- Transposed Convolution (
(b),(d),(f),(h),(j))
: 마찬가지로 Transposed Convolution은 경계값 내부의 빈 공간을 복원하고 있는 것을 확인할 수 있다.
- Layer
: 위의 그림을 자세히 살펴보면(b)와 같은 얕은 층의 경우에는 전반적인 모습을 잡아내고 있지만 ,(j)와 같이 깊은 층의 경우에는 구체적인 모습까지 잡아내고 있는 것을 확인할 수 있다.
3) 코드 참조 설명
Encoder
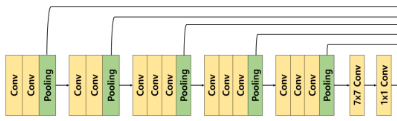
1. Conv
self.Conv = nn.Sequential( nn.Conv2d(), nn.BatchNorm2d(), nn.ReLU() )
- 이때, Conv블럭에서는
3x3의 Kernel Size와1의 Padding을 주어 이미지 크기(Resolution)의 변화가 발생하지 않는다.2. Pooling
self.Pooling = nn.MaxPool2d(kernel_size=2 ,stride=2, return_indices=True) # out, Pooling_indice = self.Pooling(Out)
return_indices=True설정을 통해 MaxPooling시의 위치 정보를 저장해두고 후에 Unpooling시에 활용하게 된다.3. Encoder Block
Encoder = nn.Sequential( self.Conv(), self.Conv(), self.Pooling() )
- Vgg16과 같이 처음 2 Block은 Conv블록을 2개씩를 활용하고 마지막 3 Block은 Conv블록을 3개씩 활용한다.
Decoder
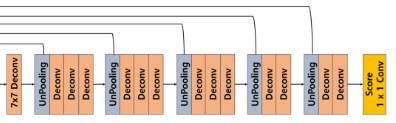
1. UnPooling
self.UnPooling = nn.MaxUnpool2d(kernel_size=2, stride=2) # out = self.UnPooling(out, Pooing_indice)
- Unpooling을 위해서 위의 Pooling작업시
return_indice=True로 설정해 indice값을 같이 넣어주어야 한다.2. Deconv
self.Deconv = nn.Sequential( nn.ConvTransposed2d(), nn.BatchNorm2d(), nn.ReLU()
- 마찬가지로 Deconv블럭으로 인해 Sparse한 Feature Map을 Dense하게 바뀌게 되지만 Resolution의 변화는 없다.
3. Decoder
Decoder = nn.Sequential( self.UnPooling(), self.Deconv(), self.Deconv() )
- 마찬가지로 그림과 같이 Deconv블럭의 수를 적절히 조절하여 사용한다.
3. FC DenseNet
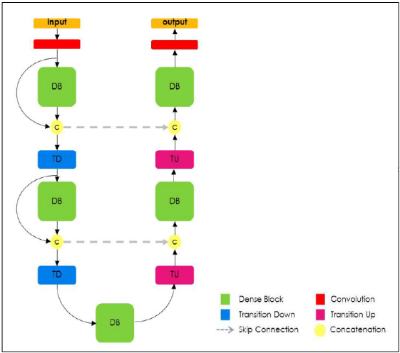
1) Dense Block
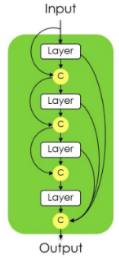
1. DenseNet
앞서 배웠던 DenseNet에서는 Skip Connection을 독특하게 적용하는 Dense Block을 활용하여 Feature Map의 Propagation을 강화하였었다.
FC DenseNet에서는 이 Dense Block을 활용하여 low Level의 Feature Map이 Output에 잘 전달되어 객체의 디테일한 모습을 잘 포착하고자 하였다.
앞서 배웠던 내용이긴 하지만 Dense Block의 가장 큰 특징을 요약해보면 다음과 같다.
- Feed Forward시 각 Layer들을 다른 모든 Layer들과 연결한다.
- Skip Connection시에 Resnet에서 제안했던 Addition방법을 하는 대신에 Concatenation을 활용한다.
2) Architecture
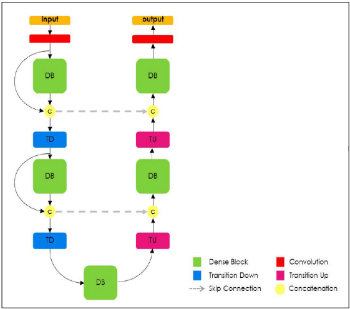
1. Encoder & Decoder
DeconvNet과 마찬가지로 Encoder와 Decoder를 활용하여 Output을 추출하게 된다.
이때, 각 Block은 Dense Block으로 구성되있고, 그림을 보면 알 수 있듯이 Encoder와 Decoder는 Skip Connection으로 다시한번 연결되고 있음을 확인할 수 있다.
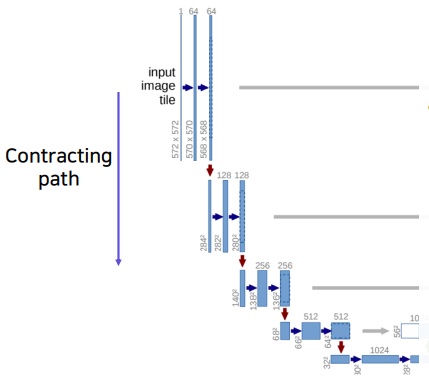
4. U-Net
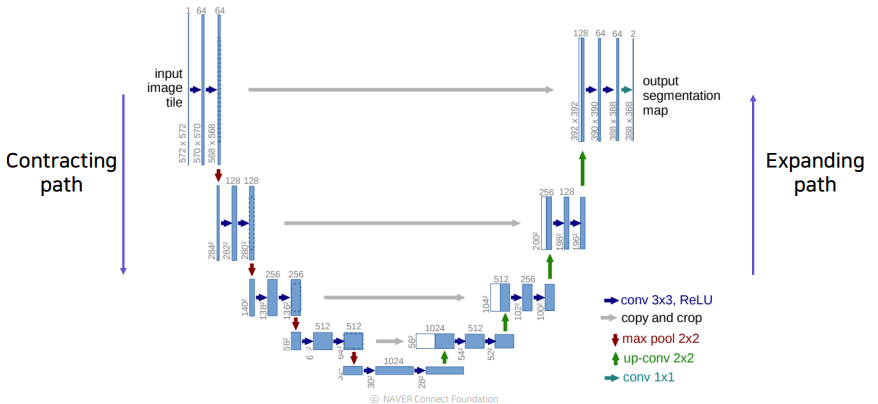
U-Net모델은 FCN의 Skip Connection구조를 좀더 잘 활용하도록 설계하여 성능을 향상시켰다.
Contracting Path
- Convolution Layer
- Receptive Field의 크기를 키우기 위해 PoolingLayer를 사용해 해상도를 낮추는 대신 채널의 수를 늘림
- 최종적으로 작은 Activation Map을 얻음
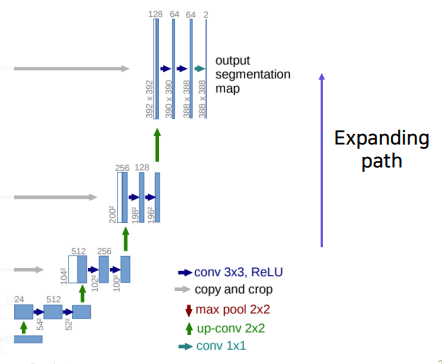
Expanding Path
- 위에서 얻은 Activation Map을 UpSampling한다.
(Upsampling할때 적절한 Stride와 Kernel의 크기를 통해 Overlap Issue를 방지하자)- Upsampling할때, 각 Layer마다 대응되는 Contracting Path의 Layer와 Concatenate해준다.
- Concatenate후 다시 채널사이즈를 줄여주는 작업을 반복한다
주의점
중간에 어떤 Feature맵도 홀수의 크기를 가지면 안된다.