Ensemble기법 종류
Ensemble에 대한 목표는 어쨌든 다음의 하나로 통일된다.
모델이 여러 관점에서 데이터를 학습하도록 하는 것이다.
이 때문에 Object Detection Task에서도
1Stage Detection모델과 2Stage Detection모델을 합치는 것이,
2Stage Detection모델들만 사용해서 합치는 것보다 더 좋은 성능을 낸다.
1. K-Fold
- 학습 데이터를 K개로 나누고 각각 K개의 모델에 대해 학습시켜 나중에 합치는 방법
2. Model Ensemble
- 여러 모델의 결과를 합쳐서 결론짓는 방법
3. Frame Work Ensemble
- Frame Work를 다르게 하여 구축한 모델을 Ensemble하는 방법
(ex.mmdetection+yolo+detectron2)
4. Seed Ensemble
- 한 모델에 대해 Seed만 다르게 하여 Ensemble하는 방법
5. Data Augmentation Ensemble
- 한 모델에 대해 Train Data Set의 Data Augmentation을 다르게 하여 학습시켜 Ensemble하는 방법
물론 위의 Ensemble방법들을 적절히 섞어 사용하여도 된다.
Bounding Box Ensemble
1. NMS
1) 정의
Non-Maximum Suppression의 약자로, 겹쳐져 있는 여러 Box에서 하나만 남기고 나머지를 제거하는 방법을 의미한다.
2) 과정
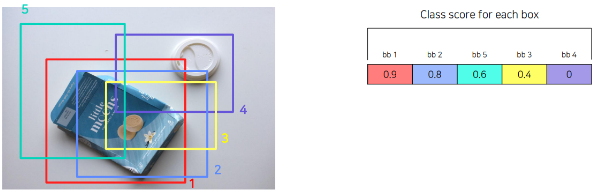
- 이미지에서 Class Score가 가장 높은 Bounding Box를 찾고, Class Score가 낮은 Bounding Box는 삭제한다.

- 위에서 찾은 Bounding Box를 기준으로 나머지 Bounding Box에 대해 IOU를 계산한다.
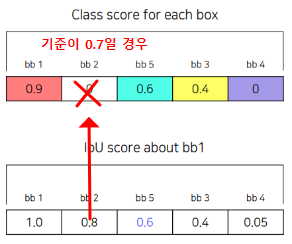
- IOU가 크면 겹치는 부분이 많다는 뜻이므로 제거한다.
(IOU Score에 대한 기준을 잘 정하는 것이 중요하다.)
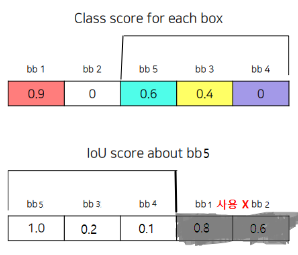
- 위에서 제거된 Bounding Box를 제거하고 1번부터 다시 시작한다.
(1번 다음으로 높았던 Bounding Box를 기준으로 다시 시작)
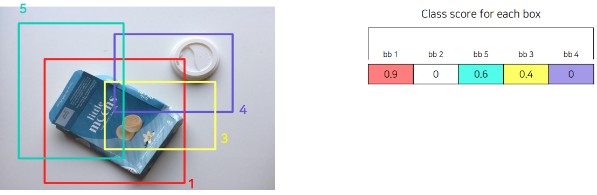
- 위의 과정을 특정 조건을 만족할 때까지 반복한다.
(ex. Bounding Box 2000개)
3) 문제점
NMS방법은 Class Score가 높던 말던, IOU가 높으면 즉, 겹치는 부분이 많아지면 무조건 삭제한다는 점에서 문제가 있다.

즉, 위와 같이 같은 Class의 물체가 겹쳐져 있는 경우를 생각해 보면 하나의 Bounding Box밖에 탐지하지 못하게 된다는 것이다.
2. Soft-NMS
1) 정의
기존의 NMS방식은 Bounding Box를 아예 삭제한다는 점에서 문제가 발생하였었다.
Soft-NMS에서는 이 문제를 해결하기 위해 IOU가 높을 경우 Bounding Box를 삭제하는 것이 아닌 Class Score를 낮추는 방식으로 작동하게 한다.
2) 과정
NMS과정과 동일하지만 IOU를 기준으로 삭제하는 부분만 달라진다.
(위의 3번과정)
NMS의 경우
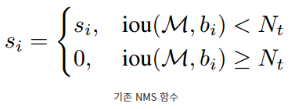
: 기준이 되는 가장 높은 Score를 가지는 Bounding Box
: M과 비교하는 Bounding Box의 Class Score
: 과 비교하는 Bounding Box
: 기준이 되는 IOU Score
보다 작으면 아예 를 0으로 만든다.
Soft-NMS
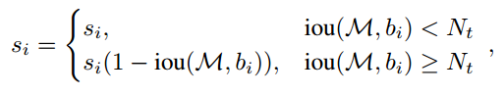
보다 작으면 를 IOU비율만큼 줄인다.
Gaussian Soft-NMS
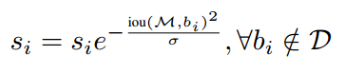
가우시안 분포를 활용해 를 줄이되 연속적으로 만들어 준다.
WBF와 비슷한 NMW라는 것도 존재한다고 함
3. WBF
1) 정의
위의 NMS와 Soft-NMS방식은 기존의 Bounding Box에서 몇개를 선택하는 방식으로 동작하였다.
WBF는 위의 방식들과 다른 새로운 방법으로 동작한다.
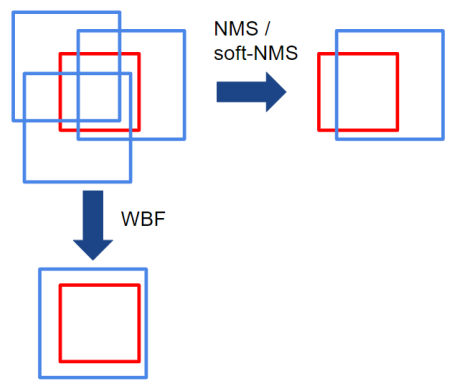
WBF는 위의 그림과 같이 모든 Bounding Box의 Confidence Score를 활용해 새로운 Average Box를 만들어내게 된다.
2) 동작과정
아래는 논문에 나온 과정을 그대로 해석해 본 내용이다.
- 모든 한 이미지에 대한 모든 Bounding Box의 정보를 list 에 넣고 정렬한다..
: 한 이미지에 대한 Bounding Box가 Confidence Score 를 기준으로 정렬되어 있는 곳.
- 두개의 비어있는 list 과 를 생성한다.
: Bounding Box의 모임
: 에 존재하는 Bonding Box를 융합한 fused Box를 만들고 보관하는 곳
- 의 맨 앞에 존재하는 Box를 에 존재하는 fused Box들과 융합될 수 있는지 확인한다.
:
(본 논문의 실험에서는 이 0.55일 때 가장 최적의 조건이었다고 함.)
- 위의 조건을 만족하는지 여부에 따라 다음의 과정을 수행한다.
- 융합될 수 없는 경우
: 해당 Box를 에서 꺼내 의 끝과 에 넣는다.- 융합될 수 있는 경우
: 해당 Box를 에서 꺼내 에 넣고 와 연결(Match)하고 다음의 과정을 수행한다.
=와 연결된 에 존재하는 T개의 Box를 모아 다음의 수실을 통해 의 위치와 Confidence Score를 조절한다.
- 모든 계산이 끝난 후 이 Ensemble한 모델의 수라고 할 때, F에 존재하는 Box들의 Confidence Score를 다음 두 식중 하나를 통해 조절해 주어야 한다.
일 경우
: 해당 Bounding Box를 예측한 Model의 수가 적다는 뜻이므로 Confidence Score를 낮춰주어야 하기 때문이다.
3) 특징
- NMS나 Soft-NMS를 사용한 후에 WBF를 사용할 수 있다.
- Ensemble하는 두 모델의 Score 차이가 클 경우 문제가 생길 수 있다.
: 사전에 Score정규화를 진행해 해결해야 한다.
- NMS에 비해서 계산 효율이 매우 떨어진다.
라이브러리
1) 설치
pip install ensemble_boxes
2) 사용 방법
boxes, scores, labels = nms(boxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr) boxes, scores, labels = soft_nms(boxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, sigma=sigma, thresh=skip_box_thr) boxes, scores, labels = weighted_boxes_fusion(boxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
(github코드)

높든* 말든*