String탐색 알고리즘
Text에서 원하는 string, pattern을 찾는 알고리즘
이 부분을 공부할 때, 도저히 무슨 말인지 모르겠다면 일단 자신이 이미 가지고 있던 생각을 잠깐 버려두고 공부해보자. 우리는 알고리즘을 만드는 것이 아니라, 이미 만들어진 알고리즘에 대해서 공부하는 것이기 때문에, 우리의 예측이나 생각이 오히려 방해가 될 수 있다고 생각한다.
그리고 그 다음 이해가 되었다 싶으면 그제서야 우리의 생각과 비교하고 의문을 가져보자.
1. Brute Force
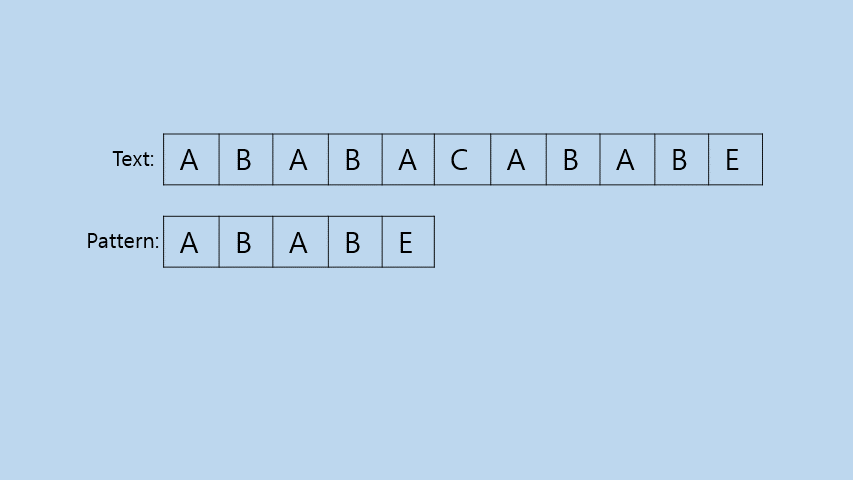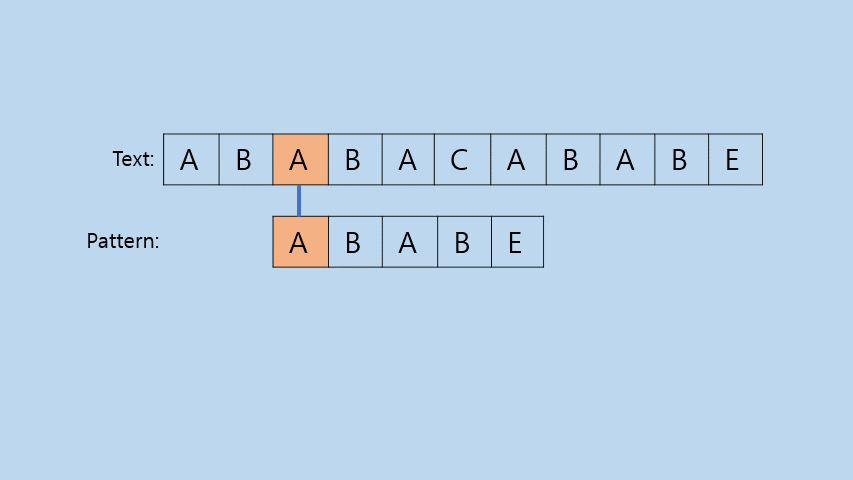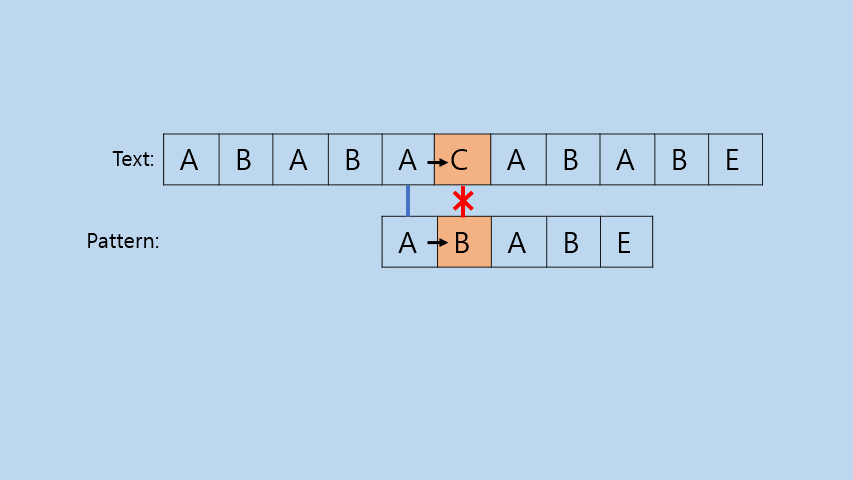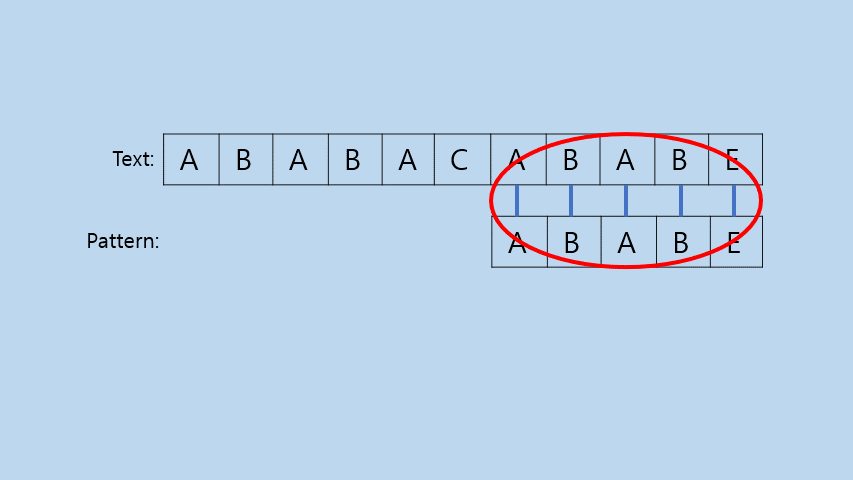
그냥 모든 경우의 수를 전부 비교해 보는 방법이다. 이 부분은 따로 코드에 대한 설명을 하지 않겠다.
1) Code
void BruteForce(string text, string pattern){ int i, j; for(i=0, j=0; i<text.length && j<pattern.length; i++, j++) { if(text[i] != pattern[j]) { i = i-j; j = -1; } } if(j==pattern.length) return i-pattern_size; else return i; }
2. KMP 알고리즘
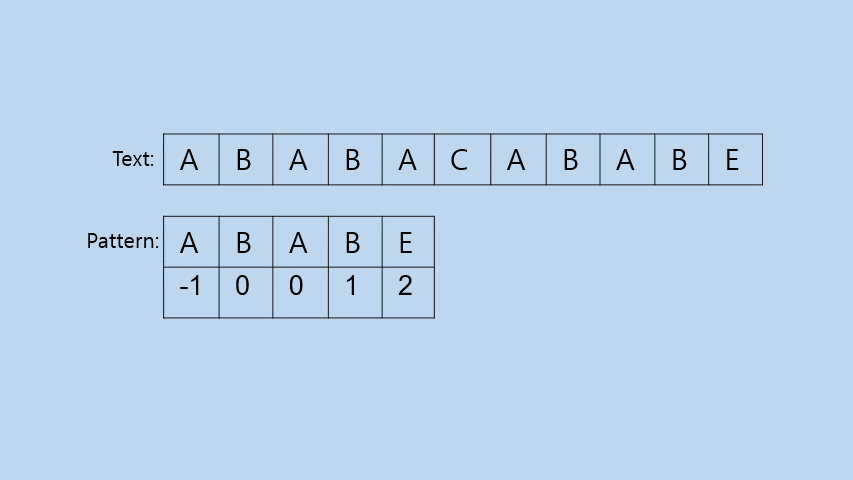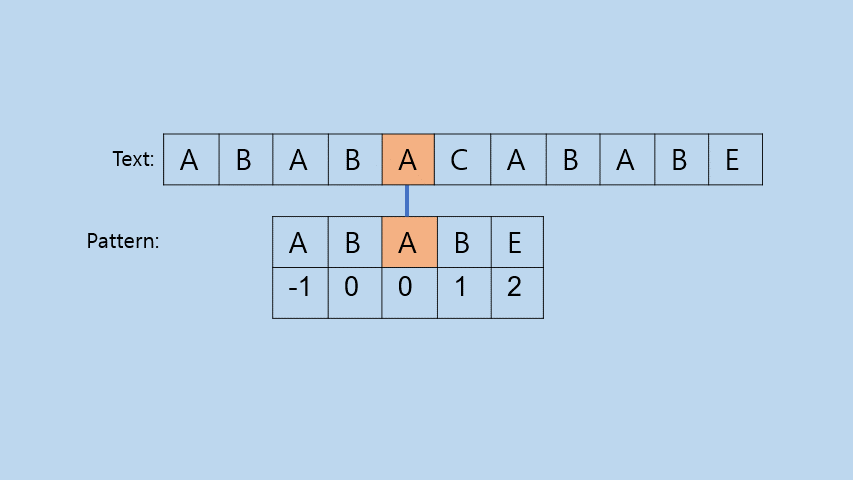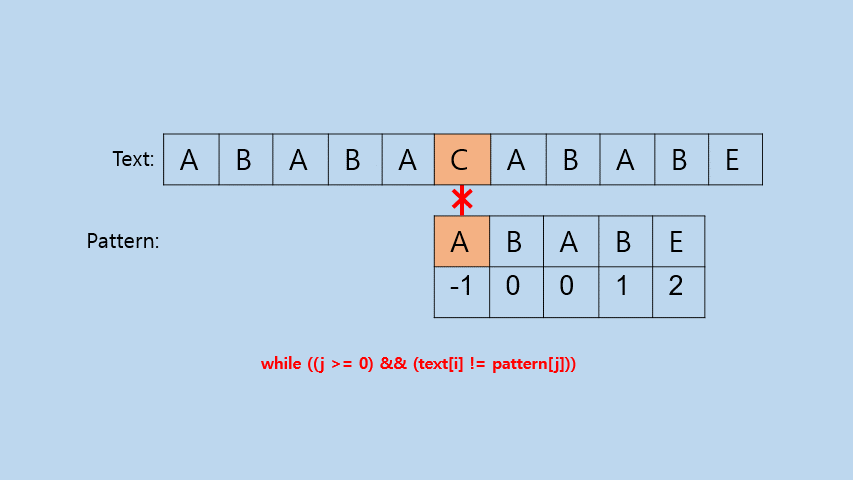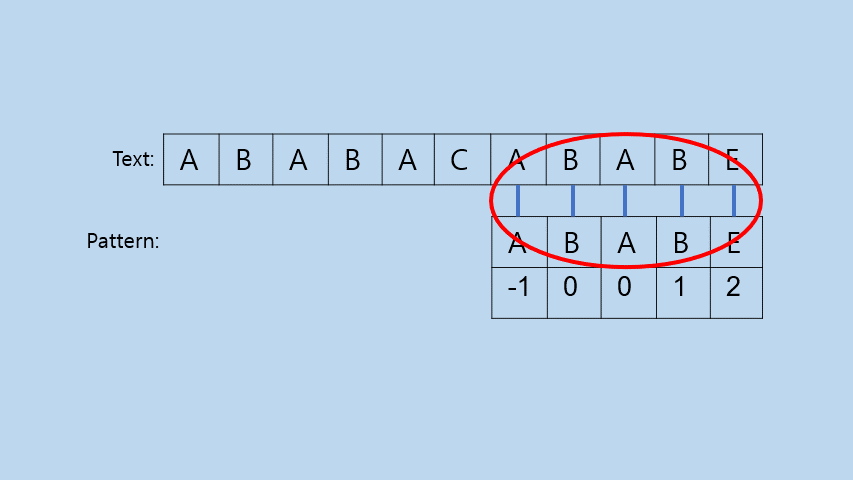
INTRO: Idea
Brute Force에서 성능을 개선하기 위해서는 필요없는 비교를 없애는 것이 가장 중요하다. Brute Force는 무조건 다음 비교를 Pattern을 한칸만 옮겨서 시작하기 때문에 필요없는 비교도 수행하기 때문이다.
자세히 들어가기전에 간단하게 생각해보면 KMP알고리즘은 Pattern과 Text의 비교가 실패했을 때, Pattern에서 앞부분에 비슷한 부분이 있는 경우 그 부분부터 다시 비교를 시작하자는 아이디어이다.
이렇게 Pattern의 앞부분부터 다시 비교하기 시작하면 위의 gif를 보면 알 수 있듯이 다음과 같은 효과를 얻을 수 있다.
- Pattern을 몇칸씩 옮겨 비교를 수행하는 효과를 얻을 수 있게된다.
- 비슷한 부분을 기준으로 하기 때문에 Pattern의 앞부분은 다시 비교를 수행하지 않아도 된다.
1) Next배열
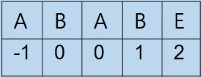
가벼운 설명
Next 배열은 Pattern에서 비슷한 부분에 대한 위치가 담긴 배열이다.
즉, Next[i]에는 Pattern[m : i-1]과 비슷했던 부분의 위치가 담겨있다. (m은 [0, i]사이의 값)여기서 i-1까지를 기준으로 하는 이유는 우리가 Pattern[i]에서 Text와 불일치가 발생했을 때 Next[i]배열을 사용하기 위해서이다.
Next배열에 들어가야 할 것

즉, 위와 같이 Pattern[m : i-1]과 비슷한 부분이 Pattern[0 : n] (n은 [0, i]사이의 값)에 있다면 Pattern[n+1]과 Text를 다시 비교하면 된다는 것이다.
다시말해서, Next[i]은 이 n+1이라는 값을 가지고 있다고 생각하면 된다.#Question 여기서 나는 왜 0:n 이어야 하는지 궁금했었다. 3:n과 같이 굳이 0부터가 아니더라도 비슷한 부분은 존재할 수 있기 때문이다. (ex. "KFABMABCA"와 같은 문자열은 "C"에서 틀릴경우 앞의 "M"부터 시작하면 되지않나?) #ANSWER 패턴 전체와 일치해야 한다는 것을 잊지말자. 위의 경우 "M"부터 시작하면 앞 부분이 일치한다는 보장이 없다. ("KF"에 의해 일치하지 못하게 된다.)
Prefix와 Suffix
위에서 우리는 Pattern[0 : n]과 Pattern[m : i-1]이 일치하는 부분을 찾아야 한다는 것을 알았다. 즉, 이것은 Prefix(접두사)와 Suffix(접미사)가 같다는 것을 의미한다.
예를 들어 문자열
"AABAC"와"ABAABAC"의 부분문자열에 대해 Prefix와 Suffix가 같은 부분을 살펴보자.
Next배열의 의미
즉, 위 그림의 예시를 보면 알 수 있듯이 next[i]는 Pattern[0 : i-1]에서 prefix == suffix인 부분의 길이라고 생각할 수 있다.
2) Code - InitNEXT()
이제 next 배열을 구현하기 위한 초기화 코드에 대해 생각해 보자.
기본적인 컨셉은 pattern의 인덱스를 가리키는 변수인 i와 j를 생성하고, 이 변수들을 통해 prefix와 suffix의 일치를 확인해 가는 것이다.
void InitNext(string pattern, int* next) { int i, j; for (i = 0, j = -1; i < pattern.length(); i++, j++) { next[i] = j; while ((j >= 0) && (pattern[i] != pattern[j])) j = next[j]; } }(참고: 여기서는 pattern의 앞부분을 탐색하는 변수를 j, 뒷부분을 탐색하는 변수를 i로 설정하였다.)
next[i] = j;
i의 역할
: next의 포인터로 Pattern[0 : i-1], 즉 범위를 정하는 역할을 하고있다.j의 역할
: Pattern의 포인터로 Pattern의 preffix를 찾는 역할을 하고 있다.진행과정
: 첫 반복(i=0, j=-1)때, Pattern[0 : -1]의 Prefix는 -1로 설정한다.
: 두번째 반복(i=1, j=0)때, Pattern[0 : 0]의 Prefix는 0으로 설정한다.
: 세번째 반복부터는 next[i]에 이전 반복에서 계산해 놓은 j를 대입한다.(즉, while문에서는 현재 i에 대해 Pattern[0 : i]의 Prefix의 위치를 j에 저장할 것임을 예측할 수 있다.)
j = next[j];
목표
: Pattern[0 : i]의 Prefix길이를 j에 저장한다.참고
: j < i이고 현재는 i번째 반복이므로 next[j]는 계산이 완료된 상태이다.
: 첫 while에서 j의 값은 next[i], 즉 Pattern[0 : i-1]의 Prefix(위치+1)와 같다.진행과정
- 첫 반복에서 j에 Pattern[0 : j-1]의 prefix길이를 저장한다.
: 즉, [0 : i-1]의 prefix의 Prefix 길이를 저장- 다음 반복에서 j에 Pattern[0 : j-1]의 prefix의 prefix의 길이를 저장한다
: 즉. [0 : i-1]의 prefix의 prefix의 prefix길이를 저장
: 이 과정을 Pattern[i]와 Pattern[prefix]가 같아질 때 까지 반복한다.(첫 반복에서 j-1 = next[i]-1 = Pattern[0 : i-1]의 prefix위치)
(두번째 반복부터 j-1 = Prefix의길이-1 = prefix의 위치)
4) Code - KMP()
이제 Kmp알고리즘을 구현해 보자.
InitNext(pattern, next); //KMP는 next를 먼저 초기화하고 사용한다. int KMP(string text, string pattern, int* next) { int i, j; for (i = 0, j = 0; i < text.length() && j < pattern.length(); i++, j++) { while ((j >= 0) && (text[i] != pattern[j])) j = next[j]; } if (j == pattern.length()) return i - pattern.length(); else return i; }사실 위에서 next배열의 정의와 InitNext()함수를 잘 이해했다면, KMP의 동작 과정을 표현하는데에는 문제가 없을 것이다.
즉,
text[i] != pattren[j]로 Pattern일치에 실패했을 때 j를 재설정해주고 다시 비교하면 된다. 그리고 이를 반복하게 하도록 하자.
5) Code - main()
int main() { string pattern, text; getline(cin, text); getline(cin, pattern); InitNext(pattern, next); int loc = -1; while (true) { loc++; loc = KMP(text, loc, pattern, next); if (loc == text.length()) break; cout << "패턴이 발생한 위치: " << loc << endl; if (loc >= text.length() - 1) break; } cout << "탐색종료" << endl; }위의 KMP함수는 패턴일치가 한번이라도 일어나면 바로 값을 리턴하도록 설계되었다.
따라서
while(true)로 text가 끝날 때 까지 비교하도록하고, 이 때KMP()의 시작 위치만 바꿔준다면 text에서 모든 일치패턴의 위치를 찾을 수 있게 된다.
6) Code - 유한상태장치
next배열은 아래와 pattern[i]에서 틀릴경우 다시 비교할 패턴의 인덱스를 저장하고 있다.
이 때, 다시 비교할 패턴이 pattern[i]와 일치하다면? 이 때에는 어차피 다시 비교해도 또 pattern[i]와 text[j]는 불일치하다고 판별될 것이다.
즉, 이를 없애기 위해 다음과 같이 next배열 초기화 코드를 고쳐줄 수 있다.
void InitNext(string pattern, int* next) { int i, j; for (i = 0, j = -1; i < pattern.length(); i++, j++) { if(pattern[i]==pattern[j]) // 추가된 조건 next[i] = next[j]; else next[i] = j; while ((j >= 0) && (pattern[i] != pattern[j])) j = next[j]; } }
이 과정을 좀 더 이해하기 쉽게 그림으로 표현해 본 것은 다음과 같다.
pattern={1, 0, 1, 0, 0, 1, 1, 1}이라고 가정하고
next에 의한 이동과정은 다음과 같이 표현할 수 있다.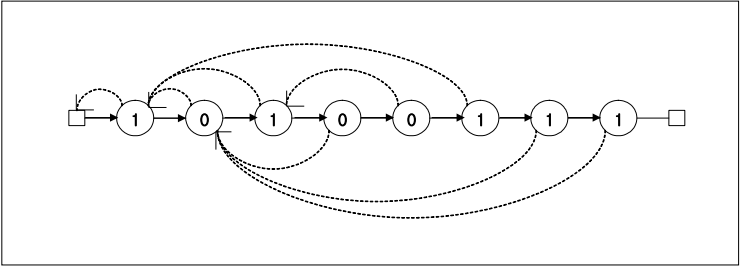
(위는 원래 next배열에 대한 pattern의 이동과정)
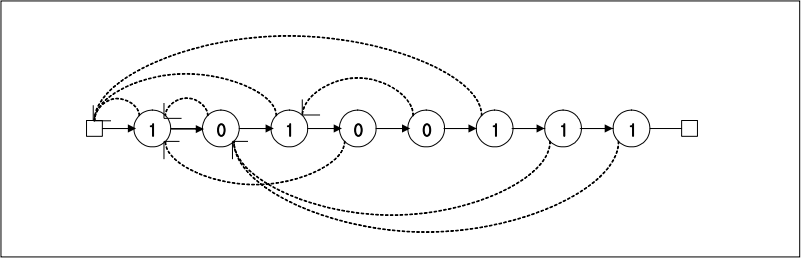
(위는 개선된 next배열로 인한 pattern의 이동과정)
3. Boyer Moore알고리즘
ctrl+f와 같이 실제로 현재 많은 프로그램에서 사용하고 있는 알고리즘이다.
(참고로, KMP보다 더 성능이 좋다.)
INTRO: Idea
Text와 Pattern의 불일치는 주로 뒷부분에서 일어난다는 점에서 착안한 알고리즘이다. 즉, Text와 Pattern의 비교시 뒤에서부터 비교하게 된다.
위의 gif를 보면 알 수 있듯이 Text[i]와 Pattern[j]에서 어떤 기준에 따라 i값을 단순증가를 시킨다는 점은 KMP와 비슷하다.
하지만 KMP는 i를 1씩 증가시키고 주로 j값의 변화를 주었다면,
Boyer Moore는 i를 1이상의 값씩 증가시키고 j는 마지막 원소를 가리키도록 초기화한다는 점에서 약간 다른 점이 존재한다.
- Good Suffix Method
- Bad Character Method
이 Boyer Moore알고리즘의 String Search방법은 위와 같이 2가지가 존재하는데 이 두 경우는 특정 상황마다 좋은 점이 서로 다르다.
(특정 방법의 i값의 증가폭이 더 커져 탐색 속도가 빨라질 수 있기 때문이다.)따라서 보통의 프로그램에서는 이 두가지 방법을 모두 사용하도록 구현하고 둘 중 패턴의 이동거리가 더 큰 쪽을 택하도록해 시간을 단축한다.
(하지만 문자열의 특성상 Good Suffix Method가 선택되는 경우는 거의 없다.)이제 이 Boyer Moore의 핵심인 i를 얼마나 증가시킬지에 대한 것을 유의깊게 생각하며 좀 더 자세히 알아보자.
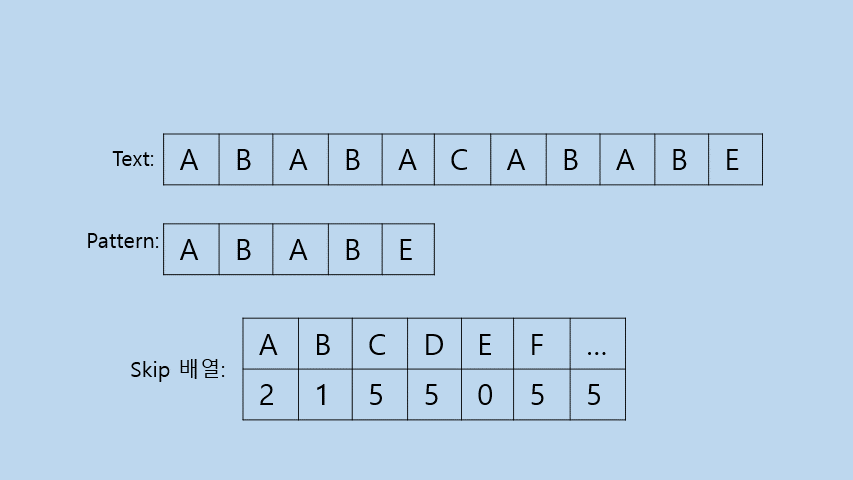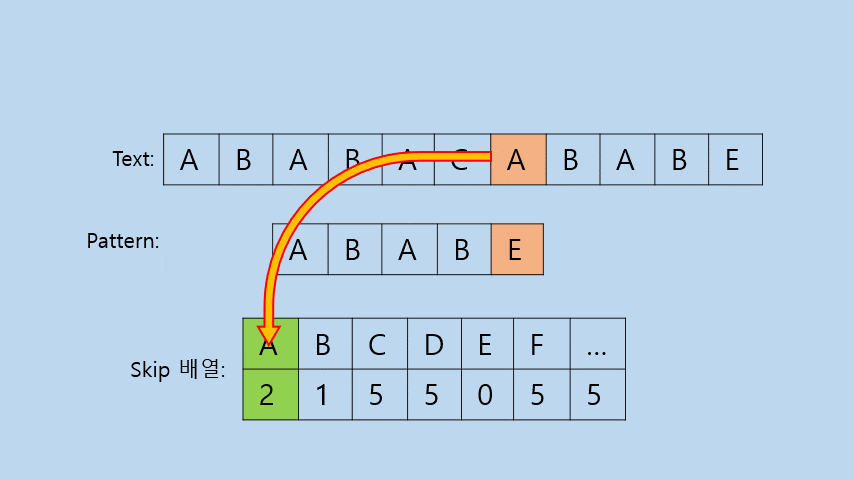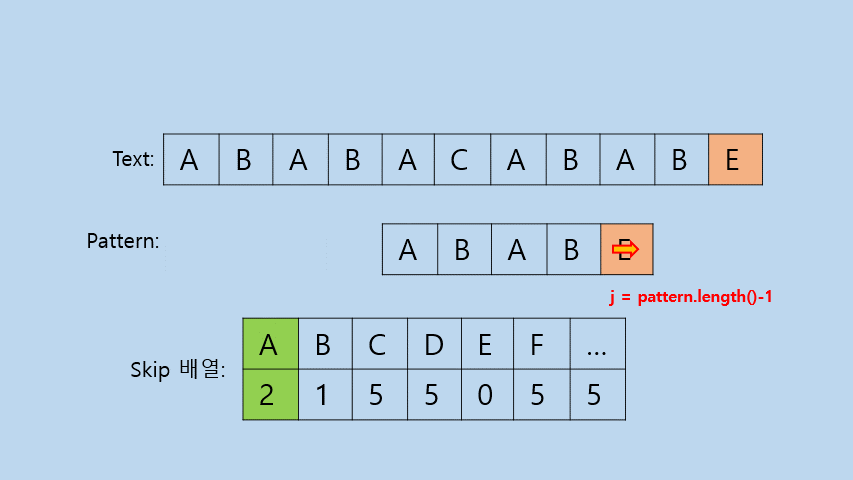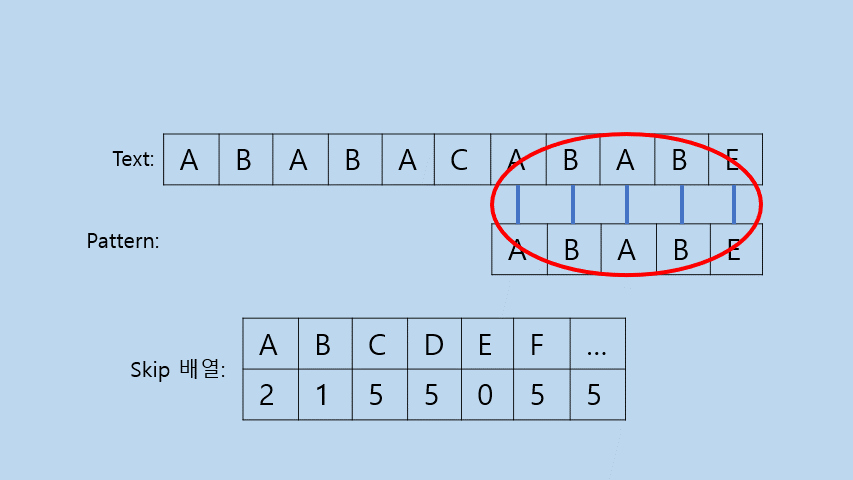
1) Skip배열

- Skip배열이란?
: Pattern에서 해당 문자가 뒤에서부터의 위치를 입력해둔 배열이다.
- Skip배열의 목적
: 해당 값 만큼 i를 증가시키기 위한 목적으로 사용한다.
- 이해를 돕기위한 예시
아래의 Case들을 볼 때, 먼저 Pattern을 얼만큼 이동할 수 있을 지 생각하는 것이 편리하다. Pattern이 이동하는 것은 Text의 i가 이동한 것과 같은 효과를 나타내기 때문이다.
- Case1
: Pattern에 Text[i]와 같은 문자가 존재하지 않을 때
- 해당 범위의 텍스트는 더이상 비교하지 않아도 된다.
- i는 현재 i의 위치에서
Pattern의 길이를 더해 재설정해야 한다.- j는 맨뒤로 옮겨 다시 처음부터 비교를 시작해야 한다.
- Case2
: Pattern[j]에 Text[i]와 같은 문자가 존재할 때.
- Text[i]와 Pattern[j]를 일치시킨후에 다시 비교를 시작한다.
- i에
(Pattern의 길이 - Pattern\[0 : j]의 길이)를 더해 재설정해야 한다. (이는 Pattern의 길이-j-1를 더한것과 같다.)- j는 맨 뒤로 옮겨 다시 처음부터 비교를 시작해야 한다.
즉, 만약 Pattern에 존재하지 않는 경우의 Skip설정을 Pattern의 길이로 설정한다면 위의 두 경우 모두 Skip배열을 활용할 수 있게 된다.


2) Code - InitSkip()
다음은 Skip Table을 만드는 함수이다.
확장된 형태의 Ascii값은 총 256개가 존재한다.
따라서 나올 수 있는 모든 Pattern의 값의 위치를 저장하기 위해 256의 크기를 가지는 배열을 선언한다.
int skip[256]; void InitSkip(string pattern) { for(int i=0; i<NUM; i++) skip[i] = pattern.length(); for(int i=0; i<pattern.length(); i++) skip[(int)pattern[i]] = pattern.length()-i-1; }
3) Boyer Moore 함수
사실 위에서 만든 Skip배열을 사용하면 안되는 경우가 존재한다. 다음의 경우를 살펴보자.

이전까지 문제없이 순행해온 경우 해당 Text의 전에는 일치 Pattern이 없다는 것이 확실하다.
더군다나, 위의 그림과 같이 Text의 첫 부분일 경우 Pattern이 남은 Text의 길이를 넘어서게된다.
- Case3
: Case1, Case2를 적용했을 때, 역행하게 되는 경우
- 역행하게 되는 경우에는 한칸만 옮겨 다시검사하도록 한다.
- i에
(Pattern의 길이 - j)를 더해 재설정해야 한다.- j는 맨 뒤로 옮겨 다시 처음부터 비교를 시작해야 한다.
먼저 위의 Case1, Case2를 고려하여 Skip배열을 만들었고, 이는 Case3을 포함하고 있지 않은 상태이다.
따라서 BoyerMoore함수를 만들 때 이 경우도 고려하도록 해서 구현해야한다.

4) Code - BoyerMoore()
int skip[256]; InitSkip(pattern); MisChar(string text, string pattern){ int i, j; for(i=pattern.length()-1, j=pattern.length()-1; j>=0; i--, j--) { while(text[i] != pattern[j]) { int k = skip[(int)text[i]]; if(pattern.length()-j > k) // case3 i = i+pattern.length()-j; else // case1, case2 i = i + k; if(i>=text.length()) return text.length(); j = pattern.length()-1; } } return i+1; }
3. Rabin Karp 알고리즘
해싱을 활용해 매칭을 하는 알고리즘
최악의 시간복잡도는 O(MN), 그러나 평균적으로는 O(n)이다.
-
패턴에 대한 해쉬값을 구한다.
-
텍스트에서 패턴의 길이만큼 잘라 해쉬값을 구한다.
-
이를 반복
중요
이 때, 바로 이전에 해쉬를 구하기 위해 사용했던 앞부분은 제외하고 뒷부분을 더할 수 있어야 하는 것이 핵심이다.
-> 이를 위한 선행지식- 호너의 룰
- 모듈라공식의 특징
4. 패턴 매칭 알고리즘
이 알고리즘은 앞에서 살펴보았던 3개의 알고리즘과는 다르게 정해진 문자를 찾는것이 아니라 특정 패턴의 문자를 찾는 알고리즘이다.
1) 정규 표현식
(아래의 표현식 이외에도 수많은 식들이 있는데 이는 구글링을 통해 참고하자.)
AB
: AB를 찾는다.
A+B
: A또는 B를 찾는다.
()*
:()안의 문자들이 0번 이상 나타나는 경우를 찾는다.
?
: 해당 자리에 어떤 문자라도 들어올 수 있다. (0개 또는 1개)
(예시)
?*(ie+ei)?*: ie 또는 ei를 갖고 있는 모든 단어(1+01)*(0+1): 두개의 0이 연속적으로 나오지 않는 0과 1로 이루어진 문자열
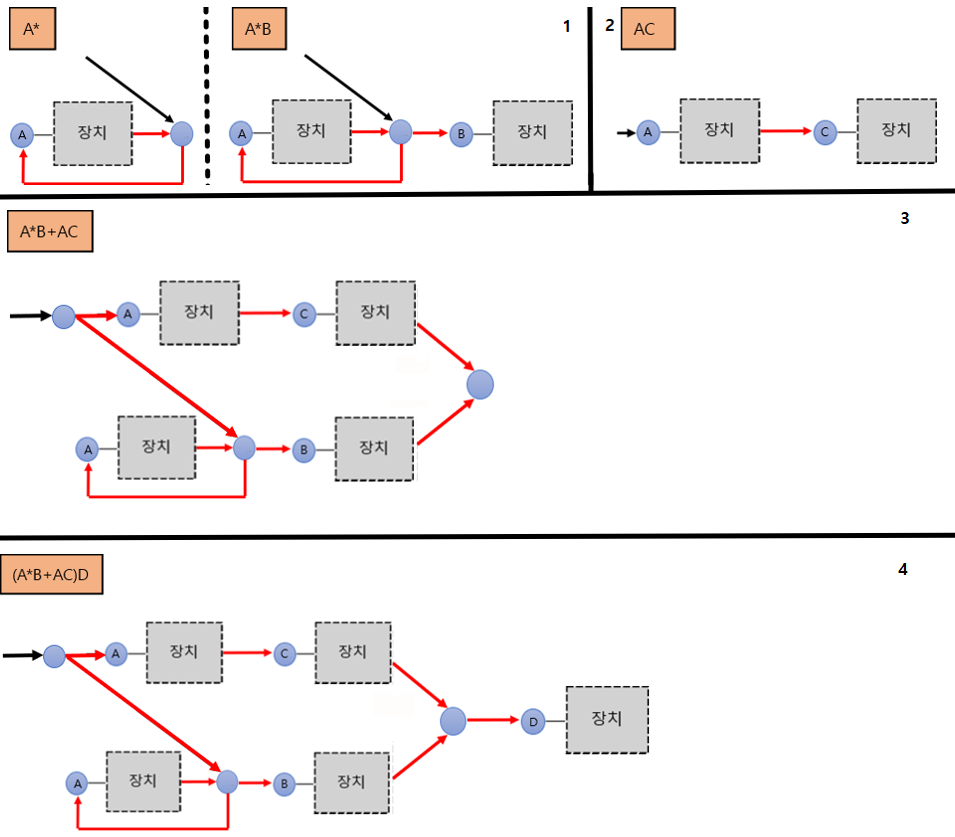
2) 패턴 매칭 장치 그리기
패턴 매칭 장치는 위에서 보았던 KMP의 유한 상태 장치처럼 현재 상태에 따라 다음에 어떤 것을 해야할 지 그림으로 표현한 장치이다.
패턴 매칭 장치는 다음과 같은 장치들로 구성되어 있다.

이때 이 장치를 정규 표현식을 참고해 다음과 같은 방법으로 연결하여 새로운 장치를 생성할 수 있다.
(논리합의 경우 표현할 때, 2개의 추가적인
O를 사용하였고, )
(폐포의 경우 표현할 때, 1개의 추가적인O를 사용한 것을 유의하자.)
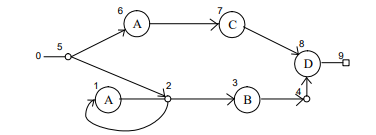
예를들어
(A*B+AC)D의 정규 표현식은 다음과 같이 나타낼 수 있다.
(정리한 결과)

3) 패턴 매칭 장치의 배열
1. 번호를 붙인다.
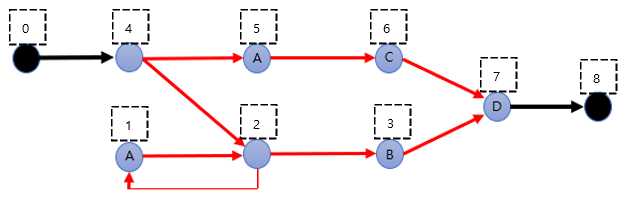
(검은색 노드는 각각 매칭 장치의 시작과 끝 노드이다.)
- 배열에 기록한다
ch[i]
: i번 노드에 위치한 문자를 기록한 배열next[i]
: i번 노드에서 갈 수 있는 노드를 기록한 배열들
(여러곳을 갈 수 있을 경우 여러개의 배열을 사용해 나타낸다.)

4) 매칭 동작 과정
- Deque(Double Ended Queue)

우리는 Deque를 사용해 매칭 과정의 정보를 저장해야 한다.
이 Deque은 특별한 점이 하나 더 있는데 뒤에서는 삭제가 발생하지 않는다는 점이다.
(참고: 앞 부분과 뒷 부분을
+기호로 나눈다.)
동작 규칙
: 검사를 시작할 때 먼저 시작 노드 다음의 값을 Deque의 앞부분에 넣는다.
: 그 후Deque.front를 다음과 같은 기준으로 검사한다.
ch[Deque.front]가 존재할 경우
: 해당 문자와 현재 검사하고 있는 문자가 일치할 경우,
->next[Deque.front]를Deque.back에 Enqueue하고 해당 값을 Queue에서 삭제한다.
: 해당 문자와 현재 검사하고 있는 문자가 일치하지 않을 경우,
->Deque.front를 삭제한다.
ch[Deque.front]가 존재하지 않을 경우
->next[Deque.front]를Deque.front에 Enqueue하고 해당 값은 Queue에서 삭제한다.
Deque.front가 존재하지 않을 경우
(Deque.front가+인 경우)
-> Deque를 뒤집어 준다.
-> 검사하는 문자를 다음 문자로 바꾼다.
Deque.front와Deque.Back모두 존재하지 않을 경우
: 매칭 실패Deque.front가 0일 경우
: 매칭 성공
5) 예시
1. 검사 성공 예시
위에서 구한
(A*B+AC)D의 패턴 매칭 장치의 배열을 활용해 Text의ABD부분을 검사할 경우
2. 검사 실패 예시
위에서 구한
(A*B+AC)D의 패턴 매칭 장치의 배열을 활용해 Text의ADC부분을 검사할 경우
