여태 까지는 시간을 절약하는 방법에 대해서 알아보았었다면, 여기서는 공간을 절약하는 방법에 대해서 알아보자.
현재 파일 압축에 많이 사용하고 있는 zip알고리즘은 Deflate알고리즘을 기반으로 하고 있다.
이 Deflate 알고리즘으로 파일을 압축하기 위해서는 두 단계를 거쳐야 하는데, 이는 다음과 같다.
- LZ77알고리즘으로 압축
- Huffman Code로 압축
여기서 우리는 Huffman Code, 그 중에서도 Huffman Encoding에 대해서 알아볼 것이다.
파일 압축
1. Huffman Encoding
1) 특징
1. 무손실 압축
허프만 인코딩은 무손실 압축이라는 점에 있어서 매우 큰 장점을 가진다.
즉, 압축을 할 때, 원본의 정보가 전혀 손상되지 않고 압축이 가능하다는 것이다.
2. 가변 길이 인코딩
가변 길이 인코딩이란? 자주 나타나는 문자에는 길이가 작은 비트를 사용하고
적게 나타나는 문자에는 길이가 긴 비트를 사용해 encoding하는 압축 기법이다. 즉, 해당 파일의 형태에 따라 압축 방법이 달라진다는 것이다.
3. 가변 길이 인코딩의 주의점
가변 길이 인코딩을 사용할 때, 정말 아무생각 없이 시도한다면 다음과 같이 코드를 할당할 수 있다.
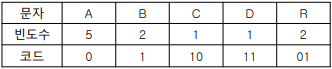
여기에는 큰 문제점이 존재한다.
예를들어BAC라는 문자를 Encoding한다고 하면1010이 될 것이다. 하지만 이 경우 다시 Decoding할 때, 원래의 값이CC였는지BAC였는지 구분할 수 없다는 점 때문이다.즉, "한번 할당된 코드는 다른 코드의 접두사로 사용되면 안된다." 라는 점을 주의하자.
(이러한 코드를 Prefix Code라고 한다.)
2) Trie

Trie는 Prefix Code를 보장하기 위해 Tree형태로 만든 자료구조이다.
Non-Leaf Node는 빈 Node이고, Leaf Node는 문자가 존재하는 형태로 짜여져 있다.여기서, Trie의 Root에서 부터 왼쪽/오른쪽으로 갈 때, 각각 0/1을 부여하고 Leaf Node에 도착할 경우 최종 부여된 Binary Code가 해당 문자의 Prefix Code가 된다.
어떤 문자열에 대한 Trie는 위의 그림과 같이 여러개가 존재할 수 있는데,
각각의 방법에 따라 문자열을 Encoding하는 평균 길이가 달라지게 된다.즉, 이 여러 Trie중 가장 좋은 방법을 찾아야 하고, 이를 결정하는 방법이 바로 Huffman Encoding이다.
3) Huffman Encoding
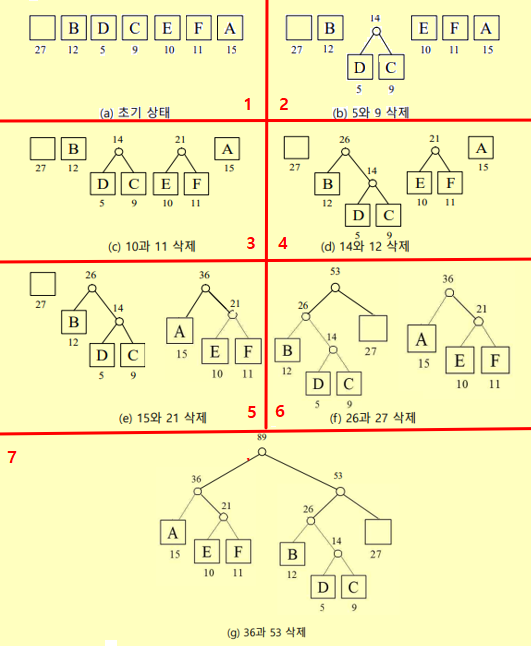
1. 방법
1) 파일에 존재하는 모든 문자의 빈도수를 계산한다.
2) 가장 적은 빈도수를 가지는 두 Node를 고른다.
3) 두 Node를 합쳐 새로운 Node를 만든다.
(이 때, 이 Node의 빈도수는 두 Node를 합친 것과 같다.)4) 2~3번 과정을 하나의 노드가 남을 때 까지 반복한다.
(Trie 완성)5) 해당 Trie에서 왼쪽/오른쪽으로 갈 때 각각 0/1 을 부여하고 문자를 만날 경우 최종 부여된 Binary Code가 압축된 코드이다.
2. Code 예시
struct nodeType { string symbol; int frequency; nodeType* left; nodeType* right; }; void huffman(nodeType* input[], int size) { priority_queue<nodeType*, vector<nodeType*>, comp> pq; for (int i = 0; i < size; i++) pq.push(input[i]); while (pq.size() != 1){ nodeType* p = pq.top(); pq.pop(); nodeType* q = pq.top(); pq.pop(); nodeType* r = new nodeType(); r->left = p; r->right = q; r->frequency = p->frequency + q->frequency; pq.push(r); } }(위의 결과
pq.top()에는 Trie의 Root가 저장되어 있다.)
3. 구축 과정 예시
암호화
암호화 시스템의 기본적인 원리는 다음과 같다.
평문(P)은 암호화 키(K)와 함께 암호화 알고리즘을 거쳐 암호문(C)가 된다.
암호문(C)는 해독키(K)와 함께 해독 알고리즘을 거쳐 평문(P)가 된다
즉, 암호화에 있어서 키의 역할이 가장 중요하다는 것을 알 수 있다.
1. 암호화 종류
암호화 알고리즘의 종류는 주로 키의 종류에 따라 나뉜다.
- 대칭 키 알고리즘
: 암호화 키와 해독 키가 같은 알고리즘
- MD5
- SHA1
- SHA2
- AES256
(여기서 MD5는 암호화가 빠르지만 안전하지 않고, AES256쪽으로 갈수록 안전하지만 암호화가 느려진다.)
- 비 대칭 키 알고리즘
: 암호화 키와 해독 키가 다른 알고리즘
- RSA
(RSA는 일부 키를 일반에 공개하기 때문에 공개 키 알고리즘이기도 한다)
2. 암호화 기법
1) 원시적인 기법
- 전치 기법
: 평문을 일정한 규칙을 가지고 암호문으로 바꾸는 방법을 의미한다.
- 대체 기법
: 평문을 다른 문자 체제로 다시 표현하는 방법을 의미한다.
2) DES & AES
- DES(데이터 암호 표준)
: IBM에서 개발한 암호 기법으로 평문을 16단계의 복잡한 단계를 거쳐 암호문으로 만들게 된다.
- 이 방법은 더이상 안전하지 않은 방법이 되었기 때문에 현재는 AES를 사용한다.
- AES-256(개선된 암호 표준)
: 256비트를 Key로 사용하게 되는 방법으로 마찬가지로 암호문을 만들기 위해서는 복잡한 단계를 거쳐야 한다.
3) RSA
- RSA 작동원리
"Rivest, Shamir and Adleman"가 만든 알고리즘으로 주로 통신으로 데이터를 주고받을 때 사용한다.
RSA는 암호화 키를 공개하는 "공개키 알고리즘"이면서 이 암호화 키와 해독 키가 서로 다른 "비대칭 키 알고리즘"이다.
즉, 송신자는 수신자의 공개키를 찾아 해당 키로 암호화한 후 전송하고, 수신자는 자신이 가진 비밀키를 통해 암호문을 해독한다.
(이를 위해서 공개키는 다음과 같은 구성 조건을 가진다.)
->비밀키(공개키(메세지))=메세지
-> 비밀키, 공개키의 쌍은 유일
-> 공개키로부터 비밀키를 알아낼 수 없어야 한다.
- Idea
- 주어진 숫자가 소수인지를 결정하는 알고리즘은 있다.
- 주어진 큰 숫자의 소수인자를 찾아내는 알고리즘은 없다.
- 수행절차
(공개키: r, e)
->r=p*q,e는 (p-1)*(q-1)과 상대적 소수인 수(비밀키: d)
->d=1 / (e modulo (p-1)*(q-1))

