TOP-K sampling 은 기존 생성 모델에서 사용하는 방법중 하나이다.
챗봇의 대답은 일정한 기준(Similarity score , BM25 score)점수에 대한 최고점수를 답변으로 추론하는 경우가 많은데.
이럴 경우 똑같은 질문을 했을 경우 계속해서 같은 답변만 하게 된다.
예를 들면.
"밥 뭐 먹었어?" 의 질문의 경우는 한 가지 음식(떡볶이)만 계속 대답하게 되는 경우가 발생하는 것.
그래서 우리는 TopK sampling 방식을 사용해서 다양한 답변을 할 수 있도록 하였다.
TopK sampling 과 Ramdom sampling 의 차이점은
Random 의 경우는 Top5 로 가정했을때 각각의 등장 확률을 25%로 균등하게 분배하는 반면
TopK sampling은 점수가 높을 수록 등장확률을 높혀주는 방식이다.
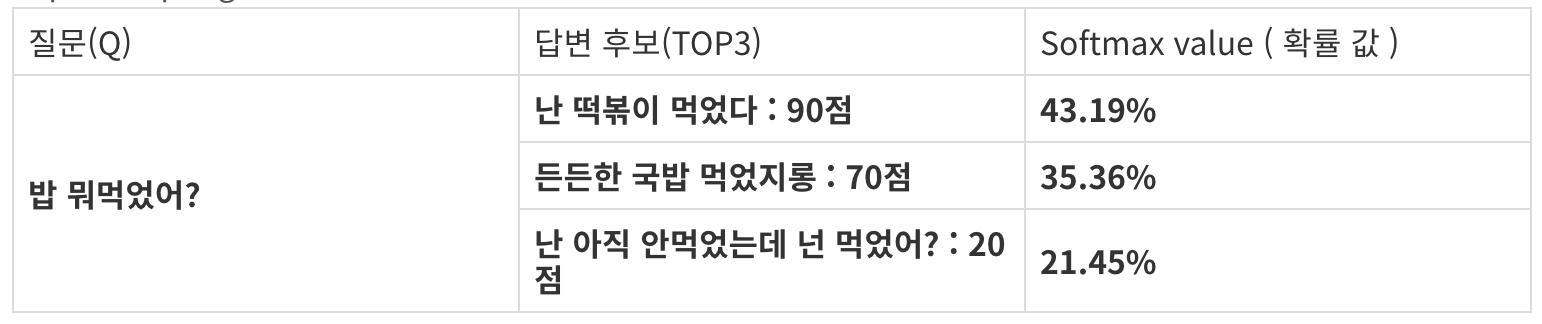
질문에 대한 Top3 답변이 있다고 가정할때 softmax 함수를 사용해서
해당 점수에대한 비율로 값을 변경하여 이 값을 확률 값으로 사용한다.
[0.4319, 0.3536, 0.2145]
TOP5 example code
import torch.nn.functional as F
import torch
def top_k_sampling(score_list: List[int], answer_list: List[str]):
score_list = torch.tensor(score_list)
softmax_list = F.softmax(score_list, dim=0)
if len(softmax_list) != 5:
zeros = torch.zeros(1, 5 - len(softmax_list))[0]
softmax_list = torch.cat([softmax_list, zeros], dim=0)
random_value = random()
range1 = softmax_list[0]
range2 = range1 + softmax_list[1]
range3 = range2 + softmax_list[2]
range4 = range3 + softmax_list[3]
if random_value <= range1:
answer = answer_list[0]
elif random_value > range1 and random_value <= range2:
answer = answer_list[1]
elif random_value > range2 and random_value <= range3:
answer = answer_list[2]
elif random_value > range3 and random_value <= range4:
answer = answer_list[3]
else:
answer = answer_list[4]
return answer
Technical Problem Solver (기술로 문제를 해결하는 사람)