강화학습의 개념
행동심릭학에서 강화(REinforcement)라는 개념은 동물이 시행착오를 통해 학습하는 방법 중 하나이다.
강화라는 개념을 처음으로 제시한 것은 스키너(Skinner)라는 행동심리학자이다.
행동 심리학에는 시행착오 학습이라는 개념이 있다.
-시행착오 학습은 동물이 이것 저것 시도해보면서 그 결과를 통해 학습하는 것을 말한다.
-스키너는 쥐 실험을 통해 동물이 행동과 그 결과 사이의 관계를 학습하는 것을 확인했다.
스키너는 아래와 같이 상자안에 굶긴 쥐를 집어 넣고 실험을 수행했다.
-굶긴 쥐를 상자에 넣는다.
-쥐는 돌아다니다가 우연히 상자 안에 있는 지렛대를 누르게 된다.
-지렛대를 누르자 먹이가 나온다.
-지렛대를 누르는 행동과 먹이와의 상관관계를 모르는 쥐는 다시 돌아다닌다.
-그러다가 우연히 쥐가 다시 지렛대를 누르면 쥐는 이제 먹이와 지렛대 사이의 관계를 알게 되고 점점 지렛대를 자주 누르게 된다.
-이 과정을 반복하면서 쥐는 지렛대를 누르면 먹이를 먹을 수 있다는 것을 학습한다.
강화라는 것은 동물이 이전에 배우지 않았지만 직접 시도하면서 행동과 그 결과를 나타나는 좋은 보상 사이의 상관관계를 학습하는 것이다.
강화의 핵심은 바로 보상을 얻게 해주는 행동의 빈도 증가이다.
앞의 실험에서 쥐는 페달을 밟았을 때 왜 먹이가 나오는지 모르지만 페달을 밟을 때마다 먹이가 나온다는 것을 알게 되고 상황을 이해 못하더라도 행동과 행동의 결과를 보상을 통해 연결 할 수 있다.
머신러닝과 강화학습
머신러닝은 인공지능의 한 범주로서 컴퓨터가 스스로 학습하게 하는 알고리즘을 개발하는 분야이다.
1959년 아서 사무엘은 머신러닝을 "기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습해서 실행 할 수 있도록 하는 알고리즘을 개발하는 연구 분야" 라고 정의 했다.
머신러닝은 지도학습(supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning) 세가지로 나뉜다.
강화 학습은 정답이 주어진 것은 아니지만 그저 주어진 데이터에 대해 학습하는 것이 아니기 때문에 지도학습과 비지도학습과 그 성격이 다르다.
강화 학습은 보상을 통해 학습한다.
보상은 컴퓨터가 선택한 행동(action)에 대한 환경의 반응이다. 이 보상은 직접적인 답은 아니지만 컴퓨터에게는 간접적인 정답의 역할을 한다.
스스로 학습하는 컴퓨터, 에이전트
강화학습을 통해 스스로 학습하는 컴퓨터를 에이전트(agent)라고 할 것이다.
에이전트는 환경에 대해 사전지식이 없는 상태에서 학습한다.
에이전트는 자신이 놓인 환경에서 자신의 상태를 인식한 후 행동한다.
그러면 환경은 에이전트에게 보상을 주고 다음 상태를 알려준다.
이 보상을 통해 에이전트는 어떤 행동이 좋은 행동인지 간접적으로 알게 된다.
이러한 보상을 지속해서 얻는다면 에이전트는 좋은 행동을 학습할 수 있다.
강화 학습의 목적은 에이전트가 환경을 탐색하면서 얻은 보상들의 합을 최대화하는 "최적의 행동 양식, 또는 정책" 을 학습하는 것이다.
보상은 양수로 설정할 수도 있고 경우에 따라 음수로 설정할 수 도 있다.(보상을 음수로 설정한다면 처벌이 된다.)
상벌을 적절히 융합할 수 있다면 효과적인 학습이 가능하다.
상만 받거나 벌만 받는 것보다 에이전트는 적절한 상벌을 통해 자신이 무엇을 해야 하는지 더 명확하게 알 수 있다.
강화 학습 장점
강화학습의 장점은 환경에 대한 사전지식이 없어도 학습이 가능하다는 것이다.
자전거를 배울 때 자전거의 무게와 핸들 각도, 나의 반응 속도를 생각하면서 자전거를 배우지 않았다.
자전거에 대해 아무것도 모르지만 자전거를 타면서 어떻게 자전거를 타는지를 배웟을 것이다.
에이전트는 어떠한 기능을 학습하려면 다양한 상황에 대한 정보가 있어야 하지만, 이러한 정보 없이 에이전트는 시행착오를 통해 기능을 학습한다.
강화학습 문제
100명의 학생이 있고 학생들의 수학 실력을 비교해서 수학 성적을 높일 전략을 세우려 한다면 어떻게 학생들의 수학 실력을 비교할 수 있을까요?
순차적 행동 결정 문제
가장 간단한 방법은 시험을 통해 수학 실력을 수치화하는 것이다.
에이전트가 학습하고 발전하려면 문제를 수학적으로 표현해야 한다.
순차적으로 행동을 결정하는 문제를 정의할 때 사용하는 방법이 MDP(Markov Decision Process) 이다.
MDP는 순차적 행동 결정 문제를 수학적으로 정의해서 에이전트가 순차적 행동 결정문제에 접근할 수 있게 한다.
순차적 행동 결정 문제의 구성 요소
상태(state)
에이전트의 상태이다.
상태라고 하면 보통 어떠한 정적인 요소만 포함한 현재 에이전트의 정보라고 생각한다.
여기서는 에이전트의 동적인 요소 또한 포함한다. (ex:움직이는 속도)
에이전트가 상태를 통해 상황을 판단해서 행동을 결정하기에 충분한 정보를 제공 해야 한다.
탁구를 치는 에이전트가 있다고 가정할 때, 탁구공의 위치만 알고 속도를 모른다면 에이전트는 탁구를 칠 수가 없다.
에이전트가 탁구를 치는 것을 학습하려면 탁구공의 위치, 속도, 가속도 같은 정보가 필요하다.
행동(action)
에이전트가 어떠한 상태에서 취할 수 있는 행동으로 상 하 좌 우 와 같은 것을 말한다. (게임에서 행동이라면 게임기를 통해 줄 수 있는 입력을 말한다.)
학습이 되지 않은 에이전트는 어떤 행동이 좋은 행동인지에 대한 정보가 전혀 없다. 따라서 무작위로 행동을 취한다.
하지만 에이전트는 학습하면서 특정한 행동들을 할 확률을 높인다. 에이전트가 행동을 취하면 환경은 에이전트에게 보상을 주고 다음 상태를 알려준다.
보상(reward)
보상은 에이전트가 학습할 수 있는 유일한 정보이다.
보상 정보를 통해 에이전트는 자신이 했던 행동들을 평가 할 수 있고 이로 인해 어떤 행동이 좋은 행동인지 알 수 있다.
강화학습의 목표는 시간에 따라 얻는 보상들의 합을 최대로 하는 정책을 찾는 것이다.
보상은 에이전트에 속하지 않는 환경의 일부이다.
에이전트는 어떤 상황에서 얼마의 보상이 나오는지 미리 알지 못한다.
정책(policy)
순차적 행동 결정 문제에서 구해야 할 답은 정책이다.
에이전트가 보상을 얻으려면 행동을 해야 하는데 특정 상태가 아닌 모든 상태에 대해 어떤 행동을 해야 할지 알아야 한다.
이렇게 모든 상태에 대해 에이전트가 어떤 행동을 해야 하는지 정해놓은 것이 정책이다.
순차적 행동 결정 문제를 풀었다고 한다면 제일 좋은 정책을 에이전트가 얻었다는 것이다.
제일 좋은 정책은 최적 정책(optimal policy)라고 하며 에이전트는 최적 정책에 따라 행동 했을 때 보상의 합을 최대로 받을 수 있다.
방대한 상태를 가진 문제에서의 강화학습
방대한 상태(NP)를 가진 문제를 푸는 가장 좋은 예는 알파고 이다.
바둑의 경우의 수는 10의 360승으로서 우주의 원자 수보다 많다.
이보다 더 많은 상태를 가지고 있는 문제가 바로 로봇의 학습 문제이다.
로봇이 관찰하는 정보와 행동, 보상이 모두 연속적이기 때문에 사실상 가능한 경우의 수는 무한대라고 할 수 있다.
로봇에 강화학습을 적용하려면 알파고와 같이 수많은 상태에 대한 정보를 함수와 같은 형태로 근사 하는 인공신경망(Artificial Neural Network)이 필요하다.
강화학습 예시(브레이크 아웃)
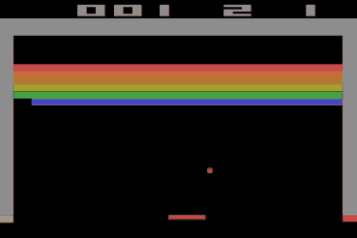
출처 : https://blog.naver.com/aidiid/221166194913
아타리의 고전 게임인 브레이크아웃에 강화학습을 적용한 논문이 딥마인드의 "Playing Atari with Deep Reinforcement Learning" 이다.
딥마인드에서는 에이전트가 단순히 벽돌만 깨는 것을 학습하는 것이 아니고 한 쪽 터널을 뚫어 여러 개의 벽돌을 한꺼번에 깨보는 것도 학습시켰다.
브레이크 아웃의 MDP와 학습 방법
MDP
상태 : 브레이크아웃에서 에이전트가 환경으로부터 받아들이는 상태는 게임화면이다. 에이전트가 상황을 파악할 수 있도록 화면을 연속적으로 4개를 받는다. 이 4개의 화면이 하나의 상태로 에이전트에게 제공된다.
행동 : 제자리, 왼쪽, 오른쪽, 발사가 가능하고 브레이크아웃에서 발사는 게임을 시작할 때 사용한다. 에이전트가 한 상태에서 행동을 결정하면 잠깐 동안 그 행동을 반복한다. 이것은 상태를 화면 4개로 받아 오기 때문에 4개의 화면이 나올 동안에는 같은 행동을 해야 에이전트가 학습 할 수 있다.
보상 : 벽돌이 하나씩 깨질 때마다 보상(1+)을 받고 더 위쪽을 깰수록 더 큰 보상을 받는다. 아무것도 깨지 않을 때는 보상으로(0)을 받는다. 그리고 공을 놓쳐 목숨을 잃을 경우에는 보상으로(-1)을 받는다.
학습
처음에 에이전트는 게임이나 상황에 대해 전혀 모르기 때문에 무작위로 제자리, 왼쪽, 오
른쪽으로 움직인다. 그러다가 에이전트가 우연히 공을 쳐서 벽돌을 깨면 게임 환경으로
부터 보상(+1)을 받는다. 지속적으로 게임을 하면 이러한 일이 반복된다.
• 강화학습을 통해 학습되는 것은 인공신경망이다.
• 입력으로 4개의 연속적인 게임 화면이 들어온다.
• 인공신경망으로 입력이 들어오면 그 상태에서 에이전트가 할 수 있는 행동이 얼마나 좋
은지 출력으로 내놓는다. 행동이 얼마나 좋은지가 행동의 가치가 되고 이것을 큐함수(Q
function)이라고 한다.
• 이 문제에서 사용한 인공신경망은 DQN(Deep Q-Network)을 사용하였다.
• DQN으로 입력이 들어오면 DQN은 그 상태에서 제자리, 왼쪽, 오른쪽 행동의 큐함수를
출력으로 내 놓는다.
• 에이전트는 출력으로 나온 큐함수에 따라서 행동한다.
• 에이전트가 그 행동을 취하면 환경은 에이전트에게 보상과 다음 상태를 알려준다.
• 에이전트는 환경과 상호작용하면서 DQN을 더 많은 보상을 받도록 조금씩 수정한다
