다이내믹 프로그래밍
다이내믹 프로그래밍은 작은 문제가 큰 문제 안에 중첩되어 있는 경우에 작은 문제의 답을 다른 작은 문제에서 이용함으로써 효율적으로 계산하는 방법이다.
다이내믹 프로그래밍으로 벨만 기대 방정식을 추는 것이 정책 이터레이션이며 벨만 최적 방정식을 푸는 것이 가치 이터레이션이다.
리처드 벨만은 1953년 다이내믹 프로그래밍을 처음 소개했다.
다이내믹이라는 말은 그 말이 가리키는 대상이 시간에 따라 변한다는 것을 말한다.
다이내믹 프로그래밍의 기본 개념은 큰 문제 안에 작은 문제로 쪼개서 풀겠다는 것이다. 즉 작은 문제를 해결하고 이를 이용하여 더 큰 문제를 풀어 가는 방식을 말한다.
정책 이터레이션
정책은 에이전트가 모든 상태에서 어떻게 행동할지에 대한 정보이다.
MDP로 정의되는 문제에서 결국 알고 싶은 것은 가장 높은 보상을 얻게 하는 정책을 찾는 것이다.
처음에는 최선의 정책을 알 수가 없으므로 어떤 특정한 정책을 시작으로 계속 발전시켜나가는 방법을 사용한다.
보통 처음에는 무작위로 행동하는 정책으로 시작한다.
최적 정책은 무작위정책이 아니라 현재의 정책을 평가하고 더 나은 정책으로 발전 해야 한다.
정책 이터레이션에서는 평가를 정책평가 (Policy Evaluation) 라고 하며, 발전을 정책 발전(Policy Improvement)이라고 한다.
어떤 정책이 있을 때 그 정책을 정책 평가 과정을 통해 얼마나 좋은지 평가하고 그 평가를 기준으로 정책을 좀 더 나은 정책으로 발전 시킨다.
좀 더 나은 정책이 또 현재의 정책이 되어 위 과정을 반복한다.
정책 평가
가치함수는 현재 정책을 따라갔을 때 받을 보상에 대한 기댓값이기 때문에 좋은 판단 기준이 됩니다.
정책 이터레이션은 이 가치함수를 다이내믹 프로그래밍을 이용하여 구하기 위해서 벨만 기대 방정식을 사용합니다.
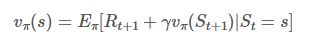
핵심은 주변 상태의 가치함수와 한 타임스텝의 보상만 고려해서 현재 상태의 다음 가치함수를 계산하겠다는 것입니다.
이때 주변 상태의 가치함수들은 여러번 업데이트된 가치함수가 아니므로 참 가치함수가 아닙니다.
따라서 이를 이용해서 구한 현재 상태의 다음 가치함수도 참 값이 아니죠. 하지만 이 계산을 여러번 반복하면 참 값으로 수렴하는 것입니다.
정책 발전
정책 평가만을 반복한다면 현재 정책에 대한 참 가치함수에만 근접할 뿐 최적 정책을 찾을 수는 없습니다. 우리는 정책 평가를 마쳤다면 정책을 발전 시켜야 합니다.
정책 발전의 방법이 정해져있지는 않지만 저희는 가장 널리 알려진 탐욕 정책 발전 을 사용합니다. 이는 우리가 앞에서 배운 큐함수 즉 행동 가치함수를 사용합니다.
큐함수란 어떤 상태에서 어떤 행동을 했을 때 얻게 될 보상들의 합으로 다음과 같이 표현했습니다.
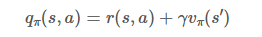
탐욕 정책 발전은 어떤 상태 s에 대한 큐함수 중 가장 큰 큐함수를 가지는 행동만을 선택하는 방법입니다. 눈 앞에 보이는 것 중에서 당장에 가장 큰 이익을 추구하는 것이죠.
따라서 정책 발전을 통해 업데이트된 정책은 다음과 같습니다.
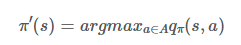
이 탐욕 정책 발전을 사용하면 단기적으로 무조건 이익을 보며 장기적으로는 최적 정책에 수렴할 수 있습니다.
계산에 필요한 정보와 함수는 Env 라는 클래스로 정의돼 있습니다.
env.width, env.height : 그리드월드의 너비와 높이 (그리드월드의 가로, 세로를 정수로 반환)
env.state_after_action(state, action) : 특정 상태에서 특정 행동을 했을 때 에이전트가 가는 다음 상태 ( 행동 후의 상태를 좌표로 표현한 리스트를 반환 ex) [1,2])
env.get_all_states() : 존재하는 모든 상태 ( 모든 상태를 반환)
env.get_reward(state,action) : 특정 상태에서 특정 행동을 했을 때 얻는 보상 (정수의 형태로 보상을 반환)
env.possible_actions : 에이전트가 가능한 행동(상,하,좌,우) ([0,1,2,3]을 반환, 순서대로 상, 하, 좌, 우 를 의미)
출처 : https://developer-lionhong.tistory.com/10
그리드월드에서의 정책 평가
정책 반복 (Policy Iteration) 개요
정책 반복은 크게 두 가지 과정을 반복합니다:
정책 평가 (Policy Evaluation): 현재 정책을 기준으로 가치 함수 계산
정책 개선 (Policy Improvement): 가치 함수 기반으로 정책을 더 나은 방향으로 업데이트
이 두 단계를 반복하다 보면 최적의 정책과 가치 함수에 도달합니다.
import numpy as np
from environment import GraphicDisplay, Env
class PolicyIteration:
def __init__(self, env):
# 환경에 대한 객체 선언
self.env = env
# 가치함수를 2차원 리스트로 초기화
self.value_table = [[0.0] * env.width for _ in range(env.height)]
# 상 하 좌 우 동일한 확률로 정책 초기화
self.policy_table = [[[0.25, 0.25, 0.25, 0.25]] * env.width
for _ in range(env.height)]
# 마침 상태의 설정
self.policy_table[2][2] = []
# 할인율
self.discount_factor = 0.9
# 벨만 기대 방정식을 통해 다음 가치함수를 계산하는 정책 평가
def policy_evaluation(self):
# 다음 가치함수 초기화
next_value_table = [[0.00] * self.env.width for _ in range(self.env.height)]
for state in self.env.get_all_states():
value = 0.0
# 마침 상태의 가치 함수 = 0
if state == [2,2]:
next_value_table[state[0]][state[1]] = value
continue
# 벨만 기대 방정식
for action in self.env.possible_actions:
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value += (self.get_policy(state)[action] *
(reward + self.discount_factor * next_value))
next_value_table[state[0]][state[1]] = value
self.value_table = next_value_table
# 현재 가치 함수에 대해서 탐욕 정책 발전
def policy_improvement(self):
next_policy = self.policy_table
for state in self.env.get_all_states():
if state == [2,2]:
continue
value_list = []
# 반환할 정책 초기화
result = [0.0, 0.0, 0.0, 0.0]
# 모든 행동에 대해서 [보상 + (할인율 * 다음 상태 가치함수)] 계산
for index,action in enumerate(self.env.possible_actions):
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value = reward + self.discount_factor * next_value
value_list.append(value)
# 받을 보상이 최대인 행동들에 대해 탐욕 정책 발전
# 가장 큰 큐함수의 index를 max_idx_list 에 저장
max_idx_list = np.argwhere(value_list == np.amax(value_list))
# 2차원 배열을 1차원 리스트로 바꿔줌
max_idx_list = max_idx_list.flatten().tolist()
# 각 행동을 선택할 행동을 구하기 위해서 1 을 max_idx_list의 길이로 나눠줌.
prob = 1 / len(max_idx_list)
for idx in max_idx_list:
result[idx] = prob
# 해당하는 상태의 정책 업데이트
next_policy[state[0]][state[1]] = result
# 전체 정책 업데이트
self.policy_table = next_policy
# 특정 상태에서 정책에 따라 무작위로 행동을 반환
def get_action(self, state):
policy = self.get_policy(state)
policy = np.array(policy)
return np.random.choice(4, 1, p=policy)[0]
# 상태에 따른 정책 반환
def get_policy(self, state):
return self.policy_table[state[0]][state[1]]
# 가치 함수의 값을 반환
def get_value(self, state):
return self.value_table[state[0]][state[1]]
if __name__ == "__main__":
env = Env()
policy_iteration = PolicyIteration(env)
grid_world = GraphicDisplay(policy_iteration)
grid_world.mainloop()
환경설정
import tkinter as tk
from tkinter import Button
import time
import numpy as np
from PIL import ImageTk, Image
PhotoImage = ImageTk.PhotoImage
UNIT = 100 # 픽셀 수
HEIGHT = 5 # 그리드월드 세로
WIDTH = 5 # 그리드월드 가로
TRANSITION_PROB = 1
POSSIBLE_ACTIONS = [0, 1, 2, 3] # 좌, 우, 상, 하
ACTIONS = [(-1, 0), (1, 0), (0, -1), (0, 1)] # 좌표로 나타낸 행동
REWARDS = []
class GraphicDisplay(tk.Tk):
def __init__(self, agent):
super(GraphicDisplay, self).__init__()
self.title('Policy Iteration')
self.geometry('{0}x{1}'.format(HEIGHT * UNIT, HEIGHT * UNIT + 50))
self.texts = []
self.arrows = []
self.env = Env()
self.agent = agent
self.evaluation_count = 0
self.improvement_count = 0
self.is_moving = 0
(self.up, self.down, self.left, self.right), self.shapes = self.load_images()
self.canvas = self._build_canvas()
self.text_reward(2, 2, "R : 1.0")
self.text_reward(1, 2, "R : -1.0")
self.text_reward(2, 1, "R : -1.0")
def _build_canvas(self):
canvas = tk.Canvas(self, bg='white',
height=HEIGHT * UNIT,
width=WIDTH * UNIT)
# 버튼 초기화
iteration_button = Button(self, text="Evaluate",
command=self.evaluate_policy)
iteration_button.configure(width=10, activebackground="#33B5E5")
canvas.create_window(WIDTH * UNIT * 0.13, HEIGHT * UNIT + 10,
window=iteration_button)
policy_button = Button(self, text="Improve",
command=self.improve_policy)
policy_button.configure(width=10, activebackground="#33B5E5")
canvas.create_window(WIDTH * UNIT * 0.37, HEIGHT * UNIT + 10,
window=policy_button)
policy_button = Button(self, text="move", command=self.move_by_policy)
policy_button.configure(width=10, activebackground="#33B5E5")
canvas.create_window(WIDTH * UNIT * 0.62, HEIGHT * UNIT + 10,
window=policy_button)
policy_button = Button(self, text="reset", command=self.reset)
policy_button.configure(width=10, activebackground="#33B5E5")
canvas.create_window(WIDTH * UNIT * 0.87, HEIGHT * UNIT + 10,
window=policy_button)
# 그리드 생성
for col in range(0, WIDTH * UNIT, UNIT): # 0~400 by 80
x0, y0, x1, y1 = col, 0, col, HEIGHT * UNIT
canvas.create_line(x0, y0, x1, y1)
for row in range(0, HEIGHT * UNIT, UNIT): # 0~400 by 80
x0, y0, x1, y1 = 0, row, HEIGHT * UNIT, row
canvas.create_line(x0, y0, x1, y1)
# 캔버스에 이미지 추가
self.rectangle = canvas.create_image(50, 50, image=self.shapes[0])
canvas.create_image(250, 150, image=self.shapes[1])
canvas.create_image(150, 250, image=self.shapes[1])
canvas.create_image(250, 250, image=self.shapes[2])
canvas.pack()
return canvas
def load_images(self):
up = PhotoImage(Image.open("../img/up.png").resize((13, 13)))
right = PhotoImage(Image.open("../img/right.png").resize((13, 13)))
left = PhotoImage(Image.open("../img/left.png").resize((13, 13)))
down = PhotoImage(Image.open("../img/down.png").resize((13, 13)))
rectangle = PhotoImage(Image.open("../img/rectangle.png").resize((65, 65)))
triangle = PhotoImage(Image.open("../img/triangle.png").resize((65, 65)))
circle = PhotoImage(Image.open("../img/circle.png").resize((65, 65)))
return (up, down, left, right), (rectangle, triangle, circle)
def reset(self):
if self.is_moving == 0:
self.evaluation_count = 0
self.improvement_count = 0
for i in self.texts:
self.canvas.delete(i)
for i in self.arrows:
self.canvas.delete(i)
self.agent.value_table = [[0.0] * WIDTH for _ in range(HEIGHT)]
self.agent.policy_table = ([[[0.25, 0.25, 0.25, 0.25]] * WIDTH
for _ in range(HEIGHT)])
self.agent.policy_table[2][2] = []
x, y = self.canvas.coords(self.rectangle)
self.canvas.move(self.rectangle, UNIT / 2 - x, UNIT / 2 - y)
def text_value(self, row, col, contents, font='Helvetica', size=10,
style='normal', anchor="nw"):
origin_x, origin_y = 85, 70
x, y = origin_y + (UNIT * col), origin_x + (UNIT * row)
font = (font, str(size), style)
text = self.canvas.create_text(x, y, fill="black", text=contents,
font=font, anchor=anchor)
return self.texts.append(text)
def text_reward(self, row, col, contents, font='Helvetica', size=10,
style='normal', anchor="nw"):
origin_x, origin_y = 5, 5
x, y = origin_y + (UNIT * col), origin_x + (UNIT * row)
font = (font, str(size), style)
text = self.canvas.create_text(x, y, fill="black", text=contents,
font=font, anchor=anchor)
return self.texts.append(text)
def rectangle_move(self, action):
base_action = np.array([0, 0])
location = self.find_rectangle()
self.render()
if action == 0 and location[0] > 0: # 상
base_action[1] -= UNIT
elif action == 1 and location[0] < HEIGHT - 1: # 하
base_action[1] += UNIT
elif action == 2 and location[1] > 0: # 좌
base_action[0] -= UNIT
elif action == 3 and location[1] < WIDTH - 1: # 우
base_action[0] += UNIT
# move agent
self.canvas.move(self.rectangle, base_action[0], base_action[1])
def find_rectangle(self):
temp = self.canvas.coords(self.rectangle)
x = (temp[0] / 100) - 0.5
y = (temp[1] / 100) - 0.5
return int(y), int(x)
def move_by_policy(self):
if self.improvement_count != 0 and self.is_moving != 1:
self.is_moving = 1
x, y = self.canvas.coords(self.rectangle)
self.canvas.move(self.rectangle, UNIT / 2 - x, UNIT / 2 - y)
x, y = self.find_rectangle()
while len(self.agent.policy_table[x][y]) != 0:
self.after(100,
self.rectangle_move(self.agent.get_action([x, y])))
x, y = self.find_rectangle()
self.is_moving = 0
def draw_one_arrow(self, col, row, policy):
if col == 2 and row == 2:
return
if policy[0] > 0: # up
origin_x, origin_y = 50 + (UNIT * row), 10 + (UNIT * col)
self.arrows.append(self.canvas.create_image(origin_x, origin_y,
image=self.up))
if policy[1] > 0: # down
origin_x, origin_y = 50 + (UNIT * row), 90 + (UNIT * col)
self.arrows.append(self.canvas.create_image(origin_x, origin_y,
image=self.down))
if policy[2] > 0: # left
origin_x, origin_y = 10 + (UNIT * row), 50 + (UNIT * col)
self.arrows.append(self.canvas.create_image(origin_x, origin_y,
image=self.left))
if policy[3] > 0: # right
origin_x, origin_y = 90 + (UNIT * row), 50 + (UNIT * col)
self.arrows.append(self.canvas.create_image(origin_x, origin_y,
image=self.right))
def draw_from_policy(self, policy_table):
for i in range(HEIGHT):
for j in range(WIDTH):
self.draw_one_arrow(i, j, policy_table[i][j])
def print_value_table(self, value_table):
for i in range(WIDTH):
for j in range(HEIGHT):
self.text_value(i, j, round(value_table[i][j], 2))
def render(self):
time.sleep(0.1)
self.canvas.tag_raise(self.rectangle)
self.update()
def evaluate_policy(self):
self.evaluation_count += 1
for i in self.texts:
self.canvas.delete(i)
self.agent.policy_evaluation()
self.print_value_table(self.agent.value_table)
def improve_policy(self):
self.improvement_count += 1
for i in self.arrows:
self.canvas.delete(i)
self.agent.policy_improvement()
self.draw_from_policy(self.agent.policy_table)
class Env:
def __init__(self):
self.transition_probability = TRANSITION_PROB
self.width = WIDTH
self.height = HEIGHT
self.reward = [[0] * WIDTH for _ in range(HEIGHT)]
self.possible_actions = POSSIBLE_ACTIONS
self.reward[2][2] = 1 # (2,2) 좌표 동그라미 위치에 보상 1
self.reward[1][2] = -1 # (1,2) 좌표 세모 위치에 보상 -1
self.reward[2][1] = -1 # (2,1) 좌표 세모 위치에 보상 -1
self.all_state = []
for x in range(WIDTH):
for y in range(HEIGHT):
state = [x, y]
self.all_state.append(state)
def get_reward(self, state, action):
next_state = self.state_after_action(state, action)
return self.reward[next_state[0]][next_state[1]]
def state_after_action(self, state, action_index):
action = ACTIONS[action_index]
return self.check_boundary([state[0] + action[0], state[1] + action[1]])
@staticmethod
def check_boundary(state):
state[0] = (0 if state[0] < 0 else WIDTH - 1
if state[0] > WIDTH - 1 else state[0])
state[1] = (0 if state[1] < 0 else HEIGHT - 1
if state[1] > HEIGHT - 1 else state[1])
return state
def get_transition_prob(self, state, action):
return self.transition_probability
def get_all_states(self):
return self.all_state
초기상태
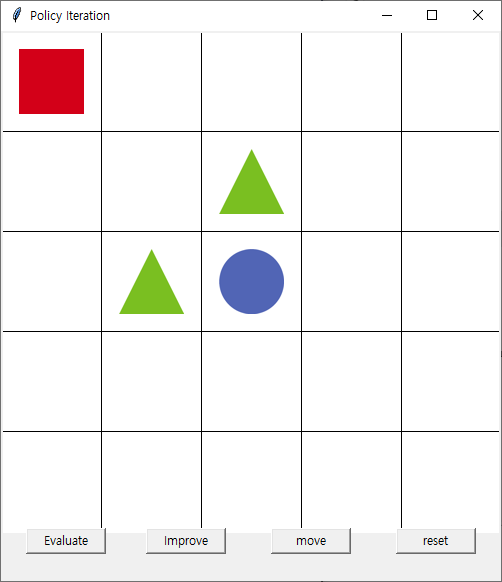
Evaluate 1회 발생시
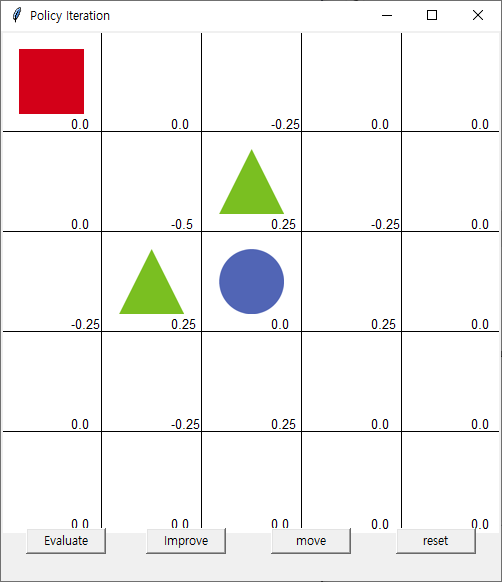
1회 improve
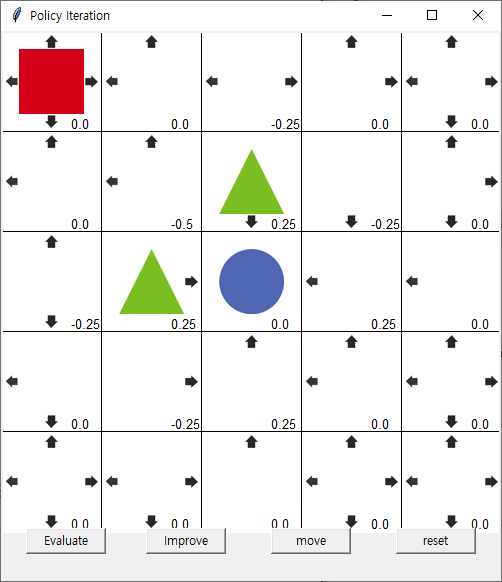
move 발생시 (1,1) (1,2) (2,1) 에만 움직임
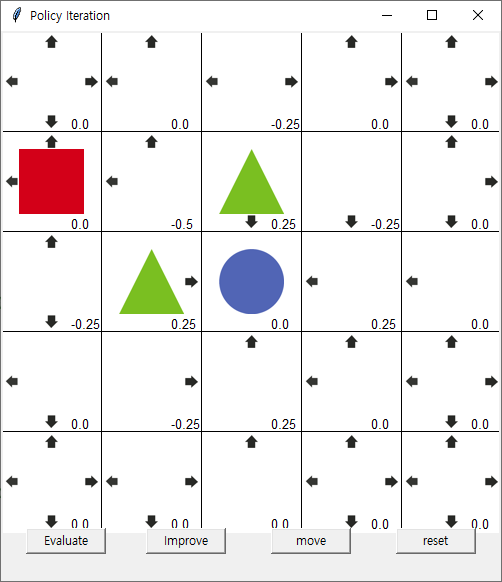
2회 Evaluate
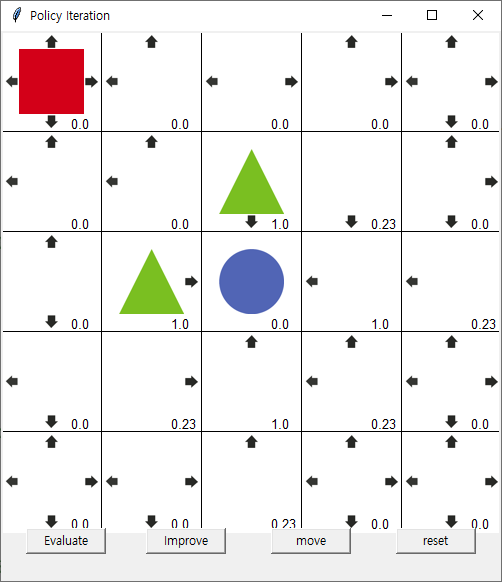
2회 imporve
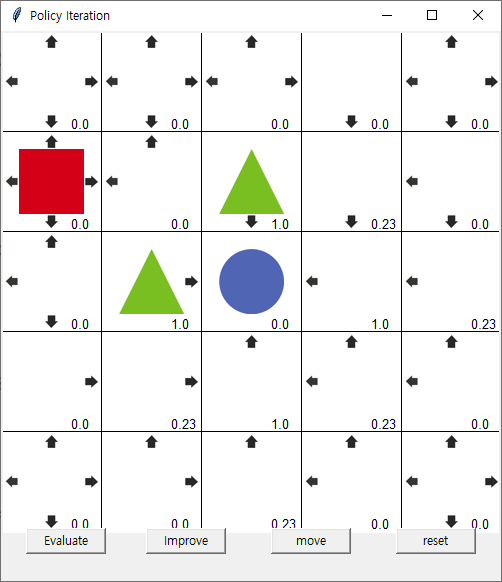
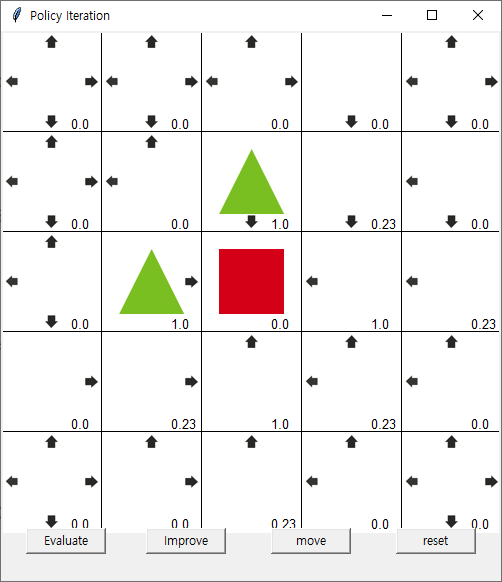
중앙까지 길이 생겨서 도달
할인율 0.9의 의미와 이유
할인율 (γ, gamma): 미래 보상에 대한 현재 가치의 가중치
공식적으로는 다음과 같은 식에서 사용됩니다:
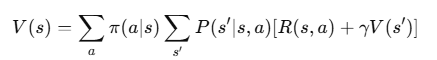
왜 0.9로 설정했는가?
0.9는 미래 보상을 꽤 중요하게 여기되, 현재 보상보단 약간 덜 중요하게 여기는 수준입니다.
0 < γ < 1 범위 내에서:
γ = 0 → 오직 현재 보상만 고려 (미래 무시)
γ = 1 → 미래 보상도 현재와 동등하게 고려 (무한합 문제 발생 가능)
γ = 0.9 → 미래 보상은 고려하되, 현재보다 점점 덜 중요
예시:
보상이 매 타임스텝에 1씩 주어진다고 가정하면
예시:
보상이 매 타임스텝에 1씩 주어진다고 가정하면
Step γ^t 보상의 현재 가치
0 1 1
1 0.9 0.9
2 0.81 0.81
3 0.729 0.729
... ... ...
→ 시간이 흐를수록 보상의 중요도는 감소정리: 할인율 0.9가 의미하는 바
정책 반복의 안정성과 수렴성을 고려할 때 γ = 0.9는 매우 일반적인 선택입니다.
너무 낮으면 미래를 고려하지 못하고, 너무 높으면 수렴 속도가 느려지며 정책이 불안정할 수 있습니다.
환경 특성(에이전트가 얼마나 오래 머무는지 등)에 따라 튜닝하지만, 0.9는 실용적인 기본값입니다.
가치 이터레이션
명시적인 정책과 내재적인 정책
정책 이터레이션은 명시적인(explicit)정책이며, 그 정책을 평가하는 도구로서 가치함수를 사용한다.
아래 그림과 같이 정책과 가치함수는 명확히 분리되어 있다.
정책과 가치함수가 명확히 분리되어 있다는 점은 정책 이터레이션이 벨만 기대 방정식을 이용하는 이유가 된다.
만일 정책이 결정적인 형태로만 정의 되고, 현재의 가치함수가 최적은 아니지만 최적이라고 가정하고 그 가치함수에 대해 결정적인 형태의 정책을 적용하는 것을 가치 이터레이션(value iteration) 이라고 한다.
즉 위와 같은 행동을 반복적으로 시행 해줌으로써 최적 가치 함수에 도달하고 최적 정책을 구할 수 있다.
벨만 최적 방정식과 가치 이터레이션
가치함수 안에 내재적으로 정책이 포함되어 있다.
시작부터 최적 정책을 가정하기 때문에 정책 발전이 필요 없다.
행동가치 함수에서 가장 높은 값
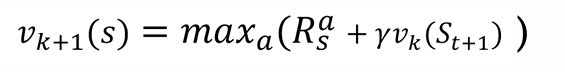
import numpy as np
from environment import GraphicDisplay, Env
class ValueIteration:
def __init__(self, env):
self.env = env
self.value_table = [[0.0] * env.width for _ in range(env.height)]
self.discount_factor = 0.9
def value_iteration(self):
next_value_table = [[0.0] * self.env.width
for _ in range(self.env.height)]
for state in self.env.get_all_states():
if state == [2, 2]:
next_value_table[state[0]][state[1]] = 0.0
continue
# 벨만 최적 방정식
value_list = []
for action in self.env.possible_actions:
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value_list.append((reward + self.discount_factor * next_value))
# 최댓값을 다음 가치 함수로 대입
next_value_table[state[0]][state[1]] = max(value_list)
self.value_table = next_value_table
# 현재 가치 함수로부터 행동을 반환
def get_action(self, state):
if state == [2,2]:
return []
# 모든 행동에 대해 큐함수 (보상 + (감가율 * 다음 상태 가치함수))를 계산
value_list = []
for action in self.env.possible_actions:
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value = (reward + self.discount_factor * next_value)
value_list.append(value)
# 최대 큐 함수를 가진 행동(복수일 경우 여러 개)을 반환
max_idx_list = np.argwhere(value_list == np.amax(value_list))
action_list = max_idx_list.flatten().tolist()
return action_list
def get_value(self, state):
return self.value_table[state[0]][state[1]]
if __name__ == "__main__":
env = Env()
value_iteration = ValueIteration(env)
grid_world = GraphicDisplay(value_iteration)
grid_world.mainloop()
다이내믹 프로그래밍의 한계
다이내믹 프로그래밍은 계산을 빨리하는 것이지 학습하는 것이 아니다(머신러닝이 아님)
계산복잡도 높다
차원이 늘어나면 상태의 수가 지수적으로 증가한다.
환경에 대한 완벽한 정보가 필요하다.
