vgg16
import os
import glob
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
import torchvision.models as models
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" # cuda 여러개 병렬처리 사용
os.environ["CUDA_VISIBLE_DEVICES"]= "0"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
def display_images(image_paths, title, max_images=4):
"""지정된 경로의 이미지를 최대 4개까지 출력합니다."""
plt.figure(figsize=(12, 3))
for i, image_path in enumerate(image_paths[:max_images]):
img = plt.imread(image_path)
plt.subplot(1, max_images, i+1)
plt.imshow(img)
plt.title(title)
plt.axis('off')
plt.show()
#########################################################################################################
# categories = ['Train santa', 'Train normal', 'Val santa', 'Val normal', 'Test santa', 'Test normal' ]
#
# for category in categories:
# image_paths = glob.glob(
# f'../data/santaImage/{category.lower().replace("","/")}/*')
# display_images(image_paths, category)
# print(f"{category} 총 이미지 수: {len(image_paths)}")
'''
# 바 그래프 생성
plt.figure(figsize=(10,6))
plt.bar(categories, [len(glob.glob(
f'data/santaImage/{category.lower().replace(" ", "/")}/*'))
for category in categories], color = ['blue', 'orange', 'green', 'red'])
plt.title('Number of Images per Category')
'''
#########################################################################################################
# 데이터 전처리 정의
#########################################################################################################
transform = transforms.Compose([
transforms.Resize((224,224)), # 이미지 크기 조정
transforms.RandomRotation(30), # 이미지를 최대 30도까지 무작위로 회전
transforms.ToTensor(), # 이미지를 텐서로 변환
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 정규화 (ImageNormalize)
])
train_path = '../data/santaImage/train'
val_path = '../data/santaImage/val'
# 데이터셋 로드 및 데이터 로더 생성
train_dataset = ImageFolder(train_path, transform=transform)
val_dataset = ImageFolder(val_path, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size = 16, shuffle=False)
#########################################################################################################
class VGG19(nn.Module):
def __init__(self, num_classes=1000):
super(VGG19, self).__init__()
self.features = nn.Sequential(
#########################################################################################################
# Conv Block 1
nn.Conv2d(3,64, kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64,64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
# Conv Block 2
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 3
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 4
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv Block 5
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
#########################################################################################################
)
self.classifier = nn.Sequential(
#########################################################################################################
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes) # 기존 논문에서는 1000개의 클래스 분류 문제
# 시그모이드 활성화 함수는 nn.BCEWithLogitsLoss 에 포함
#########################################################################################################
)
def forward(self, x):
#########################################################################################################
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
#########################################################################################################
# 사전 학습된 VGG19 모델 불러오기
#########################################################################################################
pretrained_vgg19 = models.vgg19(pretrained=True)
# 새로 정의한 모델 인스턴스 생성
net = VGG19(num_classes=1000) # 이진 분류 문제 with BCEWithLogitsLoss
# 사전 학습 모델의 features 부분에서 가중치 추출
pretrained_keys = set(pretrained_vgg19.features.state_dict().keys())
# 사전 학습된 모델에서 커스텀 모델로 가중치 복사 시도
result = net.features.load_state_dict(pretrained_vgg19.features.state_dict(), strict=False)
# 복사 후 커스텀 모델의 features 부분에서 가중치 추출
custom_keys = set(net.features.state_dict().keys())
# 성공적으로 복사된 가중치(커스텀 모델과 사전 학습된 모델 모두에 존재)
successfully_copied_keys = pretrained_keys.intersection(custom_keys)
# 커스텀 모델에 있지만 사전 학습된 모델에 없는 가중치
missing_keys = custom_keys - pretrained_keys
# 사전 학습된 모델에 있지만 커스텀 모델에 없는 가중치
unexpected_keys = pretrained_keys - custom_keys
#########################################################################################################
print("성공적으로 복사된 가중치:", successfully_copied_keys)
print("커스텀 모델에는 있지만 사전 학습된 모델에는 없는 가중치 (누락):", result.missing_keys)
print("사전 학습된 모델에는 있지만 커스텀 모델에는 없는 가중치 (예상치 못한):", result.unexpected_keys) # net 모델에 없는데 pretrained_vgg19 가중치 파일에는 존재하는 항목의 이름이 리스트로 반환
#########################################################################################################
for param in net.features.parameters():
param.requires_grad = False
print(net.classifier)
net.classifier[6] = nn.Linear(4096,1)
for param in net.classifier.parameters():
param.requires_grad = True
net = net.to(device)
print(net)
loss_func = nn.BCEWithLogitsLoss()
#########################################################################################################
def validate_model(net, val_loader, loss_func):
net.eval() # 모델을 평가 모드로 설정
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
labels = labels.float().unsqueeze(1) # 레이블을 float 타입으로 변환 및 차원 맞춤
outputs = net(inputs)
val_loss += loss_func(outputs, labels).item()
predicted = torch.sigmoid(outputs) > 0.5
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss /= len(val_loader)
val_accuracy = 100 * correct / total
return val_loss, val_accuracy
import torch.optim as optim
def train_model(optimizer_name, net, train_loader, val_loader, loss_func, num_epochs=10):
#########################################################################################################
# optimizer 설정
if optimizer_name == 'SGD':
optimizer = optim.SGD(net.parameters(), lr=0.00001, momentum=0.9)
elif optimizer_name == 'Adam':
optimizer = optim.Adam(net.parameters(), lr=0.00001, betas=(0.9,0.999))
elif optimizer_name == 'RAdam':
optimizer = optim.RAdam(net.parameters(), lr=0.00001, betas=(0.9,0.999))
else:
raise ValueError(f"Unsupported optimizer: {optimizer_name}")
#########################################################################################################
# 학습/검증 손실과 검증 정확도를 저장할 리스트
train_losses=[]
val_losses = []
val_accuracies = []
#########################################################################################################
for epoch in range(num_epochs):
net.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
labels = labels.float().unsqueeze(1) # 레이블을 float 타입으로 변환 및 차원 맞춤
optimizer.zero_grad()
outputs = net(inputs)
loss = loss_func(outputs, labels) # 손실 계산
loss.backward()
optimizer.step()
running_loss += loss.item()
#########################################################################################################
# 매 에포크마다 평균 학습 손실 계산
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
# 검증 손실 및 정확도 계산
val_loss, val_accuracy = validate_model(net, val_loader, loss_func)
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
print(f'[{optimizer_name}] Epoch {epoch + 1}, '
f'Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}, '
f'Validation Accuracy: {val_accuracy:.2f}%')
return train_losses, val_losses, val_accuracies
train_losses_Adam, val_losses_Adam, val_accuracies_Adam = (
train_model('Adam', net, train_loader, val_loader, loss_func))
# 학습 손실과 검증 정확도 그래프 그리기
plt.figure(figsize=(15,10))
# 학습 손실 그래프
plt.subplot(3,1,1) # 3행 1열의 첫 번째 위치
plt.plot(train_losses_Adam, label='Adam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
# plt.ylim(0, 0.2)
# 검증 손실 그래프
plt.subplot(3,1,2) # 3행 1열의 두 번째 위치
plt.plot(val_losses_Adam, label='Adam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Validation Loss Over Epochs')
plt.legend()
#plt.ylim(0, 1.5)
# 검증 정확도 그래프
plt.subplot(3,1,3) # 3행 1열의 세 번째 위치
plt.plot(val_accuracies_Adam, label='Adam', color='green' )
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
#plt.ylim(80, 100)
plt.tight_layout()
plt.show()C:\Users\hi\Desktop\PS\python_lib\Scripts\python.exe C:\Users\hi\PycharmProjects\DeepVision_part\day1\vgg16Ex.py
cuda
C:\Users\hi\Desktop\PS\python_lib\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
C:\Users\hi\Desktop\PS\python_lib\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG19_Weights.IMAGENET1K_V1`. You can also use `weights=VGG19_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
성공적으로 복사된 가중치: {'7.weight', '5.weight', '0.bias', '19.bias', '28.bias', '30.bias', '7.bias', '14.weight', '30.weight', '2.bias', '0.weight', '12.bias', '10.weight', '14.bias', '23.weight', '21.weight', '28.weight', '34.bias', '32.bias', '23.bias', '12.weight', '25.weight', '16.bias', '32.weight', '2.weight', '34.weight', '5.bias', '25.bias', '21.bias', '19.weight', '16.weight', '10.bias'}
커스텀 모델에는 있지만 사전 학습된 모델에는 없는 가중치 (누락): []
사전 학습된 모델에는 있지만 커스텀 모델에는 없는 가중치 (예상치 못한): []
Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
VGG19(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1, bias=True)
)
)
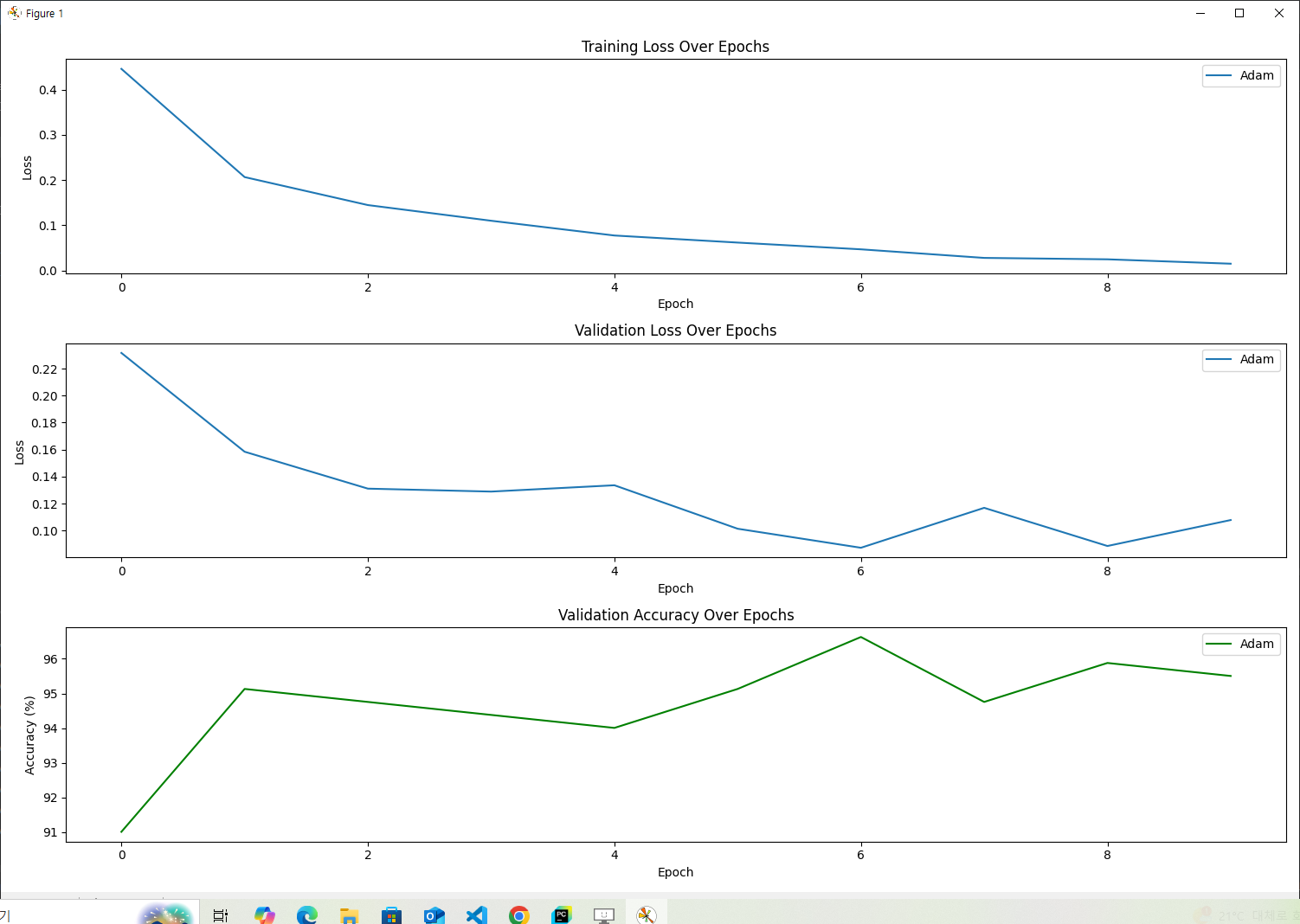
[Adam] Epoch 1, Train Loss: 0.445799, Val Loss: 0.231588, Validation Accuracy: 91.01%
[Adam] Epoch 2, Train Loss: 0.206486, Val Loss: 0.158461, Validation Accuracy: 95.13%
[Adam] Epoch 3, Train Loss: 0.144582, Val Loss: 0.131150, Validation Accuracy: 94.76%
[Adam] Epoch 4, Train Loss: 0.109928, Val Loss: 0.128969, Validation Accuracy: 94.38%
[Adam] Epoch 5, Train Loss: 0.077303, Val Loss: 0.133646, Validation Accuracy: 94.01%
[Adam] Epoch 6, Train Loss: 0.061653, Val Loss: 0.101470, Validation Accuracy: 95.13%
[Adam] Epoch 7, Train Loss: 0.046735, Val Loss: 0.087388, Validation Accuracy: 96.63%
[Adam] Epoch 8, Train Loss: 0.027756, Val Loss: 0.116941, Validation Accuracy: 94.76%
[Adam] Epoch 9, Train Loss: 0.024646, Val Loss: 0.088697, Validation Accuracy: 95.88%
[Adam] Epoch 10, Train Loss: 0.014942, Val Loss: 0.107904, Validation Accuracy: 95.51%
구글 colab 이론 링크
ResNet
https://colab.research.google.com/drive/1AvXy0kh8fLRhCBVC5cBuN9z6Dlh5EAe3
DenseNet
https://colab.research.google.com/drive/1S4yCPxy1EE4WOVcaPa1L9THmTPAc0p-W
Resnet

import os
import glob
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
import torchvision.models as models
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('Device:', device)
print('Count of using GPUs:', torch.cuda.device_count())
print('Current cuda device:', torch.cuda.current_device())
# 이미지를 출력하는 함수
def display_images(image_paths, title, max_images=4):
"""지정된 경로의 이미지를 최대 4개까지 출력합니다."""
plt.figure(figsize=(12, 3))
for i, image_path in enumerate(image_paths[:max_images]):
img = plt.imread(image_path)
plt.subplot(1, max_images, i+1)
plt.imshow(img)
plt.title(title)
plt.axis('off')
plt.show()
# 이미지와 바 그래프 출력
# categories = ['Train chihuahua', 'Train muffin', 'Val chihuahua', 'Val muffin', 'Test chihuahua', 'Test muffin']
#
# for category in categories:
# image_paths = glob.glob(f'data/images/{category.lower().replace(" ", "/")}/*')
# display_images(image_paths, category)
# print(f"{category} 총 이미지 수: {len(image_paths)}")
# # 바 그래프 생성
# plt.figure(figsize=(10, 6))
# plt.bar(categories, [len(glob.glob(f'data/images/{category.lower().replace(" ", "/")}/*')) for category in categories], color=['blue', 'orange', 'green', 'red'])
# plt.title('Number of Images per Category')
# plt.xlabel('Category')
# plt.ylabel('Number of Images')
# plt.xticks(rotation=45)
# plt.show()
from imgaug import augmenters as iaa
import numpy as np
##############################################################################################################
##############################################################################################################
# imgaug를 사용한 커스텀 데이터셋 정의
class ImgAugTransform:
def __init__(self):
##############################################################################################################
self.aug = iaa.Sequential([
iaa.LinearContrast((0.75,1.5)), # 대비 조절
iaa.Crop(percent=(0,0.2)), # 이미지의 0%에서 20%까지 무작위로 잘라냄
iaa.GaussianBlur(sigma=(0.0, 3.0)), # 가우시안 블러
iaa.AdditiveGaussianNoise(scale=(10,60)), # 가우시안 노이즈 추가
iaa.Fliplr(0.5), # 50 % 확률로 좌우 반전
iaa.Flipud(0.2), # 20 % 확률로 상하 반전
iaa.Affine(rotate=(-20, 20), mode='symmetric'), # -20 도에서 20 도 사이로 회전
iaa.Affine(scale=(0.5, 1.5)), # 50 % 에서 150 % 사이로 확대/축소
])
##############################################################################################################
def __call__(self, img):
##############################################################################################################
img = np.array(img)
return self.aug.augment_image(img)
##############################################################################################################
# 커스텀 데이터셋 클래스
class CustomDataset(ImageFolder):
def __init__(self, root, imgaug=None, transform=None):
##############################################################################################################
super(CustomDataset, self).__init__(root, transform=transform)
self.imgaug_transform = imgaug # imgaug 매개변수를 직접 저장
##############################################################################################################
def __getitem__(self, index):
##############################################################################################################
path, target = self.samples[index]
img = self.loader(path)
#imgaug 증강 적용
if self.imgaug_transform is not None:
img = self.imgaug_transform(img)
# imgaug는 numpy 배열을 반환하므로, PIL Image로 다시 변환
img = Image.fromarray(img)
# ToTensor 및 Normalize 적용
if self.transform is not None:
img = self.transform(img)
return img, target
##############################################################################################################
from torchvision import transforms
pytorch_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 이미지 크기 조정
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 데이터셋 및 데이터 로더 초기화
train_path = 'data/images/train'
val_path = 'data/images/val'
##############################################################################################################
train_dataset = CustomDataset(train_path,imgaug=ImgAugTransform(), transform=pytorch_transforms)
val_dataset = CustomDataset(val_path,imgaug=None, transform=pytorch_transforms)
##############################################################################################################
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
def imshow(img, size=(20, 20), mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)):
img = img.numpy().transpose((1, 2, 0))
mean = np.array(mean)
std = np.array(std)
img = std * img + mean # 역정규화
img = np.clip(img, 0, 1) # 값이 0과 1 사이에 오도록 클리핑
plt.figure(figsize=size)
plt.imshow(img)
plt.axis('off')
plt.show()
# DataLoader를 이용하여 배치 데이터 가져오기
dataiter = iter(train_loader)
images, _ = next(dataiter)
from torchvision.utils import make_grid
# 이미지 그리드 생성 및 시각화, nrow를 조정하여 한 줄에 표시되는 이미지의 수 조정
imshow(make_grid(images[:8], nrow=4), size=(20, 10))
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
##############################################################################################################
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
##############################################################################################################
def forward(self, x):
##############################################################################################################
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
##############################################################################################################
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
##############################################################################################################
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3,64,kernel_size=7, stride=1,padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block,64, layers[0])
self.layer2 = self._make_layer(block,128,layers[1], stride=2)
self.layer3 = self._make_layer(block,256,layers[2],stride=2)
self.layer4 = self._make_layer(block,512,layers[3],stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
##############################################################################################################
def _make_layer(self, block, out_channels, blocks, stride=1):
##############################################################################################################
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
##############################################################################################################
def forward(self, x):
##############################################################################################################
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
##############################################################################################################
# Ex)
# 64 64 256, 256 256 256, 256 256 256 -> 128 128 512, 512 512 512, 512 512 512, 512 512 512 ->
# 256 256 1024, 1024 1024 1024, 1024 1024 1024, 1024 1024 1024, 1024 1024 1024, 1024 1024 1024 -> 512 512 2048, 2048 2048 2048, 2048 2048 2048
##############################################################################################################
def resnet50(num_classes=1000):
return ResNet(Bottleneck, [3,4,6,3], num_classes)
# 사전 학습된 resnet50 모델 불러오기
pretrained_resnet50 = models.resnet50(pretrained=True)
# 새로 정의한 모델 인스턴스 생성
net = resnet50(num_classes=1000)
##############################################################################################################
# 사전 학습된 모델의 features 부분에서 가중치 추출
pretrained_keys = set(pretrained_resnet50.state_dict().keys())
# 사전 학습된 모델에서 커스텀 모델로 가중치 복사 시도
result = net.load_state_dict(pretrained_resnet50.state_dict(), strict=False)
# 복사 후 커스텀 모델의 features 부분에서 가중치 추출
custom_keys = set(net.state_dict().keys())
# 성공적으로 복사된 가중치 (커스텀 모델과 사전 학습된 모델 모두에 존재)
successfully_copied_keys = pretrained_keys.intersection(custom_keys)
# 커스텀 모델에 있지만 사전 학습된 모델에 없는 가중치
missing_keys = custom_keys - pretrained_keys
# 사전 학습된 모델에 있지만 커스텀 모델에 없는 가중치
unexpected_keys = pretrained_keys - custom_keys
print("성공적으로 복사된 가중치:", successfully_copied_keys)
print("커스텀 모델에는 있지만 사전 학습된 모델에는 없는 가중치 (누락):", result.missing_keys)
print("사전 학습된 모델에는 있지만 커스텀 모델에는 없는 가중치 (예상치 못한):", result.unexpected_keys) # net 모델에 없는데 pretrained_vgg19 가중치 파일에는 존재하는 항목의 이름이 리스트로 반환
print(net)
# 모델의 모든 파라미터를 고정
for param in net.parameters():
param.requires_grad = False
# classifier 부분의 가중치는 재학습을 위해 새로 정의
net.fc = nn.Linear(2048, 2)
for param in net.fc.parameters():
param.requires_grad = True
net = net.to(device)
criterion = nn.CrossEntropyLoss()
import torch.optim as optim
def train_model(optimizer_name, net, train_loader, val_loader, criterion, num_epochs=10):
# optimizer설정
if optimizer_name == 'SGD':
optimizer = optim.SGD(net.parameters(), lr=0.00003, momentum=0.9)
elif optimizer_name == 'Adam':
optimizer = optim.Adam(net.parameters(), lr=0.00003, betas=(0.9, 0.999))
elif optimizer_name == 'RAdam':
optimizer = optim.RAdam(net.parameters(), lr=0.00003, betas=(0.9, 0.999))
else:
raise ValueError(f"Unsupported optimizer: {optimizer_name}")
# 학습/검증 손실과 검증 정확도를 저장할 리스트
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(num_epochs):
net.train() # 모델을 학습 모드로 설정
running_loss = 0.0
for i, data in enumerate(train_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 매 에포크마다 평균 학습 손실 계산
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
# 검증 손실 계산
val_loss = 0.0
net.eval() # 모델을 평가 모드로 설정
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
val_loss += loss.item()
val_loss /= len(val_loader)
val_losses.append(val_loss)
val_accuracy = 100 * correct / total
val_accuracies.append(val_accuracy)
print(f'[{optimizer_name}] Epoch {epoch + 1}, Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}, Validation Accuracy: {val_accuracy:.2f}%')
return train_losses, val_losses, val_accuracies
train_losses_Adam, val_losses_Adam, val_accuracies_Adam = train_model('Adam', net, train_loader, val_loader, criterion)
# 학습 손실과 검증 정확도 그래프 그리기
plt.figure(figsize=(15, 10))
# 학습 손실 그래프
plt.subplot(3, 1, 1) # 3행 1열의 첫 번째 위치
plt.plot(train_losses_Adam, label='Adam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
# 검증 손실 그래프
plt.subplot(3, 1, 2) # 3행 1열의 두 번째 위치
plt.plot(val_losses_Adam, label='Adam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Validation Loss Over Epochs')
plt.legend()
# 검증 정확도 그래프
plt.subplot(3, 1, 3) # 3행 1열의 세 번째 위치
plt.plot(val_accuracies_Adam, label='Adam', color='green')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
plt.tight_layout()
plt.show()
C:\Users\hi\Desktop\PS\python_lib\Scripts\python.exe C:\Users\hi\PycharmProjects\DeepVision_part\day1\ResNetEx.py
Device: cuda
Count of using GPUs: 1
Current cuda device: 0
C:\Users\hi\Desktop\PS\python_lib\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
C:\Users\hi\Desktop\PS\python_lib\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
성공적으로 복사된 가중치: {'layer2.0.bn2.weight', 'layer3.3.bn1.weight', 'layer2.1.conv1.weight', 'layer3.0.conv1.weight', 'layer1.1.bn3.running_var', 'layer2.3.bn2.num_batches_tracked', 'layer4.0.downsample.1.num_batches_tracked', 'layer3.3.bn2.weight', 'layer1.0.downsample.0.weight', 'layer4.0.bn2.num_batches_tracked', 'layer2.3.bn3.weight', 'layer3.0.bn1.num_batches_tracked', 'layer3.5.bn2.running_var', 'layer4.1.bn1.bias', 'layer2.3.bn2.running_mean', 'layer3.2.bn2.num_batches_tracked', 'layer3.4.bn3.num_batches_tracked', 'layer4.0.conv1.weight', 'layer1.1.bn3.bias', 'layer3.1.bn1.running_var', 'layer1.0.bn3.running_var', 'layer2.1.bn3.running_var', 'layer3.2.bn2.weight', 'layer3.0.downsample.0.weight', 'layer1.0.bn1.num_batches_tracked', 'conv1.weight', 'layer3.1.bn3.weight', 'layer4.2.conv1.weight', 'layer3.2.conv3.weight', 'layer4.0.downsample.1.bias', 'layer4.2.bn3.weight', 'layer2.1.bn2.running_mean', 'layer3.4.bn2.weight', 'layer3.0.bn2.running_mean', 'layer3.4.bn1.weight', 'layer4.0.bn2.weight', 'layer4.2.bn2.running_var', 'layer2.0.downsample.1.num_batches_tracked', 'layer3.4.bn2.running_var', 'layer1.2.conv1.weight', 'layer4.2.bn3.num_batches_tracked', 'layer4.1.bn2.bias', 'layer2.2.bn3.weight', 'layer4.1.bn2.running_var', 'layer3.1.conv3.weight', 'layer3.3.bn2.bias', 'layer4.0.bn3.running_mean', 'fc.weight', 'layer3.1.bn3.bias', 'layer3.2.bn3.running_var', 'layer3.4.bn2.num_batches_tracked', 'layer3.2.bn3.weight', 'layer3.0.bn2.weight', 'layer3.4.bn1.bias', 'layer3.0.bn3.num_batches_tracked', 'layer3.3.bn1.running_var', 'layer1.0.bn3.bias', 'layer3.2.bn2.bias', 'layer3.0.downsample.1.num_batches_tracked', 'layer1.2.bn1.bias', 'layer1.0.bn1.running_mean', 'layer4.1.bn2.weight', 'layer4.0.bn1.num_batches_tracked', 'layer3.0.bn1.running_var', 'layer1.0.bn2.weight', 'layer3.2.bn2.running_var', 'layer1.2.bn1.num_batches_tracked', 'layer4.0.bn2.bias', 'layer3.5.bn3.running_var', 'layer2.2.conv3.weight', 'layer4.1.bn3.weight', 'layer3.0.downsample.1.running_var', 'layer3.5.bn3.num_batches_tracked', 'layer4.2.bn1.running_mean', 'layer1.2.bn3.running_mean', 'layer2.0.bn3.bias', 'layer3.3.bn3.bias', 'layer2.2.bn1.weight', 'layer4.0.bn3.running_var', 'layer2.0.bn3.running_mean', 'layer4.1.bn3.bias', 'layer2.3.conv2.weight', 'layer1.2.bn1.weight', 'layer1.2.conv3.weight', 'layer3.0.bn3.bias', 'bn1.running_mean', 'layer4.2.conv3.weight', 'layer2.0.conv3.weight', 'layer3.2.conv2.weight', 'layer3.3.bn3.running_mean', 'layer1.0.bn3.weight', 'layer2.2.bn2.weight', 'layer2.2.bn2.num_batches_tracked', 'layer3.4.bn3.bias', 'layer2.1.bn3.weight', 'layer1.2.bn2.running_var', 'layer3.3.bn3.num_batches_tracked', 'layer2.3.bn2.running_var', 'layer3.5.bn1.bias', 'layer1.1.conv3.weight', 'layer3.5.bn1.running_var', 'layer2.0.downsample.1.running_var', 'layer1.0.bn2.num_batches_tracked', 'layer3.0.bn1.running_mean', 'bn1.running_var', 'layer4.2.bn1.running_var', 'layer2.3.bn2.weight', 'layer3.1.bn1.num_batches_tracked', 'layer4.0.bn3.bias', 'layer4.0.bn1.running_mean', 'layer3.4.bn2.bias', 'layer2.1.bn3.running_mean', 'layer4.0.conv2.weight', 'layer3.3.conv2.weight', 'layer1.0.downsample.1.running_var', 'layer3.3.bn1.num_batches_tracked', 'layer2.3.bn1.running_var', 'layer3.2.bn3.num_batches_tracked', 'layer3.3.bn3.weight', 'layer2.1.bn3.bias', 'layer4.0.downsample.1.weight', 'layer2.0.bn1.running_mean', 'layer1.0.downsample.1.num_batches_tracked', 'layer1.1.bn3.running_mean', 'layer1.2.conv2.weight', 'layer4.0.bn1.running_var', 'layer2.0.bn2.running_mean', 'layer4.1.conv3.weight', 'layer2.1.bn2.num_batches_tracked', 'layer3.0.bn1.bias', 'layer4.2.bn2.bias', 'layer3.1.conv1.weight', 'layer4.1.bn3.running_mean', 'layer3.5.bn1.running_mean', 'layer2.0.conv1.weight', 'layer3.1.bn2.running_mean', 'layer2.0.bn1.running_var', 'layer3.0.bn2.running_var', 'layer1.2.bn2.bias', 'layer3.0.bn2.bias', 'layer1.2.bn1.running_var', 'layer2.3.bn3.num_batches_tracked', 'layer4.1.bn1.weight', 'layer1.2.bn3.running_var', 'layer1.1.bn2.running_mean', 'layer2.0.bn2.bias', 'layer3.1.bn2.running_var', 'layer2.0.bn1.weight', 'layer4.2.bn2.num_batches_tracked', 'layer3.0.bn3.running_mean', 'layer3.3.bn2.running_var', 'layer3.5.bn2.bias', 'layer1.2.bn2.running_mean', 'layer2.1.bn1.num_batches_tracked', 'layer2.0.bn1.num_batches_tracked', 'layer3.4.conv3.weight', 'layer2.3.conv3.weight', 'layer1.0.bn3.num_batches_tracked', 'layer1.0.conv1.weight', 'layer3.5.bn3.weight', 'layer2.2.bn3.num_batches_tracked', 'layer1.1.bn1.weight', 'fc.bias', 'layer3.2.bn2.running_mean', 'layer3.3.bn2.running_mean', 'layer3.3.conv3.weight', 'layer2.0.bn2.num_batches_tracked', 'layer3.3.bn2.num_batches_tracked', 'layer3.0.bn3.running_var', 'layer2.2.conv2.weight', 'layer1.1.bn2.num_batches_tracked', 'layer4.0.downsample.0.weight', 'layer4.0.bn1.weight', 'layer2.1.bn1.bias', 'layer3.3.bn3.running_var', 'layer2.0.bn2.running_var', 'layer3.2.bn1.bias', 'layer4.1.bn1.num_batches_tracked', 'layer1.1.conv1.weight', 'layer3.5.bn2.weight', 'layer3.4.bn3.weight', 'layer4.0.bn2.running_var', 'layer3.2.bn3.bias', 'layer3.0.downsample.1.bias', 'layer2.3.bn1.bias', 'layer2.2.bn2.running_mean', 'layer2.1.conv2.weight', 'layer3.5.conv3.weight', 'layer3.5.bn3.bias', 'layer3.5.conv2.weight', 'layer4.2.bn2.running_mean', 'layer1.0.bn2.bias', 'layer4.1.bn1.running_var', 'layer2.3.bn1.running_mean', 'layer3.5.bn3.running_mean', 'layer3.4.bn2.running_mean', 'layer2.3.bn3.running_mean', 'layer1.0.conv3.weight', 'bn1.bias', 'layer3.1.bn3.running_var', 'layer3.2.bn1.weight', 'layer3.1.bn3.running_mean', 'layer1.2.bn3.weight', 'layer1.2.bn3.bias', 'layer2.0.bn3.num_batches_tracked', 'layer2.2.bn1.running_mean', 'layer1.1.bn3.weight', 'layer2.3.conv1.weight', 'layer2.3.bn3.bias', 'layer1.1.bn1.running_var', 'layer3.5.bn1.weight', 'layer4.0.bn1.bias', 'layer3.1.bn1.bias', 'layer3.5.bn2.num_batches_tracked', 'layer3.2.bn3.running_mean', 'layer2.0.downsample.0.weight', 'layer2.1.bn2.weight', 'layer2.1.bn3.num_batches_tracked', 'layer4.0.bn3.num_batches_tracked', 'layer2.1.bn1.running_mean', 'layer4.1.bn2.running_mean', 'layer2.2.bn2.running_var', 'layer3.1.bn2.num_batches_tracked', 'layer2.3.bn1.weight', 'layer3.1.bn2.bias', 'layer1.2.bn3.num_batches_tracked', 'layer1.0.bn1.weight', 'layer1.1.conv2.weight', 'layer2.2.bn3.running_var', 'layer3.3.conv1.weight', 'layer2.2.bn2.bias', 'layer3.2.bn1.num_batches_tracked', 'layer3.1.bn1.weight', 'layer3.1.bn3.num_batches_tracked', 'layer2.2.bn1.num_batches_tracked', 'layer4.1.conv1.weight', 'layer4.0.conv3.weight', 'layer4.2.bn1.bias', 'layer2.1.conv3.weight', 'layer4.2.bn3.running_mean', 'layer2.0.downsample.1.bias', 'layer2.0.downsample.1.weight', 'layer3.0.bn1.weight', 'layer1.0.bn1.running_var', 'layer4.0.downsample.1.running_var', 'layer4.0.bn2.running_mean', 'layer2.2.bn1.bias', 'layer3.0.bn2.num_batches_tracked', 'layer2.3.bn3.running_var', 'layer3.1.bn2.weight', 'layer4.0.downsample.1.running_mean', 'layer2.0.conv2.weight', 'layer1.0.bn1.bias', 'layer1.2.bn1.running_mean', 'layer3.3.bn1.bias', 'layer2.1.bn2.bias', 'layer3.4.bn1.running_var', 'layer1.1.bn2.running_var', 'layer2.0.bn3.running_var', 'layer4.2.bn2.weight', 'layer1.1.bn1.num_batches_tracked', 'layer2.0.bn1.bias', 'layer2.1.bn1.weight', 'layer2.3.bn1.num_batches_tracked', 'layer3.0.downsample.1.running_mean', 'layer2.1.bn2.running_var', 'layer3.1.bn1.running_mean', 'layer4.0.bn3.weight', 'layer2.2.bn3.running_mean', 'layer1.0.downsample.1.running_mean', 'layer3.4.bn1.num_batches_tracked', 'layer3.5.bn2.running_mean', 'layer2.1.bn1.running_var', 'layer2.0.bn3.weight', 'layer4.2.conv2.weight', 'layer3.0.conv3.weight', 'layer3.5.bn1.num_batches_tracked', 'bn1.num_batches_tracked', 'layer1.1.bn1.running_mean', 'layer1.2.bn2.num_batches_tracked', 'layer1.1.bn2.bias', 'layer1.0.downsample.1.bias', 'layer4.1.bn3.num_batches_tracked', 'layer3.2.bn1.running_mean', 'layer4.2.bn1.weight', 'layer3.0.downsample.1.weight', 'layer2.2.bn1.running_var', 'layer3.4.conv2.weight', 'layer3.2.conv1.weight', 'layer2.0.downsample.1.running_mean', 'layer3.4.conv1.weight', 'layer1.0.conv2.weight', 'bn1.weight', 'layer3.4.bn3.running_var', 'layer3.0.bn3.weight', 'layer4.1.bn3.running_var', 'layer3.1.conv2.weight', 'layer2.2.conv1.weight', 'layer3.0.conv2.weight', 'layer3.3.bn1.running_mean', 'layer1.0.downsample.1.weight', 'layer4.2.bn1.num_batches_tracked', 'layer1.0.bn3.running_mean', 'layer3.4.bn1.running_mean', 'layer2.3.bn2.bias', 'layer3.2.bn1.running_var', 'layer1.0.bn2.running_mean', 'layer4.1.conv2.weight', 'layer3.5.conv1.weight', 'layer1.1.bn2.weight', 'layer1.0.bn2.running_var', 'layer4.2.bn3.running_var', 'layer2.2.bn3.bias', 'layer1.1.bn1.bias', 'layer4.1.bn1.running_mean', 'layer1.1.bn3.num_batches_tracked', 'layer3.4.bn3.running_mean', 'layer4.1.bn2.num_batches_tracked', 'layer1.2.bn2.weight', 'layer4.2.bn3.bias'}
커스텀 모델에는 있지만 사전 학습된 모델에는 없는 가중치 (누락): []
사전 학습된 모델에는 있지만 커스텀 모델에는 없는 가중치 (예상치 못한): []
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
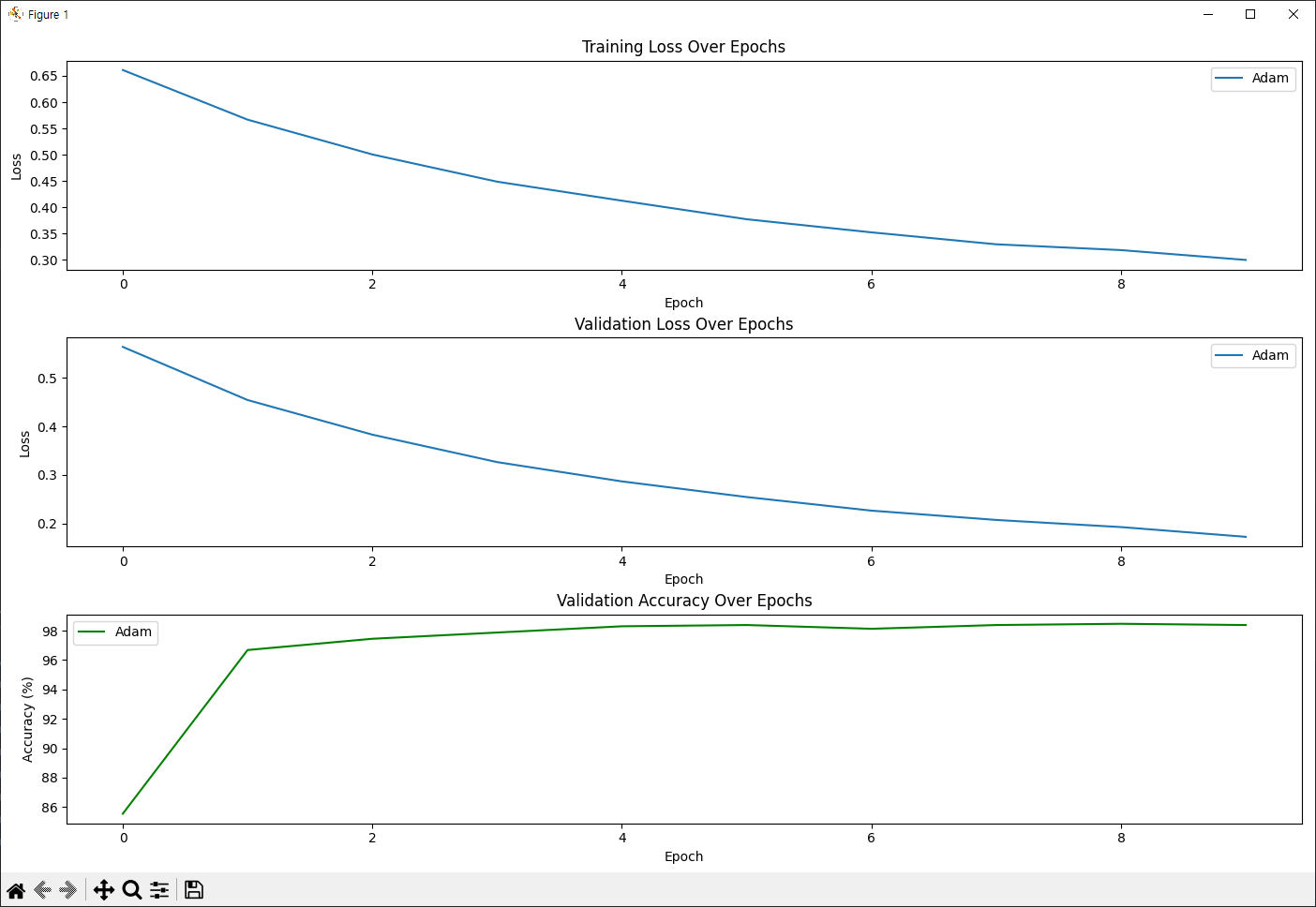
[Adam] Epoch 1, Train Loss: 0.661120, Val Loss: 0.563869, Validation Accuracy: 85.54%
[Adam] Epoch 2, Train Loss: 0.566690, Val Loss: 0.454372, Validation Accuracy: 96.68%
[Adam] Epoch 3, Train Loss: 0.500504, Val Loss: 0.383023, Validation Accuracy: 97.45%
[Adam] Epoch 4, Train Loss: 0.448676, Val Loss: 0.326422, Validation Accuracy: 97.87%
[Adam] Epoch 5, Train Loss: 0.412545, Val Loss: 0.286671, Validation Accuracy: 98.30%
[Adam] Epoch 6, Train Loss: 0.377239, Val Loss: 0.254442, Validation Accuracy: 98.38%
[Adam] Epoch 7, Train Loss: 0.352292, Val Loss: 0.226421, Validation Accuracy: 98.13%
[Adam] Epoch 8, Train Loss: 0.329578, Val Loss: 0.207234, Validation Accuracy: 98.38%
[Adam] Epoch 9, Train Loss: 0.318533, Val Loss: 0.192519, Validation Accuracy: 98.47%
[Adam] Epoch 10, Train Loss: 0.299828, Val Loss: 0.172458, Validation Accuracy: 98.38%
종료 코드 0(으)로 완료된 프로세스
DenseNet
import os
import glob
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
from tqdm import tqdm
import torchvision.transforms as transforms
import torchvision.models as models
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('Device:', device)
print('Count of using GPUs:', torch.cuda.device_count())
print('Current cuda device:', torch.cuda.current_device())
# # 이미지를 출력하는 함수
# def display_images(image_paths, title, max_images=4):
# """지정된 경로의 이미지를 최대 4개까지 출력합니다."""
# plt.figure(figsize=(12, 3))
# for i, image_path in enumerate(image_paths[:max_images]):
# img = plt.imread(image_path)
# plt.subplot(1, max_images, i+1)
# plt.imshow(img)
# plt.title(title)
# plt.axis('off')
# plt.show()
#
#
# # 이미지와 바 그래프 출력
# categories = ['Train damage', 'Train normal', 'Val damage', 'Val normal', 'Test damage', 'Test normal']
#
#
# for category in categories:
# image_paths = glob.glob(f'data/images/{category.lower().replace(" ", "/")}/*')
# display_images(image_paths, category)
# print(f"{category} 총 이미지 수: {len(image_paths)}")
#
# # 바 그래프 생성
# plt.figure(figsize=(10, 6))
# plt.bar(categories, [len(glob.glob(f'data/images/{category.lower().replace(" ", "/")}/*')) for category in categories], color=['blue', 'orange', 'green', 'red'])
# plt.title('Number of Images per Category')
# plt.xlabel('Category')
# plt.ylabel('Number of Images')
# plt.xticks(rotation=45)
# plt.show()
from imgaug import augmenters as iaa
import imgaug as ia
import numpy as np
import random
# imgaug를 사용한 커스텀 데이터셋 정의
class ImgAugTransform:
def __init__(self):
self.aug = iaa.Sequential([
iaa.LinearContrast((0.75, 1.5)), # 대비 조절
iaa.Fliplr(0.5), # 50% 확률로 좌우 반전
iaa.Flipud(0.2), # 20% 확률로 상하 반전
])
def __call__(self, img):
img = np.array(img)
return self.aug.augment_image(img)
class CustomDataset(ImageFolder):
def __init__(self, root, imgaug=None, transform=None, sample_per_class=None):
super(CustomDataset, self).__init__(root, transform=transform)
self.imgaug_transform = imgaug # imgaug 매개변수를 직접 저장
if sample_per_class is not None:
self.samples = self._reduce_samples(sample_per_class)
def _reduce_samples(self, sample_per_class):
class_samples = {}
for path, target in self.samples:
if target not in class_samples:
class_samples[target] = [path]
else:
class_samples[target].append(path)
reduced_samples = []
for target, paths in class_samples.items():
if len(paths) > sample_per_class:
reduced_samples.extend([(path, target) for path in random.sample(paths, sample_per_class)])
else:
reduced_samples.extend([(path, target) for path in paths])
return reduced_samples
def __getitem__(self, index):
path, target = self.samples[index]
img = self.loader(path)
# imgaug 증강 적용
if self.imgaug_transform is not None:
img = self.imgaug_transform(img)
# imgaug는 numpy 배열을 반환하므로, PIL Image로 다시 변환
img = Image.fromarray(img)
# ToTensor 및 Normalize 적용
if self.transform is not None:
img = self.transform(img)
return img, target
from torchvision import transforms
pytorch_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 이미지 크기 조정
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_path = 'data/images/train'
val_path = 'data/images/val'
train_dataset = CustomDataset(train_path, imgaug=ImgAugTransform(), transform=pytorch_transforms)
val_dataset = CustomDataset(val_path, imgaug=None, transform=pytorch_transforms, sample_per_class=128)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
def imshow(img, size=(20, 20), mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)):
img = img.numpy().transpose((1, 2, 0))
mean = np.array(mean)
std = np.array(std)
img = std * img + mean # 역정규화
img = np.clip(img, 0, 1) # 값이 0과 1 사이에 오도록 클리핑
plt.figure(figsize=size)
plt.imshow(img)
plt.axis('off')
plt.show()
# DataLoader를 이용하여 배치 데이터 가져오기
dataiter = iter(train_loader)
images, _ = next(dataiter)
from torchvision.utils import make_grid
# 이미지 그리드 생성 및 시각화, nrow를 조정하여 한 줄에 표시되는 이미지의 수 조정
imshow(make_grid(images[:8], nrow=4), size=(20, 10))
from collections import OrderedDict
import torch.nn.functional as F
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *
growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1), layer)
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class densenet169(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 32, 32),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(densenet169, self).__init__()
# Initial convolution
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_input_features=num_features,
bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
# 사전 학습된 densenet169 모델 불러오기
pretrained_densenet169 = models.densenet169(pretrained=True)
# 새로 정의한 모델 인스턴스 생성
net = densenet169(num_classes=1000)
# 사전 학습된 모델의 features 부분에서 가중치 추출
pretrained_keys = set(pretrained_densenet169.state_dict().keys())
# 사전 학습된 모델에서 커스텀 모델로 가중치 복사 시도
result = net.load_state_dict(pretrained_densenet169.state_dict(), strict=False)
# 복사 후 커스텀 모델의 features 부분에서 가중치 추출
custom_keys = set(net.state_dict().keys())
# 성공적으로 복사된 가중치 (커스텀 모델과 사전 학습된 모델 모두에 존재)
successfully_copied_keys = pretrained_keys.intersection(custom_keys)
# 커스텀 모델에 있지만 사전 학습된 모델에 없는 가중치
missing_keys = custom_keys - pretrained_keys
# 사전 학습된 모델에 있지만 커스텀 모델에 없는 가중치
unexpected_keys = pretrained_keys - custom_keys
print("성공적으로 복사된 가중치:", successfully_copied_keys)
print("커스텀 모델에는 있지만 사전 학습된 모델에는 없는 가중치 (누락):", result.missing_keys)
print("사전 학습된 모델에는 있지만 커스텀 모델에는 없는 가중치 (예상치 못한):", result.unexpected_keys) # net 모델에 없는데 pretrained_vgg19 가중치 파일에는 존재하는 항목의 이름이 리스트로 반환
print(net)
for param in net.parameters():
param.requires_grad = False
net.classifier = nn.Linear(1664, 1)
for param in net.classifier.parameters():
param.requires_grad = True
net = net.to(device)
criterion = nn.BCEWithLogitsLoss()
def validate_model(net, val_loader, criterion):
net.eval() # 모델을 평가 모드로 설정
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
labels = labels.float().unsqueeze(1) # 레이블을 float 타입으로 변환 및 차원 맞춤
outputs = net(inputs)
val_loss += criterion(outputs, labels).item()
predicted = torch.sigmoid(outputs) > 0.5
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss /= len(val_loader)
val_accuracy = 100 * correct / total
return val_loss, val_accuracy
def train_model(optimizer_name, net, train_loader, val_loader, criterion, num_epochs=20):
# optimizer 설정
if optimizer_name == 'SGD':
optimizer = optim.SGD(net.parameters(), lr=0.00003, momentum=0.9)
elif optimizer_name == 'Adam':
optimizer = optim.Adam(net.parameters(), lr=0.00003, betas=(0.9, 0.999))
elif optimizer_name == 'RAdam':
optimizer = optim.RAdam(net.parameters(), lr=0.00003, betas=(0.9, 0.999))
else:
raise ValueError(f"Unsupported optimizer: {optimizer_name}")
# 학습/검증 손실과 검증 정확도를 저장할 리스트
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(num_epochs):
net.train() # 모델을 학습 모드로 설정
running_loss = 0.0
# tqdm을 사용하여 진행 상황 표시
for i, (inputs, labels) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")):
inputs, labels = inputs.to(device), labels.to(device)
labels = labels.float().unsqueeze(1) # 레이블을 float 타입으로 변환 및 차원 맞춤
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels) # 손실 계산
loss.backward()
optimizer.step()
running_loss += loss.item()
# 매 에포크마다 평균 학습 손실 계산
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
# 검증 손실 및 정확도 계산
val_loss, val_accuracy = validate_model(net, val_loader, criterion)
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
# 에폭 종료 후 로그 출력
print(f'[{optimizer_name}] Epoch {epoch + 1}, Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}, Validation Accuracy: {val_accuracy:.2f}%')
return train_losses, val_losses, val_accuracies
train_losses_RAdam, val_losses_RAdam, val_accuracies_RAdam = train_model('RAdam', net, train_loader, val_loader, criterion)
# 학습 손실과 검증 정확도 그래프 그리기
plt.figure(figsize=(15, 10))
# 학습 손실 그래프
plt.subplot(3, 1, 1) # 3행 1열의 첫 번째 위치
plt.plot(train_losses_RAdam, label='RAdam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
# 검증 손실 그래프
plt.subplot(3, 1, 2) # 3행 1열의 두 번째 위치
plt.plot(val_losses_RAdam, label='RAdam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Validation Loss Over Epochs')
plt.legend()
# 검증 정확도 그래프
plt.subplot(3, 1, 3) # 3행 1열의 세 번째 위치
plt.plot(val_accuracies_RAdam, label='RAdam')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
plt.tight_layout()
plt.show()
def load_and_transform_image(image_path, transform):
image = Image.open(image_path).convert('RGB')
return transform(image).unsqueeze(0).to(device) # 이미지를 모델에 맞게 변환하고 배치 차원 추가
class_folders = {
'damage': 'data/images/test/damage',
'normal': 'data/images/test/normal'
}
plt.figure(figsize=(20, 8))
# subplot 인덱스를 위한 카운터
counter = 1
# 각 클래스별로 5장의 이미지 추론 및 시각화
for class_name, folder_path in class_folders.items():
# 해당 클래스의 이미지 경로 가져오기
image_paths = glob.glob(os.path.join(folder_path, '*'))
selected_paths = image_paths[:5] # 첫 5장 선택
for image_path in selected_paths:
image = load_and_transform_image(image_path, pytorch_transforms)
net.eval() # 모델을 평가 모드로 설정
# 모델을 사용한 추론
with torch.no_grad():
outputs = net(image)
# 시그모이드 함수 적용하여 확률 얻기
probs = torch.sigmoid(outputs).item()
prediction = 'normal' if probs >= 0.5 else 'damage'
# 결과 시각화
plt.subplot(2, 5, counter)
plt.imshow(Image.open(image_path))
plt.title(f'True: {class_name}, Pred: {prediction}')
plt.axis('off')
counter += 1 # subplot 인덱스 업데이트
plt.tight_layout()
plt.show()C:\Users\hi\Desktop\PS\python_lib\Scripts\python.exe C:\Users\hi\PycharmProjects\DeepVision_part\day1\Densenet_part\asdf.py
Device: cuda
Count of using GPUs: 1
Current cuda device: 0
C:\Users\hi\Desktop\PS\python_lib\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
C:\Users\hi\Desktop\PS\python_lib\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=DenseNet169_Weights.IMAGENET1K_V1`. You can also use `weights=DenseNet169_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
성공적으로 복사된 가중치: {'features.denseblock3.denselayer9.norm1.weight', 'features.denseblock3.denselayer26.conv2.weight', 'features.denseblock2.denselayer7.norm1.num_batches_tracked', 'features.denseblock4.denselayer13.conv1.weight', 'features.denseblock4.denselayer10.norm1.num_batches_tracked', 'features.denseblock3.denselayer2.norm1.weight', 'features.denseblock1.denselayer4.norm1.weight', 'features.denseblock4.denselayer7.norm1.num_batches_tracked', 'features.denseblock3.denselayer1.conv2.weight', 'features.denseblock1.denselayer4.norm1.bias', 'features.denseblock4.denselayer10.norm1.bias', 'features.denseblock1.denselayer1.norm2.running_mean', 'features.denseblock4.denselayer31.norm1.num_batches_tracked', 'features.denseblock4.denselayer15.conv1.weight', 'features.denseblock1.denselayer3.norm2.running_var', 'features.denseblock4.denselayer6.norm2.running_mean', 'features.denseblock2.denselayer3.norm2.running_var', 'features.denseblock3.denselayer16.norm2.bias', 'features.denseblock4.denselayer1.norm2.weight', 'features.denseblock4.denselayer8.norm2.running_mean', 'features.denseblock4.denselayer8.conv2.weight', 'features.denseblock4.denselayer23.norm1.running_mean', 'features.denseblock3.denselayer11.norm2.running_var', 'features.denseblock4.denselayer5.norm1.num_batches_tracked', 'features.denseblock4.denselayer18.norm2.num_batches_tracked', 'features.denseblock4.denselayer12.conv2.weight', 'features.denseblock2.denselayer6.norm1.weight', 'features.denseblock4.denselayer4.norm1.running_var', 'features.denseblock4.denselayer2.norm1.num_batches_tracked', 'features.denseblock4.denselayer14.norm2.bias', 'features.denseblock1.denselayer4.norm2.num_batches_tracked', 'features.denseblock4.denselayer30.norm1.bias', 'features.denseblock4.denselayer20.norm2.running_var', 'features.denseblock4.denselayer7.norm2.weight', 'features.denseblock3.denselayer6.norm1.num_batches_tracked', 'features.denseblock3.denselayer13.norm2.weight', 'features.denseblock1.denselayer2.norm1.running_mean', 'features.denseblock3.denselayer21.norm2.running_mean', 'features.denseblock3.denselayer11.norm1.bias', 'features.denseblock4.denselayer14.norm1.num_batches_tracked', 'features.denseblock3.denselayer27.norm2.bias', 'features.denseblock2.denselayer2.norm1.bias', 'features.denseblock3.denselayer12.norm2.running_mean', 'features.denseblock4.denselayer9.conv1.weight', 'features.denseblock4.denselayer13.norm2.running_var', 'features.denseblock4.denselayer9.norm1.running_var', 'features.denseblock3.denselayer18.norm2.bias', 'features.denseblock3.denselayer11.norm1.num_batches_tracked', 'features.denseblock2.denselayer7.norm1.bias', 'features.denseblock2.denselayer3.norm1.num_batches_tracked', 'features.denseblock4.denselayer4.norm2.weight', 'features.denseblock4.denselayer5.norm2.weight', 'features.denseblock4.denselayer6.norm1.running_mean', 'features.denseblock4.denselayer20.norm1.running_mean', 'features.denseblock2.denselayer12.conv1.weight', 'features.denseblock3.denselayer14.norm2.bias', 'features.denseblock4.denselayer7.norm1.running_mean', 'features.denseblock4.denselayer20.norm2.running_mean', 'features.transition2.norm.running_var', 'features.denseblock2.denselayer3.norm1.running_var', 'features.denseblock2.denselayer6.norm2.running_mean', 'features.denseblock3.denselayer10.norm1.weight', 'features.denseblock4.denselayer4.norm1.bias', 'features.denseblock3.denselayer28.norm2.running_mean', 'features.denseblock3.denselayer30.norm2.running_mean', 'features.denseblock3.denselayer26.norm2.running_mean', 'features.norm5.running_mean', 'features.denseblock3.denselayer21.norm2.weight', 'features.denseblock3.denselayer31.norm1.running_mean', 'features.denseblock4.denselayer10.norm1.running_mean', 'features.denseblock1.denselayer4.norm1.running_var', 'features.denseblock1.denselayer4.conv2.weight', 'features.denseblock2.denselayer5.norm1.bias', 'features.denseblock4.denselayer15.norm1.running_mean', 'features.denseblock3.denselayer5.norm1.running_var', 'features.denseblock4.denselayer20.norm2.weight', 'features.denseblock4.denselayer10.norm2.bias', 'features.denseblock4.denselayer8.norm2.num_batches_tracked', 'features.denseblock4.denselayer17.norm1.num_batches_tracked', 'features.denseblock3.denselayer32.norm2.bias', 'features.denseblock1.denselayer1.norm1.running_mean', 'features.denseblock4.denselayer18.norm2.running_var', 'features.transition3.norm.bias', 'features.denseblock1.denselayer6.norm2.bias', 'features.transition1.norm.running_var', 'features.denseblock2.denselayer11.norm2.bias', 'features.denseblock3.denselayer4.norm1.bias', 'features.denseblock3.denselayer5.norm1.num_batches_tracked', 'features.denseblock2.denselayer9.norm2.bias', 'features.denseblock3.denselayer8.norm1.running_var', 'features.denseblock4.denselayer10.conv2.weight', 'features.denseblock4.denselayer28.norm2.running_mean', 'features.denseblock4.denselayer21.norm2.bias', 'features.denseblock1.denselayer1.norm1.weight', 'features.denseblock1.denselayer5.norm2.running_mean', 'features.denseblock3.denselayer9.norm2.bias', 'features.denseblock4.denselayer26.norm1.bias', 'features.denseblock2.denselayer5.norm2.bias', 'features.denseblock3.denselayer7.norm1.bias', 'features.denseblock3.denselayer13.norm1.weight', 'features.denseblock4.denselayer5.conv2.weight', 'features.denseblock1.denselayer5.conv2.weight', 'features.denseblock2.denselayer7.norm2.running_var', 'features.denseblock3.denselayer24.norm2.num_batches_tracked', 'features.denseblock3.denselayer27.norm2.running_mean', 'features.denseblock4.denselayer2.norm1.running_var', 'features.denseblock4.denselayer9.conv2.weight', 'features.denseblock4.denselayer11.norm1.running_var', 'features.denseblock4.denselayer27.norm1.bias', 'features.denseblock4.denselayer32.norm1.running_var', 'features.denseblock2.denselayer6.norm2.running_var', 'features.denseblock3.denselayer7.norm2.weight', 'features.denseblock3.denselayer12.norm2.running_var', 'features.denseblock4.denselayer28.norm1.num_batches_tracked', 'features.denseblock4.denselayer27.norm1.running_var', 'features.denseblock3.denselayer13.conv1.weight', 'features.denseblock4.denselayer24.norm1.weight', 'features.denseblock4.denselayer6.norm1.num_batches_tracked', 'features.denseblock3.denselayer9.conv1.weight', 'features.denseblock2.denselayer12.norm1.weight', 'features.denseblock3.denselayer15.norm2.running_mean', 'features.denseblock3.denselayer20.norm1.weight', 'features.denseblock4.denselayer29.norm2.num_batches_tracked', 'features.denseblock1.denselayer6.norm2.running_mean', 'features.denseblock4.denselayer2.conv1.weight', 'features.denseblock2.denselayer10.conv2.weight', 'features.denseblock4.denselayer6.norm1.bias', 'features.denseblock4.denselayer24.norm1.num_batches_tracked', 'features.denseblock2.denselayer5.norm1.num_batches_tracked', 'features.norm5.weight', 'features.denseblock3.denselayer23.norm2.num_batches_tracked', 'features.denseblock3.denselayer16.norm1.bias', 'features.denseblock4.denselayer7.conv2.weight', 'features.denseblock4.denselayer8.norm1.weight', 'features.denseblock1.denselayer2.norm2.num_batches_tracked', 'features.denseblock4.denselayer9.norm1.weight', 'features.denseblock4.denselayer23.norm1.bias', 'features.denseblock4.denselayer27.conv2.weight', 'features.denseblock4.denselayer32.norm2.bias', 'features.denseblock3.denselayer23.norm1.bias', 'features.denseblock4.denselayer28.norm1.running_mean', 'features.denseblock3.denselayer5.norm1.bias', 'features.denseblock3.denselayer27.norm1.weight', 'features.denseblock4.denselayer5.norm2.running_var', 'features.denseblock4.denselayer28.conv1.weight', 'features.denseblock4.denselayer29.norm1.running_mean', 'features.denseblock4.denselayer17.norm2.num_batches_tracked', 'features.transition2.conv.weight', 'features.denseblock4.denselayer4.norm1.running_mean', 'features.denseblock4.denselayer28.norm1.weight', 'features.denseblock3.denselayer3.norm1.weight', 'features.denseblock4.denselayer20.norm1.weight', 'features.denseblock4.denselayer16.norm1.running_var', 'features.denseblock3.denselayer31.norm2.bias', 'features.denseblock4.denselayer11.conv1.weight', 'features.transition2.norm.num_batches_tracked', 'features.denseblock4.denselayer11.norm1.weight', 'features.denseblock1.denselayer4.norm2.running_mean', 'features.denseblock4.denselayer15.norm2.running_var', 'features.denseblock4.denselayer2.norm2.bias', 'features.denseblock4.denselayer18.norm1.running_var', 'features.denseblock4.denselayer22.norm2.weight', 'features.denseblock2.denselayer2.norm1.num_batches_tracked', 'features.denseblock2.denselayer4.norm1.running_mean', 'features.denseblock1.denselayer1.norm2.weight', 'features.denseblock4.denselayer17.conv2.weight', 'features.denseblock3.denselayer23.norm1.weight', 'features.denseblock4.denselayer25.norm1.weight', 'features.denseblock4.denselayer11.norm1.num_batches_tracked', 'features.denseblock3.denselayer9.norm1.num_batches_tracked', 'features.denseblock3.denselayer18.norm2.weight', 'features.denseblock3.denselayer1.norm2.bias', 'features.denseblock3.denselayer10.norm1.bias', 'features.denseblock2.denselayer2.norm2.weight', 'features.denseblock4.denselayer20.norm1.num_batches_tracked', 'features.denseblock3.denselayer31.norm2.num_batches_tracked', 'features.denseblock3.denselayer13.norm1.bias', 'features.denseblock3.denselayer20.norm1.running_var', 'features.denseblock4.denselayer8.norm1.running_mean', 'features.denseblock1.denselayer2.norm1.bias', 'features.denseblock3.denselayer22.norm1.running_mean', 'features.denseblock2.denselayer10.norm1.num_batches_tracked', 'features.denseblock1.denselayer5.norm1.bias', 'features.denseblock2.denselayer8.norm2.bias', 'features.transition1.norm.weight', 'features.denseblock4.denselayer26.norm2.weight', 'features.denseblock4.denselayer28.norm2.num_batches_tracked', 'features.denseblock4.denselayer12.norm2.bias', 'features.denseblock4.denselayer14.norm1.running_mean', 'features.denseblock4.denselayer25.norm2.weight', 'features.denseblock4.denselayer27.conv1.weight', 'features.denseblock4.denselayer28.norm2.bias', 'features.transition3.norm.weight', 'features.denseblock4.denselayer8.norm2.bias', 'features.denseblock4.denselayer29.norm2.weight', 'features.denseblock4.denselayer32.norm1.num_batches_tracked', 'features.denseblock3.denselayer11.conv2.weight', 'features.denseblock3.denselayer5.norm2.bias', 'features.denseblock3.denselayer17.conv2.weight', 'features.denseblock4.denselayer24.norm2.running_mean', 'features.denseblock3.denselayer10.norm1.running_mean', 'features.denseblock3.denselayer29.norm1.running_mean', 'features.denseblock4.denselayer27.norm1.num_batches_tracked', 'features.denseblock3.denselayer22.norm2.bias', 'features.denseblock4.denselayer32.norm1.running_mean', 'features.denseblock4.denselayer24.norm1.bias', 'features.denseblock3.denselayer18.norm1.weight', 'features.denseblock4.denselayer4.conv1.weight', 'features.denseblock3.denselayer29.norm2.running_var', 'features.denseblock3.denselayer29.norm2.weight', 'features.denseblock2.denselayer8.conv1.weight', 'features.denseblock4.denselayer1.norm1.running_mean', 'features.denseblock3.denselayer16.norm1.weight', 'features.denseblock3.denselayer3.norm1.num_batches_tracked', 'features.denseblock3.denselayer31.norm1.num_batches_tracked', 'features.denseblock4.denselayer12.norm1.running_var', 'features.denseblock4.denselayer22.norm2.bias', 'features.denseblock4.denselayer25.norm1.running_mean', 'features.denseblock3.denselayer10.norm2.bias', 'features.denseblock2.denselayer7.norm1.running_mean', 'features.denseblock1.denselayer2.norm1.num_batches_tracked', 'features.denseblock4.denselayer12.norm1.weight', 'features.denseblock4.denselayer26.norm1.weight', 'features.denseblock2.denselayer8.norm2.weight', 'features.denseblock1.denselayer4.norm1.running_mean', 'features.denseblock4.denselayer10.norm2.num_batches_tracked', 'features.denseblock2.denselayer9.norm2.running_mean', 'features.denseblock3.denselayer21.norm2.num_batches_tracked', 'features.denseblock3.denselayer27.norm2.num_batches_tracked', 'features.denseblock4.denselayer19.norm2.running_mean', 'features.denseblock2.denselayer5.norm1.running_var', 'features.denseblock2.denselayer6.norm2.weight', 'features.denseblock2.denselayer7.norm1.weight', 'features.denseblock3.denselayer17.norm2.num_batches_tracked', 'features.denseblock3.denselayer31.norm2.weight', 'features.denseblock4.denselayer11.conv2.weight', 'features.denseblock4.denselayer24.norm2.num_batches_tracked', 'features.denseblock3.denselayer19.conv1.weight', 'features.denseblock3.denselayer4.norm2.running_mean', 'features.denseblock4.denselayer15.norm1.num_batches_tracked', 'features.denseblock3.denselayer30.norm1.weight', 'features.denseblock3.denselayer17.norm1.running_var', 'features.denseblock4.denselayer12.norm2.running_var', 'features.denseblock3.denselayer14.norm1.running_var', 'features.denseblock1.denselayer5.norm2.num_batches_tracked', 'features.denseblock3.denselayer25.norm1.running_var', 'features.denseblock4.denselayer9.norm2.bias', 'features.denseblock4.denselayer14.norm2.weight', 'features.denseblock1.denselayer1.conv1.weight', 'features.denseblock4.denselayer18.conv2.weight', 'features.denseblock3.denselayer12.norm1.weight', 'features.denseblock2.denselayer2.norm2.bias', 'features.denseblock2.denselayer9.norm1.num_batches_tracked', 'features.denseblock3.denselayer9.norm2.weight', 'features.denseblock3.denselayer30.norm1.running_var', 'features.denseblock3.denselayer2.norm1.bias', 'features.denseblock4.denselayer19.norm2.weight', 'features.denseblock2.denselayer6.conv1.weight', 'features.denseblock4.denselayer20.conv1.weight', 'features.denseblock4.denselayer4.norm2.num_batches_tracked', 'features.denseblock3.denselayer8.conv1.weight', 'features.denseblock3.denselayer30.norm2.num_batches_tracked', 'features.denseblock3.denselayer17.norm2.running_mean', 'features.denseblock4.denselayer18.norm1.weight', 'features.denseblock1.denselayer5.norm2.running_var', 'features.denseblock3.denselayer13.norm1.running_mean', 'features.denseblock4.denselayer28.norm2.running_var', 'features.denseblock4.denselayer26.norm1.running_var', 'features.denseblock3.denselayer27.norm1.bias', 'features.denseblock4.denselayer22.norm1.weight', 'features.denseblock4.denselayer31.conv1.weight', 'features.denseblock4.denselayer5.norm1.bias', 'features.denseblock1.denselayer5.conv1.weight', 'features.denseblock4.denselayer1.norm1.weight', 'features.denseblock4.denselayer3.norm2.running_var', 'features.denseblock1.denselayer2.norm2.bias', 'features.denseblock4.denselayer15.norm1.bias', 'features.denseblock2.denselayer8.norm1.running_mean', 'features.denseblock3.denselayer23.norm2.running_mean', 'features.denseblock3.denselayer16.norm2.running_var', 'features.denseblock4.denselayer17.norm2.running_var', 'features.denseblock3.denselayer16.conv2.weight', 'features.denseblock4.denselayer14.norm2.running_var', 'features.denseblock4.denselayer32.conv2.weight', 'features.denseblock3.denselayer2.norm2.num_batches_tracked', 'features.denseblock3.denselayer4.norm2.running_var', 'features.denseblock3.denselayer30.norm2.weight', 'features.denseblock3.denselayer28.norm2.running_var', 'features.denseblock3.denselayer22.norm1.bias', 'features.denseblock4.denselayer4.norm2.running_var', 'features.denseblock1.denselayer5.norm1.running_var', 'features.norm5.bias', 'features.denseblock4.denselayer18.norm2.running_mean', 'features.denseblock4.denselayer1.norm2.num_batches_tracked', 'features.denseblock4.denselayer19.norm1.running_mean', 'features.denseblock2.denselayer1.norm1.num_batches_tracked', 'features.denseblock3.denselayer4.conv2.weight', 'features.denseblock4.denselayer30.norm2.running_var', 'features.denseblock3.denselayer5.norm2.running_mean', 'features.denseblock3.denselayer26.norm1.bias', 'features.denseblock2.denselayer2.norm2.running_mean', 'features.denseblock3.denselayer13.norm2.num_batches_tracked', 'features.denseblock3.denselayer23.norm2.running_var', 'features.denseblock4.denselayer2.norm2.weight', 'features.denseblock4.denselayer10.norm1.weight', 'features.denseblock3.denselayer5.norm2.num_batches_tracked', 'features.denseblock4.denselayer25.norm2.running_mean', 'features.denseblock3.denselayer1.norm2.weight', 'features.denseblock2.denselayer9.norm1.running_mean', 'features.denseblock2.denselayer6.norm2.bias', 'features.denseblock4.denselayer27.norm2.num_batches_tracked', 'features.denseblock3.denselayer16.norm1.num_batches_tracked', 'features.denseblock1.denselayer3.norm2.running_mean', 'features.denseblock4.denselayer7.norm2.bias', 'features.denseblock2.denselayer3.norm2.running_mean', 'features.denseblock4.denselayer8.norm1.num_batches_tracked', 'features.denseblock4.denselayer28.conv2.weight', 'features.denseblock3.denselayer30.norm1.running_mean', 'features.denseblock4.denselayer31.norm1.weight', 'features.denseblock3.denselayer18.norm2.num_batches_tracked', 'features.denseblock3.denselayer19.norm2.running_var', 'features.denseblock4.denselayer20.norm1.running_var', 'features.denseblock3.denselayer26.norm2.weight', 'features.denseblock4.denselayer24.norm2.bias', 'features.denseblock2.denselayer10.norm1.weight', 'features.norm0.running_var', 'features.denseblock4.denselayer2.norm1.weight', 'features.denseblock2.denselayer12.norm2.bias', 'features.denseblock4.denselayer3.norm1.num_batches_tracked', 'features.denseblock4.denselayer7.norm2.running_var', 'features.denseblock4.denselayer11.norm2.bias', 'features.denseblock4.denselayer12.norm2.running_mean', 'features.denseblock1.denselayer2.norm2.running_var', 'features.denseblock3.denselayer3.conv2.weight', 'features.denseblock3.denselayer15.conv1.weight', 'features.denseblock4.denselayer30.norm2.running_mean', 'features.denseblock3.denselayer7.norm2.running_mean', 'features.denseblock3.denselayer27.norm2.weight', 'features.denseblock2.denselayer11.norm1.running_mean', 'features.denseblock3.denselayer22.norm1.running_var', 'features.denseblock1.denselayer3.norm2.bias', 'features.denseblock4.denselayer26.norm1.num_batches_tracked', 'features.denseblock3.denselayer1.norm2.running_mean', 'features.denseblock3.denselayer11.norm2.weight', 'features.denseblock4.denselayer6.norm1.running_var', 'features.denseblock4.denselayer30.conv1.weight', 'features.denseblock4.denselayer19.conv1.weight', 'features.denseblock3.denselayer7.norm1.running_mean', 'features.denseblock3.denselayer13.norm2.running_var', 'features.denseblock3.denselayer28.conv2.weight', 'features.denseblock3.denselayer18.norm1.running_mean', 'features.denseblock4.denselayer21.norm1.bias', 'features.denseblock4.denselayer23.conv1.weight', 'features.denseblock3.denselayer25.norm1.weight', 'features.denseblock4.denselayer18.norm1.num_batches_tracked', 'features.denseblock3.denselayer19.norm1.bias', 'features.denseblock1.denselayer5.norm1.weight', 'features.denseblock2.denselayer1.norm1.bias', 'features.denseblock3.denselayer1.norm1.running_var', 'features.denseblock3.denselayer3.norm1.running_mean', 'features.denseblock4.denselayer30.norm1.running_var', 'features.denseblock4.denselayer24.norm2.weight', 'features.denseblock3.denselayer28.conv1.weight', 'features.denseblock4.denselayer5.norm2.running_mean', 'features.denseblock3.denselayer24.norm1.running_mean', 'features.denseblock4.denselayer7.norm1.bias', 'features.denseblock4.denselayer15.norm2.num_batches_tracked', 'features.denseblock2.denselayer9.norm2.num_batches_tracked', 'features.denseblock4.denselayer6.norm2.bias', 'features.denseblock4.denselayer13.norm2.bias', 'features.denseblock2.denselayer4.norm2.num_batches_tracked', 'features.denseblock2.denselayer9.norm1.running_var', 'features.denseblock2.denselayer1.norm2.num_batches_tracked', 'features.denseblock2.denselayer5.conv1.weight', 'features.denseblock3.denselayer5.norm1.weight', 'features.denseblock3.denselayer27.norm1.running_var', 'features.denseblock4.denselayer12.norm1.num_batches_tracked', 'features.denseblock1.denselayer5.norm2.weight', 'features.denseblock3.denselayer14.norm2.running_var', 'features.denseblock4.denselayer14.norm1.bias', 'features.denseblock4.denselayer29.conv1.weight', 'features.denseblock4.denselayer27.norm2.running_mean', 'features.denseblock4.denselayer13.norm2.num_batches_tracked', 'features.denseblock4.denselayer30.norm2.num_batches_tracked', 'features.denseblock2.denselayer6.norm2.num_batches_tracked', 'features.denseblock4.denselayer7.norm2.num_batches_tracked', 'features.denseblock4.denselayer1.norm2.running_var', 'features.denseblock3.denselayer11.norm1.running_var', 'features.denseblock2.denselayer7.conv1.weight', 'features.denseblock3.denselayer20.conv2.weight', 'features.denseblock4.denselayer25.conv1.weight', 'features.denseblock4.denselayer19.norm2.num_batches_tracked', 'features.denseblock3.denselayer28.norm2.weight', 'features.denseblock2.denselayer11.conv2.weight', 'features.denseblock4.denselayer10.norm2.weight', 'features.denseblock4.denselayer16.conv1.weight', 'features.denseblock1.denselayer6.norm1.num_batches_tracked', 'features.denseblock3.denselayer4.norm2.bias', 'features.transition3.conv.weight', 'features.denseblock4.denselayer14.norm1.running_var', 'features.denseblock4.denselayer16.norm1.weight', 'features.denseblock1.denselayer6.norm2.running_var', 'features.denseblock3.denselayer29.conv2.weight', 'features.denseblock4.denselayer15.norm2.bias', 'features.denseblock4.denselayer15.norm2.running_mean', 'features.denseblock3.denselayer1.norm1.weight', 'features.transition2.norm.weight', 'features.denseblock3.denselayer27.norm1.running_mean', 'features.denseblock3.denselayer18.norm2.running_mean', 'features.denseblock2.denselayer11.norm1.running_var', 'features.denseblock4.denselayer21.norm1.num_batches_tracked', 'features.denseblock2.denselayer1.norm2.running_var', 'features.denseblock3.denselayer11.conv1.weight', 'features.denseblock4.denselayer29.conv2.weight', 'features.denseblock4.denselayer21.norm1.weight', 'features.denseblock3.denselayer3.conv1.weight', 'features.denseblock4.denselayer5.norm1.weight', 'features.denseblock3.denselayer26.conv1.weight', 'features.denseblock3.denselayer2.norm2.weight', 'features.denseblock2.denselayer1.norm2.bias', 'features.transition3.norm.running_var', 'features.denseblock1.denselayer6.norm1.running_mean', 'features.denseblock4.denselayer3.norm1.bias', 'features.denseblock3.denselayer13.norm1.running_var', 'features.denseblock3.denselayer9.norm2.num_batches_tracked', 'features.denseblock4.denselayer30.norm1.running_mean', 'features.denseblock3.denselayer32.norm1.running_mean', 'features.norm0.bias', 'features.denseblock3.denselayer24.norm2.bias', 'features.transition3.norm.running_mean', 'features.denseblock1.denselayer3.norm1.running_mean', 'features.denseblock3.denselayer15.norm2.num_batches_tracked', 'features.denseblock3.denselayer13.conv2.weight', 'features.denseblock3.denselayer20.norm1.num_batches_tracked', 'features.denseblock3.denselayer22.conv2.weight', 'features.denseblock4.denselayer10.norm2.running_mean', 'features.denseblock3.denselayer20.norm2.num_batches_tracked', 'features.norm5.running_var', 'features.denseblock1.denselayer6.norm2.num_batches_tracked', 'features.denseblock4.denselayer15.conv2.weight', 'features.denseblock3.denselayer32.conv2.weight', 'features.denseblock2.denselayer10.norm1.running_var', 'features.denseblock3.denselayer2.norm1.running_var', 'features.denseblock4.denselayer30.norm2.weight', 'features.norm5.num_batches_tracked', 'features.denseblock3.denselayer11.norm1.running_mean', 'features.denseblock3.denselayer5.norm2.weight', 'features.denseblock4.denselayer16.norm2.weight', 'features.denseblock4.denselayer16.norm2.num_batches_tracked', 'features.denseblock3.denselayer19.conv2.weight', 'features.denseblock4.denselayer23.norm1.running_var', 'features.denseblock4.denselayer24.conv2.weight', 'features.denseblock2.denselayer4.conv1.weight', 'features.denseblock3.denselayer24.norm2.running_var', 'features.denseblock4.denselayer6.conv2.weight', 'features.denseblock3.denselayer13.norm1.num_batches_tracked', 'features.denseblock3.denselayer6.norm2.bias', 'features.denseblock4.denselayer23.norm2.weight', 'features.denseblock3.denselayer6.norm1.running_mean', 'features.denseblock4.denselayer14.norm2.num_batches_tracked', 'features.denseblock1.denselayer2.norm2.running_mean', 'features.denseblock3.denselayer17.norm1.bias', 'features.denseblock3.denselayer11.norm1.weight', 'features.denseblock3.denselayer28.norm1.bias', 'features.denseblock3.denselayer15.norm1.running_mean', 'features.denseblock4.denselayer1.norm1.bias', 'features.denseblock4.denselayer18.norm2.bias', 'features.denseblock2.denselayer10.norm2.running_mean', 'features.denseblock3.denselayer28.norm2.num_batches_tracked', 'features.denseblock4.denselayer21.norm2.running_var', 'features.denseblock2.denselayer8.conv2.weight', 'features.conv0.weight', 'features.denseblock4.denselayer1.norm2.bias', 'features.denseblock4.denselayer14.norm2.running_mean', 'features.denseblock1.denselayer3.norm2.weight', 'features.denseblock2.denselayer1.norm2.running_mean', 'features.denseblock4.denselayer7.norm1.weight', 'features.denseblock3.denselayer28.norm1.weight', 'features.transition1.norm.bias', 'features.denseblock1.denselayer5.norm1.num_batches_tracked', 'features.denseblock3.denselayer20.norm2.running_var', 'features.denseblock2.denselayer3.conv1.weight', 'features.denseblock2.denselayer5.norm2.running_mean', 'features.denseblock3.denselayer3.norm2.num_batches_tracked', 'features.denseblock3.denselayer21.norm1.weight', 'features.denseblock3.denselayer30.norm1.num_batches_tracked', 'features.denseblock4.denselayer16.norm2.running_mean', 'features.denseblock4.denselayer25.norm1.running_var', 'features.denseblock3.denselayer24.norm1.weight', 'features.denseblock3.denselayer10.conv1.weight', 'features.denseblock4.denselayer21.conv2.weight', 'features.denseblock1.denselayer1.norm1.bias', 'features.denseblock1.denselayer5.norm2.bias', 'features.denseblock4.denselayer27.norm2.bias', 'features.denseblock4.denselayer16.conv2.weight', 'features.denseblock3.denselayer6.norm2.running_mean', 'features.denseblock4.denselayer18.norm1.running_mean', 'features.denseblock4.denselayer8.norm2.running_var', 'features.denseblock3.denselayer19.norm1.num_batches_tracked', 'features.transition3.norm.num_batches_tracked', 'features.denseblock4.denselayer7.norm2.running_mean', 'features.denseblock3.denselayer25.conv2.weight', 'features.denseblock4.denselayer31.norm2.running_mean', 'features.denseblock4.denselayer13.norm2.weight', 'features.denseblock4.denselayer3.norm2.running_mean', 'features.denseblock1.denselayer1.conv2.weight', 'features.denseblock3.denselayer29.norm2.num_batches_tracked', 'features.denseblock3.denselayer10.conv2.weight', 'features.denseblock3.denselayer8.norm2.num_batches_tracked', 'features.denseblock3.denselayer28.norm1.running_mean', 'features.denseblock3.denselayer25.conv1.weight', 'features.denseblock3.denselayer10.norm1.num_batches_tracked', 'features.denseblock3.denselayer25.norm2.weight', 'features.denseblock3.denselayer20.norm2.bias', 'features.denseblock4.denselayer11.norm1.bias', 'features.denseblock3.denselayer27.conv1.weight', 'features.denseblock4.denselayer8.conv1.weight', 'features.denseblock4.denselayer13.norm1.running_var', 'features.denseblock4.denselayer22.norm1.bias', 'features.denseblock4.denselayer17.norm2.weight', 'features.transition1.norm.running_mean', 'features.denseblock1.denselayer4.conv1.weight', 'features.denseblock2.denselayer3.conv2.weight', 'features.denseblock4.denselayer13.norm1.num_batches_tracked', 'features.denseblock2.denselayer11.norm2.weight', 'features.denseblock3.denselayer23.norm2.weight', 'features.denseblock3.denselayer27.norm2.running_var', 'features.denseblock1.denselayer1.norm1.running_var', 'features.denseblock2.denselayer2.norm1.running_var', 'features.denseblock3.denselayer9.norm2.running_mean', 'features.denseblock4.denselayer8.norm1.running_var', 'features.denseblock4.denselayer22.norm1.running_mean', 'features.denseblock3.denselayer3.norm2.running_mean', 'features.denseblock3.denselayer13.norm2.bias', 'features.denseblock3.denselayer17.norm2.running_var', 'features.denseblock4.denselayer10.conv1.weight', 'features.denseblock3.denselayer10.norm2.running_mean', 'features.denseblock4.denselayer11.norm1.running_mean', 'features.denseblock4.denselayer21.norm2.running_mean', 'features.denseblock1.denselayer4.norm2.weight', 'features.denseblock4.denselayer32.norm2.weight', 'classifier.weight', 'features.denseblock4.denselayer21.conv1.weight', 'features.denseblock4.denselayer2.norm2.running_var', 'features.denseblock4.denselayer19.norm1.bias', 'features.denseblock4.denselayer21.norm2.weight', 'features.denseblock3.denselayer18.norm1.bias', 'features.denseblock3.denselayer19.norm1.running_mean', 'features.denseblock3.denselayer15.norm1.weight', 'features.denseblock3.denselayer19.norm1.running_var', 'features.denseblock3.denselayer25.norm2.running_var', 'features.denseblock2.denselayer3.norm1.bias', 'features.denseblock4.denselayer16.norm2.running_var', 'features.denseblock2.denselayer5.norm1.running_mean', 'features.denseblock4.denselayer12.conv1.weight', 'features.denseblock4.denselayer22.conv1.weight', 'features.denseblock4.denselayer30.norm2.bias', 'features.denseblock4.denselayer31.norm2.running_var', 'features.denseblock4.denselayer32.conv1.weight', 'features.denseblock3.denselayer11.norm2.bias', 'features.denseblock3.denselayer16.conv1.weight', 'features.denseblock4.denselayer28.norm1.bias', 'features.denseblock1.denselayer2.norm1.weight', 'features.denseblock3.denselayer25.norm2.running_mean', 'features.denseblock3.denselayer22.norm1.weight', 'features.denseblock4.denselayer5.norm2.bias', 'features.denseblock2.denselayer7.norm2.weight', 'features.denseblock3.denselayer15.norm1.num_batches_tracked', 'features.denseblock4.denselayer12.norm1.running_mean', 'features.denseblock4.denselayer13.norm1.weight', 'features.denseblock4.denselayer23.conv2.weight', 'features.denseblock4.denselayer27.norm1.weight', 'features.denseblock3.denselayer12.norm2.weight', 'features.denseblock4.denselayer23.norm2.bias', 'features.denseblock3.denselayer21.conv2.weight', 'features.denseblock3.denselayer23.norm1.num_batches_tracked', 'features.denseblock2.denselayer2.norm1.weight', 'features.denseblock4.denselayer6.norm1.weight', 'features.denseblock3.denselayer23.norm1.running_mean', 'features.denseblock4.denselayer26.norm2.bias', 'features.denseblock4.denselayer27.norm2.weight', 'features.denseblock3.denselayer14.norm1.bias', 'features.denseblock3.denselayer32.norm2.weight', 'features.denseblock3.denselayer6.norm1.bias', 'features.denseblock1.denselayer6.norm2.weight', 'features.denseblock3.denselayer30.norm1.bias', 'features.denseblock3.denselayer32.norm1.weight', 'features.denseblock3.denselayer20.conv1.weight', 'features.denseblock3.denselayer21.norm2.running_var', 'features.denseblock1.denselayer3.norm1.running_var', 'features.denseblock1.denselayer2.conv1.weight', 'features.denseblock4.denselayer6.norm2.num_batches_tracked', 'features.denseblock1.denselayer3.norm1.bias', 'features.denseblock1.denselayer3.conv2.weight', 'features.denseblock4.denselayer6.norm2.running_var', 'features.denseblock2.denselayer7.norm2.running_mean', 'features.denseblock3.denselayer4.norm2.weight', 'features.denseblock3.denselayer8.norm2.weight', 'features.denseblock3.denselayer5.norm2.running_var', 'features.denseblock4.denselayer22.conv2.weight', 'features.denseblock4.denselayer31.norm2.weight', 'features.denseblock4.denselayer3.norm1.running_var', 'features.denseblock3.denselayer17.conv1.weight', 'features.denseblock3.denselayer21.norm1.running_var', 'features.denseblock2.denselayer8.norm1.num_batches_tracked', 'features.denseblock3.denselayer26.norm1.running_mean', 'features.denseblock3.denselayer31.norm1.weight', 'features.denseblock4.denselayer2.norm2.num_batches_tracked', 'features.denseblock4.denselayer31.norm1.running_var', 'features.denseblock4.denselayer25.norm2.bias', 'features.denseblock3.denselayer7.norm2.bias', 'features.denseblock3.denselayer9.norm2.running_var', 'features.denseblock3.denselayer17.norm2.bias', 'features.denseblock4.denselayer22.norm2.num_batches_tracked', 'features.denseblock3.denselayer4.norm1.weight', 'features.denseblock3.denselayer7.norm1.weight', 'features.denseblock2.denselayer5.norm2.num_batches_tracked', 'features.denseblock3.denselayer10.norm2.num_batches_tracked', 'features.denseblock4.denselayer1.conv2.weight', 'features.denseblock4.denselayer10.norm1.running_var', 'features.denseblock4.denselayer8.norm2.weight', 'features.denseblock4.denselayer15.norm1.weight', 'features.denseblock3.denselayer4.norm2.num_batches_tracked', 'features.denseblock3.denselayer11.norm2.num_batches_tracked', 'features.denseblock3.denselayer32.norm2.num_batches_tracked', 'features.denseblock4.denselayer29.norm2.running_mean', 'features.denseblock4.denselayer25.norm1.bias', 'features.denseblock2.denselayer10.norm1.running_mean', 'features.denseblock3.denselayer20.norm2.weight', 'features.denseblock2.denselayer11.norm2.running_var', 'features.denseblock3.denselayer25.norm2.num_batches_tracked', 'features.denseblock4.denselayer9.norm1.bias', 'features.denseblock2.denselayer4.norm2.bias', 'features.denseblock4.denselayer17.conv1.weight', 'features.denseblock3.denselayer15.norm1.running_var', 'features.denseblock4.denselayer23.norm2.num_batches_tracked', 'features.denseblock3.denselayer29.norm2.running_mean', 'features.denseblock4.denselayer29.norm1.weight', 'features.denseblock2.denselayer9.norm1.weight', 'features.denseblock2.denselayer2.conv1.weight', 'features.denseblock2.denselayer1.norm2.weight', 'features.denseblock4.denselayer23.norm2.running_var', 'features.denseblock3.denselayer10.norm2.weight', 'features.denseblock3.denselayer22.norm2.running_mean', 'features.denseblock2.denselayer2.norm1.running_mean', 'features.denseblock2.denselayer12.norm2.running_mean', 'features.denseblock4.denselayer30.norm1.weight', 'features.denseblock3.denselayer2.norm2.running_var', 'features.denseblock4.denselayer16.norm1.running_mean', 'features.denseblock4.denselayer25.norm2.running_var', 'features.denseblock3.denselayer15.norm2.bias', 'features.denseblock3.denselayer20.norm2.running_mean', 'features.denseblock3.denselayer6.conv1.weight', 'features.denseblock3.denselayer17.norm1.running_mean', 'features.denseblock3.denselayer9.norm1.bias', 'features.denseblock2.denselayer10.norm1.bias', 'features.denseblock3.denselayer1.norm2.num_batches_tracked', 'features.denseblock4.denselayer22.norm2.running_mean', 'features.denseblock4.denselayer21.norm1.running_mean', 'features.denseblock3.denselayer14.norm2.num_batches_tracked', 'features.denseblock3.denselayer7.norm1.num_batches_tracked', 'features.denseblock3.denselayer21.conv1.weight', 'features.denseblock2.denselayer5.norm1.weight', 'features.denseblock4.denselayer8.norm1.bias', 'features.denseblock2.denselayer8.norm2.num_batches_tracked', 'features.denseblock3.denselayer5.conv2.weight', 'features.denseblock4.denselayer29.norm1.running_var', 'features.denseblock3.denselayer18.conv2.weight', 'features.denseblock1.denselayer4.norm2.bias', 'features.denseblock4.denselayer1.norm1.num_batches_tracked', 'features.denseblock4.denselayer19.norm2.running_var', 'features.denseblock4.denselayer14.conv2.weight', 'features.denseblock4.denselayer9.norm2.weight', 'features.denseblock4.denselayer25.conv2.weight', 'features.denseblock3.denselayer16.norm1.running_mean', 'features.denseblock3.denselayer32.norm1.num_batches_tracked', 'features.denseblock4.denselayer21.norm2.num_batches_tracked', 'features.denseblock1.denselayer1.norm2.running_var', 'features.denseblock4.denselayer29.norm2.running_var', 'features.denseblock4.denselayer4.norm2.running_mean', 'features.denseblock3.denselayer12.norm1.num_batches_tracked', 'features.denseblock3.denselayer2.norm1.num_batches_tracked', 'features.denseblock2.denselayer8.norm1.weight', 'features.denseblock4.denselayer26.conv1.weight', 'features.denseblock4.denselayer12.norm2.num_batches_tracked', 'features.denseblock3.denselayer18.norm2.running_var', 'features.denseblock4.denselayer29.norm2.bias', 'features.denseblock1.denselayer1.norm1.num_batches_tracked', 'features.denseblock3.denselayer8.norm1.bias', 'features.denseblock3.denselayer4.norm1.num_batches_tracked', 'features.denseblock4.denselayer7.norm1.running_var', 'features.denseblock2.denselayer1.norm1.running_mean', 'features.denseblock2.denselayer6.norm1.running_var', 'features.denseblock3.denselayer23.norm1.running_var', 'features.denseblock3.denselayer25.norm2.bias', 'features.denseblock3.denselayer8.norm1.weight', 'features.denseblock3.denselayer31.conv1.weight', 'features.denseblock2.denselayer2.norm2.running_var', 'features.denseblock4.denselayer6.conv1.weight', 'features.denseblock4.denselayer31.norm2.num_batches_tracked', 'features.denseblock4.denselayer19.norm1.running_var', 'features.denseblock4.denselayer24.conv1.weight', 'features.denseblock2.denselayer9.conv2.weight', 'features.denseblock3.denselayer32.norm1.running_var', 'features.transition1.conv.weight', 'features.denseblock3.denselayer25.norm1.running_mean', 'features.denseblock4.denselayer17.norm1.running_mean', 'features.denseblock3.denselayer16.norm2.weight', 'features.denseblock4.denselayer13.norm2.running_mean', 'features.denseblock2.denselayer1.norm1.weight', 'features.denseblock4.denselayer3.conv1.weight', 'features.denseblock3.denselayer1.norm1.bias', 'features.denseblock4.denselayer17.norm2.bias', 'features.denseblock3.denselayer2.norm2.running_mean', 'features.denseblock4.denselayer1.norm2.running_mean', 'features.denseblock4.denselayer18.conv1.weight', 'features.denseblock3.denselayer3.norm1.bias', 'features.denseblock2.denselayer4.norm2.running_var', 'features.denseblock3.denselayer7.norm1.running_var', 'features.denseblock2.denselayer6.conv2.weight', 'features.denseblock3.denselayer12.norm2.bias', 'features.denseblock3.denselayer23.conv1.weight', 'features.denseblock2.denselayer2.conv2.weight', 'features.denseblock3.denselayer8.norm2.bias', 'features.denseblock3.denselayer31.norm2.running_mean', 'features.denseblock3.denselayer29.norm2.bias', 'features.denseblock3.denselayer12.norm1.bias', 'features.denseblock3.denselayer16.norm1.running_var', 'features.denseblock3.denselayer19.norm2.bias', 'features.denseblock4.denselayer30.conv2.weight', 'features.denseblock3.denselayer18.norm1.running_var', 'features.denseblock4.denselayer26.conv2.weight', 'features.denseblock1.denselayer6.norm1.bias', 'features.denseblock4.denselayer13.norm1.running_mean', 'features.denseblock2.denselayer3.norm2.num_batches_tracked', 'features.denseblock4.denselayer11.norm2.running_var', 'features.denseblock4.denselayer19.norm1.weight', 'features.denseblock4.denselayer4.norm1.weight', 'features.denseblock4.denselayer6.norm2.weight', 'features.denseblock2.denselayer9.norm2.weight', 'features.denseblock2.denselayer8.norm2.running_mean', 'features.denseblock2.denselayer6.norm1.num_batches_tracked', 'features.denseblock2.denselayer5.norm2.weight', 'features.denseblock3.denselayer19.norm2.weight', 'features.denseblock4.denselayer14.norm1.weight', 'features.denseblock1.denselayer5.norm1.running_mean', 'features.denseblock3.denselayer24.norm1.running_var', 'features.denseblock4.denselayer27.norm2.running_var', 'features.denseblock3.denselayer21.norm2.bias', 'features.denseblock2.denselayer11.norm2.num_batches_tracked', 'features.denseblock3.denselayer1.norm2.running_var', 'features.denseblock4.denselayer3.norm2.weight', 'features.denseblock4.denselayer28.norm2.weight', 'features.denseblock3.denselayer28.norm1.num_batches_tracked', 'features.denseblock3.denselayer18.norm1.num_batches_tracked', 'features.denseblock4.denselayer13.conv2.weight', 'features.denseblock2.denselayer4.norm1.bias', 'features.denseblock4.denselayer28.norm1.running_var', 'features.denseblock4.denselayer3.norm1.weight', 'features.denseblock4.denselayer25.norm2.num_batches_tracked', 'features.denseblock3.denselayer20.norm1.bias', 'features.denseblock4.denselayer3.norm2.bias', 'features.denseblock2.denselayer2.norm2.num_batches_tracked', 'features.denseblock4.denselayer2.norm1.running_mean', 'features.norm0.num_batches_tracked', 'features.denseblock2.denselayer4.conv2.weight', 'features.denseblock3.denselayer24.norm1.num_batches_tracked', 'features.denseblock2.denselayer10.conv1.weight', 'features.denseblock4.denselayer2.norm1.bias', 'features.denseblock2.denselayer5.conv2.weight', 'features.denseblock2.denselayer9.norm2.running_var', 'features.denseblock3.denselayer26.norm1.weight', 'features.denseblock4.denselayer12.norm2.weight', 'features.denseblock3.denselayer3.norm2.weight', 'features.denseblock4.denselayer11.norm2.running_mean', 'features.denseblock2.denselayer7.norm1.running_var', 'features.denseblock3.denselayer5.norm1.running_mean', 'features.transition2.norm.running_mean', 'features.denseblock3.denselayer14.norm1.running_mean', 'features.denseblock3.denselayer23.norm2.bias', 'features.denseblock4.denselayer5.conv1.weight', 'features.denseblock3.denselayer14.conv1.weight', 'features.denseblock3.denselayer14.norm2.weight', 'features.denseblock4.denselayer17.norm1.bias', 'features.denseblock4.denselayer21.norm1.running_var', 'features.denseblock1.denselayer4.norm2.running_var', 'features.denseblock3.denselayer18.conv1.weight', 'features.denseblock3.denselayer6.norm2.num_batches_tracked', 'features.norm0.weight', 'features.denseblock3.denselayer8.norm1.num_batches_tracked', 'features.denseblock3.denselayer23.conv2.weight', 'features.denseblock3.denselayer17.norm2.weight', 'features.denseblock4.denselayer23.norm1.num_batches_tracked', 'features.denseblock3.denselayer1.norm1.num_batches_tracked', 'features.denseblock4.denselayer16.norm1.bias', 'features.denseblock1.denselayer1.norm2.num_batches_tracked', 'features.denseblock4.denselayer3.conv2.weight', 'features.denseblock3.denselayer15.conv2.weight', 'features.denseblock3.denselayer22.norm2.num_batches_tracked', 'features.denseblock1.denselayer6.conv2.weight', 'features.denseblock3.denselayer4.norm1.running_var', 'features.denseblock3.denselayer12.norm2.num_batches_tracked', 'features.denseblock3.denselayer17.norm1.weight', 'features.denseblock1.denselayer2.conv2.weight', 'features.denseblock3.denselayer26.norm2.num_batches_tracked', 'features.denseblock3.denselayer28.norm2.bias', 'features.denseblock4.denselayer4.conv2.weight', 'features.denseblock4.denselayer32.norm1.bias', 'features.denseblock4.denselayer32.norm2.num_batches_tracked', 'features.denseblock3.denselayer9.conv2.weight', 'features.denseblock3.denselayer9.norm1.running_var', 'features.denseblock4.denselayer9.norm2.running_var', 'features.denseblock3.denselayer10.norm1.running_var', 'features.denseblock2.denselayer6.norm1.running_mean', 'features.denseblock3.denselayer30.conv2.weight', 'features.denseblock1.denselayer6.conv1.weight', 'features.denseblock3.denselayer7.conv2.weight', 'features.denseblock3.denselayer17.norm1.num_batches_tracked', 'features.denseblock4.denselayer32.norm1.weight', 'features.denseblock2.denselayer11.norm1.bias', 'features.norm0.running_mean', 'features.denseblock4.denselayer9.norm2.num_batches_tracked', 'features.denseblock2.denselayer7.norm2.bias', 'features.denseblock3.denselayer31.norm1.running_var', 'features.denseblock2.denselayer1.conv2.weight', 'features.denseblock3.denselayer26.norm2.running_var', 'features.denseblock4.denselayer9.norm1.running_mean', 'features.denseblock4.denselayer16.norm2.bias', 'features.denseblock2.denselayer12.norm1.num_batches_tracked', 'features.denseblock3.denselayer15.norm2.weight', 'features.denseblock4.denselayer15.norm2.weight', 'features.denseblock3.denselayer29.norm1.running_var', 'features.denseblock4.denselayer22.norm1.num_batches_tracked', 'features.denseblock3.denselayer29.norm1.bias', 'features.denseblock4.denselayer32.norm2.running_var', 'features.denseblock4.denselayer9.norm1.num_batches_tracked', 'features.denseblock4.denselayer15.norm1.running_var', 'features.denseblock3.denselayer3.norm2.bias', 'features.transition2.norm.bias', 'features.denseblock1.denselayer1.norm2.bias', 'features.denseblock4.denselayer27.norm1.running_mean', 'features.denseblock3.denselayer21.norm1.running_mean', 'features.denseblock3.denselayer8.conv2.weight', 'features.denseblock3.denselayer26.norm1.num_batches_tracked', 'features.denseblock4.denselayer3.norm1.running_mean', 'features.denseblock4.denselayer22.norm1.running_var', 'features.denseblock4.denselayer4.norm2.bias', 'features.denseblock3.denselayer20.norm1.running_mean', 'features.denseblock1.denselayer2.norm2.weight', 'features.denseblock2.denselayer5.norm2.running_var', 'features.denseblock2.denselayer7.norm2.num_batches_tracked', 'features.denseblock4.denselayer2.norm2.running_mean', 'features.denseblock4.denselayer30.norm1.num_batches_tracked', 'features.denseblock2.denselayer3.norm2.bias', 'features.denseblock2.denselayer4.norm1.num_batches_tracked', 'features.denseblock3.denselayer8.norm1.running_mean', 'features.denseblock3.denselayer10.norm2.running_var', 'features.denseblock4.denselayer23.norm2.running_mean', 'features.denseblock2.denselayer4.norm1.weight', 'features.denseblock3.denselayer15.norm1.bias', 'features.denseblock4.denselayer11.norm2.weight', 'features.denseblock3.denselayer19.norm2.running_mean', 'features.denseblock4.denselayer17.norm1.weight', 'features.denseblock4.denselayer25.norm1.num_batches_tracked', 'features.denseblock3.denselayer6.norm2.weight', 'features.denseblock3.denselayer2.conv1.weight', 'features.denseblock4.denselayer3.norm2.num_batches_tracked', 'features.denseblock3.denselayer3.norm1.running_var', 'features.denseblock3.denselayer8.norm2.running_var', 'features.denseblock3.denselayer26.norm2.bias', 'features.denseblock2.denselayer3.norm1.running_mean', 'features.denseblock3.denselayer19.norm1.weight', 'features.denseblock4.denselayer5.norm2.num_batches_tracked', 'features.denseblock4.denselayer31.norm1.bias', 'features.denseblock2.denselayer4.norm1.running_var', 'features.denseblock4.denselayer11.norm2.num_batches_tracked', 'features.denseblock3.denselayer24.norm1.bias', 'features.denseblock2.denselayer10.norm2.running_var', 'features.denseblock3.denselayer21.norm1.bias', 'features.denseblock3.denselayer22.norm1.num_batches_tracked', 'features.denseblock2.denselayer10.norm2.bias', 'features.denseblock3.denselayer24.conv2.weight', 'features.denseblock3.denselayer32.norm2.running_mean', 'features.denseblock3.denselayer16.norm2.running_mean', 'features.denseblock3.denselayer9.norm1.running_mean', 'features.denseblock3.denselayer11.norm2.running_mean', 'features.denseblock3.denselayer7.norm2.num_batches_tracked', 'features.denseblock2.denselayer11.norm2.running_mean', 'features.denseblock4.denselayer20.norm2.num_batches_tracked', 'features.denseblock1.denselayer3.norm1.num_batches_tracked', 'features.denseblock4.denselayer23.norm1.weight', 'features.denseblock3.denselayer5.conv1.weight', 'features.denseblock1.denselayer6.norm1.weight', 'features.denseblock2.denselayer3.norm1.weight', 'features.denseblock3.denselayer22.conv1.weight', 'features.denseblock1.denselayer3.norm1.weight', 'features.denseblock4.denselayer31.conv2.weight', 'features.denseblock4.denselayer7.conv1.weight', 'features.denseblock2.denselayer8.norm1.bias', 'features.denseblock2.denselayer4.norm2.weight', 'features.denseblock2.denselayer9.norm1.bias', 'features.denseblock3.denselayer4.conv1.weight', 'features.denseblock2.denselayer12.norm1.bias', 'features.denseblock2.denselayer12.norm2.weight', 'features.denseblock3.denselayer2.norm2.bias', 'features.denseblock2.denselayer9.conv1.weight', 'features.denseblock2.denselayer10.norm2.weight', 'features.denseblock3.denselayer2.conv2.weight', 'features.denseblock3.denselayer12.norm1.running_mean', 'features.denseblock4.denselayer13.norm1.bias', 'features.denseblock2.denselayer11.conv1.weight', 'features.denseblock4.denselayer1.conv1.weight', 'features.denseblock4.denselayer2.conv2.weight', 'features.denseblock4.denselayer9.norm2.running_mean', 'features.denseblock4.denselayer12.norm1.bias', 'features.denseblock4.denselayer20.norm2.bias', 'features.denseblock3.denselayer1.conv1.weight', 'features.denseblock4.denselayer26.norm1.running_mean', 'features.denseblock4.denselayer31.norm1.running_mean', 'features.denseblock2.denselayer12.norm1.running_mean', 'features.denseblock3.denselayer25.norm1.num_batches_tracked', 'features.denseblock3.denselayer14.norm1.weight', 'features.denseblock3.denselayer26.norm1.running_var', 'features.denseblock3.denselayer29.norm1.weight', 'features.denseblock3.denselayer2.norm1.running_mean', 'features.denseblock3.denselayer30.conv1.weight', 'features.denseblock2.denselayer11.norm1.num_batches_tracked', 'features.denseblock3.denselayer31.conv2.weight', 'features.denseblock1.denselayer3.conv1.weight', 'features.denseblock4.denselayer20.conv2.weight', 'features.denseblock4.denselayer26.norm2.num_batches_tracked', 'features.denseblock3.denselayer8.norm2.running_mean', 'features.denseblock3.denselayer27.conv2.weight', 'classifier.bias', 'features.denseblock3.denselayer4.norm1.running_mean', 'features.denseblock2.denselayer8.norm1.running_var', 'features.denseblock4.denselayer24.norm2.running_var', 'features.denseblock2.denselayer12.norm2.num_batches_tracked', 'features.denseblock4.denselayer29.norm1.num_batches_tracked', 'features.denseblock3.denselayer27.norm1.num_batches_tracked', 'features.denseblock3.denselayer25.norm1.bias', 'features.denseblock4.denselayer10.norm2.running_var', 'features.denseblock4.denselayer26.norm2.running_var', 'features.denseblock4.denselayer17.norm1.running_var', 'features.denseblock4.denselayer17.norm2.running_mean', 'features.denseblock2.denselayer8.norm2.running_var', 'features.denseblock3.denselayer29.conv1.weight', 'features.denseblock3.denselayer31.norm1.bias', 'features.denseblock3.denselayer12.conv1.weight', 'features.denseblock3.denselayer12.norm1.running_var', 'features.denseblock3.denselayer29.norm1.num_batches_tracked', 'features.denseblock1.denselayer3.norm2.num_batches_tracked', 'features.denseblock4.denselayer16.norm1.num_batches_tracked', 'features.denseblock2.denselayer6.norm1.bias', 'features.denseblock3.denselayer21.norm1.num_batches_tracked', 'features.denseblock4.denselayer19.norm1.num_batches_tracked', 'features.denseblock2.denselayer10.norm2.num_batches_tracked', 'features.denseblock2.denselayer1.norm1.running_var', 'features.denseblock4.denselayer26.norm2.running_mean', 'features.denseblock3.denselayer6.norm1.weight', 'features.denseblock3.denselayer22.norm2.weight', 'features.denseblock3.denselayer12.conv2.weight', 'features.denseblock2.denselayer11.norm1.weight', 'features.denseblock4.denselayer19.conv2.weight', 'features.denseblock3.denselayer14.conv2.weight', 'features.denseblock3.denselayer22.norm2.running_var', 'features.denseblock1.denselayer6.norm1.running_var', 'features.denseblock3.denselayer15.norm2.running_var', 'features.denseblock3.denselayer32.norm1.bias', 'features.denseblock4.denselayer1.norm1.running_var', 'features.denseblock1.denselayer2.norm1.running_var', 'features.denseblock3.denselayer6.conv2.weight', 'features.denseblock4.denselayer19.norm2.bias', 'features.denseblock2.denselayer12.norm2.running_var', 'features.denseblock3.denselayer30.norm2.bias', 'features.denseblock4.denselayer5.norm1.running_mean', 'features.denseblock4.denselayer24.norm1.running_var', 'features.denseblock4.denselayer32.norm2.running_mean', 'features.denseblock1.denselayer4.norm1.num_batches_tracked', 'features.denseblock4.denselayer18.norm1.bias', 'features.denseblock3.denselayer13.norm2.running_mean', 'features.denseblock4.denselayer20.norm1.bias', 'features.denseblock3.denselayer7.conv1.weight', 'features.denseblock3.denselayer30.norm2.running_var', 'features.denseblock3.denselayer19.norm2.num_batches_tracked', 'features.denseblock4.denselayer24.norm1.running_mean', 'features.denseblock2.denselayer12.norm1.running_var', 'features.denseblock4.denselayer18.norm2.weight', 'features.denseblock4.denselayer22.norm2.running_var', 'features.denseblock2.denselayer3.norm2.weight', 'features.denseblock3.denselayer24.norm2.weight', 'features.denseblock3.denselayer14.norm1.num_batches_tracked', 'features.denseblock3.denselayer3.norm2.running_var', 'features.denseblock3.denselayer7.norm2.running_var', 'features.denseblock3.denselayer14.norm2.running_mean', 'features.denseblock2.denselayer4.norm2.running_mean', 'features.denseblock3.denselayer6.norm1.running_var', 'features.denseblock2.denselayer1.conv1.weight', 'features.denseblock3.denselayer24.conv1.weight', 'features.denseblock2.denselayer12.conv2.weight', 'features.denseblock3.denselayer28.norm1.running_var', 'features.denseblock3.denselayer32.conv1.weight', 'features.denseblock3.denselayer1.norm1.running_mean', 'features.denseblock2.denselayer7.conv2.weight', 'features.denseblock3.denselayer6.norm2.running_var', 'features.denseblock3.denselayer31.norm2.running_var', 'features.transition1.norm.num_batches_tracked', 'features.denseblock4.denselayer14.conv1.weight', 'features.denseblock4.denselayer31.norm2.bias', 'features.denseblock4.denselayer4.norm1.num_batches_tracked', 'features.denseblock3.denselayer16.norm2.num_batches_tracked', 'features.denseblock3.denselayer32.norm2.running_var', 'features.denseblock3.denselayer24.norm2.running_mean', 'features.denseblock4.denselayer29.norm1.bias', 'features.denseblock4.denselayer5.norm1.running_var'}
커스텀 모델에는 있지만 사전 학습된 모델에는 없는 가중치 (누락): []
사전 학습된 모델에는 있지만 커스텀 모델에는 없는 가중치 (예상치 못한): []
densenet169(
(features): Sequential(
(conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu0): ReLU(inplace=True)
(pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(denseblock1): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): _DenseLayer(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): _DenseLayer(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): _DenseLayer(
(norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): _DenseLayer(
(norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition1): _Transition(
(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock2): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): _DenseLayer(
(norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): _DenseLayer(
(norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): _DenseLayer(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): _DenseLayer(
(norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer7): _DenseLayer(
(norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer8): _DenseLayer(
(norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer9): _DenseLayer(
(norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer10): _DenseLayer(
(norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer11): _DenseLayer(
(norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer12): _DenseLayer(
(norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition2): _Transition(
(norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock3): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): _DenseLayer(
(norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): _DenseLayer(
(norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): _DenseLayer(
(norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): _DenseLayer(
(norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer7): _DenseLayer(
(norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer8): _DenseLayer(
(norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer9): _DenseLayer(
(norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer10): _DenseLayer(
(norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer11): _DenseLayer(
(norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer12): _DenseLayer(
(norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer13): _DenseLayer(
(norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer14): _DenseLayer(
(norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer15): _DenseLayer(
(norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer16): _DenseLayer(
(norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer17): _DenseLayer(
(norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer18): _DenseLayer(
(norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer19): _DenseLayer(
(norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer20): _DenseLayer(
(norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer21): _DenseLayer(
(norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer22): _DenseLayer(
(norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer23): _DenseLayer(
(norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer24): _DenseLayer(
(norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer25): _DenseLayer(
(norm1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer26): _DenseLayer(
(norm1): BatchNorm2d(1056, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1056, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer27): _DenseLayer(
(norm1): BatchNorm2d(1088, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1088, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer28): _DenseLayer(
(norm1): BatchNorm2d(1120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1120, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer29): _DenseLayer(
(norm1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1152, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer30): _DenseLayer(
(norm1): BatchNorm2d(1184, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1184, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer31): _DenseLayer(
(norm1): BatchNorm2d(1216, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1216, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer32): _DenseLayer(
(norm1): BatchNorm2d(1248, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1248, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition3): _Transition(
(norm): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(1280, 640, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock4): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): _DenseLayer(
(norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): _DenseLayer(
(norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): _DenseLayer(
(norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): _DenseLayer(
(norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer7): _DenseLayer(
(norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer8): _DenseLayer(
(norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer9): _DenseLayer(
(norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer10): _DenseLayer(
(norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer11): _DenseLayer(
(norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer12): _DenseLayer(
(norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer13): _DenseLayer(
(norm1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1024, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer14): _DenseLayer(
(norm1): BatchNorm2d(1056, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1056, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer15): _DenseLayer(
(norm1): BatchNorm2d(1088, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1088, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer16): _DenseLayer(
(norm1): BatchNorm2d(1120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1120, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer17): _DenseLayer(
(norm1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1152, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer18): _DenseLayer(
(norm1): BatchNorm2d(1184, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1184, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer19): _DenseLayer(
(norm1): BatchNorm2d(1216, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1216, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer20): _DenseLayer(
(norm1): BatchNorm2d(1248, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1248, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer21): _DenseLayer(
(norm1): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1280, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer22): _DenseLayer(
(norm1): BatchNorm2d(1312, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1312, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer23): _DenseLayer(
(norm1): BatchNorm2d(1344, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1344, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer24): _DenseLayer(
(norm1): BatchNorm2d(1376, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1376, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer25): _DenseLayer(
(norm1): BatchNorm2d(1408, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1408, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer26): _DenseLayer(
(norm1): BatchNorm2d(1440, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1440, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer27): _DenseLayer(
(norm1): BatchNorm2d(1472, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1472, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer28): _DenseLayer(
(norm1): BatchNorm2d(1504, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1504, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer29): _DenseLayer(
(norm1): BatchNorm2d(1536, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1536, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer30): _DenseLayer(
(norm1): BatchNorm2d(1568, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1568, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer31): _DenseLayer(
(norm1): BatchNorm2d(1600, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1600, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer32): _DenseLayer(
(norm1): BatchNorm2d(1632, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(1632, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(norm5): BatchNorm2d(1664, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(classifier): Linear(in_features=1664, out_features=1000, bias=True)
)
Epoch 1/20: 100%|██████████| 369/369 [02:41<00:00, 2.29it/s]
Epoch 2/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 1, Train Loss: 0.710434, Val Loss: 0.681238, Validation Accuracy: 57.42%
Epoch 2/20: 100%|██████████| 369/369 [01:17<00:00, 4.74it/s]
Epoch 3/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 2, Train Loss: 0.656075, Val Loss: 0.614972, Validation Accuracy: 72.27%
Epoch 3/20: 100%|██████████| 369/369 [01:17<00:00, 4.74it/s]
Epoch 4/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 3, Train Loss: 0.592858, Val Loss: 0.548546, Validation Accuracy: 80.86%
Epoch 4/20: 100%|██████████| 369/369 [01:17<00:00, 4.74it/s]
[RAdam] Epoch 4, Train Loss: 0.535009, Val Loss: 0.496064, Validation Accuracy: 85.16%
Epoch 5/20: 100%|██████████| 369/369 [01:17<00:00, 4.75it/s]
Epoch 6/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 5, Train Loss: 0.485272, Val Loss: 0.447254, Validation Accuracy: 87.89%
Epoch 6/20: 100%|██████████| 369/369 [01:18<00:00, 4.68it/s]
Epoch 7/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 6, Train Loss: 0.443909, Val Loss: 0.408133, Validation Accuracy: 88.28%
Epoch 7/20: 100%|██████████| 369/369 [01:21<00:00, 4.56it/s]
Epoch 8/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 7, Train Loss: 0.411022, Val Loss: 0.379368, Validation Accuracy: 88.28%
Epoch 8/20: 100%|██████████| 369/369 [01:20<00:00, 4.61it/s]
Epoch 9/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 8, Train Loss: 0.381758, Val Loss: 0.356696, Validation Accuracy: 87.50%
Epoch 9/20: 100%|██████████| 369/369 [01:19<00:00, 4.65it/s]
Epoch 10/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 9, Train Loss: 0.357149, Val Loss: 0.333771, Validation Accuracy: 89.06%
Epoch 10/20: 100%|██████████| 369/369 [01:23<00:00, 4.44it/s]
Epoch 11/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 10, Train Loss: 0.337093, Val Loss: 0.317413, Validation Accuracy: 89.06%
Epoch 11/20: 100%|██████████| 369/369 [01:22<00:00, 4.45it/s]
[RAdam] Epoch 11, Train Loss: 0.324470, Val Loss: 0.301277, Validation Accuracy: 89.06%
Epoch 12/20: 100%|██████████| 369/369 [01:21<00:00, 4.50it/s]
[RAdam] Epoch 12, Train Loss: 0.312084, Val Loss: 0.291835, Validation Accuracy: 88.28%
Epoch 13/20: 100%|██████████| 369/369 [01:18<00:00, 4.68it/s]
[RAdam] Epoch 13, Train Loss: 0.296267, Val Loss: 0.279125, Validation Accuracy: 89.45%
Epoch 14/20: 100%|██████████| 369/369 [01:17<00:00, 4.74it/s]
Epoch 15/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 14, Train Loss: 0.285852, Val Loss: 0.266033, Validation Accuracy: 90.23%
Epoch 15/20: 100%|██████████| 369/369 [01:18<00:00, 4.72it/s]
Epoch 16/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 15, Train Loss: 0.274571, Val Loss: 0.260234, Validation Accuracy: 89.45%
Epoch 16/20: 100%|██████████| 369/369 [01:17<00:00, 4.75it/s]
Epoch 17/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 16, Train Loss: 0.266833, Val Loss: 0.252310, Validation Accuracy: 91.02%
Epoch 17/20: 100%|██████████| 369/369 [01:21<00:00, 4.55it/s]
Epoch 18/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 17, Train Loss: 0.261149, Val Loss: 0.243409, Validation Accuracy: 91.80%
Epoch 18/20: 100%|██████████| 369/369 [01:21<00:00, 4.55it/s]
[RAdam] Epoch 18, Train Loss: 0.258195, Val Loss: 0.235197, Validation Accuracy: 91.41%
Epoch 19/20: 100%|██████████| 369/369 [01:21<00:00, 4.52it/s]
Epoch 20/20: 0%| | 0/369 [00:00<?, ?it/s][RAdam] Epoch 19, Train Loss: 0.247852, Val Loss: 0.233422, Validation Accuracy: 92.19%
Epoch 20/20: 100%|██████████| 369/369 [01:21<00:00, 4.54it/s]
[RAdam] Epoch 20, Train Loss: 0.240499, Val Loss: 0.229154, Validation Accuracy: 91.80%

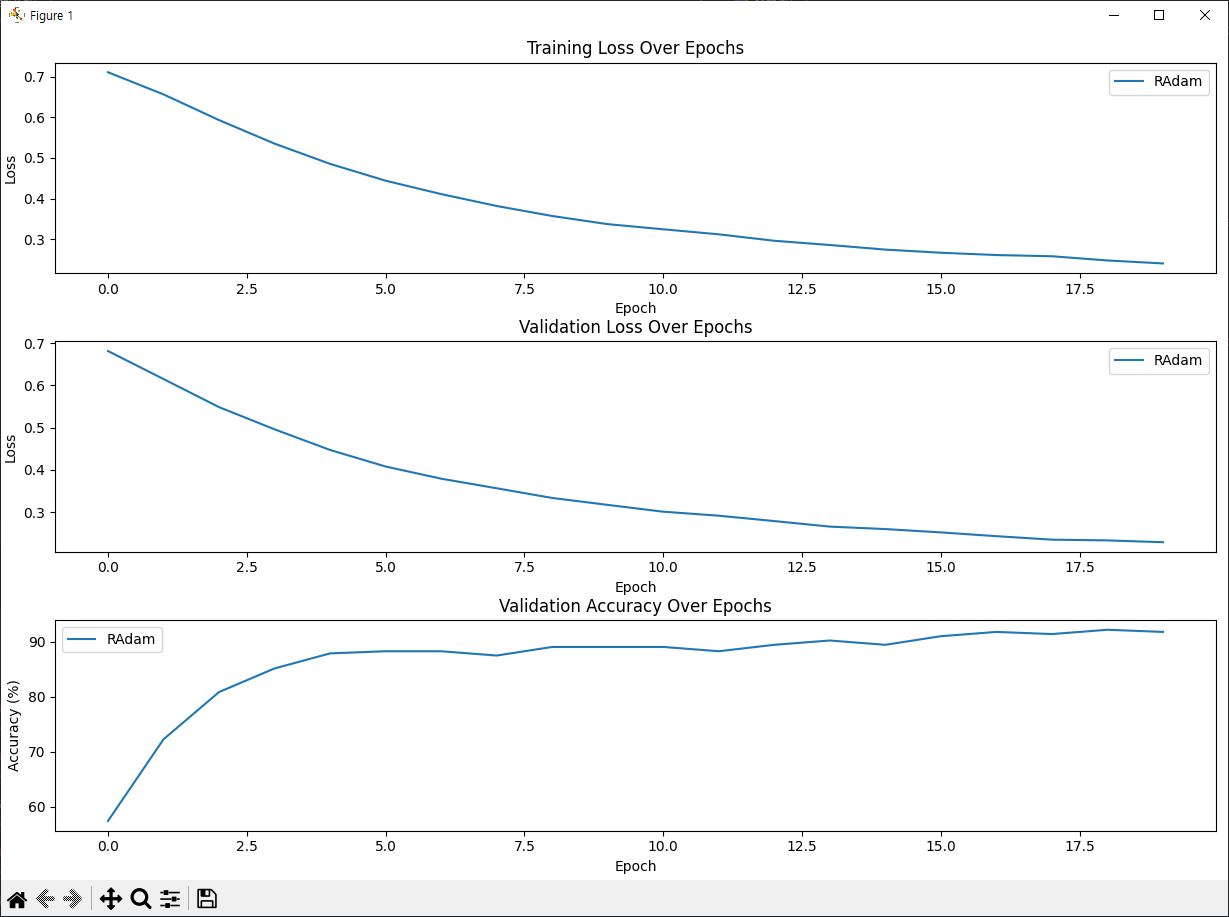

+AI to AI+