과적합 이해하기
과적합(over fitting)이란 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않는 것을 말함
다음 그림 그래프에서 빨간색을 보면 주어진 샘플에 정확히 맞게끔 선이 그어져 있음
하지만 이 선은 너무 이 경우에만 최적화되어 있음
다시 말해서, 완전히 새로운 데이터에 적용하면 이 선을 통해 정확히 두 그룹을 나누지 못하게 된다는 의미
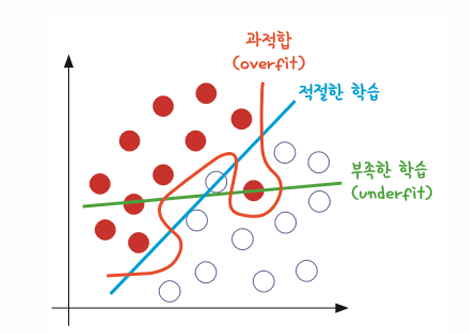
과적합이 일어난 경우(빨간색) 와 학습이 제대로 이루어지지 않은 경우(초록색)
과적합은 층이 너무 많거나 변수가 복잡해서 발생하기도 하고 테스트셋과 학습셋이 중복될 때 생기기도 함
특히 딥러닝은 학습 단계에서 입력, 은닉층, 출력층의 노드들에 상당히 많은 변수들이 투입됨
-> 따라서 딥러닝을 진행하는 동안 과적합에 빠지지 않게 늘 주의해야 한다!
학습셋과 테스트셋
그렇다면 과적합을 방지하려면 어떻게 해야 할까?
먼저 학습을 하는 데이터셋과 이를 테스트할 데이터셋을 완전히 구분한 다음 학습과 동시에 테스트를 병행하며 진행하는 것이 한 방법
예를 들어, 데이터셋이 총 100개의 샘플로 이루어져 있다면 다음과 같이 두 개의 셋으로 나눔
70개 샘플은 학습셋으로 | 30개 샘플은 테스트셋으로
신경망을 만들어 70개의 샘플로 학습을 진행한 후 이 학습의 결과를 저장
-> 이렇게 저장된 파일을 '모델'이라고 부름
모델은 다른 셋에 적용할 경우 학습 단계에서 각인되었던 그대로 다시 수행함
따라서 나머지 30개의 샘플로 실험해서 정확도를 살펴보면 학습이 얼마나 잘 되었는지를 알 수 있는 것
딥러닝 같은 알고리즘을 충분히 조절하여 가장 나은 모델이 만들어지면, 이를 실생활에 대입하여 활용하는 것이 바로 머신러닝의 개발 순서
from torch.nn.functional import dropout
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import ssl
import torch
ssl._create_default_https_context = ssl._create_unverified_context
train_set = datasets.FashionMNIST(root='FashionMNIST_data/',
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor()])
)
test_set = datasets.FashionMNIST(root='FashionMNIST_data/',
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor()])
)
batch_size = 100
train_loader = DataLoader(train_set,
batch_size=batch_size,
shuffle=True,
drop_last=True)
test_loader = DataLoader(train_set,
batch_size=batch_size,
shuffle=True,
drop_last=True)
import torch.nn as nn
import torch.nn.functional as F
class ImageNN(nn.Module):
def __init__(self, drop_p=0.5):
super().__init__()
self.fc1 = nn.Linear(784,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,10)
self.dropout_p = drop_p
def forward(self,x):
x = x.view(-1, 784)
out = F.relu(self.fc1(x))
out = F.dropout(out, p=self.dropout_p, training=self.training)
out = F.relu(self.fc2(out))
out = F.dropout(out, p=self.dropout_p, training=self.training)
y = self.fc3(out)
return y
import torch.optim as optim
model = ImageNN(drop_p=0.2)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(model, train_loader, optimizer):
model.train()
for x_train, y_train in train_loader:
# x_train = x_train.view(-1, 28*28)
optimizer.zero_grad()
hypothesis = model(x_train)
loss = loss_func(hypothesis, y_train)
loss.backward()
optimizer.step()
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for x_test, y_test in test_loader:
hypothesis = model(x_test)
test_loss += F.cross_entropy(hypothesis, y_test).item()
pred = torch.argmax(hypothesis, dim=1)
correct += pred.eq(y_test.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100 * correct / len(test_loader.dataset)
return test_loss, test_accuracy
for epoch in range(20):
train(model, train_loader, optimizer)
test_loss, test_accuracy = evaluate(model, test_loader)
print(f'epoch{epoch+1}, loss:{test_loss:.4f}, accuracy:{test_accuracy:2.2f}%')
epoch1, loss:0.0104, accuracy:63.62%
epoch2, loss:0.0078, accuracy:70.38%
epoch3, loss:0.0069, accuracy:74.81%
epoch4, loss:0.0063, accuracy:77.94%
epoch5, loss:0.0059, accuracy:79.66%
epoch6, loss:0.0055, accuracy:80.77%
epoch7, loss:0.0053, accuracy:81.74%
epoch8, loss:0.0050, accuracy:82.39%
epoch9, loss:0.0048, accuracy:83.14%
epoch10, loss:0.0047, accuracy:83.60%
epoch11, loss:0.0046, accuracy:83.93%
epoch12, loss:0.0045, accuracy:84.24%
epoch13, loss:0.0043, accuracy:84.58%
epoch14, loss:0.0043, accuracy:84.87%
epoch15, loss:0.0042, accuracy:85.23%
epoch16, loss:0.0041, accuracy:85.42%
epoch17, loss:0.0040, accuracy:85.63%
epoch18, loss:0.0040, accuracy:85.89%
epoch19, loss:0.0039, accuracy:86.05%
epoch20, loss:0.0039, accuracy:86.28%Early Stopping
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from matplotlib.lines import lineStyles
from torch.utils.data import DataLoader, SubsetRandomSampler
torch.manual_seed(111)
import numpy as np
def create_datasets(batch_size):
train_data = dset.MNIST(root='MNIST_data/',
train=True,
download=True,
transform=transforms.ToTensor())
test_data = dset.MNIST(root='MNIST_data/',
train=False,
download=True,
transform=transforms.ToTensor())
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(0.2 * num_train))
train_idx, valid_idx = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
train_loader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
valid_loader = DataLoader(train_data, sampler=valid_sampler, batch_size=batch_size)
test_loader = DataLoader(test_data, batch_size=batch_size)
return train_loader, test_loader, valid_loader
import torch.nn as nn
import torch.nn.functional as F
class ImageNN(nn.Module):
def __init__(self, drop_p=0.5):
super().__init__()
self.fc1 = nn.Linear(784,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,10)
self.dropout_p = drop_p
def forward(self,x):
x = x.view(-1, 784)
out = F.relu(self.fc1(x))
out = F.dropout(out, p=self.dropout_p, training=self.training)
out = F.relu(self.fc2(out))
out = F.dropout(out, p=self.dropout_p, training=self.training)
y = self.fc3(out)
return y
import torch.optim as optim
model = ImageNN(drop_p=0.5)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
class EarlyStopping:
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def save_checkpoint(self, val_loss, model):
if self.verbose:
print(f'validation loss: ({self.val_loss_min:.6f}) -> ({val_loss:.6f}) saving model!!!!')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
def __call__(self, val_loss, model):
score = val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score > self.best_score + self.delta:
self.counter += 1
if self.counter > self.patience:
self.early_stop = True
else:
print(f'earlyStopping counter : {self.counter}/{self.patience}')
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def train_model(model, patience, n_epochs):
train_losses = []
valid_losses = []
avg_train_losses = []
avg_valid_losses = []
early_stopping = EarlyStopping(patience=patience, verbose=True)
for epoch in range(1, n_epochs+1):
model.train()
for x_train, y_train in train_loader:
optimizer.zero_grad()
hypothesis = model(x_train)
loss = loss_func(hypothesis, y_train)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
model.eval()
for x_data, target in valid_loader:
output = model(x_data)
loss = loss_func(output, target)
valid_losses.append(loss.item())
train_loss = np.mean(train_losses)
valid_loss = np.mean(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
epoch_len = len(str(n_epochs))
print(f'[{epoch:<{epoch_len}} / {n_epochs: >{epoch_len}}'+
f'train_loss:{train_loss:.5f} valid_loss:{valid_loss:.5f}')
train_losses=[]
valid_losses=[]
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print('early stopping!!!!')
break
model.load_state_dict(torch.load('checkpoint.pt'))
return model,avg_train_losses, avg_valid_losses
batch_size = 256
n_epochs = 100
train_loader, test_loader, valid_loader = create_datasets(batch_size)
patience = 15
model, train_loss, valid_loss = train_model(model, patience, n_epochs)
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,8))
plt.plot(range(1,len(train_loss)+1), train_loss, label='Training Loss')
plt.plot(range(1,len(train_loss)+1), valid_loss, label='validation Loss')
minpos = valid_loss.index(min(valid_loss)) + 1
plt.axvline(minpos, linestyle='--', color='r', label='Early Stopping Checkpoint')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.ylim(0,0.5)
plt.xlim(0,len(train_loss)+1)
plt.grid(True)
plt.legend(loc='best')
plt.tight_layout()
plt.show()
[1 / 100train_loss:0.70745 valid_loss:0.27587
validation loss: (inf) -> (0.275870) saving model!!!!
[2 / 100train_loss:0.30190 valid_loss:0.19409
validation loss: (0.275870) -> (0.194086) saving model!!!!
[3 / 100train_loss:0.23278 valid_loss:0.15369
validation loss: (0.194086) -> (0.153694) saving model!!!!
[4 / 100train_loss:0.19333 valid_loss:0.12559
validation loss: (0.153694) -> (0.125590) saving model!!!!
[5 / 100train_loss:0.16700 valid_loss:0.11274
validation loss: (0.125590) -> (0.112740) saving model!!!!
[6 / 100train_loss:0.15125 valid_loss:0.10279
validation loss: (0.112740) -> (0.102789) saving model!!!!
[7 / 100train_loss:0.13499 valid_loss:0.09821
validation loss: (0.102789) -> (0.098213) saving model!!!!
[8 / 100train_loss:0.12751 valid_loss:0.09558
validation loss: (0.098213) -> (0.095581) saving model!!!!
[9 / 100train_loss:0.11567 valid_loss:0.08603
validation loss: (0.095581) -> (0.086033) saving model!!!!
[10 / 100train_loss:0.10829 valid_loss:0.08986
earlyStopping counter : 1/15
[11 / 100train_loss:0.10461 valid_loss:0.08319
validation loss: (0.086033) -> (0.083191) saving model!!!!
[12 / 100train_loss:0.09654 valid_loss:0.08188
validation loss: (0.083191) -> (0.081877) saving model!!!!
[13 / 100train_loss:0.09280 valid_loss:0.08119
validation loss: (0.081877) -> (0.081185) saving model!!!!
[14 / 100train_loss:0.08834 valid_loss:0.07885
validation loss: (0.081185) -> (0.078854) saving model!!!!
[15 / 100train_loss:0.08574 valid_loss:0.07706
validation loss: (0.078854) -> (0.077061) saving model!!!!
[16 / 100train_loss:0.08248 valid_loss:0.07773
earlyStopping counter : 1/15
[17 / 100train_loss:0.07739 valid_loss:0.07931
earlyStopping counter : 2/15
[18 / 100train_loss:0.07500 valid_loss:0.07516
validation loss: (0.077061) -> (0.075158) saving model!!!!
[19 / 100train_loss:0.07197 valid_loss:0.07416
validation loss: (0.075158) -> (0.074157) saving model!!!!
[20 / 100train_loss:0.07283 valid_loss:0.07270
validation loss: (0.074157) -> (0.072698) saving model!!!!
[21 / 100train_loss:0.07025 valid_loss:0.07617
earlyStopping counter : 1/15
[22 / 100train_loss:0.06892 valid_loss:0.07474
earlyStopping counter : 2/15
[23 / 100train_loss:0.06567 valid_loss:0.07290
earlyStopping counter : 3/15
[24 / 100train_loss:0.06516 valid_loss:0.07624
earlyStopping counter : 4/15
[25 / 100train_loss:0.06244 valid_loss:0.07824
earlyStopping counter : 5/15
[26 / 100train_loss:0.06258 valid_loss:0.07696
earlyStopping counter : 6/15
[27 / 100train_loss:0.05644 valid_loss:0.07599
earlyStopping counter : 7/15
[28 / 100train_loss:0.05728 valid_loss:0.07663
earlyStopping counter : 8/15
[29 / 100train_loss:0.05725 valid_loss:0.07302
earlyStopping counter : 9/15
[30 / 100train_loss:0.05770 valid_loss:0.07202
validation loss: (0.072698) -> (0.072024) saving model!!!!
[31 / 100train_loss:0.05409 valid_loss:0.07794
earlyStopping counter : 1/15
[32 / 100train_loss:0.05071 valid_loss:0.07306
earlyStopping counter : 2/15
[33 / 100train_loss:0.05190 valid_loss:0.07452
earlyStopping counter : 3/15
[34 / 100train_loss:0.05174 valid_loss:0.07290
earlyStopping counter : 4/15
[35 / 100train_loss:0.04928 valid_loss:0.07531
earlyStopping counter : 5/15
[36 / 100train_loss:0.04986 valid_loss:0.07642
earlyStopping counter : 6/15
[37 / 100train_loss:0.04894 valid_loss:0.07482
earlyStopping counter : 7/15
[38 / 100train_loss:0.04985 valid_loss:0.07716
earlyStopping counter : 8/15
[39 / 100train_loss:0.04625 valid_loss:0.07393
earlyStopping counter : 9/15
[40 / 100train_loss:0.04926 valid_loss:0.07799
earlyStopping counter : 10/15
[41 / 100train_loss:0.04421 valid_loss:0.07863
earlyStopping counter : 11/15
[42 / 100train_loss:0.04845 valid_loss:0.07821
earlyStopping counter : 12/15
[43 / 100train_loss:0.04329 valid_loss:0.08012
earlyStopping counter : 13/15
[44 / 100train_loss:0.04476 valid_loss:0.07810
earlyStopping counter : 14/15
[45 / 100train_loss:0.04101 valid_loss:0.08055
earlyStopping counter : 15/15
[46 / 100train_loss:0.04448 valid_loss:0.07705
early stopping!!!!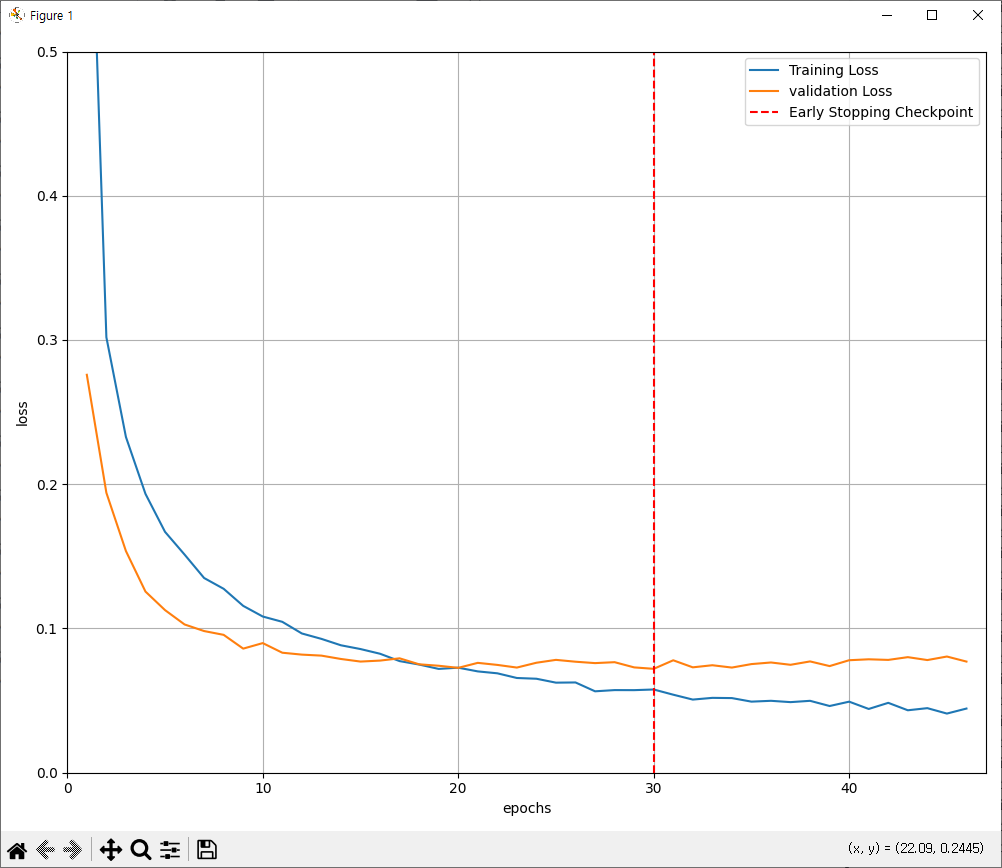
코드설명
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from matplotlib.lines import lineStyles
from torch.utils.data import DataLoader, SubsetRandomSampler
torch.manual_seed(111)
import numpy as np
def create_datasets(batch_size):
train_data = dset.MNIST(root='MNIST_data/',
train=True,
download=True,
transform=transforms.ToTensor())
test_data = dset.MNIST(root='MNIST_data/',
train=False,
download=True,
transform=transforms.ToTensor())
'''
torchvision.datasets.MNIST 를 사용하여 MNIST 데이터셋을 다운로드하고
transforms.ToTensor()를 적용해 텐서로 변환합니다.
train = True 이면 학습 데이터, train = False 이면 테스트 데이터 입니다.
'''
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(0.2 * num_train))
train_idx, valid_idx = indices[split:], indices[:split]
'''
학습 데이터의 20%를 검증 데이터 (validation set)로 사용합니다.
np.random.shuffle(indices) 를 통해 인덱스를 랜덤하게 섞습니다.
처음 20%는 검증 데이터(valid_idx), 나머지는 학습 데이터(train_idx)로 사용합니다.
'''
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
train_loader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
valid_loader = DataLoader(train_data, sampler=valid_sampler, batch_size=batch_size)
test_loader = DataLoader(test_data, batch_size=batch_size)
'''
SubsetRandomSampler 를 사용하여 학습 데이터와 검증 데이터를 분리합니다.
DataLoader를 이용해 데이터를 배치(batch) 단위로 불러올 수 있도록 설정합니다.
'''
return train_loader, test_loader, valid_loader
import torch.nn as nn
import torch.nn.functional as F
class ImageNN(nn.Module):
def __init__(self, drop_p=0.5):
super().__init__()
self.fc1 = nn.Linear(784,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,10)
'''
nn.Linear(784,256) : 입력 크기가 784(28x28)이고, 첫 번째 은닉층(hidden layer)의 뉴런 수는 256개 입니다.
nn.Linear(256,128) : 두 번째 은닉층은 128개 뉴런.
nn.Linear(128,10) : 마지막 출력층은 10개 뉴런 (0~9까지 숫자 분류)
드롭아웃(dropout)을 추가하여 과적합을 방지합니다.
'''
self.dropout_p = drop_p
def forward(self,x):
x = x.view(-1, 784)
out = F.relu(self.fc1(x))
out = F.dropout(out, p=self.dropout_p, training=self.training)
out = F.relu(self.fc2(out))
out = F.dropout(out, p=self.dropout_p, training=self.training)
y = self.fc3(out)
return y
'''
x.view(-1,784): 28x28 이미지 데이터를 1차원(784) 으로 변환
F.relu() : 활성화 함수로 ReLU 사용
F.dropout(): 학습 시 뉴런을 랜덤하게 비활성화(drop)하여 일반화를 돕습니다.
'''
import torch.optim as optim
model = ImageNN(drop_p=0.5)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
'''
모델을 생성하고 drop_p=0.5로 드롭아웃 확률을 설정합니다.
nn.CrossEntropyLoss(): 다중 클래스 분류 문제에 적합한 손실 함수
optim.Adam() : Adam 옵티마이저 사용
'''
class EarlyStopping:
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
'''
patience=7 : 검증 손실이 7번 연속으로 개선되지 않으면 학습을 중단합니다.
verbose=True : 모델이 저장될 때 출력 메시지를 표시
delta = 0 : 최소 변화량(변화가 이 값보다 작으면 개선되지 않았다고 판단)
'''
def save_checkpoint(self, val_loss, model):
if self.verbose:
print(f'validation loss: ({self.val_loss_min:.6f}) -> ({val_loss:.6f}) saving model!!!!')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
def __call__(self, val_loss, model):
score = val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score > self.best_score + self.delta:
self.counter += 1
if self.counter > self.patience:
self.early_stop = True
else:
print(f'earlyStopping counter : {self.counter}/{self.patience}')
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
'''
검증 손실(val_loss)이 개선되지 않으면 카운트를 증가시키고, patience 횟수를 초과하면 학습을 중단합니다.
'''
def train_model(model, patience, n_epochs):
train_losses = []
valid_losses = []
avg_train_losses = []
avg_valid_losses = []
early_stopping = EarlyStopping(patience=patience, verbose=True)
'''
train_losses, valid_losses : 미니배치(batch)단위 손실 저장.
avg_train_losses, avg_valid_losses : 에포크(epoch) 단위 평균 손실 저장.
'''
for epoch in range(1, n_epochs+1):
model.train()
for x_train, y_train in train_loader:
optimizer.zero_grad()
hypothesis = model(x_train)
loss = loss_func(hypothesis, y_train)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
'''
optimizer.zero_grad() : 기울기 초기화
hypothesis = model(x_train) : 모델이 예측값 계산
loss = loss_func(hypothesis, y_train) : 손실(loss) 계산.
loss.backward() : 역전파 수행
optimizer.step() : 가중치 업데이트
'''
model.eval()
for x_data, target in valid_loader:
output = model(x_data)
loss = loss_func(output, target)
valid_losses.append(loss.item())
'''
검증 데이터(valid_loader)를 이용해 모델을 평가(model.eval())합니다.
'''
train_loss = np.mean(train_losses)
valid_loss = np.mean(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
epoch_len = len(str(n_epochs))
print(f'[{epoch:<{epoch_len}} / {n_epochs: >{epoch_len}}'+
f'train_loss:{train_loss:.5f} valid_loss:{valid_loss:.5f}')
train_losses=[]
valid_losses=[]
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print('early stopping!!!!')
break
''' 조기 종료 체크 '''
model.load_state_dict(torch.load('checkpoint.pt'))
return model,avg_train_losses, avg_valid_losses
''' 최적의 모델(checkpoint.pt)을 불러옵니다. '''
batch_size = 256
n_epochs = 100
train_loader, test_loader, valid_loader = create_datasets(batch_size)
patience = 15
model, train_loss, valid_loss = train_model(model, patience, n_epochs)
'''
batch_size = 256 : 배치 크기 256
n_epochs = 100 : 최대 100 에포크 학습
patience = 15 : 15번 이상 검증 손실 없으면 학습 중단.
'''
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,8))
plt.plot(range(1,len(train_loss)+1), train_loss, label='Training Loss')
plt.plot(range(1,len(train_loss)+1), valid_loss, label='validation Loss')
minpos = valid_loss.index(min(valid_loss)) + 1
plt.axvline(minpos, linestyle='--', color='r', label='Early Stopping Checkpoint')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.ylim(0,0.5)
plt.xlim(0,len(train_loss)+1)
plt.grid(True)
plt.legend(loc='best')
plt.tight_layout()
plt.show()
'''
훈련 손실(train_loss)과 검증 손실(valid_loss)을 그래프로 시각화.
plt.axvline(minpos, linestyle='--', color='r') : 최소 검증 손실 지점(최적 모델 저장 시점) 에 빨간 선 표시.
'''
