CNN
'504192'
일반적인 사람에게 이 사진의 숫자를 읽어보라 하면 대부분 '504192' 라고 읽을 것
그런데 컴퓨터에게 이 글씨를 읽게 하고 이 글씨가 어떤 의미인지를 알게 하는 과정은 쉽지 않음
숫자 5는 어떤 특징을 가졌고, 숫자 9는 6과 어떻게 다른지를 기계가 스스로 파악하여 정확하게 읽고 판단하게 만드는 것은 머신러닝의 오랜 진입 과제였음
MNIST 데이터셋은 미국 국립표준기술원(NIST)이 고등학생과 인구조사국 직원 등이 쓴 손글씨를 이용해 만든 데이터로 구성되어 있음
70,000개의 글자 이미지에 각각 0부터 9까지 이름표를 붙인 데이터셋
머신러닝을 배우는 사람이라면 자신의 알고리즘과 다른 알고리즘의 성과를 비교해 보고자 한 번씩 도전해 보는 가장 유명한 데이터 중 하나
Fully Connected Layer 만으로 구성된 인공 신경망의 입력 데이터는 1차원(배열) 형태로 한정된다.
한 장의 컬러 사진은 3차원 데이터입니다. 배치 모드에 사용되는 여러 장의 사진은 4차원 데이터 입니다. 사진 데이터로 전 연결(FC, Fully Connected) 신경망을 학습시켜야 할 경우에, 3차원 사진 데이터를 1차원으로 평면화 시켜야 한다.
사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수밖에 없다. 결과적으로 이미지 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 추출 및 학습이 비효율적으고 정확도를 높이는데 한계가 있습니다. 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델이 바로 CNN(Convolutional Neural Networ)이다.
CNN 차별성
CNN(Convolutional Neural Network)은 기존 Fully Connected Neural Network 와 비교하여 다음과 같은 차별성을 갖는다.
-
각 레이어의 입출력 데이터의 형상 유지
-
이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
-
복수의 필터로 이미지의 특징 추출 및 학습
-
추출한 이미지의 특징을 모으고 강화하는 pooling 레이어
-
필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 매우 적음
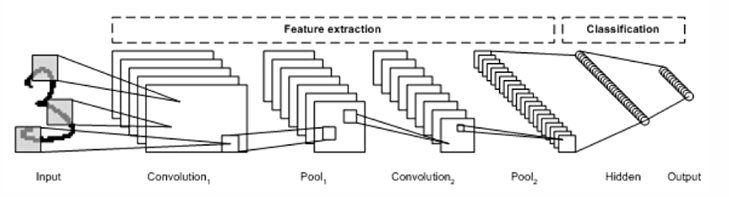
CNN은 아래의 이미지와 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있다.
컨볼루션(Convolution)
컨볼루션 신경망은 입력된 이미지에서 다시 한번 특징을 추출하기 위해 마스크(필터, 윈도 또는 커널이라고도 함)를 도입하는 기법
채널(channel)
컬러 사진은 천연색을 표현하기 위해서, 각 픽셀을 RGB 3개의 실수로 표현한 3차원 데이터이다.
컬러 이미지는 3개의 채널로 구성된다. 반면에 흑백 명암만을 표현하는 흑백 사진은 2차원 데이터로 1개 채널로 구성된다
필터(filter)
Filter를 Kernel이라고 한다.
필터는 일반적으로 (4,4)이나 (3,3)과 같은 정사각 행렬로 정의된다.
CNN에서 학습의 대상은 필터 파라미터 이다. 그림과 같이 입력 데이터를 지정된 간격으로 순회하며 채널별로 합성곱을 하고 모든 채널(컬러의 경우 3개) 의 합성곱의 합을 Feature Map 로 만든다.
스트라이드(stride)
필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산한다.
여기서 지정된 간격으로 필터를 순회하는 간격을 Stride 라고 한다.
입력 데이터가 여러 채널을 갖을 경우 필터는 각 채널을 순회하며 합성곱을 계산한 후, 채널별 피처 맵을 만든다.
각 채널의 피처 맵을 합산하여 최종 피처 맵으로 반환한다.
입력 데이터는 채널 수와 상관없이 필터 별로 1개의 피처 맵이 만들어 진다.
패딩(padding)
Convolution 레이어에서 Filter와 Stride에 작용으로 Feature Map 크기는 입력데이터 보다 작다.
Convolution 레이어의 출력 데이터가 줄어드는 것을 방지하는 방법이 패딩이다.
패딩은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미한다.
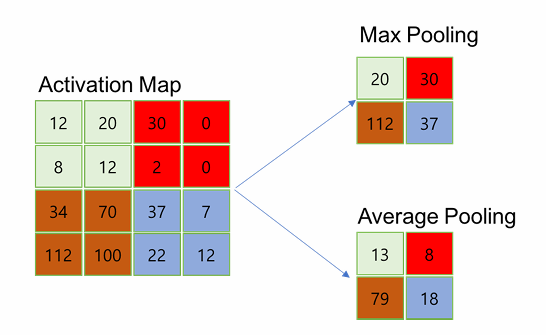
풀링(pooling)
풀링 레이어는 컨볼루션 레이어의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용된다.
폴링 레이어를 처리하는 방법으로는 Max Pooling과 Average Pooling, Min Pooling이 있다.
CNN 구성
CNN은 Convolution Layer와 Max Pooling 레이어를 반복적으로 stack을 쌓는 특징 추출(Feature Extraction)부분과 Fully Connected Layer를 구성하고 마지막 출력층에 Softmax 를 적용한 분류 부분으로 나뉜다.
출처 : https://yjjo.tistory.com/8
CNN(Convolutional Neural Network)은 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식하고 강조하는 방식으로 이미지의 특징을 추출하는 부분과 이미지를 분류하는 부분으로 구성된다. 특징 추출 영역은 Filter를 사용하여 공유 파라미터 수를 최소화하면서 이미지의 특징을 찾는 Convolution 레이어와 특징을 강화하고 모으는 Pooling 레이어로 구성된다.
CNN은 Filter의 크기, Stride, Padding 과 Pooling 크기로 출력 데이터 크기를 조절하고, 필터의 개수로 출력 데이터의 채널을 결정한다.
CNN는 같은 레이어 크기의 Fully Connected Neural Network와 비교해 볼 때, 학습 파라미터양은 20%규모이다. 은닉층이 깊어질 수록 학습 파라미터의 차이는 더 벌어진다. CNN은 Fully Connected Neural Network와 비교하여 더 작은 학습 파라미터로 더 높은 인식률을 제공한다.
CNN 모델
ILSVRC 대회 (CVPR 학술대회에서 개최)
1000 부류에 대해 분류, 검출, 위치 지정 문제 : 1순위와 5순위 오류율로 대결
120만 장의 훈련집합, 5만 장의 검증집합, 15만장의 테스트집합
우승 : AlexNet(2012) -> Clarifi팀(2013) -> GoogLeNet & VGGNet(2014) -> ResNet(2015)
우승한 CNN은 프로그램과 가중치를 공개함으로써 널리 사용되는 표준 신경망이 된다.
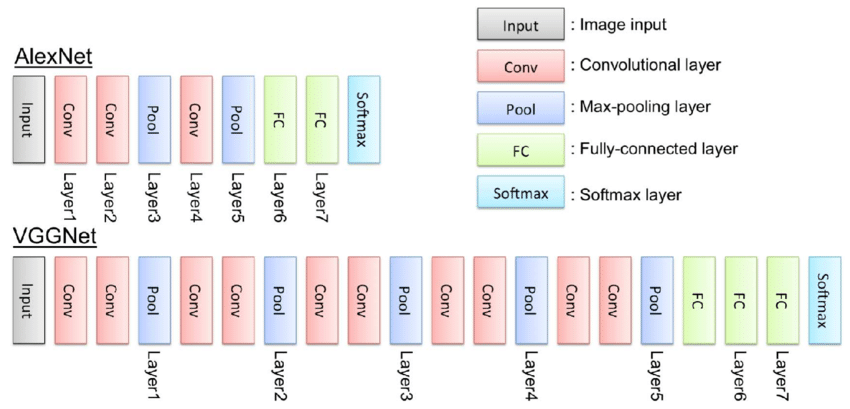
CNN모델(AlexNet)
구조
컨볼루션층 5개와 완전연결(FC)층 3개
컨볼루션층은 200만개, FC층은 6500만개 가량의 매개변수
FC층에 30배 많은 매개변수 -> 향후 CNN은 FC층의 매개변수를 줄이는 방향으로 발전한다.
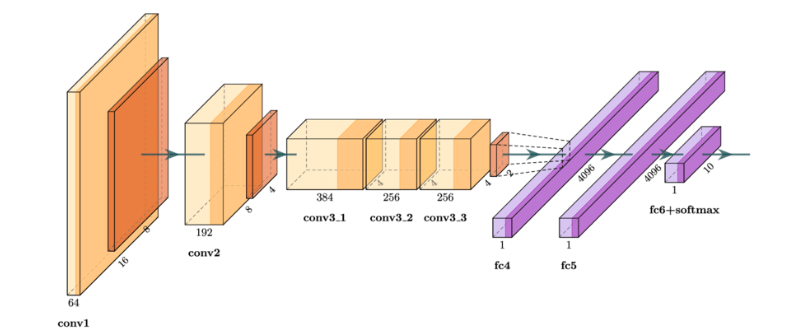
CNN모델(VGGNet)
3*3 의 작은 커널을 사용하여 신경망을 더욱 깊게 만든다
컨볼루션층 8~16개를 두어 AlexNet의 5개에 비해 2~3배 깊어진다
16층짜리 VGG-16 (컨볼루션 13층 + FC 3층)
출처 : https://codebaragi23.github.io/machine%20learning/1.-VGGNet-paper-review/
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
root = 'images/images'
dataset = ImageFolder(root=root,
transform=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor()
]))
data_loader = DataLoader(dataset,
batch_size=32,
shuffle=True)
print(dataset.classes)
images, labels = next(iter(data_loader))
print(images.shape)
print(labels.shape)
print(labels)
labels.map = {v:k for k, v in dataset.class_to_idx.items()}
print(labels.map)
print(len(dataset))
from torch.utils.data import random_split
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_data, test_data = random_split(dataset, [train_size, test_size])
batch_size = 32
train_loader = DataLoader(train_data,
batch_size = batch_size,
shuffle=True)
test_loader = DataLoader(test_data,
batch_size = batch_size,
shuffle=False)
from torchvision import models
model = models.vgg16(pretrained=True)
#print(model)
for param in model.parameters():
# print(param.requires_grad)
param.requires_grad = False
import torch.nn as nn
fc = nn.Sequential(
nn.Linear(7 * 7 * 512, 256),
nn.ReLU(),
nn.Linear(256,64),
nn.ReLU(),
nn.Linear(64,2)
)
model.classifier = fc
print(model)
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr = 0.0005)
loss_func = nn.CrossEntropyLoss()
def model_train(model, data_loader, loss_fn, optimizer):
model.train()
running_loss = 0
corr = 0
for idx, (x_data, y_data) in enumerate(data_loader):
optimizer.zero_grad()
hypothesis = model(x_data)
loss = loss_fn(hypothesis, y_data)
loss.backward()
optimizer.step()
pred = hypothesis.argmax(dim=1)
corr += pred.eq(y_data).sum().item()
running_loss += loss.item() * x_data.size(0)
print(f'{idx}/{len(data_loader)}')
acc = corr / len(data_loader.dataset)
return running_loss / len(data_loader.dataset), acc
import torch
def model_evaluate(model, data_loader, loss_fn):
model.eval()
with torch.no_grad():
corr = 0
running_loss = 0
for x_test, y_test in data_loader:
hypothesis = model(x_test)
pred = hypothesis.argmax(dim=1)
corr += torch.sum(pred.eq(y_test)).item()
running_loss += loss_fn(hypothesis, y_test).item() * x_test.size(0)
acc = corr / len(data_loader.dataset)
return running_loss / len(data_loader.dataset), acc
num_epochs = 10
model_name = 'vgg16-trained'
min_loss = np.inf
for epoch in range(num_epochs):
train_loss, train_acc = model_train(model, train_loader, loss_func, optimizer)
val_loss, val_acc = model_evaluate(model, test_loader, loss_func)
if val_loss < min_loss:
print(f'val_loss has been improved from {min_loss:.5f} to {val_loss:.5f}. saving model!!!!!!!')
min_loss = val_loss
torch.save(model.state_dict(), f'{model_name}.pth')
print(f'epoch:{epoch+1} loss{train_loss:.5f}, acc:{train_acc:.5f} val_loss:{val_loss:.5f}, val_acc:{val_acc:.5f}')
model.load_state_dict(torch.load(f'{model_name}.pth'))
final_loss, final_acc = model_evaluate(model, test_loader, loss_func)
print(f'evaluation loss:{final_loss:.5f} evaluation accuracy:{final_acc:.5f}')
GPU 사용
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
import torch
# GPU 설정 (CUDA가 가능하면 GPU 사용, 아니면 CPU 사용)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
root = 'images/images'
# 데이터셋 불러오기 및 변환 적용
dataset = ImageFolder(root=root,
transform=transforms.Compose([
transforms.Resize([224, 224]), # 이미지 크기 조정
transforms.ToTensor() # 텐서 변환
]))
# 데이터 로더 설정
data_loader = DataLoader(dataset,
batch_size=32,
shuffle=True) # 데이터 무작위 섞기
# 데이터셋 클래스 확인
print(dataset.classes)
# 샘플 데이터 확인
images, labels = next(iter(data_loader))
print(images.shape)
print(labels.shape)
print(labels)
# 클래스 이름과 인덱스를 매핑
labels.map = {v: k for k, v in dataset.class_to_idx.items()}
print(labels.map)
print(len(dataset))
from torch.utils.data import random_split
# 데이터셋을 학습 데이터(80%)와 테스트 데이터(20%)로 분할
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_data, test_data = random_split(dataset, [train_size, test_size])
batch_size = 32
# 학습 데이터 로더
train_loader = DataLoader(train_data,
batch_size=batch_size,
shuffle=True)
# 테스트 데이터 로더
test_loader = DataLoader(test_data,
batch_size=batch_size,
shuffle=False)
from torchvision import models
# 사전 학습된 VGG16 모델 불러오기
model = models.vgg16(pretrained=True).to(device)
# 기존 가중치 고정 (특정 레이어만 학습하도록 설정)
for param in model.parameters():
param.requires_grad = False
import torch.nn as nn
# 분류기(FC 레이어) 수정
fc = nn.Sequential(
nn.Linear(7 * 7 * 512, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 2) # 클래스 개수(예: 2개)
)
# VGG 모델의 분류기를 새로운 분류기로 변경
model.classifier = fc.to(device)
print(model)
import torch.optim as optim
# 옵티마이저 및 손실 함수 설정
optimizer = optim.Adam(model.parameters(), lr=0.0005)
loss_func = nn.CrossEntropyLoss()
# 모델 학습 함수 정의
def model_train(model, data_loader, loss_fn, optimizer):
model.train()
running_loss = 0
corr = 0
for idx, (x_data, y_data) in enumerate(data_loader):
x_data, y_data = x_data.to(device), y_data.to(device) # 데이터를 GPU로 이동
optimizer.zero_grad()
hypothesis = model(x_data)
loss = loss_fn(hypothesis, y_data)
loss.backward()
optimizer.step()
pred = hypothesis.argmax(dim=1) # 예측값 계산
corr += pred.eq(y_data).sum().item() # 정확도 계산
running_loss += loss.item() * x_data.size(0)
print(f'{idx}/{len(data_loader)}')
acc = corr / len(data_loader.dataset)
return running_loss / len(data_loader.dataset), acc
# 모델 평가 함수 정의
def model_evaluate(model, data_loader, loss_fn):
model.eval()
with torch.no_grad():
corr = 0
running_loss = 0
for x_test, y_test in data_loader:
x_test, y_test = x_test.to(device), y_test.to(device) # 데이터를 GPU로 이동
hypothesis = model(x_test)
pred = hypothesis.argmax(dim=1)
corr += torch.sum(pred.eq(y_test)).item()
running_loss += loss_fn(hypothesis, y_test).item() * x_test.size(0)
acc = corr / len(data_loader.dataset)
return running_loss / len(data_loader.dataset), acc
# 학습 실행
num_epochs = 10
model_name = 'vgg16-trained'
min_loss = np.inf
for epoch in range(num_epochs):
train_loss, train_acc = model_train(model, train_loader, loss_func, optimizer)
val_loss, val_acc = model_evaluate(model, test_loader, loss_func)
# 모델 저장 (최상의 검증 손실을 기록)
if val_loss < min_loss:
print(f'val_loss has been improved from {min_loss:.5f} to {val_loss:.5f}. saving model!!!!!!!')
min_loss = val_loss
torch.save(model.state_dict(), f'{model_name}.pth')
print(f'epoch:{epoch+1} loss{train_loss:.5f}, acc:{train_acc:.5f} val_loss:{val_loss:.5f}, val_acc:{val_acc:.5f}')
# 저장된 모델 불러와서 평가
model.load_state_dict(torch.load(f'{model_name}.pth'))
model.to(device)
final_loss, final_acc = model_evaluate(model, test_loader, loss_func)
print(f'evaluation loss:{final_loss:.5f} evaluation accuracy:{final_acc:.5f}')
# epoch:10 loss0.00009, acc:1.00000 val_loss:0.19417, val_acc:0.95000
# epoch:10 loss0.00003, acc:1.00000 val_loss:0.28842, val_acc:0.94375
# epoch:10 loss0.00011, acc:1.00000 val_loss:0.21265, val_acc:0.96250
# evaluation loss:0.14119 evaluation accuracy:0.93125CNN모델(ResNet)
ResNet은 잔류 학습 사용한다.
전역 평균 폴링 사용(FC층 제거)
배치 정규화 적용 (드롭아웃 적용 불필요) -> 배치 정규화

