로지스틱 회귀 정의
"예, 아니오로만 대답하세요!"
법정 드라마나 영화에서 검사가 피고인을 다그치는 장면의 흔한 대사
때로 할 말이 많아도 예 혹은 아니오로만 대답해야 할 때가 있음
-> 이와 같은 상황이 딥러닝에서도 끊임없이 일어남
전달받은 정보를 놓고 참과 거짓 중에 하나를 판단해 다음 단계로 넘기는 장치들이 딥러닝 내부에서 쉬지 않고 작동한다.
딥러닝을 수행한다는 것은 겉으로 드러나지 않는 '미니 판단 장치'들을 이용해서 복잡한 연산을 해낸 끝에 최적의 예측 값을 내놓는 작업!
이렇게 참과 거짓 중에 하나를 내놓는 과정은 로지스틱 회귀(logistic regression) 의 원리를 거쳐 이루어짐
참인지 거짓인지를 구분하는 로지스틱 회귀의 원리를 이용해 '참, 거짓 미니 판단 장치' 를 만들어 주어진 입력 값의 특징을 추출함
이를 저장해서 '모델(model)'을 만듦
그런 다음 누군가 비슷한 질문을 하면 지금까지 만들어 놓은 이 모델을 꺼내어 답을 함
이것이 바로 딥러닝 동작 원리!
시그모이드 함수
S자 형태로 그래프가 그려지는 함수가 있다! -> 시그모이드 함수(sigmoid function)
시그 모이드 함수를 나타내는 방정식
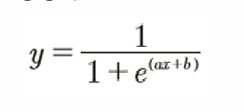
여기서 e는 자연 상수라고 불리는 무리수로 값은 2.71828...
파이 처럼 수학에서 중요하게 사용되는 상수로 고정된 값이므로 우리가 따로 구해야 하는 값은 아님
우리가 구해야 하는 값은 결국 ax+b
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1+np.exp(-x))
x = np.arange(-10,10,0.1)
y = sigmoid(x)
plt.plot([0,0],[1,0],':')
plt.plot([-10,10],[0,0],':')
plt.plot([-10,10],[1,1],':')
plt.plot(x,y)
plt.grid(True)
plt.show()
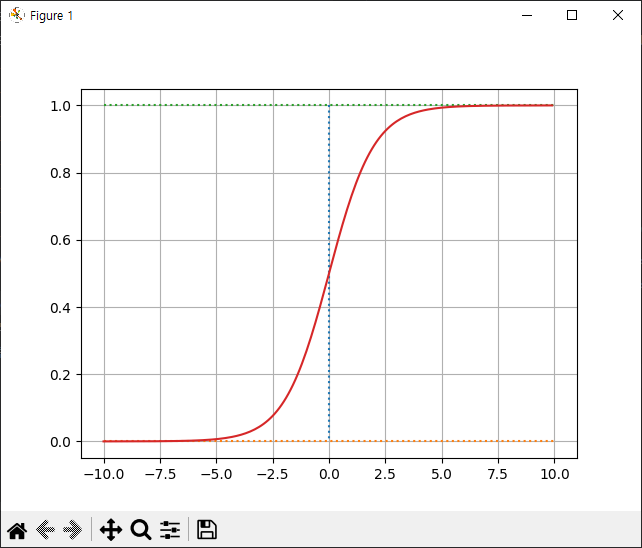
선형 회귀에서 우리가 구해야 하는 것이 a와 b였듯이 여기서도 마찬가지
먼저 a는 그래프의 경사도를 결정
아래 그림과 같이 a 값이 커지면 경사가 커지고 a 값이 작아지면 경사가 작아짐
a 값의 변화에 따른 기울기 변화
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1+np.exp(-x))
x = np.arange(-10,10,0.1)
y = sigmoid(x)
plt.plot([0,0],[1,0],':')
plt.plot([-10,10],[0,0],':')
plt.plot([-10,10],[1,1],':')
y1 = sigmoid(0.5 * x)
y2 = sigmoid(x)
y3 = sigmoid(2 * x)
plt.plot(x,y1,label='0.5 * y')
plt.plot(x,y2, label='x')
plt.plot(x,y3, label='2 * x')
plt.grid(True)
plt.legend(loc='best')
plt.show()
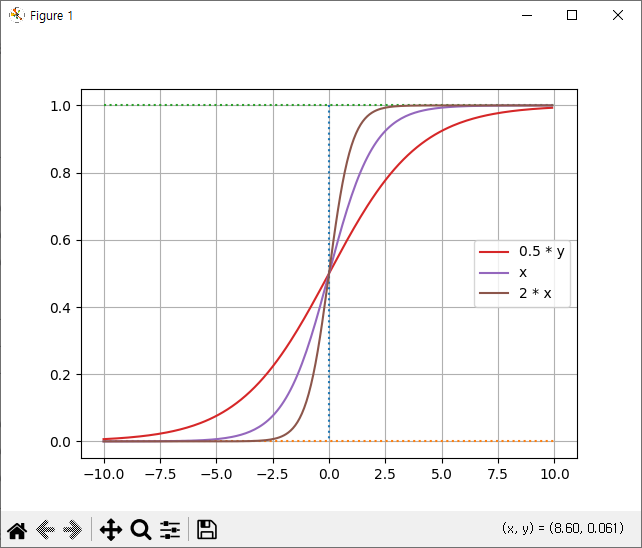
b는 그래프의 좌우 이동을 의미
아래 그림과 같이 b 값이 크고 작아짐에 따라 그래프가 이동함
b 값의 변화에 따른 그래프 변화
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1+np.exp(-x))
x = np.arange(-10,10,0.1)
y = sigmoid(x)
plt.plot([0,0],[1,0],':')
plt.plot([-10,10],[0,0],':')
plt.plot([-10,10],[1,1],':')
y1 = sigmoid(x - 1.5)
y2 = sigmoid(x)
y3 = sigmoid(x + 1.5)
plt.plot(x,y1,label='x - 1.5')
plt.plot(x,y2, label='x')
plt.plot(x,y3, label='x + 1.5')
plt.grid(True)
plt.legend(loc='best')
plt.show()
a와 오차와의 관계
a 가 작아질수록 오차는 무한대로 커지지만, a가 커진다고 해서 오차가 무한대로 커지지는 않는다.
b와 오차와의 관계
a 값이 너무 작아지거나 커지면 오차도 무한대로 커진다.
오차 공식
이제 우리에게 주어진 과제는 또다시 a와 b의 값을 구하는 것임
시그모이드 함수에서 a와 b의 값을 어떻게 구해야 할까?
답은 역시 경사 하강법
그런데 경사 하강법은 먼저 오차를 구한 다음 오차가 작은 쪽으로 이동시키는 방법
그렇다면 이번에도 예측 값과 실제 값의 차이, 즉 오차를 구하는 공식이 필요함
시그모이드 함수의 특징은 y 값이 0과1 사이라는 것
따라서 실제 값이 1일 때 예측 값이 0에 가까워지면 오차가 커져야 함
반대로, 실제 값이 0일 때 예측 값이 1에 가까워지는 경우에도 오차는 커져야 함
이를 공식으로 만들 수 있게 해 주는 함수 : 로그함수
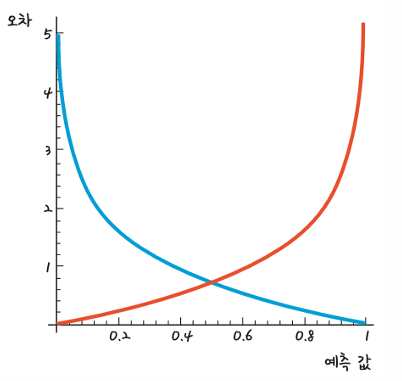
파란색 선은 실제 값이 1 일 때 사용할 수 있는 그래프
예측 값이 1 일 때 오차가 0 이고, 반대로 예측 값이 0에 가까울수록 오차는 커짐
ㄴ
빨간색 선은 반대로 실제 값이 0 일 때 사용할 수 있는 함수
예측 값이 0 일 때 오차가 없고, 1에 가까워질수록 오차가 매우 커짐
앞의 파란색과 빨간색 그래프의 식은 각각 -log h와 -log (1 - h)
y의 실제 값이 1일 때 –log h 그래프를쓰고, 0일 때 -log (1 - h) 그래프를 써야 함
이는 다음과 같은 방법으로 해결할 수 있음
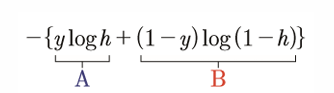
실제 값 y가 1이면 B 부분이 없어짐
반대로 0이면 A 부분이 없어짐
따라서 y 값에 따라 빨간색 그래프와 파란색 그래프를 각각 사용할 수 있게 됨
import torch
import torch.optim as optim
x_data = [[1,2],[2,3],[3,1],[4,3],[5,3],[6,2]]
y_data = [[0],[0],[0],[1],[1],[1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
w = torch.zeros((2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
hypothesis = 1 / (1 + torch.exp(-(x_train.matmul(w)+b)))
print(hypothesis)
print()
hypothesis2 = torch.sigmoid(x_train.matmul(w) + b)
print(hypothesis2)
print()
losses = -(y_train * torch.log(hypothesis2) + (1 - y_train) * torch.log(1 -hypothesis2))
print(losses)
print()
loss = losses.mean()
print(loss)
import torch.nn.functional as F
loss2 = F.binary_cross_entropy(hypothesis2, y_train)
print(loss2)
optimizer = optim.SGD([w,b], lr=1)
for epoch in range(1000):
hypothesis = torch.sigmoid(x_train.matmul(w)+b)
loss = F.binary_cross_entropy(hypothesis, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'epoch{epoch+1} loss:{loss.item():.4f}')
print()
hypothesis = torch.sigmoid(x_train.matmul(w)+b)
print(hypothesis)
prediction = hypothesis > 0.5
print(prediction) tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<MulBackward0>)
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward0>)
tensor([[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931]], grad_fn=<NegBackward0>)
tensor(0.6931, grad_fn=<MeanBackward0>)
tensor(0.6931, grad_fn=<BinaryCrossEntropyBackward0>)
epoch1 loss:0.6931
epoch101 loss:0.1347
epoch201 loss:0.0806
epoch301 loss:0.0579
epoch401 loss:0.0453
epoch501 loss:0.0373
epoch601 loss:0.0317
epoch701 loss:0.0276
epoch801 loss:0.0244
epoch901 loss:0.0219
tensor([[2.7711e-04],
[3.1636e-02],
[3.9014e-02],
[9.5618e-01],
[9.9823e-01],
[9.9969e-01]], grad_fn=<SigmoidBackward0>)
tensor([[False],
[False],
[False],
[ True],
[ True],
[ True]])
로지스틱 회귀
import torch
import torch.nn as nn
x = torch.FloatTensor(torch.randn(16,10))
class CustomLinear(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self,x):
y = self.linear(x)
return y
CModel = CustomLinear(10,5)
y = CModel.forward(x)
print(y)
print()
y2 = CModel(x)
print(y2)tensor([[-2.6341e-01, -1.0208e+00, -2.5800e-01, -3.1607e-01, 3.3978e-02],
[-1.0624e-01, -1.4139e+00, -4.7145e-01, 1.8639e-01, -1.2951e+00],
[-4.8658e-01, -3.3047e-01, 7.5490e-01, 9.2192e-04, 7.1388e-01],
[ 1.0006e+00, -3.6216e-01, 1.5522e-01, -9.1982e-01, 5.2496e-01],
[-2.5777e-01, -5.0360e-01, -5.5840e-01, -3.7397e-03, -3.6565e-02],
[-8.4089e-01, 6.2029e-01, 9.4616e-01, -1.4691e-01, -3.4951e-01],
[ 3.3397e-01, 4.9649e-01, 6.7951e-02, -5.7414e-01, 5.8304e-01],
[-5.0281e-01, 6.7047e-01, 1.9916e-01, -2.5474e-01, 2.7591e-01],
[-8.7686e-01, 1.3770e+00, 2.3860e-01, 7.4601e-02, -6.8819e-01],
[ 1.0100e+00, 5.6837e-01, 9.8449e-02, -3.6363e-01, -4.5011e-01],
[-8.0752e-01, -3.9387e-01, 2.4441e-01, -2.4610e-01, 5.0092e-04],
[-7.6974e-01, 5.6311e-01, 9.9695e-01, 5.8447e-03, -7.6326e-02],
[ 4.5107e-01, -3.0980e-01, -1.4181e-01, -2.2309e-01, -2.2975e-03],
[-1.9953e-02, 2.4106e-01, 1.1845e+00, 9.0231e-03, -2.5761e-01],
[-7.0585e-01, 2.5033e-02, 1.4928e+00, 6.1135e-01, -1.2899e+00],
[-9.8386e-01, -2.5446e-01, 1.0505e+00, 8.0299e-02, 1.9774e-01]],
grad_fn=<AddmmBackward0>)
tensor([[-2.6341e-01, -1.0208e+00, -2.5800e-01, -3.1607e-01, 3.3978e-02],
[-1.0624e-01, -1.4139e+00, -4.7145e-01, 1.8639e-01, -1.2951e+00],
[-4.8658e-01, -3.3047e-01, 7.5490e-01, 9.2192e-04, 7.1388e-01],
[ 1.0006e+00, -3.6216e-01, 1.5522e-01, -9.1982e-01, 5.2496e-01],
[-2.5777e-01, -5.0360e-01, -5.5840e-01, -3.7397e-03, -3.6565e-02],
[-8.4089e-01, 6.2029e-01, 9.4616e-01, -1.4691e-01, -3.4951e-01],
[ 3.3397e-01, 4.9649e-01, 6.7951e-02, -5.7414e-01, 5.8304e-01],
[-5.0281e-01, 6.7047e-01, 1.9916e-01, -2.5474e-01, 2.7591e-01],
[-8.7686e-01, 1.3770e+00, 2.3860e-01, 7.4601e-02, -6.8819e-01],
[ 1.0100e+00, 5.6837e-01, 9.8449e-02, -3.6363e-01, -4.5011e-01],
[-8.0752e-01, -3.9387e-01, 2.4441e-01, -2.4610e-01, 5.0092e-04],
[-7.6974e-01, 5.6311e-01, 9.9695e-01, 5.8447e-03, -7.6326e-02],
[ 4.5107e-01, -3.0980e-01, -1.4181e-01, -2.2309e-01, -2.2975e-03],
[-1.9953e-02, 2.4106e-01, 1.1845e+00, 9.0231e-03, -2.5761e-01],
[-7.0585e-01, 2.5033e-02, 1.4928e+00, 6.1135e-01, -1.2899e+00],
[-9.8386e-01, -2.5446e-01, 1.0505e+00, 8.0299e-02, 1.9774e-01]],
grad_fn=<AddmmBackward0>)batch
import torch
x_train = torch.FloatTensor([[73,80,75],
[93,88,93],
[89,91,88],
[96,98,100],
[73,66,70]])
y_train = torch.FloatTensor([[152],[185],[180],[196],[142]])
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
dataset = TensorDataset(x_train, y_train)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
print(dataloader)
print()
for data in dataloader:
print(data, end='\n\n')
print()
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(3,1)
optimizer = optim.SGD(model.parameters(), lr=1e-5)
import torch.nn.functional as F
for epoch in range(20):
for batch_idx, data in enumerate(dataloader):
batch_x, batch_y = data
hypothesis = model(batch_x)
loss = F.mse_loss(hypothesis, batch_y)
optimizer.zero_grad
loss.backward()
optimizer.step()
print(f'{epoch + 1} / {batch_idx + 1}, loss:{loss.item():.4f}')
<torch.utils.data.dataloader.DataLoader object at 0x0000021D6809A820>
[tensor([[73., 80., 75.],
[93., 88., 93.]]), tensor([[152.],
[185.]])]
[tensor([[ 96., 98., 100.],
[ 73., 66., 70.]]), tensor([[196.],
[142.]])]
[tensor([[89., 91., 88.]]), tensor([[180.]])]
1 / 1, loss:6673.3921
1 / 2, loss:2047.6831
1 / 3, loss:66.2820
2 / 1, loss:3494.7068
2 / 2, loss:6872.1514
2 / 3, loss:5965.2007
3 / 1, loss:573.5370
3 / 2, loss:858.3049
3 / 3, loss:4942.9668
4 / 1, loss:5523.2778
4 / 2, loss:2392.0249
4 / 3, loss:69.1114
5 / 1, loss:1510.6377
5 / 2, loss:6283.9302
5 / 3, loss:2675.6404
6 / 1, loss:1500.1870
6 / 2, loss:14.8127
6 / 3, loss:2178.3850
7 / 1, loss:4028.7632
7 / 2, loss:3516.9949
7 / 3, loss:296.4013
8 / 1, loss:420.7939
8 / 2, loss:3870.0671
8 / 3, loss:2947.0139
9 / 1, loss:2024.2083
9 / 2, loss:31.2432
9 / 3, loss:834.8931
10 / 1, loss:4216.4097
10 / 2, loss:3858.7593
10 / 3, loss:1670.0559
11 / 1, loss:26.6473
11 / 2, loss:1924.0381
11 / 3, loss:6680.9121
12 / 1, loss:3118.7432
12 / 2, loss:70.6226
12 / 3, loss:1695.6296
13 / 1, loss:3617.6936
13 / 2, loss:4787.7959
13 / 3, loss:591.9705
14 / 1, loss:146.4464
14 / 2, loss:2736.7925
14 / 3, loss:4580.6143
15 / 1, loss:2330.7393
15 / 2, loss:40.1501
15 / 3, loss:985.4317
16 / 1, loss:5031.9204
16 / 2, loss:4314.4062
16 / 3, loss:2188.5095
17 / 1, loss:24.4946
17 / 2, loss:3063.0171
17 / 3, loss:7276.9209
18 / 1, loss:1996.3513
18 / 2, loss:248.4840
18 / 3, loss:1211.2144
19 / 1, loss:3481.9741
19 / 2, loss:4581.8105
19 / 3, loss:1812.7616
20 / 1, loss:12.1901
20 / 2, loss:2773.2246
20 / 3, loss:4753.2417quiz
# a. batch size 는 3으로 한다
# model 은 nn.Module을 상속 받아 구성한다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader
x_train = torch.FloatTensor([[73,80,75,65],
[93,88,93,88],
[89,91,90,76],
[96,98,100,99],
[73,65,70,100],
[84,98,90,100]])
y_train = torch.FloatTensor([[152],[185],[180],[196],[142],[188]])
dataset = TensorDataset(x_train, y_train)
dataloader = DataLoader(dataset, batch_size=3, shuffle=True)
class MLRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(4,1)
def forward(self, x):
return self.linear(x)
model = MLRegressionModel()
optimizer = optim.SGD(model.parameters(),lr=1e-5)
for epoch in range(2000):
for batch_idx, (x_train, y_train) in enumerate(dataloader):
hypothesis = model(x_train)
loss = F.mse_loss(hypothesis, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print('epoch :{} cost:{:.4f}'.format(epoch+1, loss.item()))
epoch :1 cost:40636.3008
epoch :1 cost:12018.6650
epoch :101 cost:7.2847
epoch :101 cost:1.9027
epoch :201 cost:5.4006
epoch :201 cost:3.3131
epoch :301 cost:5.4546
epoch :301 cost:4.8805
epoch :401 cost:3.9817
epoch :401 cost:5.1650
epoch :501 cost:1.0721
epoch :501 cost:6.9170
epoch :601 cost:1.5015
epoch :601 cost:4.6655
epoch :701 cost:2.5420
epoch :701 cost:4.8572
epoch :801 cost:4.3025
epoch :801 cost:1.0483
epoch :901 cost:3.4931
epoch :901 cost:2.2180
epoch :1001 cost:2.8011
epoch :1001 cost:3.6591
epoch :1101 cost:3.6734
epoch :1101 cost:1.8402
epoch :1201 cost:1.1253
epoch :1201 cost:3.9974
epoch :1301 cost:0.5229
epoch :1301 cost:4.4484
epoch :1401 cost:3.3506
epoch :1401 cost:1.6750
epoch :1501 cost:3.6642
epoch :1501 cost:0.9518
epoch :1601 cost:0.3165
epoch :1601 cost:4.1038
epoch :1701 cost:3.4281
epoch :1701 cost:3.6459
epoch :1801 cost:3.5116
epoch :1801 cost:3.0417
epoch :1901 cost:3.3044
epoch :1901 cost:1.1462
연습
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self):
self.x_data = [[73,80,75],
[93,88,93],
[89,91,88],
[96,98,100],
[73,66,70]]
self.y_data = [[152],[185],[180],[196],[142]]
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x,y
dataset = CustomDataset()
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
for data in dataloader:
print(data, end='\n\n')
import torch.optim as optim
model = nn.Linear(3,1)
optimizer = optim.SGD(model.parameters(), lr=1e-5)
import torch.nn.functional as F
for epoch in range(20):
for batch_idx, data in enumerate(dataloader):
batch_x, batch_y = data
hypothesis = model(batch_x)
loss = F.mse_loss(hypothesis, batch_y)
optimizer.zero_grad
loss.backward()
optimizer.step()
print(f'{epoch + 1} / {batch_idx + 1}, loss:{loss.item():.4f}')[tensor([[89., 91., 88.],
[73., 80., 75.]]), tensor([[180.],
[152.]])]
[tensor([[ 93., 88., 93.],
[ 96., 98., 100.]]), tensor([[185.],
[196.]])]
[tensor([[73., 66., 70.]]), tensor([[142.]])]
1 / 1, loss:50600.6133
1 / 2, loss:11882.2373
1 / 3, loss:1227.0132
2 / 1, loss:33472.0234
2 / 2, loss:53256.8984
2 / 3, loss:62223.0703
3 / 1, loss:3989.1262
3 / 2, loss:12829.5176
3 / 3, loss:88522.1953
4 / 1, loss:59516.1719
4 / 2, loss:48194.6367
4 / 3, loss:139.9222
5 / 1, loss:32864.1836
5 / 2, loss:79075.6953
5 / 3, loss:122931.7266
6 / 1, loss:20214.8359
6 / 2, loss:11837.7256
6 / 3, loss:76835.7891
7 / 1, loss:158309.6406
7 / 2, loss:95110.4688
7 / 3, loss:11771.0137
8 / 1, loss:29951.1250
8 / 2, loss:129955.8047
8 / 3, loss:92105.9922
9 / 1, loss:103458.6250
9 / 2, loss:1919.0164
9 / 3, loss:35132.7656
10 / 1, loss:188928.6250
10 / 2, loss:135002.5156
10 / 3, loss:25271.3359
11 / 1, loss:2114.1470
11 / 2, loss:65821.7188
11 / 3, loss:157901.5000
12 / 1, loss:84661.2578
12 / 2, loss:7437.9873
12 / 3, loss:26668.8555
13 / 1, loss:110612.6406
13 / 2, loss:80699.8125
13 / 3, loss:19879.7012
14 / 1, loss:94.6433
14 / 2, loss:28607.5371
14 / 3, loss:108946.4531
15 / 1, loss:43143.5000
15 / 2, loss:5594.2168
15 / 3, loss:13661.0928
16 / 1, loss:47934.0391
16 / 2, loss:59519.9766
16 / 3, loss:42114.2656
17 / 1, loss:53.7648
17 / 2, loss:37306.8906
17 / 3, loss:57149.6367
18 / 1, loss:78054.3281
18 / 2, loss:12422.4570
18 / 3, loss:5424.7993
19 / 1, loss:57497.0078
19 / 2, loss:97834.8750
19 / 3, loss:58230.3828
20 / 1, loss:2647.5842
20 / 2, loss:25903.4180
20 / 3, loss:77982.6797예제
import torch
import torch.optim as optim
x_data = [[1,2],[2,3],[3,1],[4,3],[5,3],[6,2]]
y_data = [[0],[0],[0],[1],[1],[1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
import torch.nn as nn
class LogisticClass(nn.Module):
def __init__(self):
super().__init__()
self.sigmoid = nn.Sigmoid()
self.linear = nn.Linear(2,1)
def forward(self,x):
return self.sigmoid(self.linear(x))
import torch.nn.functional as F
model = LogisticClass()
optimizer = optim.SGD(model.parameters(), lr=1)
w = torch.zeros((2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
hypothesis = model(x_train)
print(hypothesis)
print()
hypothesis2 = torch.sigmoid(x_train.matmul(w) + b)
print(hypothesis2)
print()
losses = -(y_train * torch.log(hypothesis2) + (1 - y_train) * torch.log(1 -hypothesis2))
print(losses)
print()
loss = losses.mean()
print(loss)
import torch.nn.functional as F
loss2 = F.binary_cross_entropy(hypothesis2, y_train)
print(loss2)
optimizer = optim.SGD([w,b], lr=1)
for epoch in range(1000):
hypothesis = model(x_train)
loss = F.binary_cross_entropy(hypothesis, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
prediction = hypothesis > torch.FloatTensor([0.5])
correction_prediction = prediction.float() == y_train
accuracy = correction_prediction.sum().item() / len(correction_prediction)
print(f'epoch{epoch + 1} loss:{loss.item():.4f} accuracy:{accuracy * 100: 2.2f}')
print()
hypothesis = torch.sigmoid(x_train.matmul(w)+b)
print(hypothesis)
prediction = hypothesis > 0.5
print(prediction)tensor([[0.2176],
[0.0931],
[0.1929],
[0.0456],
[0.0315],
[0.0394]], grad_fn=<SigmoidBackward0>)
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward0>)
tensor([[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931]], grad_fn=<NegBackward0>)
tensor(0.6931, grad_fn=<MeanBackward0>)
tensor(0.6931, grad_fn=<BinaryCrossEntropyBackward0>)
epoch1 loss:1.7226 accuracy: 50.00
epoch101 loss:1.7226 accuracy: 50.00
epoch201 loss:1.7226 accuracy: 50.00
epoch301 loss:1.7226 accuracy: 50.00
epoch401 loss:1.7226 accuracy: 50.00
epoch501 loss:1.7226 accuracy: 50.00
epoch601 loss:1.7226 accuracy: 50.00
epoch701 loss:1.7226 accuracy: 50.00
epoch801 loss:1.7226 accuracy: 50.00
epoch901 loss:1.7226 accuracy: 50.00
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward0>)
tensor([[False],
[False],
[False],
[False],
[False],
[False]])
에제2
import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print(cancer.keys())
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['class'] = cancer.target
df.info()
cols = ['mean radius', 'mean texture', 'mean perimeter','mean area','mean smoothness',
'mean concavity', 'worst radius', 'worst perimeter','worst concavity','worst texture','class']
import torch
import torch.nn as nn
import torch.optim as optim
data = torch.from_numpy(df[cols].values).float()
x_train = data[:,:-1]
y_train = data[:,-1:]
print(x_train.shape, y_train.shape)
class LogisticModel(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.Linear = nn.Linear(input_size, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.sigmoid(self.Linear(x))
return y
model = LogisticModel(input_size=x_train.size(-1), output_size=y_train.size(-1))
loss_func = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=5e-5)
for epoch in range(200000):
hypothesis = model(x_train)
loss = loss_func(hypothesis, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10000 == 0:
print(f'epoch:{epoch+1}loss:{loss.item():.4f}')
correction_cnt = (y_train == (hypothesis > 0.5)).sum()
print('accuracy : {:2.1f}'.format(correction_cnt/float(y_train.size(0))*100))dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
14 smoothness error 569 non-null float64
15 compactness error 569 non-null float64
16 concavity error 569 non-null float64
17 concave points error 569 non-null float64
18 symmetry error 569 non-null float64
19 fractal dimension error 569 non-null float64
20 worst radius 569 non-null float64
21 worst texture 569 non-null float64
22 worst perimeter 569 non-null float64
23 worst area 569 non-null float64
24 worst smoothness 569 non-null float64
25 worst compactness 569 non-null float64
26 worst concavity 569 non-null float64
27 worst concave points 569 non-null float64
28 worst symmetry 569 non-null float64
29 worst fractal dimension 569 non-null float64
30 class 569 non-null int32
dtypes: float64(30), int32(1)
memory usage: 135.7 KB
torch.Size([569, 10]) torch.Size([569, 1])
epoch:1loss:37.4614
epoch:10001loss:0.3045
epoch:20001loss:0.2032
epoch:30001loss:0.1844
epoch:40001loss:0.1756
epoch:50001loss:0.1706
epoch:60001loss:0.1674
epoch:70001loss:0.1652
epoch:80001loss:0.1637
epoch:90001loss:0.1625
epoch:100001loss:0.1616
epoch:110001loss:0.1608
epoch:120001loss:0.1602
epoch:130001loss:0.1597
epoch:140001loss:0.1593
epoch:150001loss:0.1589
epoch:160001loss:0.1586
epoch:170001loss:0.1582
epoch:180001loss:0.1580
epoch:190001loss:0.1577
accuracy : 93.1