퍼셉트론
뉴런과 뉴런 사이에는 시냅스라는 연결 부위가 있는데, 신경 말단에서 자극을 받으면 시냅스에서 화학 물질이 나와 전위 변화를 일으킴
전위가 임계 값을 넘으면 다음 뉴런으로 신호를 전달하고, 임계 값에 미치지 못하면 아무것도 하지 않음 -> 퍼셉트론의 개념과 유사!
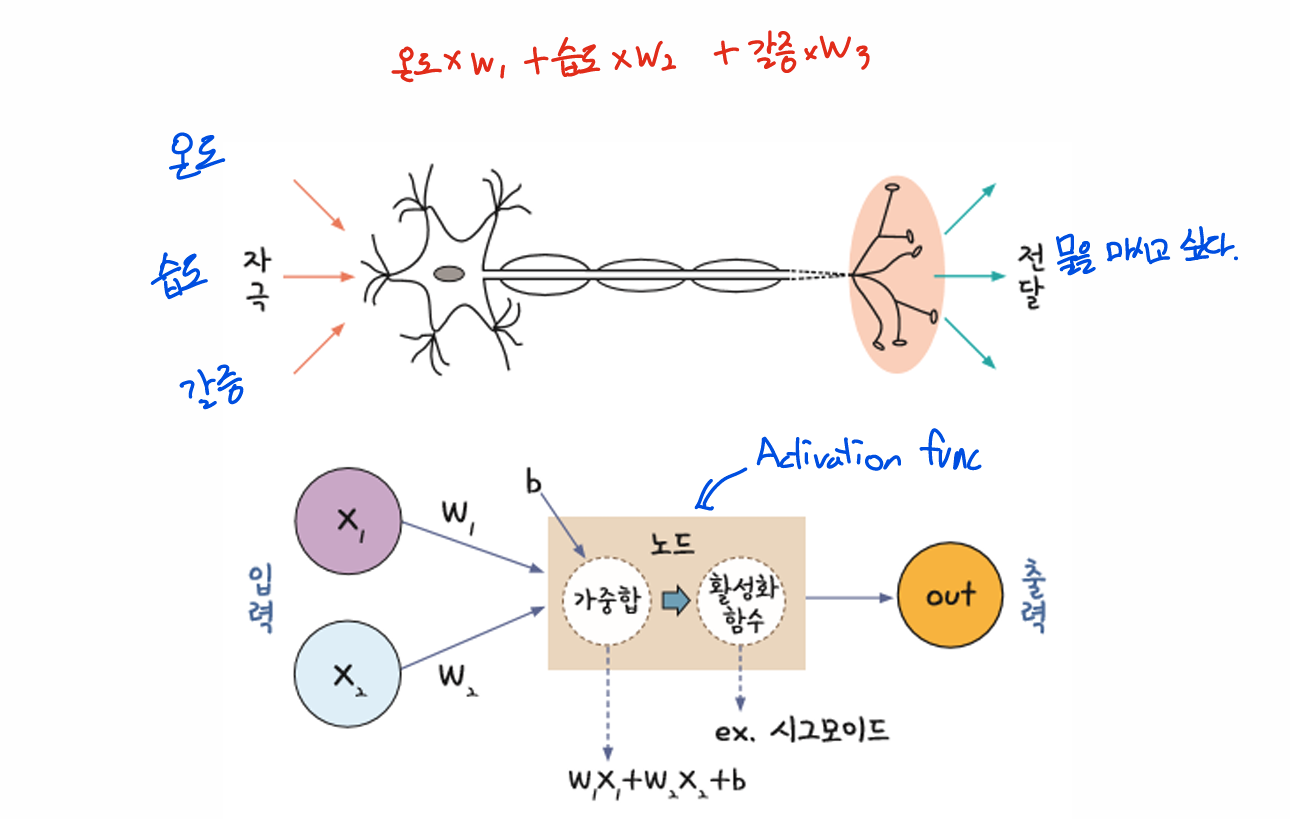
신경망을 이루는 가장 중요한 기본 단위는 퍼셉트론(perceptron)
퍼셉트론은 입력 값과 활성화 함수를 사용해 출력 값을 다음으로 넘기는 가장 작은 신경망 단위
import numpy as np
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5,0.5])
b = -0.2
tp = np.sum(w * x) + b
if tp <= 0:
return 0
else :
return 1
def AND(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5,0.5])
b = -0.7
tp = np.sum(w * x) + b
if tp <= 0:
return 0
else :
return 1
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5])
b = 0.7
tp = np.sum(w * x) + b
if tp <= 0:
return 0
else:
return 1
input_data = [(0,0),(0,1),(1,0),(1,1)]
for x in input_data:
y = NAND(x[0], x[1])
print(f'{x} => {y}')
(0, 0) => 1
(0, 1) => 1
(1, 0) => 1
(1, 1) => 0다층 퍼셉트론
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import BCELoss
from day2.logisticEx2 import prediction
torch.manual_seed(777)
x_data = torch.FloatTensor([[0,0],[0,1],[1,0],[1,1]])
y_data = torch.FloatTensor([[0], [1], [1], [1]])
model = nn.Sequential(
nn.Linear(2,2),
nn.Sigmoid(),
nn.Linear(2,1),
nn.Sigmoid()
)
loss_func = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=1)
for epoch in range(10000):
hypothesis = model(x_data)
loss = loss_func(hypothesis, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'epoch:{epoch+1} loss:{loss.item():.4f}')
with torch.no_grad():
hypothesis = model(x_data)
prediction = (hypothesis > 0.5).float()
accuracy = (prediction == y_data).float().mean()
print('hypothesis:\n{}\nprediction:\n{}\ntarget:\n{}\naccuracy:{:.4f}'.format(
hypothesis.numpy(), prediction.numpy(), y_data.numpy(), accuracy.item()
))
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<MulBackward0>)
tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward0>)
tensor([[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931]], grad_fn=<NegBackward0>)
tensor(0.6931, grad_fn=<MeanBackward0>)
tensor(0.6931, grad_fn=<BinaryCrossEntropyBackward0>)
epoch1 loss:0.6931
epoch101 loss:0.1347
epoch201 loss:0.0806
epoch301 loss:0.0579
epoch401 loss:0.0453
epoch501 loss:0.0373
epoch601 loss:0.0317
epoch701 loss:0.0276
epoch801 loss:0.0244
epoch901 loss:0.0219
tensor([[2.7711e-04],
[3.1636e-02],
[3.9014e-02],
[9.5618e-01],
[9.9823e-01],
[9.9969e-01]], grad_fn=<SigmoidBackward0>)
tensor([[False],
[False],
[False],
[ True],
[ True],
[ True]])
epoch:1 loss:0.5895
epoch:101 loss:0.4898
epoch:201 loss:0.0649
epoch:301 loss:0.0222
epoch:401 loss:0.0126
epoch:501 loss:0.0086
epoch:601 loss:0.0065
epoch:701 loss:0.0052
epoch:801 loss:0.0043
epoch:901 loss:0.0037
epoch:1001 loss:0.0032
epoch:1101 loss:0.0028
epoch:1201 loss:0.0025
epoch:1301 loss:0.0023
epoch:1401 loss:0.0021
epoch:1501 loss:0.0019
epoch:1601 loss:0.0018
epoch:1701 loss:0.0016
epoch:1801 loss:0.0015
epoch:1901 loss:0.0014
epoch:2001 loss:0.0014
epoch:2101 loss:0.0013
epoch:2201 loss:0.0012
epoch:2301 loss:0.0012
epoch:2401 loss:0.0011
epoch:2501 loss:0.0011
epoch:2601 loss:0.0010
epoch:2701 loss:0.0010
epoch:2801 loss:0.0009
epoch:2901 loss:0.0009
epoch:3001 loss:0.0009
epoch:3101 loss:0.0008
epoch:3201 loss:0.0008
epoch:3301 loss:0.0008
epoch:3401 loss:0.0007
epoch:3501 loss:0.0007
epoch:3601 loss:0.0007
epoch:3701 loss:0.0007
epoch:3801 loss:0.0007
epoch:3901 loss:0.0006
epoch:4001 loss:0.0006
epoch:4101 loss:0.0006
epoch:4201 loss:0.0006
epoch:4301 loss:0.0006
epoch:4401 loss:0.0006
epoch:4501 loss:0.0005
epoch:4601 loss:0.0005
epoch:4701 loss:0.0005
epoch:4801 loss:0.0005
epoch:4901 loss:0.0005
epoch:5001 loss:0.0005
epoch:5101 loss:0.0005
epoch:5201 loss:0.0005
epoch:5301 loss:0.0005
epoch:5401 loss:0.0004
epoch:5501 loss:0.0004
epoch:5601 loss:0.0004
epoch:5701 loss:0.0004
epoch:5801 loss:0.0004
epoch:5901 loss:0.0004
epoch:6001 loss:0.0004
epoch:6101 loss:0.0004
epoch:6201 loss:0.0004
epoch:6301 loss:0.0004
epoch:6401 loss:0.0004
epoch:6501 loss:0.0004
epoch:6601 loss:0.0004
epoch:6701 loss:0.0004
epoch:6801 loss:0.0003
epoch:6901 loss:0.0003
epoch:7001 loss:0.0003
epoch:7101 loss:0.0003
epoch:7201 loss:0.0003
epoch:7301 loss:0.0003
epoch:7401 loss:0.0003
epoch:7501 loss:0.0003
epoch:7601 loss:0.0003
epoch:7701 loss:0.0003
epoch:7801 loss:0.0003
epoch:7901 loss:0.0003
epoch:8001 loss:0.0003
epoch:8101 loss:0.0003
epoch:8201 loss:0.0003
epoch:8301 loss:0.0003
epoch:8401 loss:0.0003
epoch:8501 loss:0.0003
epoch:8601 loss:0.0003
epoch:8701 loss:0.0003
epoch:8801 loss:0.0003
epoch:8901 loss:0.0003
epoch:9001 loss:0.0003
epoch:9101 loss:0.0003
epoch:9201 loss:0.0003
epoch:9301 loss:0.0002
epoch:9401 loss:0.0002
epoch:9501 loss:0.0002
epoch:9601 loss:0.0002
epoch:9701 loss:0.0002
epoch:9801 loss:0.0002
epoch:9901 loss:0.0002
hypothesis:
[[4.6560614e-04]
[9.9979478e-01]
[9.9979478e-01]
[9.9995089e-01]]
prediction:
[[0.]
[1.]
[1.]
[1.]]
target:
[[0.]
[1.]
[1.]
[1.]]
accuracy:1.0000

+AI to AI+