지금까지 Redis에 대해서 공부를 해보았고,
Prove Project에서 mamcache에 대해서 배우고, mamcache로 구현을 했습니다.
지금부터 Aws Ec2를 활용하여 다중서버 환경에서 Redis로 캐싱 시스템 구현하기에 대해서 배워 보도록 하겠습니다.
왜 다중서버 환경에서 Redis를 활용해야하는가?
해당 내용은 mamcache를 사용해야하는 이유에 대해서 설명할때 설명을 하였습니다.
간단히 설명하자면,
서버가 1대일대는 글로벌 캐시인 Redis를 사용할 필요가 없어서 메모리 캐시를 사용해라 이말입니다.
당연히, 서비스 기업에서는 하나의 서버로만 어플리케이션을 구축하지 않을 것입니다.
왜냐하면 1분에 수십 수만건의 요청이 들어오는데, 하나의 애플리케이션 서버로는 감당이 안될 것입니다.
그렇기 때문에 메모리캐시가 아니라(서버 각각 redis사용하면 서버1에서의 캐시 내용을 서버 2는 알수 없음), 글로벌 캐시를 두어야 합니다.
다중 서버 설치하기,
Aws Ec2를 사용하여서, 인스턴스를 하나 더 빌리고 Redis환경 설정을 해주었습니다.
다중서버를 띄우고 동일한 글로벌 캐시를 바라보게 하는 방법은,
각 서버에서 spring boot jar파일을 실행시키게 되는데,
해당 jar파일에서 Redis의 동일한 host와 port번호를 설정하였으므로, 하나의 글로벌 캐시를 바라보게 됩니다.
spring:
data:
redis:
host: 3.39.xxx.xx
port: 6379
Redis에 캐싱 하기
그렇다면, Redis에 어떤 값을 캐싱할지는, 이전에 Mamcache에서 했던 내용과 동일합니다.
어떤 로직을 통해 캐싱을 할지는 해당 글을 참고해 주셨으면 좋겠습니다.
@Component
@RequiredArgsConstructor
public class CacheInitializer {
private final ProveRepository proveRepository;
private final ImageRepository imageRepository;
private final LikeRepository likeRepository;
private final CommentLikeRepository commentLikeRepository;
private final CommentRepository commentRepository;
private final CacheManager cacheManager;
@PostConstruct // Bean이 초기화될 때 호출됨
public void init() {
List<Prove> proves = proveRepository.findTop100ByStudyTagOrderByLikeCountDesc(); // DB에서 100개의 Prove 가져오기
System.out.println(proves);
System.out.println("hello");
// Prove 객체를 DTO로 변환
List<ProveDtoV2> proveDtos = makeProveDtos(proves);
// 캐시에 저장하기 전에 DTO 리스트를 JSON 문자열로 변환
ObjectMapper objectMapper = new ObjectMapper();
Cache cache = cacheManager.getCache("STUDY");
if (cache != null) {
try {
// DTO 리스트를 JSON 문자열로 변환
String jsonString = objectMapper.writeValueAsString(proveDtos);
// 캐시에 JSON 문자열 저장
cache.put("top100Proves", jsonString);
System.out.println("Prove 데이터가 STUDY 캐시에 JSON 형태로 저장되었습니다.");
} catch (JsonProcessingException e) {
e.printStackTrace();
System.out.println("캐시에 저장 중 오류가 발생했습니다.");
}
}
}@PostConstruct를 사용해 의존성 주입이 완료된 후에 init메서드를 호출합니다.
좋아요가 가장 많은 순서대로 STUDY 태그를 가진 Prove 계시글을 가져옵니다.
makeProveDto메서들 통해 DTO를 만든다음에, JSON 문자열로 변환한후에 캐시에 올려둡니다.
만약, 홈페이지에 접속한 User가 STUDY에 관심이 있다고 태그를 입력하면, 해당 요청을 보내게 됩니다.
@GetMapping("/api/allProves/v4/STUDY")
public List<ProveDtoV2>getProvesV4(){
return proveService.getProvesWithCache();
}public List<ProveDtoV2> getProvesWithCache() {
// "STUDY" 캐시 사용
Cache cache = cacheManager.getCache("STUDY");
// 캐시에서 JSON 문자열을 가져오기
String cachedProvesJson = cache.get("top100Proves", String.class);
System.out.println("캐시에서 데이터를 반환합니다.");
// ObjectMapper를 사용하여 JSON 문자열을 ProveDtoV2 리스트로 변환
ObjectMapper objectMapper = new ObjectMapper();
try {
// ProveDtoV2 리스트로 변환
List<ProveDtoV2> proveDtoList = objectMapper.readValue(cachedProvesJson, new TypeReference<List<ProveDtoV2>>() {});
// 변환된 리스트 반환
return proveDtoList;
} catch (JsonMappingException e) {
throw new RuntimeException("JSON 매핑 오류", e);
} catch (JsonProcessingException e) {
throw new RuntimeException("JSON 처리 오류", e);
}
}
캐시에서 가져와서 반환합니다.

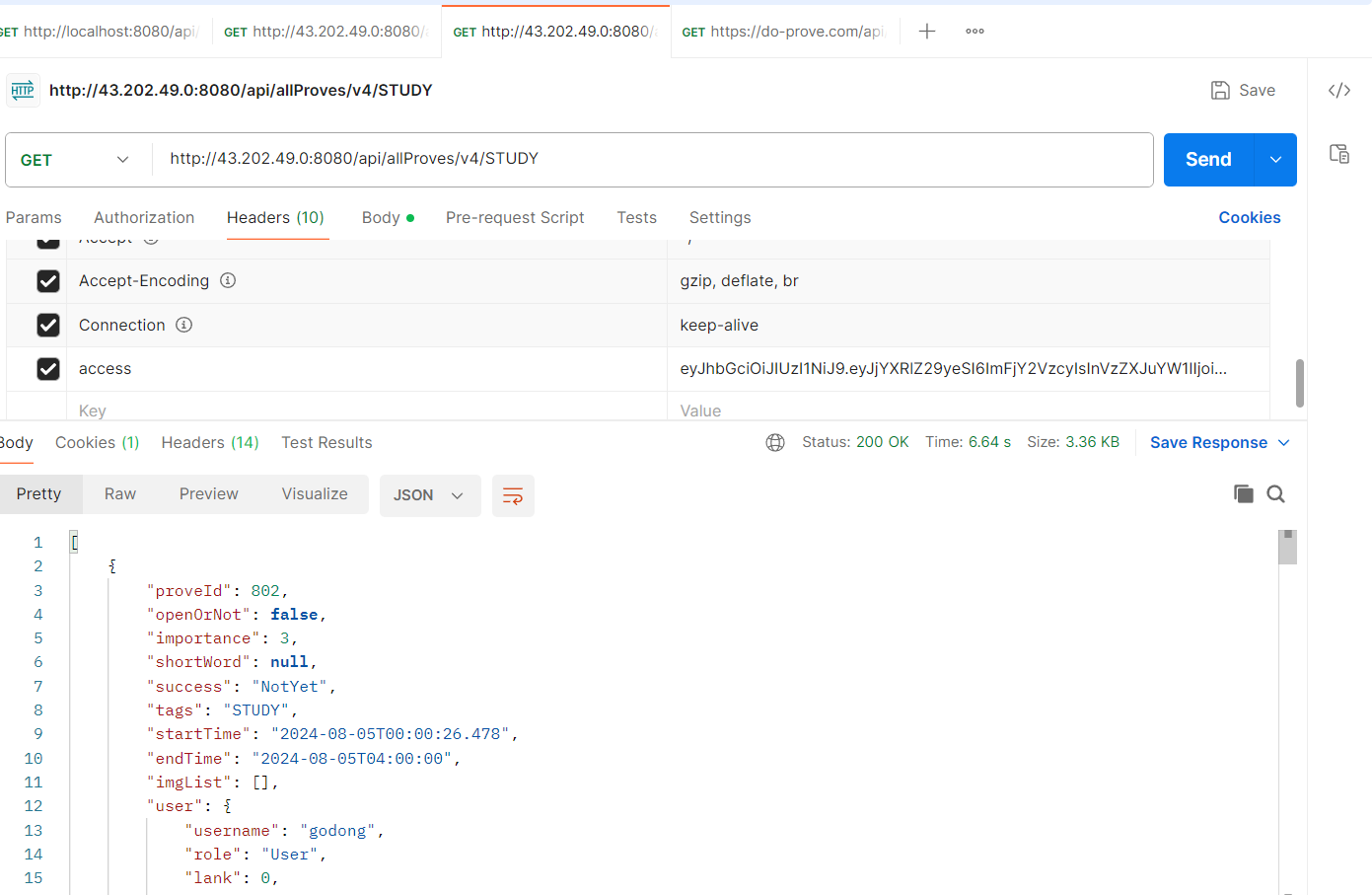
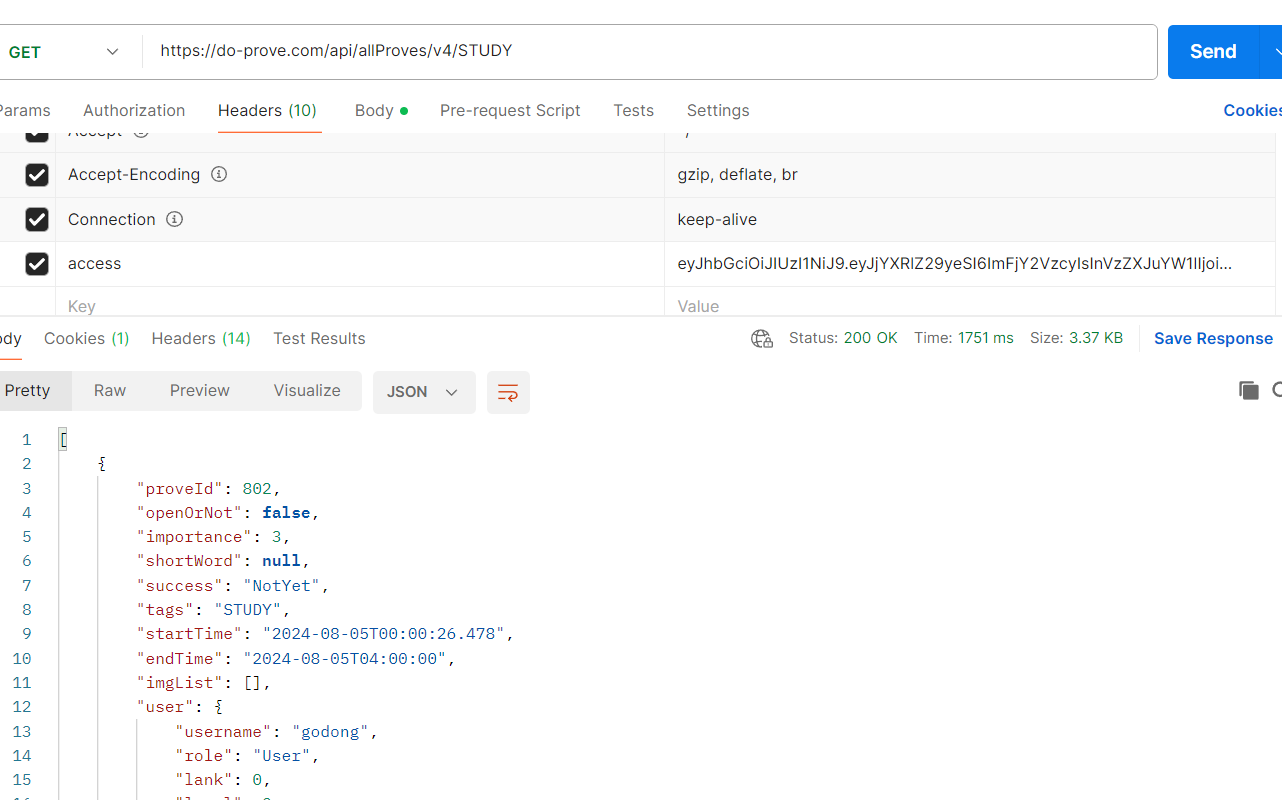
동일한 Redis 글로벌 캐시를 사용하는, 서버로 요청을 보냈을때도 동일한 캐시 value를 가져오는 것을 확인 할 수 있습니다.
문제 발생 및 해결
Redis에다 캐시 value를 올린후에,
Redis에서 캐시를 가져올때, JSON형식을 직렬화/역직렬화할때 생기는 문제를 만났습니다.
해당 내용은 여기를 참고해주세요.
고찰
-
Redis는 어떤 상황에서 사용해야하는지 파악하는게 중요하다. -> 다중 서버 환경에서 사용해야 한다.
-
내 프로젝트에서는 Redis를 계시글을 올릴때마다 Redis에다가 해당 계시글을 올리는게 아니라, 캐시 워밍 기법을 적용하였다.
-
마지막 사진에서 do-prove.com이라는 애플리케이션 서버와, 43.202.xx.xxx의 애플리케이션 서버 둘다 글로벌 캐시를 사용하여서 동일한 값을 가져온것을 확인하였다.
그런데 생각을 해보니까, 다중 서버 환경에서는 데이터 일관성을 유지하기 힘들지 않나? 라는 생각을 헀다.
Redis가 단일 서버에서 동작할때는 일관성을 개발자가 전혀 생각할 필요가 없다.
왜냐하면 Redis는 싱글스레드 방식으로 동작하므로 한번에 하나의 명령을 수행하고, 다음 명령을 수행한다. 즉 명령들이 직렬화 되므로, 데이터 일관성을 보장을 해준다.그러나 단일 서버에서 Redis를 사용할 이유는 없고, 글로벌 캐시환경처럼 여러 서버에서 Redis에 동시에 접근하는 과정에서 동시에 데이터를 업데이트 하면 데이터 충돌이 발생할 수 있다.
즉, 분산환경에서 동시성 문제를 해결줘야한다.
do-prove.com, 43.202.xx.xxx이 상품 재고 관리 시스템이라고 가정해보자.
사용자 1이 do~여기다 요청을 보내고 사용자 2가 43~ 여기다 요청을 보낸다 치자.
사용자1,2가 동시에 같은 상품 item:100을 구매하려 한다고 치자.
서버 do-prove.com, 43.202.xx.xxx가 동시에 Redis에 있는 item:100의 재고 수량을 확인한다.
만약 재고가 5개라고 치면, 서버 1에서는 재고를 1개 줄여서 4로 업데이트하고, 서버 2도 동시에 같은 재고 데이터를 사용하여 4로 업데이트 한다.결과적으로 두 사용자는 각각 1개씩 구매했지만, 재고는 실제로 2개가 줄어야함에도 불구하고 동시성 문제로 인해 재고는 1개만 줄어들어 재고 수량이 잘못계산된다.
지금까지
성능향상을 위한 캐싱기법사용
-> mamacache를 prove프로젝트에 사용하기
-> Redis에 대한 공부
-> Redis를 prove프로젝트에 사용하기
여기까지 왔다.
마지막으로 고찰 3번에 말한, Redis에서 동시성 문제 확인과 해결방안에 대해서 공부하고 성능향상을 위한 캐싱기법 시리즈를 마무리하고자 한다.
