Memory management
-
Logial address(=virtual address)
각 프로세스마다 독립적으로 가지는 주소공간
각 프로세스 마다 0번지 부터 시작
cpu가 보는 주소는 logical address이다. -
Physical address
메모리에 실제 올라가는 위치이다.
그래서 메모리 하단에는 운영체제 커널에 관련된 주소공간이 있고 위로 갈수록 이제 각 프로세스가 차지하는 실제 메모리 주소가 있다. -
주소바인딩: 주소를 결정하는것
우리는 실제 프로그래밍을 할때 주소에다가 값을 넣지 않는다. 예를 들어 int a = 3;이런식으로 코드를 짜지, 0x03번지에 3을 넣으라고 하지 않는다.
그래서 우리가 짠 코드르 Symbolic Address라고 하고 이 Symbolic Address=> Logical Address => Physical Address로 주소 변환이 일어나는 과정에서
Logical Address에서 실제 메모리에 올릴때 어디서 주소변환이 일어나는지 이것을 알아보도록한다.
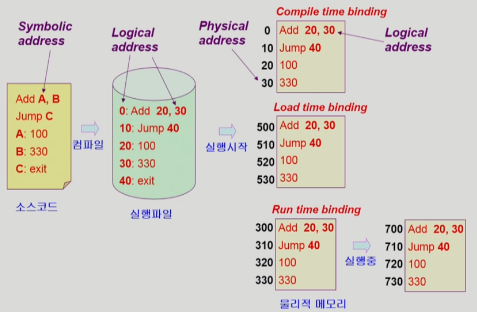
그림을 보면 A와 B값을 더하고 C로 점프하는 소스코드를 우리는 만들었다.
그러면 컴파일을 하면서 프로세스는 각자 독자적인 Logical Memory공간을 가지게 되므로 0번지부터 시작하는 논리적 주소공간을 얻게 된다.
그러나 실행시작을 하면서, 이제 실제 메모리에 올릴때 3가지의 바인딩이 있는데 하나하나 설명하자면
-
Compile time binding
여기에서는 실제 물리적 메모리에 올려야할 주소를 미리 컴파일 시점에 정하는 것이다.
0,10,20,30번지를 그대로 물리적메모리에 올리는것이다.
그런데 현재 OS에서는당연히 사용할 수가 없는데 이러면 하나의 프로세스밖에 실행을 못한다. 왜냐하면 프로세스의 Logical 주소는 항상 0번지 부터 시작하는데 이미 0번지 10번지에 이미 P1이 올라갔으면 P2프로세스를 실행시키면 0번지부터 논리적 주소가 시작되는데 이걸 이미 올라가있는 P1을 쫒아내고 0번지에 다시 밀어넣는 수밖에 없기 때문이다. 옛날 컴퓨터는 프로세스를 1개씩 만들어서 사용하고 그랬어서 사용된 것이다. -
Load Time Binding
Load Time Binding에서는 컴파일 타임에서는 논리적 주소만 결정되고 0,10,20,,,, 그다음에 실행을 시키면 메모리가 500번지부터 비어있다고 치면 그 500번부터 밀어넣는 것이다. -
RuntimeBinding
실행되는 도중에 주소가 바뀔수 있다는 말이다.
그래서 실행을 시작할때 300번지에 잘 넣었는데 실행 도중에 메모리에서 쫒겨났다가 다시 메모리에 올릴때는 300번지는 이미 내가 나가이는동안 다른놈이 들어와서 쓰고 있을 수 있기 때문에 700번지에 새로 올리는것이다.
MMU
Memory Management Unit
하드웨어 디바이스로 Logical address를 Physical address로 매핑해준다.
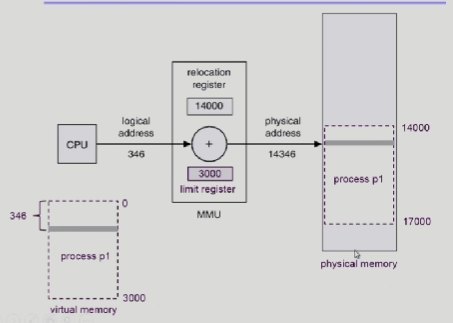
CPU가 346번지 address에 있는 내용을 달라고 요청이 오면, MMU가 relocation register, limit register 두개로 주소변환을 해준다.
왼쪽 하단의 그림은 프로세스의 logical memory를 나타낸것이다.
그러므로 0번지부터 출발해서 3000번지까지 있고 346번지를 달라 한것이다.
오른쪽 그림을 보면 physical memory에 14000번지에 실제로 프로세스가 올라가 있는데 그럼 실제주소는 14000 + 346을 해주면 되는것이다.
limit register는 이 가상메모리의 크기값을 가지고 있다. 이걸 가지고 있는 이유가 악의적인 프로그램이 본인의 가상메모리의 크기가 3000까지 밖에 없는데 CPU instruction을 조작해서 4000번지를 달라고 해버리면, Physical memory에서 18000번지를 조회하므로, 즉 다른 프로그램이 존재하는 영역을 달라 해버리니까 그런 경우를 막기위해서 쓴다.
그래서
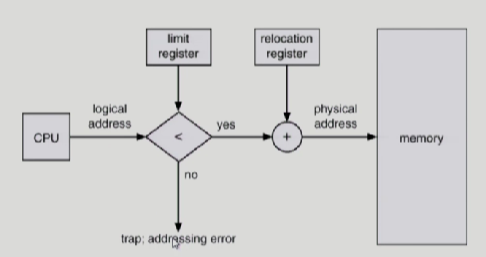
cpu가 요청을 하면 우선 1차적으로 limitregister가 확인을 먼저한다. 더 큰 주소공간을 요청한게 아닌지 만약에 limit register값보다 작은 값을 요청했다면 relocationregister에서 요청 주소를 더해서 physical memory에서 읽어다가 cpu한테 전달해준다.
그래서 user program은 logical address만을 다룬다. 왜? 어차피 physical address로 변환해주는건 하드디바이스인 MMU가 처리하기 때문이다.
실제 physical address를 볼 수 도 없고 알 필요도 없다.
용어 4가지 설명
- Dynamic Loading
Loading: 메모리로 올리는것
프로그램을 메모리에 올려야 실행이 되는데 그때그때 마다 필요한게 다르니까 필요한 부분만 필요할 때마다 메모리에 load시키는것이다.
프로그램을 처음 실행시킬때 처음부터 통채로 메모리에 올려두는것이 아니라 일부분만 올려두는것이다. => memory utilization 향상
참고)
현재 운영체제는 당연히 메모리에 통채로 프로그램을 올려두고 쓰지 않는다. 필요한 만큼만 올리고 다쓰면 쫒겨나고 이런방식인데, 이건 근데 Dynamic Loading이라고 하지 않는다.
이건 OS가 관리해주는 Paging System에 의해서 실행되는것이다. 그래서 올라갔다 내렸다 하는건 OS가 관리해주는것이고,
보통 Dynamic Loading이라고 하는것은, 운영체제가 지원해주는게 아니고, 프로그래머가 프로그램 자체에서 구현을 어느부분을 올리고 어느부분을 내릴지 직접 구현해야하는 것이다.
그러면 이걸 직접 Dynamic Loading 코드를 수작업으로 짜야하냐? 이건 아니다.
이걸 쉽게하기 위해서 OS가 라이브러리를 지원해준다.
다만 여기서 말하고 싶은것은 OS가 지원해주는 Paging기법과 Dynamic Loading은 원래 다른것이라는걸 말하고 싶은거다.
-
Overlays
메모리에 프로세스의 부분중 실제 필요한 정보만을 올림
마치 Dynamic Loading과 비슷한거 같지만, 이건 완전히 초창기 컴퓨터에 프로세스 하나 자체를 메모리에 올릴 수 없을 때 수작업으로 작은 메모리 공간에 프로세스 하나를 짤라서 하나 올리고 또 다하면 다른 하나를 올리고 이런과정이다. -
Swapping
프로세스를 일시적으로 메모리에 하드디스크(swap area)로 쫒아내는것
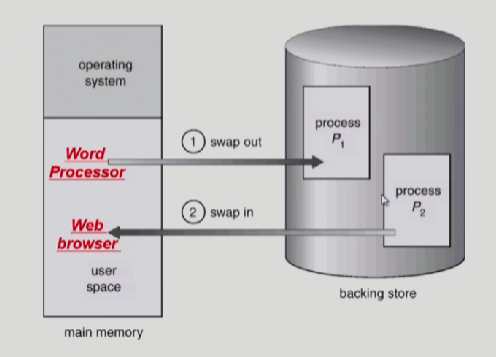
중기 스케쥴러(swapper)가 swap out시킬 프로세스를 선정한다.
그럼 어떤놈을 쫒아내느냐? CPU스케쥴링에서 우선순위가 낮은 놈을 쫒아내고 우선순위가 높은놈을 메모리에 올려놓는다.
이걸 메모리에 올려놓을때 Binding과 알아 봐야하는데,
Compile time binding이나 Load time binding과 같은 경우에는 처음에 할당된 0번지와 500번지에 올라와야한다.
그래서 다른 메모리가 비어있더라도 정해진 자리에 넣어야하는거니까 swapping의 성능이 떨어진다.
swapping의 효율성이 증가하려면 Runtime Binding이 지원이 되야한다.
즉 300번지에 있던 프로세스가 쫒겨나고 다시 메모리에 들어올때는 새로운 700번지에 올려놓는것이다. -
Dynamic Linking
Linking을 실행시간까지 미루는기법
프로그램을 작성하고 컴파일을하고 Link를 해서 실행 파일을 만드는데 이 link라는건 여러군데에서 존재하는 컴파일된 파일을 묶어가지고 하나의 실행파일로 만드는걸 말한다.
예를 들어, 내가 소스파일을 여러개 따로 코딩해서 linking하거나, 내가 직접 만들지 않았지만 유용한 라이브러리 같은것도 다른사람이 만들고 필요할때 불러다 쓰는 방식.
라이브러리들도 linking이 되서 내가 만든 실행파일에도 라이브러리에 포함되는방식이다.static linking
라이브러리가 프로그램의 실행파일 코드에 포함됨
dynamic linking
라이브러리가 실행되면 그때 연결된다. 그래서 실행파일에 라이브러리가 없다가, 라이브러리가 호출되야하면, 호출부분에 라이브러리 루틴의 위치를 찾기위한 stub라는 작은 코드를 두고, 라이브러리가 이미 메모리에 있으면 그 루틴의 주소에 가고 없으면 디스크에서 읽어온다.
Allocation of Physical Memory
- OS 상주영역 - 낮은 주소영역 사용
- 사용자 프로세스 영역 - 높은 주소 영역 사용

사용자 프로세스 영역의 할당법 - Contiguous allocation - 연속할당(프로그램이 메모리에 올라갈때 통채로 올라가는것)
- Non Contiguous allocation - 불연속할당(프로그램의 일부마다 다른 위치의 메모리에 올라가는것)
Contiguous Allocation
연속할당 방식에는 두가지 방법이 있음, 고정 분할 방식, 가변분할 방식
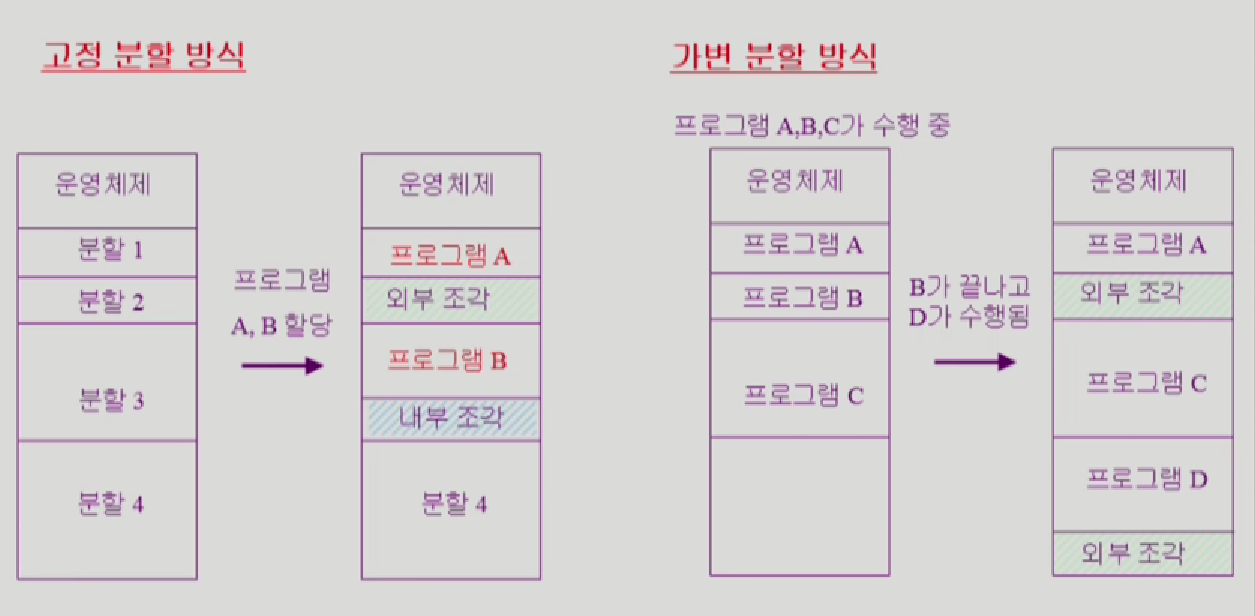
-
고정 분할방식
미리 메모리를 파티션 해놓고, 그 다음에 A,B를 그 파티션에 맞게 할당하는방법
A는 분할 1크기에 맞아서 들어갔는데 프로그램 B는 분할 2에는 사이즈가 더 커서 못들어가니까 분할 3번에 들어간 것이다.
외부조각: 프로그램이 해당 파티션보다 커서 못들어가서 남은 ㅈ각
내부조각: 프로그램이 파티션보다 작아서 파티션에서 남는조각 -
가변 분할 방식
프로그램이 실행될 때 마다 차곡차곡 올려둠, 만약 프로그램이 끝나면 외부조각이 됨
그림의 경우 D가 B가 빠진 파티션에 들어가려했지만, 해당 파티션보다 커서 못들어가니까 C 뒤의 파티션에 D가 들어가고 B가 떠나고 난 파티션은 외부조각이 되었다.
즉 이렇게 외부조각 같은 Hole들이 발생하게 되는데
Hole
가용 메모리 공간
다양한 크기의 hole들이 메모리 여러 공간에 흩어져 있다. Hole에 맞는 프로그램을 넣는 과정이 필요하다.
Dynamic Storage - Allocation Probelm
가변 분할 방식에서 size n인 요청을 만족하는 가장 적절한 hole을 찾는 문제
- First - fit
size가 N이상인 것중에서 최초로 찾는 hole에 할당 - Best - fit
size가 n이상인 가장 작은 hole을 찾아서 할당 - Worst - fit
가장 큰 hole에 할당
Compacton
Hole들을 한군데다가 몰아 넣어서 큰 Block을 만드는것, 매우 비용이 많이 드는 방법으로 Runtime-Binding이 지원되야 수행가능
Non Contiguous Allocation
Paging, Segmentation 기법
Paging
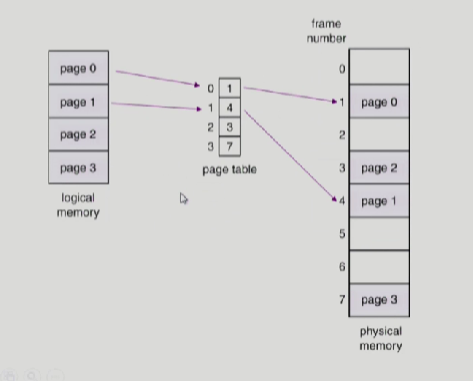
그림과 같이, 논리적인 메모리를 동일한 크기의 페이지로 짜르고 그다음에 Physical memory에서 비어있는 공간 어디던지 일단 밀어넣는다.
주소변환을 위해 page table이 사용된다.
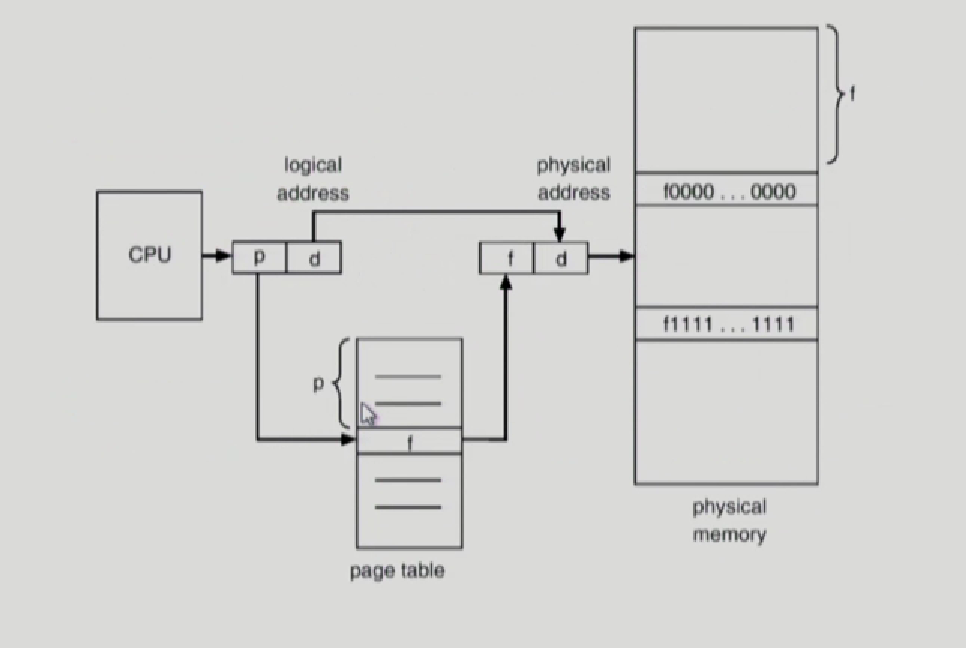
p->논리적인 페이지 번호
d->논리적인 페이지 내에서 얼만큼 떨어져있는지 나타내는 offset
pagetable에서 p번을 찾아 나서면 f라는 실제 page frame 번호를 얻게 되고, 논리적 주소를 물리적 주소로 바꾸게 되는데 f라는 실제 Page Frame으로 바꿔주면된다.
그럼 맨 처음 그림으로 되돌아 가면 논리적 주소에서 page 0에 해당하는 0이 바로 p이다. 그다음 pagetable에서 변환된 0에 해당하는 frame 번호 f가 1이 되는것이다.
이렇게 논리적페이지 번호가, 실제 pageframe으로 바뀌어도, 내부에서의 상대적 위치는 동일하기 때문에 d는 바뀌지 않는다.
page0번이 0에서 ~100번지 까지 라면, 실제 frame은 어디 저기 11 번째 page physical address에 존재하더라도 11번째 page frame에 그대로 0~100번지 내용이 올라가므로 d는 변하지 않는것이다.
여기서는 예시로 Page 0번 서울 1번 대전 2번 부산 3번 인천 으로 되어있으면
page 0번 서울에 실제 d 11-2번지 이런식으로 되어있는것이다.
Page Table 구현
page table은 Main memory에 상주한다.
그러므로 모든 메모리 접근 연산에는 2번의 메모리 access가 필요하다.
page table이 메모리 내에 있으므로 처음에는 주소변환을 위해서 메모리에 접근해야하고, 실제 data/instruction 접근 1번 이런식으로 2번의 메모리 access가 필요하다.
앞에서 Register 2개로 주소변환을 한다고 하였는데 Page table에서
- Page - table base register: 메모리 상에 페이지 테이블이 어디있는지 가르킴
- Page - table lengh register: page table의 길이를 나타냄
이 두개의 register를 사용한다.
어쨋든 메모리 한번 접근할때 2번의 메모리 access가 필요하므로, 속도향상을 위해서 별도의 하드웨어를 사용하는데 이걸 Associative Register, TLB 라는 캐시 메모리와 CPU사이에서 주소변환을 해주는 계층이 존재한다.
TLB
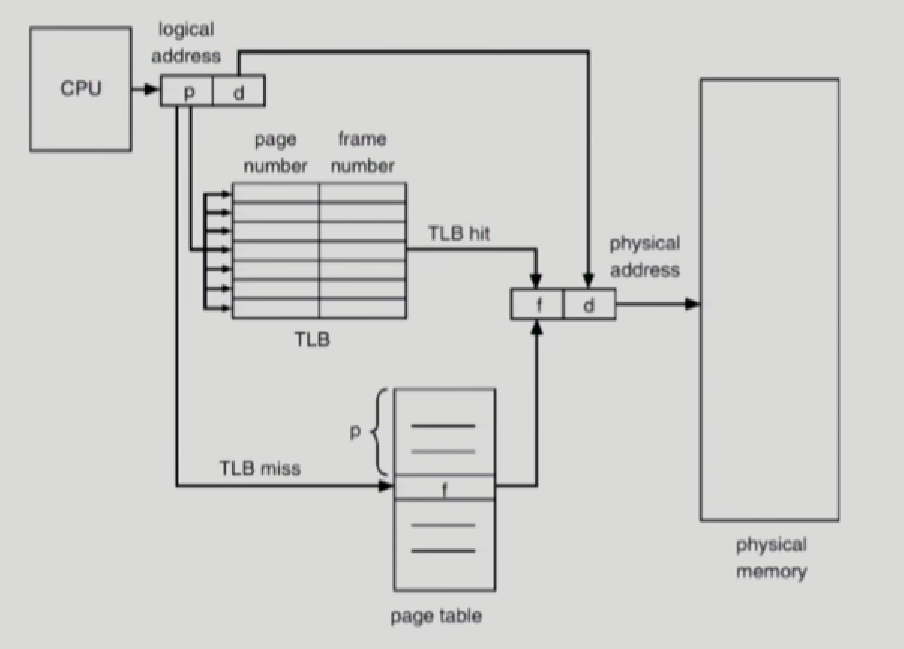
주소 변환을 위한 캐시메모리 TLB -> Page Table에서 빈번히 참조되는 일부 엔트리를 TLB에서 캐싱하고 있다.
그래서 CPU가 논리적 주소를 주게 되면, Physical memory에 있는 page table에 접근하기 전에 TLB를 먼저 검색해본다.
- TLB에 있는경우 -> TLB에 접근해서 바로 주소변환을 한다. -> 메모리에 접근 1번
- TLB에 없는경우 -> pageTable을 통해서 주소변환 -> 메모리에 접근 2번
TLB에는 당연히 page Table처럼 전체의 주소를 가지고 있는게 아님.
page table에서는 frame번호를 얻을때, p라는 page number로 page table에 조회시에 p만큼 쭉 이동해서 보면 바로 frame번호가 나옴,
그러나 TLB에서는 pagenumber에 해당하는 p와 그 page에 해당하는 frame번호가 쌍으로 존재한다. 있을수도 있고 안있을 수도 있다.
그래서 p로 framnumber를 찾으면 TLB를 처음부터 끝까지 다 뒤지고 그 다음에 없으면 pageTable로 가서 찾아야하는데, TLB는 Parallel Search 즉 병렬 탐색이 가능다.
그래서 cpu가 p를 TLB한테 주면, TLB가 병렬로 한번에 쫙 찾고, TLB miss가 나면 page Table로 가서 주소변환을 한다.
pagetable에서는 병렬 탐색같은게 필요가 없다. 왜? 그냥 배열 형태니까 p라는 index에 가보면 frame number가 존재한다.
고로, TLB는 context switch때 Flush가 된다.
Effective Access Time

tlb 접근시간이 입실론, 메모리 접근시간을 1로 두자 당연히 tlb접근시간은 실제 메모리 access시간보다 훨신작은 입실론이다.
hit ratio를 알파라고 하면
EAT공식을 얻는다.
여기서 miss파트가 메모리접근을 두번하므로 2임을 확인할 수 있다.
Two-Level Page Table
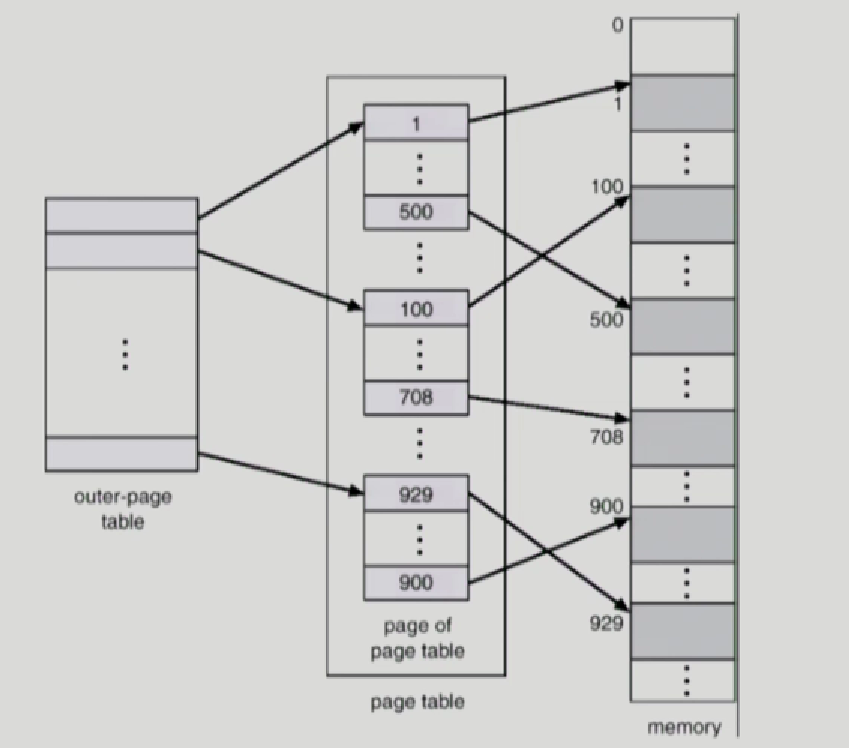
현대 컴퓨터는 address space가 매우 크다.
왜냐하면 논리적 주소가 32bit라고 가정하면 0~2^32-1번지까지 매길수있고 이 크기가 4G의 주소공간이다.
즉 하나의 프로세스마다 독자적인 주소공간이 있다면 하나의 프로세스마다 4G의 주소공간을 차지한다고 볼수 있다.
만약에 그림과같이 논리적 메모리의 공간이 4G이고 하나의 page마다 4k라고 가정한다면 1M개의 page table entry가 필요하다.
그러나 문제는 대부분의 프로그램이 4G 크기의 논리적 메모리 주소공간에서 프로그램이 사용하는 공간은 매우 일부분만 차지하므로, page Table 공간이 심하게 낭비된다.
우리가 1단계 paging에서 page0,1,2,3에 해당하는 구역을 서울 대구 대전 부산으로 나오고 이 page에서 frame번호를 얻어 바로 d라는 11-22번지를 넣었다.
그러나 이제 Two-Level Page Table에서는 서울시 강남구 11-2번지로 원래는 서울 하나였지만 세분화해서 서울 강남구로 2단계 paging을 진행한다.
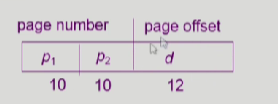
이처럼 논리적 주소를 p1,p2,d로 나눈다.
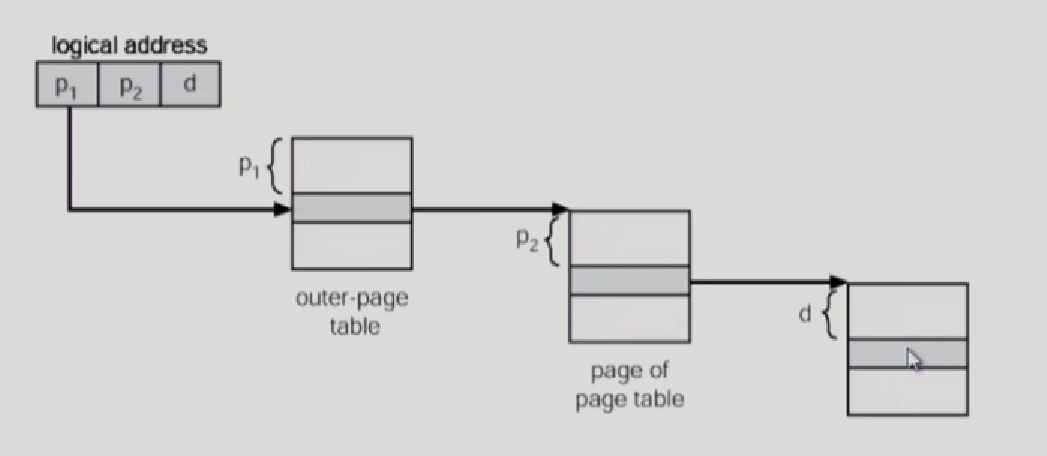
그림과 같이 논리적 주소 p1,p2,d에서 바깥 page에서 찾을 p1, 주소변환정보를 얻는데 안쪽 page Table에서 어떤 페이지에 해당하는지 찾고 또 안쪽 pagetable에서 page frame번호를 찾아서 p1,p2에다가 덮어씌우면, page Frame번호에서 d만큼 떨어진 위치에가서 찾으면 원하는 정보를 찾을 수 있다.
그러면 이 논리적주소를 32bit 주소체계에서 구분을 어떻게 한걸까?
만약 10000개의 집의 주소를 구분하려면 0번지부터 10^4-1번지까지 10000개의 주소가 필요하다.
이와같이 d에 해당하는 logical memory의 주소가 4k이니까 2^12byte를 구분하기 위해서는 12bit가 필요하다.
고로, 페이지 내부에서 byte단위로 얼마나 떨어져 있는지를 구분하는 offset을 위해서 12bit가 필요하고,
pagenumber는 각각 10인데
안쪽 페이지 테이블이 테이블 화 되서 실제 physicalmemory에 들어간다. 929~900에 해당하는 안쪽 테이블이 4k인데 각 엔트리가 4byte이므로 엔트리 수가 1K개 만큼 있다. 1k는 2^10이므로 , p2가 0번지부터 얼만큼 떨어졌는지를 구분하는것이므로 10bit가 필요해서 10이다.
그렇다면 왜? Two level Page table을 쓰는게 이득인지 알수 있다.
논리적주소는 4G이고 하나의 페이지 엔트리당 4k이니까 1M개에서 정작 사용하는건 첫번째 두번째 마지막쨰 밖에 안된다. 그러면 이너 테이블에다가 이 첫번쨰 두번쨰 마지막째 page 엔트리만올리고, 그 내부에 한개의 4k page0에서도 심지어 4byte의 엔트리가 1k개 만큼 있으므로, 여기서도 쓰는게 얼마 안된다. 그래서 여기서도 실제 쓰이는 부분만 pysical memory에 올려서 공간을 효율적으로 사용할 수 있다.
Multilevel Paging and Performance
2단계가아니라, MultiLevel도 페이징이 가능하다.
만약 4단계 페이지 테이블을 사용하는경우 메모리 접근은 5번 해야한다.
만야게 TLB hit ratio가 98%, 메모리 접근시간은 100ns, tlb접근시간은 20ns라 가정한다면,
effective memory access time = 0.98 120 + 0.02(1005+20) = 128ns가 된다.
메모리 접근시간이 100초라고 하면 28ns밖에 걸리지 않으므로 효율적이다.
valid(v)/invalid(i)
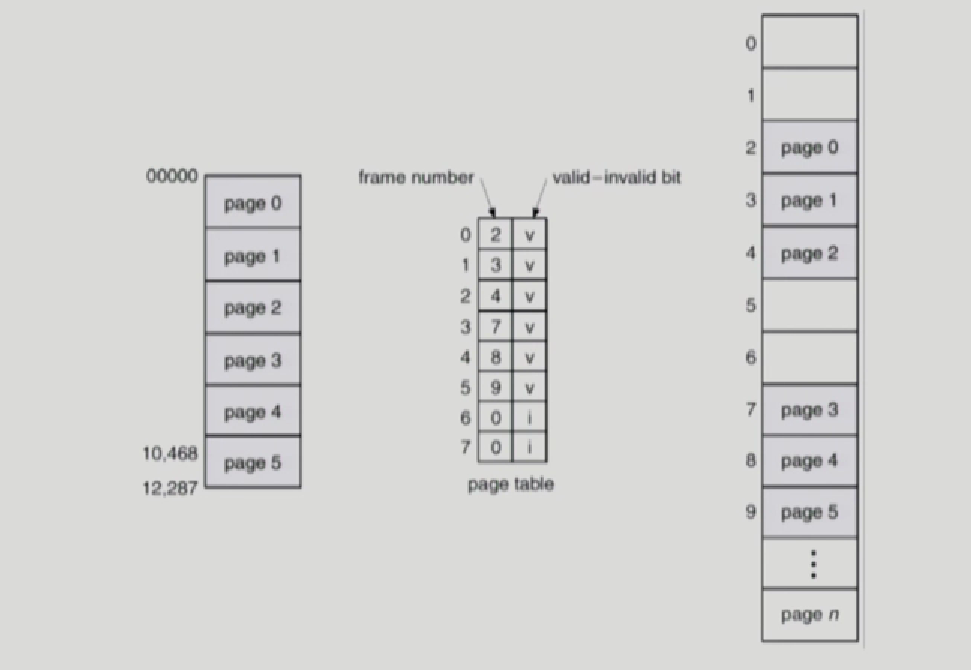
왼쪽은 논리적 메모리
오른쪽은 physical 메모리에 해당한다.
페이지 테이블에서 사실 부가적인 비트가 하나 더 있는데, 그것이 valid, invalid이다.
v엔트리와, i엔트리가 존재한다.
이것의 용도가 무엇이냐면
논리적 메모리에서 32bit 주소체계를 쓰면 page갯수가 1M개 존재할수있다. 왜냐하면 한개가 4K니까 전체가 4G이다.
그런데, 상위 부분에 code,data구성 아주 아래에 stack이 있고 중간에 null로 사용하지 않는페이지 들이 대부분인데, page table에서는 그런 사용하지 않는 중간 영역에 대해서도 엔트리가 만들어져야한다.
왜냐하면, table이라는 자료구조상 위에서부터 index로 접근하기 때문이다.
그래서, 논리적 메모리에서 그림과 같이 6,7번이 없더라도 page table에서는 만들어지고 대신에 valid invalid를 사용해서 6,7번 페이지가 없더라도 page table에서는 만들어진다.
그래야 6,7번 page number에 해당하는 frame넘버가 0이더라도 실제 진짜 frame number가 0 이라 0번째 frame에 들어있는지 아닌지 구분이 가능하기 때문이다.
Valid -> 0번 page가 2번 frame에 올라와있다.
invalid -> 1번 프로세스가 그 주소부분을 사용하지 않는경우, 2번 이 페이지가 논리적 메모리에 올려져 있지 않는경우(swap area에 있는경우)
Protection bit
protection bit이라고 하나 더있는데 다른게 아니라, page에 대한 접근권한을 나타낸다.
read/write/read-only
Inverted page table
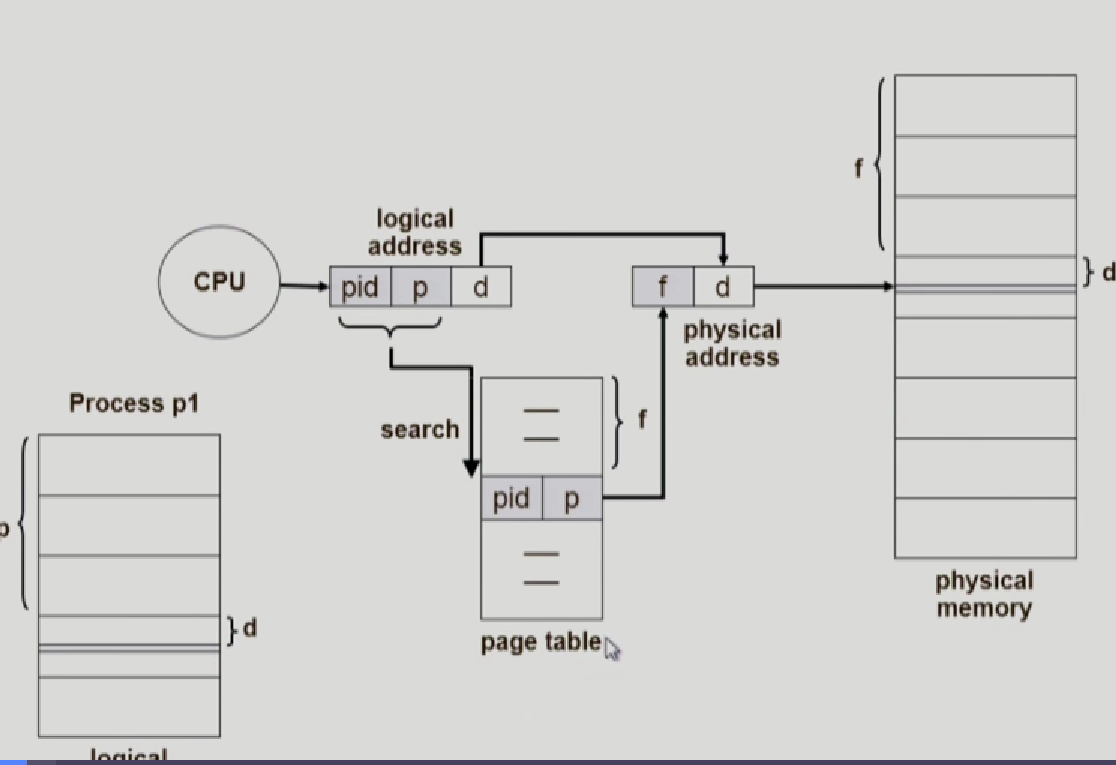
원래는 지금까지 process가 있으면 그 프로세스에 해당하는 page table이 있고 또 다른 프로세스가 있으면 그 다른 프로세스에 해당하는 page table이 각각 프로세스마다 page table이 있었다.
그러나 이제는 시스템 안에 페이지 테이블이 딱 하나 존재한다.
이게 page table에 있는 엔트리가, 프로세스의 페이지 엔트리 갯수만큼 존재하는것이 아니라,
physical memory의 frame갯수만큼 존재하는것이다.
cpu가 그림처럼 pid/p/d라는 logical address를 줬다고 가정해보자 p는 page number니까 다른 여러개의 process가 있을 수 있기 때문에 pid를 같이 저장해서 어떤 프로세스의 page number인지 확인해야한다.
그리고 pid/p에 해당하는 index를 page table에서 찾으면 위에서(0번지) 부터 몇번이나 떨어져있는지 f를 구하고 physical address 주소인 f/d로 변환해준다.
그러면 어? page table에 장점인 이전에 inverse 아닐때는 그냥 page table은 배열같은 형식이기 때문에 해당하는 pagenumber를 주면 그대로 따라면 frame number까지 나왔는데 이제는 전부터 pageTable을 탐색해야한다.
이러면 장점이 없는거 아니냐? 할 수 있는데 탐색의 시간은 조금 더 걸리더라도, page의 저장공간을 줄이기 위해서 사용하였다.
Shard page
- shared code
프로세스마다 공통적으로 공유할 수 있는 코드
read-only로 해서 프로세스간에 하나의 code만 메모리에 올림
shard-code는 모든 프로세스의 logical address space에서 동일한 위치에 있어야한다.
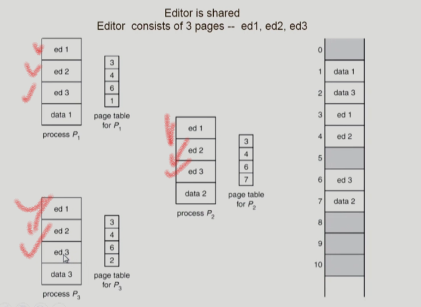
이런식으로 공유가 되는 코드들은 pagenumber가 1,2,3으로 동일해야한다. - private code and data
각 프로세스들은 독자적으로 메모리에 올림
Segmentation
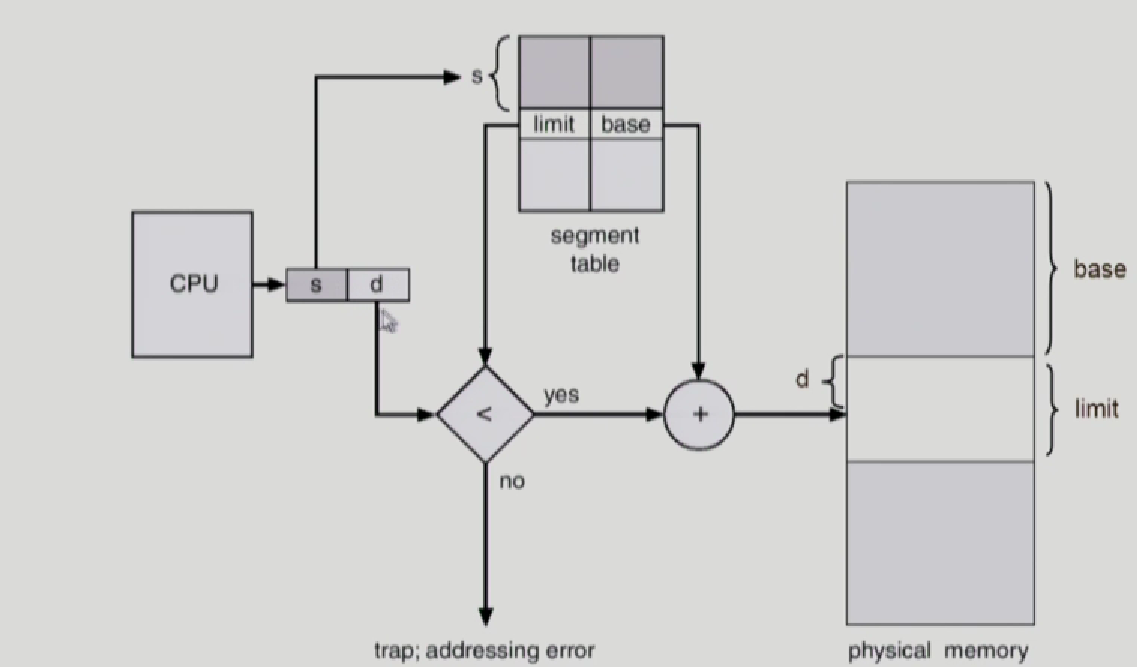
cpu가 segmentation을 주면 두개로 나눈다.
하나는 세그먼트 번호, 다른 하나는 세그먼트로부터 떨어진 offset
segment table의 시작위치는 register가 가지고 있고, 거기서 부터 s만큼 떨어진 엔트리에 가면 이 세그먼트가 물리적 메모리에 몇번 번지에 올라가있는지 base가 있고 segment는 paging과 다르게 두가지 정보를 가지고 있는데 limit라는것도 있다.
limit -> segment의 길이를 나타낸다.
주소변환을 할때 체크해야할 두가지
- cpu에 주어진 segment 번호가, Segment-table length register(STLR)보다 작은지 확인한다.
이 레지스터의 segment갯수가 들어있기 때문이다. - limit보다 d가 크지 않은가 확인한다.
그래서 base가 segment 시작 위치, limit가 segment의 길이를 나타내게 된다.
Paging vs Segmentation
paging기법은 page크기가 균일하므로 offset의 크기가 page크기에 의해 결정된다.
그러나 segmentation 기법은 d라는 offset의 최대 길이가 offset으로 표현할 수 있는 bit수를 넘어갈 수 없다.
32bit면 32bit로 표현할수있는 최대길이를 하나의 segment로 표현도 가능하다는 말이다.
또
paging기법에서는 시작주소가 frame번호로 주어지면 된다. 왜냐하면 물리적 메모리도 동일한 페이지 size로 나누어져 있기 때문이다.
segmentation에서는 segment마다 크기가 다 다르므로, 정확한 base이 위치가 필요하다.
즉, 앞에서 가변분할 방식과 같이, segment마다 크기가 다 다르므로, 프로세스를 종료했다가 실행했다가 하면서, 작은 세그먼트, 큰세그먼트들이 들어왔다 나갔다하면서 hole(외부조각)들이 생기는데 이것이 segment 기법의 단점이다.
그렇다면 장점은 뭐가있을까?
Protection
segment의 크기는 가변적이다. 즉 프로그래머가 의미단위로 짜를 수 있다는 것이다.
이말이 뭔말이냐면, 어떤건 read/write/exectuion으로 의미단위를 나눠줘야 하는데, paging은 동일 크기로 짜르다 보면, 어떤 페이지에는 코드와 데이터가 같이 들어갈 수 도 있는데 이러면, read만 줘야하는지 read write다줘야하나 이런 고민이 든다 왜냐하면 code는 only read만 해야하기 때문이다. 즉 추가적인 보안작업이 필요하다.
그런데 segmentation은 의미단위로 read부분 write부분 execution부분을 의미단위로 짜를 수 있기 때문에 효율적이다.
Sharing
어떤 프로세스의 주소공간을 프로세스끼리 공유하고 싶다면, 의미단위로 해야하지 동일한 크기 단위로 짜르는건 의미가 없다.
즉 의미나 보안에 있어서는 segment 기법이 이득이다.
STBR레지스터는 segment table 자체가 메모리 어디에 있는지 확인
STLR레지스터는 segment table 길이가 얼만틈되는지 확인
그래서, segment 5번 번호를 요청했는데 실제로는 segment를 3개밖에 사용하지 않는경우 STLR과 비교해서 검사하게 된다.
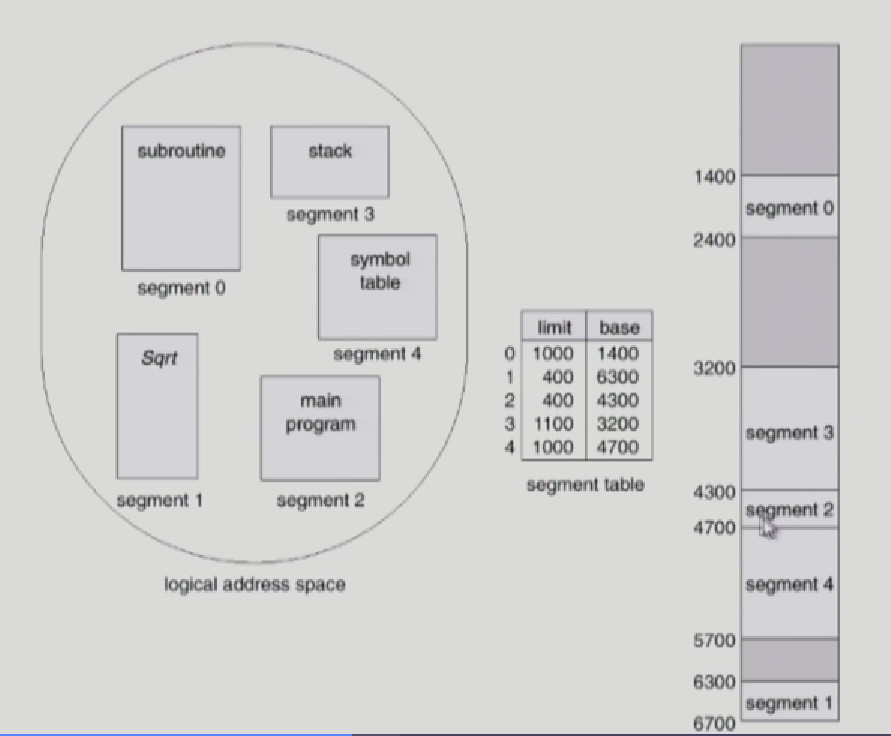
그림과 같이 하나의 프로그램을 구성하는 5개의 segment가 있다고 해보자. main,stack,symbol table,,,등등
이 segment에 대해서 주소변환을 위한 segment table이 있고
0번 segment경우 물리적 메모리 시작 위치가 1400 그리고 길이가 1000이라 1400번지부터 2400번지까지 segment0번이 차지하고 있는 것을 볼 수 있다.
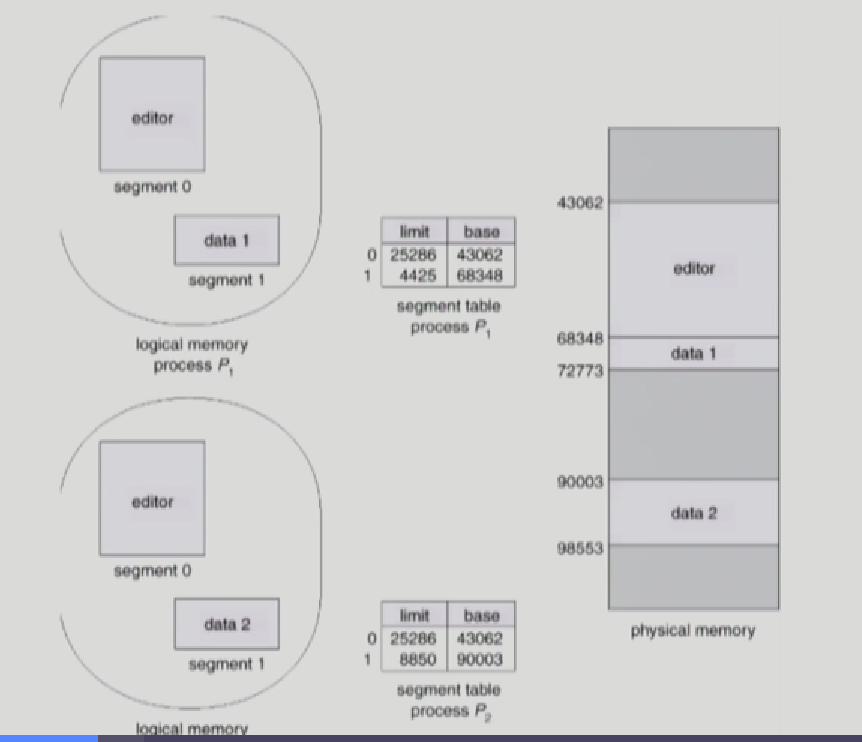
Shared segment는 같은 논리적 주소에 있어야한다.
그림을 보면 editor는 동일한 코드인 shared segment이므로 동일한 논리주소에 있어야한다.
각 프로세스마다 0번지 segment number에 해당하고 43062번지부터 시작하고 있다.
Segmentation with Paging(paging과 segmentation 혼합)
segment 하나가 여러개의 page로 구성되어 있다.
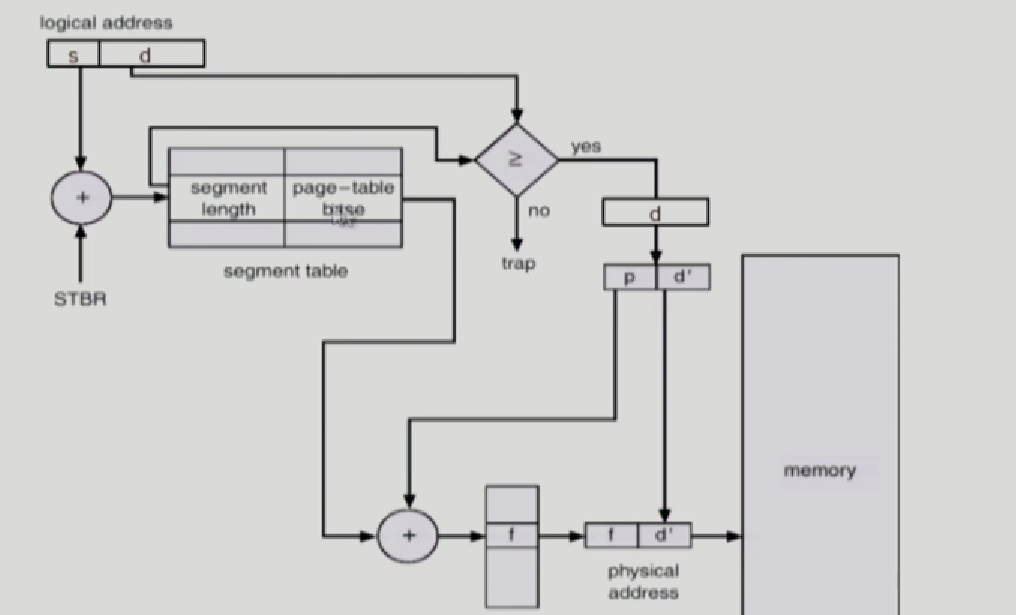
논리적 주소에는 s는 segment번호와 d segment안에어서 얼만큼 떨어져있는지 offset으로 있다.
우선 segment table을 찾아야한다. 우리는 segment number를 가지고 있기 때문이다.
STBR에 segment table이 메모리 어디에 올라와있는지 시작 위치가 있고,
거기서 부터 s번째 엔트리에 가면 이 segment에 대한 주소변환 정보가 있다.
original segmentation에 가면 이 segment가 메모리에 어디에 올라있는지 시작 위치가 담겨져 있었다.
그래서 original segmentation에서는 segment가 통채로 올라가기 때문에 각 segment의 시작 위치만 알고 있으면 된다.
그러나 segmentation with paging기법은 하나의 segment가 각 페이지로 구성이 된다.
그래서 메모리에 올라갈때는 각 page 단위로 쪼개져서 올라간다.
그렇게 되면, 이전에 segmentation의 단점인 segmentation 크기들이 각각 달라서 생기는 hole들이 발생하는 문제가 안생긴다.
왜냐하면 page 단위로 쪼개져서 올라가므로 각 page의 크기는 일정하기 때문에, 메모리도 page크기 단위로 쪼개면 hole없이 메모리에 올릴 수 있다.
그렇게 하고 Protection과 Shared는 segment table에서 담당하는것이다.
그러면 이제 실제 어떤 방식으로 주소 변환이 일어나는지 보자.
일단 logical address가 그림과 같이 주어지면, segment length와 offset인 d를 확인한다.
segment length가 10인데 segment로 부터 떨어진 offset의 길이가 더 크면 안되니까 이걸먼저 확인해서, 그 offset이 segment length보다 짧으면 주소변환이 가능하게 한다.
하나의 segment를 여러개의 page로 짤랐으므로, 하나의 segment당 page table이 존재한다.
그러므로, 이 page table에서 얼만큼 떨어져야 해당하는 page에 대한 frame 번호를 얻을 수 있는지를 d를 통해서 얻는다. d를 p/d'로 짤라서 앞부분은 페이지 번호로 쓰고 d'는 이 페이지에서 얼마나 떨어졌는지 offset으로 사용한다.
고로, logical address에서 d가 segment에서 얼만큼 떨어졌는지에 대한 offset인데 segment하나가 여러개의 page로 구성되어 있으므로, d를 쪼개서 앞부분은 페이지 번호 뒷부분은 페이지 안에서 얼만큼 떨어졌는지 offset을 구한다.
다시 설명해보자면, logical address로 부터 page-table base를 구하고 (segment 당 페이지
테이블이 있으니까 segment1에 해당하는 page table로 가서) 그다음에 p라는 page
number로 가보면 f라는 실제 frame number가 있으니까 phsycial address의f/d'로 바
꿔서 주소변환을 해준다.
그런데 이 모든 과정은 전부 OS가 전혀 관여하지 않는다.
이 physical meory로의 주소변환은 OS가 해주느게 아니라 MMU라는 register 하드웨어가 해주는것이다.
생각해보면 프로세스가 cpu를 잡으면서 주소변환을 요청할 때 만약 os가 해주면 cpu자체가 os한테 넘어가게 될것이다. 이건 말이안된다.
그래서 physical address로의 변환은 register가 관여하고 뒷챕터에서 나오는 virtual memory에서 OS가 관여를 하게된다.
