레디스를 캐시로 어떻게 배치해야하는가
레디스를 어떻게 배치하냐 설계 차이로 시스템 성능에 큰 영향을 미친다.
이를 캐싱전략이라고도 하며, 데이터의 유형과 해당 데이터의 엑세스 패턴을 고려하여 선택해야한다.
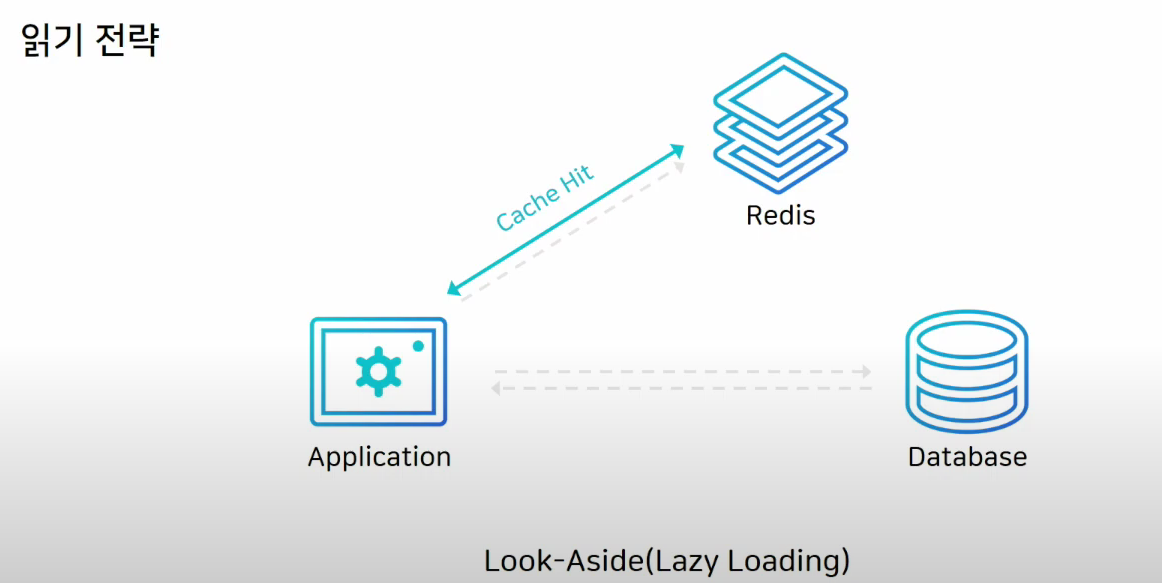
캐시로 레디스를 쓸때 가장 일반적으로 사용
어플리케이션은 데이터를 확인할때 캐시를 먼저 보고, 없으면 DB에서 끌어온다. 그리고 레디스에 다시 저장한다.
레디스가 다운되더라도 DB에서 데이터를 가져올 수 있다.
대신에 레디스에 커넥션이 많이 붙어있다면 레디스가 죽으면 DB에 해당 커넥션이 전부다 붙어버리므로 부하가 몰릴 수 있다.
DB에만 새로운 data를 저장했더라면, 처음에 캐시미스가 엄청 발생하여서, 성능의 저하가 올 수 있다. 이럴때는 미리 DB에서 cache로 data를 밀어넣는 작업을 통해 DB 부하를 줄일 수 있다.
이를 Cache Warming(캐시 워밍)이라고 한다.
쓰기 전략
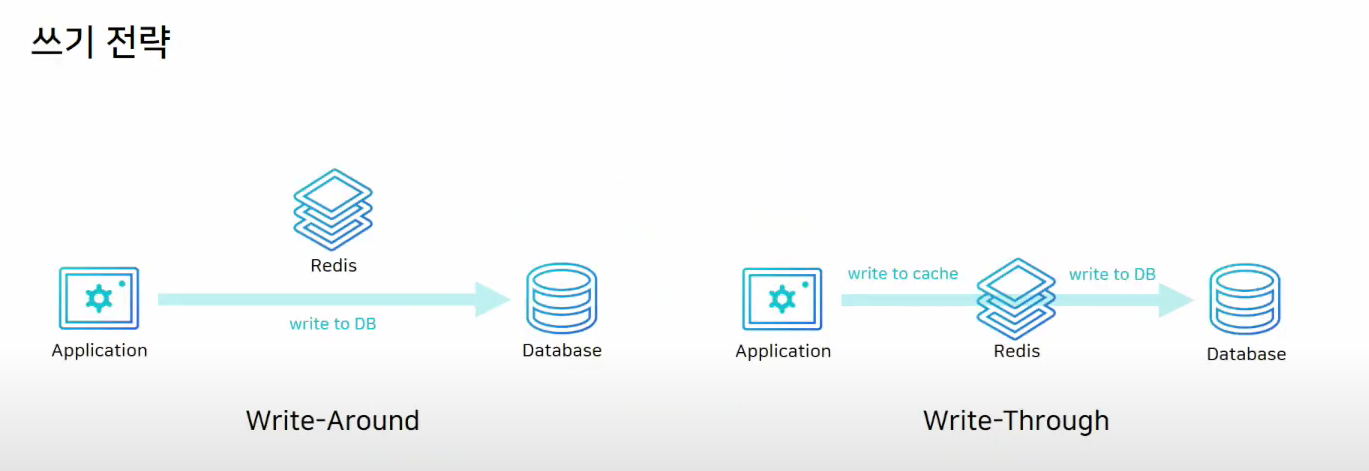
Write-Around: data를 일단 DB에 저장을한다. 캐시 미스가 발생하면 DB에서 끌어온다.
이렇게 되면 캐시내의 dta와 DB의 data의 정합성이 떨어질수 있다.
Write-Throuh: DB에 데이터를 저장할때 Cache에도 같이 저장을 한다.
캐시는 항상 최신정보를 가지고 있지만, 두단계 스탭을 거쳐야하므로 상대적으로 느리다.
또한, 저장된 데이터를 무조건 쓴다는 보장이 없는데 Cache에 데이터를 올리니까 리소스 낭비가 된다.
고로, 이런 경우에는 Expired Time을 설정해야한다.
Redis의 Data Type
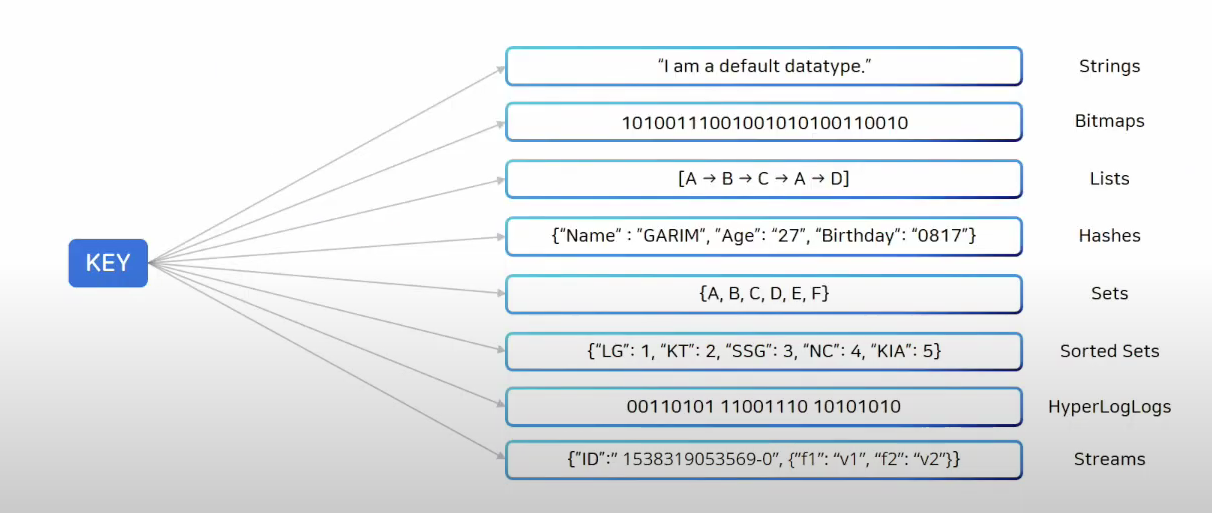
레디스는 다양한 데이터 타입을 제공한다.
set커멘드를 통해서 저장되는건 항상 string으로 저장됨
list를 통해서 data를 순서대로 저장할 수 있음
Hash는 하나의 키안에 여러개의 필드와 벨류 쌍으로 데이터를 저장한다.
set은 중복되지 않은 문자열의 집합
sorted set은 set처럼 중복되지 않지만 Score이라는 값으로 정렬된다. Score가 같은경우 사전순으로 정렬되어 저장된다.
Stream은 로그를 저장하기 좋은 자료구조다.
예시
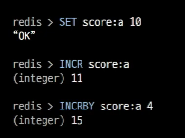
Counting
Counting을 해야하는 상황이 필요할때는 Key하나를 만들어서 카운팅 할 상황마다 하나씩 증가시키는것이다.
이럴때는 INCR함수를 사용하면 쉽다.
두번째로는 Bits연산을 사용하는것이다.
예를 들어 오늘 서비스에 접속한 유저수를 세고싶을때, 날짜 Key를 하나 만들어놓고, 유저 ID에 해당하는 bit를 1로 올려주는것이다.
한개의 비트가 한명을 의미하므로, 천만명의 유저는 천만 개의 bit로 표현할 수 있고 이는 1.2Mbyte밖에 차지하지 않는다.
이걸 잘생각해야하는게 어? 어차피 Integer가 4byte인데, 그냥 Integer amount두고 amount++하면 된느거 아니야? 하는데 이거는 총 방문숫자를 의미하는거고,
userId=100이 들어왔는지 userId=150이 들어왔는지 구분해서 저장하려면 Bits연산을 사용해야한다는것이다.
만약 천만명의 userId를 List<Integer>로 저장했다면 굉장히 data가 많이 들어갈 것이다.
Messaging
앞에서 Count를 사용하는 예제는 이해하기가 수월할 것이다.
그러나 글을 작성하기전 본인과 레디스를 처음 공부하시는 분들은 메시징이 뭔지 이해하기 어려울것이다.
Messaging? 문자 메시지를 보낸다는건가?
레디스에서 Messaging을 어떻게 쓴다는거지?
메시징과 메시지 브로커에 대한 내용은 아래의 포스트를 참고하자.
메시징과 메시지 브로커
Blocking으로 메시지 기능 활용하기
레디스의 리스트는 메시지 큐로 사용하기 적절하다.
자체적으로 blocking기능을 적용하고 있으므로, 불필요한 폴링 프로세스를 막을 수 있다.
Blocking 기능이란?
메시지 큐를 사용하는 시스템에서는 큐에 데이터가 없을 때 어떻게 처리할지가 문제이다.
일반적으로는 Polling이라고해서, 일정시간마다 큐에 데이터를 확인하는것이다. 그러나 폴링은 일정시간마다 계속 큐에가서 메시지 유무를 판단해야하므로 CPU와 네트워크 리소스를 낭비할 수 있다.
레디스는 이런 문제를 해결하기 위해서 Blocking POP명령어, BLPOP,BRPOP을 제공한다.
Blocking은 큐에 데이터가 없을 경우, 데이터를 꺼내는 명령어가 데이터를 기다리다가 새로운 데이터가 들어오면 바로 처리할 수 있게 하는 기능이다.
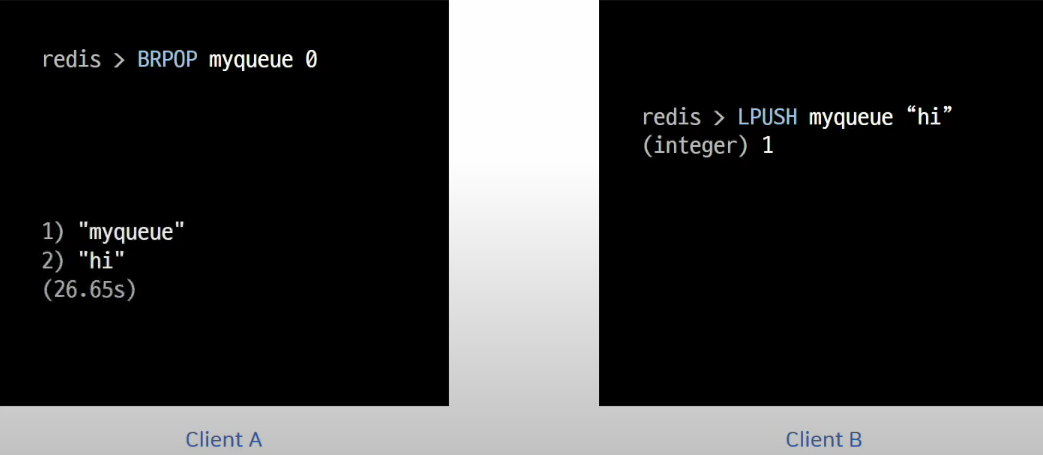
ClientA가 BRPOP으로 메시지가 들어오길 기다리다가 ClientB가 메시지를 넣어주자 마자 CLinetA가 메시지를 큐에서 꺼내서 읽는것을 확인할 수 있다.
List로 메시지 기능 활용하기
Blocking 기능을 이용하면 Event Queue로 활용될수 있다.
LPUSHX, RPUSHX같은 커멘드를 사용하면, 키가 있을때에만 리스트에 데이터를 추가한다.
키가 이미 있다는건 예전에 사용했던 큐라는거고, 사용했던 큐에만 메시지를 넣어줄 수 있기 때문에, 비효율적인 데이터이동을 막을 수 있다.
그냥 이렇게 말로만 하면 이해하기가 어렵고 예시를 들어보자.
실제로 트위터에서 타임라인 업데이트를 할 때 이러한 방식을 사용한다.
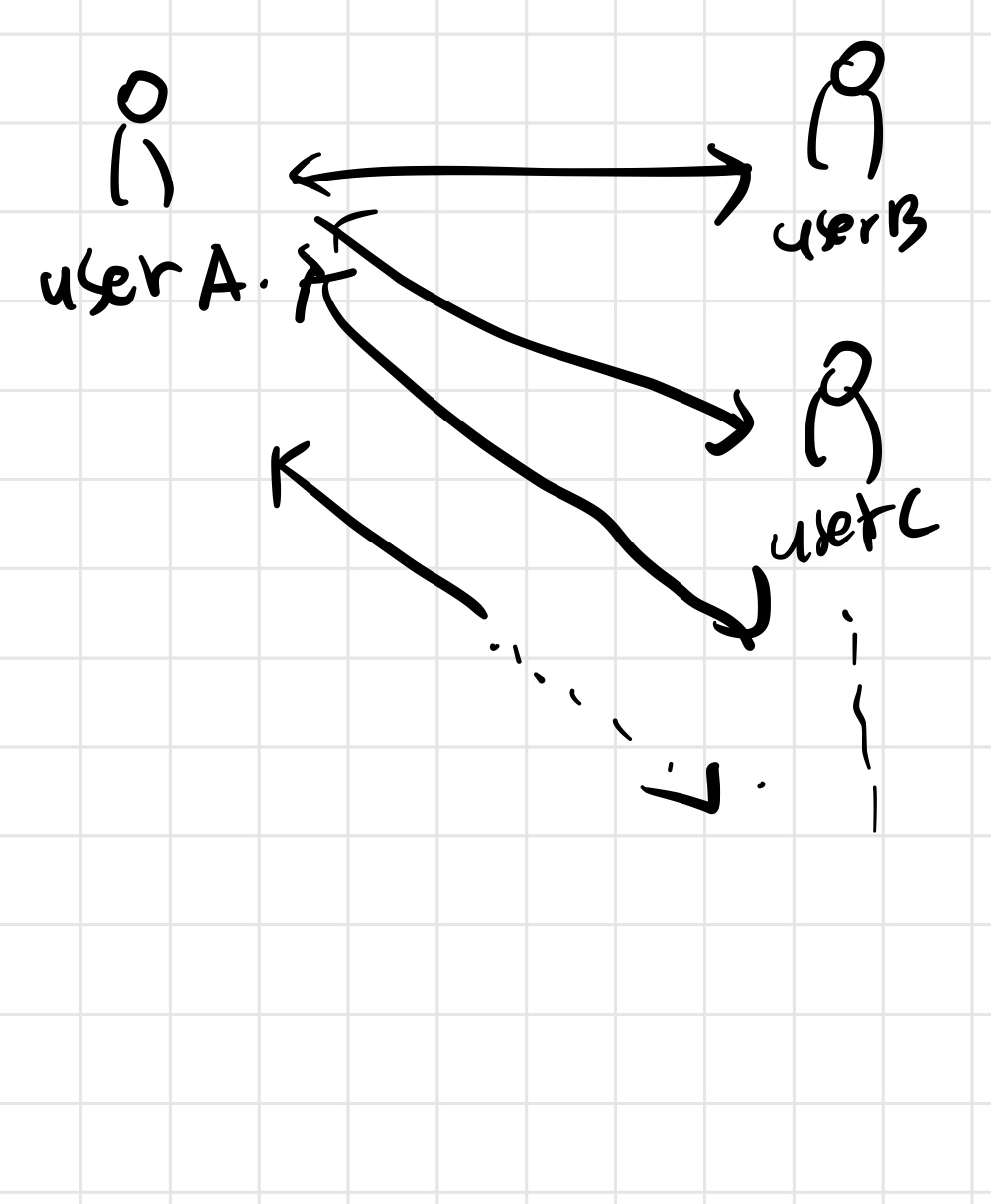
이렇게 UserA와 UserB,UserC,,,이렇게 맞팔이 되어있다고 치자.
만약 UserA가 new_tweet라는 타임라인을 업데이트를 하면 UserB,UserC의 타임라인에 UserA가 new_tweet을 올렸습니다.
이런식으로 업데이트를 해야할 것이다.
그런데 만약 UserB,UserC,,,의 각각 타임라인에 해당하는 List가 있으면 그냥 맞팔 인원만큼 for문을 돌면서 넣어주면 될것이다.
예시로
for(int i=0;i<UserA_Friends.size();i++){
r.rpush('User[i]_list', new_tweet)
}이런식으로 UserB의 List에 new_tweet를 넣고, UserC의 List에 new_tweet을 넣고, 이런식으로 다 넣어주면 된다.
그런데 UserB는 트위터를 자주이용하고, UserC는 트위터를 자주 이용하지 않는다면, 굳이 UserC한테까지 캐싱을 해서 자원을 낭비할 필요가없다.
그렇다면 자주 이용하는 UserB한테만 새로운 포스트를 캐싱할 수 있는 방법이 무었일까?
바로 Redis의 List를 사용하는 것이다.
LPUSHX,RPUSHX는 키가 있을때만 데이터를 저장가능하다.
고로, RPUSHX커맨드를 사용하면, 트위터를 자주이용하는 유저에만 데이터를 캐시할 수 있고 자주 이용하지 않는 유저는 키가 없으므로 캐싱할 수 없다.
간략한 수도 코드로 살펴보자.(원래 포스트할때 자기자신 list에도 넣고 남의 list에도 넣음)
import redis
r = redis.Redis()
# 유저 A, B, C의 타임라인 리스트가 각각 존재
r.lpush('userA_timeline', 'A의 트윗1')
r.lpush('userB_timeline', 'B의 트윗1')
#현재 UserA와 UserB는 자주 트위터를 사용하므로 글을 올린다.
#lpush를 사용하면 리스트가 없는경우 리스트를 만든다. UserA의 타임라인 리스트 키가 userA_timeline이고 UserB의 타임라인 리스트 키가 userB_timeline이다.
#UserA가 새로운 트윗작성
new_tweet = "A의 새 트윗"
r.rpushx('userA_timeline', new_tweet)
r.rpushx('userB_timeline', new_tweet)
#UserC 한테 push하려해도 rpushx즉 userC_timeline이라는 키의 list없으므로 그냥 넘김
r.rpushx('userC_timeline', new_tweet)
...이런식으로 userA가 새로운 트윗을 작성하면 이미 자주사용하는 유저의 list에만 rpushx를 하여 캐싱을 전부가 아닌 내 친구중 트위터를 자주 사용하는 사람에게만 할 수 있다.
그래서 내가 생각해본게, 트위터 타임라인은 실시간 업데이트이니까,
만약 UserA가 글을 올렸을때 List에서 바로 메시지를 가져와서 업데이트를 하려면,
UserB가 BRPOP을 걸어두고, UserA가 UserB의 list에 메시지를 넣어주면 바로 꺼내서 쓰니까 실시간 업데이트가 되는건가? 싶어서 찾아봤는데
이건 또 아니다.
왜냐하면 하나를 간과한게 있는데, 이론상 유저 B가 BRPOP으로 자신의 타임라인 큐를 기다리면서, 유저 A가 트윗을 올리고 그 트윗이 유저 B의 타임라인 큐에 들어가자마자 실시간으로 꺼내 볼 수 있는것은 맞다.
근데 이게 실용적이지 못한게, 유저 B가 이러면 항상 BRPOP을 사용해서 타임라인을 기다리고 있어야하는데, 한번의 BRPOP으로 메시지를 꺼내오면 다시 또 새로운 BRPOP 명령어를 실행해서 유저 B가 항상 트윗을 받을 준비가 되어있어야 하므로 효율적이지 않다.
그러므로, 이럴떄는 웹소켓기능을 사용한다고 한다.
이글은 레디스에대한 글이므로 간단히 설명하고 넘어간다.
웹소켓은 서버와 클라이언트간에 지속적인 연결을 유지하는 프로토콜이라고 한다.
그래서 Redis를 통해서 데이터를 캐싱을 시켜놓으면, 웹소켓을 통해 UserB에게 업데이트 알림이 전달되면, 트위터 서버에서 UserB의 타임라인을 업데이트한다고 한다.
이때 Redis에 저장된 UserB의 타임라인 리스트에서 새로운 트윗을 읽어와 타임라인에 반영한다고 한다.
Stream
Stream은 로그를 저장하기 아주 적절한 자료구조이다.
로그가 서버에 쌓이는것처럼, 모든 데이터는 append-only방식으로 저장되며, 중간에 데이터가 바뀌지 않는다.
- Append-Only란?
기존 데이터를 변경하거나 삭제하지 않고, 새로운 데이터를 항상 덧붙이는(append) 방식으로 저장하는 방법을 의미한다.
데이터를 덧붙이는 방식으로 저장하면, 데이터가 손상되거나 오류가 발생하더라도 마지막으로 덧붙인 부분만 검토하면 되므로 데이터 복구가 용이하다.
또한, 데이터베이스가 갑자기 죽어버리더라도, Append Only 파일을 통해 마지막 상태까지 복구할 수 있다.
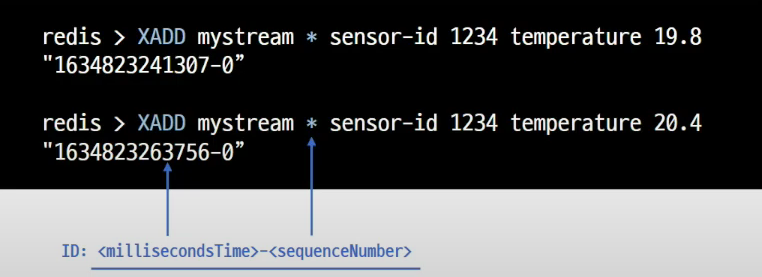
XADD로 해당 로그를 저장하게 되면, * 를 통해서 id값을 반환 시켜주는데 데이터가 저장된 시간을 의미하고 Hash처럼 id가 Key가 되고 Value로 sensor-id가 저장되는 것을 볼 수 있다.
데이터를 읽어올때도 시간대로 검색을 할 수도 있다.
Redis에서 데이터 영구저장
Redis는 In-memory 데이터 스토어
서버 재시작시 모든 데이터 유실, 복제 기능을 사용하더라도 데이터 유실에서 안전하지 못함.
왜냐하면 사람이 실수로 데이터를 삭제하면 복제본에도 똑같이 데이터가 삭제되기 때문
Redis를 캐시 이외의 용도로 사용한다면 백업 기능을 사용해야한다.
AOF
Append Only File
데이터를 변경하는 커멘드가 들어오면 커멘드를 그대로 저장
많이 로그가 쌓이므로 반드시 압축해서 저장해야하고, 우리가 읽을 수 없는 바이너리 파일로 저장된다.
RDB
Data 그대로를 사진찍듯이 저장
자동/수동 파일 저장방법
RDB
-
자동: redis.conf파일에서 SAVE옵션(시간 기준)
save<seconds> <changes>
save 900 1 # 15분 동안 1번의 변경이 발생할 때 스냅샷 저장
save 300 10 # 5분 동안 10번의 변경이 발생할 때 스냅샷 저장
save 60 10000 # 1분 동안 10000번의 변경이 발생할 때 스냅샷 저장 -
수동: BGSAVE 커맨드를 사용하여 cli 창에서 수동으로 RDB파일 저장 -> SAVE커맨드는 절대 사용 금지(해당 명령은 백그라운드에서 저장 작업을 수행하므로, Redis가 요청을 처리하는 동안에도 작업이 계속된다. SAVE 명령은 Redis가 저장하는 동안 블로킹되기 때문에 권장되지 않는다.)
redis-cli BGSAVE
AOF
- 자동: redis.conf파일에서 auto-aof-rewrite-percentage
- 수동: BGREWRITEOF 커맨드를 사용해 CLI 창에서 수동으로 AOF파일 재작성
선택기준
Redis를 캐시로 만 사용한다면 해당 기능은 설정하지 않아도 된다.
-
백업은 필요하지만 어느정도 데이터 손실이 발생해도 괜찮은경우
RDB 단독사용, redis.conf파일에서 save옵션을 적절히 사용 -
장애 상황 직전까지의 모든 데이터가 보장되야하는 경우
AOF사용, APPENDSYNC옵션이 everysec인경우 최대 1초사이의 데이터 유실이 발생가능하다. -
제일 강력한 내구성 사용
RDB,AOF둘다사용
Redis를 잘 이용하기!
Redis는 Single Tread로 동작한다.
만약 사용자가 오래걸리는 요청을 보내면, 다른 요청들은 대가상태가 된다.
keys 모든 키들을 보여주는건데, 개발환경에서 습관적으로 사용하다가, 운영서버에서 실수로 keys 가 손이 먼저 나가게되면 운영서버가 뻑이 날 수 있다.
그래서 아에 keys를 사용하는것을 권장하지않고 scan으로 대체하는 것이 좋다.
scan은 커서 기반으로 동작한다. 한번에 모든 결과를 반환하지 않고, 일정한 크기의 결과를 여러번에 걸쳐 반환하는 형식이다.
SCAN cursor [MATCH pattern] [COUNT count]
127.0.0.1:6379> SCAN 0
1) "20" # 다음 커서 값
2) 1) "key1" # 검색된 키 목록
2) "key2"
삭제도 마찬가지이다. Hash나 Sorted Set에는 내부에 여러개의 item을 저장할 수 있는데, 키 내부에 item이 많아질수록 성능이 저하되게 된다.
고로, 하나의 키에 item을 100만개 이하로 저장하는것이 좋은데,
만약 100만개 이상이라 item을 지울때 del을 사용하게 되면, 키를 지우는동안 아무런 동작을 수행할수가 없다.
이때, unlink를 사용하면 키를 백그라운드로 지워주므로 unlink를 권장한다.
변경하면 장애를 막을 수 있는 기본 설정값들
STOP-WRITES-ON-BGSAVE-ERROR = NOyes가 defualt이다.
RDB파일이 정상적으로 저장되지 않았을때, redis로 들어오는 모든 write를 차단하는것이다.
만약, redis 서버에대한 모니터링을 적절히 하고 있다면 이 기능을 꺼두는게 더 효율적이다.
MAXMEMORY-POLICY = ALLKEYS-LRURedis를 캐시로 사용할때는 Expire Time을 반드시 설정해야한다.
메모리가 한정되어있기 때문에, 만약 해당 설정을 하지 않으면 redis 메모리에 data가 금새 max까지 차버리기 때문이다.
이때, Data가 Max메모리까지 가득 차게 되면 MAXMEMORY-POLICY에 의해 삭제되는데, 기본 설정이 noeviction(default)이다.
noeviction은 삭제 안함인데, 이는 데이터가 꽉찼는데 삭제를 안해버리므로 장애가 발생할 수 있다.
volatile-lru는 expire 설정이 있는 값들중에서 가장 최근에 사용하지 않은 키를 삭제한다.
allkeys-lru는 모든 키에대해서 lru로 삭제한다는것이다.
Cache Stampede
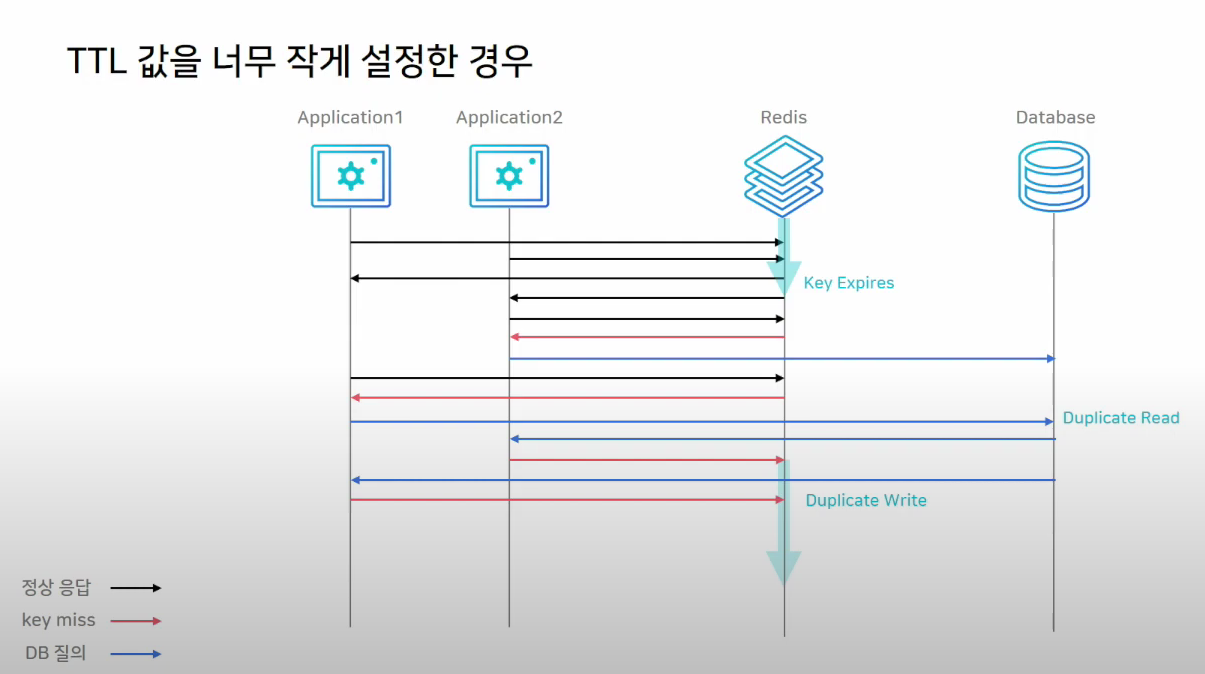
대규모 트래픽 환경에서 TTL 값을 너무 작게 설정하면 Cache Stampede 현상이 발생할 수 있다.
Look aside패턴에서는 서버가 Redis에서 데이터가 없다는 요청을 받으면 DB로 데이터를 직접 요청을 하게 되고, 이를 다시 Redis에다가 기록하는 과정을 거치게 된다.
그런데, 키가 만료되는 순간, 많은 서버에서 해당 키를 바라보고 있었다면, 모든 어플리케이션 서버가 DB에 가서 같은 데이터를 찾게되는 Duplicated Read가 발생하게 된다.
또한, 읽어온 값을 각각 Redis에 쓰게되는 Duplicated Write가 발생하게 된다.
한번 이런 상황이 발생하면, 불필요한 작업이 늘어나고 처리량이 늘어나게 된다.
Memory 관리
Redis는 메모리를 사용하는 저장소이므로, 메모리관리가 제일 중요하다.
모니터링을 할때는 used_memory가 아닌 used_memory_rss값을 모니터링하는것이 중요하다.
- used_memory: 논리적으로 Redis가 사용하는 메모리
- used_memory_rss: OS가 실제로 Redis에 할당한 물리적 메모리
실제 저장된 데이터는 적은데, RSS값은 큰 상황이 발생될 수 있고, 이럴때 Fragmentation이 크다고 말한다.
주로 삭제되는 키가 많을때 fragmentation이 증가한다.
예를 들어, 특정 시점에 키가 피크를 치고 다시 삭제되는 경우인데
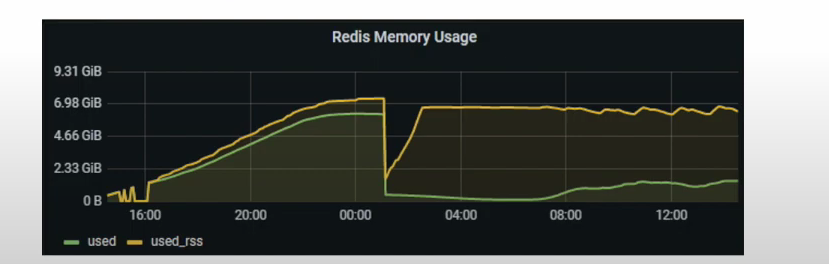
그림과 같이 used는 확 내려갔는데 rss는 아직 감소하지 않은것을 볼 수 있다.
그렇다면 키가 삭제되었는데 왜 rss가 감소하지 않는걸까?
키가 피크 시점에 많이 생성되고 삭제되면, 메모리 할당과 해제가 반복되면서 메모리 블록들이 비어있는 작은 조각으로 나뉘어,메모리 단편화가 발생한다.
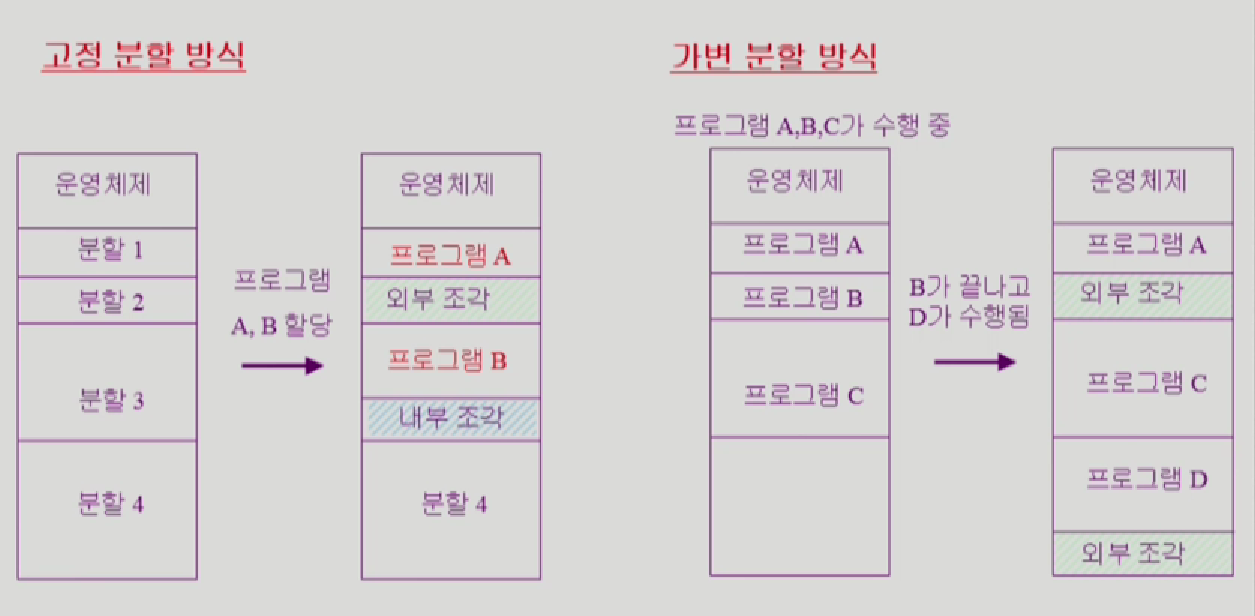
여기서 가변분할 방식처럼 B가 나가고 D가 들어와야하는데 B에는 size가 안맞아서 못들어가니까, 원래 B의 공간이 외부조각 Hole이 생기고, 또 분할 4번에서 D가 들어갔는데 공간이 남을 수 도 있다.
만약 B가 나가고 남은 공간이 3 D가 들어가고 남은공간이 1이라고 치고, 다음 Data가 4라고 치면, 당연히 못들어간다. 왜냐하면 사용가능한 메모리공간은 3+1로 4이지만 연속된 메모리 블럭이 아니기 때문이다.
그러므로, REdis는 여전히 많은 메모리를 차지하고 있는것처럼 보인다.
고로, 이러한 메모리 단편화를 줄여주는 기능인 active defragmentation기능을 제공하는데,
Redis는 해당 기능으로, 작은 조각으로 남아있는 메모리 블럭들을 모아서 연속된 메모리 블럭으로 만들고, 운영체제에 다시 메모리를 반환할 수 있게 돕는다.
이때, CONFIG SET activedefrag yes를 통해 잠깐 켜두면 좋다.
참고
https://www.youtube.com/watch?v=92NizoBL4uA
https://velog.io/@wnguswn7/Redis%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C-Redis%EC%9D%98-%ED%8A%B9%EC%A7%95%EA%B3%BC-%EC%82%AC%EC%9A%A9-%EC%8B%9C-%EC%A3%BC%EC%9D%98%EC%A0%90
https://velog.io/@ad_astra/Memory-Managemnet
