Keras
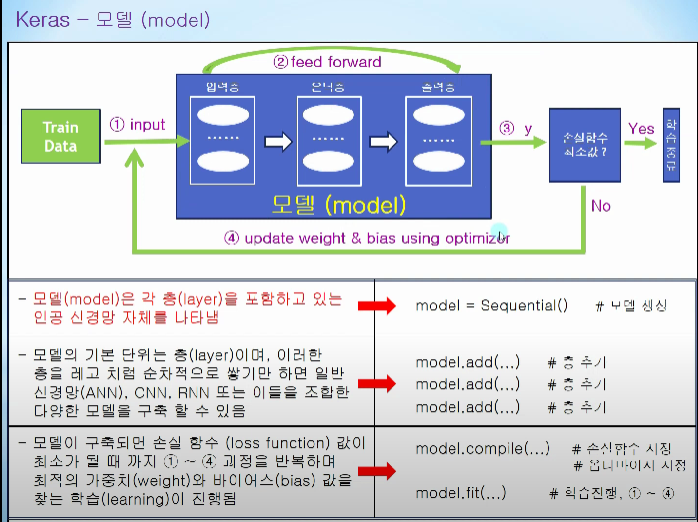
모델의 기본단위 - 층
add메서드를 통해 층을 쌓고, 각 층끼리 조합을 통해 CNN,RNN구현가능
모델 구축시 1~4과정을 계속 돌리면서 weight와 bias를 찾는과정
-
데이터 생성
train data(During learning): 학습에 사용되는 데이터 -> 이걸 통해 가중치와 편향을 최적화하기 위해 사용됨.
validation data(During learning): 오버피팅을 확인하기 위해 사용되는 데이터 -> 전체데이터를 한번 학습시킨뒤에 과적합 확인을 위해 사용됨
test data(After learning): 학습후 정확도 평가, 입력값에 대한 미래의 값을 예측하기위해 사용됨 -
모델구축

Sequential(): 인공신경망 자체(그림에서 박스)
Flatten: 입력층을 add로 붙임, 다차원 입력데이터를 1차원으로 정렬
Dense: 은닉층을 add()로 붙임, 입력과 출력사이의 있는 모든 노드가 연결되어있음, 첫번째 인자가 출력 노드수, activation - 활성화 함수(linear,sigmold,relu)
3번: 첫번째 계층에 바로 Dense 계층을 쓰는경우 같이 나타냄 -
모델 컴파일
최적화 알고리즘, 오차함수, 모니터링 지표를 통해서 컴파일
model.compile(optimizer = SGD(learning_rate=0.1),loss='mse',metrics='['accuracy']')
최적화알고리즘 SGD, 학습률 0.1, 오차함수 mse, 매트릭 loss(손실)은 기본이므로 여기서 정확도도 같이 측정하겠다. -
모델 학습
손실함수값이 최소가 되게 각 층의 가중치와 편향을 찾음
model.fit(x_train,t_train,epochs=10,batch_size=100,verbose=0,validation_split=0.2)
첫번째 인자: 입력데이터, 두번째 인자: 정답데이터, 세번째 인자: 전체데이터를 총 10번반복, validation_data는 내가 만든 테스트셋, split은 데이터중 20프로를 가져다가 검증데이터로 사용 -
모델 평가
test데이터를 통해 모델평가 및 임의의 데이터로 예측
model.evaluate(x_test, t_test, epochs=10, batch_size=100)
x_test: 테스트 데이터, t_test는 정답데이터 , epochs: 평가를 위해 몇번을 반복할껀지
->return: 테스트 데이터의 정확도
model.predict(x_input_data,batch_size=100)
1번째 인자는 예측하고자하는 데이터, return: numpy -
모델 저장
가중치와 편향이 최적화된 모델을 저장 -> 다양한 테스트 데이터에 재학습 필요없음
model.save()
Linear Regression, Loss function
regression(회귀): Training Data를 통해 데이터 특성과 산관관계 파악 - 미지의 데이터가 주어졌을때 결과 예측
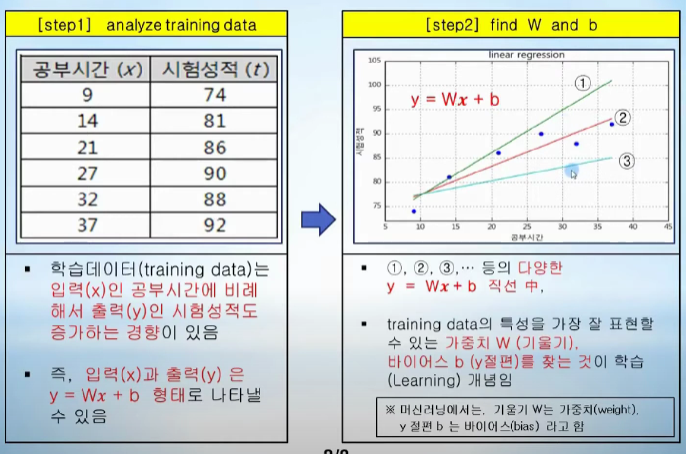
결국 왼쪽의 test 데이터를 바탕으로 y=Wx+b 그래프를 찾는것임 W는 가중치 b가 편향
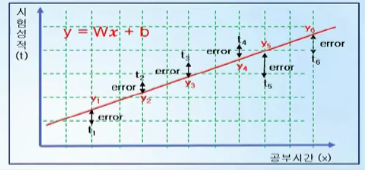
y=Wx+b를 찾았다고 가정 -> x를 뿌려서 y를 찾으면 시험성적 t와의 차이만큼 오차가 생김 t-y 즉 ML은 t-y의 합이 최소가 되서 미래 값을 잘 예측할 수 있는 w랑 b를 찾는것임
즉 손실함수란 y=Wx+b에다가 x값을 넣은 y랑 t와의 차이를 전부 더해서 수식으로 나타내는것인데, 이게 t-y를하면 -, +가 합쳐져서 0일수있으니까 이걸 제곱해서 손실함수를 구함
즉 loss function은 평균오차를 구하는것임
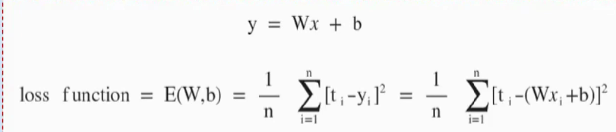
Gradient Decent algorithm
b가 0이라고 가정

W값의 변화에따라 18.7 -> 4.67 -> 0 이런식으로 변화하는것을 알 수 있음
이걸 그래프로 그려보면
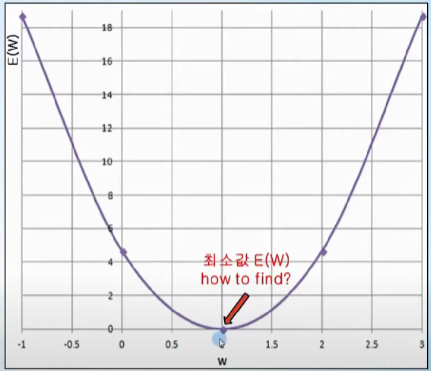
이렇게되고, 미분값이 0일때 E(w)값이 최소임을 찾을 수 있다.
즉, 임의의 W를 선택하고 미분값이 작아지는 방향으로 증가,감소시켜나가다가 더이상 작아지지 않는곳을 찾고, 그지점이 E(w)의 최소값임
E(W)의 편미분 값이 양수라면 W값은 왼쪽으로 이동해야함
E(W)의 편미분 값이 음수라면 W값은 오른쪽으로 이동해야함
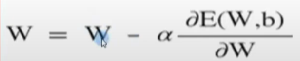
알파: 학습율
편향인 b도 동일함
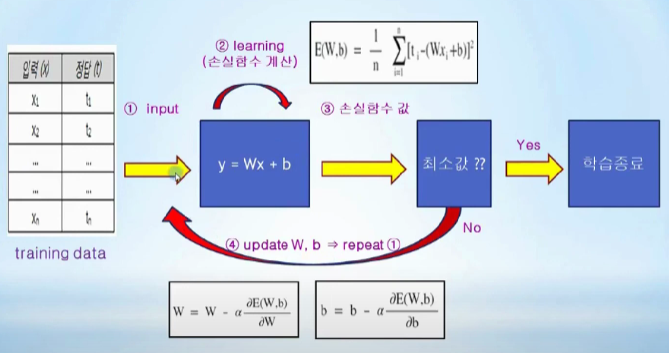
프로세스: trainig data가 들어오면 손실함수를 계산 -> 손실함수 값이 최소면 종료 -> 아니라면 손실함수가 최소가 되는 W,b를 편미분 값을 이용해 update
선형회귀
입력 정답
1 2 0 -4
5 4 3 4
...
이렇게 input과 정답이 들어오면, y = w1x1 + w2x2 + w3x3 + b라는 선형회귀 문제가 된다 우리는 w1,2,3,b를 찾아야한다.
model = Sequential() //모델생성
model.add(Dense(1, input_shape(3,),activation = 'linear')) // 입력이 3개들어와서 3
model.compile(optimizer = SGD(learning_rate= 1e-2),loss = 'mse') // SGD 학습알고리즘, rate가 학습률 loss가 평균제곱오차Classification(분류)
미지의 입력데이터에 대해서 결과값이 어떤 종류로 분류될 수 있는가를 예측
공부시간 9, fail
... 32, pass
라면, 미지의 공부시간 55가 들어오면 fail인지 pass인지
Logistic Regression
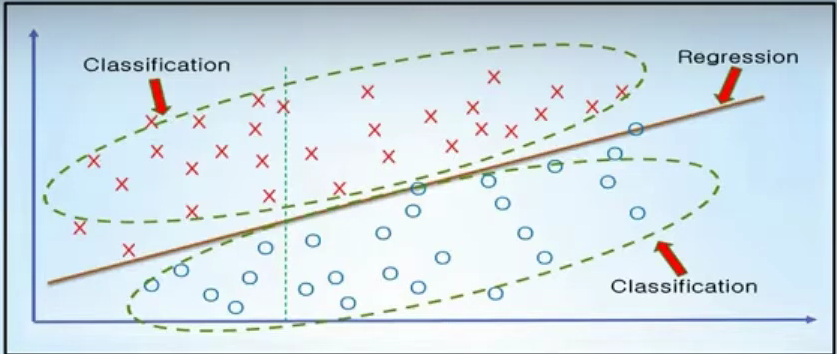
1. 앞에서 했던 Linear Regression으로 최적의 직선을 찾고
2. 그직선으로 위(1), 아래(0)으로 나눈다.
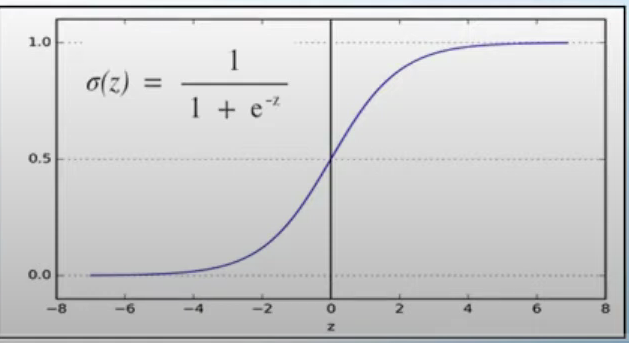
classification에서는 출력값 y가 0또는1을 가져야하는데 train data x가 z=Wx+b를 통과하면 z가 나오고, z를 sigmoid함수를 통해 계산값이 0.5보다 크면 1 작으면 0으로 분류하는 작업이 필요
sigmoid(y축 범위가 0또는1임)
Classification 프로세스
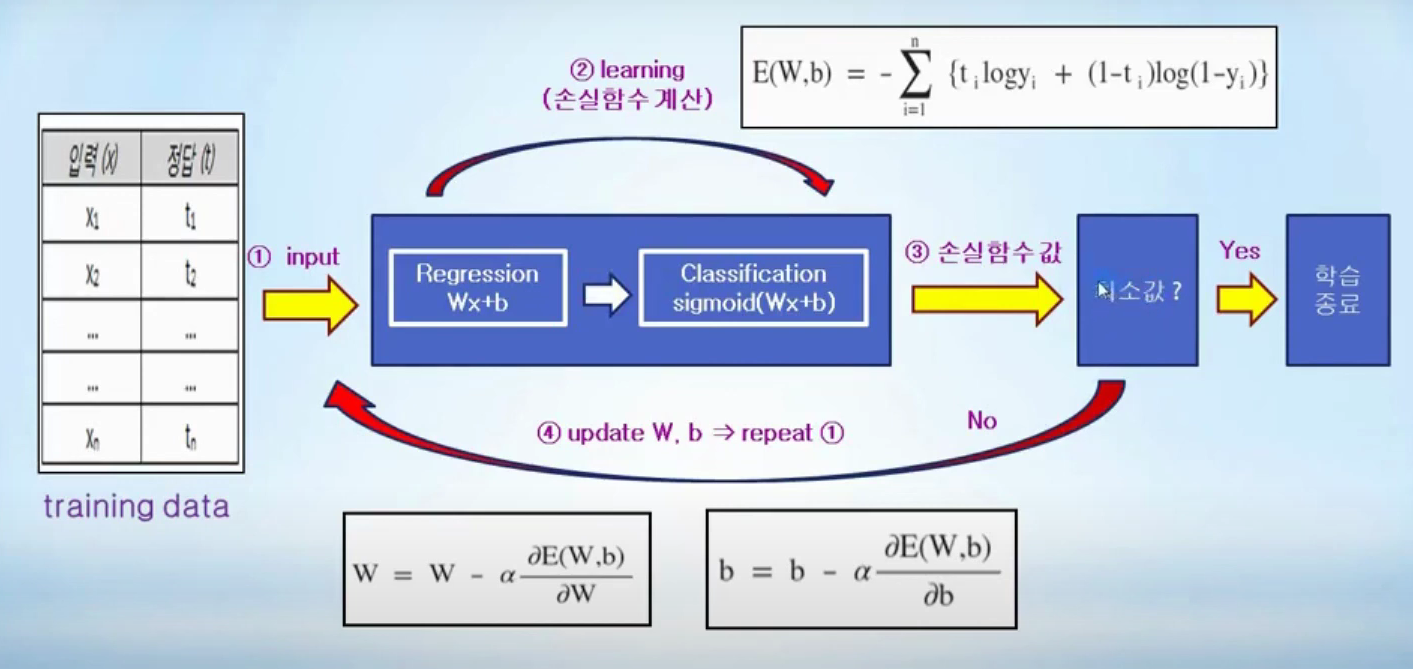
1. 입력과 정답 Trains data를 넣는다.
2. Regression을 통해 Wx+b를 찾는다.
3. Wx+b값을 sigmoid함수에 넣어서 y값을 찾는다.
4. 손실함수를 계산한다.
손실함수 계산방법
p(C=1|x) = y = sigmoid(Wx+b) -> 인풋 x값이 한개일때 출력이 1일 확률이다.
p(C=0|x) = 1-p(C=1|x) = 1-y -> 인풋 x값이 한개일때 출력이 0일 ㅗ학률이다.
p(C=t|x) = y^t(1-y)^1-t이다.
그런데 x가 1개가아니라 a개라고 치면, 확률의 곱인 우도함수로 나타낼수있다.

즉 우도함수가 최대가 되도록 W,b를 업데이트 해나가야하는데, 문제는 함수값이 최대값을 알기위해서는 편미분을 해야하는데(앞에서 경사하강법) 곱셈은 그게 힘드니까, log를 취해줌
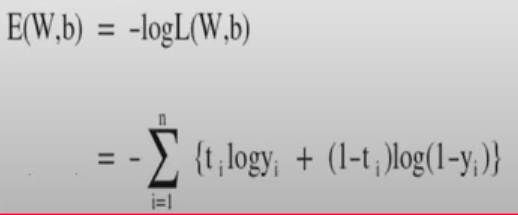
그러면 덧셈으로 바꾸고, 함수의 부호를 바꿔주면 함수의 최대화 문제를 최소화 문제로 바꿀수있다.
이렇게 만든 E(W,b)가 최소인지 확인하고 만약 아니라면, W,b의 값을 편미분을 통해서 바꿔가면서 업데이트 한다.
5. E(W,b)의 값이 최소라면 종료한다.
실제 예제
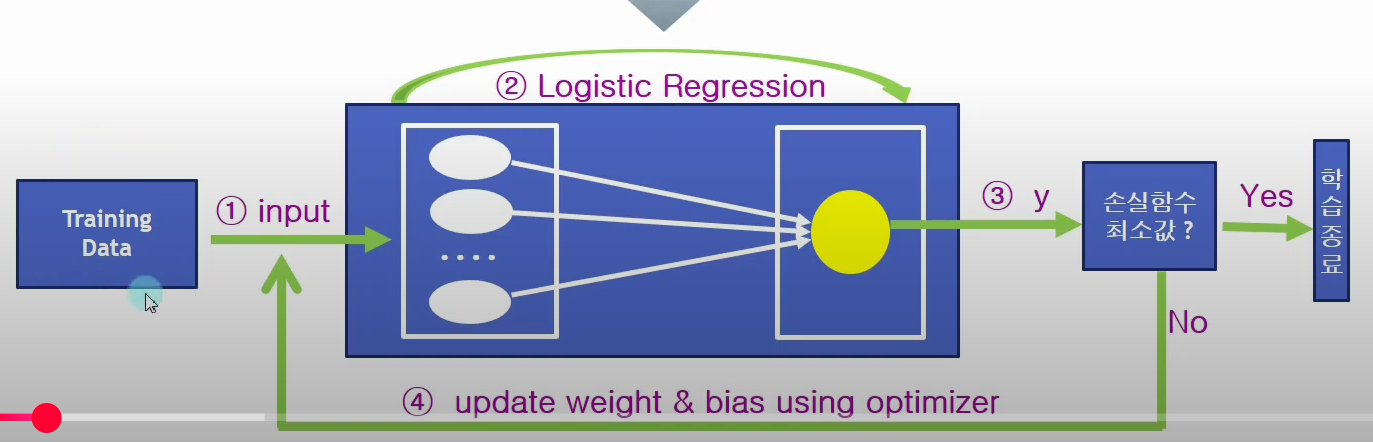
keras에서는 노랑색 부분에 sigmoid(Wx+b)를 수행
피마 인디언 부족 당뇨병 발병 여부 예측(data set)
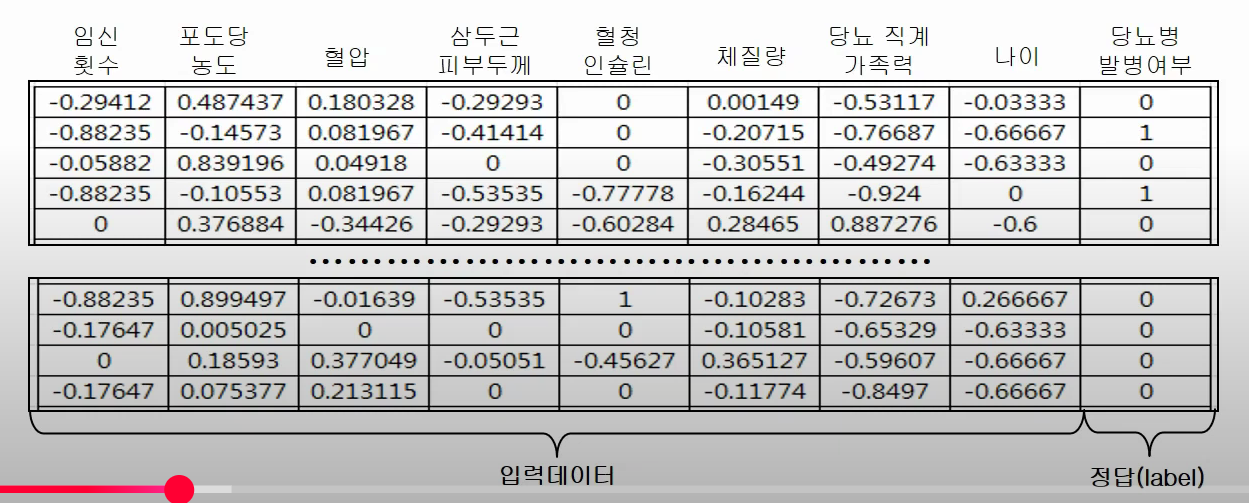
import numpy as np
try:
loaded_data = np.loadtxt('./diabetes.csv', delimiter=',')
# training data / test data 분리
seperation_rate = 0.3 # 분리 비율
test_data_num = int(len(loaded_data) * seperation_rate)
np.random.shuffle(loaded_data)
test_data = loaded_data[ 0:test_data_num ]
training_data = loaded_data[ test_data_num: ]
# training_x_data / training_t__data 생성
//training_data에서 0부터 마지막 전까지가 input data
training_x_data = training_data[ :, 0:-1]
//마지막이 정답데이터 발병유무
training_t_data = training_data[ :, [-1]]
# test_x_data / test_t__data 생성
test_x_data = test_data[ :, 0:-1]
test_t_data = test_data[ :, [-1]]
print("loaded_data.shape = ", loaded_data.shape)
print("training_x_data.shape = ", training_x_data.shape)
print("training_t_data.shape = ", training_t_data.shape)
print("test_x_data.shape = ", test_x_data.shape)
print("test_t_data.shape = ", test_t_data.shape)
except Exception as err:
print(str(err))model = Sequential()
# 노드 1개인 출력층 생성, input_shape는 x_data.shape[1]이 input 층이 8개인것임 classification이니까 sigmoid사용
model.add(Dense(training_t_data.shape[1],
input_shape=(training_x_data.shape[1],),
activation='sigmoid'))
# 학습을 위한 optimizer, 손실함수 loss 정의
//학습알고리즘 SGD, 손실함수 로지스틱 classification에서는 정답이 0 또는 1이므로 loss함수를 binary로 지정
model.compile(optimizer=SGD(learning_rate=0.01),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()//fit메서드로 학습, validation_split: training data로 부터 20%비율로 validation data생성후 overfitting확인
hist = model.fit(training_x_data, training_t_data, epochs=500, validation_split=0.2, verbose=2)model.evaluate(test_x_data, test_t_data)
//loss와 accuracy를 matplotlib을 통해확인
import matplotlib.pyplot as plt
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.grid()
plt.plot(hist.history['accuracy'], label='train accuracy')
plt.plot(hist.history['val_accuracy'], label='validation accuracy')
plt.legend(loc='best')
plt.show()
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid()
plt.plot(hist.history['loss'], label='train loss')
plt.plot(hist.history['val_loss'], label='validation loss')
plt.legend(loc='best')
plt.show()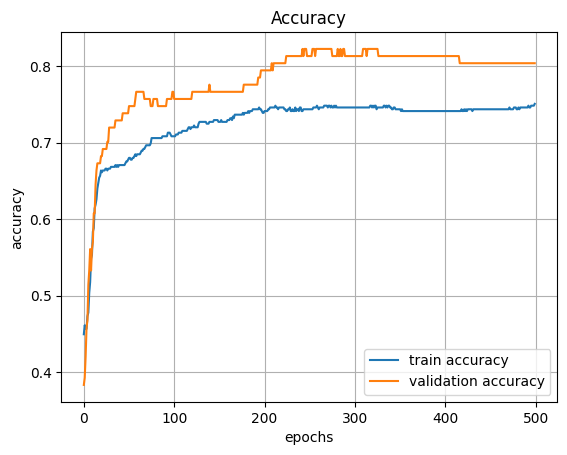
epochs이 200번부터는 더이상 증가하지 않는데, 200번 부터는 오버피팅이 발생하는것임.
Deep Learning Basic
인공지능 -> 머신러닝(선형회귀, 로지스틱 회귀) -> 딥러닝 (ANN,CNN,RNN)
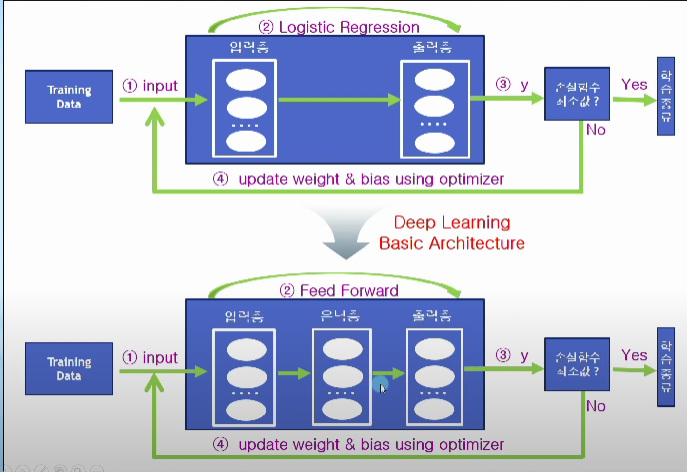
Logistic 회귀는 중간에 은닉층이 없이 입력층과 출력층이 그대로 연결되어있음. 딥러닝은 은닉층이 존재
기본 코드
//모델 생성은 동일
model = tf.keras.models.Sequential()
//은닉층 추가, 은닉층 노드가 8개이고, 은닉층으로 들어오는 input이 1개인것임.
model.add(tf.keras.layers.Dense(8, input_shape(1,), acivattion = 'sigmoid'))
//은닉층과 출력층을 붙임, 출력노드 1개
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))
//컴파일
model.compile(tf.keras.optimizers.SGD(learning_rate=0.1), loss = 'binary_crossentropy',mettrics=['accuracy'])
//모델 학습
model.fit(x_data,t_data,epochs = 500)MNIST
입력층: Flatten을 사용해서 2828크기의 2차원이미지를 784개의 길이를 가지는 1차원 벡터로 변환
은닉층: 은닉층의 갯수와 은닉층에서의 노드개수는 하이퍼 파라미터로 개발자가 튜닝
출력층: 출력층 노드갯수는 정답의 범주와 같은 10개로 설정함, 학습데이터가 0부터 9 까지 10개이므로 출력층 노드갯수또한 10개로 설정해야함.
데이터 전처리
-
정규화
MinMax공식을 사용, 데이터 범위를 0~1사이의 값으로 변화, '[0,52,255]'->'[0,0.2,1.0]' -
표준화
평균과 표준편차를 사용하여 특정범위를 벗어난 데이터를 outlier로 간주, data_new = data-Mean/표준편차 -
원핫 인코딩
정답개수와 동일한 크기를 가지는 리스트를 만들고, 정답에 해당하는 리스트의 인덱스값에 1을 넣고 나머지는 0을 넣음 -> 리스트에서 가장 큰 값을 가지는 인덱스를 정답으로 인식
//데이터 전처리: 정규화,원핫 인코딩
# 학습 데이터 / 테스트 데이터 정규화 (Normalization)
# 최솟값 0 최댓값 255
x_train = (x_train - 0.0) / (255.0 - 0.0)
x_test = (x_test - 0.0) / (255.0 - 0.0)
# 정답 데이터 원핫 인코딩 (One-Hot Encoding)
# 원핫인코딩은 to_categorical 메서드를 이용, MNIST의 정답데이터가 0~9까지 10개 중 한개이므로, num_classes=10으로 지정하여 10개의 리스트를 만들어야함
t_train = tf.keras.utils.to_categorical(t_train, num_classes=10)
t_test = tf.keras.utils.to_categorical(t_test, num_classes=10)//모델생성
model = tf.keras.Sequential()
# input_shape이 28*28크기 2차원 이미지를 784개의 1차원 벡터를 Flatten으로 바꾸기
model.add(tf.keras.Input(shape=(28, 28)))
model.add(tf.keras.layers.Flatten())
#은닉층의 하이퍼 파라미터 100은 알아서 조정
model.add(tf.keras.layers.Dense(100, activation='relu'))
# 정답층의 노드갯수는 입력층의 노드개수와 동일한 10
model.add(tf.keras.layers.Dense(10, activation='softmax'))# Optimzer을 Adam으로 사용, 손실함수는 원핫 인코딩 방식이므로 반드시 categorical_crossentropy를 사용해야함.
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss='categorical_crossentropy',
metrics=['accuracy'])
#모델학습, traning data로부터 30%비율로 validationi data생성해서 오버피팅 확인
hist = model.fit(x_train, t_train, epochs=30, validation_split=0.3)#정확도 확인
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.grid()
plt.plot(hist.history['accuracy'], label='train accuracy')
plt.plot(hist.history['val_accuracy'], label='validation accuracy')
plt.legend(loc='best')
plt.show()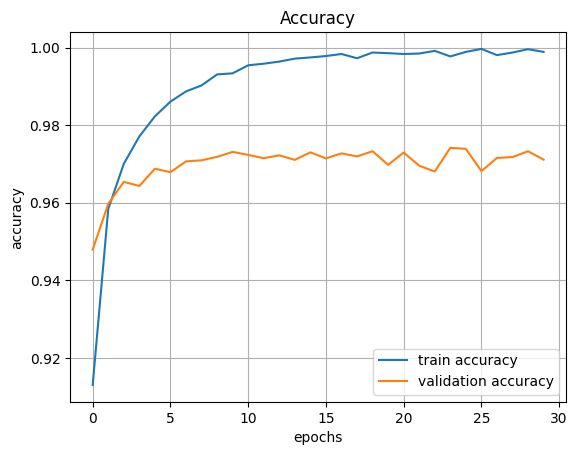
2번째 Fashion MNIST
신발 한장의 사진 28*28이고, 학습데이터가 6만장, 만개의 테스트데이터, 정답이 0부터 9까지 10개로 나눠져있음, 0번 신발 1번 옷,,,,
fashion_mnist.load_data()로 테스트 데이터, 학습데이터를 불러옴
#Fashion Mnist예제에서는 원핫 인코딩은 사용하지 않음
x_train = (x_train - 0.0) / (255.0 - 0.0)
x_test = (x_test - 0.0) / (255.0 - 0.0)
... 앞선 예제와 동일
#compile부분이 loss함수가 원핫 인코딩이 아니므로, sparse_categorical_crossentropy로 설정
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
.... 앞선 예제와 동일
CNN
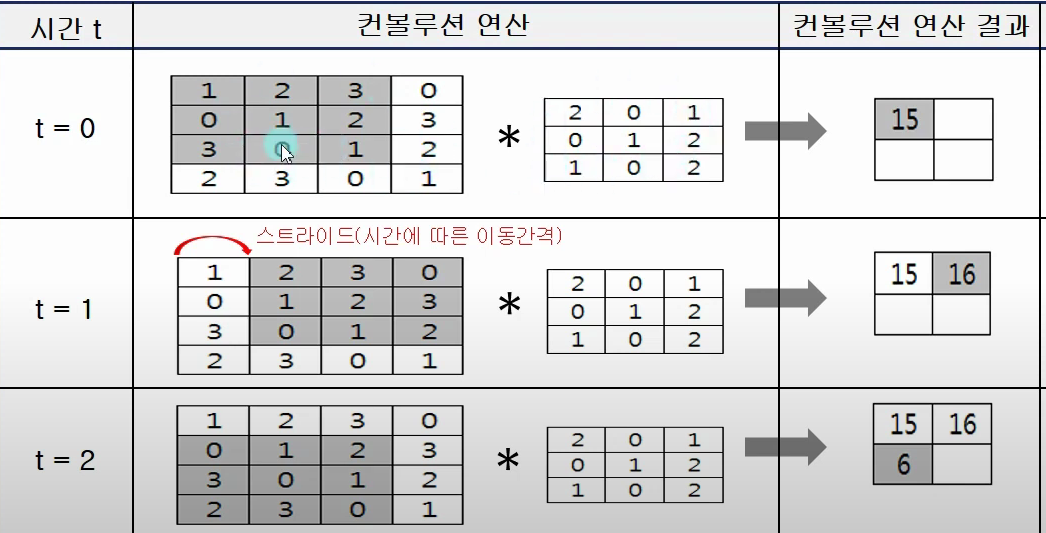
컨볼루션 수식에서 f(x)*g(x-t)부분은 f(x)에다가 곱셈 연산을 통해 [1,0,2]라는 원본데이터를 [2,0,4]로 바꾸는것이고, 적분구간은 평균을 구하는것이다.
고로 시간에 따라 움직이는 데이터 g(x)에 의해서 입력 f(x)가 평균적으로 얼만큼 변하는지를 나타내는것임.
NN vs CNN
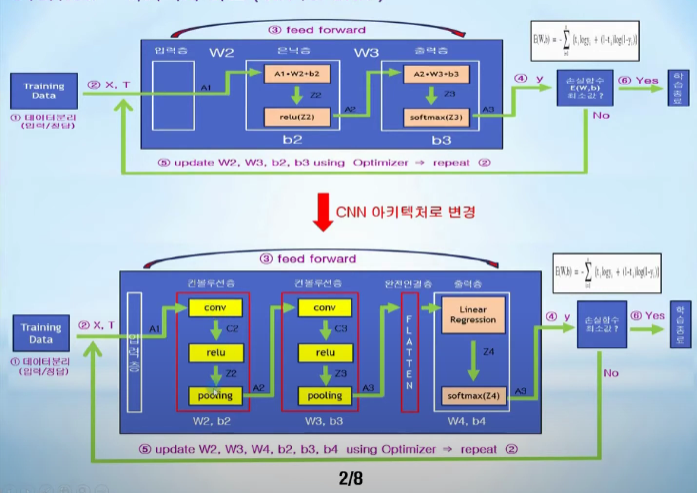
뉴럴 네트웍에서는 앞선시간했던것 처럼 은닉층이 존재하고 출력층에서 나온 y값을 손실함수의 최솟값인지 확인하는 과정을 거친다.
CNN도 동일하다. 그러나 NN에 해당하는 은닉층이 여러개의 컨볼루션 층과 완전연결층으로 구성되어있음을 확인할 수 있다.
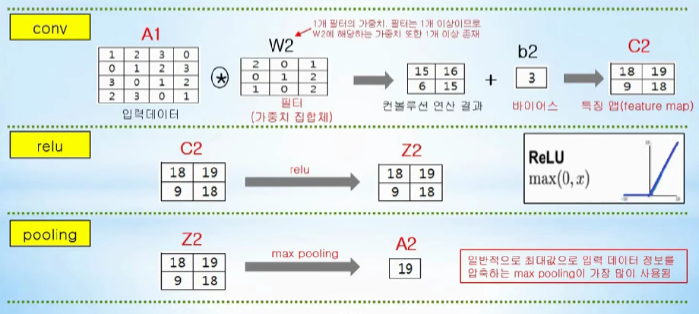
conv: 입력데이터와 가중치들에 해당하는 집합체인 필터와의 컨볼루션 연산을 통해 입력데이터의 특징(feature)를 추출한다.
첫번재 컨볼루션층에 주어지는 입력데이터 A1 * filter_1+b2(첫번째 컨볼루션 층의 편향) -> A1의 특징 추출
두번재 컨볼루션층에 주어지는 입력데이터 A2 * filter_2+b3(두번째 컨볼루션 층의 편향) -> A2의 특징 추출
relu: activate function, 입력으로 주어진 값이 0보다 크면 그대로 내보내고, 0보다 작으면 0을 내보냄
pooling: 입력정보에서 최댓값, 최솟값, 평균값등으로 압축하여 연산량을 줄여준다. 대부분 max pooling이 사용됌.
패딩
컨볼루션 이후 디맨션 축소로인한 입력데이터 주변을 0으로 채우는것.
입력(4,4) 필터 (3,3) 패딩1, 스트라이드 1(필터 한번이동할때 간격)
OH = (4 + 21 -3)/1 +1 =4 OW = (4+21-3/1) + 1 = 4
결과 출력데이터 크기 (4,4)
CIFAR 10
CIFAR 10은 aiplane,automobil,bird등 10개의 정답데이터, 하나의 사진당 32323이라는 컬러 데이터로 이루어져있음
#데이터 불러오기
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
# 높이 너비 채널의 형태로 텐서로 변환
x_train=x_train.reshape(-1, 32, 32, 3)
x_test=x_test.reshape(-1, 32, 32, 3)
//255로 나누어 0과 1사이 값으로 정규화, 최댓값이 255이기 때문
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
cnn = Sequential()
#Convolution Layer, 3*3 크기의 필터 32개로 구성
cnn.add(Conv2D(input_shape=(32,32,3), kernel_size=(3,3),
filters=32, activation='relu'))
#Convolution Layer, 3*3 크기의 필터 64개로 구성
cnn.add(Conv2D(kernel_size=(3,3), filters=64, activation='relu'))
#Maxpooling진행
cnn.add(MaxPool2D(pool_size=(2,2)))
#25%비율로 연결을 끊어 overfitting방지
cnn.add(Dropout(0.25))
#3차원 텐서를 1차원 벡터로 변환
cnn.add(Flatten())
#128개의 노드를 가지는 dense층
cnn.add(Dense(128, activation='relu'))
cnn.add(Dropout(0.5))
#출력층은 0부터 9까지 정답
cnn.add(Dense(10, activation='softmax'))
cnn.compile(loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(), metrics=['accuracy'])
hist = cnn.fit(x_train, y_train, batch_size=128,
epochs=30, validation_data=(x_test, y_test))성능개선 방법
- 컨볼루션 레이어를 더 중첩시키면 성능이 개선됨
- 회전, 줌, shift등으로 이미지 데이터 보강
- 높은 해상도로 바꾸기 3232 -> 469469
- 배치 정규화 등
Image Data Augmentation
원본이미지에 회전, 반전, 확대등으로 이미지 데이터 개수를 증가시키는것
keras - imageDataGenerator제공
# ImageDataGenerator생성, 30도이내 회전, 가로 30%범위 이동, 40%범위에서 기울임, 좌우반전 가능
gen = ImageDataGenrator(rotation_range = 30, width_shift_range=0.3,shear_range=0.4,horizontal_flip=True)
#load_img호출시 return이 JpegImageFile이므로 CNN학습을위해서 img_to_array로 변형시켜줘야함 정규화로 0부터1사이 값으로
loaded_img = load_img(img_names[i],target_size=(100,100))
#정구화
loaded_img_array = img_to_array(loaded_img/255.0)
image_array_list.append(loaded_img_array)
batch_size = 2
#flow함수에 입력으로 주어지는 데이터는 (원본데이터 전체 갯수, 높이,너비,채널)의 형식인 4차원 텐서로 주어져야함.
# 만약 (100,100,3) 100by100 color 사진이 4개 있다면, (4,100,100,3)으로 주어져야함
#이렇게 전체 개수를 포함한 4차원텐서로 만들기위해서는 np.array등을 사용
#batch_size는 size만큼 무작위로 뽑아서 변형진행
data_gen = gen.flow(np.array(img_array_list), batch_size = batch_siz)
#두개의 이미지가 생성
img = data_gen.next() flow_from_directory()예제
data_gen = gen.flow_from_directory(diretory=data_path,batch_size=batch_siz,shuffle=True,target_size(100,100),class_mode='categorical')flow_from_directory()함수를 이미지 부를때, 하위 디렉토리 이름에 맞춰 자동으로 라벨링을함
test_dir
-cat: cat1.jpg,cat2.jpg
-deer: derr1.jpg,,,
class모드는 정답을 나타내는 방식이며, binary는 0또는1 categorical은 one-hot encoding형태, sparse는 십진수형태
one-hot encoding
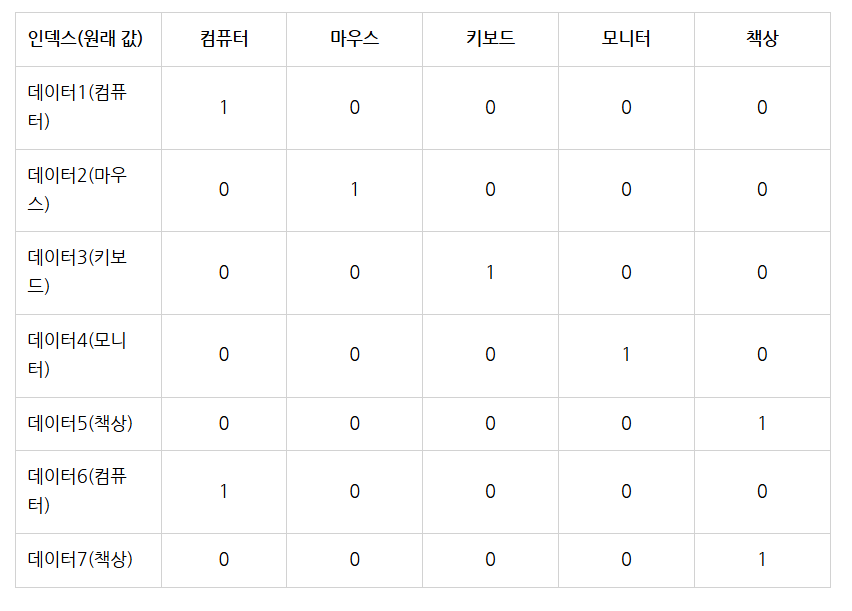
왜 사용하냐, 연속적인 특징이 없는경우에 연속성이 없다는것을 확실히 하기 위해서.
label = data_gen.next()에서 batch_siz만큼 이미지 생성
그러나 mode가 categorical방식이므로 label이 one-hot encoding방식으로 나타나므로 십진수로 표현하기위해서
np.argmax(label)을 해줘야함
결론
Linear Regression은 단일 선형회귀 y = w^Tx+b를 만드는 모델이다. 은닉층이 없거나 1개인 다층퍼셉트론이다.
CNN은 입력이미지의 지역적 패턴을 잡아내기위해서 컨볼루션 연산을 사용하고, 마지막에 Linear Regression을 통해서 추출된 고수준 특징을 바탕으로 회귀값,분류를 산출하는것이다. 고로 마지막 Linear층은 그 특징으로 최종결정을 내리는 층이다.
Linear Regression은 사진을 한번 쓱보고 이건 뭐다라는 판단
CNN은 사진을 여러번 컨볼루션하며 선이있네 -> 원이 있네 -> 귀같네 -> 아,고양이네 이런식으로 구체화하는 판단.
