cpu burst: 오래걸리는 IO작업이 아닌 cpu를 잡아서 기계어 실행
I/O burst: I/O작업을 기다리는것
이 두가지의 버스트로 프로세스는 진행이된다.
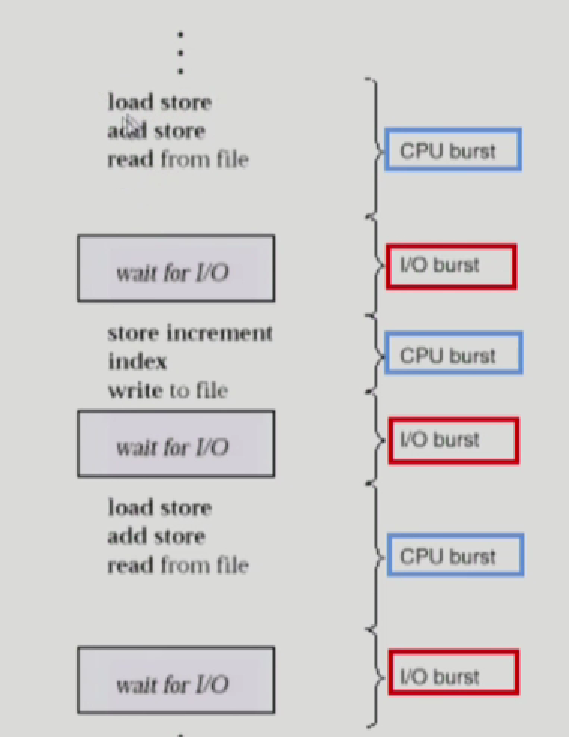
이제 CPU-burst Time의 분포도를 봐보자
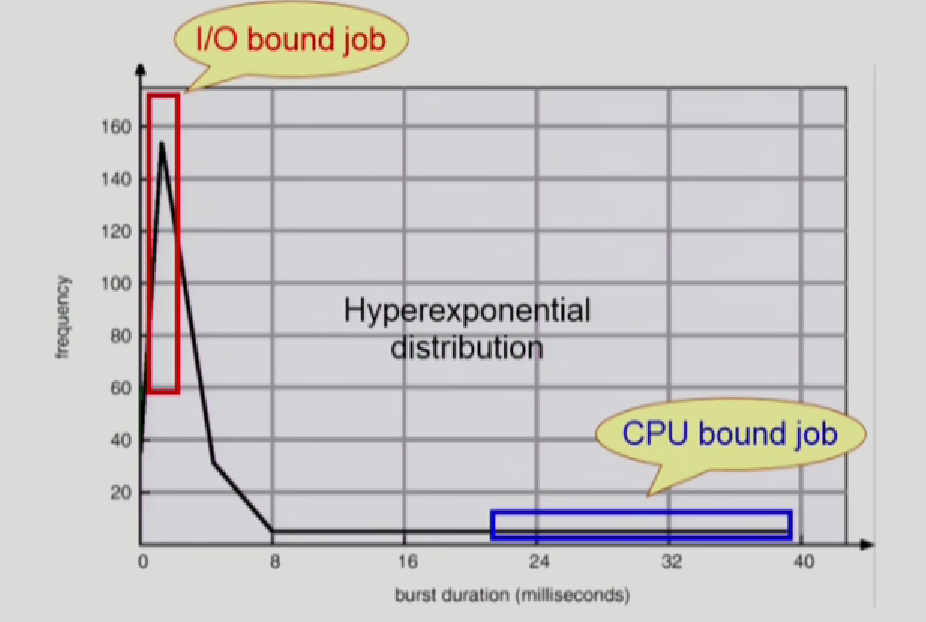
그래프를 보면 얼마나 사람과 interactive한 job이 많냐에 따라서 분포도가 다른데,
당연히 사람과 interactive한게 많으면, I/O를 받아야 되는 횟수가 많으니까, cpu burst time이 짧아지고 횟수가 많아진다.-> 사람이 계속 요청을 보내고, 키보드를 입력하고 이러니까
대신에 사람과 interactive가 적은, 예를들어 행렬 1000*1000 곱셈같은것은 문론 행렬내용을 메모리에 올려야되지만, 이 IO가 끝나면 진득히 cpu burst만한다.
그래프를 보면, cpu burst가 짧은 -> IO가 많이 끼어드는 이런게 빈도수가 많은 IO bound job이라 하고
CPU만 한번잡으면 진득히 쓰는걸 CPU bound job이라고 한다.
결국 이걸 초장부터 소개한 이유가 뭐냐면, CPU스케쥴링 때문이다.
만약에 CPU bound job이 한번 cpu를 잡고 계속 써버리면, 너무 오래걸리니까 IO를 받아야 하는 User가 너무 답답함을 느낄 것이다.
물론, cpu를 공평하게 나누는것도 있지만, 이런 IO bound job에게 cpu를 우선적으로 주는것이 필요하다. => 이게 cpu 스케쥴링의 기본이다. 공평성보다는 효율성
그래서 프로세스의 특성을 분류해보자면,
-
I/O bound process
cpu를 잡고 계산하는 시간보다 IO에 많은 시간이 필요한 Job [Many short Cpu Bursts] -
CPU bound process
계산위주의 job [Few very Long CPU bursts]
CPU scheduler & dispatcher
둘다 운영체제의 code에 적혀있다. 당연히 운영체제가 운영체제 code를 보고 어떤놈한테 자원을 줄지 결정할테니까.
- CPU Scheduler -- Ready상태의 프로세스중에서 다음에 어떤 놈한테 cpu를 줄지 고르는 과정
- Dispatcher -- cpu제어권을 실제로 위의 Cpu Scheduler를 통해서 선택된 놈한테 넘기는 과정(Context switch)
CPU 스케쥴링이 필요한 경우
- Running -> Blocked (I/O작업)
- Running -> Ready (할당시간 만료)
- Blocked -> Ready (I/O 작업 완료후 인터럽트)
- Terminated (종료)
★용어알기
NonPreEmptive
강제로 뺏지않고 자진반납 - 1,4
PreEmptive
나머지는 전부 강제로 빼앗음
그래서 결국 CPU 스케쥴링을 크게 두가지로 나눈다.
NonPreEmptive,PreEmptive
그러면 CPU 스케쥴링이 여러가지가 있는데, 어떤게 좋냐? 판단하기 위한것이 선정 척도(Scheduling Critaria)라고한다.
이걸 또 두가지로 크게 나누면, 시스템입장에서 선정척도, 프로그램입장에서 선정 척도로 나눌 수 있다.
중국집에 비유해서 선정척도들에 대해 소개를 해보자.
먼자 시스템입장에서 선정 척도이다.
내가 중국집(시스템)을 차렸고, 주방장(cpu)을 고용했다 하자.
-
Cpu Utilization(cpu 이용률)
전체시간중에서 cpu가 놀지 않고 일한 비율을 뜻한다.
내가 중국집 주인 입장에서 당연히 중국집 오픈시간에서 주방장이 일한 시간이 많아야하므로, 클수록 좋다. -
Throughput
주어진 시간에 몇개의 작업을 완료하였는가?
주어진 시간에 CPU한테 많은 일을 시키는것이 좋다.
중국집에서 단위시간당 얼마나 많은 손님을 받고 내보냈는가이다.
고객입장에서의 선정척도이다.
-
Turn around Time(반환시간)
Cpu를 쓰러 딱 들어와서 다쓰고 나갈 때까지 걸린 시간이다.
손님 입장에서, 고객이 중국집에 와서 밥먹고 나간시간이다.
만약 코스요리를 시켰다면, 음식을 먹는시간+ 다음 코스 요리가 나올때까지 걸리는 시간이다.
또한 손님마다 빨리나오는 -> 작업처리시간이 짧은 짜장면 한그릇 손님과 코스요리를 시키는 손님이 종류 별로 있을 것이다.여기서 오해를 하면 안되는게 wait For IO에서 기다린시간 쓴시간 기다린시간 쓴시간 반복되다가 IO가 필요해서 wait하러 다른 Device의 Ready Queue로 간 시간이 바로 turn around 시간이다.
이말이 뭐냐면 간혹 프로세스 A가 딱 cpu를 쓰기 시작해서 main함수를 나가서 exit하는 그 시간을 Turn around Time이라고 오해할 수 있는게 그게 아니라
우리는 CPU관점에서 따지고 있기 때문에 IO가 발생하면, CPU제어권을 운영체제한테 넘겨준다.
고로, 선정 척도가 하나의 프로세스가 시작부터 끝까지 걸리는시간을 말하는것이 아니고
매 CPU burst건마다. Wait FOr IO부터 Wait FOr IO까지 여러 프로세스가 번갈아서 뺏고 쓰고 뺏고 쓰고 하는 과정에서 얼마나 많은 프로세스를 처리했는지, 또 얼마나 wait르 했는지 이걸 판별하는것이다. -
waiting time - 기다리는 시간 CPU를 쓰고자 하더라도 Ready Queue에서 기다리는 시간,
즉 waiting time + 실제로 기다렸다가 CPU를 받아서 쓴시간 => Turn Around TIme
고객이 중국집에서 음식 나올 때까지 기다린 시간 -
ResponseTime
ready queue에 들어와서 처음으로 cpu를 얻기 까지 걸린시간
어떻게 waiting time과 다르냐면, preEmptive같은경우에는 waitForIo와 waitForIO사이에 IO요청이 없다면 수많은 프로세스들이 번갈아가면서 CPU를 쓴다.
고로, 그 줄서서 기다리는 시간이 여러차례 발생하고 이걸 전부 합한게 waiting time이다
Wait For IO-process1-process2-process3-process1-process2 reauest IO- waitFOrIO
이렇게 되는데, 이제 waiting time은 여기서 process1이 사용할때 process2,3은 기다려야하므로 이 기다린 시간을 각각 더한게 waiting time이되고,
responseTime은 처음 들어와서 최초의 cpu를 얻을때까지 기다린 시간이다.
process1은 0초 process2는 10초 process3은 20초가 될것이다.중국집에 비유를 하면 첫번째 음식이 나올때 까지 기다린 시간이다, 처음에 중국집 들어가면 주문하고 기다린 다음에 딱 단무지가 나오는 시간이 바로 이 response time이다.
CPU Scheduling
-
FCFS
먼저 온놈부터 처리, 비선점형 스케쥴링이다. 안끝나면 cpu를 안 내놓는것이다.
만약에 cpu를 굉장히 오래쓰는 프로세스가 한번 잡아버리면 뒤에 놈들은 전부 기다려야하는 안좋은 상활이 발생가능하다. -
SJF
shortest job first, 짧은 시간 걸리는 프로세스를 먼저 처리한다.
이렇게하면 당연히 줄이 빨리빨리 줄어드니까 queue가 짧아진다.
preemptive버전: 내가 쓰고있는데 더 짧은 얘가 들어오면 새로 들어온 놈한테 준다.

P1이 도착해서 쓰고있더라도 더짧은 P2가 들어오면 내놓고 기다린다.
2초를 썻으므로 cpu Burst가 5초가 되고 나머지 p2,3,4가 전부 5초보다는 작으므로 제일 마지막에 수행된다.nonpreemptive버전: 더짧은 얘가 들어왔더라도 내가 안내놓는 방식으로 구현

여기서 preemptive방식이 cpu Scheduling에서 average waiting time이 제일 작다.
그러면 어? 이 preemptive sjf버전이 가장 짧으니까 이거 쓰면 되나? 싶은데 아니다.
starvation이라는 문제가 있다.
극단적으로 짧은 job을 선호하므로, 만약 cpu사용시간이 매우 긴 프로세스는 엄청 기다려야한다.두번째는 cpu사용시간을 미리 알수가 없다.
만약에 user한테 input을 입력받아야하는 process가 있다면, 이 user가 10초뒤에 입력할지 아니면 1분뒤에 입력할지 모르는 상황에서, cpu를 얼마나 이 프로세스가 사용할지 예측한다는 것이 말이 안된다.그러므로, 어느정도 cpu를 쓸지 추정을 해서 아 이 프로세스는 이만큼 쓰겠지 하고 sjf로직에서 판단을 하는데

t를 실제 n번째 프로세스가 cpu를 사용하는시간
타우 n+1은 다음에 cpu를 사용할것으로 예측되는 시간
하면 알파를가지고
타우 n+1을 예측가능하다. 다음 프로세스가 cpu를 쓸것으로 예측하는시간
aTn+(1-a)Tn
그런데 이건 점화식이니까 풀어서 쓰면
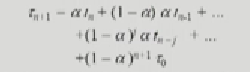
이런식이 되는데 그러면 이 식에서 변수가
t0~tn, a, 타우 0 3가지로 이루어져있다. 만약에
n번째 상황이라면 이미 cpu를 사용한 t0~tn은 기록을 해두었을것이고
a는 설정값, 타우0만 안다면
다음 프로세스의cpu 사용시간을 예측할 수 있다.
Priority Scheduling
우선순위가 제일 높은 프로세스한테 cpu를 준다.
preemptive 버전: cpu를 줘서 쓰고있는데 더 우선순위가 높은 프로세스가 들어오면 뺏어서 새로들어온 놈한테 준다.
nonpreemptive 버전: cpu를 쓰고 있다면, 우선순위가 더 높은 얘가 들어오더라도 주지않는것
생각해보면 sjf도 일종의 우선순위 스케쥴링이다. 우선순위라는게 정수로 주어질때 SJF에서는 우선순위가 cpu이용 시간으로 설정한 것이다.
문제점이 또 Starvation이 발생할 수 있다.
고로,Aging기법을 도입해야한다. 기다릴수록 오래기다린 프로세스한테 우선순위를 높여주는방식
그래서 SJF로 cpu이용시간이 짧은 프로세스를 먼저 처리하더라도, 어느정도 기다린 CPU쓰는 시간이 긴 프로세스도 우선순위가 높아져서 결국 사용가능하게 한다.
Round Robin
현재 Queue에 n개의 프로세스, q라는 시간을 각 프로세스마다 사용하게 한다고 치자,
그러면 어떠한 프로세스간에 (n-1)q시간내에 cpu를 맛 볼 수 있다.
이러면 앞에서 설명한 response time이 매우 짧아진다. 왜냐면 어떤 프로세스던 (n-1)q시간 보다 더 길게 기다리지는 않기 때문이다.
이렇게 되면 아주 짧은시간을 쓰는프로세스는 q라는 작은 시간에도 다 작업을 수행하고 나가버릴것이다.
cpu를 쓰는 시간이 긴 프로세스는 반대로 썻다. 뺏겼다. 썻다 뺏겼다를 반복할 것이다.
q가 너무 크면 FCFS와 같은 스케쥴링이 될것이다.
q가 너무 작으면, 뺏겼다 썻다 하는 과정에서 Context Switch가 너무 많이 발생하므로 오버해드가 커진다.--성능이 나빠질 가능성이 있다.
Multi Level Queue
여러줄로 cpu를 줄서기를 함
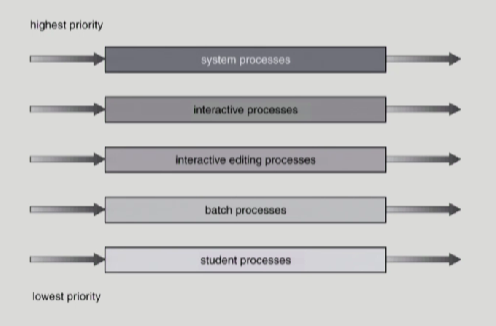
이 그림과 같이 큐를 하나로만 설정하는것과 반대로, 여러개의 큐를 놓은다음에 위로 올라갈수록 우선순위가 높은 큐부터 cpu를 할당하는것이다.
우선순위가 높은 줄이 비어 있다면, cpu가 그 밑에 있는 줄의 큐에서 프로세스를 집어서 처리하는 방식이다.
FeedBack Queue는 우선순위가 바뀔수있다. 강등,승격 가능
Multi Level Queue는 Ready Queue를 여러개로 분할하는것이다.
여기서는 2가지로 나누는데
- ForeGround
- BackGround 로 나눈다.
각 큐는 독립적인 스케쥴링 알고리즘을 가지는데,
ForeGround는 Interactive하기 때문에 RR 알고리즘을 쓰고, BackGround는 Batch-No Human Interaction이므로 FCFS를 사용한다. 즉 1. 어느줄에 CPU를 줄것이냐 2. 그 줄에서 어느 놈한테 CPU를 줄것이냐
로 스케쥴링이 필요하게 되는데 Fixed Priority Schduling -> 우선순위가 높은 줄이 반드시 비어 있어야지만, 밑에 줄에 cpu를 주는 방식 Time Slice -> 각 큐에 CPU time을 적절한 비율로 할당, RR에는 80%, FCFS에는 20% 이런식으로 비율을 할당한다. Multi Level Feedback Queue
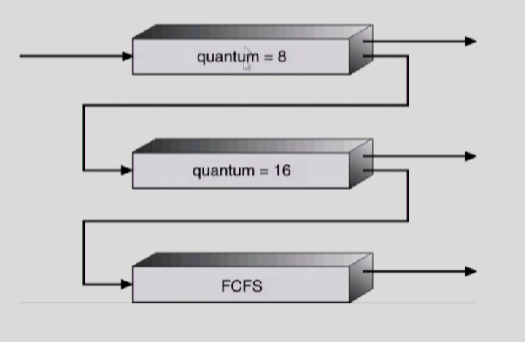
프로세스가 아에 설정된 줄에서 벗어나지 못하면 Starvation이 발생할 수 있다. 그러니까 우선순위가 높은애들이 계속 들어오면, 우선순위가 낮은 애들은 절대로, cpu를 얻을수가 없다.
그래서 프로세스를 다른 큐로 이동을 가능하게 만든것이 Feedback Queue이다.
Aging을 이와같은 방식으로 구현이 가능하다.
Multi Level Feedback Queue를 정의하는 파라미터들
- queue의 수
- 각 큐의 Scheduling Algorithm
- process를 상위 큐로 보내는 기준
- process를 하위 큐로 보내는 기준
- 프로세스가 CPU 서비스를 받으려 할때 들어갈 큐를 결정하는 기준
순서
1. new job이 queue Q0로 들어감
2. cpu를 잡아서 할당시간 8millisconds동안 수행
3. 8 밀리세컨드동안 끝내지 못했으면 queue Q1으로 내려감
4. Q1에 줄서서 기다렸다가 cpu를 잡아서 16ms동안 수행됨
5. 16ms에 끝내지 못했다면, queue Q2로 쫒겨남
특이한 케이스의 CPU 스케쥴링
Multiple-processor Scheduling
cpu가 여러개 있는 경우이다.
각 CPU가 알아서 큐에 한줄로 세워져 있는 프로세스를 꺼내서 수행한다.
반드시 특정 CPU에서 수행되어야 하는 프로세스가 있는 경우에는 복잡하다.
Load Sharing
일부 CPU에 job이 몰리지 않게 적절히 공유하는 메커니즘이 필요하다.
cpu를 놀게하지 마라
SMP-symmetric multiprocessing
각 프로세서가 각자 알아서 스케쥴링을 결정
Asymmetric multiprocessing
하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 이것을 따른다.
원래 OS에서는 싱글 프로세서를 기반으로 설명하므로, 여기서는 Multi-processor에 대한내용은 언급만 하고 넘어감.'
Real-Time Scheduling
정해진 시간에 반드시 실행되어야하는것, DeadLine을 보장
반드시 정해진 시간에 프로세스가 완료되어야하므로, 완료가 보장되는 경우를 고려하여 프로세스 처리 순서를 설정하낟.
Thread Scheduling
Local Scheduling
User level Thread - 사용자 프로세스가 직접 스레드를 관리, 운영체제는 스레드 모름
쓰레드 존재를 모르기 때문에, 그냥 프로세스한테 CPU를 줄건지 말건지만 결정하면됨
그 프로세스 내부에서 어떤 스레드한테 cpu를 줄건지는 Local에서 결정하는것
Global Scheduling
Kernel Level Thread - 운영체제가 쓰레드를 알고 있음
일반 프로세스와 마찬가지로 커널의 단기 스케쥴러가 어떤 스레드를 스케쥴 할지 결정
어떤 알고리즘이 좋은지 평가하는방법
Queueing Models
이론적인 방법이다. 확률 분포로 주어지는 arrival Rate와 Service rate를 통해서 performance index를 계산한다.
Implementation & Mesurement
실제 시스템에다 구현을 하고 실제 작업을 해보고 성능 측정을 비교하는 방식
Simulation 모의실험
모의 프로그램으로 작성한 후에 여러가지 경우를 실험해보고, 어떤 알고리즘이 좋은지 판별하기
