이번시간에는 이전시간에 보았던, cpu,메모리등에서 스케쥴링을 어떤식으로 하는지 배워보는 시간을 가질것이다.
cpu 스케쥴링
어떤 process에 cpu사용권을 줄것인가 이것이 바로 OS의 중요한 관건이다.
FCFS(First-Come First-Served)

만약에 process P1,P2,P3 순서대로 도착했다고하자.
도착한 순서대로 CPU를 이용하므로 제일 먼저 도착한 P1이 24초를 이용한다.
그뒤에 안써도되니까 IO를 하러 이동할것이다.(디스크로 간다던지 키보드로 간다.) 아니면 종료를 해도 좋다.
그 다음 P2가 본인이 원하는 3초를 쓰게 해준다. 나가면 다시 P3한테 주는 그런식이다.
이러면 문제가 효율적이지 않다.
Waitingtime,AVG waiting time을 계산해보면
wating time:P1=0,P2=24,P3=27
AVG wating time: (0+24+27)/3=17
공정하지만 효율적이지 못하다.
SJF(Shortest-Job-First)

이번에는 효율성을 높이기 위해서 누가 먼저 CPU를 짧게 쓰느냐를 기준으로 순서를 정해보자.
그렇다면 제일 시간이 짧은 P3,P2,P1순으로 CPU를 쓸것이다.
근데 이러면 효율성은 좋은데 형평성이 문제다.
짧은 애들만 먼저 큐에 계속 먼저 들어가니까 길게쓰는 놈은 무한정 기다리는 case가 발생한다.=>starvation
Round-Robin
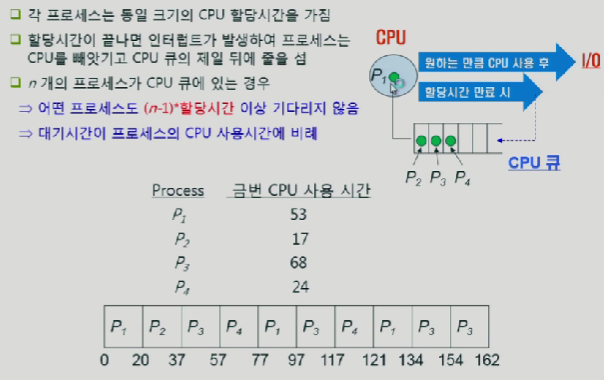
그러므로 효율성과 형평성을 만족시키기위해 이제는 round-robin방식을 이용할 것이다.
한번에 프로세스가 cpu를 쓸 수 있는 시간을 정해두고, 쓰고나서 뒤로가서 또 줄을 서야되는 과정이다.(할당시간이 끝나면 cpu뻇기고 cpu큐 제일 뒤에 줄섬)
이러한 과정을 통해 효율성이 증대되는데, cpu를 짧게 쓰려는 애들은 빨리 후딱 쓰고 IO로 나가면되고, 길게 쓰려는 애들은 쓰고 뺏기고를 계속 반복하면서 수행하면된다.
이렇게되면 만약 큐에 N개의 프로세스가 존재한다면 최대 (N-1)*할당시간 만큼 기다리게 된다.
메모리관리
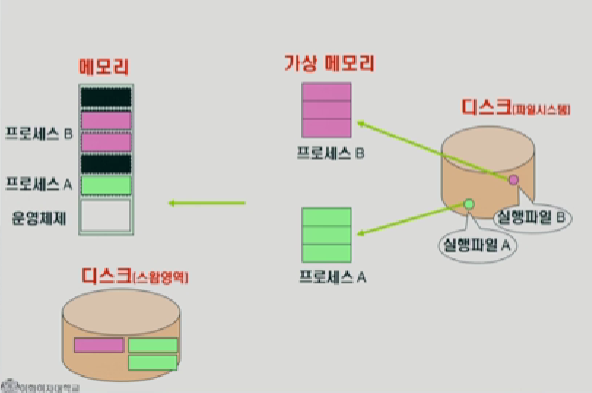
디스크에는 실행file이 있고 메모리는 휘발성이니까 비어있다가 실행파일이 메모리에 올라가게 되면 프로세스가 된다.
사실은 그냥 메모리에 올라가는게 아니고 다른 것이 또 있다.
뭐냐면 가상메모리를 만들어서 0번지부터 프로세스가 메모리를 어떻게 형성하는가 쭉 만들고, 그다음에 메모리에는 당장 필요한 부분만 먼저 올라간다
*이렇게 하는이유는 필요없는 부분까지 다 올려놓으면 효율성이 저하된다.
그래서 메모리가 꽉차면, 나머지 부분들이 스왑영역으로 쫒겨난다.
고로 디스크는 filesystem,스왑영역 두가지가 있다.
메모리에서 쫒겨난 가상메모리에 있는 부분을 스왑영역이라한다.
스왑영역은 메모리의 연장공간이다. 그러므로 디스크는 비휘발성이지만 전원이 꺼지면
프로세스는 전부 날라간다.
그러므로 스왑영역은 살아는 있지만, 의미가 없는공간이 된다.
그러면 관건이 저 가상메모리가 쪼개지는게 page단위인데 어떤걸 넣고 어떤걸 쫒아낼것인가? 이게 관건이다.
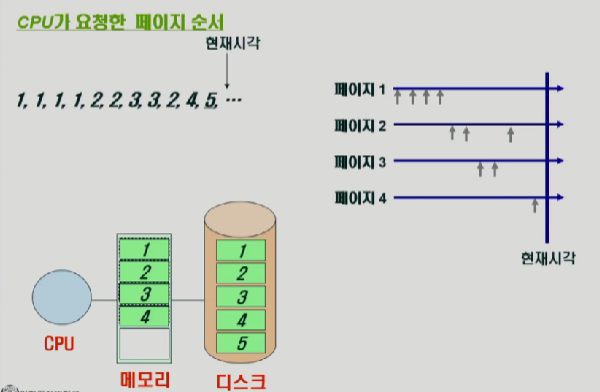
페이지 요청순서가 1,1,1,1,2,,,,이런식으로 왔다고 가정을해보자.
처음에 메모리가 비어있고, 1번 page가 없으므로, os가 디스크 컨트롤러에 요청을해서 메모리에 1번을 올린다.
한버 올라갔으니까, 다음번에 요청할때는 메모리에있는 1번페이지를 가져다 쓴다.
2번 요청되면 동일하게 디스크에서 읽어다가 쓴다.
3,4번 동일하다.
그런데 문제가 있다.
5번에서 읽어오려니까 메모리가 꽉찬다.=>1,2,3,4중에서 한놈은 쫒겨나야한다.
그럼 문제가 뭘 쫒아낼꺼냐?
os는 현재 미래에 어떤 요청이 들어올지 모르는 상황에서 효율성을 높이기 위해서 어떤것이 많이 요청할지 예측을해야된다.
미래를 예측하기 위해서는 과거를 봐야한다.
LRU => 가장 오래전에 참조 페이지 삭제 =>1번이 삭제가된다.
LFU => 참조횟수가 가장 적은 페이지 삭제 =>4번이 삭제가 된다.
디스크 스케쥴링
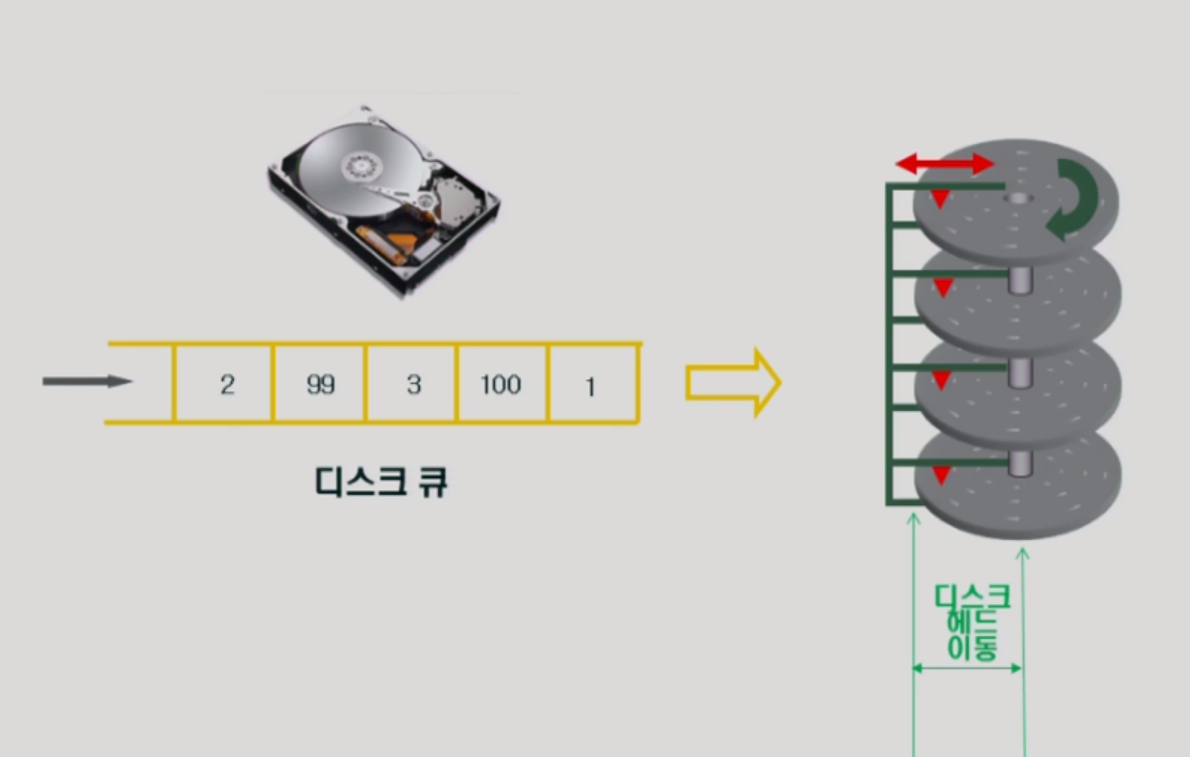
디스크에서 파일을 읽어달라는 요청이 시간마다 들어온다. 그러면 동일하게 디스크 queue에 쌓인다.
디스크는 회전하고 있고, 그림에서 디스크헤드(빨간색 화살표가) 1번부터 100번까지 디스크를 왔다갔다 하면서 읽어야한다.
디스크에서는 요청처리 순서나 read and write가 중요한게 아니고
헤드의 이동을 최대한 줄이면서 요청을 처리하는게 중요하다.
디스크 접근시간은 3가지로 나눌수 있다.
- 탐색시간=>헤드가 움직이는시간
- 회전지연=>헤드가 원하는 섹터에 도달하기까지 걸리는시간
- 전송시간=>data를 전달하는데 걸리는시간.
그렇다면 디스크는 요청처리를 어떻게할까.
FCFS=>요청이 들어온 순서대로한다.
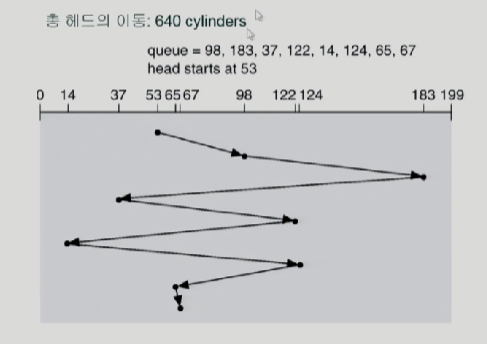
SSTF=>현재 디스크헤드의 위치와 가까운데 부터 요청을 처리한다.
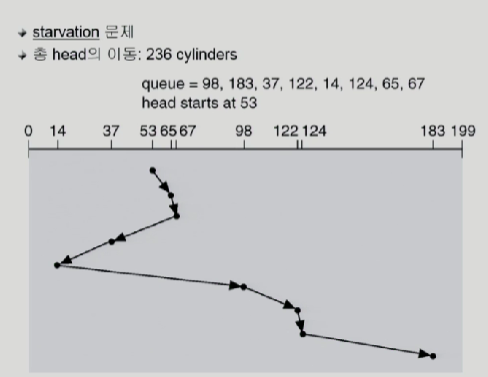
그런데 이것은 starvation문제가 발생할수있다. 왜냐하면 요청은 실시간으로 계속들어오기 때문에 디스크헤드와 가까이 있는 요청이 계속 들어온다면, 멀리있는 요청은 아에 처리가 되지 않을 수 있다.
그래서 이제는 SCAN방식을 쓴다.
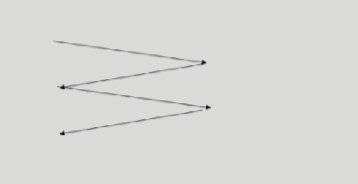
이게 뭐냐면 헤드는 항상 자기가 갈길을 간다. 1번부터 100번까지 쭉 돌면서 방문한다. 그렇게 자기가 갈길을 가다가 요청이 들어온게 있으면 처리하고 지나간다.
원판 끝까지 가면, 다시 반대방향으로 또 자기가 갈길을 가다가 요청이 있으면 처리하고 지나간다.
저장장치 계층구조와 캐싱
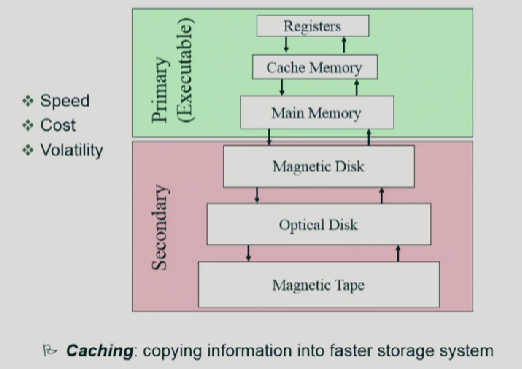
속도: 위로갈수록 빠르고, 아래로 내려올수록 느리다
비용: 위로갈수록 비싸다. 아래로 내려올수록 싸다.
휘발성: 윗단은 휘발, 아랫단은 비휘발 -IO
Caching:속도차이를 완충시키기위한 방법
저장을 하기위해서는 아래로 내리고 내리고 해서 저장을하고, 불러올때는 밑에서부터 올리고 올리고 해야된다.
그런데 이과정이 너무 오래걸리니까, 밑에까지 안내려가고 중간에 저장을하는것이다. 그렇게하면 밑에까지 내려가지 않아도 중간에 만약 요청한게 있다면 가져다 쓰면되는것이다. 만약 없다면, 끝까지 내려가야한다.
플래시 메모리
- 비휘발성
- 전력소모적음
- 작은size
- 물리적 충격적음
- 쓰기 횟수제약
- 전하량에 따라 0,1을 구분하기 때문에 오래지나면 data loss발생
