프로세스-실행중인 프로그램
프로세스 문맥-특정시점을 탁 짤라서, cpu의 상태를 나타내기 위한것,
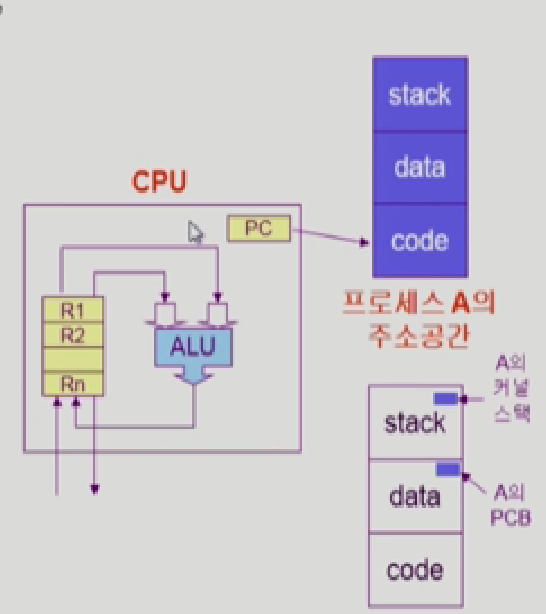
프로세스가 실행되면, 그 프로세스만의 독자 주소공간을 만든다, code,data,stack
그다음, cpu를 잡게 되면 program counter라는 레지스터가 code를 가르키고, 그 code에 해당하는 기계어를 읽어서 register에 불러들이고, 또 산술결과를 처리하고
그 값을 메모리에 저장하거나, 뭐 이런 과정을 거치는데
그렇게 진행하다가, 이 프로세스는 어디까지 와있나? 이걸 규명하기 위해서 프로세스 문맥이 필요하다.
=> program counter가 어디를 가르키냐? process메모리에는 무슨 내용을 담고있는가? stack영역에서 어떤 함수를 호출해서 어디까지 쌓아 두었는가? 등등
문맥은 그래서 3가지로 설명가능하다.
-
하드웨어 문맥: process는 cpu를 잡고 기계어를 실행하는데, 현재 cpu가 어디까지 기계어를 실행하였는가 알기 위한 program counter, 또 각 register에 어떤 값을 가지고있었는가?
-
프로세스 주소공간: code,data,stack 각 프로세스마다 프로세스의 주소공간.
-
프로세스 관련 커널 자료구조, PCB
커널의 주소공간
커널스택-각 프로세스가 자기자신 code를 실행할때, 함수호출이 일어나면 자신의 stack에다가 쌓고, return하고 하는데
중간에 프로세스가 할 수 없는 일을 운영체제한테 부탁할때, systemcall을 갈긴다.
그러면 program counter가 커널 주소공간의 code를 가르키면서 커널의 코드를 실행한다.
근데, 이 커널도 함수로 이루어져 있으므로, 함수를 호출하고 return할때 stack에다가 정보를 쌓아둔다.
그런데 이 부탁을 하나의 프로세스가 아닌 프로세스 A,B,C 다양한 프로세스가 부탁 할 수 있다.
그러므로, 프로세스별로 각각 어떤 프로세스가 호출했는지에 따라 별도로 커널스택을
쌓는다. 그래야 정보가 꼬이지 않는다.
PCB
운영체제가 각 프로세스를 관리하기 위해서 각 프로세스마다 유지하는 정보이다.
PCB에 뭐가 있냐?
- OS가관리하는 정보
process state,processId, scheduling information,priority등등 우리는 queue에서 선입선출마냥 cpu를 쥐어줄것 같지만 사실 우선도에 따라서 쥐어주는데 자세한 내용은 나중에 스케쥴링에서 다룰것이다. - CPU 수행 관련 하드웨어 값
programCounter,registers - 메모리 관련
Code,data,stack의 위치정보 - 파일관련
Open file descriptors..
결국, 그래서 이걸 왜하냐? 결국 프로세스 A를 실행하다가 뻇기고, 다시 실행할때 프로세스 문맥을 저장해놓지 않으면 처음부터 다시 시작해야한다.
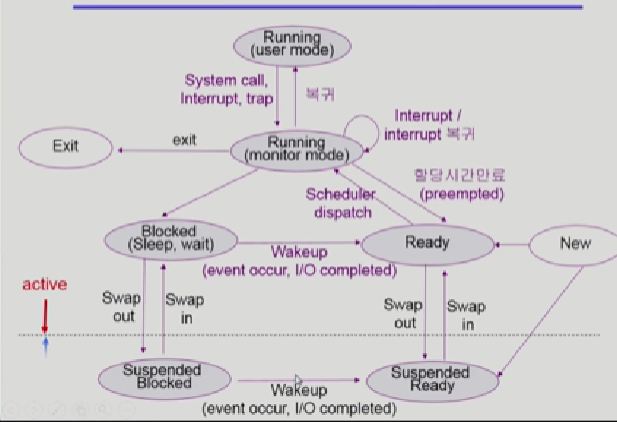
프로세스의 상태
running-cpu를 잡고 기계어를 수행할때
ready-cpu를 기다리는 상태, 당장 cpu를 얻으면 기계어 수행이 가능한 상태, disk에서 file을 읽어오는것을 기다리는 상태 이런게 아니다.
blocked(wait,sleep)-cpu를 주어도 수행이 불가능한 상태, io가 즉시 만족되지 않아. 이를 기다리는 상태 ex). 디스크에서 file을 읽어와야하는경우
new:프로세스가 생성중인 상태
terminated:프로세스가 종료중인 상태
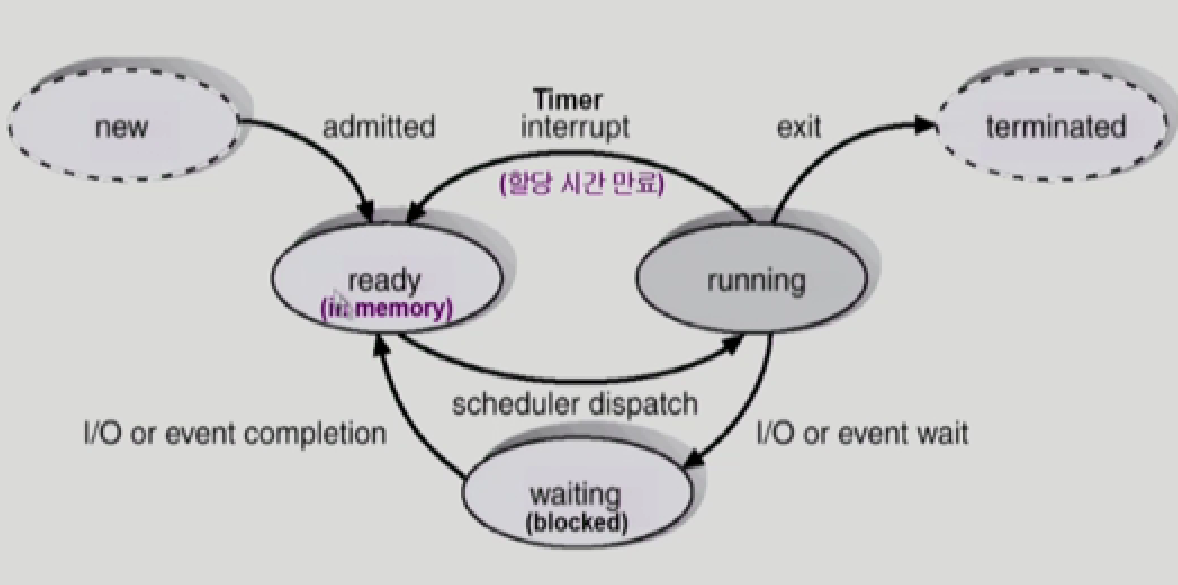
프로세스 상태도
프로세스가 new로 생성되고 ready인 상태
cpu를 얻으면 running
cpu를 내놓는것은 3가지경우
- 자진해서 프로그램이 끝나서 내놓는경우 exit
- IO같은 오래걸리는 작업을 하러 cpu를 내놓는경우
- 더 쓰고싶은데 timer가 종료되는것 timer interrupt
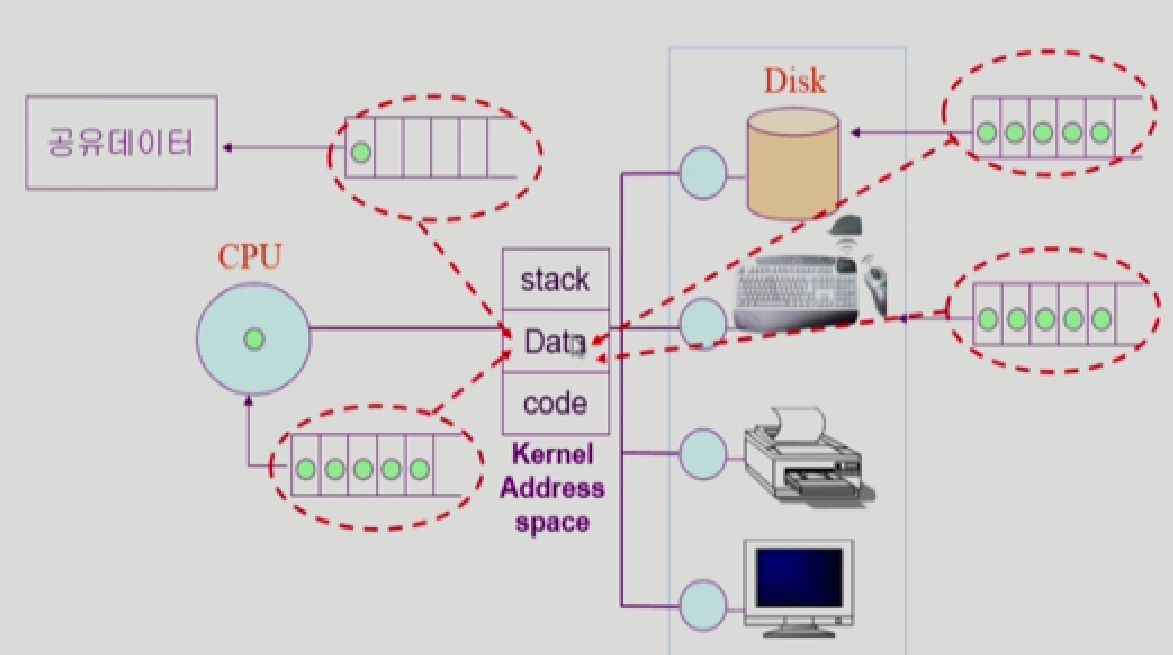
프로세스의 상태
cpu는 하나의 프로세스를 처리할 수 밖에 없다. 요즘은 cpu를 여러개 두어서 처리하는 기술도 있지만, 하나라고 설명하겠다.
하나의 프로세스 연두색 동그라미를 running시키다가,
timer Interrupt가 들어오면 queue의 뒷쪽으로 가서 대기한다.
만약 IO를 해야한다면, disk I/O queue 맨 뒷쪽 줄에 서서 IO작업을 대기하게 된다.
작업이 끝나면 disk Controller가 cpu한테 인터럽트를 걸고
cpu는 프로세슬르 실행하고 있더라도 인터럽트가 들어오면, 하던작업을 멈추고, cpu의 제어권이 운영체제 커널로 이동하게 된다.
그러면 IO를 요청한 해당 프로세스 메모리의 영역에 data를 넘겨주거나, Blocked된 상태를 ready Queue에 넣거나 이런 작업을 한다.
또한 공유데이터도 한 프로세스가 쓰다가 다른 프로세스가 달라고 요청한다고, 같이 동시에 처리하지 않는다. 왜? 값이 꼬일 수 있어서 그래서 하나의 프로세스가 하나의 공유데이터에 접근을 하면, 다른 프로세스는 이 queue에서 기다려야하낟.
그래서 이 queue들은 kernal주소에서 data영역에 자료구조 큐를 만들어 넣고, ready이면 cpu가 처리하게하고 blocked이면 처리를 안하게 하고 이런식으로 구성이 되어있다.
문맥교환
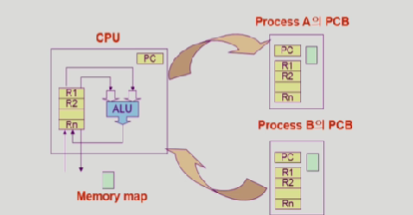
cpu를 뺏겼다가 다시 얻었다고 치자, 그런데 Context를 기억하지 않는다면, 처음부터 다시 프로세스를 실행시켜야 할것이다.
그래서, 만약 processA가 cpu를 쓰고 있으면, ProgramCounter가 어딘가를 가르키고있을테고, register에 어떤 값들이 들어있을것이다.
그다음, 만약 cpu를 빼앗기게 되면, 그냥 이 내용을 싹다 지우는게 아니라,
Program Counter나 Register에 있는 값을 각 Process의 PCB에 save를 해둔다.
그래서 이 PCB가 커널의 주소공간에서 Data영역에 들어가게된다.
만약에 프로세스가 다시 cpu를 얻게 되면, 이 pcb에 있는 정보들을 가지고 복원해서 다시 실행을 시킨다.
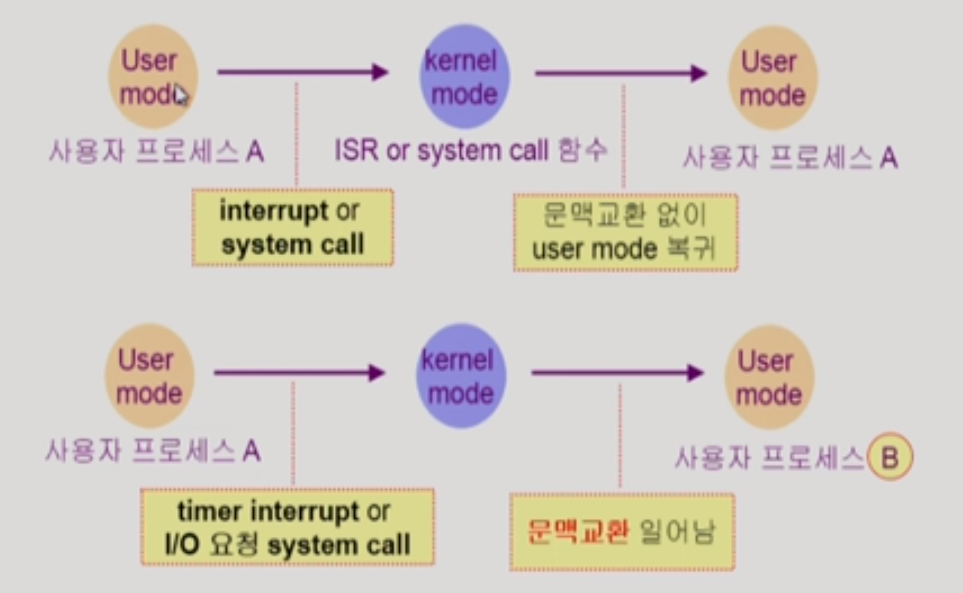
syscall이나 interrupt가 발생한다고 항상 문맥교환이 일어나진 않는다.
여기 사진에서 위에것은 syscall을 하고, 자신의 process로 돌아온다.
그러므로, processA에서 운영체제로 cpu가 넘어가게 되고, 그다음 자신의 프로세스로 돌아오면 이것은 문맥교환이 아니다.
하지만, timerInterrupt나 syscall,interrupt등이 일어난 뒤에 자신의 프로세스가 아니라 다른 프로세스로 cpu가 넘어간다면, 이게 문맥 교환이다.
프로세스를 스케쥴링 하기 위한 큐
- Job Queue => 현재 시스템에 있는 모든 프로세스의 집합
- Ready Queue => 메모리내에서 cpu를 잡아서 실행되기를 기다리는 프로세스 집합
- Device Queue => I/O device의 처리를 기다리는 프로세스의 집합
Reday Queue, Device Queue는 JobQueue에 포함 근데 Ready Queue에 있으면 DeviceQueue에는 안들어있고, Device Queue에 있으면 Reday Queue에는 없고 이런식이다.
스케쥴러
-
CPU 스케쥴러
어떤 프로세스를 다음번에 running시킬지 결정 -
JobSchedular
일단 이 로직은 이제 쓰이지 않는다.
이 스케쥴러는 프로세스가 시작이 될때, new가 되고 ready상태로 넘어오는 과정에서 메모리에 올라가는것을 admitted해주는 스케쥴러이다.
프로세스가 new가 되고 메모리를 얻지 못한다면, 아무것도 할 수 없을 것이다.
그래서 메모리에 올라가는 것을 허가받으면 이제 ready상태가 되는것이다.
어떤 프로세스가 new상태에 있는데 메모리를 줄지 말지 결정하는게 이제 Long-termScheduler이다.
이말은 degree of Multiprogramming을 제어한다는것이다.
메모리에 얼만틈의 프로세스를 올릴지 제어하는것인데
만약 프로세스 10개한테 전부 메모리를 주면 degree of Multiprogramming이 10이고,
프로세스중에서 만약 5개만 메모리르 주면 degree of Multiprogramming이 5인것이다.
근데 실제 시스템은 이렇지않다. 어떤건 메모리에 올리고 어떤건 메모리에 안올리고, 이런식으로 동작하지않고,
모든 프로세스가 new되면 일단 메모리에 곧바로 올려놓는다. -
중기 스케쥴러 Swapper
아까 2번의 단점을 해결하기 위한것이 중기 스케쥴러이다.
프로세스를 무조건 메모리에 올려놓으면, 또 너무 많은 프로세스가 메모리를 차지하면 성능이 저하가 된다.
그러므로, 너무 많은 프로세스가 올라오면, 여유공간 마련을 위해 프로세스를 통채로 메모리에서 디스크로 쫒아낸다.
이것 역시 degree of Multiprogramming을 제어한다.
그래서 만약 메모리를 뺏겼다 치자.
그러면 앞에서 프로세스의 상태는 running,ready,blocked 3가지라 했는데
그 어떠한 것도 포함이 되지 않는다.
그래서 Suspended(slopped) 상태가 추가가 된다.
CPU 뿐만아니라 외부에서 강제로 프로세스를 정지 시켜놓은 상태이다.
그러면 프로세스는 통채로 디스크에 swap Out된다.
그래서 이 blocked와 suspended를 잘 구분해야하는데
blocked는 자기가 요청한 I/O event를 스스로 기다리면서, event가 완료되면,
ready상태로 변하는것이고,
suspended는 외부에서 프로세스를 정지시켜서, 외부에서 resume해줘야 Active상태로 변하는것이다.
참고)
만약에 userMode로 running을 하다가 systemcall로 cpu가 운영체제로 넘어간다 치자. 그러면 운영체제가 커널의 code를 실행하더라도, 이건 운영체제가 running된다 라고 표현하지 않고, processA가 커널모드로 running중이다 라고 한다.
interrupt이 걸리면, 외부의 다른 요인에 의해서 정지 될때가 있다. 심지어 앞처럼
자기가 syscall을 갈긴것도 아닌데, 그래도 이것도 processA가 여전히 running하고 있다고 친다.
blocked상태,ready상태에서 syspended되었는지 구분되어있다.
하지만 둘다 inactive한 상태인것은맞다.
그러나, SuspendedBlocked상태이더라도 만약 I/O가 완료되었다면, CPU를 얻어서 무언가 작업을 할 수 는 없더라도 그래도 Suspended Ready상태로 이동하긴한다.
Thread
쓰레드를 공부하기 전에 잠깐, 동기와 비동기를 생각하고 넘어가자
이전에도 했지만,
동기=>프로세스가 입출력 요청을 하고 입출력 요청 결과를 받을 때까지 기다려야하는게 동기
비동기 => 프로세스가 입출력 요청을 하였지만 기다리지 않고 바로 CPU를 잡아서 기계어를 수행하면 비동기
Thread
프로세스내에서 실행되는 흐름 중 하나이다. 뒤에서 조금 풀어서 설명하겠다.
-
구성
program counter
register set
stack space -
Thread가 동료 Thread와 공유하는 부분(task)
code section
data section
OS resources
하나의 프로세스안에 쓰레드가 여러개 있으면 Task는 하나있다.(각 쓰레드끼리 공유해서 쓰니까)
쓰레드를 쓰면 좋은점이 4가지가 있는데 먼저 풀어서 설명하겠다.
일단 멀티 쓰레드가 좋은점이 하나의 쓰레드가 blocked되어도 동일한 task의 다른 쓰레드가 실행되어서 빠른 응답이 가능하다.
예를들어, 웹브라우저에 웹페이지를 읽어야한다고 치자.
이것 또한 당연히 IO 작업에 해당한다.
그래서 웹페이지를 읽어오는 과정은 매우 오래걸리고, 불러오는 과정에서 Blocked 상태가 될것이다.
그래서 만약 동기식이라면 아무것도 못하고 빈화면만 보여줄 것이다.
그러면 사용자는 매우 불편할 것이다.
그런데 만약 웹브라우저를 여러개의 쓰레드를 사용해서 프로세스를 구현하면,
rest api방식으로 url쳐서 get을 하면,
먼저 웹페이지 html을 가져와야할것이다. 여기에는 사진도 있을 수 있고, 글도 있을 수 있고 여러가지 가져와야 할것이 많다.
하지만, 만약 html file과 사진, 글 전부 한꺼번에 들고오려면, 이 웹페이지를 가져오는동안 blocked상태가 될것이고, user는 빈 화면만 보고 있을 것이다.
그래서 프로세스는=> 웹페이지를 불러오는것이고,
이 프로세스안에 html file을 가져오는 쓰레드, 이미지를 가져오는 쓰레드, 뭐 글을 가져오는 쓰레드 이런식으로 나누어서 프로세스를 구성하게 한다면,
만약 이미지를 가져오는 IO 작업이 너무 오래걸리더라도, blocked상태로 전환하는게 아니라, 다른 쓰레드가 가져온 html file이라던지 뭐 Text라도 먼저 보여주는 형식으로 하면, user 입장에서는 조금 더 빠른 결과를 얻을 수 있어서 좋다.
또, 자원 절약도 된다.
동일한 일을 수행하는데 별도의 프로세스로 만들어 놓으면, 메모리나 자원의 낭비가 된다.
예를들어, 웹브라우저를 여러개 띄우거나, MSoffice를 여러개 띄우는걸 각각 다른 프로세스로 만들어 놓는다면, 각각의 프로세스마다 주소공간을 만들게 되고 각 프로세스마다 code data stack의 메모리를 사용하므로, 낭비가 된다.
고로 하나의 프로세스안에 쓰레드만 여러개 두면, 자원 절약이 된다.
프로세스마다 하나의 PCB가 만들어 져서 운영체제가 관리 한다 했는데,
프로세스 하나당 쓰레드가 여러개 있게 되면, CPU 수행과 관련되 정보만 각각 쓰레드 마다 별도의 카피를 가지게 된다.
이것이 program Counter나 registers에 해당한다.
생각해보면 당연한게 각각 다른 code를 수행하고 그 수행한 값이 register에 담겨있으니 별도로 가지고 있는게 맞다.
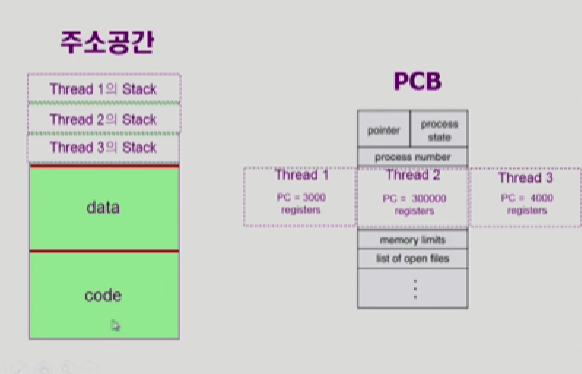
그래서 여기 사진을 보면
쓰레드는 프로세스 안에서 독자적으로 가져야하는 정보만 별도로 가지고 있다.
PCB에서는 program counter, register를 독자적으로 가지고
주소공간에서는 code와 data를 공유하고 stack영역만 독자적으로 가지고있다.
쓰레드 장점 4가지
-
응답성 => 웹브라우저 주소를 치면, html 문서가 날아오는데 그 문서안에 임베드 되야할 웹브라우저가 있다.
근데 여기에는 이미지,text,동영상등을 포함해서 보여주는데 이걸 한꺼번에 들고오려면, blocked되어서 user가 답답해 하니까
결국 html file을 받고 그 다음 거기에 필요한 이미지, text를 다시 요청하게 한다.
원래는 그럼 웹을 가져오는 그 프로세스가 blocked되는데, 쓰레드를 여러개로 두면 이제 이미지를 가져오는 동안이라도 html file이라던지 text를 보여주면 되니까
답답함이 덜하다.
즉 아까 위에서 설명했던 비동기로 설명해보자면, 이미지 file을 읽어오는 IO작업을 하는 과정에서 이 프로세스를 동기마냥 blocked시키는게아니고,
IO가 끝나기전에 CPU를 얻어서 화면에다가 html text라도 먼저 보여주는것이 좋다. -
자원공유
똑같은 일을 하는 프로그램이 여러개 있는데 하나의 프로세스를 만들고 그 안에 CPU수행단위만 여러개 만들면, 자원을 효율적으로 쓸 수 있다. -
경제성
프로세스를 하나 만드는것과 프로세스에서 다른 프로세스로 넘어가는건 매우 자원소비가 크다.
그런데, 프로세스를 하나 만들고 그 위에 쓰레드를 얹는건 비용이 더 적다. 또한 쓰레드간 CPU switch도 동일한 공간 이기 때문에 그대로 사용이 가능하다. -
MP
CPU가 여러개 일때 얻을 수 있는 장점인건데, 프로세스는 1개지만 쓰레드가 여러개 있는 상태에서 CPU가 여러개면 병렬적으로 수행이 가능하다.
쓰레드의 종류
커널 쓰레드 -> 쓰레드가 여러개 있다는 사실을 운영체제 커널이 알고 있다. 하나의 쓰레드에서 다른 쓰레드로 넘어갈때 CPU 스케쥴링 하듯이 넘겨준다.
USER 쓰레드 => 프로세스안에 쓰레드가 여러개 있다는걸 운영체제는 모르고, 라이브러리의 지원을 받아서 관리한다.
그래서 운영체제는 쓰레드가 여러개 있는지를 모르고, 프로세스 내부에서 CPU수행단위를 여러개 두고 이용하므로, 여러 제약들이 있다.
