- 23,1
- 281회 인용
- http://openaccess.thecvf.com/content/CVPR2023/papers/Li_GLIGEN_Open-Set_Grounded_Text-to-Image_Generation_CVPR_2023_paper.pdf
- https://github.com/gligen/GLIGEN
- 2100 stars
-1. 바쁘신 분들을 위한 3줄 요약
- GLIGEN의 github 코드는, 별도의 python package를 많이 사용하지 않고 Diffusion model을 직접 가독성있게 구현하여, diffusion 코드 파악에 용이하다고 알려져 있음
- internet-scale로 학습된 기존 text-to-diffusion model에(frozen weight), grounding 정보(예: 각 객체가 어디에 위치할지 지정) 를 추가 input으로 받아 fine-tuning하여, 좀 더 controllable 한 이미지 생성을 가능하게 했음
- 자율주행 realistic agent 시뮬레이션을 좀 더 controlable하게 생성하는데에 도움이 될 수도 있어보임
0. Abstract

- GLIGEN: Grounded Language to Image GENaration
- 위 그림에서
- 기존 연구들은
주황색 text caption만 조건부 입력으로 받아 image를 생성했었는데,- (객체의 정확한 위치 정보나 추가적인 조건을 제어하기 어렵습니다.)
- 본 논문에서는 초록색(회색+하늘색) Grounding information을 추가적인 input으로 주고, 이미지들이 grounding information에 맞게끔 생성되도록 학습시킴으로써
- 원하는 layout에 맞게 이미지를 생성할 수 있게 되었습니다. (훨씬 더 contrallablity가 높아졌습니다.)
- 회색: semantic information of grounding entity
- 예: text / example image
- 하늘색: grounding spatial configuration
- 예: bounding box, keypoints, edge map, depth map, semantic map 등
- 기 학습된 text-to-image diffusion models를 가지고 와서 해당 weight는 고정하고, grouding inputs에 조건화 될 수 있도록 추가 네트워크 레이어 (Gated Self-Attention)을 도입하여 그 부분만 추가로 학습시킵니다.
- 기존 연구들은
1. Introduction
- 모델은 bounding box와 같은 입력 조건을 기반으로 훈련되지 않은 새로운 개념까지 일반화할 수 있음을 보여줍니다. (
일반화 성능/zero-shot 성능good)- 예를 들어, COCO 데이터셋으로만 grounding model을 훈련했음에도, LVIS 데이터셋의 객체들에 대해 강력한 grounding zero-shot 성능을 보였습니다.
2. Related Work
정리
- GLIGEN은 기존 방법들(Autoregressive [46, 67], Layout2Image [71, 55, 34])과 달리,
새로운 개념과 조건에 대해 더 높은 일반화 성능과 유연성을 제공합니다.
핵심 요약
-
대규모 텍스트-투-이미지 생성 모델
- 최신 텍스트-투-이미지 생성 모델은 Autoregressive 모델과 Diffusion 모델로 나뉩니다.
- Autoregressive 모델:
- DALL-E [46]: 제로샷(Zero-Shot) 생성 능력을 보여준 초기 혁신적인 모델.
- Parti [67]: Autoregressive 모델을 확장 가능하게 설계한 사례. (내 논문 리스트엔 포함 X)
- Diffusion 모델:
- DALL-E 2 [45]: CLIP [44] 이미지 공간을 활용해 이미지 생성.
- Imagen [50]: 사전 학습된 언어 모델을 활용해 성능을 극대화.
- Muse [6]: 마스킹 모델링 방식을 도입해 SoTA 수준의 성능과 빠른 추론 속도 달성. (내 논문 리스트 포함 X)
- Autoregressive 모델:
- 하지만 대부분의 모델이 텍스트 입력만 사용하기 때문에, 객체의 정확한 위치 정보나 추가적인 조건을 제어하기 어렵습니다.
- Make-A-Scene [12]: Semantic Map을 활용했으나 폐쇄형 클래스(closed-set)(158개 카테고리)만 지원. (내 논문 리스트 포함 X)
- eDiff-I [3]: Attention Map 조정으로 조건부 생성이 가능하나, GLIGEN처럼 간단하거나 확장 가능하지 않음. 내 논문 (리스트 포함 X)
- 최신 텍스트-투-이미지 생성 모델은 Autoregressive 모델과 Diffusion 모델로 나뉩니다.
-
레이아웃 정보를 활용한 이미지 생성
- Bounding Box와 객체 카테고리로 이미지를 생성하는 작업은 Layout2Image로 불리며, 이는 객체 탐지의 역작업이라 볼 수 있습니다.
- 기존 연구의 문제점: 대부분의 기존 방법은 폐쇄형 클래스(closed-set)(예: COCO의 80개 카테고리)만 지원해 일반화가 어렵습니다.
-
GLIGEN과의 차별점
- GLIGEN은 오픈셋(Open-Set) Grounded Image Generation을 목표로 합니다.
- 기존 방법과 달리 bounding box 외에도 keypoints, edge map 등 다양한 조건을 활용 가능.
- ReCo [66]와 비교:
- ReCo도 오픈셋 능력을 보이지만, 기존 Stable Diffusion 모델 [47]의 가중치를 fine-tuning해 지식 손실(knowledge forgetting)의 위험이 있음.
- 반면 GLIGEN은 기존 가중치를 frozen하고, 새로운 조건부 입력을 점진적으로 통합하여 성능 저하를 방지.
- GLIGEN은 오픈셋(Open-Set) Grounded Image Generation을 목표로 합니다.
4. Open-set Grounded Image Generation
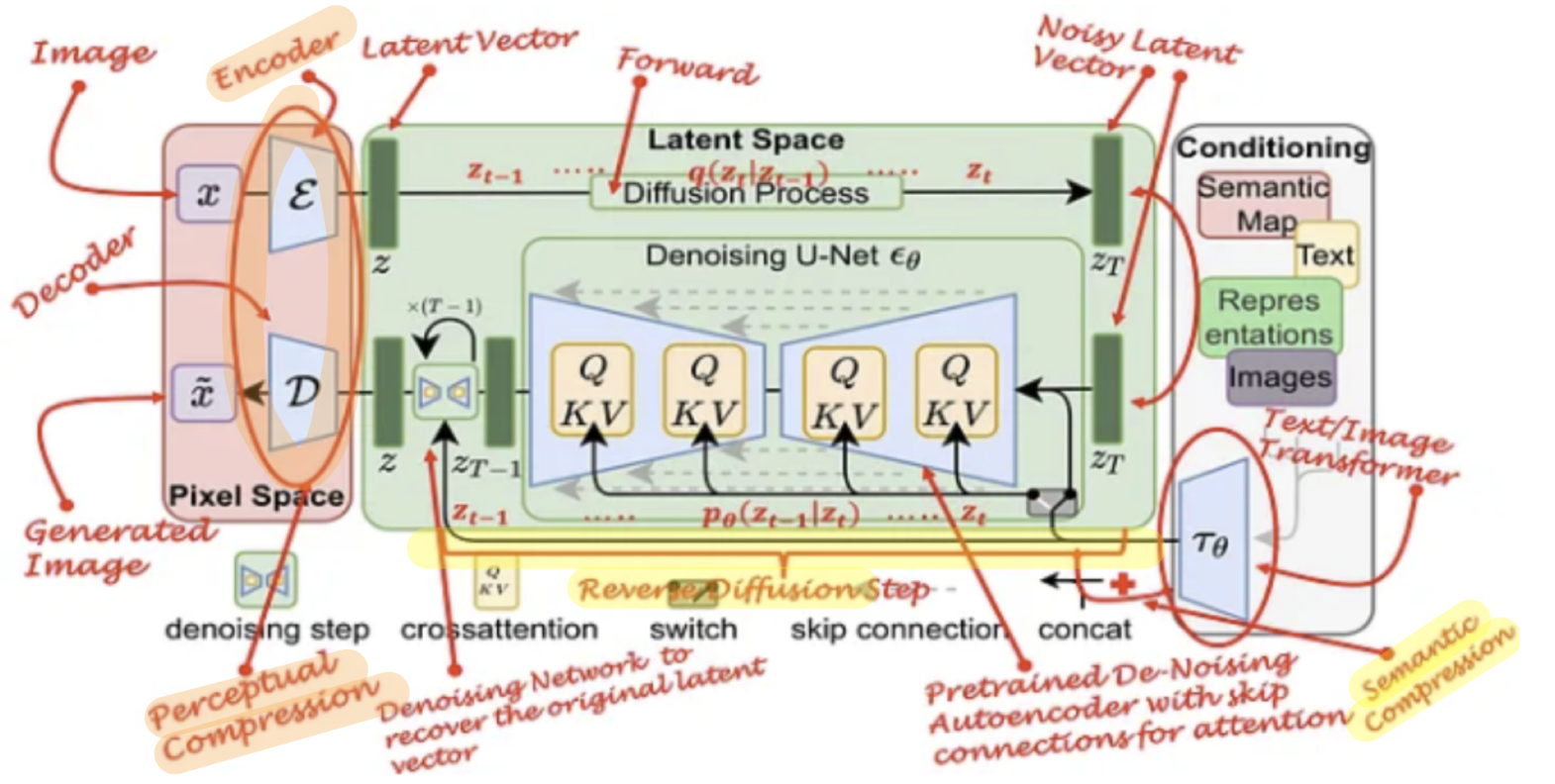
- original LDM
- 위 그림은 기본적 Latent Diffusion Model의 구조
- Stable Diffusion 논문에서는 text caption을 encode하기 위해 fixed CLIP을 사용하였습니다.
- UNet
- Series of
ResNetandTransformer blocks
- Series of
- 또한, CLIP처럼 Internet-scale text-image data를 활용해서 LDM을 pretraining 시킴으로써,
- language-to-image 생성 성능을 높였습니다.
- 아래의 그림은 해당 논문에서 제시하는 Unet 내
Transformer blocks의 구조입니다. 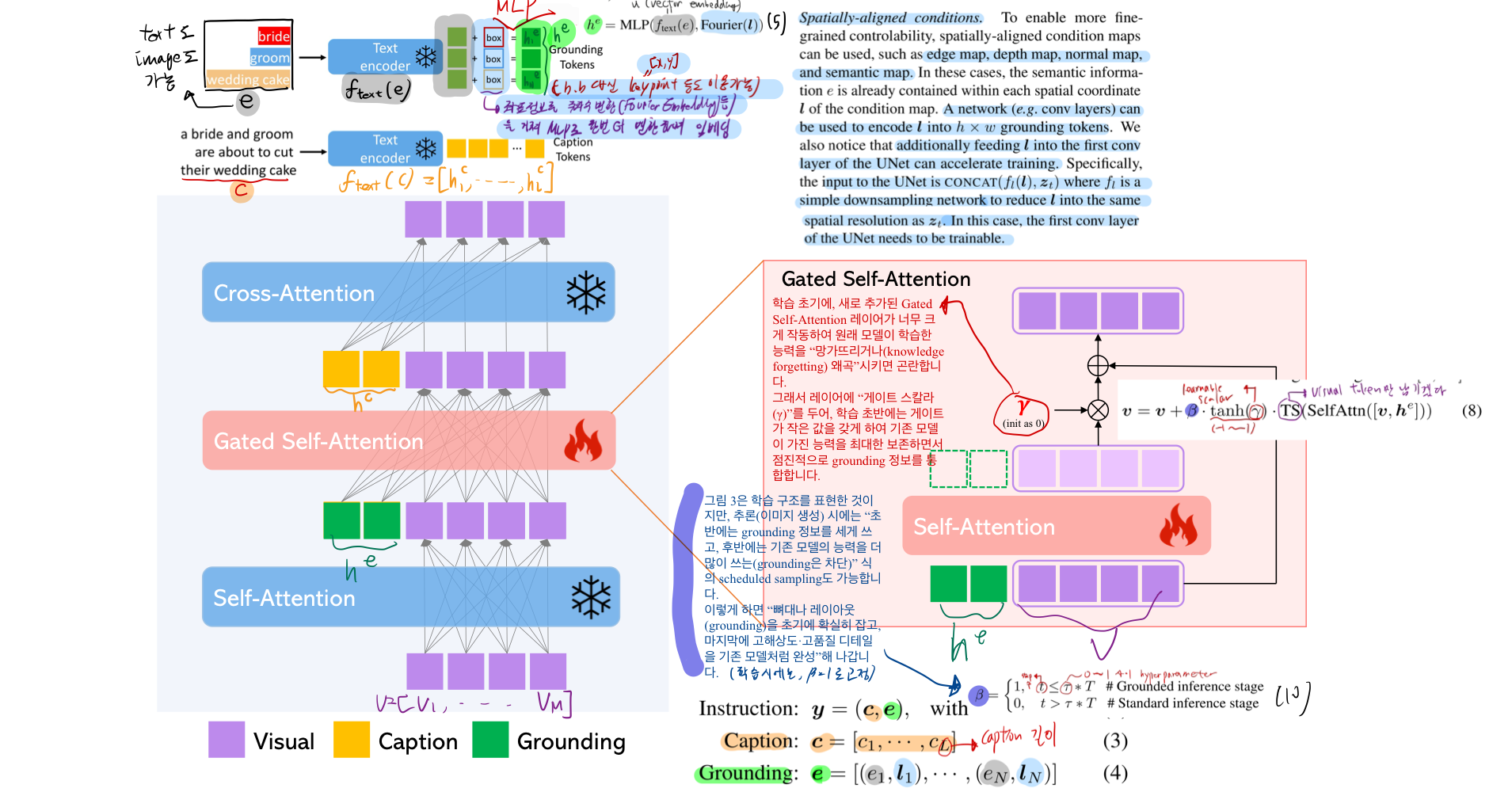
4.1. Grounding Instruction Input
- 위 그림에서, Caption을 encoding 할때 쓰였던 text encoder을
- Grounding Semantic text 를 encoding할 떄 그대로 가져다 씁니다.
- 위 그림에서 변형하여, 만약 내가
grounding spatial configuration (l, 하늘색)을 edge/depth/normal/semantic map 으로 주고 싶으면,semantic information (e, 회색)이 이미,grounding spatial configuration(l, 하늘색)에 포함되어 있는 것입니다.- edge/depth/normal/semantic map 을 Conv layer 등으로
h*w개의 grounding token으로 변형한 후 이를 Gated Network에 input으로 주입합니다. - 추가적으로 학습을 가속화 시키기 위해, UNet의 first conv layer에 을 concat하여 input으로 넣습니다.
- 은 간단한 downsampling network 입니다. (z_t 와 공간적 해상도를 맞추기 위함)
From closed-set to Open-set
과거 연구들: 비매개적(non-parametric) 임베딩이란?
비매개적 임베딩은 각 개체(entity)나 클래스(class)에 대해 고정된 벡터 임베딩을 미리 학습하고 저장하는 방식입니다.
- 예를 들어, K개의 개체가 있다고 가정해봅시다.
- 각 개체는
u1, u2, ..., uK라는 고정된 벡터로 학습됩니다. - 이 벡터들은 임베딩 사전(dictionary)에 저장되어, 필요할 때 모델이 해당 사전에서 벡터를 "조회(look-up)"하여 사용합니다.
- 각 개체는
- K개의 클래스에 대해 미리 학습된 임베딩 벡터들(U)은 다음과 같은 형태로 저장됩니다:
- 따라서, 각 개체를 하나의 고정된 벡터로 간단히 표현하는 방식입니다.
과거 연구들: 폐쇄형 클래스(closed-set)란?
- 폐쇄형 클래스(closed-set)에서는 모델이 훈련 데이터에서 본 적 있는 클래스/개체들만을 생성할 수 있습니다.
- 즉, 모델은 "학습 단계에서 본 K개의 개체"에 대한 임베딩 사전을 생성하고, 이 사전 내의 개체들만 다룰 수 있습니다.
- 예: COCO 데이터셋에 80개의 객체 클래스(예: 고양이, 개, 자동차 등)가 있다면, 모델은 이 80개 클래스에 대해서만 학습하고 생성할 수 있습니다.
비매개적 임베딩의 두 가지 주요 한계
(1) 새로운 개체에 대한 일반화 부족
- 비매개적 방식은 사전에 저장된 임베딩 벡터만 사용하기 때문에, 훈련 데이터에 없는 새로운 개체를 다룰 수 없습니다.
- 예: "코끼리"라는 개체가 사전에 없으면, 모델은 "코끼리"라는 단어를 이해하거나 이를 생성할 수 없습니다.
(2) 언어적 의미 구조의 결여
- 기존의 비매개적 방식에서는 개체(entity)를 단순히 고정된 벡터 임베딩(e.g.,
u_i)으로 대체하기 때문에, 텍스트 정보(단어/문구)가 모델에 전달되지 않습니다.- 즉, 개체 간의 의미적 연관성이나 텍스트 구조를 모델이 학습할 수 없습니다.
- 예: "큰 코끼리"와 "작은 코끼리" 같은 문구가 주어진다면, 모델은 "코끼리"라는 단어만을 벡터로 처리할 뿐, "큰"이나 "작은"이라는 수식어와의 관계를 반영하지 못합니다.
4. GLIGEN의 해결책
GLIGEN은 비매개적 방식의 한계를 극복하기 위해 text caption을 임베딩 하기 위해 사용했던 텍스트 인코더를, grounding noun entity 임베딩에 재사용하여, 개체를 단순한 벡터가 아닌 의미 기반 텍스트 임베딩으로 표현합니다:
1. 텍스트 기반 표현:
- "개체 이름(예: 코끼리)"를 텍스트 인코더에 입력하여, 텍스트 임베딩(
ftext(e))으로 변환합니다. - 이 텍스트 임베딩은 모델이 "언어적 의미 구조"를 보존하고 새로운 개념에도 적응할 수 있게 합니다.
- 오픈셋 이미지 생성 가능:
- GLIGEN은 폐쇄형 클래스(closed-set) 방식이 아닌 오픈셋(open-set) 방식을 채택하여, 새로운 개념(훈련 데이터에 없는 개체)에도 일반화할 수 있습니다.
- 예: COCO 데이터로만 훈련했어도 LVIS 데이터의 새로운 개체들을 생성 가능.

ad_official