diffusion
1.DDPM : Denoising Diffusion Probabilistic Models

1. diffusion 큰그림 먼저보자. 위 그림에서 forward process는 우리가 규칙으로 정한겁니다. T는 guassian noise 이미지($X_T$)로 만들기 위해 노이즈를 주는 총 단계의 수 입니다. (hyperparameter) noise를
2.Improved Denoising Diffusion Probabilistic Models

0. 들어가기 전에 원 논문: https://arxiv.org/pdf/2102.09672 github: https://github.com/openai/improved-diffusion 1. 뭐하는 논문? DDPM은 높은 FID와 IS 점수를 기록했지만 높은 log-
3.[1203] Diffusion 공부 순서
https://arxiv.org/pdf/2011.134565240https://proceedings.neurips.cc/paper_files/paper/2021/file/49ad23d1ec9fa4bd8d77d02681df5cfa-Paper.pdf665
4.[21.5] Diffusion Models Beat GANs on Image Synthesis

unconditional image synthesis 에서, 일련의 연구를 통해 더 나은 아키텍처를 찾은 diffusion models이 현재의 최첨단 생성 모델보다 뛰어난 이미지 샘플 품질을 달성할 수 있음을 보여줍니다. conditional image synthes
5.[21.12] Stable Diffusion : High-Resolution Image Synthesis with Latent Diffusion Models
고해상도 이미지 합성을 위한 Latent 확산 모델 https://github.com/CompVis/latent-diffusion 0. 초록 기존 연구들은, 이미지 형성 과정을 -> 노이즈 제거 오토인코더의 순차적 적용으로 분해함으로써, 확산 모델(Diffusi
6.[21.2] DALL-E : Zero-Shot Text-to-Image Generation
https://arxiv.org/pdf/2102.12092 2021, 2 5300 회 인용 요약(Abstract) 텍스트-이미지 생성은 전통적으로 고정된 데이터셋에서 훈련하기 위한 더 나은 모델링 가정을 찾는 데 초점이 맞춰져 왔습니다. 이러한 가정은 복잡한 아키텍처, 보조 손실, 혹은 훈련 중 제공되는 객체 부분 레이블이나 세그멘테이션 마스크와 같은...
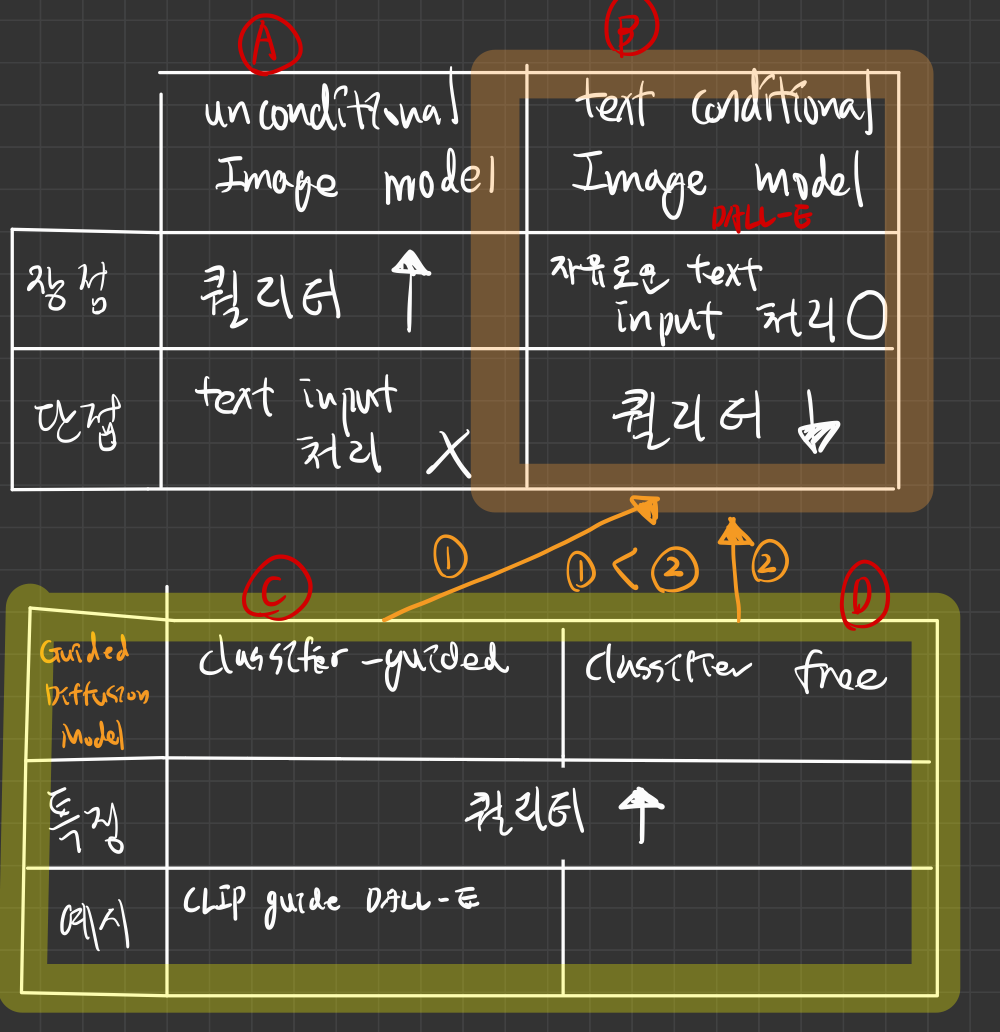
7.[21.11] CLASSIFIER-FREE DIFFUSION GUIDANCE
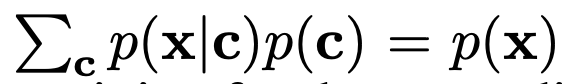
https://arxiv.org/pdf/2207.12598
8.[21.12] GLIDE
https://arxiv.org/pdf/2112.10741GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models확산 모델은 다양성과 품질 간의 균형을
9.[22.4] DALL-E 2: Hierarchical Text-Conditional Image Generation with CLIP Latents

Hierarchical Text-Conditional Image Generation with CLIP Latents https://3dvar.com/Ramesh2022Hierarchical.pdfCLIP: https://velog.io/@hsbc/C
10.[Diffusion][23,1] GLIGEN: Open-Set Grounded Text-to-Image Generation
23,1281회 인용http://openaccess.thecvf.com/content/CVPR2023/papers/Li_GLIGEN_Open-Set_Grounded_Text-to-Image_Generation_CVPR_2023_paper.pdfhttps
11.Diffusion 은 왜 Unet을 좋아해?
1. U-net의 장단점 1. U-Net의 주요 구조적 특징 엔코더-디코더 구조 엔코더(Contracting path): Convolution과 풀링(Pooling)을 거치며 점차적으로 공간적 크기를 줄이면서, 이미지에서 추상적 특징을 추출한다. 디코더(E
12.Inductive Moment Matching
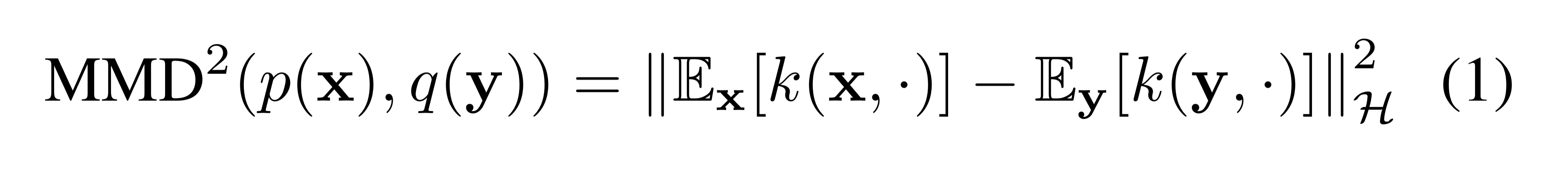
Abstract 기존 연구에서는 추론 속도를 높이기 위해 두 가지 방법을 사용했습니다. 첫번째 방법: Distillation 목표: 원래 수백 단계의 생성 과정을 몇 단계(few-step)로 압축합니다. 문제점: 한 번에 큰 비선형 변화를 예측해야