[21.12] Stable Diffusion : High-Resolution Image Synthesis with Latent Diffusion Models
diffusion
목록 보기
5/12
- 고해상도 이미지 합성을 위한 Latent 확산 모델
- 논문: https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
- https://openaccess.thecvf.com/content/CVPR2022/supplemental/Rombach_High-Resolution_Image_Synthesis_CVPR_2022_supplemental.pdf
- 2021, 12
- 15000 회 인용
- https://github.com/CompVis/latent-diffusion
- 12000 stars
-1. 바쁘신 분들을 위한 3줄 요약
- latent space 압축을 위한 autoencoder 학습과, latent space에서의 diffusion model 학습을 분리하여 따로 진행하니 ->
복잡성 감소와 세부 정보 보존 간의 거의 최적화된 지점에서 DM을 학습할 수 있어서 -> 성능과 계산 효율성을 모두 잡았습니다. - latent space 압축에는 Perceptual Image Compression module을 percetual loss (102) 와 patch-based adversarial objective(20, 23, 99) 를 이용해서 학습하였습니다. (본문에 설명 나옴)
- latent diffusion model에는
임의의 modalities를 지원하는 conditional guidance를 위해, Unet의 각 layer에 cross-attention의 K,V 값에 대응하는 conditional feature representaiton을 생성할 수 있는 구조를 제안하였습니다. (classifier-free guidance 논문의 학습 방식대로, 조건부/비조건부를 모두 학습 가능)
0. 초록
- 기존 연구들은, 이미지 형성 과정을 ->
노이즈 제거 오토인코더의 순차적 적용으로 분해함으로써,- 확산 모델(Diffusion Models, DMs)은 좋은 합성 결과를 달성
- 또한, 이들의 방법은 재학습 없이
이미지 생성 과정을 제어할 수 있는 가이드 메커니즘을 허용
- 그러나 이러한 모델은
일반적으로 픽셀 공간에서 직접 작동하므로 학습에 연산량이 많이 들고, 순차적 평가로 인해 inference 비용이 비쌉니다.
- 제한된 계산 자원에서 DM 훈련을 가능하게 하면서 품질과 유연성을 유지하기 위해, 우리는 강력한
pre-trained 오토인코더의 latent 공간에서 이를 적용 - latent 표현에서 확산 모델을 훈련하면,
- 처음으로
복잡성 감소와 세부 정보 보존 간의 거의 최적화된 지점에 도달할 수 있으며, - visual fidelity(충실도)가 크게 향상됩니다.
- visual fidelity
- 세부 정보의 보존: 이미지의 미세한 디테일(텍스처, 색상, 구조 등)이 얼마나 잘 유지되었는지
- 자연스러움: 생성된 이미지가 사람이 실제로 볼 수 있는 자연스러운 사진처럼 보이는지
- 정확성: 복원 작업의 경우, 복원된 이미지가 원본과 얼마나 일치하는지를 평가
- visual fidelity
- 처음으로
- 모델 아키텍처에 cross-attention layers를 도입함으로써,
- 우리는 확산 모델을
텍스트나 바운딩 박스와 같은 일반적인 조건 입력을 위한 강력하고 유연한 생성기로 전환했으며, - 컨볼루션 방식으로 고해상도 합성이 가능하게 했습니다.
- 우리는 확산 모델을
- 우리의 Latent Diffusion Models(LDMs)은 픽셀 기반 DM과 비교하여 계산 요구 사항을 크게 줄였습니다.
과도한 다운샘플링 없이도적절한 오토인코더 모델을 사용하면- 데이터 차원을 줄이면서도 고품질의 이미지를 생성할 수 있습니다.
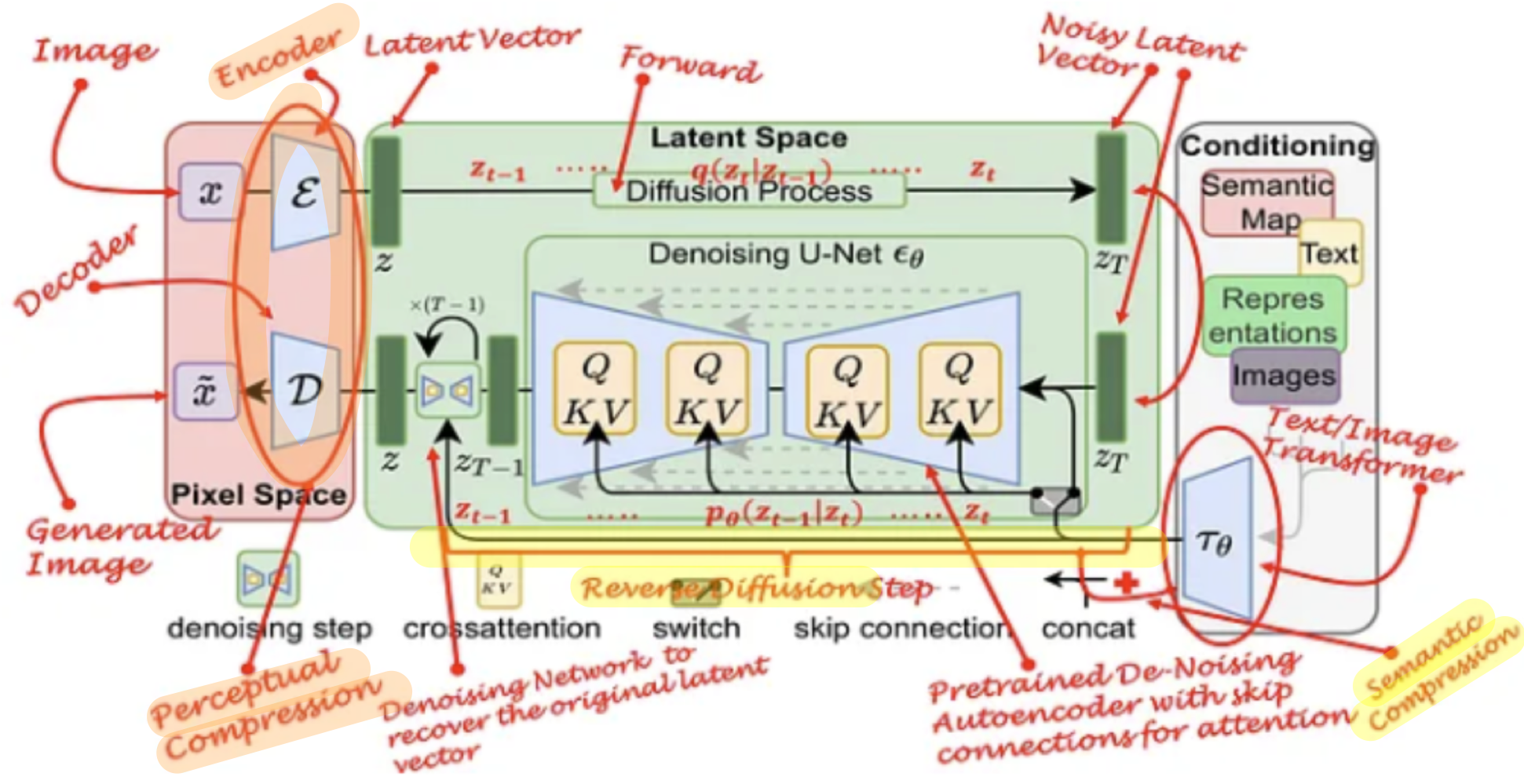
1. 소개
- 확률 기반 모델로서, DMs는 GANs와 같은 모드 붕괴 및 훈련 불안정을 나타내지 않으며, 매개변수 공유를 크게 활용함으로써 적은수의 매개변수로도 자연 이미지의 매우 복잡한 분포를 모델링할 수 있습니다.
고해상도 이미지 합성
- DM은 데이터의 지각할 수 없는 세부 사항을 모델링하는 데 과도한 용량(따라서 계산 자원)을 소모하게 만듭니다 [16, 71].
- 초기 노이즈 제거 단계를 덜 샘플링함으로써 이를 해결하기 위해 reweighted variational objective가 설계되었음에도 (DDPM), DMs는 여전히 계산적으로 요구 사항이 많습니다.
reweighted variational objective- ELBO는 확산 과정의 각 시간 단계 t에서의 KL 다이버전스 항목의 합으로 표현됩니다.
- 초기 단계에서는 데이터에 추가된 노이즈가 적기 때문에 복원 작업이 상대적으로 쉽습니다.
- 반면 후반 단계에서는 노이즈가 훨씬 많아져 더 복잡한 복원 작업이 필요합니다.
- 하지만 기본 ELBO는 이러한 단계별 중요도를 고려하지 않고 모든 단계에 동일한 가중치를 적용합니다.
- 이로 인해 학습 자원이 효율적으로 사용되지 않고, 전체적인 학습 비용이 증가합니다.
reweighted variational objective접근법은- 초기 단계(노이즈가 적은 단계)의 항목에 더 낮은 가중치를 부여하고, 후반 단계(노이즈가 많은 단계)에 더 높은 가중치를 부여합니다.
- 이를 통해 perceptually 무관환 디테일들을 복원과정에서 무시할 수 있습니다.
- 이러한 모델을 훈련하고 평가하려면 RGB 이미지의 고차원 공간에서 반복적인 함수 평가(및 그래디언트 계산)가 필요하기 때문입니다.
- 계산량이 많음 인해, DM은 연구 커뮤니티와 일반 사용자에게 두 가지 결과가 초래됩니다.
- 첫째, 이러한 모델을 훈련하려면 극히 일부 분야에서만 사용할 수 있는 방대한 계산 자원이 필요
- 둘째, 이미 훈련된 모델을 평가하는 데에도 시간이 많이 들고 메모리 비용이 비쌉니다.
- 동일한 모델 아키텍처를 많은 단계 에서 (25-1000단계)에서 순차적으로 실행해야 하기 때문입니다.
- 이 강력한 모델 계열의 접근성을 높이는 동시에 자원 소비를 크게 줄이기 위해, 훈련과 샘플링 모두에서 계산 복잡성을 줄이는 방법이 필요합니다.
- DMs의 성능을 손상시키지 않으면서 계산 요구를 줄이는 것은 이들의 접근성을 높이기 위한 핵심입니다.
잠재 공간으로의 전환
- 우리의 접근법은
픽셀 공간에서 이미 훈련된 확산 모델의 분석으로 시작합니다. 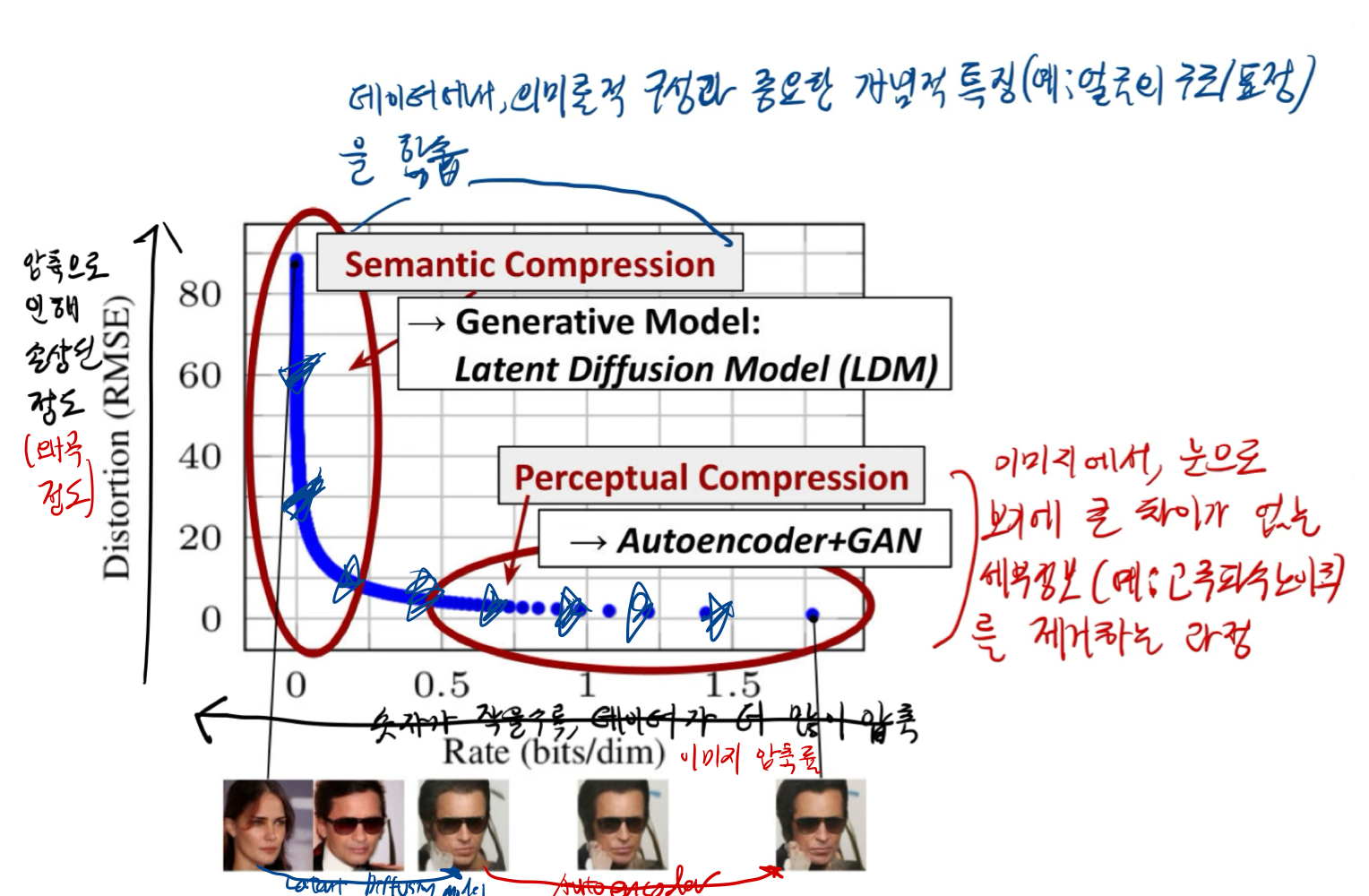
- 그림 2는 훈련된 모델의 레이트-디스토션(rate-distortion) 절충점을 보여줍니다.
- 모든 확률 기반 모델과 마찬가지로, 학습은 대략 두 단계로 나눌 수 있습니다.
- 첫 번째 단계는 고주파 세부 정보를 제거하지만 여전히 약간의 의미론적 변화를 학습하는
Perceptual Compresssion 단계입니다. - 두 번째 단계에서는 실제 생성 모델이 데이터의 의미론적 및 개념적 구성을 학습(semantic compression).
- 따라서 우리는 먼저 데이터 공간과 지각적으로 동등하지만 계산적으로 더 적합한 공간을 찾아, 고해상도 이미지 합성을 위한 확산 모델을 이 공간에서 훈련하고자 합니다.
- 우리는 훈련을 두 개의 별도 단계로 나눕니다.
- 첫째, 데이터 공간과 지각적으로 동등한 저차원(따라서 효율적인) 표현 공간을 제공하는 오토인코더를 훈련
- 중요한 점은 기존 작업 [23, 64]과 달리(예: 픽셀 공간을 직접 다루는 대신, 고도로 압축된 1D 또는 매우 낮은 해상도의 표현으로 변환한 뒤 이를 모델링 -> 계산량을 줄이기 위함 이었지만 정보 손실이 많았음),
- 우리는 과도한 공간 압축에 의존할 필요가 없음
- 중요한 점은 기존 작업 [23, 64]과 달리(예: 픽셀 공간을 직접 다루는 대신, 고도로 압축된 1D 또는 매우 낮은 해상도의 표현으로 변환한 뒤 이를 모델링 -> 계산량을 줄이기 위함 이었지만 정보 손실이 많았음),
- 이는 우리가 학습된 latent 공간에서 DMs를 훈련하기 때문이며, 이 공간은 공간적 차원과 관련하여 더 나은 확장성을 보여줍니다.
- 이는 DM(구체적으로는 Unet, (2D convolution layer))구조의
공간적 구조 데이터에 효과적인 특징(inductive bias) 때문임- 이로 인해, `품질 저하를 야기하는
- 이는 DM(구체적으로는 Unet, (2D convolution layer))구조의
- 복잡성이 줄어듦으로써 단일 네트워크 패스로 잠재 공간에서 효율적인 이미지 생성을 제공
- 우리는 이를 Latent Diffusion Models, (LDMs)이라 명명합니다.
- 이 접근법의 주목할 만한 이점은
범용 오토인코딩 단계를 한 번만 훈련하면 된다는 점이며,- 이를 여러 DM 훈련에 재사용하거나
- 완전히 다른 작업(예:
single-image CLIP-guided synthesis) 을 탐구하는 데 사용할 수 있다는 것[25, 78].
- 이를 통해 다양한 이미지-이미지 및 텍스트-이미지 작업에 대해 많은 확산 모델을 효율적으로 탐구할 수 있습니다.
- 텍스트-이미지 작업의 경우, 우리는 트랜스포머를 DM의 UNet 백본 [69]에 연결하는 아키텍처를 설계하여
임의의 토큰 기반 조건 메커니즘을 가능하게 합니다(3.3절 참조).
- 요약하자면, 우리의 작업은 다음과 같은 기여를 제공합니다:
- (i) 순수하게 트랜스포머 기반 접근법 [23, 64]과 달리, 우리의 방법은 고차원 데이터로 더 우아하게 확장되며, 따라서
- (a) 기존 작업보다 더 충실하고 자세한 재구성을 제공하는 압축 수준에서 작업할 수 있으며
- (b) 메가픽셀 이미지의 고해상도 합성에 효율적으로 적용될 수 있습니다.
- (ii) 우리는 계산 비용을 크게 줄였습니다. 픽셀 기반 확산 접근법과 비교하여 추론 비용도 크게 감소시켰습니다.
- (iii)
- 이전 연구([90])에서는 오토인코더(Autoencoder)의 인코더/디코더와 확산 모델(Diffusion Model)의 스코어 기반 분포(Score-based prior)를 하나의 통합된 과정에서 동시에 학습했습니다.
- 이 두 가지를 함께 최적화하면, 각 손실 항(재구성 손실 vs. 생성 손실)에 대한 가중치(weight)를 어떻게 잡을 것인지가 매우 까다로운(hyperparameter tuning) 문제가 됩니다.
- 이러한 불안정한 학습을 막기 위해 , latent state 에 대한 섬세한 정규화 작업이 요구되었습니다.
- 하지만, 우리의 접근법은
인코더/디코더 아키텍처(재구성(및 잠재공간 표현)을 위함)와 score-based prior(생성을 위함)을 별도로 학습합니다. (동시에 학습 X), 재구성 및 생성 능력의 섬세한 가중치 조정을 요구하지 않습니다.- 이 방식은 매우 충실한 재구성을 보장하며,
잠재 공간에 대한 정규화를 거의 요구하지 않습니다.- 가령 KL-Divergence나 벡터 양자화(VQ) 처리를 “아주 낮은 가중치”로 두거나, 최소한의 제약만 주어도 충분히 안정적으로 학습이 가능해집니다. (아래에서 나중에 설명)
- (iv) 우리는 초해상도, 복원 및 의미론적 합성과 같은
밀도 높은 조건 작업의 경우,- 우리의 모델이 컨볼루션 방식으로 적용될 수 있으며
- 약 (1024^2) 픽셀의 크고 일관된 이미지를 생성할 수 있음을 발견했습니다.
- (v) 또한, Cross attention 기반의 범용 조건 메커니즘을 설계하여 다중 모달 학습을 가능하게 했습니다.
- 이를 클래스 조건부, 텍스트-이미지, 레이아웃-이미지 모델 훈련에 사용합니다.
2. related work
2.1. 생성 모델의 다양한 접근법과 한계
-
GAN (Generative Adversarial Networks)
- 장점: 고해상도 이미지를 효율적으로 생성하며, 시각적으로 뛰어난 품질 제공.
- 단점: 최적화가 어렵고(불안정한 학습), 데이터 분포의 전체를 잘 포착하지 못함(모드 붕괴 문제).
-
VAE (Variational Autoencoders) 및 Flow 기반 모델
- 장점: 밀도(데이터 확률 분포) 추정이 잘 되고 최적화가 안정적.
- 단점: 생성 이미지 품질이 GAN보다 낮음.
-
Autoregressive Models (ARM)
- 장점: 강력한 밀도(데이터 확률 분포) 추정 성능 제공.
- 단점: 계산 비용이 크고, 샘플링이 느리며, 낮은 해상도의 이미지 생성에 주로 제한됨.
-
픽셀 기반 확산 모델 (Pixel-based Diffusion Models)
- 장점: 밀도 추정(데이터 확률 분포)과 샘플 품질에서 최첨단 성능 달성.
- 단점: 픽셀 공간의 고차원 데이터로 인해 계산 비용이 크고, 추론 속도가 느림.
2.2. 두 단계 이미지 생성 (Two-Stage Image Synthesis)
- VQ-VAE(Vector Quantized Variational Autoencoder)/VQGAN(Vector Quantized GAN):
- 첫 단계에서 데이터를 잠재 공간으로 압축하고, 두 번째 단계에서 이 공간을 기반으로 생성.
- 한계: 높은 압축 비율로 인해 세부 정보 손실 및 생성 품질 저하.
- VQGAN과 같은 접근법은 더 나은 품질을 목표로 하지만, ARM 기반 모델 훈련은 매우 높은 계산 비용을 요구함.
VQ-VAE(Vector Quantized Variational Autoencoder)
- 이미지 데이터를 더 간단한 코드로 변환하여 효율적으로 저장하거나 모델링하기 위해 만들어진 기술
- 이미지 데이터를 코드북(codebook)에 저장된 고정된 코드로 양자화(quantization)하여 압축
VQGAN(Vector Quantized GAN):
- VQGAN은 VQ-VAE에 GAN의 장점을 결합한 모델
3. Method
3.1. Perceptual Image Compression
- 우리는 autoencoder로 구성된 Perceptual Image Compression module을
percetual loss(102) 와patch-based adversarial objective(20, 23, 99) 를 이용해서 학습하였다.- , ,
- 실험 결과, ImageNet 데이터셋에서 f= 4, 8 이 고품질 이미지 생성을 잘 하면서도, 계산 효율성이 뛰어났음
- latent vector을 2D 구조로 학습하였는데, 기존 연구들에서 1D 의 learned space를 autoregressively 학습하여 사용한 것과 다른 접근법이다.
- 2D 구조로 학습하는건, 위에서 언급한 DM의 Unet구조(2D convolution layer)의 inductive bias 덕분이며,
- encoder에서 2D 구조 출력을 학습함으로써, latent vector의 내재적인 구조 정보를 품을 수 있고, 상대적으로 적은 압축을 encoder에서 수행해도 된다.
percetual loss
- DNN(예: VGG)를 사용하여, 이미지의 feature representation을 추출하고, 그 representation 간의 차이를 학습 (생성된 이미지와 원본 이미지간 비교)
- 사람이 인지하는 이미지의 유사성을 더 잘 반영
patch-based adversarial objective
- adversarial objective
- Generator(Antoencoder의 decoder)와 Discriminator가 서로 경쟁하며 학습
- patch-based
- 이미지의 작은 조각인 각 patch에 대해 real/fake를 discriminator가 판별
- 결론: 생성된 이미지가 국소적으로도 사실적으로 보이도록 학습하게 됨
High-variance latent space 피하기
- High-variance latent space?
- latent vector 각 차원(채널) 정보의 분산이 높은 것
- 분산이 높다?
- 효율적으로 적당히 정보를 압축하지 못한 것 (너무 많은 정보를 포함한 채널으로 해석 가능)
- training data의 불필요한 noise까지 학습해버린 것일 수 있다.
- 분산이 커서, weight가 조금만 바뀌어도 생성된 이미지가 불안정해지고 품질 저하가 일어날 수 있음
- 분산이 낮다?
- latent vector 각 차원(채널) 이 유의미한 정보를 담고 있지 못한 것
- 어떻게 해결할건데?
KL-regularization
- learned latent vector의 차원 분포와 standart normal distribution과의 KL-divergence를 계산하여 loss로 사용
- VAE에서 사용하는 것과 유사하다 (45, 67)
VQ-regularization
- vector quantization layer을 decoder에서 사용한다.
- vector quantization layer
- latent variable이 가질 수 있는 값의 범위를 제한 (code book vector 개념 도입)
- VQGAN(23)이랑 비슷한데, quantization layer을 decoder에 흡수했다는 점이 다르다.
3.2. Latent Diffusion Models
- latent space에서 DM을 학습하면, 우리는 중요한 semantic bits of data에 집중해서 학습할 수 있어서 좋다!
3.3. Conditioning Mechanisms
- 기존 연구의 한계점
- 클래스 라벨, 저해상도·블러 이미지는 상대적으로
단순한 조건부 입력이며, 데이터셋도 잘 갖춰져 있고 파이프라인이 확립되어 있음. - 반면,
조건부 입력으로 텍스트(description), 스케치, 위치 정보(bounding box), 마스크(mask) 등 다양한 형태의 조건은 데이터 수집, 모델 구조, 학습 프로세스 설계 측면에서 추가 난이도가 발생.
- 클래스 라벨, 저해상도·블러 이미지는 상대적으로
- 우리는 다양한 modalities를 condition으로 받기 위해( 를 pre-process 하기 위해), domain specific encoder 를 도입합니다. ( 를 intermediate representation으로 표현)
- 이 는 Unet의 intermediate laypers에 cross-attention layer의 K, V 로 입력됩니다.

핵심 정리
- 이미지-조건 쌍을 활용해, LDM을 조건부(conditional)로 학습한다.
- (조건 인코더)와 (UNet 기반 확산 모델)을 함께 학습한다. (식 (3) loss fuction 하나로)
- 는 다양한 도메인 전문가(예: 텍스트용 Transformer, 이미지용 CNN 등)를 자유롭게 쓸 수 있어, 유연한 조건부 생성이 가능해진다.
-
:
- 주된 확산 모델(UNet 기반)의 파라미터입니다.
- 시간 스텝 (t)에서, 노이즈가 추가된 상태의 잠재 벡터(예: (z_t))를 입력으로 받아 “노이즈 예측” 또는 “클린(denoised) 상태 예측”을 수행합니다.
-
:
- 조건(입력) (y)를 받아서, 모델이 이해할 수 있는 중간 표현(embedding)으로 변환해주는 별도의 “인코더” 역할을 합니다.
- 이 중간 표현은 (\epsilon_\theta)가 이미지 생성(확산) 과정에서 참고할 수 있게, UNet 내부(크로스 어텐션 등)에 주입됩니다.
“유연한(플렉시블) 조건부 메커니즘”
- 가 “도메인별 전문 모델(domain-specific expert)”로 파라미터화될 수 있다는 말은,
- 텍스트를 조건으로 쓰면: 텍스트를 처리하는 Transformer(예: BERT, GPT 등)를 로 사용
- 바운딩 박스나 레이아웃을 조건으로 쓰면: 해당 정보를 2D 특징맵(Feature Map)으로 바꿔주는 인코더
- 스케치나 마스크를 쓰면: 컨볼루션 기반 네트워크 등을 사용
- 등등, 조건 (y)의 유형에 따라 를 얼마든지 바꿀 수 있다는 뜻입니다.
- 이렇게 를 상황에 맞춰 자유롭게 설계할 수 있으니, 조건부 생성이 텍스트, 레이아웃, 스케치, 마스크 등 매우 폭넓은 입력을 지원하게 됩니다.
5. 한계점
5.0. 요약
- 샘플링 속도: LDMs는 여전히 순차적 샘플링의 한계로 인해 GAN보다 느리며, 실시간 생성에는 부적합할 수 있음.
- 잠재 공간의 한계: 잠재 공간에서 작업하기 때문에, 픽셀 수준의 정확도가 중요한 작업에서 품질 저하 가능성이 있음.
5.2. 고정된 잠재 공간의 한계(Latent Space Bottleneck)
LDMs는 잠재 공간(latent space)에서 학습 및 생성을 수행하므로, 해당 잠재 공간의 품질이 모델의 성능에 큰 영향을 미칩니다.
-
세부적인 한계점:
- 잠재 공간에서의 표현이 원본 데이터를 충분히 잘 표현하지 못할 경우, 고해상도 이미지나 픽셀 수준의 세밀한 정보가 필요한 작업에서 품질 저하가 발생할 수 있습니다.
- 논문에서 언급된 (f = 4) 오토인코더 모델은 지각적으로 매우 충실한 이미지를 복원할 수 있지만, 일부 작업(예: 초해상도 생성)에서 세밀한 픽셀 수준의 정확성(fine-grained accuracy)이 필요한 경우 병목(bottleneck)이 될 수 있습니다.
-
한계의 원인:
- 잠재 공간에서 고주파(high-frequency) 정보를 제거하거나 압축하는 과정에서 미세한 디테일이 손실될 가능성이 있습니다.

ad_official