[Planning][24.11]DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
diffusion planning
목록 보기
1/19
0. Abstract
- 최근, diffusion model을
자율주행 policy 학습에 적용 시도하는 연구들이 늘고 있다고 해요. - diffusion model을 적용하려는 이유(장점) -> policy에 대한, 연속적 확률 분포를 학습 가능함
- 특정 상황에서, 여러 훌륭한 선택지의 확률 분포를 잘 학습하는 기술적 특성
- 한 상황에서, batch 연산으로 여러 궤적들을 한번에 생성하면,
- 여러 궤적들이 학습한
전문가 데이터의 확률분포대로 나온다. - 이 여러 궤적들을,
규칙 기반 및 최적화 기반 계획 방법과 쉽게 결합 가능!
- 여러 궤적들이 학습한
- 데이터셋(전문가 운전 궤적)에 없었던 합리적인 궤적도 생성 가능하다!
- 이유는
- diffusino은 연속적 확률 분포를 학습하므로
- diffusion은 다양성 성능이 높은 생성모델이므로
- 그러나, diffusion model은 inference 속도가 느리다는 단점
- 이러한 문제를 해결하기 위해, 아래 아이디어(
truncated diffusion policy라고 하는 아이디어)를 제시- sampling 시,
여러 초기 경로 후보군(유식한 말로prior multi-mode anchors)에 noise를 조금 주입한뒤 (forward process), - denosing 과정(적은 step 활용)을 통해, 최종 궤적을 생성하도록 하는 방식
- sampling 시,
- 또한
conditional scene context와의 향상된 상호 작용을 위해효율적인 (여러 단계로 구성된) 확산 디코더를 설계했음 (파라미터 수 감소시킴)- sparse deforable attention mechanism을 사용했다고 함 (Deformable-DETR/DETR-3d 논문 컨셉을 썼다는 뜻) (BEV/PV features와 cross-attention 하기 위해)
- 제안된 모델인 DiffusionDrive는
- 기존 diffusion policy에 비해 디노이징 단계를 10배 단축
- 단 2단계 만에 뛰어난 다양성과 품질을 제공 (심지어 1 step으로도 봐줄만한 결과가 나왔다고 함)
- NVIDIA 4090에서 45FPS의 실시간 속도로 실행됨
기존 연구와의 차이점
(a) Single mode regression

- 대표적인 end-to-end planner
- Transfuser [6], UniAD [13], VAD [17]
- 이러한 패러다임은 1개의 궤적만을 출력하기 때문에,
- 주행 행동의 고유한 불확실성과 다중 모드 특성을 고려하지 않습니다.
(b) Sampling from vocabulary

- (a)의 단점을 극복하여, 여러 경로를 출력하고, 그 중에서 가장 좋은 경로를 선택하는 패러다임
미리 정의된 주행 경로들의 집합 (Vocabulary)에서 현재 상황에 가장 적합한 경로를 선택연속적인 행동 공간을 이산화하고 광범위한 주행 행동을 포착하기 위해,고정된 대규모 앵커 궤적 어휘(4096개 앵커)를 도입
- 그 중에서, 예측 점수를 기반으로 현재 상황에 맞는 경로를 선택하는 방식
- 단점
앵커 궤적의 수와 품질에 의해 성능이 크게 의존- 많은 수의 앵커를 관리하는 것은 실시간 애플리케이션에 상당한 계산 문제를 야기
- VAD2
- Hydra-MDP
(c) Vanilla diffusion policy

- (b)처럼 행동 공간을 이산화하는 대신,
- diffusion model을 적용
- 특정 상황에서 자율차가 선택할 수 있는 여러 좋은 path들을 확률적으로 학습 가능
- trajectory Vocabulary에 의존하지 않아도 되는 장점
- diffusion model을 적용
- 아직까진, diffusion model을 자율주행차에 적용한 연구가 별로 없었다고 함
- 로봇 planning에 적용하려는 시도는 꽤 있었음
- 그래서 논문에서는
Transfuser [6]+vanilla robot diffusion policy를 시도해봄 (DDIM 기반) -> TransfuserDP 라고 부름 - 한계:
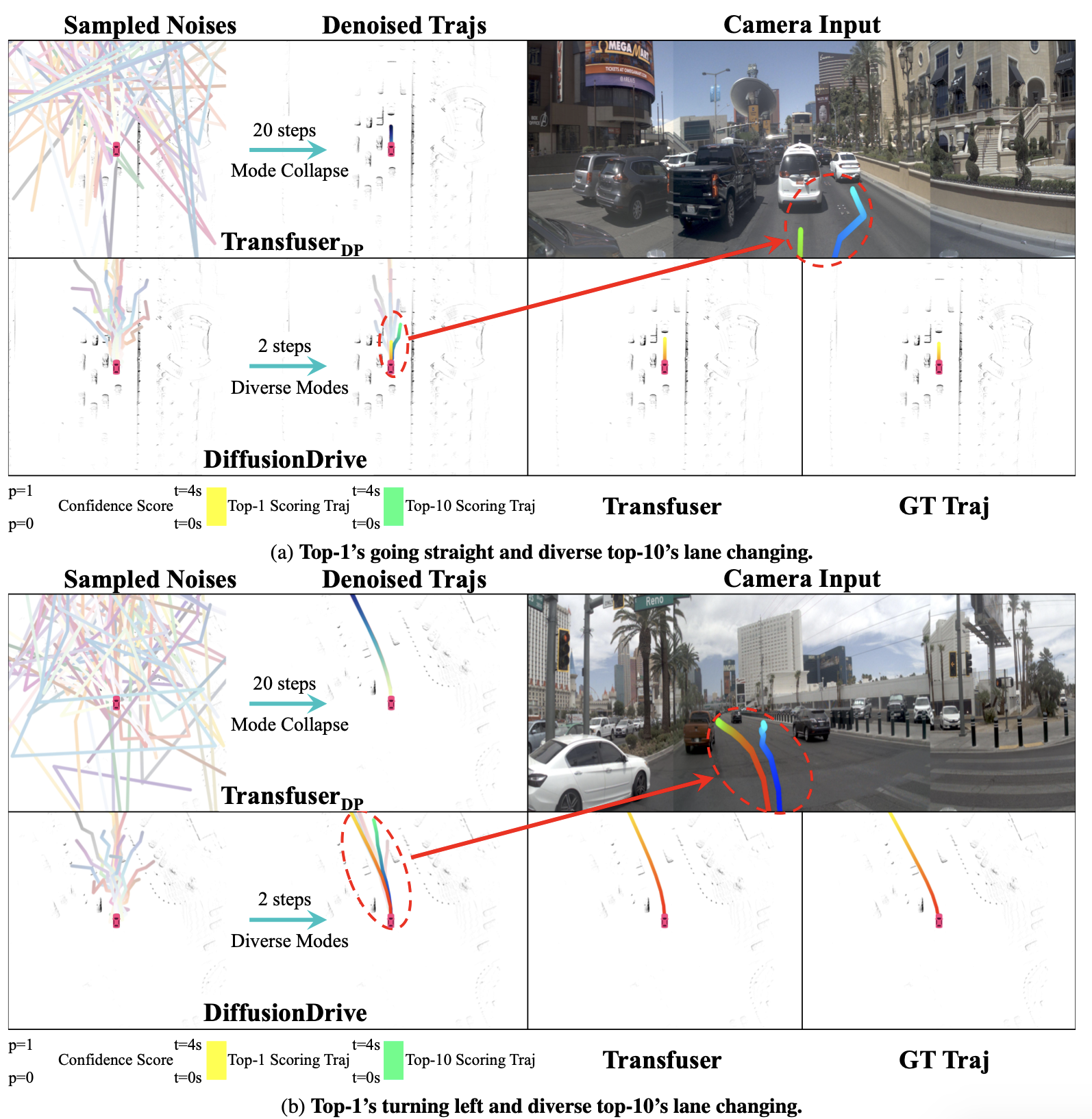
- FPS가 낮음 (20 step denoising 정도 해야 성능이 나오더라)
서로 다른 가우시안 노이즈에서 샘플링된 궤적이 서로 심하게 겹침
- diffusion policy
- Planning with Diffusion for Flexible Behavior Synthesis
(d) 논문 제안: truncated diffusion policy

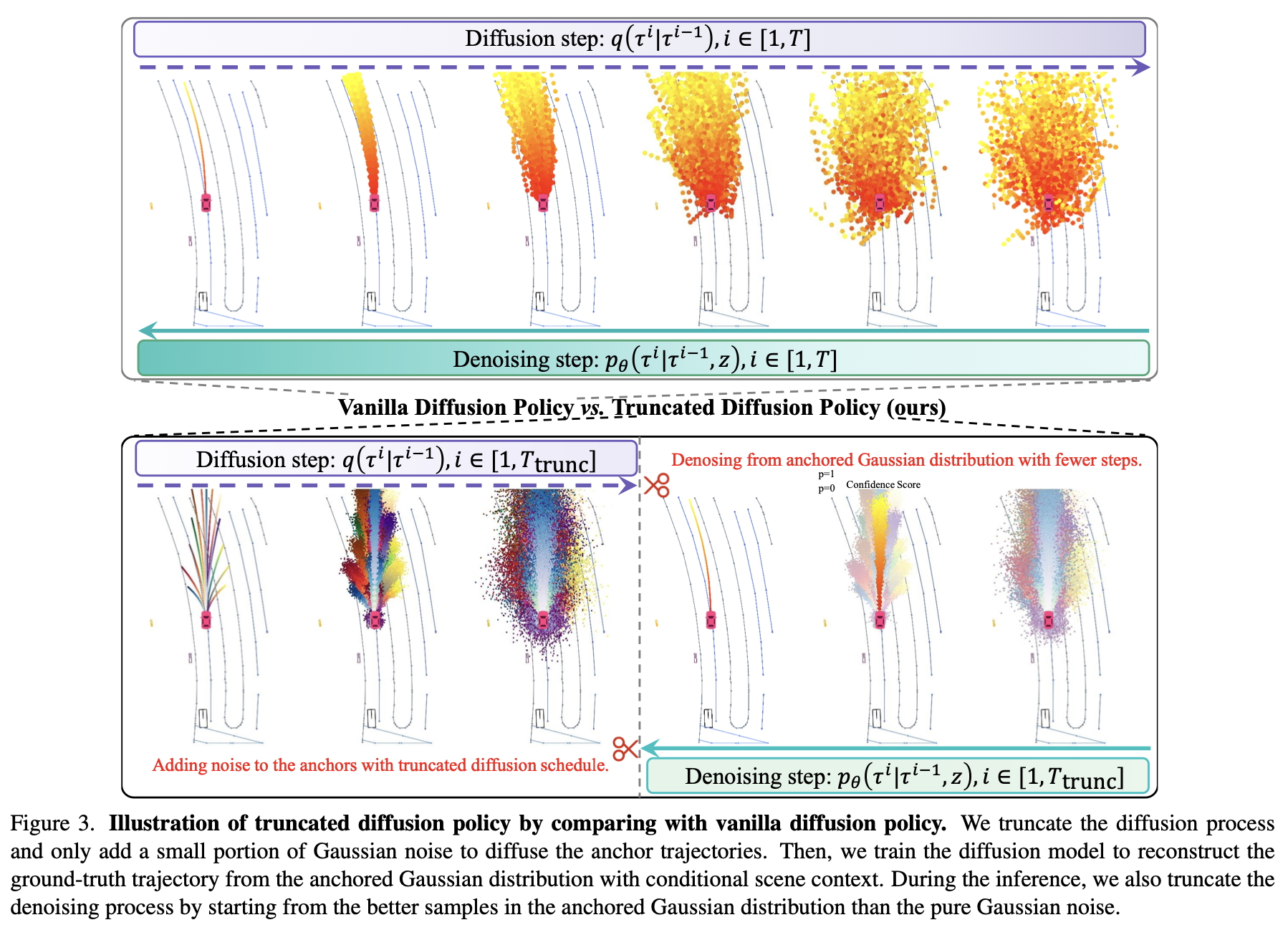
- (c)와 인간의 주행 접근법은 다름
- 인간 운전자는 random distribution이 아닌, 확립된 주행 패턴을 따릅니다. (좌회전 / 직진 / 우회전 / 차선 변경 등)
- 이에 영감을 받아, 기존 연구들의 가우시안 분포 대신, -> 사전 궤적 앵커를 중심으로 하는 여러 가우시안 분포(
앵커 가우시안 분포)로 분할해보자!
- truncated diffusion policy의 전체 흐름은 아래와 같음
- 앵커 포인트 선택: 입력 이미지와 Ego Query 정보를 기반으로 현재 주행 상황에 적합한
앵커 포인트들을 선택
- 앵커 포인트들: 여러 초기 경로 후보군들 (Figure3의 아래 가장 왼쪽 그림)
- 확산 모델의 다중 모드 분포 표현력 덕분에 , (b) 처럼 수많은 trajectory Vocabulary가 필요하진 않다.
- training-dataset 궤적들에서 K-Means Clustering을 통해 (=20개)의 anchors를 생성했다고 한다.
- 앵커 포인트 선택: 입력 이미지와 Ego Query 정보를 기반으로 현재 주행 상황에 적합한
- 조건부 가우시안 분포 생성:
선택된 앵커 포인트들을 평균으로 하는 가우시안 분포를 생성
- 선택된 앵커 궤적들에 noise를 조금 주입한다는 뜻이다.
- (c)와 비교했을 때, forward step을 적게 가져가도 괜찮다.
- 조건부 가우시안 분포 생성:
- 각 noised 엥커 포인트들에 대해 디노이징을 수행하여 경로 생성
- 이를 통해 모델은 denoising 과정에서
anchored Gaussian distribution으로부터 시작해서,multi-mode driving action distribution로의 디노이징을 학습할 수 있습니다.
다른 그림들
- 아래 그림은 가볍게 보고 넘어가자.
- 2가지 상황에서, (c)방법론과 (d)(논문 제안) 방법론을 비교한 그림
2. related work
2.2. 교통 시뮬레이션을 위한 확산 모델
- 참고
- 논문에서 제시한 참고 논문들 중에, 인용수나 github stars 수가 신뢰할만큼 높은 논문은 없었다.
2.3. 로봇 정책 학습을 위한 확산 모델
- https://github.com/jannerm/diffuser
- 922 stars
- https://anuragajay.github.io/decision-diffuser/
- 315 stars
- https://github.com/robodhruv/visualnav-transformer
- 672 stars
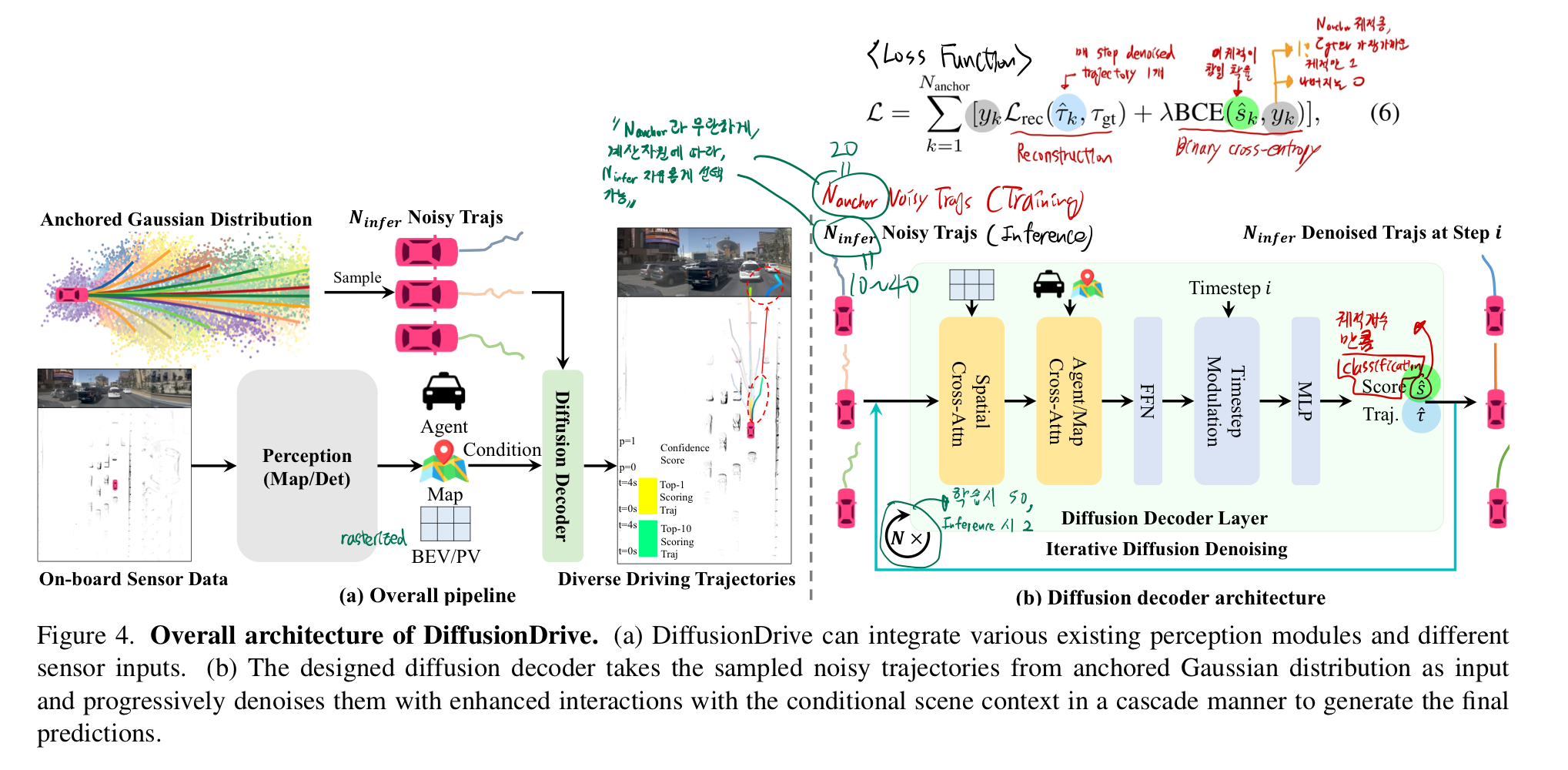
3. Method
- 전체 아키텍쳐 (중요)
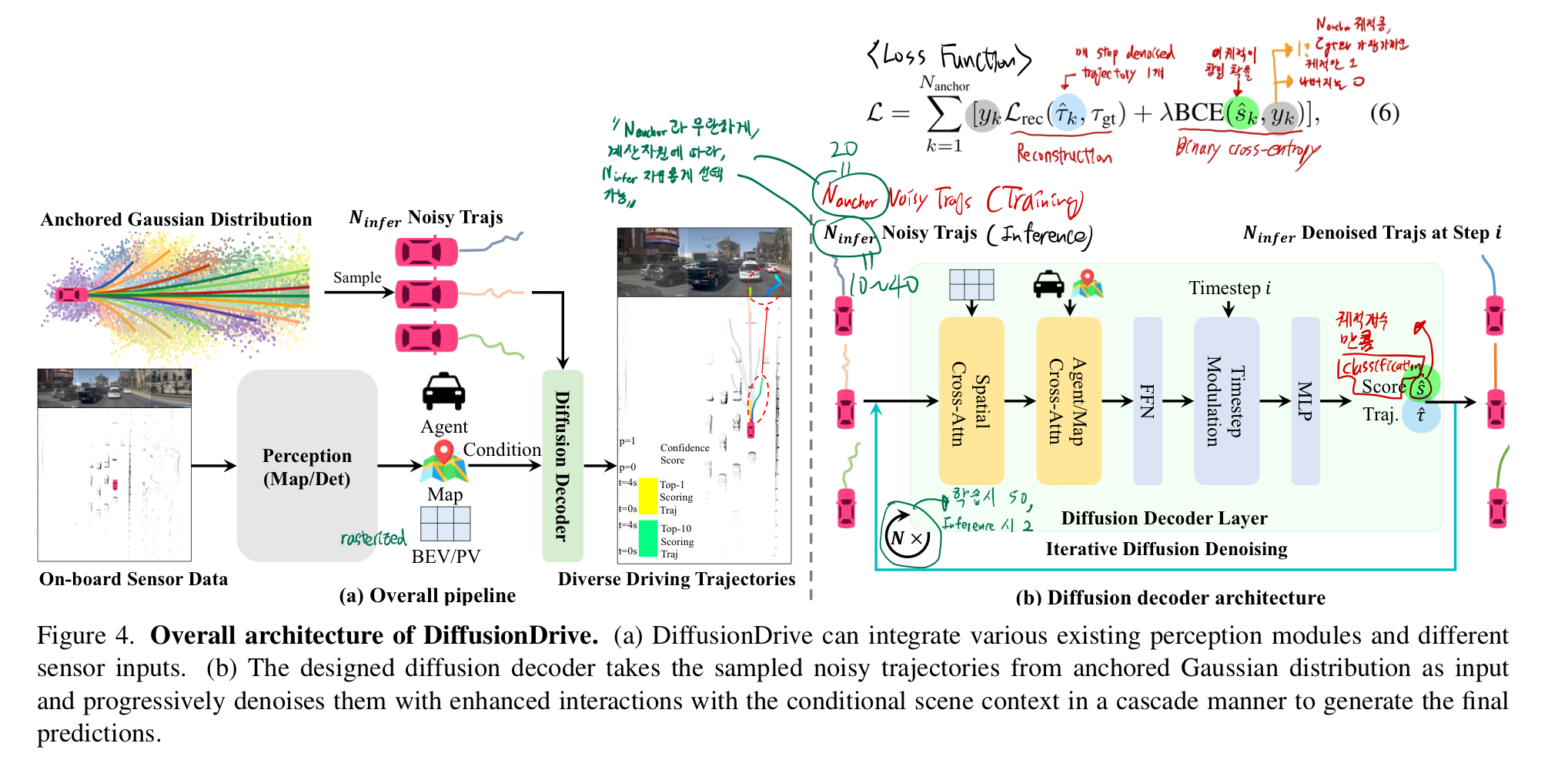
- DDIM style을 적용함
- 위 그림에서, Loss Function에 주목해서 보라! (가장 중요)
학습 & Inference
- navtrain split에서 처음부터 100 에폭 동안
- 8 4090 GPU로 512 batch로 학습률 6×10⁻⁴로 AdamW 옵티마이저를 사용하여 학습
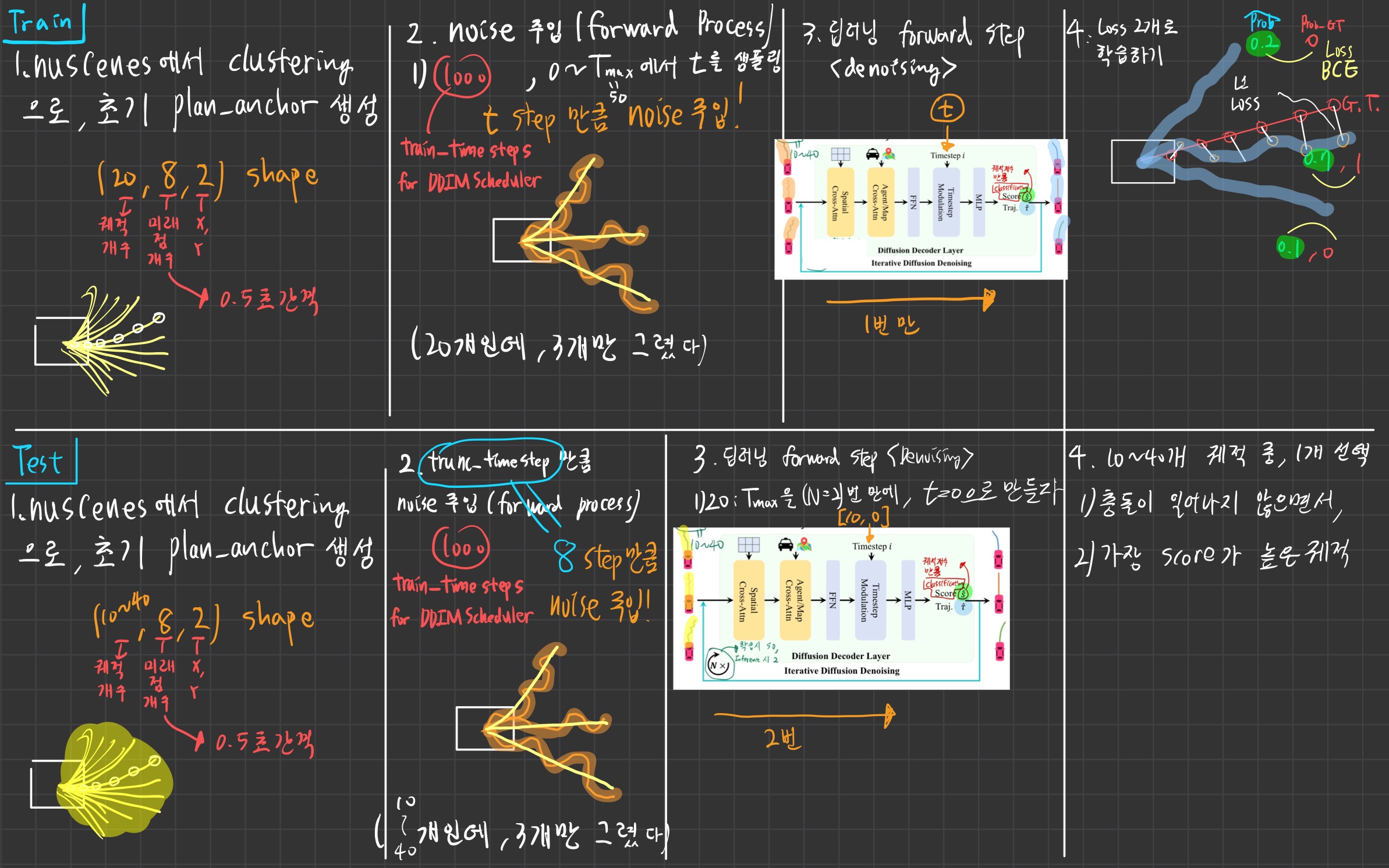

- inference 시 장점
N_anchor(=20)개로 학습했을지라도, inference 시 자유롭게N_infer(=10~40)의 값을 선택할 수 있다.N_infer은 계산 자원 요구사항에 따라 자유롭게 바꾸면 된다.
- TODO
- 위 학습/test과정에 문제가 없는지 확인
- 위 sampling 과정에 문제가 없는지 확인
4. 평가
- 4초 길이의
8-waypoint trajectory output(0.5초 간격이니까, 4초 예측) 를 평가 기준으로 삼음
1. NAVSIM dataset에서 평가 진행

- NAVSIM 벤치마크는: 위 Log Replay Evaluation Type임
- NAVSIM dataset에서, DiffusionDrive는 88.1 PDMS를 기록함
- NAVSIM dataset
- planning oriented dataset (도전적인 driving scenario만 모아둠. 운전자 의도의 다이나믹한 변화 등)
- OpenScene 기반으로 만들어짐
- nuPlan dataset의 압축된 버전 (중요한 퀄리티의 데이터만 정제한 버전)
- 360도 뷰를 커버하는 8개 카메라 이용
- 5 Lidar
- 2Hz 의 Annotation (HD map + object bounding box)
- PMDS
- PDM score (Navsim 에서 개발한 지표)
no at-fault collisions(NC)+drivable area compliance (DAC)+TTC+승차감+ego progress (EP)
- NAVSIM dataset
평가 디테일
- 구현 세부사항:
- Transfuser와 동일한 perception 모듈과 ResNet-34 백본을 사용하여 공정한 비교
- Diffusion decoder에서는
BEV(Bird’s Eye View) 피처와 상호작용하기 위해, spatial cross-attention을 적용
- Transfuser의 perception 모듈이
벡터화된 맵 정보를 포함하지 않아- agent cross-attention만 수행
- 2개의
cascade diffusion decoder 레이어를 쌓고, 20개의 클러스터링된 anchor를 기반으로 truncated diffusion policy를 적용 - 학습 시에는 diffusion 스케줄을 50/1000으로 축소하여 anchor에 노이즈를 추가하고, 추론 시에는 단 2단계의 denoising을 수행
- 로드맵 분석:
- Truncated diffusion policy를 적용한 TransfuserTD는 denoising 단계를
- 20단계에서 2단계로 줄이면서 PDMS와
모드 다양성이 크게 향상
- 20단계에서 2단계로 줄이면서 PDMS와
- 최종 모델인 DiffusionDrive는 TransfuserDP 대비 3.5 PDMS 및
64% 모드 다양성 개선, 10배 적은 denoising 단계로 6배 빠른 FPS를 달성합니다.
- Truncated diffusion policy를 적용한 TransfuserTD는 denoising 단계를
- Ablation Study:
- Diffusion decoder 내 설계 요소(예:
spatial cross-attention,cascade 메커니즘)의 효과가 확인되었으며, 파라미터 수 절감과 성능 향상이 입증
- Diffusion decoder 내 설계 요소(예:
- Cascade stage 수를 늘리면 품질이 향상되지만 4단계에서 포화 현상이 나타나며, 연산 비용과 추론 시간이 증가합니다.
- 학습 및 추론 레시피는 Transfuser를 직접 따릅니다:
- 세 장의 잘라내고 다운스케일된 전방 카메라 이미지를 1024×256 크기의 이미지로 이어 붙이고,
rasterized BEV LiDAR를 입력으로 사용 - 테스트 시에는 augmentation을 적용하지 않으며, navtest split에 대한 최종 평가 출력은 4초 동안의 8-waypoint 경로
- 세 장의 잘라내고 다운스케일된 전방 카메라 이미지를 1024×256 크기의 이미지로 이어 붙이고,
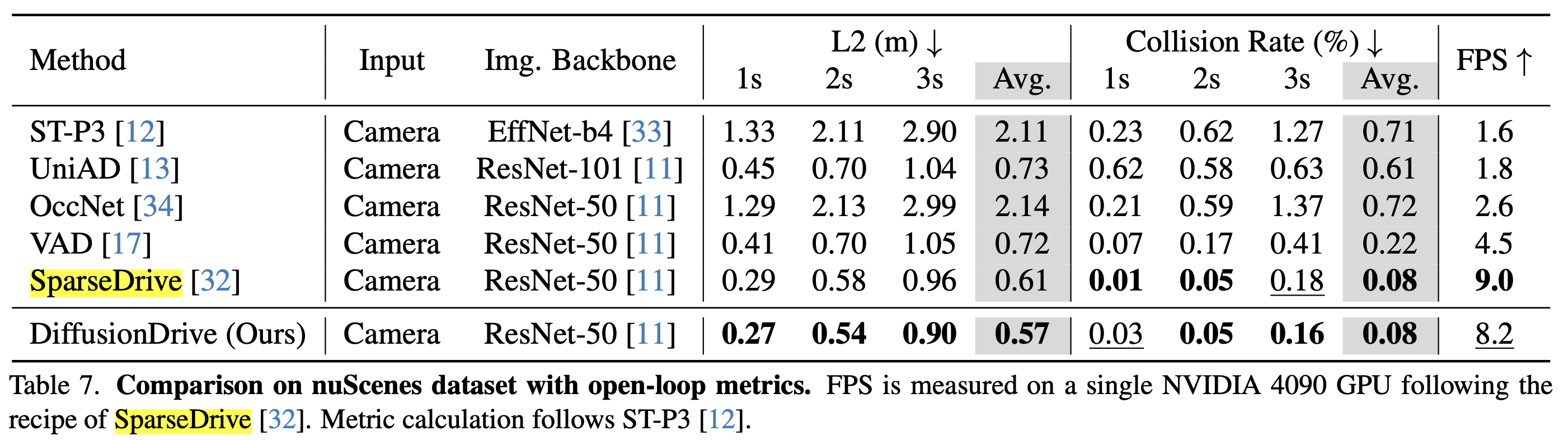
2. NuScenes dataset에서 평가 진행
- DiffusionDrive는 SparseDrive 대비 평균 L2 오차와 충돌률에서 우수한 성능을 보이며, VAD보다 1.8배 빠르고 L2 오차 20.8% 낮으며 충돌률은 63.6% 감소한 결과를 기록합니다.
- 우리는 ST-P3 [12]에서 제안한 open-loop 메트릭을 사용한 학습 및 추론 레시피를 따라
- SparseDrive [32] 기반에 DiffusionDrive를 구현
- 또한, 2개의 cascade diffusion decoder 레이어를 쌓고 18개의 클러스터링된 앵커를 사용한 truncated diffusion policy를 적용
다양성 metric: Mode diversity score
- 논문에서 정의: Mode collapse 를 측정

- TODO: 단, Area를 어떻게 측정하는지는 모르겠다.
5. code (나만 보기 위한)
- model(
V1SparseDrive)- img_backbone(
ResNet) - img_neck(
FFN) - depth_branch(
DenseDepthNet) - head(
V1SparseDriveHead)- det_head(
Sparse4DHead) - map_head(
Sparse4DHead) - motion_plan_head(
V13MotionPlanningHead)- interact_operation_order
- diff_operation_order
- decoder
- motion_decoder
- planning_decoder
- det_head(
- img_backbone(
motion_plan_head(V13MotionPlanningHead)
interact_operation_order
- ["temp_gnn","gnn", "norm", "cross_gnn", "norm", "ffn", "norm", ] * 3 + [ "refine", ]
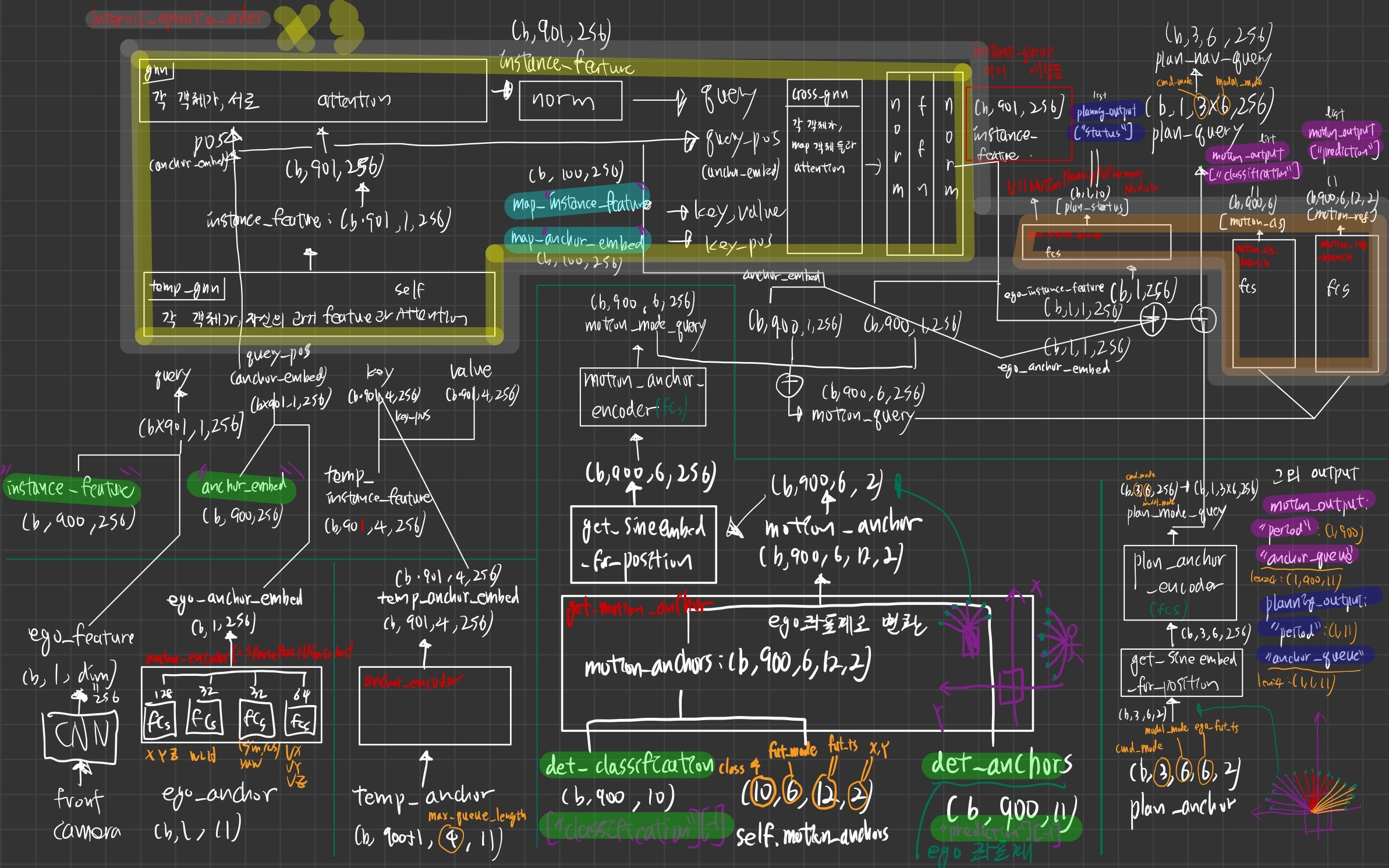
input
- det_output (초록색)
- map_output (하늘색)
- agents 용 self.motion_anchors (10, 6, 12, 2)
- ego 용 plan_anchor : (3, 6, 6, 2)
output
- planning_output (파란색 +
plan_nav_query)plan_nav_query(b, 3, 6, 256)- 3:
cmd_mode - 6:
modal_mode - 포함된 정보
- ego의 초기 anchor(future trajectories)의 가장 끝 점 (x,y)정보
- ego의 현재 state(x,y,z, w, l, h, yaw, v) 정보
- ego의 현재 feature 정보
- 내 과거와 attention했고,
- 주변 agents와 attention했고,
- 도로 정보와도 attention 한 정보
- 3:
- motion_output (보라색)
- "classification" (b, 900, 6)
- 6: future_mode
- TODO: future_mode의 각 확률을 나타내는 건가?
- 포함된 정보
- 주변 npc의 초기 anchor(future trajectories)의 가장 끝 점 (x,y)정보
- 주변 npc 기준으로, 자신의 과거정보, 서로의 정보, 도로 정보와 전부 atttention 수행한 결과 정보
- "prediction" (b, 900, 6, 12, 2)
- npc들의 예측된 미래 궤적
- "classification" (b, 900, 6)
역할
- ego_feature (b, 1, 256): front camera 로 부터 생성
- interact_operation_order
- temp_gnn
- 모든 agent들이 자신의 과거 정보와 attention
- gnn
- agent 끼리 attention
- cross_gnn
- map 정보들(차선, 경계, 보행자 횡단보도)과 attention
- refine
- temp_gnn
Diffusion loop (w diff_operation_order)
["traj_pooler","self_attn","norm","agent_cross_gnn","norm","anchor_cross_gnn","norm","ffn","norm","modulation","diff_refine",] * 2
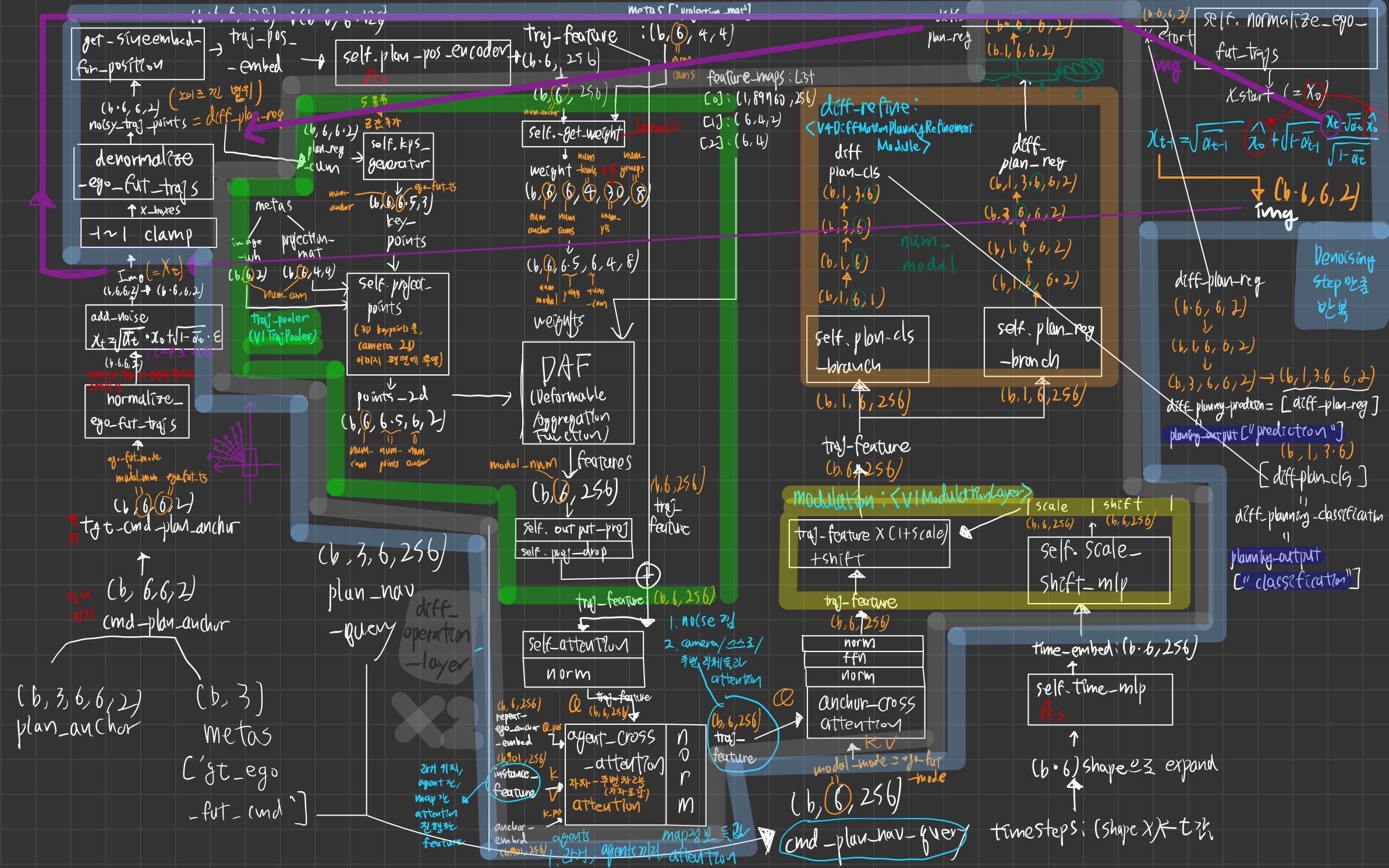
역할
- anchor (3, 6, 6, 2) 에서,
gt_ego_fut_cmd를 적용한 결과인 anchor (6,6,2)로부터 시작 - anchor (6,6,2) 에 noise를 8 step 준 후, 그걸 denoising한다.
- Diffusion loop (하늘색) 를
Denoising Step만큼 돎
- Diffusion loop (하늘색) 를
- diff_operation_order 로직
- 매 denoising step의
중간 noisy anchor (6,6,2)궤적에 해당하는 image pixel 정보들을 가져와서, (b, 6, 2)와- Deformable Aggergration Function으로 cross attention
- 주변 npc들 정보와 cross-attention
- 위에서 구한
plan_nav_query와 cross attention- ego feature 정보가 포함되어 있음
- 시간 t 정보를 융합
- 매 denoising step의
- 마지막 fc network 2개 통과
plan_cls_branch- 각 궤적의 probability
plan_reg_branch- 각 궤적의 (x,y)s
하늘색 -> 루프 2번 돎 (Denoising step)
- traj_pooler(
V11TrajPooler)- plan candidate(b, modal_num=6, 6, 2)에 대해, 카메라 이미지들로 2d projection시킨 후, 그 픽셀들과 cross attention
- self_attn
- modal_num 끼리 self attention
- agent_cross_gnn
- (자차 + 주변차량) feature과 cross attention
- anchor_cross_gnn
- 아래 방식으로 만들어진
cmd_plan_nav_query (b, 6, 256)과 cross attention- plan_anchor (b, 3, 6, 6, 2) -> 인코딩 -> (b, 1, 18, 256)
- 여기에 ego_instance_feature과 ego_anchor_embed (b, 1,1, 256) 을 더해서 만듦
- 아래 방식으로 만들어진
- modulation(
V11ModulationLayer)- 현재 timestep 정보 융합
- diff_refine(
V4DiffMotionPlanningRefinementModule)- plan_cls 와 plan_reg 를 생성
decoder
motion_decoder
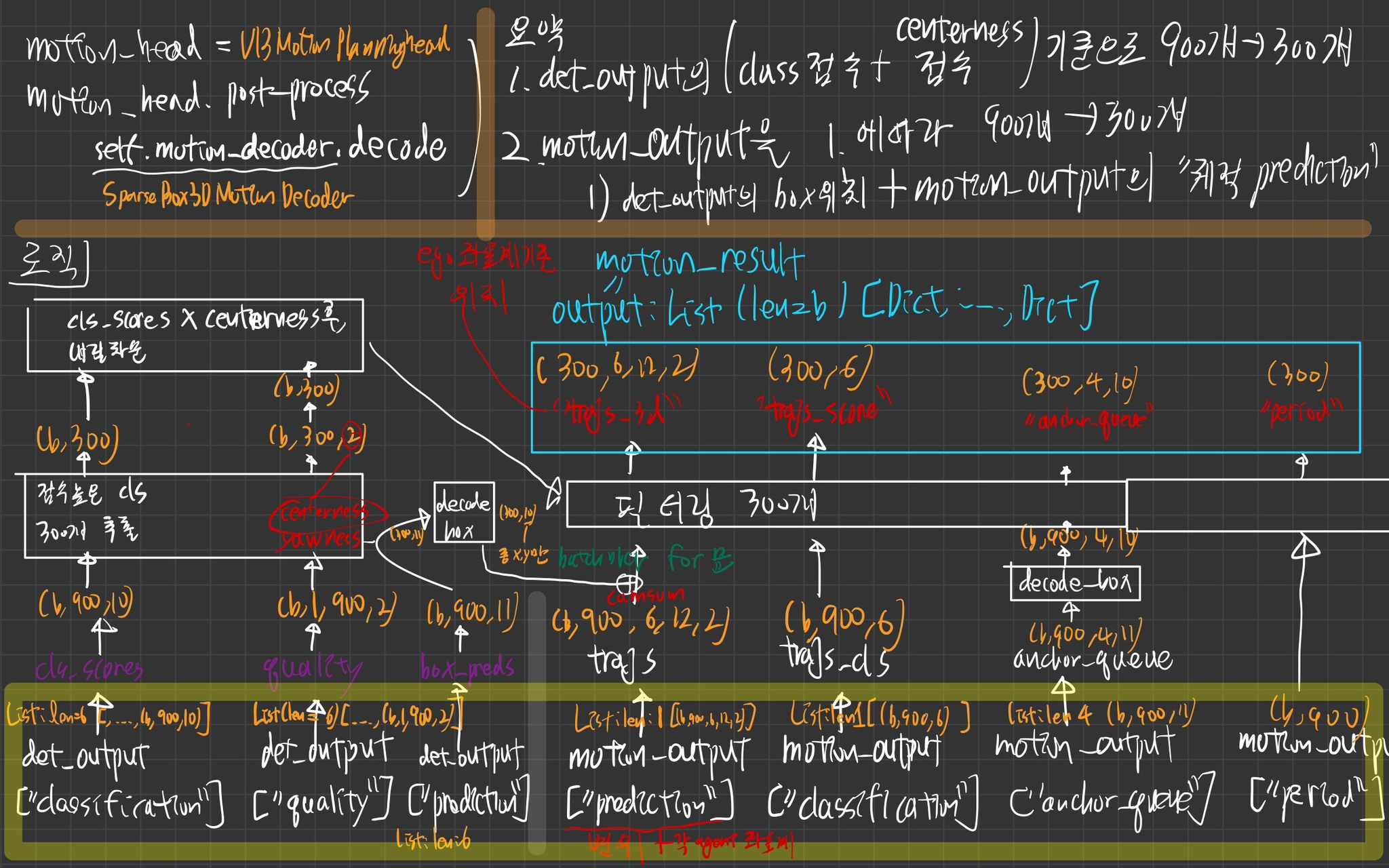
역할
- confidence와 centerness quality가 좋은 agents 300개만 추려서, prediction 결과를 필터링
planning_decoder
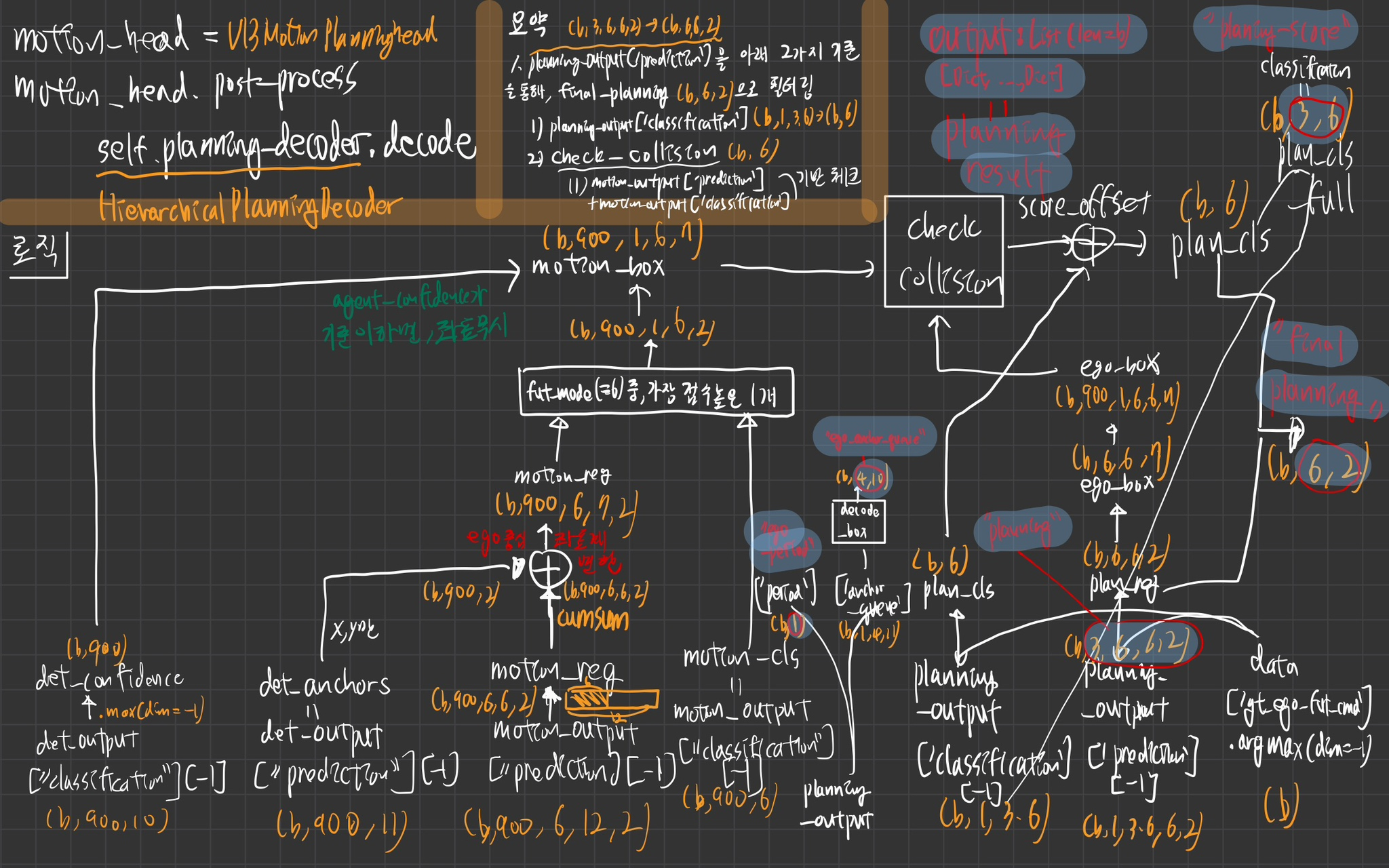
역할
- 주변 미래 agents와 충돌안하면서, confidence가 가장 높은 modality의 plan 선택!
-1. 질문 해결 리스트 정리
- (나만 보기 위한)
instance_feature과 anchor_embed는 어떻게 구하는가?
내 예상
instance_feature: 현재 정보만 보고, 이미지 plane에서, bounding box에서 feature 추출할 거 같다.anchor_embed: 3차원 좌표계에서 위치, 속도, 크기 추출 네트워크가 있어서, 그 네트워크의 output을 fully connected network에 한번 더 통과시켜 추출할 것 같다.
temp_instance_feature 어떻게 구하는가?
내 예상
- 시간 정보를 전부 보는데, 각 프레임의 이미지 plane에서의 bounding box 에서 feature 추출할 것
map_instance_feature, map_anchor_embed 는 어떻게 구하는가?
내 예상
map_instance_feature- 잘 모르겠음...
map_anchor_embed- x,y,z 등 정보를 fc에 통과시켜서 구함

ad_official
bev segmentation이나 detection같은 auxilary loss 제외하고 디코더의 메인 loss인 positive anchor에 대한 gt와의 l1 loss와 모든 앵커들에 대한 CE loss만으로 학습하는 것으로 이해하고 있습니다(diffusion loss도 없는 것 같고..). confidence가 가장 높은 예측 경로는 합리적인 예측이 학습될 것 같은데 그 외 경로들이 합리적인 차선책의 경로를 예측할 수 있게 된 이유가 뭘까요?