- https://arxiv.org/pdf/2402.13243
- https://github.com/hustvl/VAD
end-to-enddriving model based on probabilistic planning
-1. 그림들
-1.1. 논문의 motivation
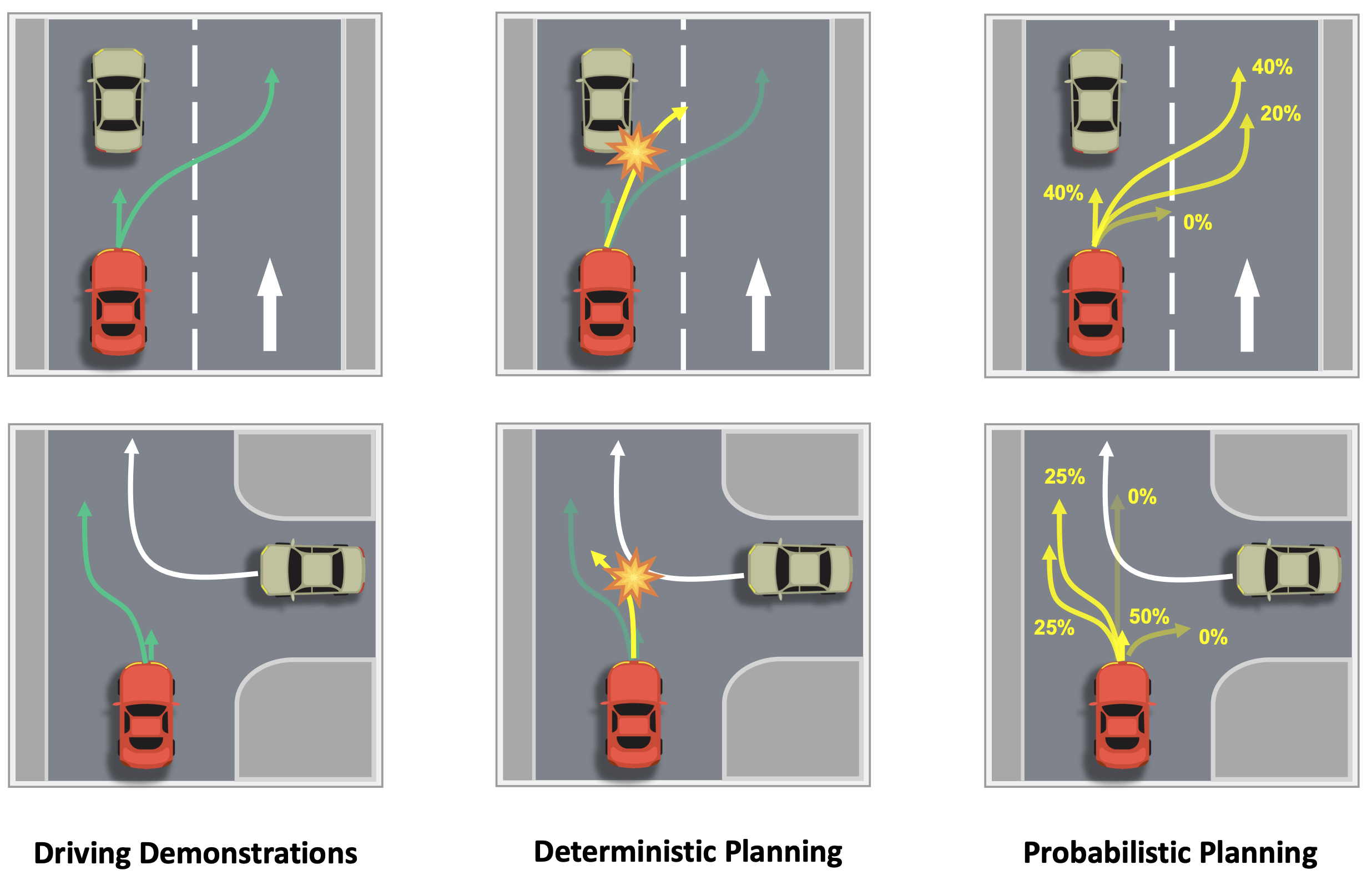
- 통계적 관점에서 볼 때, 자율주행 차의 policy는
모델링할 수 없는 많은 잠재적 요인의 영향을 받아 매우 확률적 probabilistic distribution of action을 ouput으로 사용- probabilistic output을 적용한 최초의 논문이라 주장
- probabilistic policy를 학습하면 좋은 점?
- 규칙 기반 및 최적화 기반 계획 방법과 쉽게 결합 가능
주행 스타일 선택 가능: 급한 상황에서는 공격적인 주행을, 여유로운 상황에서는 방어적인 주행을 선택할 수 있음
주행 학습 성능 자체의 향상 기대- 차선 유지를 할 수도 있고, overtaking할 수도 있는 상황이 있을 떄,
- stochastic policy network는 전체 scene을 보고 이해하는 능력을 갖출 수 있음
- deterministic policy network는 해당 상황이 2가지 선택을 할 수 있는 상황임을 학습할 수 없음
- 차선 유지를 할 수도 있고, overtaking할 수도 있는 상황이 있을 떄,
- 규칙 기반 및 최적화 기반 계획 방법과 쉽게 결합 가능
-1.2. 전체 아키텍처
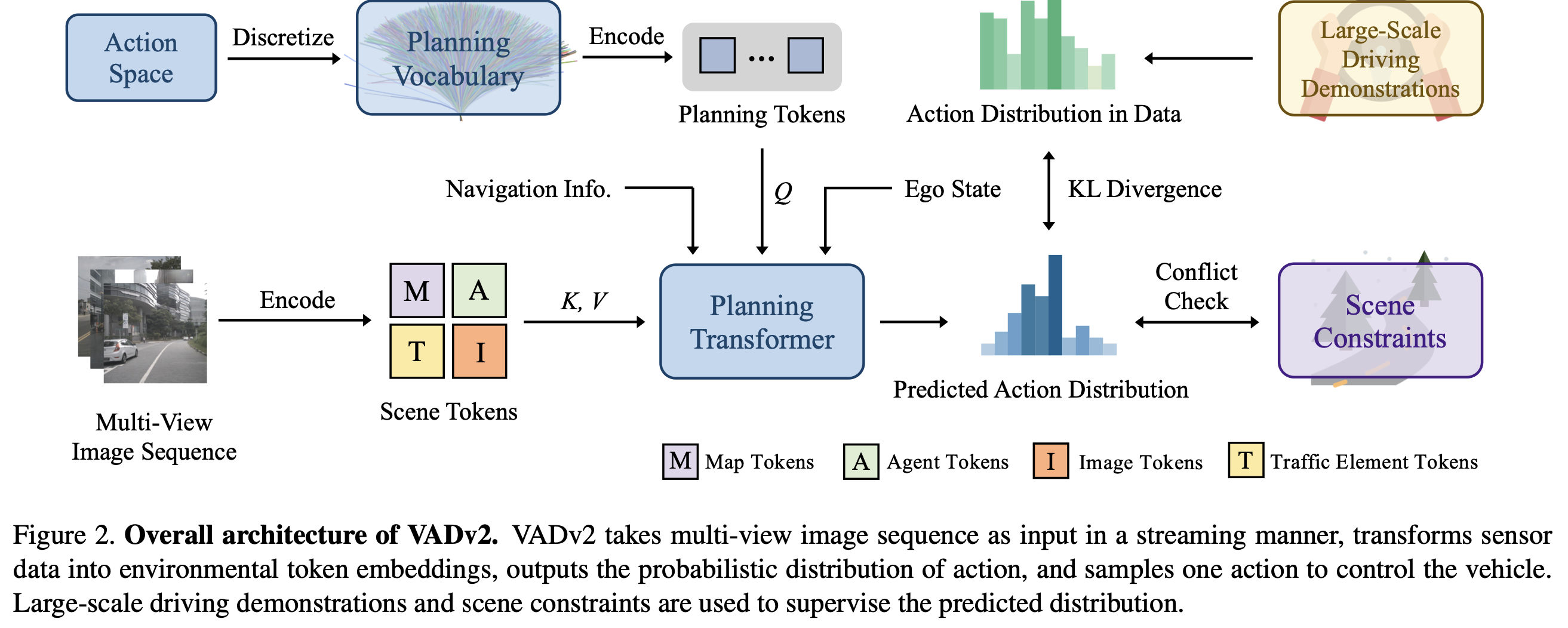
- 위 그림에서 navigation Info는
- 목적지 / 경로 계획 등
- 위 그림에서 navigation Info는
-1.2.1. planning vocabulary?
- planning 행동 공간은 고차원 연속 시공간
- 학습으로,
전문가의 연속 planning 행동 공간에 직접 맞추는 것은 불가능하기 때문에,- planning 행동 공간을 -> 많은 수의 planning vocabulary로 이산화.
- planning vocabulary는 실제 사람들이 운전하는 데이터를 분석하여 만들어집니다.
- 많은 사람들이 운전하는 모습을 관찰하고, 그 중에서 가장 대표적인 움직임들 N개를 선택하여 planning vocabulary를 구성
1. Limitation
- 단점
Planning Vocabulary의 설계에 성능이 크게 의존한다는 점- single target learning이다보니, 주행 성능을 극대화하기에는 이론적으로 한계가 있음
- 전문가의 행동(single target)을 모방하기위해 학습은 하지만,
- 충돌 위험도 / 승차감 등에 대한 명시적인 학습은 하지 않고, post-processing으로만 처리하는 한계점

ad_official