Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
[AD]simulation
목록 보기
8/10
- https://github.com/waymo-research/waymax
- 859 stars
- https://proceedings.neurips.cc/paper_files/paper/2023/file/1838feeb71c4b4ea524d0df2f7074245-Paper-Datasets_and_Benchmarks.pdf
- 2023, 10월
- 75회 인용
-1. abstract
- 다중 에이전트
데이터 기반시뮬레이터 - 유의미한 논문 기여 정리 (아래 3가지가 다임)
- Waymax는 differentiable 시뮬레이터로 구현하여, 주행 정책 학습 알고리즘의 학습 단축시간을 줄이고, global optimal 에 수렴하기 용이하게 만들었다고 함.
- 미분 가능한 시뮬레이터라는 뜻은 아래에서 자세히 설명
- Waymax는 네트워크 학습 뿐만 아니라, 시뮬레이션 환경 구동도 hardware-acceleration 할 수 있음 (JAX로 개발하였기 때문)
- 이는 학습/추론 실행 속도를 향상시킬 수 있다.
- 학습과 시뮬레이션이 호스트 머신을 통한 통신 병목 현상 없이 가속기에서 완전히 수행될 수 있습니다.
- 멀티 에이전트 학습을 실 데이터를 기반으로 빠르게 수행할 수 있는 코드를 잘 짜놓은 것 같음 (논문의 주장과 github star수가 높은걸 보니 그런것 같은데, 확인 필요)
- Waymo Open Dataset의 실제 주행 데이터를 기반으로 구축
- 다른 유명한 데이터셋으로도 쉽게 확장 가능하게 코드 짜놨음
- 다양한 다중 에이전트 시뮬레이션 시나리오를, 데이터셋을 이용해서 초기화하거나 재생(오픈루프를 의미) 하는 기능이 있음
- 자동차 뿐만 아니라, 보행자와 자전거 이용자와 같은 도심 주행에서의 까다로운 장애물을 시뮬레이션했다고 함 (신호등도 포함)
- 하지만 자세히 읽어보니, Waymo Open dataset으로부터 non-interactive하게 play하는 것만 가능한듯
- 자동차를 interactive하게 구현해놓은것은 IDM이 전부임 ㅠㅠ
- 대신, 내가 interactive-model을 개발한 후, 쉽게 바꿔끼울 수 있게 코드를 잘 구조화해서 짜놨다고 주장하고 있다.
0. 개념: 미분가능한 시뮬레이터?
0.1. 미분 불가능한 시뮬레이터 개념
- 전통적으로, 물리 기반 시뮬레이션은 "입력(상태와 행동) → 출력(다음 상태)" 관계를 갖는 블랙박스 형태
- 이러한 시뮬레이션은 주어진 초기 조건과 행동(예: 자동차의 조향각, 가속도, 외부 agent의 변동)에 따라 다음 상태(예: 차량의 위치, 속도, 외부 agent의 변동)를 계산하지만,
- 이 변환 과정은 일반적으로 미분 가능하게 설계되지 않음
- 그 이유는
- 일반적인 물리 시뮬레이션은 충돌, 마찰, 접지 등의 현상에서 비연속적이고 미분 불가능한 특성을 많이 가짐
- 그리고 ego 차량의 움직임에 따른 주변 agent의 움직임도 예측하기 어렵기 때문
- 즉, "지금 상태에서 특정 행동을 했을 때, 결과 상태가 어떻게 변하는가?"에 대한 기울기(미분값)를 쉽게 얻을 수 없는 경우가 대부분입니다.
0.2. 미분 가능한 시뮬레이션을 만드는 이유
0.2.1. 효과 : 정책 최적화와 학습 효율성 개선
- 기존의 RL 기법들은 "정책 파라미터 변화 → 보상 변화" 관계를 명시적으로 알 수 없으므로, 수많은 시뮬레이션을 돌려서 추정치(근사치)를 얻어야 하고, 이 추정치는 노이즈가 많아 불안정합니다.
- 이는 학습 과정에서 시간이 많이 걸리고, 때때로 수렴하기 어려운 상황을 초래
- 시뮬레이션이 미분 가능해지면, 학습 시간이 줄어들고, global optimum으로 수렴하기 용이해집니다.
- 정책 파라미터 변화에 대한 정확한 기울기를 바로 계산할 수 있습니다.
- 그럼 굳이 많은 에피소드를 통해 통계적 평균으로 기울기를 추정할 필요가 줄어들고, 노이즈로 인한 불안정성도 크게 완화됩니다.
0.2.1.1. 미분 불가능한 시뮬레이터에서, RL 알고리즘의 기울기 추정 방식 복습
- Policy gradient, Actor-crtic 모두, "환경과의 상호작용"을 통해 많은 경험(데이터)을 모은 뒤, 그 경험에서 추정한 값으로 기울기를 근사 (시뮬레이터 미분이 불가능하기 떄문)
- 한 번의 에피소드에서 얻은 보상은 매우 변동성이 크고, 특정한 정책 파라미터 변화에 대한 정확한 정보를 주기 어렵습니다.
- 예를 들어, 같은 정책이라도 어떤 초기 조건, 어떤 랜덤 시드에서 시뮬레이션을 돌리느냐에 따라 결과(보상)가 크게 달라집니다.
- 결국 더 많은 에피소드를 모아 평균을 내야 기울기가 어느 정도 안정화되는데, 이것이 바로 학습 과정이 느리고 불안정해지는 원인
- 예시: Policy Gradient 학습 과정

0.3. 그럼 어떻게 미분 가능하게 만드는가?
- 미분 가능한 시뮬레이터를 만들기 위해서는
- 비연속 요소(충돌, 마찰, 접지 등의 현상, 주변 agent의 움직임 모델)을 부드럽게 근사(smoothing)하거나,
- 적절한 수학적 모델(예: 미분 가능한 충돌 모델, 매끄러운 마찰 모델)을 도입해야 합니다.
- TODO
- Waymax에서는 이를 어떤 방식으로 구현했는지? 그것이 합리적인지? 를 분석해야함
- 논문을 열심히 읽어봤는데, 이 부분이 자세히 설명되지 않은 것 같음
0.3.1. 방법론 예시: Reparameterization / Pass-through Gradients
- 시뮬레이션이 미분 하기 위해서는, 환경 내 확률적 요소나 복잡한 연산을 Reparameterization/Pass-through Gradients 기법을 통해 미분 가능 형태로 만들면 된다.
- 내 생각
- 실제 세계를 잘 모델링한 미분가능한 수학적 모델을 도입해야지, 그냥 미분가능하도록 trick만 쓰는게 무슨 의미가 있나?
Reparameterization
- 재매개화 기법의 핵심은 "랜덤 변수의 샘플링"을 파라미터 θ와 독립적인 랜덤 변수 ϵ을 통해 표현하는 것입니다.
- 이렇게 하면 원래 직접적으로 θ에 의존하는 확률적 과정을, ϵ이라는 기정(given)한 노이즈에 대한 결정론적(de-terministic) 변환으로 바꿀 수 있어, θ에 대한 미분이 용이해집니다.
Pass-through Gradient
- 역전파 과정에서 특정 연산을 단순화하는 방법입니다.
- 즉, 순전파(forward)에서는 어떤 복잡한(또는 비분리) 함수 변환을 수행하지만, 역전파(backward) 시에는 그 변환을 무시하거나 단순화하여 기울기를 '통과(pass through)'시킵니다.
- 이를 통해 역전파 그래프를 간소화하고, 기울기 흐름을 원활히 할 수 있습니다.
1. Introduction
- CARLA [14], Sim4CV [33], SUMMIT [9]와 같은 시뮬레이터는 photo-realistic 렌더링에 중점을 둠
- 자율"주행 PnC" 시뮬레이터에서 중요한 점: 속도와 현실성
다양한 시나리오와현실적인 에이전트(예: 차량 및 보행자)의 동작 생성- closed-loop의 에이전트 동작 시뮬레이션 제공
- 대규모 모델과 데이터세트를 사용하는 최신 머신러닝 트렌드를 지원할 수 있는 높은 속도와 처리량
2. Related Work
2.1. 자율주행 시뮬레이터
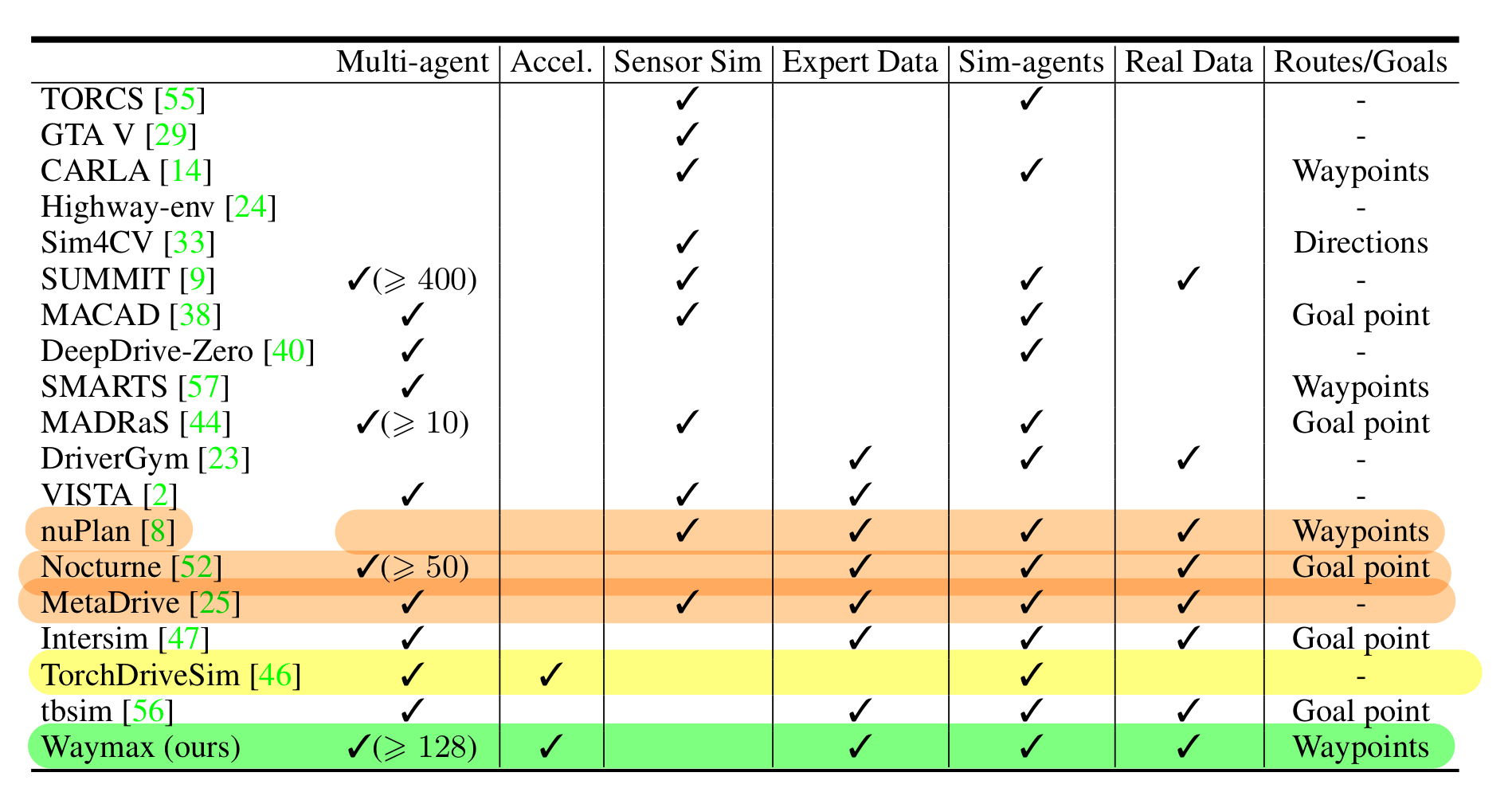
- waymax와 가장 가까운 연구는 Nocturne[52], MetaDrive[25], nuPlan[8]
- 위 3가지는
실제 주행 데이터를 사용하여 시나리오와 기록된 행동을 초기화하는 기능이 있는, 다중 에이전트 자율 주행 시뮬레이터
- 위 3가지는
- 이와 비교하여, Waymax 시뮬레이터가 가지는 장점은
- 주행 학습 뿐만 아니라, 시뮬레이션 환경 구동도 hardware-acceleration 할 수 있음
미분 가능한 시뮬레이션
2.2. 학습 기반 주행 에이전트
- Waymax는 대표적인 closed loop 방법(IL 및 RL baseline 세트)의 구현을 제공하고, Waymax가 정의한 표준 메트릭 세트에 대한 성능을 보고하였음
- 논문에서 제시한 6개 비교군 논문 모두 2022년 이전에 작성되었으며, 인용수가 100을 넘지 않고 github 코드도 없음
- Waymax는
표준 학습 및 평가 워크플로우와오픈 및 폐쇄 루프 설정에서 신뢰할 수 있는 벤치마킹을 제공함
3. 시뮬레이터 기능
- 이 섹션에서 논의된 각 구성 요소는 사용자가 자신의 프로젝트 요구에 맞게 쉽게 수정하거나 교체할 수 있습니다.
3.1. 시나리오 및 데이터셋
- 합성(가상의) 시나리오를 생성하는 시뮬레이터(예: CARLA[14])와 달리,
- Waymax는 실제 주행 로그를 사용하여 주행 시나리오를 인스턴스화하고 고정된 수의 step 동안 실행
- Waymax는 Waymo Open Motion Dataset(WOMD)[15]에 대한 기본 지원을 제공
- 각 트래젝토리 스니펫은 0.1Hz로 기록된 9초
- 트래젝토리에는
자율 주행 차량(AV), 다른 차량, 보행자, 자전거를 포함한 장면의 모든 객체에 대한 위치 및 속도 정보가 포함
- 각 시나리오에 대해
도로 그래프와 같은 정적 정보를 가져와- 로그된 정보의 시작점을 사용하여 동적 객체를 초기화
- 그런 다음,
에이전트 모델(3.5절에서 설명할 것임)을 사용하여 시뮬레이션 단계를 통해주변 동적 객체를 제어 - 각 모델은 여러 객체를 제어할 수 있습니다.
3.2. state / observation space
- 자율 주행 제어의 첫 번째 구성 요소는 state space을 정의하는 것
- state에는 두 가지 유형의 데이터가 포함
- 에피소드와 시나리오에 걸쳐 변경될 수 있는
동적 데이터
- 장면의
모든 차량, 자전거 및 보행자의 위치, 회전, 속도 및 bounding box 치수 + 교통 신호등의 색상(빨강, 노랑, 녹색)
- 에피소드와 시나리오에 걸쳐 변경될 수 있는
- 에피소드 동안에는 동일하지만 시나리오마다 다를 수 있는
정적 데이터
- "roadgraph"라고 하는, 3D pointcloud로 샘플링된 도로 및 차선 경계
- 자율 주행 차량의
on-routeandoff-routepaths (이게 뭔지는 뒤에 나옴)
- 에피소드 동안에는 동일하지만 시나리오마다 다를 수 있는
- 각 에이전트는 사용자 정의 observation 함수를 통해 시뮬레이터 state를 확인하며, 이는 부분 관측 가능성을 구현할 수 있게 함
- waymax에서 제공하는 기본 observation 함수는
- 다른 모든 차량의 위치를 에이전트의 자체 좌표계로 변환하고
- "roadgraph"를 거리에 따라 샘플링
- waymax에서 제공하는 기본 observation 함수는
3.2.1. on-Route and off-Route paths
- 자율 주행 차량이
초기 위치에서 취할 수 있는 실행 가능한 paths로 각 시나리오를 증강- 각 path는 roadgraph의 점의 하위 집합인 일련의 점들로 표시
- 각 경로 candidate는 시작 위치에서 roadgraph의
깊이 우선 탐색을 수행하여 계산됨 - 만약 path candidate가
- AV’s logged trajectory와 같은 road이면
on-route path로 정의 - 그 외는
off-route path로 정의
- AV’s logged trajectory와 같은 road이면
- 이 2가지가 state space 에 포함된다.
3.3. Object Dynamics
- Waymax는 사용자가 역학 모델을 정의할 수 있도록 하고,
- 시뮬레이션에서 차량의 물리적 역학을 제어하기 위한 몇 가지 사전 정의된 옵션을 제공
- 1) 보행자, 자전거 등: 모든 유형의 객체에 적합한 델타 동작 공간은 두 연속 상태 사이의 위치 차이(델타 항 ∆x, ∆y, ∆θ)를 사용
- 2) 자동차: 그리고 bicycle action space((a, κ))은 가속도와 조향 곡률을 사용
3.4. Metric
- Waymax는
안전성과 행동의 정확성(교통 규칙 준수, 충돌 방지등)뿐만 아니라편안함과진행 상황을 평가하기 위한 메트릭을 제공
- Waymax의 모든 메트릭은 폐쇄 루프 방식으로 계산
- 중요한 내용이 없어서 세부 사항은 생략했음
3.5. Simulated Agent Behavior
- 내가 학습/검증할 AV이외의 다른 agent의 현실적인 행동 구현이 매우 중요함
- Waymax는 다중 에이전트 시뮬레이터로서 사용자가 시뮬레이션에서 모든 객체의 행동을 제어할 수 있는 기능을 제공
- 이를 통해 사용자는
학습된 행동 모델과 같은 원하는 모델로 에이전트를 제어할 수 있습니다.
- 이를 통해 사용자는
- 그러나 Waymax는 지능형 운전자 모델(IDM)[51]만을 구현해 놓았습니다.
- Waymax의 IDM 에이전트는 데이터에 기록된 로그된 경로를 따르지만,
- IDM을 사용하여 속도 프로필을 조정하여 충돌을 피하고 자유로운 도로에서 가속합니다.
4. Software API
- 주요 라이브러리는 다음과 같습니다.
- (1) 일반적인 데이터 구조 세트
- (2)
distributed 데이터 로딩 라이브러리 - (3) 메트릭 및 dynamics와 같은 시뮬레이터 구성 요소
- (4) Gym과 유사한 환경 인터페이스
- 각 구성 요소는 수정, 교체 또는 독립적으로 사용할 수 있습니다.
4.1. Environment Interface
state = env.reset(next(dataset))
while not done:
action = policy(env.observe(state))
state = env.step(state, action)4.2. Hardware Acceleration and In-graph training
- Waymax은
학습과 시뮬레이션을 동일한 계산 그래프 내에서 결합하는 것을 지원합니다(그래프 내 학습이라고 함).- 이를 통해 학습과 시뮬레이션이 호스트 머신을 통한 통신 병목 현상 없이 가속기에서 완전히 수행될 수 있습니다.
- 이러한 기능은 Waymax가 전적으로 JAX[5] 라이브러리를 사용하여 작성되었기 때문에 가능
4.2.1. 시뮬레이션 환경을 JAX 라이브러리를 사용하여 구현할 수 있는 이유
- Waymax는 함수형 순수성(functionally pure)을 갖춘 초기화(initialization) 및 전이(transition) 함수를 제공
- 즉, 같은 입력을 주면 항상 동일한 출력을 반환하는 "순수 함수" 형태로 환경을 정의
- 이러한 stateless 설계 덕분에 JAX[5]의 JIT컴파일러와 함수형 라이브러리를 통해 시뮬레이션을 효율적으로 최적화할 수 있습니다. (컴파일 후 GPU에서 빠르게 구동 가능)
- 또한, 이 접근 방식은 사용자가 backtracking 제어 알고리즘(여러 후보 행동 시나리오를 가상으로 미리 시뮬레이션한 뒤 최적의 행동 경로를 선택하는 알고리즘)을 쉽게 구현할 수 있도록 돕습니다.
- 기존의 OpenAI Gym[6]이나 DM Control[32] 같은 환경은 내부적으로 상태를 관리하는 "상태 저장(stateful)" 방식입니다.
- 즉,
reset()이나step()함수를 호출할 때 사용자는 상태를 명시적으로 전달하지 않고, 환경 자체가 내부적으로 상태를 기억합니다.
- 반면 Waymax에서는 사용자가 명시적으로 상태를 관리하고, 매 시뮬레이션 단계에서 이 상태를
transition함수에 전달하여 다음 상태를 얻는 방식으로 작동합니다.- 이로 인해 함수형 패러다임에 맞춰 전체 연산을 정의할 수 있고, JAX를 통한 자동미분, 최적화, 가속기(GPU/TPU) 활용이 용이해집니다.
- 정리하자면, Waymax의 함수형 순수성 및 상태를 외부에서 관리하는 설계 방식은
- JAX와 같은 함수형, 자동미분 지원 라이브러리와 궁합이 좋아
- 시뮬레이션을 고성능으로 최적화하고 다양한 알고리즘을 유연하게 구현할 수 있게 합니다.
4.3. Single and Multi-agent Simulation
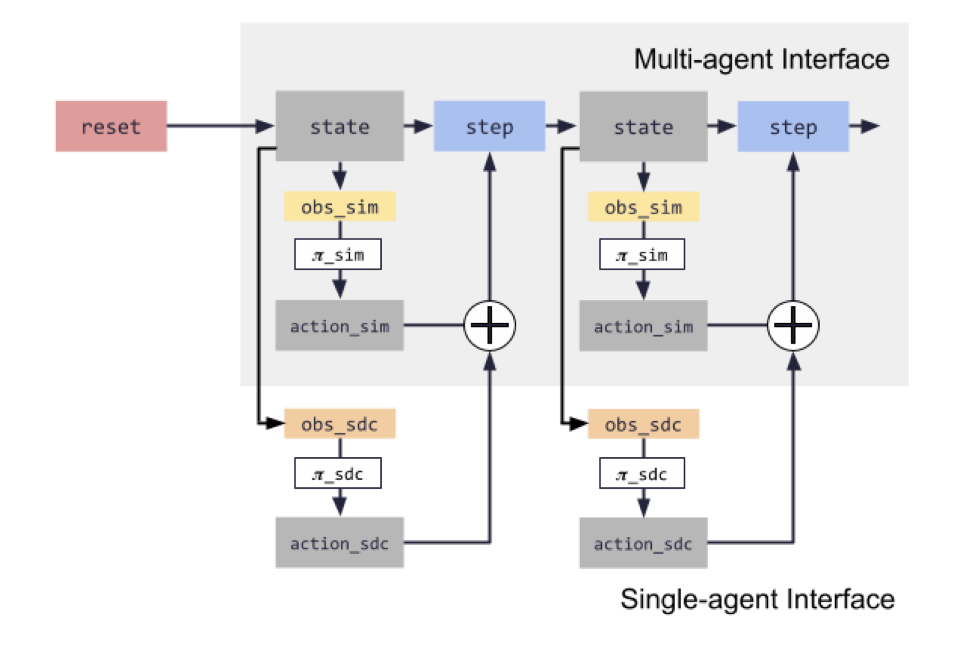
- Waymax는 아래 2가지를 모두 지원
- MultiAgentEnvironment
- 사용자가 시나리오 내의 임의의 객체를 제어할 수 있는 multi-agent simulation
- 사용자는 장면의
모든 제어 객체에 대한 동시 동작과제어해야 하는 객체를 나타내는 마스크를 제공
- PlanningAgentEnvironment
학습되거나 규칙 기반 모델 혹은 로그 재생을 사용하여 장면의 다른 차량을 제어하는, single AV 에이전트가 훈련되는 워크플로우- 자율 주행 차량만 제어하기 위한 인터페이스를 제공
- waymax에서는 하나의 MultiAgentEnvironment에 여러 정책(정책=행동 전략)을 직접 넣는 것은 가능하지만, 유연하지 않다.
- MultiAgentEnvironment를 여러개 만드는게 올바르다.
5. 실험
5.1. 런타임 벤치마크
- CPU(Intel Xeon W-2135@3.7GHz)와 GPU(Nvidia-V100)를 사용하여, Waymax의 런타임 성능을 테스트해봤음
- 다양한 배치 크기로 MultiAgentEnvironment 및 PlanningAgentEnvironment의 성능을 평가
- 매우 빠르다.
- 특히 Waymax가 배치 처리를 지원함
rollout
- 우리는 또한 전체 에피소드(즉, WOD의 경우 80단계) 동안 Actor가 주어진 환경을 롤아웃하는 Rollout 함수를 벤치마크했음
- Rollout 함수:
- 여러 단계(step)를 연속적으로 실행하여 전체 에피소드(시나리오)를 한 번에 처리하는 함수
- 주변 agent와의 상호작용은, step을 한번씩 실행하는 것과 동일하게 일어납니다.
- rollout 함수는 더 빠른 추론과 평가를 제공하는 데 특히 유용
- 이것은 Step 함수를 80번 실행하는 것보다 빠릅니다.
- Rollout 함수:
- 더 중요한 것은 GPU에서 실행하면 일관되게 2배의 속도 향상을 볼 수 있다는 것입니다.
5.2. Baseline Planning Agents
Expert
- 오픈 루프 훈련을 위함
Behavior Prediction Model(Wayformer)
- Wayformer 행동 예측 모델[35]을 계획 설정에 적용
- 원래 Wayformer는 1초의 컨텍스트 히스토리를 주어진 8초 미래 트래젝토리를 여러 개 예측
- 이를 planning setting에 적용하기 위해
- 미래를 예측할 때, 단 한 번에 긴 시간을 예측하는 대신, 짧은 구간씩 예측하고, 그 예측 결과(가장 그럴듯한 미래 경로)를 다시 다음 예측의 입력 정보로 사용하는 방식을 썼음
Behavior Cloning
- Wayformer[35] 모델의 인코더 부분을 그대로 활용하고, 그 뒤에 4층짜리 residual MLP 구조를 붙여서,
- 전문가(실제 운전자) 주행 데이터의 경로와 최대한 일치하도록(로그 우도를 극대화) 모델을 학습시킨다.
Model-free RL - DQN
- We used the Acme [19] implementation of priori- tized replay double DQN [45].
5.3. Planning BenchMark Results
- 요약: IDM을 주변 agent로 두고 자율주행 정책을 훈련하니, IDM의 양보하는 성향을 자율주행 정책이 배워서 악용해버리더라.
- RL 에이전트는 스스로 충돌을 피하는 방법을 배울 동기가 적습니다.
- 그래서 차라리, 주변 agent를 실제 dataset에서 play하여 Non-interactive 하게 학습하는게 더 낫더라.
딥 리서치의 대답
주요 기능 및 능력:
Waymax는 Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research에서 소개된 2023년 말 출시된 오픈소스 시뮬레이터로, Waymo Open Motion Dataset을 활용한 대규모 에이전트 행동 연구를 위해 설계
- Waymax는 가속도와 확장성에 중점을 두고 있으며, JAX(고성능 머신러닝 프레임워크)를 전적으로 사용하여 GPU/TPU 하드웨어에서 다수의 시뮬레이션을 병렬 실행할 수 있도록 합니다.
- 시뮬레이터는 Waymo의 모션 데이터셋으로부터 실제 시나리오(지도와 에이전트)를 로드하며, 10만 건 이상의 현실적인 주행 상황을 포함하고 있습니다.
- 이를 통해 사용자는 해당 시나리오 내에서 클로즈드 루프 상호작용을 시뮬레이션할 수 있습니다.
- 특정 시나리오에서, ego 또는 다른 에이전트는 원래의 기록된 궤적에서 벗어나 행동할 수 있으며, 시뮬레이터는 동역학 모델을 통해 이들의 상태를 시간에 따라 전파
- Waymax는 배경 에이전트에 대해 로그 재생 모드(다른 차량들이 ego의 행동을 무시하고 기록된 궤적을 그대로 따름)와 IDM 기반 반응 모델 모드를 기본 제공
- 이 IDM “트래픽 엔진”은 단순 로그 재생보다 현실적인 반응을 주입하여, 예를 들어 ego 차량이 갑자기 정지할 경우 주변 차량이 속도를 줄여 충돌을 방지하도록 합니다.
- 중요한 점은, Waymax가 모든 에이전트에 대해 사용자 정의 행동 모델을 삽입할 수 있도록 허용한다는 것입니다
- 즉, 사용자는 에이전트의 로그 재생 또는 IDM 행동을 자신이 학습한 정책(모방 학습 또는 RL)으로 대체할 수 있으며, 데이터 기반 제어를 구현할 수 있습니다.
- Waymax 자체는 사전 학습된 운전자 모델 라이브러리를 제공하지 않지만,
- 시나리오 데이터, 동역학, 평가 지표(충돌, 도로 이탈 등)를 처리하는 강력한 샌드박스로서, 연구자들이 결정 로직 개발에 집중할 수 있도록 합니다.
- 요약하면, Waymax는 실제 시나리오 데이터와 고속 시뮬레이션 코어를 결합하여, 수동 재생과 상호작용형 에이전트 행동을 모두 지원합니다.
모듈성 및 그룹 기반 커스터마이제이션:
- Waymax는 모듈식 제어를 염두에 두고 설계되었습니다.
- 시나리오 내의 각 객체(차량, 보행자 등)는
각 타임스텝마다 행동을 결정하기 위한 정책 함수가 할당될 수 있습니다. - 기본적으로, 모든 비제어 에이전트는 로그 플레이어나 파라미터화된 IDM 컨트롤러를 사용하지만, API를 통해 에이전트별로 행동을 재정의할 수 있습니다.
- 예를 들어, 시나리오에서 n대의 차량은 사용자 정의 학습 정책(알고리즘 A)을 사용하도록 지정하고, 나머지 m-n 대의 차량은 표준 IDM 모델(알고리즘 B)을 사용하도록 할 수 있습니다.
- 이는 시뮬레이션 롤아웃 전에 특정 에이전트 ID에 대해 사용자의 정책을 주입함으로써 수행됩니다.
- 이러한 그룹 지정은 매우 간단하며, 여러 정책 객체를 유지한 후 이를 각 에이전트 집합에 매핑하면 됩니다.
- 시뮬레이터의 스텝 루프는 각 에이전트의 해당 정책을 호출하여 행동을 결정합니다.
- 또한, Waymo 데이터에서 추출된 시나리오의 경우, 어떤 특정 기록된 에이전트를 교체할지 선택할 수 있어(예: 교차로를 막고 있던 트럭만을 학습된 공격적 트럭 정책으로 교체하고 나머지 차량은 IDM 사용) 세밀한 제어가 가능합니다.
- 이러한 세밀한 제어는 Waymax의 함수형 설계 덕분에 최소한의 수정으로 달성되며, ego 또한 단순한 에이전트 중 하나로 취급되어 다중 ego 시뮬레이션도 가능합니다.
다른 시뮬레이터와의 비교:
- Waymax의 가장 가까운 경쟁자는 nuPlan 및 ScenarioNet으로, 이들 모두 실제 모션 데이터셋을 시나리오의 기초로 사용합니다.
- Waymax는 Waymo 데이터셋 전용이지만, JAX 기반의 최신 엔진(병렬 처리를 위한 GPU 최적화)을 제공하여,
- 이 엄청난 속도(예: Google의 Brax 물리 엔진과 유사한 인터페이스 제공)는 대규모 테스트나 학습에 있어 독보적인 장점입니다.
- Waymax는 동시에 다수의 에이전트를 다루도록 설계되었습니다.
- 이는 복잡한 다중 에이전트 상호작용을 포함하는 Waymo 데이터셋의 규모를 그대로 활용할 수 있음을 의미합니다.
- 그러나 Waymax는 학습된 모델과 함께 사용되도록 설계되었으므로, Waymo 연구팀이 종종 학습된 주행 계획기나 예측기를 교체하여 테스트하는 방식과 맞닿아 있습니다.
- 또한, Waymax는 센서를 시뮬레이션하거나 포토리얼리즘을 제공하지 않고, 경계 상자 및 웨이포인트와 같은 추상화된 상태로 작동하여, 행동 연구에 적합하도록 설계되었습니다.
사용성, 데이터셋 통합 및 시나리오 생성:
- Waymax는 Waymo Research의 공식 발표물로서 잘 문서화되어 있으며, 튜토리얼이 제공됩니다.
- 연구자에게 무료이나 다운로드 요청을 통해 제공되는 Waymo Open Motion Dataset에 접근해야 합니다.
- 데이터셋과의 통합은 원시 tfrecord 파일을 직접 로드할 수 있을 정도로 원활하며,
- Google Cloud Storage에서 스트리밍 데이터 지원도 있어, 매우 대용량의 데이터셋을 다루는 데 유리합니다.
- 사용자 정의 에이전트 모델을 작성할 때 JAX에 익숙해야 하며, 간단한 Python 함수로 프로토타입을 작성할 수도 있습니다.
- 또한, 로그 분포, 충돌, 도로 이탈 등 시뮬레이션과 원본 로그 또는 서로 다른 컨트롤러 간의 차이를 정량적으로 평가할 수 있는 평가 지표도 포함되어 있습니다(Waymax Metrics).
- 시나리오 생성 측면에서는, Waymax 자체는 새로운 지도나 교통 흐름을 생성하지 않고, Waymo 데이터셋에서 제공된 시나리오에 의존합니다.
- 그러나, 해당 데이터셋이 다양한 조건을 포함하고 있기 때문에, 관심 있는 시나리오(예: 보호받지 못한 좌회전 상황)만 선택하여 사용할 수 있습니다.
- 내장된 랜덤 시나리오 생성기는 없지만, 불러온 시나리오의 초기 조건(예: 차량의 시작 속도 또는 위치)을 수정하여 변형을 만들고, 강건성을 테스트할 수 있습니다.
- 모듈성은 강력하여, 새로운 모델을 추가할 때 시뮬레이터 핵심 코드를 수정할 필요 없이, 해당 에이전트에 대해 함수를 전달하면 됩니다.
- Waymax는 함수형 및 벡터화된 설계 덕분에 복잡도가 증가해도 결정론성과 속도를 유지할 수 있습니다.
장점:
- 진정한 데이터 기반 시나리오: Waymo의 실제 주행 시나리오(고도로 상세하며 다수의 에이전트를 포함)를 직접 사용하여, 수작업 없이도 높은 현실감을 제공합니다(Waymax).
- 고성능 (JAX): GPU/TPU에서 JIT 컴파일된 물리 및 병렬 처리를 통해 시뮬레이션을 극도로 빠르게 실행할 수 있어, 수백만 스텝 또는 수천 개의 시나리오를 병렬 실행할 수 있습니다.
- 사용자 정의 모델 지원: 사용자 정의 에이전트 모델을 쉽게 통합할 수 있으며, 각 차량에 대해 서로 다른 제어기를 할당하여 이종 운전자 집단(예: 인간 유사 정책과 로봇 정책의 혼합) 실험이 가능합니다.
- 내장 평가 지표 및 안전 검사: 충돌, 도로 이탈 등 표준화된 평가 지표를 제공하여, 시뮬레이션 결과가 실제 운전자 데이터와 얼마나 일치하는지 정량적으로 평가할 수 있습니다.
- 전문가에 의한 활발한 개발: Waymo 연구팀이 개발하여 실제 자율주행 평가 요구에 부합하며, 오픈소스로 공개되어 사용자 기반이 꾸준히 성장하고, 지속적인 업데이트가 예상됩니다.
단점:
- 데이터셋 특이성: 기본적으로
Waymo Open Motion Dataset 포맷만 지원하므로, 다른 데이터셋(nuScenes, Argoverse) 시나리오를 사용하려면 변환 코드 작성 또는 확장이 필요 - 사전 학습된 모방 모델 부재: 내장된 트래픽 행동은 로그 재생 또는 단순한 IDM 모델에 의존하므로, 진정한 인간과 유사한 반응형 교통을 구현하려면 사용자가 직접 모방 학습 모델을 학습하여 삽입해야 합니다.
- 추상적 시뮬레이션 (센서 미지원): Waymax는 카메라 이미지나 라이다 스캔을 생성하지 않고, 경계 상자와 웨이포인트 등 추상적인 상태 정보만 제공하여, 엔드투엔드 자율주행 테스트에는 적합하지 않습니다.
- JAX 학습 곡선: JAX 및 함수형 프로그래밍 스타일에 익숙해야 최대 성능을 활용할 수 있으며, 기존의 Python OOP 인터페이스에 익숙한 개발자에게는 다소 어려울 수 있습니다.
- 제한된 시나리오 편집: 시나리오가 로그에서 제공된 실제 상황에 기반하므로, 지도 및 초기 조건이 고정되어 있으며, 임의의 도로망이나 교통 흐름을 새롭게 설계하기에는 한계가 있습니다.

ad_official