해야할 것
- 종료 조건
- 원래: 목적지 도착 / 최대 스텝 초과 / 차선 이탈 / 충돌(차량/물체/인도) / 사람 이동체 충돌 등
- 추가해야할 것: 최대 스텝 초과하면 끝나도록 (20초?)
- N개 시나리오를 돌리고, 종료하도록 하기
- 추후: DiffusionPlannerEnv 를 아래 2가지 목적에 맞게 나눠야 함
- RL 학습용
- 평가용
- 알아야 할 것
- 지금은 어떤 시나리오가 어떤 기준으로 나오는지 잘 모르겠음
- 아래와 같은 것들은 수행하긴 함
- 차선 갯수 다양화, 차로 폭 다양화, 차량 밀도 다양화
- 제한 속도 다양화
- 사고 확률 다양화
- 다양한 도로 구조가 나오는데, 이는 어떻게 나오는건지?를 확인해야함
- 아래와 같은 것들은 수행하긴 함
- 지금은 어떤 시나리오가 어떤 기준으로 나오는지 잘 모르겠음
전체 큰그림
1. 전체적인 역할
- DiffusionPlannerEnv는 MetaDrive 시뮬레이터를 기반으로 만들어진, “확산 기반 주행 계획(diffusion planning)” 연구용 환경입니다.
- 쉽게 말해, 자율주행차가 다른 차량들의 미래 움직임을 동시에 예측·제어하면서,
- 본인(ego) 의 경로를 계획 · 검증할 수 있도록 특화된 실험 무대를 제공하는 것이 목적
2. 구성 요소와 동작 흐름
-
환경 설정(컨피그)
-
기본 엔진 설정(BaseEnv) → MetaDrive 기본 설정 → DiffusionPlanner 전용 설정의 세 단계를 합쳐 하나의 최종 설정을 만듭니다.
-
여기서 DiffusionPlanner 전용 설정은
차로 폭·차로 수 무작위화구간별 최고·최저 속도 제한사고 확률,관측 범위,트래픽 밀도등을 따로 지정
등 다양한 시나리오 변형을 켜 두어 일반화 능력을 시험할 수 있게 합니다.
-
-
지도와 트래픽 관리
SpeedLimitPGMapManager가 블록 기반 도로를 만들고, 각 블록에 속도 제한을 부여합니다.DiffusionTrafficManager는 NPC 차량을 생성·관리합니다.
필요하면TrafficObjectManager가 사고/장애물도 추가해 돌발 상황을 만듭니다.
-
관측(Observation)
DiffusionPlannerObservation클래스가 제공하는 전용 센서 패키지를 사용
예) 차량·차선 위치, 주변 차량의 과거 궤적 등 → 확산 모델이 바로 사용할 수 있는 형태로 가공.
-
행동 정책(Policy)
- 기본값은 LQR(선형‑이차 레귤레이터) 로 안전한 데모 주행을 합니다.
- 연구자가 직접 작성한 Diffusion Planner를 대체 삽입하면, 곧바로 훈련·평가가 가능합니다.
-
외부 NPC 제어 인터페이스
-
set_external_npc_actions()함수로- 크기: (NPC 수, 예측 길이, 4차원 제어)
(4차원은 일반적으로 처럼 위치·속도·방향) - 0으로 채워진 행(row)은 무시하여 필요한 NPC만 부분 변경
하는 식으로 외부 모델이 계산한 다수 차량의 미래 제어를 주입할 수 있습니다.
- 크기: (NPC 수, 예측 길이, 4차원 제어)
-
-
엔진 단축키
r리셋,p일시정지,b탑뷰 전환 등 실험 중 빠른 반복·시각화를 지원합니다.
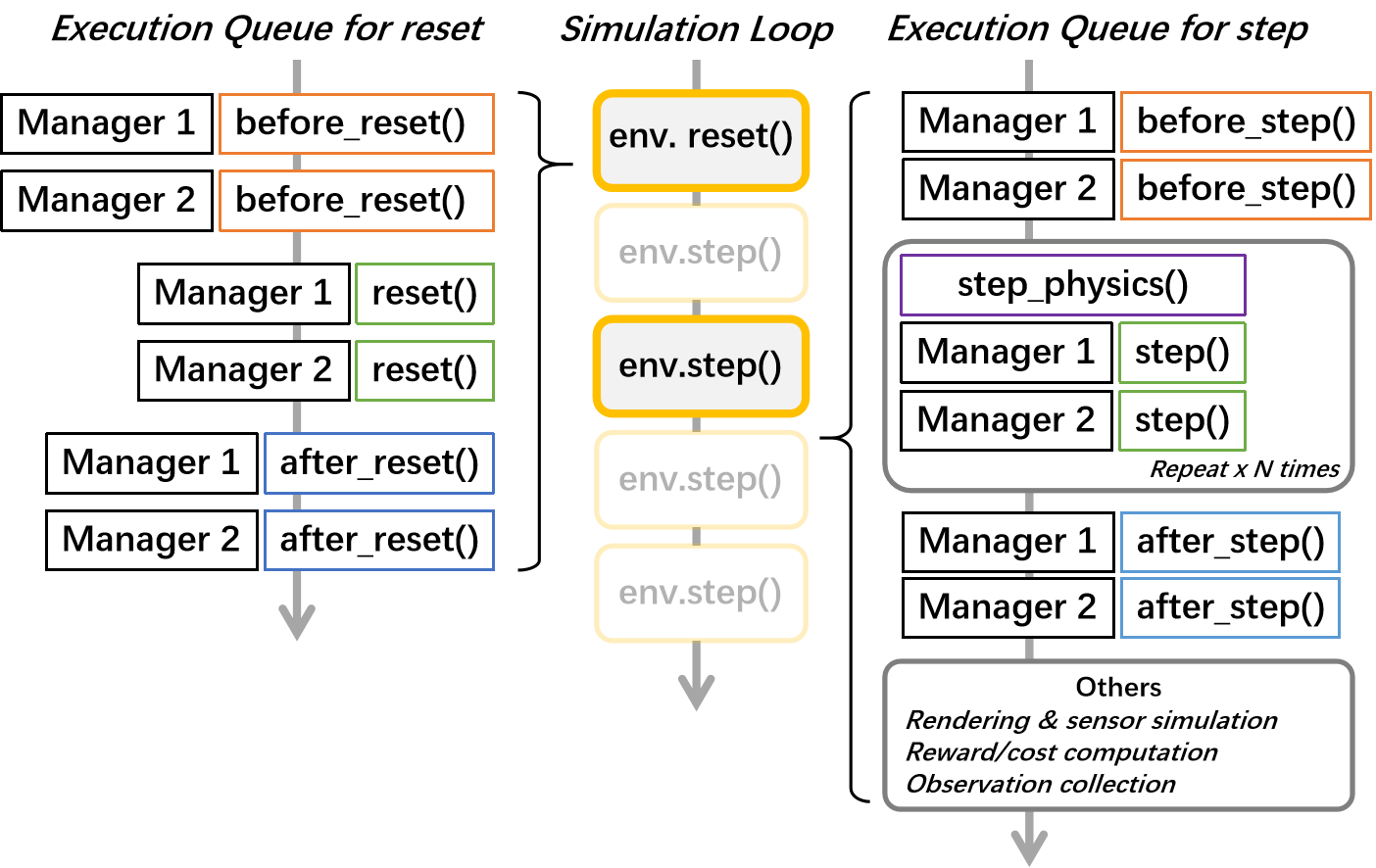
3. 한 타임스텝(step)의 내부 알고리즘
-
행동 수집
- 연구자가 넘긴 ego 행동
DiffusionTrafficManager나set_external_npc_actions()에서 채워진 NPC 행동을 모읍니다.
-
시뮬레이터 진행
- 실제 물리 시간 를 여러 번 잘게 쪼개서(결정 반복) 차량 상태를 업데이트합니다.
-
보상 계산
핵심식은 다음과 같이 요약할 수 있습니다.-
: 진행 거리 × 차로 중심 유지 정도
-
: 현재 속도 비율
-
: 도착(+), 충돌·차선이탈(−) 등 종료 이벤트 보상/패널티
-
-
종료 조건
- 목적지 도착, 최대 스텝 초과, 차선이탈, 충돌(차량·물체·인도), 사람이동체 충돌 등.
-
관측·정보 반환
- 다음 스텝에 사용할 관측, 보상, 종료 플래그, 그리고 통계 정보를 에이전트에게 돌려줍니다.
4. DiffusionPlannerEnv만의 특징 정리
- 다차선·가변 차로 지도 + 속도 제한이 혼합되어 보다 현실적인 규제 환경을 재현합니다.
- 교통 밀도 0 상태부터 연구자가 직접 NPC 행동을 전부 생성할 수 있어
다중 참여자 계획(multi‑agent planning) 실험에 탁월합니다. - 관측 범위·사고 확률·속도 한계 등을 매 에피소드마다 바꾸는 설정이 기본이라
일반화 학습과 로버스트 테스트가 용이합니다. - 기본 LQR로 “안전 주행 예시”를 보여주지만, 코드 한 줄로 Diffusion 기반 정책으로 대체 가능합니다.

ad_official