교원dacon_논문 reading
CtC loss
Intro
- 음성인식이나 문자인식(OCR)에서 target sequence와 output sequence 길이가 다를때, ouput 길이가 target보다 길때, loss function을 정의하는 방법
- 'hello'라는 음성 파일로부터 -> 'hello'라는 text를 만드는 것이 목적
=> 'hhhellloo'와 같은 형태로 문자열을 만들어 냄
- 음성 속도가 일정하지 않아 합쳐야하는 character와 합치지 않아야하는 character를 구분할 필요가 있다
blank 개념
- 연속된 같은 character는 하나로 합치고(merger), 실제 연속된 character는 다르게 처리하기 위한 개년
- 실제 연속된 character 사이에는 blank를 넣은 형태로 모델이 예측하게 만듬
- hello => 'l','-','-','l'- apple => 'p','-','p'
- blank가 1개 이상 사이에 들어가는 것도 가능
- blank 개념이 도입되면서, 주어진 GT가 될 수 있는 output이 여러개 될 수 있음
optimizaton
- blank 개념에 따라, 여러개의 output에 대한 확률을 모두 합해 최대화 될 수 있도록 optimization을 수행
- GT(target)이 'a'라면 Prediction이 'a'가 될 수 있는 모든 output의 확률 합이 최대화 될 수 있도록 optimizton- prediction이 'a'(GT)가 되는 모든 경우를 찾아 확률을 합함 : (aa,a-,-a)=> dynamic programming 기법 사용
use
- 텍스트를 인식하는 컴퓨터를 필요로 할때,
- 피처 시퀀스를 추출하는 CRNN과 시퀀스로부터 정보를 전파하는 RNN…
- 각각의 시퀀스 요소에 대한 문자의 점수를 출력해 행렬로 표현한다.
- TRAIN
- INFER
- CTC의 사용 이유
- text-lines의 이미지가 있는 데이터셋을 생성
- 각 이미지의 수평 위치에 대해 일치하는 문자를 지정
- 각각의 수평적인 위치에 문자 점수를 출력하도록 뉴럴 네트워크를 학습
- 문제
- 데이터 셋에 어노테이션을 생성하는 것은 시간이 많이 걸린다.
- 문자 단위 점수만 얻기 때문에, 최종 텍스트를 얻기 위해서는 몇몇 추가적인 과정이 필요
- 하나의 문자는 여러 개의 수평 위치에 걸처져 있을 수 있따.
- 예를 들어 ‘o’는 넓은 문자이기 때문에 ‘ttooo’를 얻게된다. ⇒ 모든 중복된 t와 o를 제거해야 함
- BUT 원래 텍스트가 ‘too’일 때, 모든 중복된 ‘o’를 제거하면 잘못된 결과를 얻게 된다.
⇒ 문제 해결 필요 ⇒ CTC로 2가지 문제 해결 가능- 이미지에서 발생된 텍스트의 CTC loss function에 대해만 언급해야 한다.
- 이미지 속의 위치와 문자의 넓이는 무시
- 인식된 텍스트에 대해 추가적인 처리가 필요하지 않다.
- 이미지에서 발생된 텍스트의 CTC loss function에 대해만 언급해야 한다.
CTC 작동 원리
- 각각 수평적인 위치의 이미지를 어노테이션 하는 것을 원치 않는다.
- 뉴럴 네트워크의 아웃풋 행렬 그리고 일치하는 ground-truth(GT) 텍스트 만을 CTC loss function에 제공- 어디서 각각의 문자가 발생되는지 어떻게 알 수 있을까?
- 알 수 없다.
- 이미지에서 GT 텍스트의 모든 가능한 정렬(조정)을 시도하고 모든 점수의 합계를 취한다.
- 각 정렬의 합계가 높은 값을 가지면 GT 텍스트의 점수도 높은 값을 가진다.
- 어디서 각각의 문자가 발생되는지 어떻게 알 수 있을까?
- Encoding the text
- 중복된 문자 어떻게 인코드 하는지의 이슈
- pseudo-character(blank)로 해결
- 특별한 문자는 다음의 텍스트에서 ‘-’로 표시되어진다.
- (중복 문자 문제를 해결하기 위해 코딩 스키마를 사용)
- 텍스트 인코딩 시, 어떤 위치에든 임의의 많은 blank를 넣을 수 있다.
- 그리고 blank들은 디코딩할 때 제거됨
- 특별한 문자는 다음의 텍스트에서 ‘-’로 표시되어진다.
Loss calculation
- 뉴럴 네트워크에 훈련시키기 위해 주어진 이미지와 GT텍스트의 쌍에 대한 loss 값을 계산할 필요가 있다.
- 뉴럴 네트워크가 매 타입 스텝에 각각의 문자의 점수를 포함하는 행렬을 출력
- 손실 값은 GT 텍스트의 모든 정렬 가능한 점수가 합해짐으로서 계산된다.
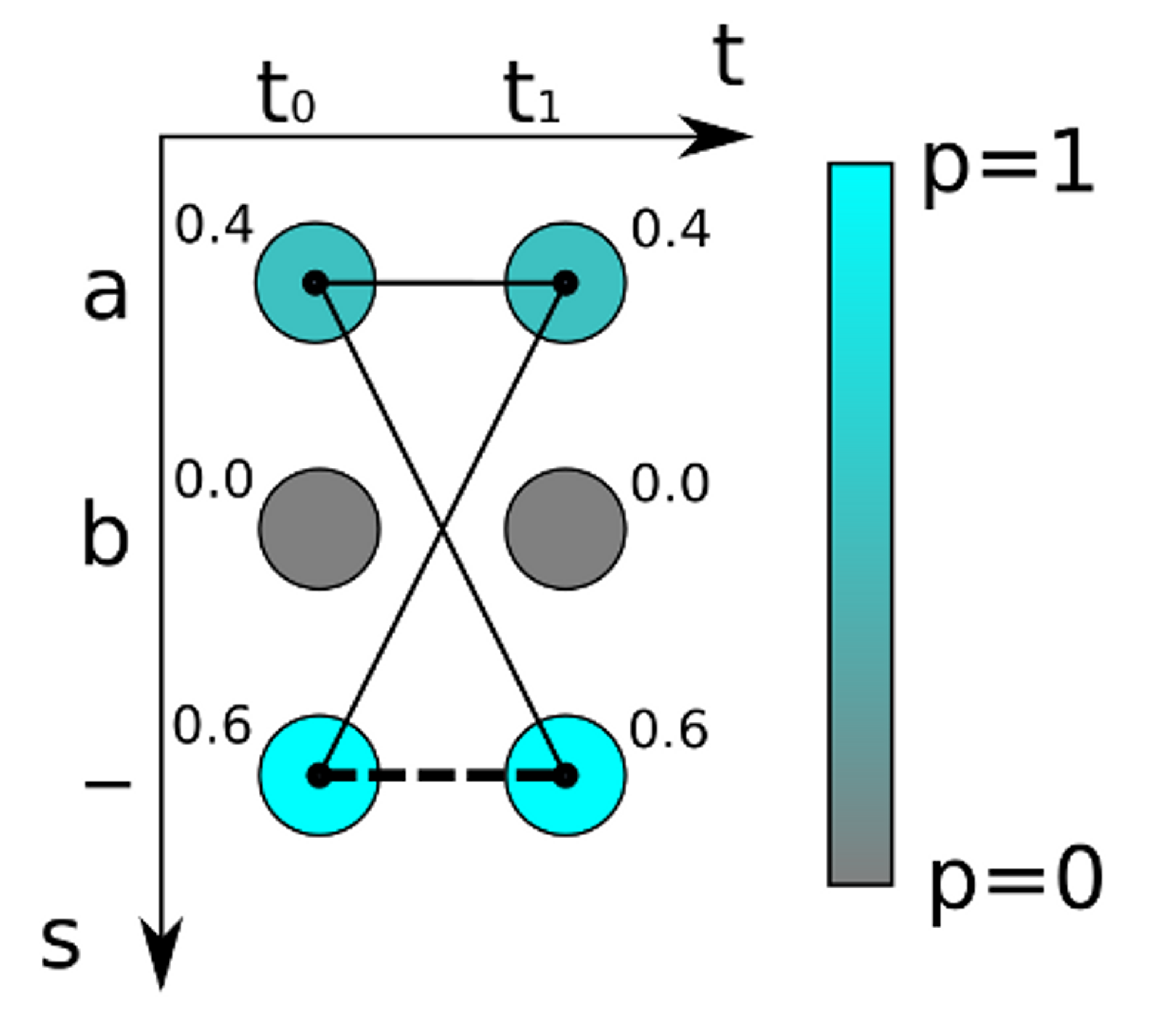
- Dynamic Programming 기법 사용
- 이동 규칙을 적용해 path를 만든다

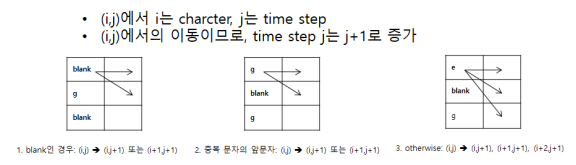
- apple 이 될 수 있는 valid path에 따라 순환식을 만들어 Forward, Backward Computation 적용
Decoding
- Best path decoding
- 타임 스텝마다 가장 가능성이 높은 문자를 채택함으로써 최고의 길을 계산- 중복 문자를 먼저 제거하면서 인코딩을 하지 않는다. 그 길에 있는 모든 blank를 지운다. 남아있는 문자는 인식된 텍스트
- 중복 문자를 먼저 제거하면서 인코딩을 하지 않는다. 그 길에 있는 모든 blank를 지운다. 남아있는 문자는 인식된 텍스트
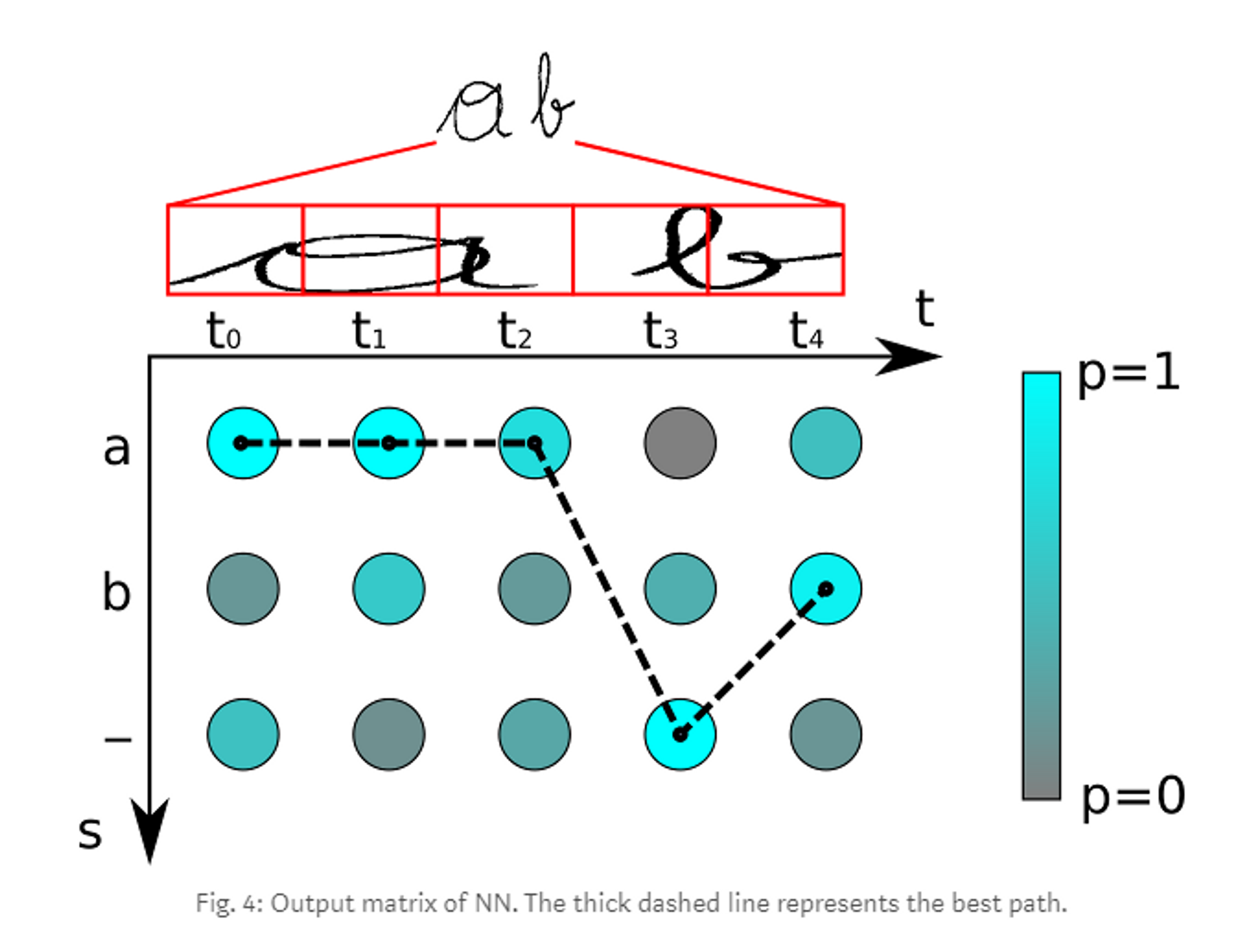
- ‘a’,‘b’, ‘-’로 구성된 문자 / 5번의 타임 스텝
- 이 행렬의 최고의 길을 찾는 디코더를 적용
- t0에서 가장 가능성이 높은 문자 ‘a’- t1 : t0와 같음
- t2 : t0와 같음
- t3 : blank가 높은 점수
- t4 : ‘b’가 가장 가능성이 높다
⇒ ‘aaa-b’ 라는 경로를 줌 ⇒ 중복된 문자를 제거 ⇒ ‘a-b’가 남는다
⇒ 남아있는 경로에서 blank를 제거 ⇒ 그러면 인식된 텍스트로서 ‘ab’라는 결과 출력
reference
https://soyoung-new-challenge.tistory.com/16
CTC(Connectionist Temporal Classification)-조희철

https://zybuluo.com/bothbest/note/2620977
https://medibulletin.com/author/chinabamboo/
https://thefwa.com/profiles/chinabamboo
https://www.politforums.net/profile.php?showuser=chinabamboo
https://tutorialslink.com/member/ChinaBamboo/68662
https://schoolido.lu/user/chinabamboo/
https://backloggery.com/chinabamboo
https://www.catapulta.me/users/chinabamboo
https://party.biz/profile/327933
https://wearedevs.net/profile?uid=202610
https://my.usaflag.org/members/chinabamboo/profile/
https://malt-orden.info/userinfo.php?uid=414587
https://womenindata.mn.co/members/35670855
https://givestar.io/profile/26482d73-cc4c-4e15-8a36-31a21bcbd467
https://aisalon.mn.co/members/35670809
https://pathwaycitychurch.mn.co/members/35670788
https://www.yourquote.in/china-bamboo-bfc-d1dpf/quotes
https://noti.st/chinabamboo
https://www.tkaraoke.com/forums/profile/chinabamboo/