Chapter 📗 5. 모집단과 표본 분포
📝 (1) 모집단(Population)과 표본(Sample)
📝 (2) 표본 분포
.
.
📗5. 모집단과 표본 분포
📝(1) 모집단(Population)과 표본(Sample)
모집단
표본
평균
μ
X
분산
σ2
s2
.
1) 표본추출(Sampling)
모집단으로부터 표본을 추출하는 것, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론하고자함
복원추출: 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출될 수 있다.
비복원추출: 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법
Random Sampling): 모집단에서 데이터를 추출할 때 편향되지 않도록 각 개체가 모두 동일한 확률로 추출하는 방법
그런데 데이터가 불균형 데이터(Imbalanced Data)일 경우 문제가 생긴다! 이럴 때에는 Sampling 기법을 통하여 해결하거나, 모델을 통한 성능을 개선해야 한다. 이번 시간에는 Sampling 기법에 대해서 알아본다.
2) Sampling 기법 - 관심 대상의 비율이 낮은 경우
Over Sampling
타켓 데이터의 적은 class의 수를 많은 class의 비율만큼 증가 시킨다.(일정 비율로 복원추출하는 개념)
과도 적합의 문제가 발생할 수 있다는 문제가 있다.
Under sampling
타켓 데이터의 많은 class의 수를 적은 class의 비율만큼 감소시킨다.
임의로 뽑은 데이터가 편향될 수 있고, 모형의 성능이 떨어질 수 있다는 문제가 있다.
.
.
📝(2) 표본 분포
1) 통계량(statistic)
표본에 기초하여 계산되는 수치
대표적으로 Xˉ와 s2가 있다.
표본분포(sampling distribution): 통계량들이 이루는 표본 분포
표본 평균Xˉ의 기댓값과 분산 E[Xˉ]=E[n1(x1+x2+...+xn)]=n1(E[x1]+E[x2]+...E[xn])=n1nμ=μ var[Xˉ]=var[n1(x1+x2+...+xn)]=n21(var[x1]+var[x2]+...+var[xn])=n21nσ2=nσ2
2) 표본분포
모집단의 분포가 N(μ,σ2)이라고 할 때,
확률표본 X1,X2,X3,...,Xn은 ~ iidN(μ,σ2) 를 따른다. Xˉ ~ N(μ,nσ2), Z ~ N(0,1)
중심극한 정리: 평균이 μ이고 분산이σ2인 임의의 모집단에서 랜덤표본 X1,X2,X3,...,Xn을 추출할 때 표본의 크기 n이 충분히 크면(n≥30), 표본 평균 Xˉ는 근사적으로 정규분포 N(μ,nσ2)를 따른다. Z=σ/nXˉ−μ ~ N(0,1)
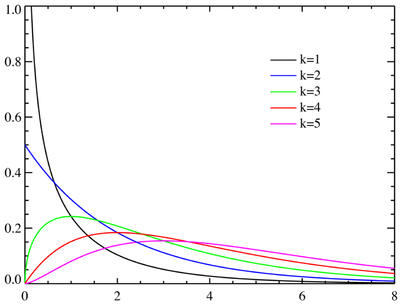
3) 카이제곱 분포(Chi-square distribution)
확률 변수 Z12,Z22,...,Zn2가 표준 정규 분포를 따른다면, 확률 변수 Z는 Z12+Z22+...+Zn2
Z ~ χ2(ν), Z가 카이제곱분포를 따를 때 f(x:ν)=2ν/2Γ(ν/2)1x2ν−1e−x/2,(x>0) E[X]=ν var[X]=2ν
카이제곱 분포는 감마분포에서 α=2ν,λ=2와 같다.
카이제곱 분포는 범주형 자료분석에서 활용한다.
자유도(df): 표본수-제약조건의 수 또는 표본수-추정해야 하는 모수의 수를 의미하며 일반적으로 n-1을 사용한다.
카이제곱 분포는 자유도 ν의 크기에 따라 모양이 달라진다.
카이제곱 분포는 자유도가 커질수록 분포가 좌우대칭 형태가 된다.(표준정규분포에 근사한다.) ν≥30이면 확률을 근사적으로 정규분포로 구할 수 있다.
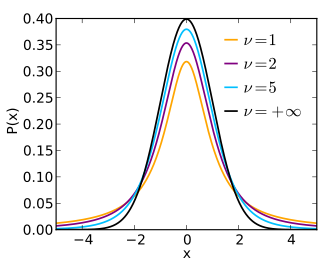
4) T분포(t-distribution)
Z ~ N(0,1)을 따르고, Y ~ χ2일 때, T=Y/νz를 따른다.
만약 확률변수 X가 정규분포를 따르고 모표준편차 σ를 안다면, z=σ/nx−μ ~ N(0,1)
만약 모표준편차 σ를 모른다면, σ를 대신해서 표본표준편차 s를 이용하여 확률변수 Z를 정의한다. t=σ/nx−μ ~ t(ν), 여기서 ν의 자유도는 n-1이다.
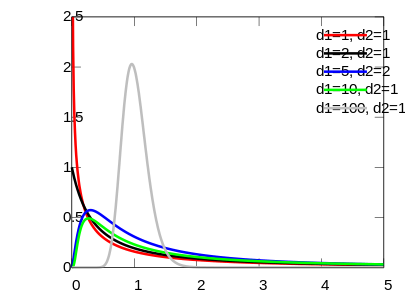
5) F분포(F-distribution)
서로 독립인 두 정규모집단의 분산 또는 표준편차들의 비율에 대한 통계적 추론, 분산분석 등에 활용된다.
Y1 ~ χ2(ν2), Y2 ~ χ2(ν2) 이면, F ~ Y2/ν2Y1/ν1,(F>0)
두 개의 독립적인 모집단 (Y1,Y2)으로부터 각각 표본을 추출했을 때 Y1~σ12(n−1)s12~χ2(n1−1), Y2~σ22(n−1)s22~χ2(n2−1)
F분포는 아래와 같다. F=Y2/ν2Y1/ν1=σ12(n−1)s2/(n−1)σ12(n−1)s2/(n−1)=s22/σ22s12/σ12 ~ F(n1−1,n2−1)