❗ 주제: 타이타닉
❗ 목표: 타이타닉호 탑승객의 정보를 활용하여, 이들의 생존여부를 예측하는 모델 만들기
- 참고: 분석 코드는 이유한님의 분석본으로 블로그(https://kaggle-kr.tistory.com/17?category=868316)의 튜토리얼을 보고 필사하였습니다.
🚢 1. Dataset Check
분석에 앞서 사용할 라이브러리를 불러왔습니다. 이번에 missingno라는 라이브러리를 처음 사용해봤는데, 결측치를 시각화하는 작업에 사용했습니다.

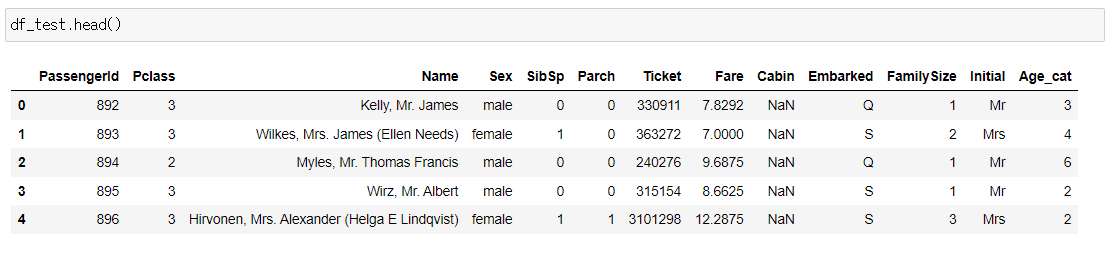
첫 번째 작업으로 데이터셋의 Null data와 Target label을 살펴보는 작업을 했습니다. 먼저 사용할 데이터셋을 살펴보겠습니다.
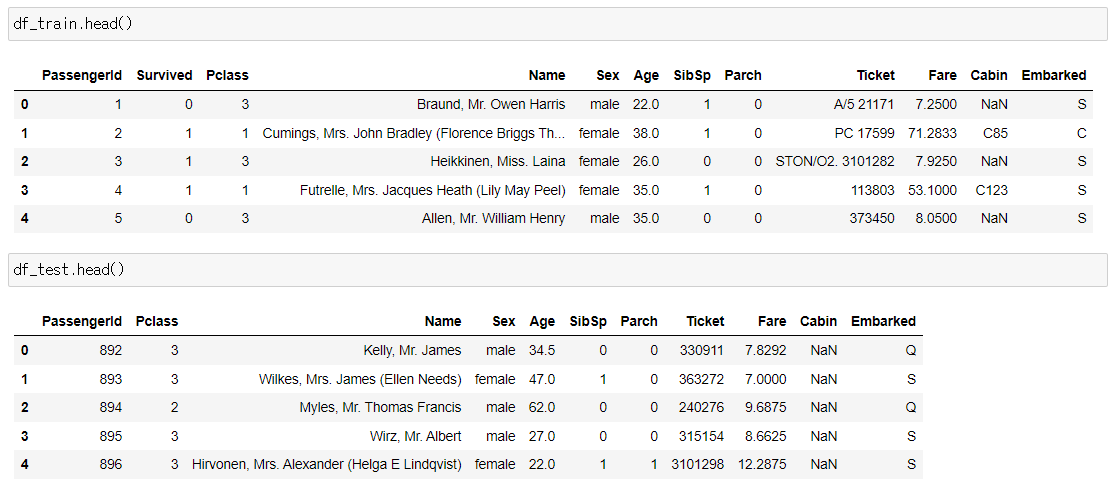
문제에서 다루는 feature는 Pclass, Age, SibSp, Parch, Fare이며, 예측하려는 target label은 Survived입니다. 각 컬럼들은 다음과 같은 정보를 가지고 있습니다.
- Survived: 생존여부. 1과 0으로 표현
- Pclass : 티켓의 클래스. 1=1st, 2=2nd, 3=3rd를 클래스로 나눔
- SibSp : 함께 탑승한 형제와 배우자의 수
- Parch : 함께 탑승한 부모, 아이의 수
- Ticket : 티켓 번호
- Fare : 탑승료
- Cabin : 객실 번호
- Embarked : 탑승 항구
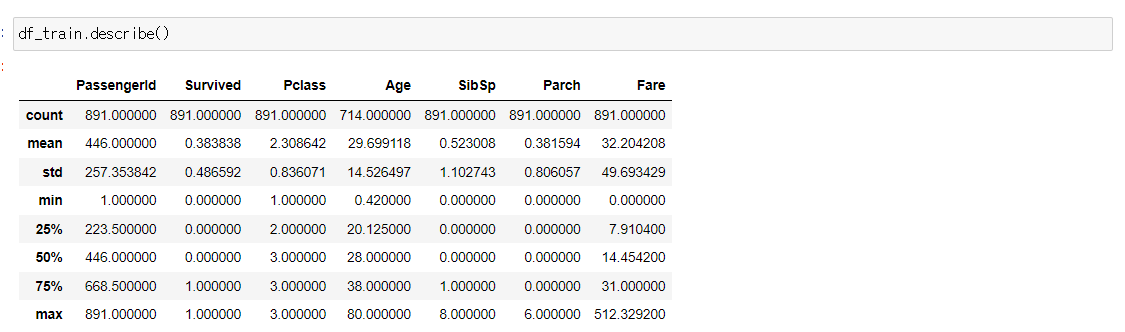
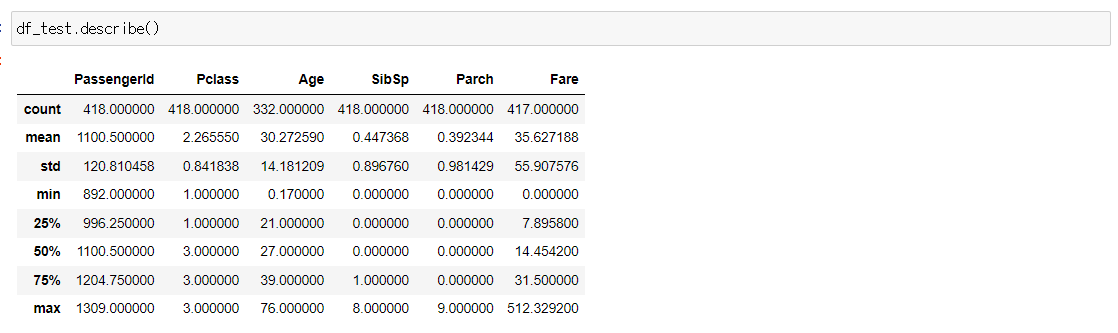
데이터셋의 통계량도 확인해봅니다.
1.1 Null Data Check
몇 개의 컬럼에 들어있는 Null data를 확인해보고 시각화하여 살펴봅니다. 각 컬럼의 Null data들의 비율을 수치로 확인해보겠습니다.
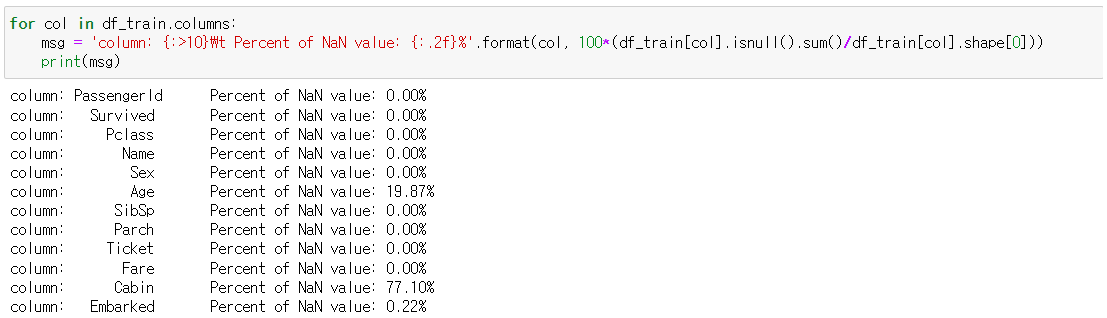
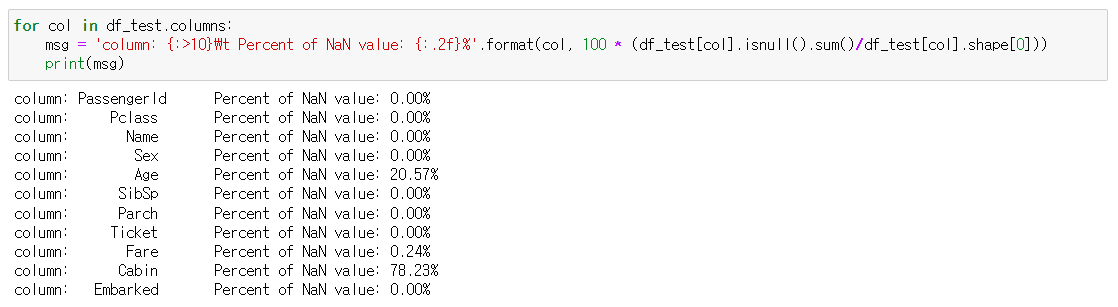
train과 test set에서 Age(둘 다 약 20%), Cabin(둘 다 약 80%), Embarked(train만 0.22%) null data가 존재하는 것을 확인 할 수 있습니다. 이제 Null data를 시각화하여 한 눈에 쉽게 확인해보겠습니다.
msno.matrix(df=df_train.iloc[:,:], figsize=(8,8), color=(0.8, 0.5, 0.2))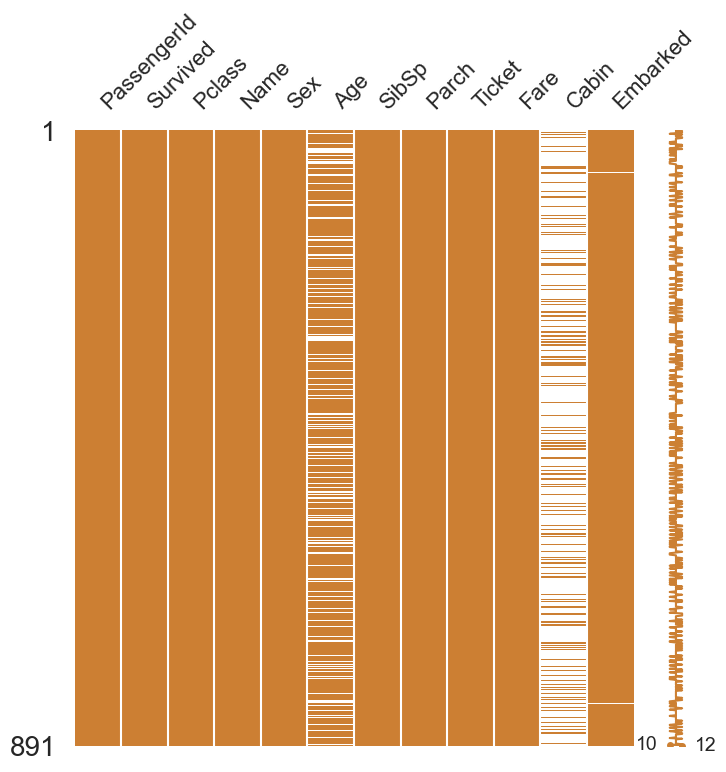
msno.matrix(df=df_test.iloc[:,:], figsize=(8,8), color=(0.8, 0.5, 0.2))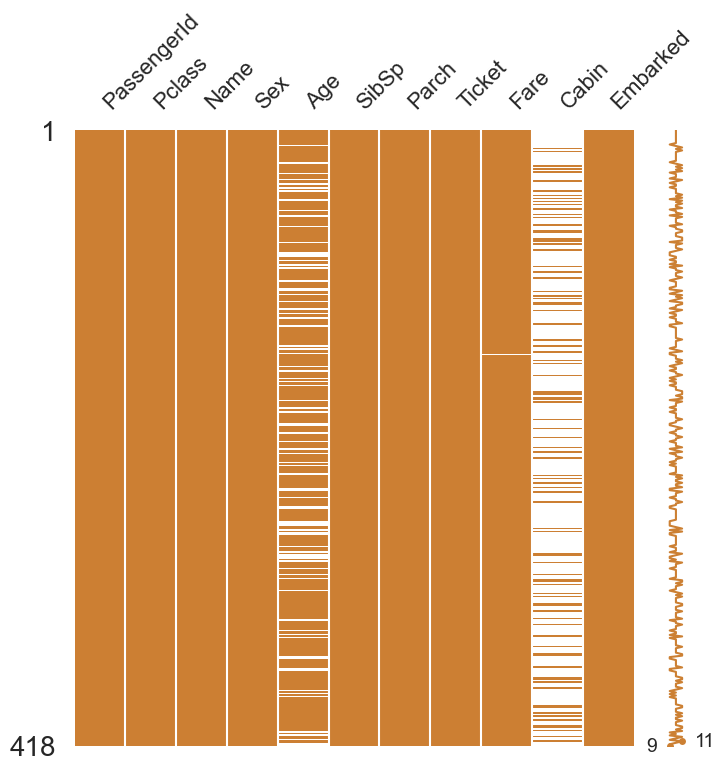
좀 더 수치자료를 확인해보는 방법으로도 시각화해봅니다.
msno.bar(df=df_train.iloc[:,:], figsize=(8,8), color=(0.8, 0.5, 0.2))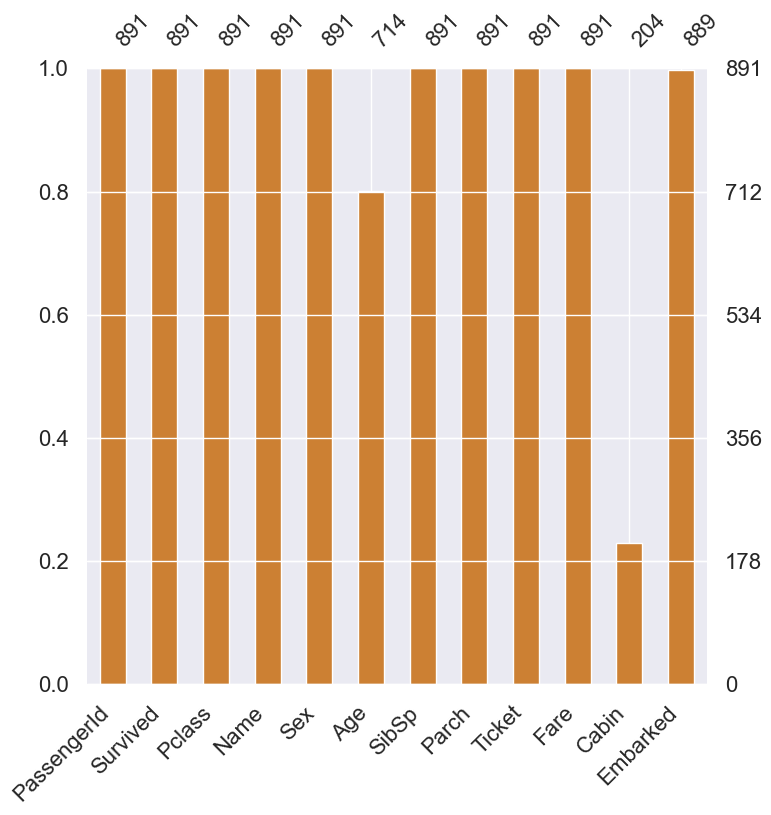
msno.bar(df=df_test.iloc[:,:], figsize=(8,8), color=(0.8, 0.5, 0.2))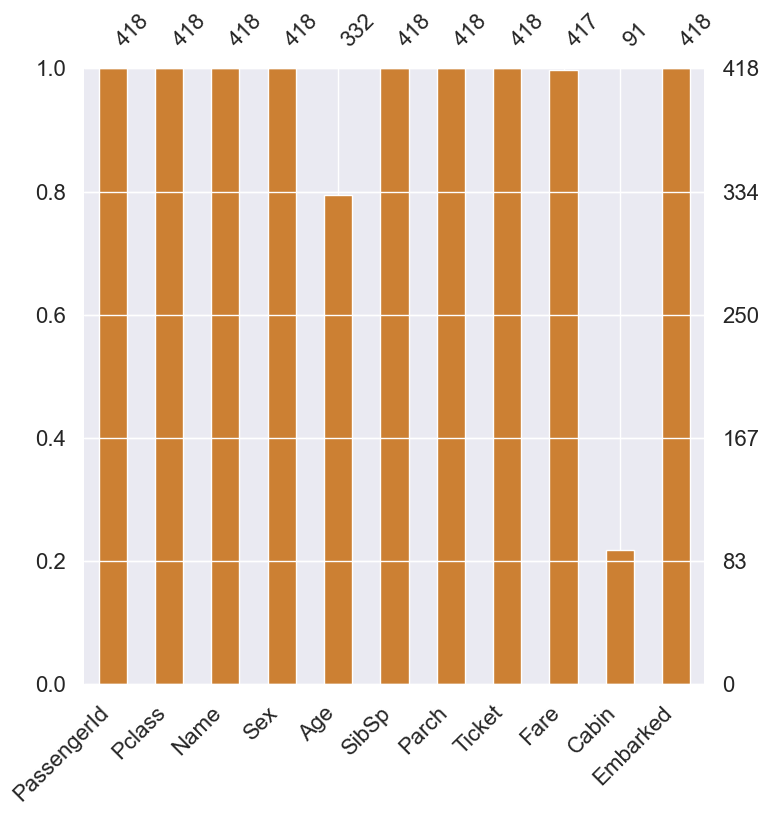
위와 같이 그래프로 Null data가 존재하는 컬럼의 종류가 그 양의 정도를 시각화하여 알아볼 수 있습니다.
1.2 Target Label Check
target label('Survived')의 분포도를 확인해보겠습니다.
f, ax = plt.subplots(1,2, figsize=(18,8))
df_train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie plot - Survived')
ax[0].set_ylabel('')
sns.countplot(data=df_train, x='Survived', ax=ax[1])
ax[1].set_title('Count plot - Survived')
plt.show()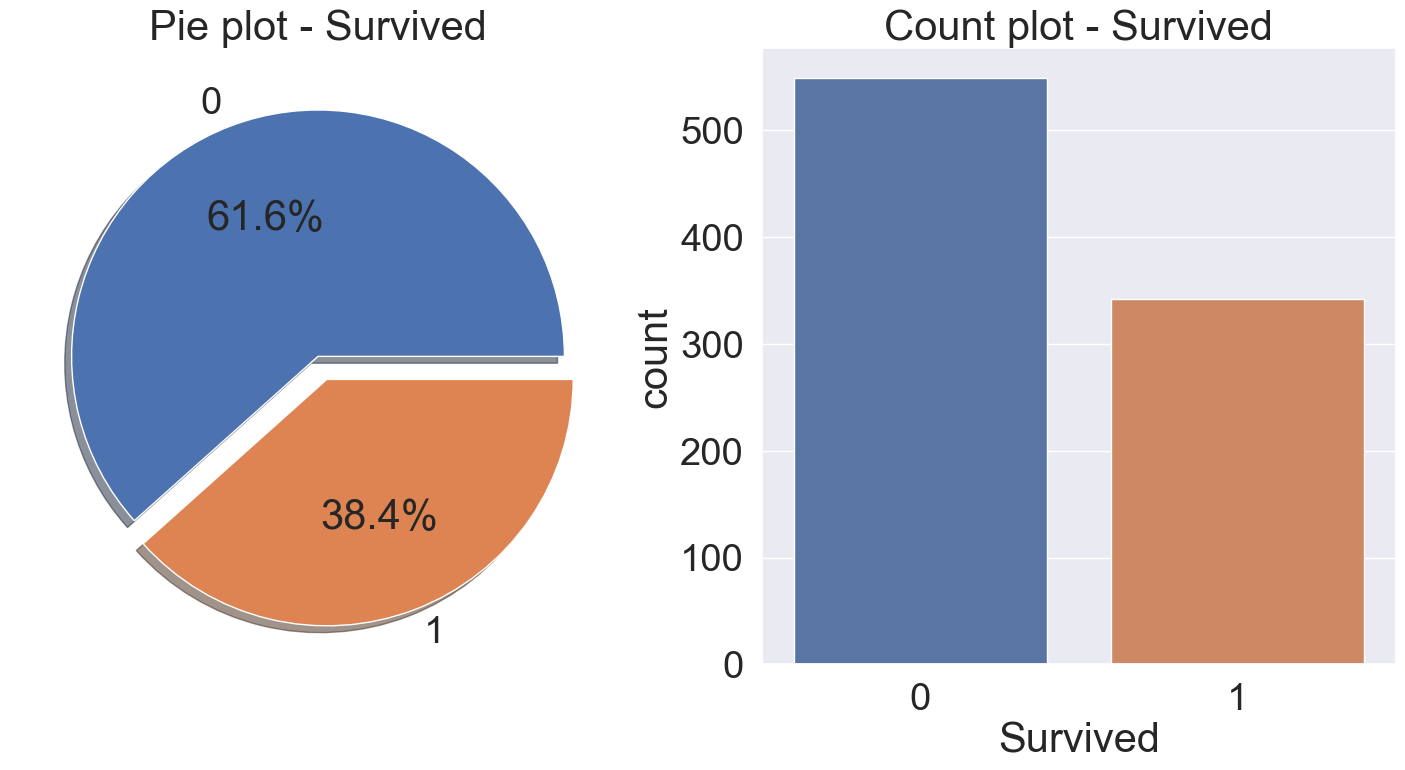
🚢 2. Exploratory Data Analysis(EDA)
여러 feature들을 개별적으로 분석하고, feature들 간의 상관관계 확인해봅니다. 여러 시각화 툴을 사용하여 insight를 얻는 작업을 합니다.
2.1 Pclass
Pclass는 티켓의 등급을 3단계로 구분하였으며, ordinal, 서수형 데이터입니다. 먼저 Pclass에 따른 생존률의 차이를 살펴보겠습니다.
'Pclass', 'Survived'를 가져온 후, pclass로 묶습니다. 그러고나면 각 pclass마다 0,1이 count가 되는데, 이를 평균내면 각 pclass별 생존률이 확인됩니다.
아래와 같이 count()를 하면, 각 class에 몇 명이 있는지 확인할 수 있으며, sum()을 하면 216명 중 생존(survived=1)한 사람의 총합을 알 수 있습니다.
# Pclass별(티켓의 등급별) 인원수
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).count()
# Pclaass별(티켓의 등급별) 생존자의 인원수
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).sum()
crosstab을 활용해서 수치정보와 시각화를 동시에 할 수 있습니다.
pd.crosstab(df_train['Pclass'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')
groupby() 메서드를 활용하여 각 클랙스별 생존률의 평균을 구한다음, 막대그래프로 시각화하여 확인해봅니다.
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar()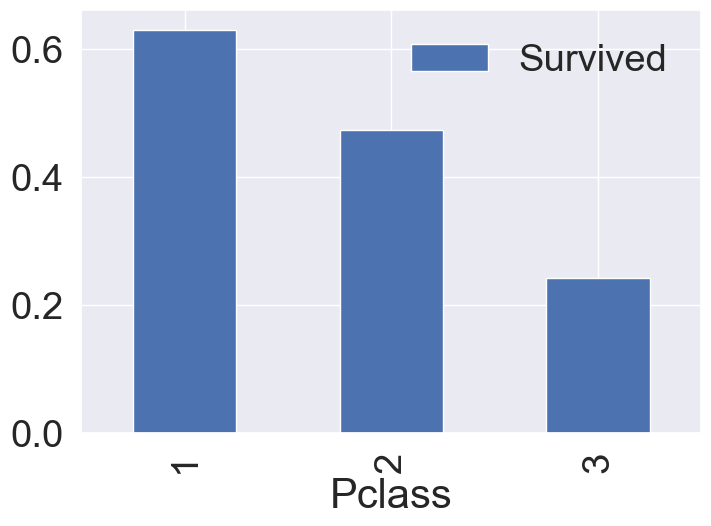
Pclass가 높을 수록(1st) 생존률이 높은 것을 확인할 수 있습니다.
seaborn의 countplot을 이용하여 특정 label에 따른 개수를 확인해 보겠습니다.
y_position=1.02
f, ax = plt.subplots(1, 2, figsize=(18,8))
df_train['Pclass'].value_counts().plot.bar(color=['#CD7F32', '#FFDF00', '#D3D3D3'], ax=ax[0])
ax[0].set_title('Number of Passengers by Pclass', y=y_position)
ax[0].set_ylabel('Count')
sns.countplot(data=df_train, x='Pclass', hue='Survived', ax=ax[1])
ax[1].set_title('Pclass: Survived vs. Dead', y=y_position)
plt.show()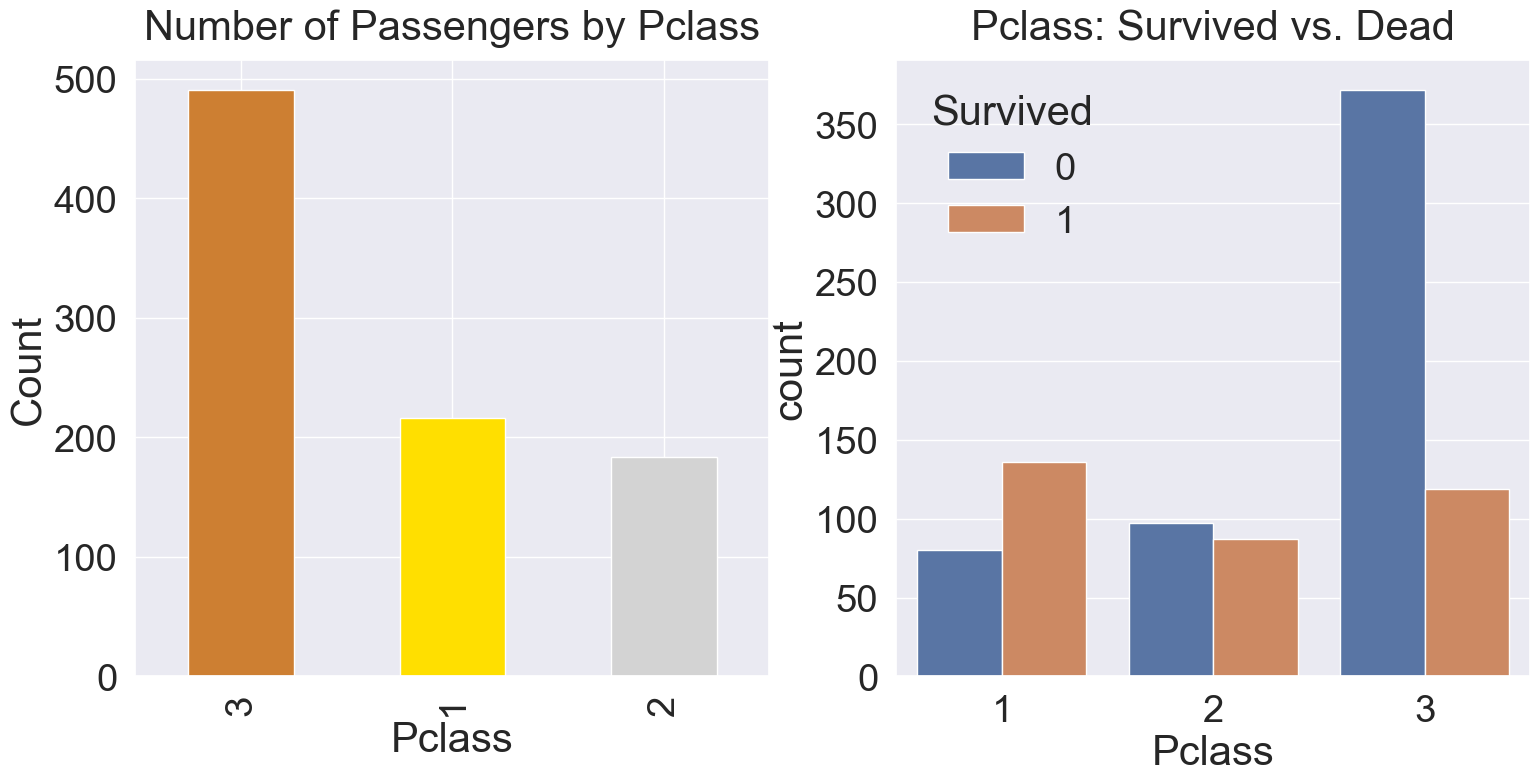
Pclass의 값 1,2,3의 순서대로 생존률은 63%, 48%, 25%입니다.
따라서 클래스가 높을 수록, 생존 확률이 높은 것을 확인할 수 있습니다. 생존에 Pclass가 큰 영향을 미친다는 것을 생각해 볼 수 있겠습니다. 또한, 나중에 모델을 세울 때 해당 feature를 사용하는 것이 좋다는 것을 판단할 수도 있습니다.
2.2 Sex
성별로 생존률이 어떻게 달라지는지 확인해 봅니다.
마찬가지로 pandas groupby와 seaborn countplot을 사용해서 시각화합니다.
f, ax = plt.subplots(1, 2, figsize=(18,8))
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived by Sex')
sns.countplot(data=df_train, x='Sex', hue='Survived', ax=ax[1])
ax[1].set_title('Sex: Survived vs. Dead')
plt.show()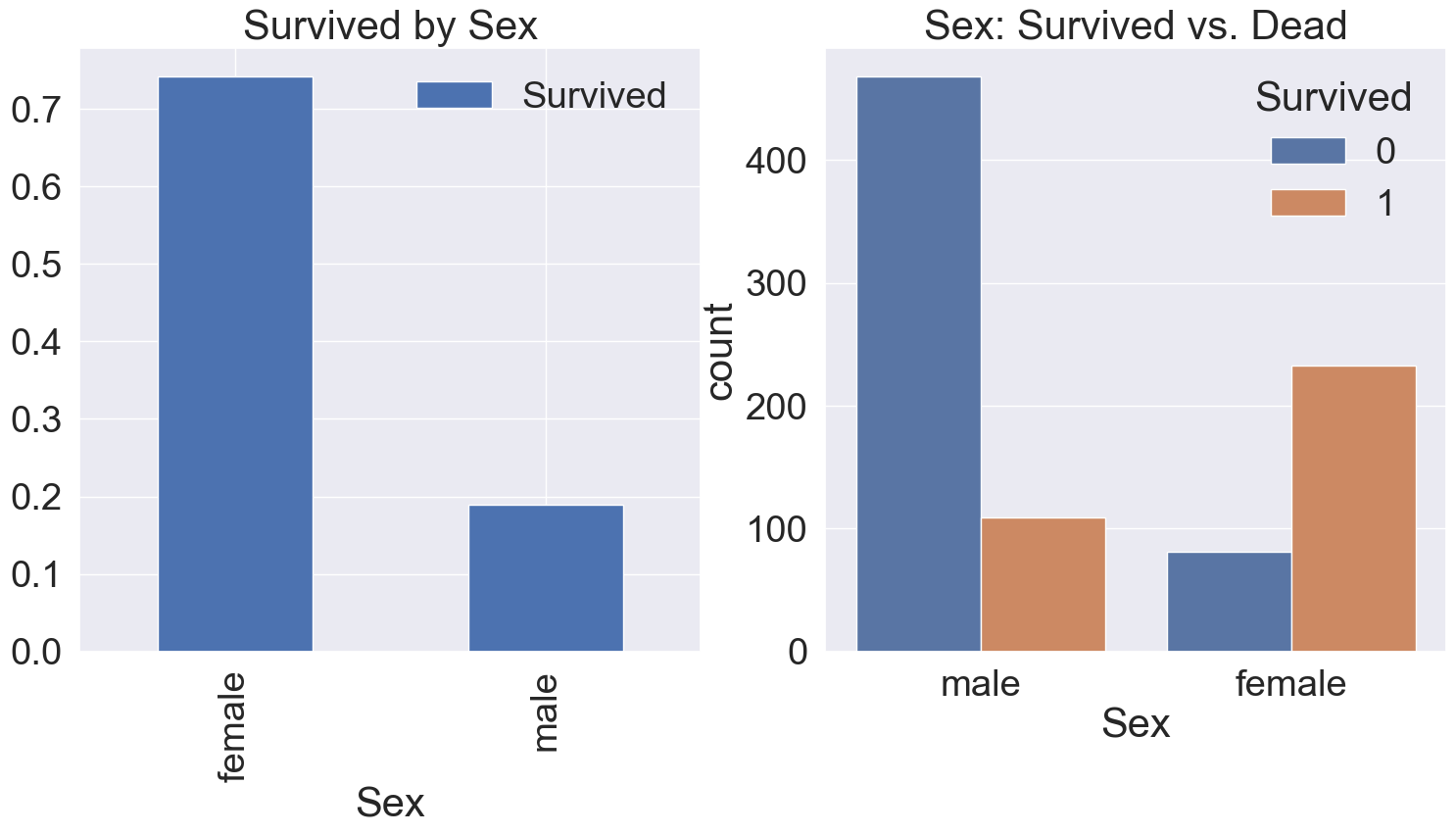
여성의 생존률이 남성의 것보다 높은 것을 확인할 수 있습니다.
다른 방법으로도 확인해보겠습니다.
df_train[['Sex','Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
pd.crosstab(df_train['Sex'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')
2.3 Both Sex and Pclass
이번에는 sex, pclass 두 가지 feature에 따라 생존여부가 어떻게 달라지는지 확인해보겠습니다.
sns.catplot(x='Pclass', y='Survived', hue='Sex',kind='point', data=df_train, height=6)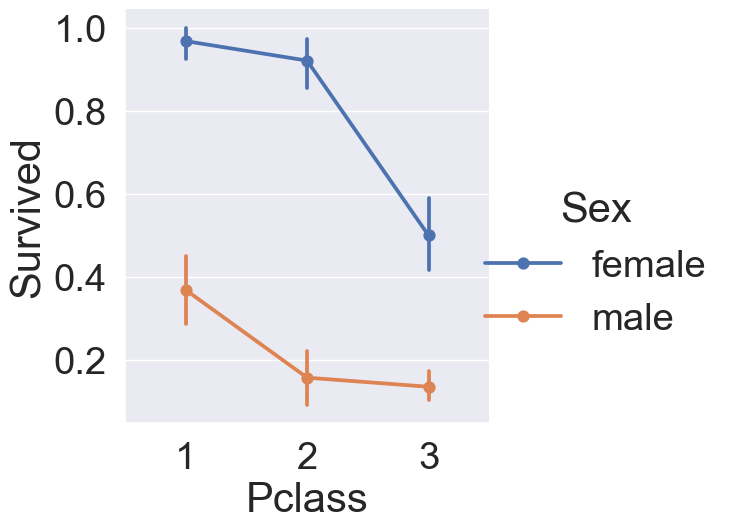
모든 티켓 등급에서 여성이 남성보다 생존 확률이 높은 것을 확인할 수 있습니다. 또한 반대로, 남녀 상관없이 티켓 등급이 높을수록 생존 확륙이 높은 것도 확인해볼 수 있습니다. 그래프의 모양을 변형시켜서 확인해보겠습니다.
sns.catplot(x='Sex', y='Survived', hue='Pclass',kind='point', data=df_train, height=6)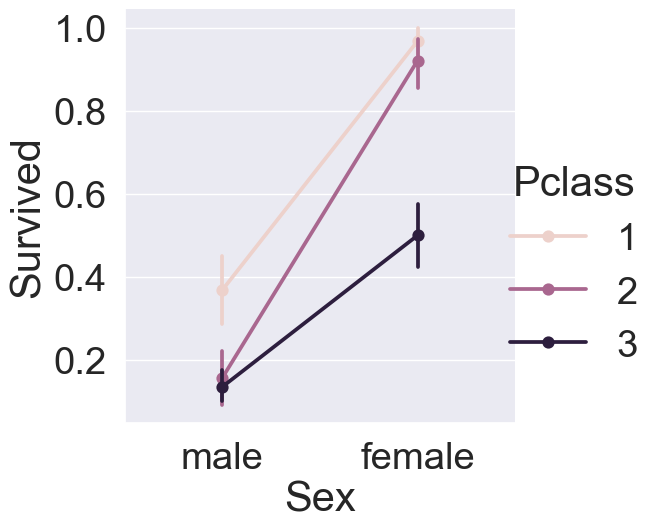
2.4 Age
Age feature를 살펴보겠습니다.
print('최고령 탑승객의 나이 : {:.1f} Years'.format(df_train['Age'].max()))
print('최연소 탑승객의 나이 : {:.1f} Years'.format(df_train['Age'].min()))
print('탑승객의 평균 나이 : {:.1f} Years'.format(df_train['Age'].mean()))
연령대의 상한선과 하한선을 살펴보았습니다. 이를 이용해서 age의 histogram을 그려봅니다.
# 밀도 그래프: KDE(Kernel Density Estimate : 커넬 밀도 추정)
fig, ax = plt.subplots(1,1, figsize=(9,5))
sns.kdeplot(df_train[ df_train['Survived']==1 ]['Age'], ax=ax)
sns.kdeplot(df_train[ df_train['Survived']==0 ]['Age'], ax=ax)
plt.legend(['Survived==1', 'Survived==0'])
plt.show()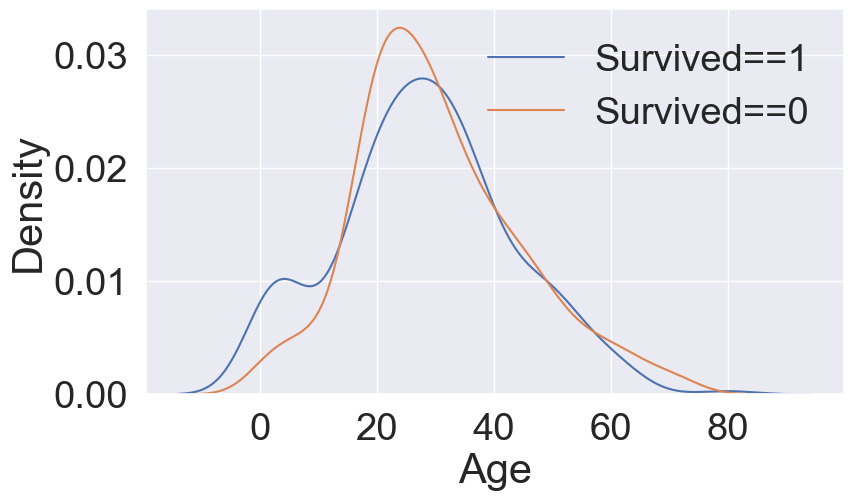
생존자의 연령대는 낮다는 것을 확인해볼 수 있습니다.
다음으로 티겟 등급별(Pclass) 연령대(Age) 분포를 확인해보겠습니다.
# Age distribution within classes
plt.figure(figsize=(8,6))
df_train['Age'][df_train['Pclass']==1].plot(kind='kde')
df_train['Age'][df_train['Pclass']==2].plot(kind='kde')
df_train['Age'][df_train['Pclass']==3].plot(kind='kde')
plt.xlabel('Age')
plt.title('Age Distribution within Classes')
plt.legend(['1st class', '2nd class', '3rd classs'])
plt.show()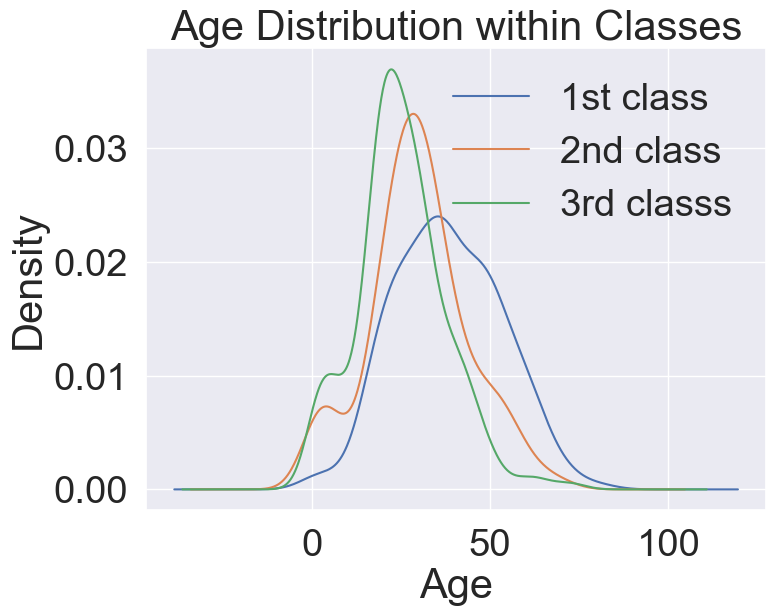
class가 높을수록 연령대 또한 높아집니다. 나이대가 변하면서 생존률이 어떻게 되는지 살펴보기 위해, 연령대 범위를 점점 넓혀가면서 생존률의 변화를 확인해보겠습니다. 나이 범위를 점점 넓혀가면서, 생존률이 어떻게 되는지 확인해보자.
cummulate_survival_ratio = []
for i in range(1,81):
cummulate_survival_ratio.append(df_train[df_train['Age']<i]['Survived'].sum() / len(df_train[df_train['Age']<i]['Survived']))
plt.figure(figsize=(7,7))
plt.plot(cummulate_survival_ratio)
plt.title('Survival rate change depending on range of Age', y=1.02)
plt.ylabel('Survival rate')
plt.xlabel('Range of Age(0~x)')
plt.show()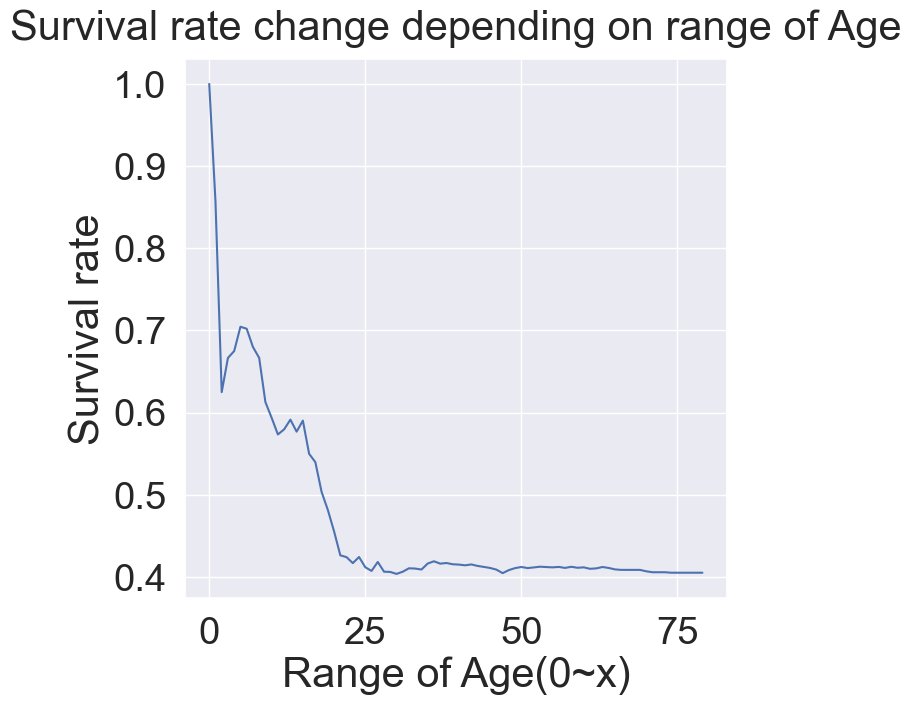
나이가 어릴수록 생존률이 높아지는 것을 확인할 수 있습니다.
2.5 Pclass, Sex, Age
지금까지 본 Sex, Pclass, Age, Survived 모두에 대해서 확인합니다. 이는 seaborn violinplot을 이용해서 쉽게 확인할 수 있습니다.
x축은 우리가 나눠서 보고 싶어하는 case(Pclass, Sex)를 나타내고, y축은 확인하고 싶은 distribution(Age)으로 배정하겠습니다.
f, ax = plt.subplots(1,2, figsize=(18,8))
sns.violinplot(x='Pclass', y='Age', hue='Survived', data=df_train, scale='count', split=True, ax=ax[0])
ax[0].set_title('Age by Pclass according to Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot(x='Sex', y='Age', hue='Survived', data=df_train, scale='count', split=True, ax=ax[1])
ax[1].set_title('Age by Sex according to Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()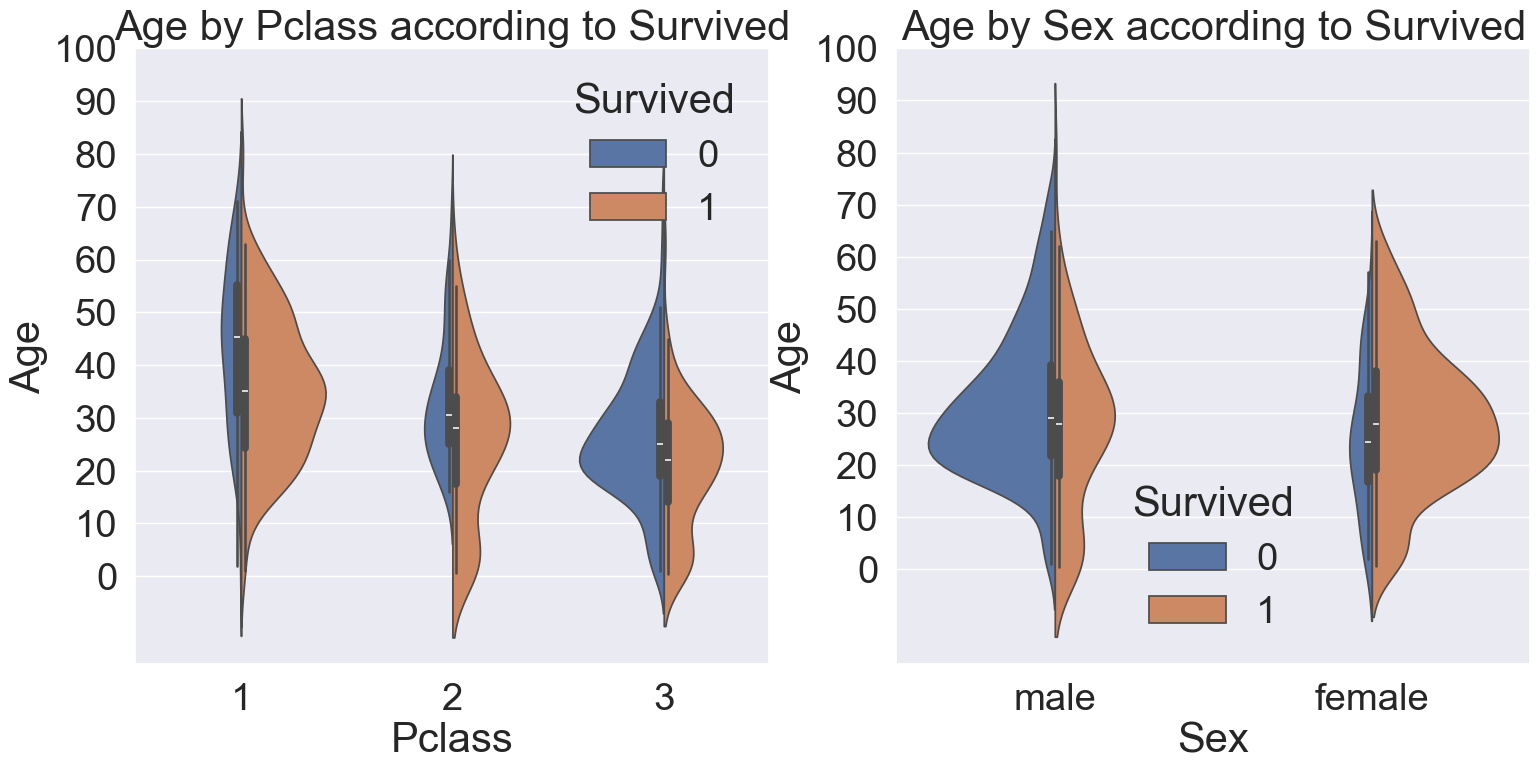
왼쪽 그래프는 Pclass별 Age의 분포를 생존여부에 따라 구분했으며, 오른쪽 그래프는 Sex별 Age의 분포를 생존여부에 따라 구분했습니다.
생존여부만 봤을 때, 모든 클래스에서 나이가 어릴 수록 많이 생존했음을 알 수 있습니다. 또한 오른쪽 그래프를 통해서 여성이 많이 생존했음을 알 수 있다. 구조시 여성과 아이들이 구조 대상의 우선 순위였다는 것을 확인할 수 있습니다.
2.6 Embarked
Embarked는 탑승항구입니다. 탑승항구에 따른 생존여부의 차이가 있는지 확인해보겠습니다.
f, ax = plt.subplots(1,1, figsize=(7,7))
df_train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax)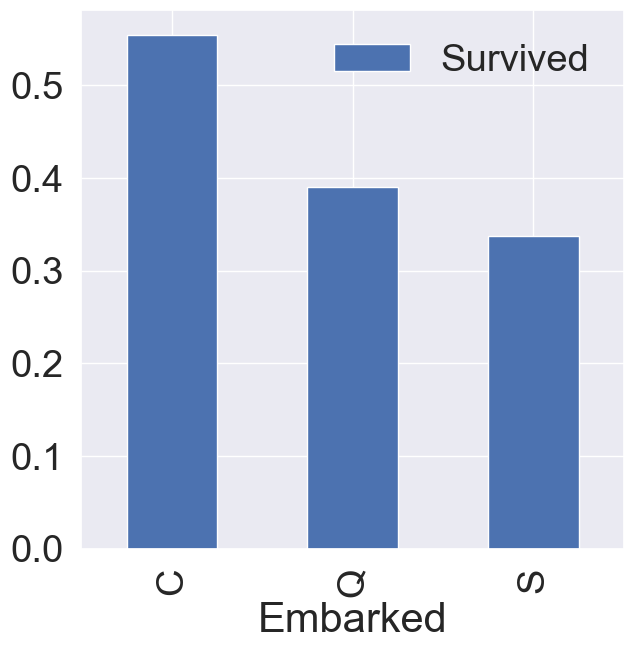
C 항구 탑승객의 생존률이 제일 높은 것을 확인할 수 있습니다.
나머지 항구들의 생존률은 비슷하지만 모델에 사용할 feature로 사용한다. 다른 feature들로 split하여 살펴보겠습니다.
f,ax = plt.subplots(2,2,figsize=(20,15))
sns.countplot(x='Embarked', data=df_train, ax=ax[0,0])
ax[0,0].set_title('(1) No. of Passengers Boarded')
sns.countplot(x='Embarked', hue='Sex', data=df_train, ax=ax[0,1])
ax[0,1].set_title('(2) Male-Female Split for Embarked')
sns.countplot(x='Embarked', hue='Survived', data=df_train, ax=ax[1,0])
ax[1,0].set_title('(3) Embarked counts according to Survived')
sns.countplot(x='Embarked', hue='Pclass', data=df_train, ax=ax[1,1])
ax[1,1].set_title('(4) Embarked counts according to Pclass')
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()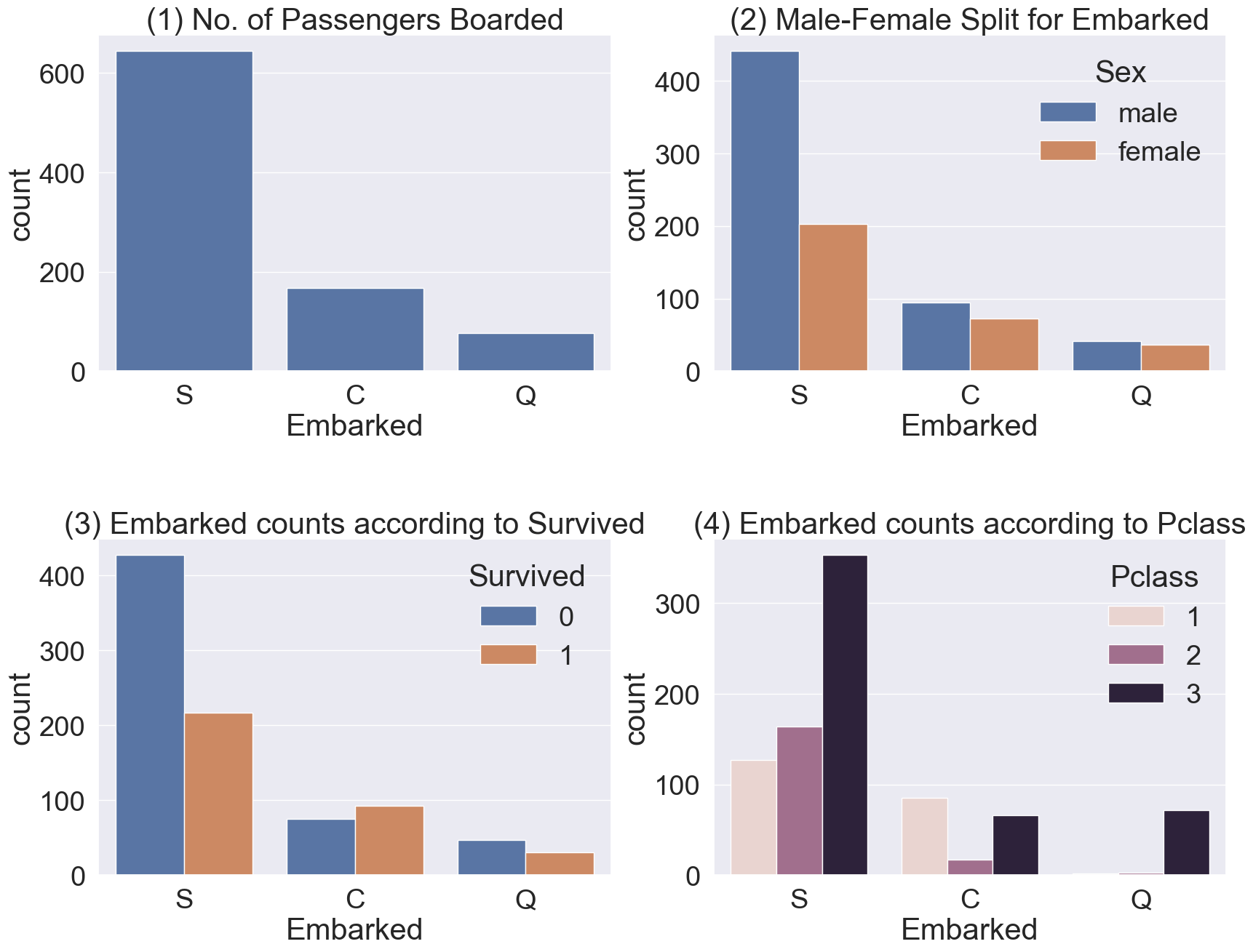
- (1) : 전체적으로 봤을 때, S항구에서 가장 많은 사람이 탑승했습니다.
- (2) : C항구와 Q항구는 남녀 비율이 비슷하고, S항구는 남자가 더 많습니다.
- (3) : 생존확률이 S항구의 경우 많이 낮은 걸 볼 수 있습니다.
- (4) : pclass로 split해보니, C항구가 생존확률이 높은 건 클래스가 높은 탑승객이 많아서임을 알 수 있습니다. 반대로 S항구는 3rd class 탑승객이 많아서 생존률이 낮습니다.
2.7 Family = SibSp + Parch
SibSp(형제의 수)와 Parch(부모자녀의 수)를 합하여 새로운 feature Family(가족구성원의 수)를 만들어 분석해봅니다.
df_train['FamilySize'] = df_train['SibSp'] + df_train['Parch'] + 1 # 자신을 포함해야 하므로 1을 더한다.
df_test['FamilySize'] = df_test['SibSp'] + df_test['Parch'] + 1 # 자신을 포함해야 하므로 1을 더한다.가족구성원수의 maximum과 minimum을 확인해보겠습니다.
print('Maximum size of family: ', df_train['FamilySize'].max())
print('Minimum size of family: ', df_train['FamilySize'].min())
이제 가족구성원 수에 따른 생존률의 차이를 확인해보겠습니다.
f, ax = plt.subplots(1,3, figsize=(40,10))
sns.countplot(data=df_train, x='FamilySize', ax=ax[0])
ax[0].set_title('(1) No. of Passengers Boarded', y=1.02)
sns.countplot(data=df_train, x='FamilySize', hue='Survived', ax=ax[1])
ax[1].set_title('(2) Survived countplot depending on FamilySize', y=1.02)
df_train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax[2])
ax[2].set_title('(3) Survived rate depending on FamilySize', y=1.02)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()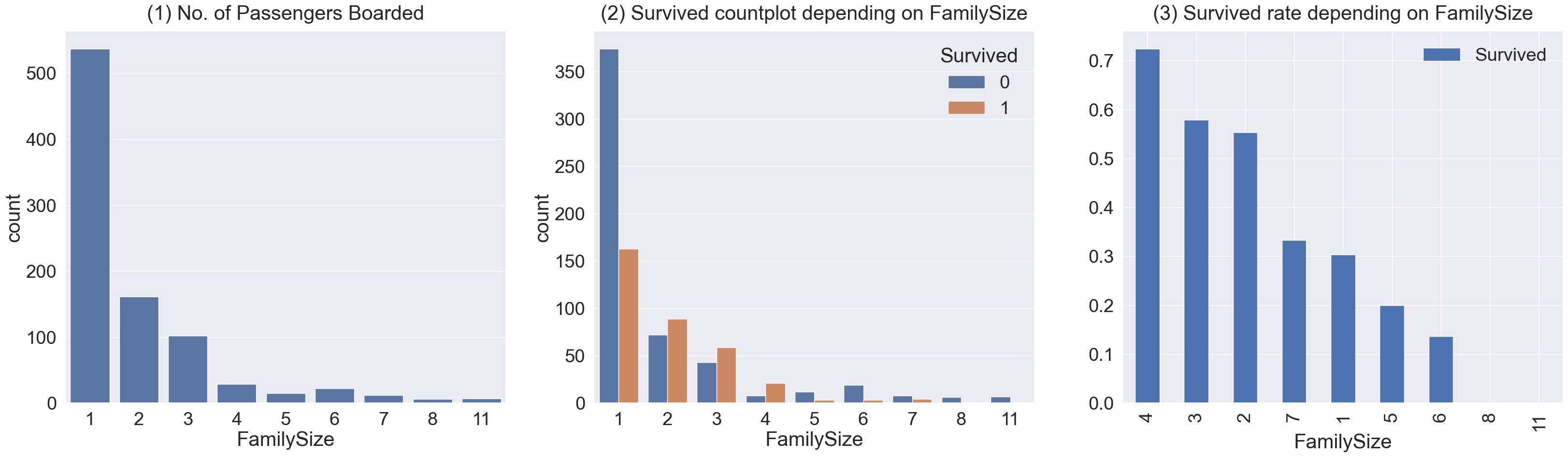
- (1) : 가족의 구성원의 숫자가 1명부터 11명까지 있음을 확인할 수 있으며, 1인 가족이 가장 많고, 그 다음으로는 2,3,4인 가족의 수가 많습니다.
- (2),(3) : 가족 크기에 따른 생존비교입니다. 3~4인 가족의 경우 생존확률이 가장 큽니다. 가족 구성원의 수가 너무 작아도, 너무 커도 생존 확률이 낮음을 확인할 수 있습니다.
2.8 Fare
Fare는 탑승요금이며, continuous feature입니다. histogram을 그려서 데이터를 살펴보겠습니다.
fig, ax = plt.subplots(1,1, figsize=(8,8))
g= sns.distplot(df_train['Fare'], color='b', label='Skewness : {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g=g.legend(loc='best')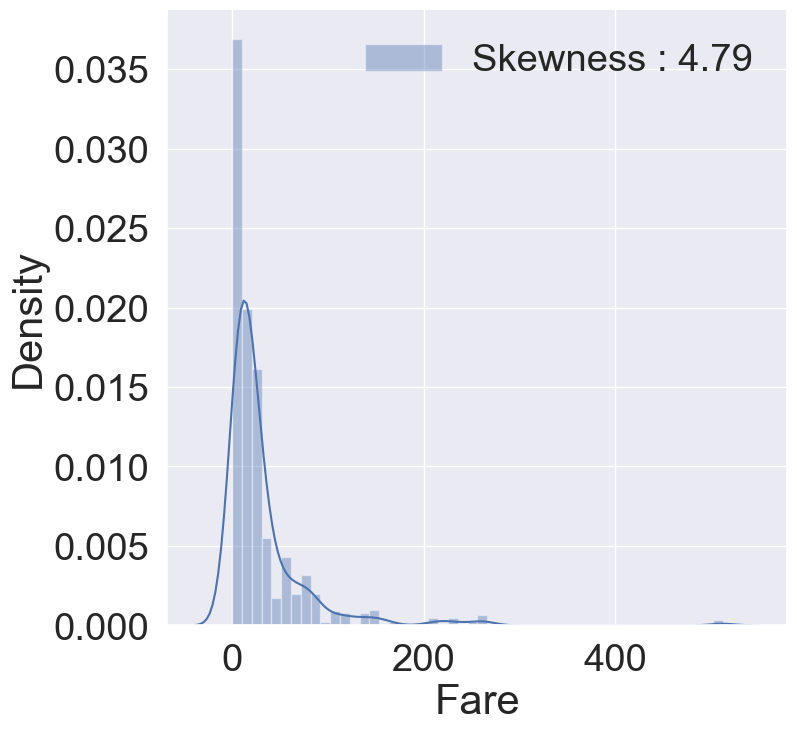
distribution이 매우 비대칭인 것을 알 수 있습니다. 만약 이대로 모델에 넣는다면 자칫 모델이 잘못 학습할 수도 있습니다.
몇 개 없는 outlier에 대해서 너무 민감하게 반응한다면, 실제 예측시에 좋지 못한 결과를 부를 수 있으므로 outlier의 영향을 줄이기 위해서 Fare에 log를 취하겠습니다.
# test set에 있는 nan value를 평균값으로 치환한다.
# 치환 전
print(df_test.loc[df_test.Fare.isnull(), 'Fare'])
# 치환 후
df_test.loc[df_test.Fare.isnull(), 'Fare'] = df_test['Fare'].mean()
print(df_test.loc[df_test.Fare.isnull(), 'Fare'])
# Fare 데이터에 log값 취하기
df_train['Fare'] = df_train['Fare'].map(lambda i : np.log(i) if i>0 else 0)
df_test['Fare'] = df_test['Fare'].map(lambda i : np.log(i) if i>0 else 0)
# 그래프로 확인
fig, ax = plt.subplots(1,1, figsize=(8,8))
g= sns.distplot(df_train['Fare'], color='b', label='Skewness : {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g=g.legend(loc='best')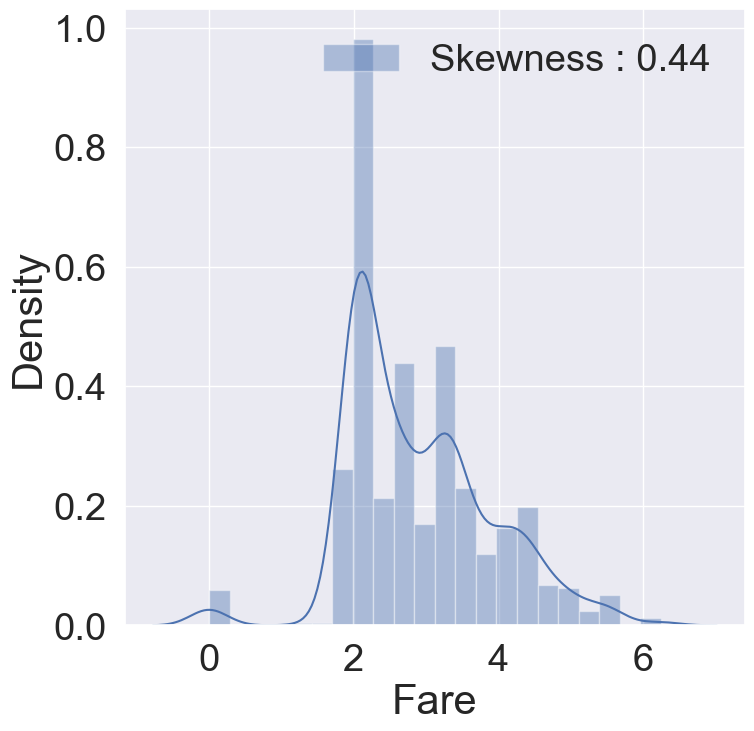
Fare 데이터에 log를 취하니, 비대칭성이 많이 사라진 것을 볼 수 있습니다.
2.9 Cabin
이 feature는 NaN이 대략 77%이므로 생존에 영향을 미칠 중요한 정보를 얻어내기가 쉽지 않으므로 모델에 포함시키지 않도록 합니다.
# Cabin 컬럼의 NaN value의 비율
print('Cabin column\'s Percent of NaN value: {:.2f}%'.format(100*(df_train['Cabin'].isnull().sum()/df_train['Cabin'].shape[0])))
🚢 3. Feature Enginnering
이제 feature engineering 작업을 시작합니다. 가장 먼저, dataset에 있는 null data를 채우는 작업을 하겠습니다.
train뿐만이 아니라 test도 똑같이 적용해야하는 것에 유의해야 합니다.
3.1 Fill Null
3.1.1 Fill Nul in Age using title
Age에는 null data가 177개가 있습니다. 이를 채우기 위해 title + statistics를 사용하겠습니다.
영어에는 Miss, Mr, Mrs같은 title이 존재하는데, 데이터셋의 각 탑승객의 이름에는 이런 title이 들어있는 것을 이용하겠습니다.

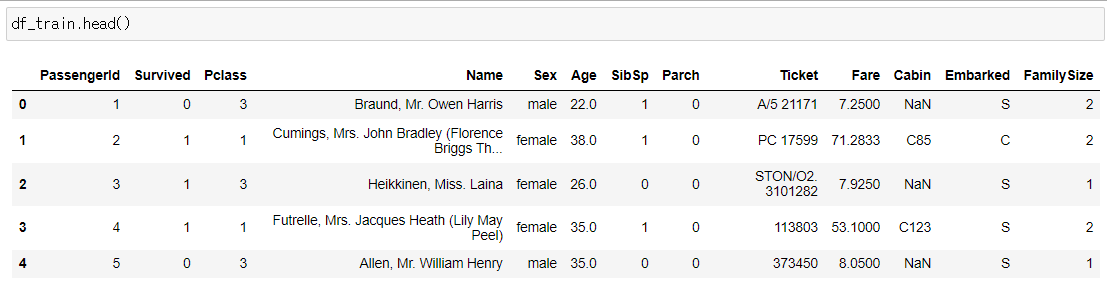
# lets extract the Salutations
df_train['Initial']=df_train.Name.str.extract('([A-za-z]+)\.')
df_test['Initial']=df_test.Name.str.extract('([A-za-z]+)\.')
crosstab을 활용하여 추출한 Initial과 Sex간의 count를 살펴보겠습니다.
pd.crosstab(df_train['Initial'], df_train['Sex']).T.style.background_gradient(cmap='summer_r')
위의 테이블을 이용해서 성별 initial을 구분해서 몇 개의 간략한 initial들로 치환해주겠습니다.
df_train['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don','Dona'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr','Mr'],
inplace=True)
df_test['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don','Dona'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr','Mr'],
inplace=True)initial별 각 feature들의 평균값을 확인해보겠습니다.
df_train.groupby('Initial')[['PassengerId','Survived','Pclass','Age','SibSp','Parch','Fare','FamilySize']].mean()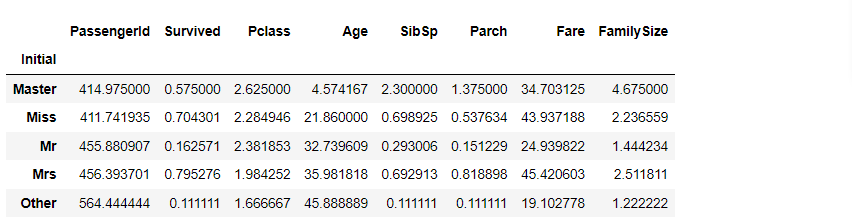
여성과 관계있는 Mrs, Miss initial들의 생존률이 높은 것을 확인할 수 있습니다.
그래프로 시각화해보겠습니다.
df_train.groupby('Initial')['Survived'].mean().plot.bar()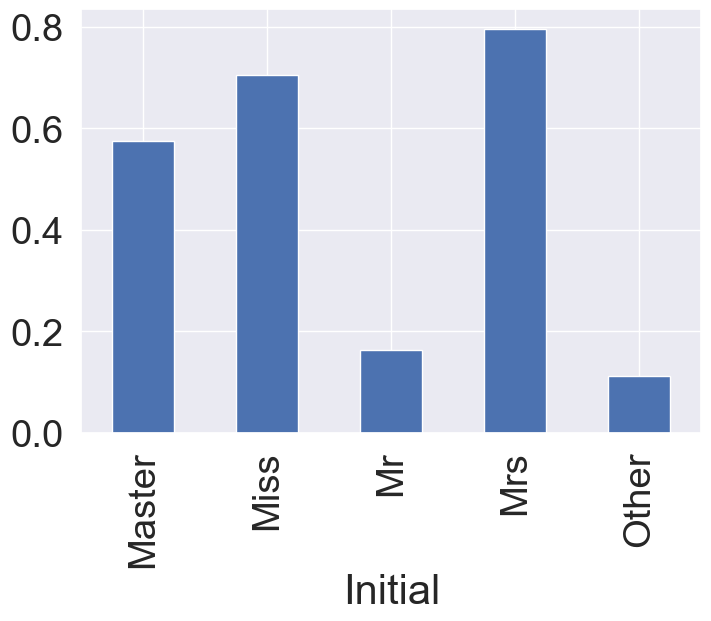
이제 본격적으로 Null을 채웁니다. null data를 채우는 방법은 정말 많이 존재한다. statistics를 활용하는 방법도 있고, null data가 없는 데이터를 기반으로 새로운 머신러닝 알고리즘을 만들어 예측해서 채워넣는 방식도 있습니다. 여기서는 statistics를 활용하는 방법을 사용한다. 여기서 statistics은 train data의 것을 의미합니다. 우리는 언제나 test를 unseen으로 둔 상태로 놔둬야 하며, train에서 얻은 statistics를 기반으로 test의 null data를 채워줘야 하는 것에 유의해야 합니다.
Age의 평균을 이용해 Null value를 채우도록 하겠습니다.
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Mr'), 'Age'] = 33
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Mrs'), 'Age'] = 36
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Master'), 'Age'] = 5
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Miss'), 'Age'] = 22
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Other'), 'Age'] = 46
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Mr'), 'Age'] = 33
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Mrs'), 'Age'] = 36
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Master'), 'Age'] = 5
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Miss'), 'Age'] = 22
df_test.loc[(df_test.Age.isnull())&(df_test.Initial=='Other'), 'Age'] = 463.1.2 Fill Null in Embarked

Embarked column은 Null value가 2개이고, S에서 가장 많은 탑승객이 있었으므로, 간단하게 Null을 S로 채우겠습니다.
df_train['Embarked'].fillna('S', inplace=True)
3.2 Change Age (continuous to categorical)
Age는 현재 continuous feagure입니다. 이대로 써도 모델을 세울 수 있지만, Age를 몇 개의 group으로 나누어 category화 하겠습니다. 두 가지 방법으로 비교해봅니다. dataframe의 indexing 방법인 loc를 사용하여 그룹화하고, apply를 사용해 함수를 이용해봅니다.
첫번째로 loc를 사용한 방법입니다.
나이는 10살 간격으로 나누었습니다.
df_train['Age_cat'] = 0
df_train.loc[df_train['Age'] < 10, 'Age_cat'] = 0
df_train.loc[(10<=df_train['Age']) & (df_train['Age']<20), 'Age_cat']=1
df_train.loc[(20<=df_train['Age']) & (df_train['Age']<30), 'Age_cat']=2
df_train.loc[(30<=df_train['Age']) & (df_train['Age']<40), 'Age_cat']=3
df_train.loc[(40<=df_train['Age']) & (df_train['Age']<50), 'Age_cat']=4
df_train.loc[(50<=df_train['Age']) & (df_train['Age']<60), 'Age_cat']=5
df_train.loc[(60<=df_train['Age']) & (df_train['Age']<70), 'Age_cat']=6
df_train.loc[70 <=df_train['Age'], 'Age_cat'] = 7
df_test['Age_cat'] = 0
df_test.loc[df_test['Age'] < 10, 'Age_cat'] = 0
df_test.loc[(10<=df_test['Age']) & (df_test['Age']<20), 'Age_cat']=1
df_test.loc[(20<=df_test['Age']) & (df_test['Age']<30), 'Age_cat']=2
df_test.loc[(30<=df_test['Age']) & (df_test['Age']<40), 'Age_cat']=3
df_test.loc[(40<=df_test['Age']) & (df_test['Age']<50), 'Age_cat']=4
df_test.loc[(50<=df_test['Age']) & (df_test['Age']<60), 'Age_cat']=5
df_test.loc[(60<=df_test['Age']) & (df_test['Age']<70), 'Age_cat']=6
df_test.loc[70 <=df_test['Age'], 'Age_cat'] = 7두 번째로 간단한 함수를 만들어 apply 메서드에 넣어주는 방법입니다.
def category_age(x):
if x < 10:
return 0
elif x < 20:
return 1
elif x < 30:
return 2
elif x < 40:
return 3
elif x < 50:
return 4
elif x < 60:
return 5
elif x < 70:
return 6
else:
return 7
df_train['Age_cat_2'] = df_train['Age'].apply(category_age)두 가지 방법이 잘 적용됐다면, 둘 다 같은 결과를 내야합니다.
이를 확인하기 위해 series간 boolean 비교 후 all() 메서드를 사용하겠습니다. all() 메서드는 모든 값이 True면 True, 하나라도 False면 False를 줍니다.
print('1번 방법, 2번 방법 둘다 같은 결과를 내면 True를 줘야함 ->', (df_train['Age_cat']==df_train['Age_cat_2']).all() )
잘 적용된 것을 확인했으므로, 불필요한 column은 삭제합니다.
df_train.drop(['Age', 'Age_cat_2'], axis=1, inplace=True)
df_test.drop(['Age'], axis=1, inplace=True)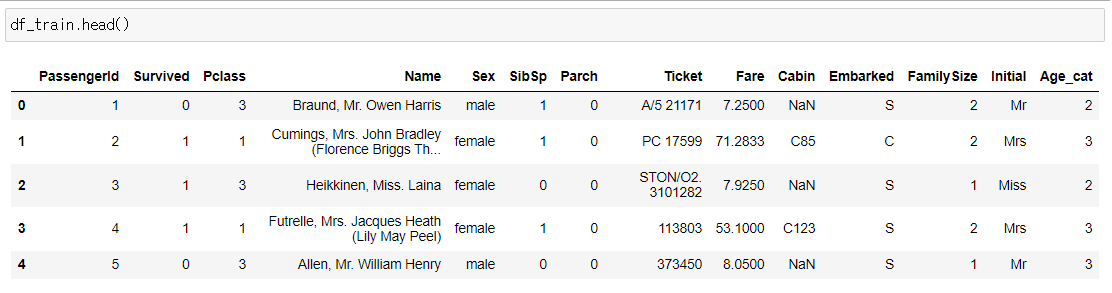
3.3 Change Initial, Embarked and Sex (string to numerical)
현재 Initial은 Mr, Mrs, Miss, Master, Other 총 5개로 이루어져 있습니다. 이런 카테고리로 표현되어 있는 데이터를 모델에 인풋으로 넣어줄 때 우리가 해야할 것은 먼저 컴퓨터가 인식할 수 있도록 수치화해야 하는 것입니다.
사전 순서대로 mapping 하겠습니다.
df_train['Initial'] = df_train['Initial'].map({'Master':0, 'Miss':1, 'Mr':2, 'Mrs':3, 'Other':4})
df_test['Initial'] = df_test['Initial'].map({'Master':0, 'Miss':1, 'Mr':2, 'Mrs':3, 'Other':4})Embarked도 C,Q,S로 이루어져 있으므로. map을 이용해 바꾸겠습니다. 그러기에 앞서, 특정 column에 어떤 값들이 있는지 확인해보겠습니다. 간단히 unique() method를 이용하거나, value_counts()를 써서 count까는 보는 방법도 있습니다.

데이터를 확인했으므로, 수치화하겠습니다.
df_train['Embarked'] = df_train['Embarked'].map({'C':0, 'Q':1, 'S':2})
df_test['Embarked'] = df_test['Embarked'].map({'C':0, 'Q':1, 'S':2})Sex도 마찬가지로 수치화합니다.
df_train['Sex'] = df_train['Sex'].map({'female':0, 'male':1})
df_test['Sex'] = df_test['Sex'].map({'female':0, 'male':1})이제 각 feature간의 상관관계를 살펴보겠습니다. 두 변수간의 pearson correlation을 구하면 (-1,1) 사이의 값을 얻을 수 있습니다. heatmap을 이용해서 시각화하여 한 눈에 살펴보겠습니다.
heatmap_data=df_train[['Survived', 'Pclass', 'Sex', 'Fare', 'Embarked', 'FamilySize', 'Initial', 'Age_cat']]
colormap=plt.cm.RdBu
plt.figure(figsize=(14,12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(heatmap_data.astype(float).corr(), linewidths=0.1, vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True, annot_kws={'size':16})
plt.show()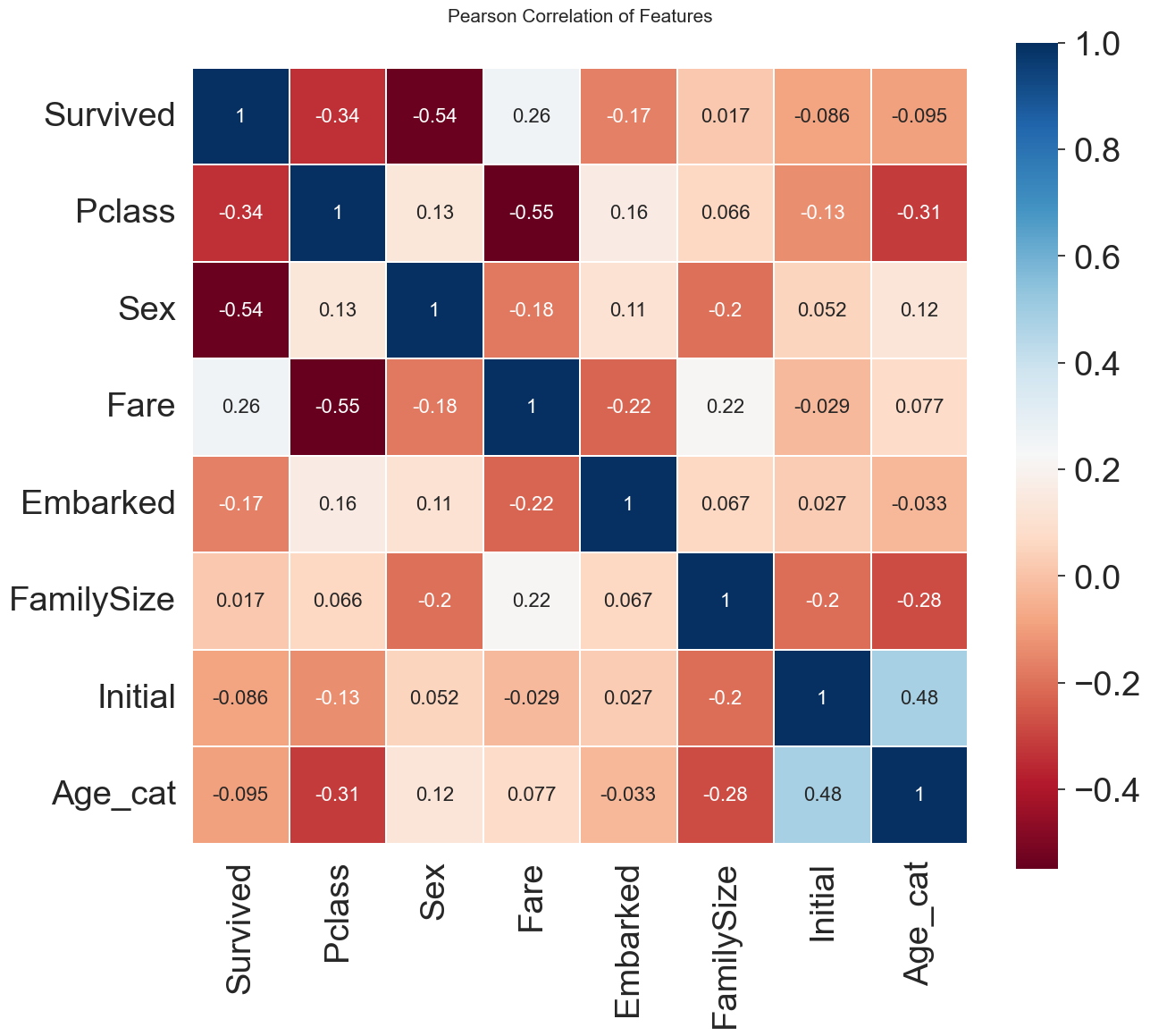
Sex와 Pclass가 Survived에 상관관계가 어느 정도 있음을 확인할 수 있습니다. 게다가 fare와 embarked의 유의미한 상관관계를 살펴볼 수 도 있습니다. 하지만 강한 상관관계를 가지는 featur들은 없다는 것을 확인할 수 있습니다.
이것은 모델을 학습시킬 때, 불필요한 feature가 없다는 것을 의미합니다. 1 또는 -1의 상관관계를 가진 feature A,B가 있다면, 우리가 얻을 수 있는 정도는 하나이기 때문입니다.
이제 실제로 모델을 학습시키기 위해 data preprocessing(전처리)을 진행해봅니다.
3.4 One-hot encoding on Initial and Embarked
수치화한 카테고리 데이터를 그대로 넣어도 되지만, 모델의 성능을 높이기 위해 one-hot encoding을 해줄 수도 있습니다.
one-hot encoding은 위 카테고리를 (0,1)로 이루어진 5차원의 벡터로 나타내는 것을 말합니다.
총 5개의 카테고리이므로, one-hot encoding을 하고 나면 새로운 5개의 컬럼이 생겨날 것입니다.
Initial을 prefix로 두어서 구분이 쉽게 만들어주겠습니다.
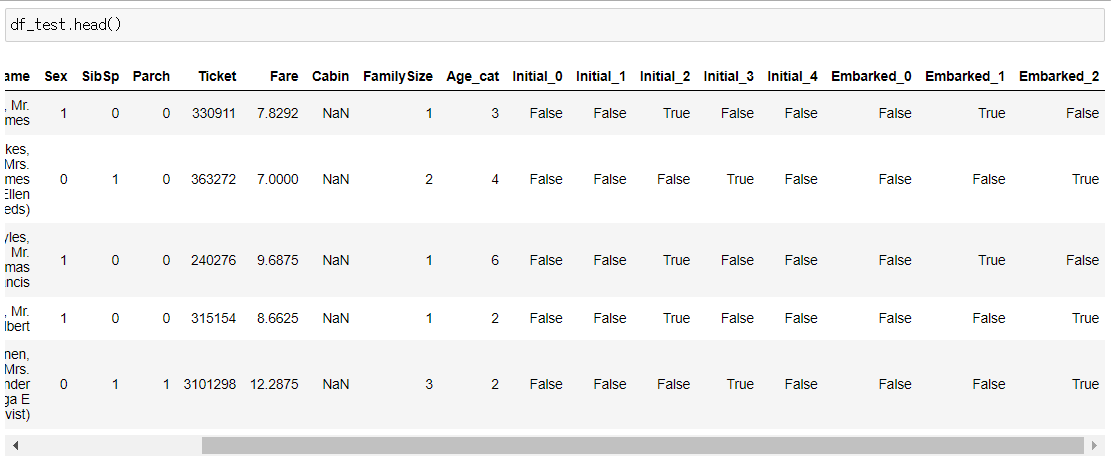
df_train = pd.get_dummies(df_train, columns=['Initial'], prefix='Initial')
df_test = pd.get_dummies(df_test, columns=['Initial'], prefix='Initial')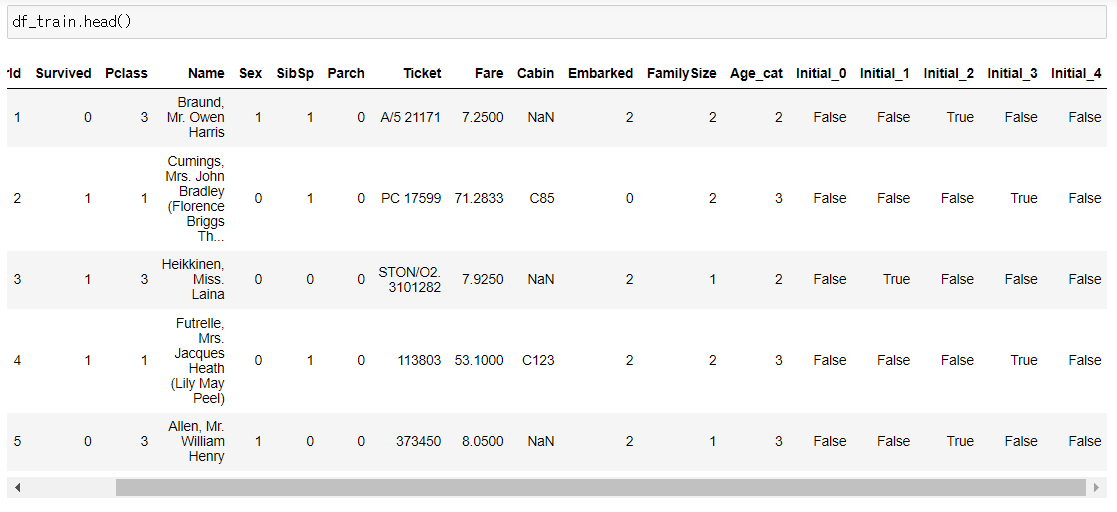
Embarked에도 적용합니다.
df_train = pd.get_dummies(df_train, columns=['Embarked'], prefix='Embarked')
df_test = pd.get_dummies(df_test, columns=['Embarked'], prefix='Embarked')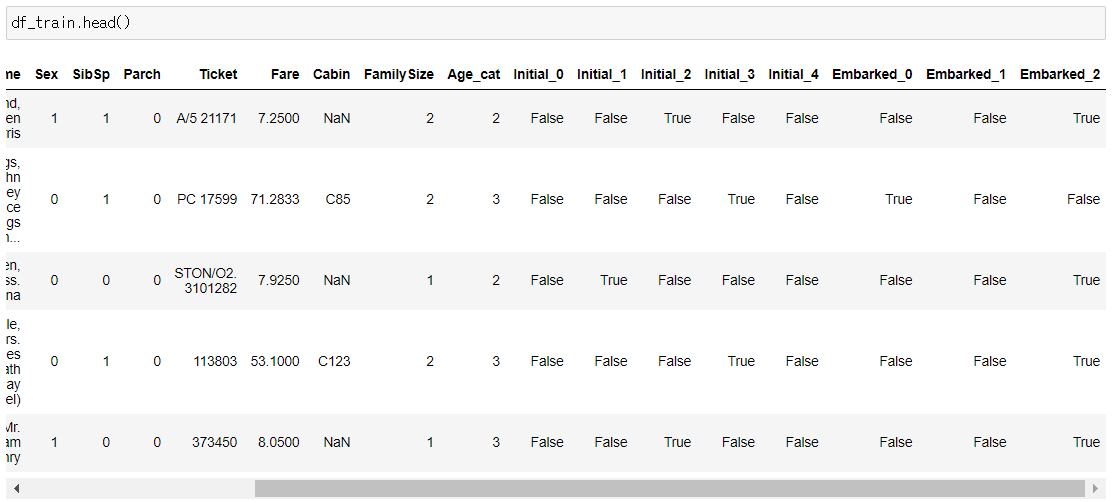
3.5 Drop Columns
이제 필요한 columns만 남기고 나머지는 지우겠습니다.
df_train.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)
df_test.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)
🚢 4. Building machine learning model and prediction using the trained model
이제 본격적으로 sklearn을 사용해 머신러닝 모델을 만듭니다.

현재 타이타닉 문제는 target class(survived)가 있으며, target class는 0,1로 이루어져 있으므로(binary) binary classfication 문제입니다.
우리가 가지고 있는 train set의 survived를 제외한 input을 가지고 모델을 최적화시켜 각 샘플(탑승객)의 생존 유무를 판단하는 모델을 만들어 내겠습니다.
그 후 모델이 학습하지 않았던 test set을 input으로 주어서 test set의 각 샘플(탑승객)의 생존 유무를 예측해봅니다.
4.1 Preparation - Split dataset into train, valid, test set
가장 먼저, 학습에 쓰일 데이터와 target label(survived)를 분리합니다.
X_train = df_train.drop('Survived', axis=1).values
target_label = df_train['Survived'].values
X_test = df_test.values보통 train, test만 언급되지만, 실제 좋은 모델을 만들기 위해서는 valid set을 따로 만들어 모델 평가를 해봅니다.
train_test_split을 사용하여 쉽게 train셋을 분리할 수 있습니다.
X_tr, X_vld, y_tr, y_vld = train_test_split(X_train, target_label, test_size=0.3, random_state=2018)이제 랜덤포레스트 모델을 사용하여 분석해봅니다.
지금은 파라미터 튜닝은 생략하고 기본 default 세팅으로 진행하겠습니다.
먼저 모델 객체를 만들고, fit 메서드로 학습시킵니다.
그런 후 valid set input을 넣어주어 예측값(X_vld sample 생존여부)를 얻을 수 있습니다.
4.2 Model generation and prediction
model = RandomForestClassifier()
model.fit(X_tr, y_tr)
prediction = model.predict(X_vld)모델을 세우고, 예측까지 끝났습니다.
모델 성능을 확인해봅니다.
print('총 {}명 중 {:.2f}% 정확도로 생존을 맞춤'.format(y_vld.shape[0], 100*metrics.accuracy_score(prediction, y_vld)))
4.3 Feature Importance
학습된 모델은 feature importance를 가지는데, 이것을 확인해 모델이 어떤 feature에 영향을 많이 받았는지 확인할 수 있습닌다.
from pandas import Series
feature_importance = model.feature_importances_
Series_feat_imp = Series(feature_importance, index=df_test.columns)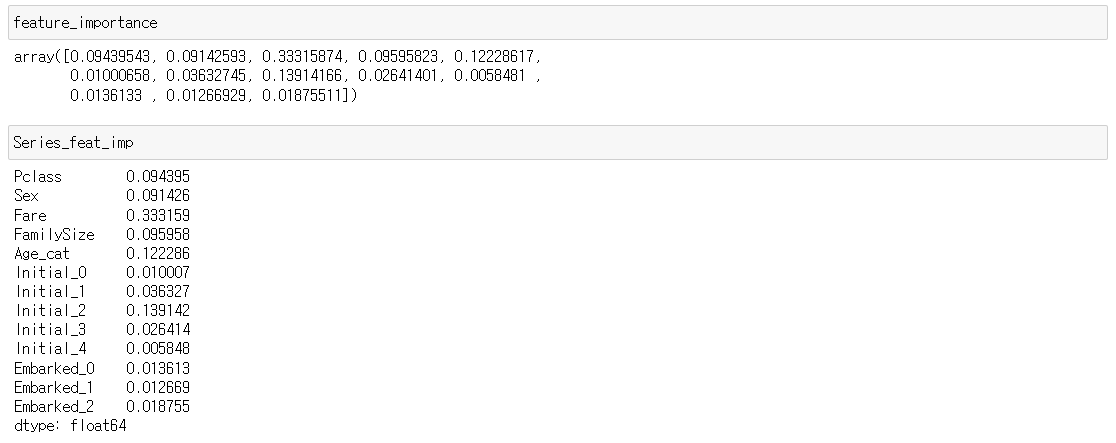
plt.figure(figsize=(8,8))
Series_feat_imp.sort_values(ascending=True).plot.barh()
plt.xlabel('Feature importance')
plt.ylabel('Feature')
plt.show()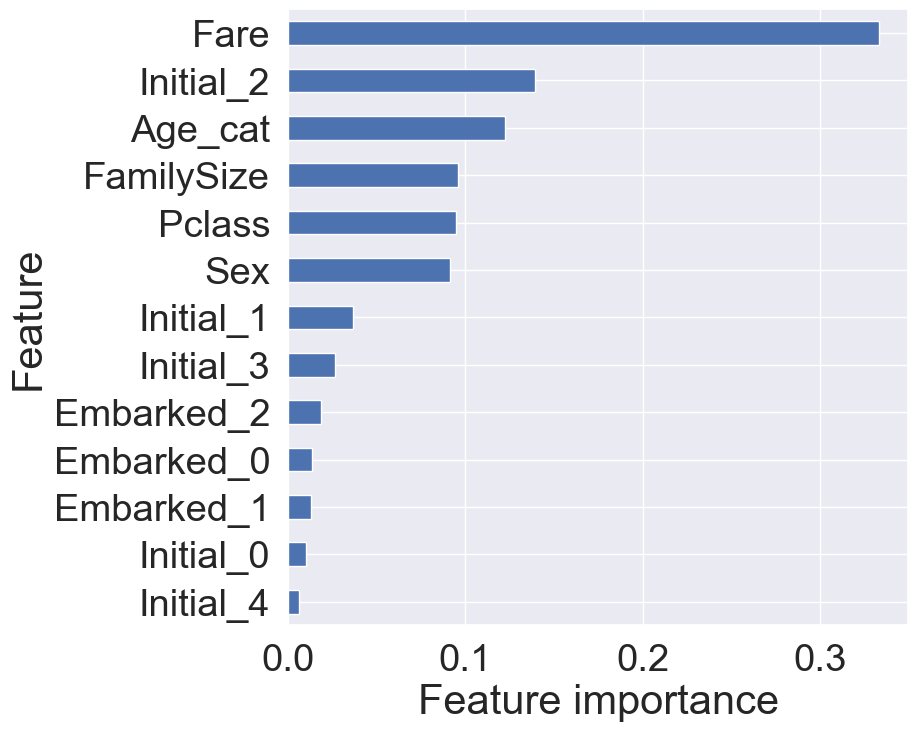
우리가 얻은 모델에서는 Fare가 가장 큰 영향력을 가지며, 그 뒤로 Initial_2, Age_cat, Pclass가 차례로 중요도를 가집니다.
하지만 영향력은 지금 모델을 기준으로 한 것이기 때문에 다른 모델을 사용하게 되면 영향력이 다르게 나올 수도 있다는 것을 유의해야 합니다. 따라서 통계적으로 좀 더 살펴보는 작업이 필요합니다.
4.4 Prediction on Test set
이제 모델이 학습하지 않았던 테이터셋을 모델에 주어서 생존여부를 예측해본다.
submission = pd.read_csv('gender_submission.csv')
submission.head()
prediction = model.predict(x_test)
submission['Survived'] = prediction그런데 X_test안에 Null값이 있어서 에러가 났습니다.

살펴보니 2 columns(Fare)에 Null값이 있었습니다.
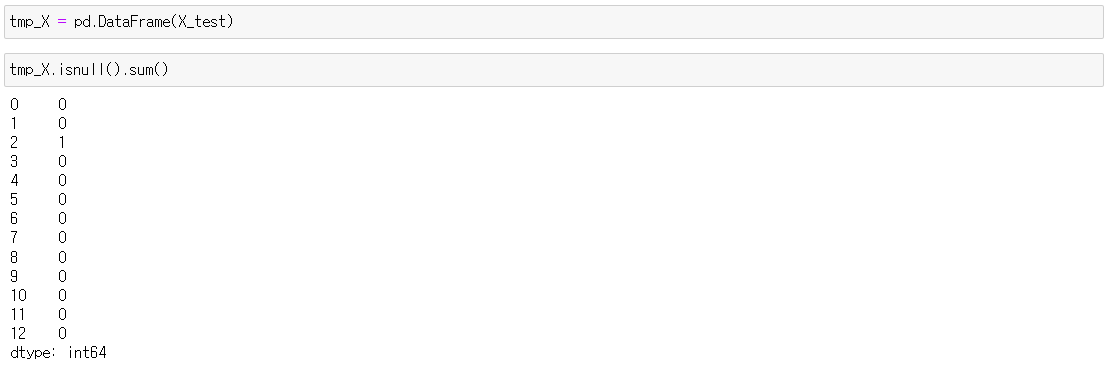
Fare컬럼의 평균치를 넣어주겠습니다.
tmp_X[2].fillna(tmp_X[2].mean(), inplace=True)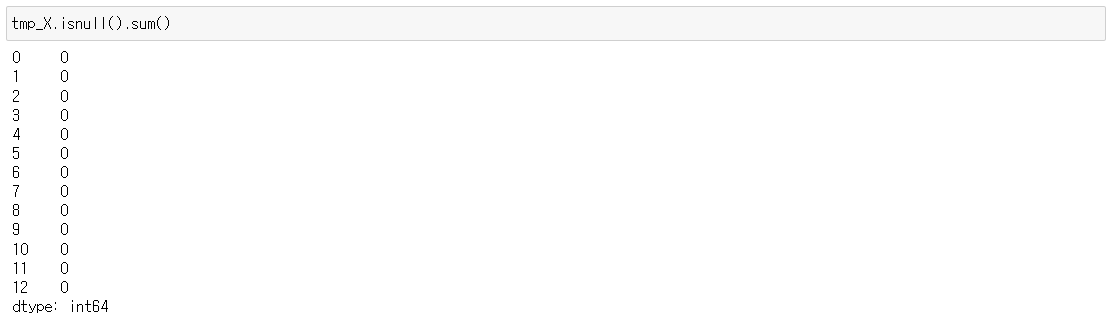
이제 Null 값이 모두 사라졌습니다.
다시 예측해보겠습니다.
prediction = model.predict(tmp)
submission['Survived'] = prediction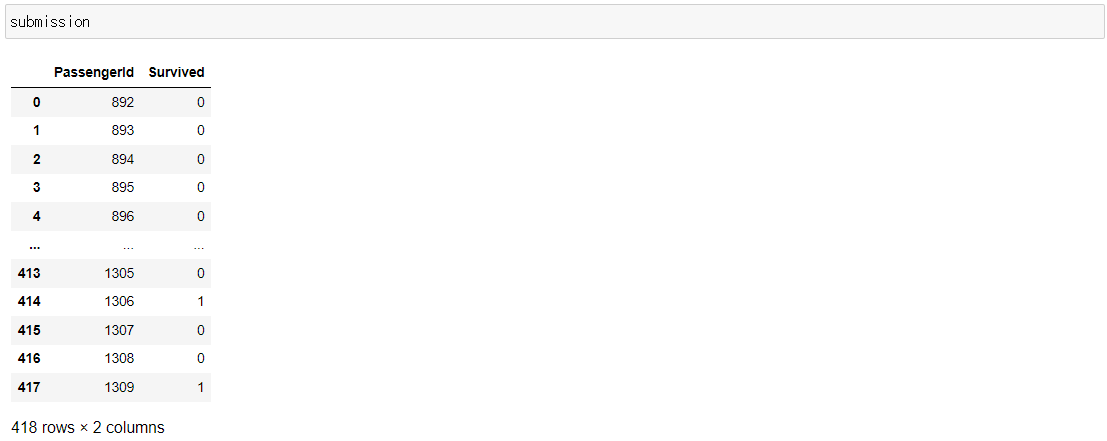
🚢 5. Conclusion
그래도 이전에 EDA수업을 받아서 그런지 따라가는데 힘들진 않았다. 다만 좀 오래전 자료여서 코드를 약간씩 변형해서 작성해야하는 부분이 좀 당황스러웠다...
예를 들어 countplot을 그려줄때, 예전에는 x좌표의 데이터가 정확히 명시하지 않아도 알아서 잡히는듯 했다. 하지만 최근 파이썬에서는 옵션을 정확히 적어줘야 정확한 그래프가 작성되었다.
심지어 라이브러리에서 사라진 기능도 있어서 애를 꽤나 먹었다.
seaborn의 facotrplot이 이제는 삭제돼서 catplot으로 비슷한 그래프를 그려내야 했다. 그것도 모르고 패키지를 몇 번이나 업그레이드 시키고 커널을 몇 번이나 재부팅했는지 모르겠다ㅠㅠㅠㅠㅠ
그리고 이거는 아직 머신러닝을 배우지 않아서 모르겠지만 마지막 4.4챕터에서 예측하는 부분에서 이전에는 null값이 존재해도 알아서 예측이 됐었는듯 했다. (튜토리얼 코드에서는 fare컬럼의 null을 처리하는 부분이 없었기에 아마 그 분도 처리를 안 하지 않았을까 하는 추측이지만...) 내가 임의로 평균 요금으로 null을 채우긴 했지만 이게 옳은 선택인지는 확신은 없다ㅜㅜ 게다가 머신러닝을 모르니 정말 필사만한 것 같아서 찜찜하다. 나도 해석하고 싶다....
반면에 아주 뜻밖의 수확도 하나 있었다. 이전에 과제를 하면서 여러 개의 그래프를 하나의 row로 동시 출력하고 싶었는데, 우연히 그 기능을 발견했다!!
내가 잘 써먹어야겠지만 그래도 그 기능을 발견해서 정말 기분이 좋다.😚
