이 파트 경우 참고자료 그대로 아니라 참조.
1-4 Python 기초 (1)
1) 변수
💡 변수(Variable)란 컴퓨터의 공간에 이름을 붙이고 값을 넣어두고나서 그 이름을 사용해서 값을 사용하는 것을 말합니다. 🙂
👨🏫 변수는 뭔가를 담는 그릇이다.
ex)a = 3 print(a) >>>>>>>>실행 >>>>>>>>>. 3a 라는 변수에(= a 라는 그릇에다가) 3이라는 숫자가 담겼다.
= a가 이제부터 3이라는 역할을 하게 된 것.
👨🏫 =이란 파이썬에서는 할당한다고 표현한다.
a라는 그릇에 3을 넣어둔다, 할당해 둔다 라고 함.
= 자체가 변수를 만드는 행위.
변수라는 것은 그릇을 계속계속 만드는 것
ex) a 라고 말하는 것만으로도 3을 가져오는 것.
나중에는 a에 엄청난게 담길수도 있다. 숫자가 3만개 담긴다거나..그렇게 많이 담겼을때 다 적을수 없잖아.
변수에 종류가 여러가지가 있다. 현재는 숫자만 넣었지만.
그 변수의 종류를 바로 자료형이라고 한다.
2) 자료형
💡 자료형이란 프로그래밍을 할 때 쓰이는 숫자, 문자열 등 자료 형태로 사용하는 모든 것을 뜻합니다. 파이썬에는 다양한 자료형이 있는데, 여기서는 그 중 가장 기본적인
정수형, 실수형, 문자열, 리스트에 대해서 이해해보겠습니다. 🙂
type(변수명)을 사용하면 파이썬의 자료형이 무엇인지를 출력해줍니다.
정수형
tpye(a) : 자료를 확인할 수 있는 명령어
tpte(변수의 이름)
a = 5
type(a)
>>>>>>>>실행 >>>>>>>>>..
int integer(정수)를 의미.
실수형
b = 5.0
type(b)
>>>>>>>>>>실행>>>>>>>>>
float
실수는 소수점도 포함된 것.
b라는 그릇의 자료형, 종류는 float(실수) 이다.
문자형
💡 주의! 문자형은 꼭! ' ' or " " 따옴표를 써야함.
c = ' 안녕하세요~ 반가워요'
type(c)
>>>>>>>>>>>>>>>실행>>>>>>>>.
str str은 String 문자열이라는 뜻.
리스트
👨🏫 리스트 라는 자료형은 일을 할때도 리스트 많이 만들어 두듯이 그거랑 똑같다. 다른점은 그런데 리스트란 변수가 그릇이면 위에것들은 그릇에 하나식만 담았는데 리스트는 그릇에 여러가지를 막 담아놓는 것을 리스트라고 한다.
💡 리스트는 대괄호가 핵심!, 무조건 대괄호로 값들을 감싸줘야 한다.
list1 = [1, 2, 3, 4, 5]
list2 = ['a', 'b', 'c', 'd', 'e']
print(type(list1))
print(type(list2))
>>>>>>>>>>>>>>>실행 >>>>>>>>>>>>>>>>>>>>>
<class 'list'>
<class 'list'>자료형이 list 라는걸 확인할수 있죠. 간단.
⭐리스트의 활용법
list1에서 하나만 접근하고 싶을때
인덱싱(indexing)
리스트에는 순서가 있는데 1,2,3,4,5 라고 작성하면 1은 0번째 원소 라고 말한다. 2는 첫번째 원소, 3은 두번째 원소.
💡💡 리스트에서 순서가 0부터 시작한다.
list1 = [1, 2, 3, 4, 5]
print(list[0])
>>>>>>>>>>>>>>실행>>>>>>>>>>>>.
1리스트에 여러개가 담겨있는데 6(원소)을 추가로 담고싶으면 .append()
list1 = [1, 2, 3, 4, 5]
list1.append(6)
print(list1)
>>>>>>>>>>>>>>실행>>>>>>>>>>>>.
[1, 2, 3, 4, 5, 6]리스트에 또 다른 리스트를 추가하는 것 .extend()
list1 = [1, 2, 3]
list2 = [`a`, `b`, 'c`]
list1.extend(list2)
print(list1)
>>>>>>>>>>>>>>실행>>>>>>>>>>>>.
[1, 2, 3, `a`, `b`, `c`]참고 (리스트의 각종 기능들) : https://wikidocs.net/14
1-5 Python 기초 (2)
3) 조건문/반복문을 쓰는 이유
만약에 우리가 데이터 분석을 하려는데, 엄청나게 많은 양의 데이터를 처리해야한다고 생각해봅시다.
예를 들어서 아래처럼 데이터마다 누가 이상한 문자를 섞어놔서, 올바른 데이터 분석을 할 수 없는 경우가 발생했다면, 어떻게 처리하면 좋을까요?
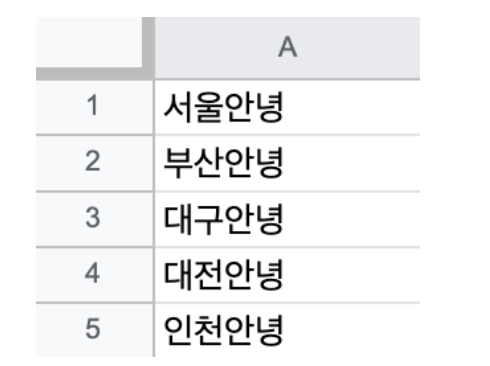
해당 데이터를 보고 일일이 '안녕' 부분을 지울 수도 있겠지만, 누가 하나하나씩 반복하면서 지워준다면 더 편할 거에요!
파이썬에서는 그 역할을 for문 (반복문) 이 해줄거에요.
# 실제 파이썬 코드는 아니고 예시입니다!
for 각각의 데이터 in 전체 데이터:
각각의 데이터에서 '안녕' 부분을 지운다.👨🏫
for문 (반복문)을 써서 복잡하고 귀찮은 작업을 한번에 처리 할 수 있다.
또 다른 예시를 들어보자면, 예를 들어서 우리가 자판기를 만들고 싶다면, 어떻게 하면 될까요?
500원짜리 커피를 파는 자판기라면, 500원 이상이 자판기에 들어왔을 때만 커피를 내어주어야 합니다. 400원도 안되고, 100원도 안되겠죠? 돈도 안들어 왔는데 나오면 안되니깐.
if문 (조건문)을 써서 일정 금액 이상인지 확인하는 작업을 하는 것이 조건문이 있는 이유.그럴 때 쓸 수 있는 것이 if문 (조건문) 입니다.
# 실제 파이썬 코드는 아니고 예시입니다!
if 들어온 돈 >= 500원:
커피를 내어준다위 코드에서 >= 이런 연산자를 썼는데, 이를 비교연산자라고 합니다.
다양한 종류가 있어서, 조건문을 더욱 다양한 방법으로 사용할 수 있게 만들어줍니다.
4) for문(반복문)
💡 반복해서 사용할 것이 있는 경우 사용하는 것이
for문입니다. 여러가지 용도로 사용할 수도 있는데, 파이썬의 리스트와도 연계하여 자주 사용되고는 한답니다. 🙂
참고 : https://wikidocs.net/22
🔥 for문을 사용할 때는 두 가지 규칙을 지켜주어야 합니다.
if문에도 적용되는 규칙
- 1. for문 끝에
: (콜론)을 붙여주어야 합니다.
- 반복해서 실행될 코드는
들여쓰기(indentation)을 해주어야 합니다.이때 들여쓰기를 하는 방법은 탭(Tab) 키를 한 번 누르거나 스페이스바(Spacebar)를 4번 사용할 수 있습니다.
👨🏫
range()함수가for문하면 꼭 나옴. 여기에 대해서 좀만 더 설명드리겠다.range 함수는range(시작 숫자, 끝 숫자) 형태를 사용, 이렇게 하면 명시한 범위에 해당하는 어떤 리스트를 만들어 주는 것임.
💡 주의할 점은 마지막 숫자는 포함되지 않는다.
- 끝 숫자는 포함되지 않고 숫자 리스트를 자동으로 만들어 주는 역할을 합니다. 예를 들어 range(0, 5)라고 하면 0, 1, 2, 3, 4 리스트를 만들어주는 것이죠.
그래서 만약 다음과 같이 for문을 작성하면 for문은 0, 1, 2, 3, 4를 순차적으로 꺼내오게 되는데, 총 5번 꺼내오게 되므로 결과적으로 for 문 아래에 들여쓰기를 한 코드는 총 5번 실행됩니다.
for i in range(0, 5): # 맨 끝에 :(콜론)을 사용하였다. print(i,'번 반복할게요~') # print 앞에 들여쓰기를 해주었다. >>>>>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>>>> 0 번 반복할게요~ 1 번 반복할게요~ 2 번 반복할게요~ 3 번 반복할게요~ 4 번 반복할게요~
🔥주의) colab 에서는 enter키 누르면 자동으로 tab되서 이런 형태이지만,
for i in range(0, 5): print(i) >>>>>>>>>>>>>실행>>>>>>>>>> 0 1 2 3 4
for문과print()가 같은 위치에, 들여쓰기가 안되어 있다면tab치기. 이렇게 tab친 부분만 for문이 작동하게 된다.
-
range()란 사실은 이 범위에 해당하는리스트를 만드는 것이다. -
i의 역할은리스트에 있는 요소들 하나하나씩을 갖고 오는 것이다. -
처음 반복할때는 0을 가지고 와서
i에 할당하고(그릇에 담기고) print문이 실행됨=출력됨. -
ex) 첫번째로 반복할때에는 첫번째 리스트에 있는 0을 가져와서 i에 담고 print(i)라는 명령문을 수행하게 된다. 순차적으로 반복문이 수행되게 됨.
for i in [0,1,2,3,4]:
print(i)
>>>>>>>>>>>>>>실행>>>>>>>>>>
0
1
2
3
4결과값이 같다.
👨🏫 💡for문이란, in 뒤에는 전체 반복할 요소를 명시함.
만약 이 요소가 5번 있으면 5번 반복하게 됨. 이 뒤에 들어갈 리스트가 있다면, 이 뒤에 들어갈 이 리스트 요소의 갯수가 총 반복 회숫가 된다.
만약 우리가 10번 반복시키고 싶다면
for i in range(0,10): = for i in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]:
총 10개의 요소가 담겨있는 리스트일 뿐이다. 라는 것이고
그래서 여기 뒤에다가 어떤 반복할 횟수 in 전체리스트를 명시했다면,
그럼 이 i에다가는 반복할 때마다 그 리스트 요소가 하나하나씩, 첫번째로 반복할때는 0이 들어가고, 두번째로 반복할때는 1이 i에 들어가고 이런 식으로 순차적으로 하나하나씩이 들어가게 된다. 라는 개념을 이해하는 것이 굉장히 중요하다.
🔥 리스트를 여러가지 넣어보면서 첫번째 반복할때는 i가 이런의미이고 저렇고 꼭 직접 리스트를 넣어보면서 실습 진행해보기.
👨🏫
indent(들여쓰기)를 한 것만 반복이 된다. 무슨 말인가? 🔥for i in [0,1,2,3,4]: print(i) print(1) #이라고 해봤습니다. 그랬더니! >>>>>>>>>>>>>실행>>>>>>>>>> 0 1 2 3 4 1빈복할 것은 다 반복을 했고. 5번 반복하라고 했었었는데 이렇게 0,1,2,3,4 를 한 번씩 i에다 담아서 출력하라. 라고 했었는데. 밑에 print(1)은 별개로 작동하는 코드가 된 것이다. 그래서 뒤에 1이 추가로 print됨.
그런데 만약에
indent를 더 추가해 봄.for i in [0,1,2,3,4]: # 인덴트를 한 것만 반복이 된다! print(i) print(1) #이라고 해봤습니다. 그랬더니! >>>>>>>>>>>>>실행>>>>>>>>>> 0 1 # 1 1 # 2 1 # 3 1 # 4 1 #대게 복잡해 졌다. 이게 뭐냐면 이 print(1)이라는 것도 이 반복하게 되는 어떤 명령어 안에 포함이 된 것이다. 그러니깐 이렇게 indent 하지 않았을때는 그냥 print(1) 1출력만 하고 끝이었는데 for문 아래에다가 indent를 해주니깐 그때부터는 print(1)도 반복하는 문장으로 포함된 것이다. 그러다보니 print(i)하고 또 print(1)이 추가로 계속 반복되게 됨.🔥🔥🔥
👨🏫 리스트를 바로 넣어서 for문을 만들어봤는데
예를 들어서 list를 하나 만들었다고 치면,
list1 = ['a', 'b', 'c', 'd', 'e']#문자는 꼭 따옴표를 붙여주셔야한다! for alphabet in list: print(alphabet) >>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>> a b c d e순차적으로 나오는 것을 확인할 수 있다.
지난 시간에도 말했는데 list1하고 문자 변수를 만들때에는 꼭 따옴표를 붙여줘야 한다.
-
in뒤에 들어가는게전체 리스트고, -
for 와 in 사이에 들어가는게 그 리스트에 있는 하나하나의 요소이다.
-
순차적으로 뽑아서
i에 넣고 출력했다. -
마찬가지로, list1에있는 요소인 a,b,c,d,e를 하나하나 순차적으로 뽑으면서 alphabat이라는 어떤 그릇에다가 담고, 반복문을 순서대로 수행하는 것이다.
-
그래서 처음 수행할 때는 alphabet에 a가 담기니깐 a가 출력된것 이고, 두번째로 반복할때는 b가 담기니깐 b가 출력된 것이고, 세번째로 반복할 때는 c가 alphabet에 담기니깐 c가 출력된 것이다. 등등.....
1-6 Python 기초 (3)
👨🏫 조건문 배울껀데, 전에 말했다 시피 자판기에 돈넣었을때, 일정 금액 이상이 들어왔을 때만 어떤 커피를 준다던지 기능을 만들기 위해서 쓴게 조건문이다 라고 설명 했었습니다.
강의자료를 보면서 조건문을 어떻게 작성하는 건지, 조건문이 필요한 게 어떤게 있는 지 같이 공부해보고 colab에서 실습해보자
5) 비교연산자
비교연산자란? 어떤 요소들이 있을때 예를들어 변수가 있을때, 비교하기 위해서 쓰는 것.
중요한 포인트는 비교를 해서 비교한 결과가 참이냐 거짓이냐에 따라서 조건문이 실행되기도 하고 실행되지 않기도 한다.
비교연산자가 무엇인지와 어떤 종류가 있는지 공부해야한다.
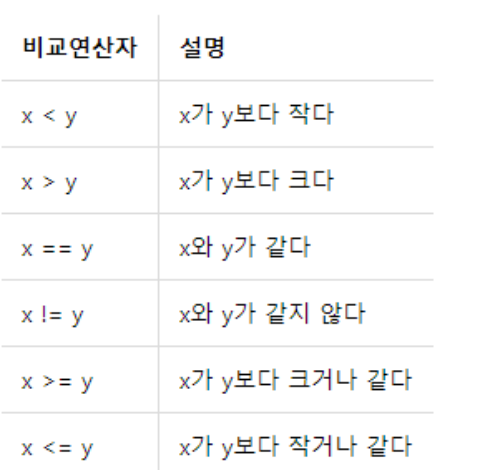
총 6가지 존재.
💡
==과=은 다르다.
=한개 있을때는 변수만들떄 썼다.=이 한개 있으면 그릇에다가 어떤 걸 담는다. 할당해라 라는 것이다.=하나는 그냥 할당해 라고 명령하는 것이라면.==이라는 것은 파이썬에게 물어보는 것이다. x==y라고 쓰면 x랑 y가 같아요?????!=는 같지 않나요? 라고 물어보는 것.
# 3이 5보다 작을까요?
3 < 5
>>>>>>>>>>>실행>>>>>>>.
True 그런데 만약에
# 3이 5보다 작을까요?
3 < 5
>>>>>>>>>>>실행>>>>>>>.
False 대답해줌.
5 == 5
>>>>>>>>>>실행>>>>>>>>.
True네 같아요 라고 답함.
6) if문 (조건문)
💡 if문(조건문)은 특정 조건이 참일 때는 특정 코드를 수행하고, 참이지 않을 때는 또 다른 코드를 수행한다를 정의할 수 있습니다. 앞에서 사용한 비교 연산자를 if문의 조건문에 사용합니다. 🙂
참고 : https://wikidocs.net/20
for문처럼 if문의 조건에서 실행되는 코드는 들여쓰기(indentation) 후 작성해야 합니다.
기본 형태
if 조건문: 수행할 문장1 # 들여쓰기 헤애힘 수행할 문장2 else: 수행할 문장A # 위가 참이아니라면, 아래문장을 수행해 주세요. 수행할 문장B여기
조건문가 비교연산자가 들어가는 곳.
👨🏫 그러면 if 조건문 : 하고 우리가 for문에서 공부했던 것처럼 들여쓰기를 해주면 이 조건문이 참일때는, (이 조건문이 맞을때, 우리가 물어본 질문에 대해서 파이썬이 네 라고 대답해 줬을때) 아래에 있는 명령문이 실행되는 것이다.
- 들여쓰기를 안하면? 들여쓰기를 한것만
for문과if문안에 포함이 안됨. - 들여쓰기 한것만 조건문에 참에 해당. 만약에 이 조건문이 참이 아니라면 밑에 A,B라는 명령문을 실행해주세요 라고
else라는 명령문을 써서 조건문을 작성해 죽ㄹ 수 있다.
👨🏫 기본적인 형태의
조건문if (조건문): # 조건문이 참일때 (맞는 말일때), 실행이 되는 부분 print('참이네요!') else: # 조건문이 거짓일 때 (틀린 말일때), 실행이 되는 부분 print('거짓이네요!')
되게 다양한 형태로 if문 을 작성할 수 있다.
조건을 여러 개를 설정하고 싶다고 생각해보자.
예를들어서 데이터 분석을 한다고 했을때 성적 관련해서 명령문을 수행하고 싶을때,
등등
elif라는 형태의 if문이 있다.
If <조건문>:
<수행할 문장1>
<수행할 문장2>
...
elif <조건문>:
<수행할 문장1>
<수행할 문장2>
...
elif <조건문>:
<수행할 문장1>
<수행할 문장2>
...
else: # else 뒤에는 조건문이 없어야 함!
<수행할 문장1>
<수행할 문장2>몇개 추가해도 상관없고 그냥 if와 else 사이에 elif가 들어간다.
🔥
elif뒤에는 조건문이 들어갈수 있다.else뒤에는 조건문이 절대로 없어야 함. 바로:을 붙여야 한다.
score = 85
if score >= 90:
print('학점이 A입니다.')
elif score >= 80:
print('학점이 B입니다.')
elif score >= 70:
print('학점이 C입니다.')
else: # else 뒤에는 조건문이 없어야 함!
print('학점이 F입니다....')
>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>
학점이 B입니다. 👨🏫 기본적인 형태에 대해서 꼭 아셔야 하고, 비교연산자에서 초보분들이 많이 하는 실수가 두가지. ==쓰기.
1-7 Python 기초 (4)
👨🏫 파이썬의 꽃이라고 할 수 있는 함수에 대해 배울 것. 우리가 앞으로 굉장히 자주 사용할 기능이며 정확하게 잏해야 다음 강의도 정확히 이해가 가능하다. 이번시간 꼭 집중해서 정확하게 이해하자.
- 왜 함수를 공부해야 하는지
- 그 함수를 어떤 식으로 만들고 사용 할 수 있는지.
7) 함수
💡 함수는 반복되는 부분이 있을 경우 이러한 코드를 따로 정의해놓고 필요할 때마다 호출할 수 있도록 합니다. 🙂
프로그래밍을 하다보면 특정 코드를 필요할 때마다 반복적으로 작성해야 할 때가 있습니다.
예시) 직육면체와 관련된 어떤 계산을 해야한다고 가정해보자. 밑의 식을 이용해서 계산하면 된다.

ex1)
5*8*2
>>>>>>>실행 >>>>>>>>>>>>
80
----------------------------------------------------
ex2)
2(4*3+3*5+5*4)
>>>>>>>>>>>>실행>>>>>>>>
94지속적으로 코드로 답을 작성하다보면 이런 의문이 드실 수 있습니다. 어차피 질문에 대해서 작성해야 하는 코드는 똑같고 입력만 계속 바뀌는 것 같은데 2(ab + bc + ca) 와 같은 수식을 자꾸 똑같이 작성해야 할 필요가 있을까?
이런 생각을 하셨다면 이미 프로그래밍에 대한 자질이 있으신 겁니다!🤩
- 이유 : 이와 같이 입력만 바뀌고 반복적으로 코드를 사용해 하는 경우를 위해
👨🏫 수많은 직육면체를 계산한다고 하면 쓸수 있는 방법이 함수이다.
- 함수의 기본 구조
def 함수이름(함수의 인자1, 함수의 인자2, ....):
수행할 코드
return 최종 결과def 라는 명령어로 시작되서. 함수명을 작성하고 괄호를 열고 함수에서 쓸 변수. 값들. 함수에서 쓸 그릇.을 여기에다 작성하면 되는데. 아직 이해안될 것이니 아래에서 인자에 대해 설명하겠다. 기본 구조, 골격에 대해 이해해 두면 좋겠다. 그래서 이렇게 함수에 쓸 인자들을 적어놓고 닫기함. 그리고 : 하시고 여기에다가 우리가 작성했던 겉넓이 공식이나 부피 공식을 작성하고 아래에다가 return 변수 혹은 어떤 계산을 한 결과값을 써주면 함수가 실행이 끝난 뒤에도 우리가 이 결과값을 쓸수 있도록 그렇게 만들어 놓는다.
그럼 우리는 이 함수를 실행하고 난 뒤에 그 결과값을 받아가지고 그걸 가지고 가공한다던지 더 계산한다던지 할수 있다.
지금 당장 이해안가도 이런 골격이라는 것 이해하기.
- 이런 형태의 함수가 있다고 가정해보자.
def volume(width, height, length):
return width * height * length # 코드 앞에 들여쓰기를 해줍니다.기본 구조를 떠올려 보세요.
def하고 그 뒤에 함수 이름. 여기서는 volume이라는 이름으로 함수를 만들었따.
그리고 그 뒤에다가 이제 우리가 이 함수를 쓸떄 필요한 변수들을 적어주는 거다.
- 예를들면 직육면체 부피를 계산한다고 했을때 우리가 가로,세로,높이 각각을 우리가 함수한테 말을 해줘야 겠죠.
가로,세로,높이 아무것도 모르는데 함수가 갑자기 직육면체의 부피를 계산해낼 수는 없을 거잖아요. 그래서 이 함수한테 필요한 어떤 값들이 무엇,무엇,무엇이다. 그니깐이번 부피 계산하는 함수 같은 경우에는가로 ,높이, 세로다 라고 이런것을 명시해주는 것.
✔ 명시를 해줘야만 이 함수가width, height, length이런 값들이 이 함수가 실행될 때 필요하구나 그래서 사용자가 이런width, height, length를 사용자가 입력을 하겠구나. 라는 것을 알 수가 있게 되는 것.
그래서 volume 뒤에 들어간 값들, width, height, length를 우리는 인자 함수의 인자라고 부릅니다.
def+함수 이름(함수의 인자들) +:그 뒤에indet잊지 마시고.return가로 * 세로 * 높이하면
이 결과값이 나중에 또 사용할수 있도록 이 함수가 만들어 준다.
이것은
for문,if문,함수다:뒤에는indent를 한다라고 그냥 외우면 된다.
:뒤에는 항상 indent를 해야만 그안에 들어가서 그 역할을 수행하게 된다는 거. 꼭 기억하기.
for문, if문처럼 함수 내부에서 실행되는 코드는 들여쓰기(indentation) 후 작성해야 합니다.
colab으로 >
부피를 구하는 함수를 만든 것 뿐. 함수를 실행한 것이 아니다. 계산 하라고 한 것이 아니라 계산을 할 어떤 틀을 만든 것 뿐입니다.
def volume (width, height, length) :
return witdth * height * length
width, height, length 값이 있어야만 함수가 실행 될 수 있다! 우리가 함수를 실행할 때 명시를 해 줄 겁니다!
retrun 의 경우 결과값을 나중에 또 사용할 수 있도록 하는 조치.
volume(5, 8, 2)
>>>>>>>>>>>>>실행>>>>>>>>>>.
80💡👨🏫 꼭 주의해야 할 차이점. 우리가 return 안했는데 출력이 됬잖아요. 그러면 🔥return이 출력하라는 뜻인가? 절대 아님.
원래라면 출력 안되는게 맞는데 colab에서는 사용자 편하라고 print를 안써도 출력 해주는 것이다. 원래 라면 return한 값을 출력할려면 print 값을 붙여야 한다.
ex)
volume(1, 2, 3)
volume(5, 8, 2)
>>>>>실행 >>>>>>>>
80 colab에서 여러줄은 출력해주지 않는다. 다 print로 감싸면 다 출력 해준다.
ex)
print(volume(1, 2, 3))
print(volume(5, 8, 2))
>>>>>실행 >>>>>>>>
6
80 🔥 ruturn이라는 것은 출력하라는 뜻이 아니라 결과값을 나중에 또 사용할 수 있도록 하는 조치일 뿐이다. 무슨말이지? 의문.
예시) volume이란 함수를 정의해놨으니깐 이걸 이용해서 한번 결과값을 어딘가에 저장해 보겠다.
volume1 = volume(5, 8, 2)
print(volume1)
>>>>>>>>>>실행>>>>>>>
80volume1 에다가 volume이 함수를 실행한 그 결과값, 그러니깐 우리가 정의했던 width, height, length 결과값이 volume1 에다가 저장이 된 것이다.
만약에 return을 안했더라면?
def volume (width, height, length) :
#return witdth * height * length
volume(1,2,3)
>>>>>>>>>>>실행>>>>>>>>>>>
6
>>>>>>>>>>>>>>>>
volume1 = volume(5, 8, 2)
print(volume1)
>>>>>>>>>>>>>실행
80
None
print(volume1) 했는데 None이 떴다. 무슨말이지? 아무것도 없다는 뜻.
👨🏫
return과
return했을 때는, volume1을 출력하라고 하니깐 80이 출력되는 것이다.return을 써야만 우리가 나중에 다른 변수에다가 결과값을 저장할 수 있다.
👨🏫 직육면체의 겉넓이를 계산하는 함수를 만들어 보자.
def surface_area(width, height, length):
return (2 * (width * height + width * length + height * length))
# 이렇게 하면 함수가 정의 된 것이다.
# 이제는 괄호안에 명시했던 것이 뭔지를 그냥 추가적으로 작성해 주면 된다.
surface_area(2, 4, 6)
# 파이썬에 가로는 4고 높이는 3이고 세로는 6이라고 말해주는 것이다.
#그래야만 그 값들이 위로 들어가게 되면서 밑에 들어가면서 함수가 제 기능을 할 수 있게 된다.
>>>>>>>> 실행>>>>>>>>>>>>>>>>>>>>>>>
88
surface_area와 같은 함수명은 하고싶은거 하면 된다.- 🔥 우리가 함수를 정의할 때 명시했던 인자는 함수를 실행할 때 꼭 적어줘야 합니다.
또 변수 area1 = surface_area(2, 4, 6) 에 저장한다고 했을때,
area1 = surface_area(2, 4, 6)
print(area1)
>>>>>>>>>>>실행>>>>>>>>>>>>
88are1에다가 surface_area의 결과값 (width * height + width * length + height * length) 이 값이 return이 되면서 area1에 그 값이 저장이 되고 우리가 사용할 수 있게 된다.
👨🏫
- 그런데 만약에 이것을 print만 했다면
def surface_area(width, height, length):
# return 2 * (width * height + width * length + height * length)
print(2 * (width * height + width * length + height * length))
area1 = surface_area(2, 4, 6)
print(area1)
>>>>>>>>>>>실행>>>>>>>>>>>>
88
None- 여기서 88뜨는 이유는 위에 print()있어서 된 것이고,
- area1에 아무것도 저장된게 없기 때문에 print() 하면 None이 나온다
ex ) 같은 패턴, print 와 reuturn 차이 알기.
print 만 한 경우,
def add(a, b):
print(a,'하고',b,'를 더하면',a+b,'입니다.')
add(3,4)
>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>
3 하고 4를 더하면 7 입니다. 하지만 이 함수는 값을 리턴하지 않으므로 리턴한 값을 변수에 저장할 수 없습니다.
var = add(3,4)
print(var)
>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>
3 하고 4 를 더하면 7 입니다.
None그렇다면, 값을 return 하도록 함수를 수정해 보자.
def add(a, b):
print(a,'하고',b,'를 더하면',a+b,'입니다.')
return a + b
var = add(3, 4)
print(var)
>>>>>>>>>>>>>실행>>>>>>>>>>>>>
3 하고 4 를 더하면 7 입니다.
7
위와 같이 var에 7이라는 값이 저장되어져 있음을 확인할 수 있습니다.
👨🏫 정리
함수의 인자는 우리가 함수를 실행하는데 있어서 필요한 어떤 값들을 미리 명시해 놓는 것을 말한다. 그래서 함수한테 인자에 해당하는 값이 뭔지 말해주지 않으면 함수가 실행 안됨. 예를 들어서, 3가지 인자를 미리 만들었으면 실행할 때는 세가지를 넣어야 하는 것이다.
👨🏫 아직은 감이 안올수 있는데 앞으로 함수 만들고 할 일이 많을테니깐 그때 그때 추가적으로 설명드리겠다. 그때마다 복습한다, 이해해 가는 과정이라 생각하고 함께 함수 만들어 가며 이해해가기.
그런데 함수 기본구조, 그리고 함수를 왜 쓰는지, 어떻게 정의할수 있는 지는 이번시간에 다 이해하고 넘어가자.
1-8 Python 기초 (5)
개념이 어려울수 있는데 직접 쓸순 없더라도 이런 것이 있구나 라고 이해하고 앞으로 데이터 분석하면서 필요한 마다마다 설명 할 것이다. 편하게 듣자. 개념이해에 중점두고 수업듣자
8) 클래스
💡 예를 들어, 아주 많은 몬스터들의 HP를 관리해야 하면 어떻게 해야 편할까요?

뭐가 편해보이는 가? 답은? 2번
쉽고 직관적일거 같다. 이것이 클레스를 이용하는 방법
예시)
class Monster():
hp = 100
mp = 10
def damage(self, attack):
self.hp = self.hp - attack
monster1 = Monster()
monster1.damage(120)
monster2 = Monster()
monster2.damage(90)
우리가 앞으로 클레식을 정의할 일은 한번도 없겠지만. 이런식으로 클래스라는게 있고 이런식으로 정의하는 구나를 이해하고 넘어가면 된다.
클래스 (class)어떠한 틀을 짜는 것과 같다. 몬스터란 'hp', 'mp' 등을 가진다 라고 미리 틀을 만들어놓는거죠.그러면 우리는 그때그때 몬스터란 무엇인지에 대해서 정의할 필요없이, 그냥 Monster() 를 호출해서 몬스터를 생성할 수 있게 되는 겁니다!
- 그렇게 생성된 결과물을
인스턴스 (객체)라고 합니다.monster1 = Monster() # 객체 = 클래스 (위에 언급됬던 그 class)이렇게 되어있으면, monster1 이라는 이름의 몬스터 객체를 생성한 것입니다.
- Monster()가
클래스 명괄호가 들어가는 것, monster1 이것이 그 클래스로 찍어 만들어 내진 Monster()이라는 틀로 만들어진 첫번쨰 몬스터가 생성이 되는 것이다.
👨🏫 지금은 정확하게 이해하실 필요는 없어요. 그런데 우리가 앞으로 나중에 데이터 분석을 하면서 머신러닝 모델을 만들거나 할 때, 이런 식으로 머신러닝 모델을 호출하게 됩니다. 그러니깐 이렇게 틀을 막 많이 누군가 만들어 놨어요. 우리는 그 틀에다 머신러닝 모델 하나 이렇게 찍어내면 우리가 이제 사용할수 있는 머신러닝 모델을 만들어 내게 된다.
앞으로 클래스는 우리가 뭔가를 만들 때, 번거롭게 일일이 하나하나 명시하지 않아도 그 틀에 맞춰서 뭔가를 만들수 있도록 미리 만들어놓은 어떤 틀을 클래스라고 한다. 그리고 그 클래스에 반죽을 넣어서 거기서 찍어내서 만들어진 어떤 결과물을 우리는 객체, 인스턴스라고 한다. 이것만 이해하고 넘어가시면 됩니다.
참고 : https://wikidocs.net/28
우리가 클래스에 대해서 정의를 할떄, 이 부분을 보면
클래스 안에다가 indent 를 한번 하고 def 어떤함수. 이런식으로 함수를 정의해놨다.
이 틀에다가 함수까지 정의를 할 수 있게 된거죠. 이게 어떤 말이냐하면 이 틀로 찍어내진 결과물들만 이 함수를 사용할 수 있다는 것입니다.
def damage(self, attack):
self.hp = self.hp - attack예를들어서) 붕어빵은 사람이 먹을 수 있잖아요. 그러니깐 붕어빵이기 때문에 먹을수 있지, 휴대폰을 먹을수 없으니깐. 붕어빵이라는 틀로 만들어 진거는 사람이 먹을수 있다. 먹을수 있는 어떤 행동을 할수 있다. 라는 걸 이런식으로 함수로 정의를 해 놓은 것이다.
그러면 그때그때 우리는 이 함수를 호출하면서 어떤 기능을 수행할 수 있게 되는 것이다. 그러니깐 클래스 안에다가 함수를 정의를 하게 되면 그 클래스로 만들어진 객체는 이 함수를 사용할 수 있게 되고. 클래스로 만들어진 객체이기 때문에 이 함수를 사용할수 있게 되고.
위에 함수를 정의한 것은 언제 어디서든지 누구나 그 함수를 사용할 수 있는 거고요. 이 클래스같은 경우는 언제 어디서든지 누구나 쓸 수 있는게 아니고 이 클래스로 만들어진 객체만 이 함수를 사용할 수 있게 된다. 그래서
monster1.damage(100)이런식으로 사용 가능. 객체.함수명() 그리고 괄호 안에 그 함수가 실행되기 위해 필요한 인자.그 전시간에 인자가 무엇인지 대해서 공부를 했었죠. 이런식으로 함수 사용 가능.
- ex)
리스트기억 나시나요?리스트도 사실은 틀인거에요. 클래스라는 틀로 만들어 진거죠.
리스트이기 때문에 append를 할수 있는 거였어요. 갑자기 그냥 숫자에다가 append를 할수는 없음.
만약에 Monster을 정의하면서 데미지를 입히는 그런 공격에 대해서 우리가 함수를 정의를 해놨기 때문에 그래서 그 Monster이기 때문에 이런 공격이라는 함수를 사용할 수 있게 되는 것입니다.
바로 함수를 함수명 () 해서 함수를 사용할 수 도 있지만 이런식으로 특정한 어떤 객체들, 어떤 요소들만 쓸수 있는 함수가 있다. 이것만 이해하고 넘어가시면 됩니다.
💡 클래스의 모든 부분을 다 이해하실 필요는 없습니다!
객체를 위와 같은 방식으로 생성할 수 있고, 그 객체가 가진 함수를 (객체명).(함수명) 을 통해서 이용할 수 있다는 사실만 기억하고 넘어가시면 됩니다.
(앞으로 우리가 이용할 패키지, 모듈에서 제공하는 기능들을 위와 같은 방식으로 이용하게 될 겁니다.)
즉, 붕어빵을 예시로 들면, 그 붕어빵 틀 (기계) 가 클래스 인 것이고, 붕어빵 그 자체가 인스턴스 (객체) 에 해당하는 것이죠.

붕어빵이 되는 이유는 붕어빵 틀에다가 반죽을 부었기 떄문이다.
9) 예외처리 - Try, except 문
Try, Except 문은 데이터를 가공할 때 자주 쓰이는 문법입니다.
가공하기 전의 데이터들은 일관되지 않은 경우가 많고, 그러다보면 일괄로 처리하기로 어려운 경우가 생깁니다. 데이터를 가공하는 과정에서 특정 데이터에서만 에러가 발생하는 경우도 있기 때문에, 그럴 때는 Try ~ except 문을 이용해서 에러가 발생하는 데이터는 다른 방식으로 처리하라고 명령할 필요가 있습니다.
예시) 변수 a,b 가 있다고 가정해보자
a = 10
b = 0
print(a/b) 만약 a를 b로 나누려고 한다면, 0으로는 수를 나눌 수 없기 때문에 ZeroDivision 에러가 발생할 겁니다. 그럴때 사용,
try:
print(a/b)
except:
print('0으로는 나눌 수 없어요!')try를 먼저 실행하고, 에러가 발생할 것 같으면 에러 대신에 여기 except 아래의 부분을 수행한다. -> 에러 대신에 except: 아래 print() 수행한다.
이것도 마찬가지로 : 뒤라서 indent 가 있다.
👨🏫 사실은 클래스라는것이 굉장히 어렵다. 원래 어려운거고 한번에 이해할수 없다.
💡 요약 : 클래스는 그냥 어떤 틀에다가 무언가를 찍어내서 객체라는 것을 생성할 수 있고 그 객체는 그 객체만이 가진 함수라는게 있을수도 있어서 그거를 우리가(객체명).(함수명) 이부분만 딱 기억하고 그냥 넘어가셔도 되요.
1-9 Python 기초 (6)
👨🏫 패키지란 무엇인가, 데이터분석에 있어서 꼭 필요한 패키지 중에 하나인 판다스에 대해 공부하고, 판다스의 뼈대가 되는 데이터프레임이라는 형태의 자료구조에 대해서 같이 공부해볼 예정.
10) 판다스와 데이터프레임
패키지 (package)는 누군가가 이미 만들어놓은 함수, 클래스 덩어리를 말합니다. 우리가 어떤 기능을 직접 구현하지 않더라도, 바로바로 사용하라고 누군가가 이미 기능을 만들어놓은 것이죠!import 라는 명령어를 사용해서, 그저 가져오기만 하면 바로 사용할 수 있습니다!
💡
판다스(Pandas)는 파이썬 데이터 분석을 위한 필수 패키지 중 하나입니다. 그중 Pandas가 제공하는표 (테이블)형태의 구조인 데이터프레임은 주로 데이터를 읽어서 저장하고, 연산을 위해 많이 사용됩니다. 매우 중요합니다!! 🙂
Python에서 판다스(Pandas)라는 패키지를 불러오는 방법
- import pandas as '사용자가 정한 이름'
- import pandas 라고 해도 되지만 일일이 치기 불편하여서 약자 형태 이름 사용.
그럴때는 뒤에 as 를 붙여서 '우리가 사용하고자하는 이름' 을 명시해주면, 그 이름으로 사용할 수 있습니다. 보통은 짧게 약자를 만들어서 이름을 붙여놓고, 그 약자 형태의 이름을 사용합니다. 그런데 pandas 의 경우에는 관례적으로 약자를 pd 라고 정해놓고 사용하므로 pd 외에 다른 이름은 사용하시지 않는 것이 좋습니다. 불러오는 방법은 다음과 같습니다
import pandas as pd- 이제 'pd.함수이름' 과 같은 형식으로 판다스가 제공하는 함수/기능들을 사용할 수 있게 됩니다.
- 어떤 표를 파이썬에서 구현한게 데이터프레임이다.
Pandas는 데이터프레임 이라는 구조를 지원한다. 데이터프레임이란 행과 열이 존재하는 2차원 테이블
데이터프레임이름 = pd.DataFrame({'칼럼명1' : [원소1, 원소2... 원소n],
'칼럼명2' : [원소1, 원소2... 원소n],
...
'칼럼명N' : [원소1, 원소2... 원소n]}}▶[코드스니펫] items
import pandas as pd # pd라는 것을 사용하려면 꼭써야한다.
# df란 이름의 데이터프레임을 생성합니다.
items = {'code' : [101, 102, 103, 104, 105, 106, 107, 108],
'과목': ['수학', '영어', '국어', '체육', '미술', '사회', '도덕', '과학'],
'수강생':[15, 15, 10, 50, 20, 50, 70, 10],
'선생님': ['김민수','김현정','강수정', '이나리', '도민성', '강수진', '김진성', '오상배']}
df = pd.DataFrame(items)
df
>>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>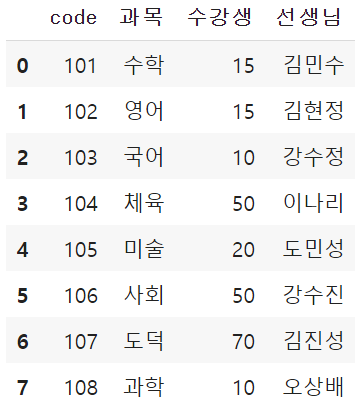
데이터 프레임에 넣어놓고 df 하면 한눈에 보면서 직관적여짐.
표시하는 방식에는 여러가지가 있다.
1) head() : 머리. 데이터프레임의 윗부분 출력하기.
# head()를 하면 상위 5개의 행만 출력
df.head()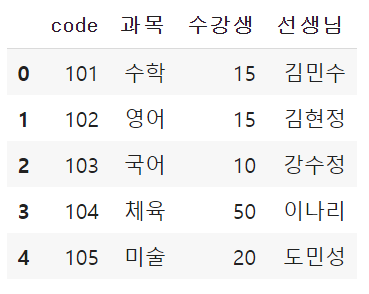
2) tail() : 꼬리. 데이터프레임의 아래부분 출력하기.
# tail()를 하면 하위 5개의 행만 출력
df.tail()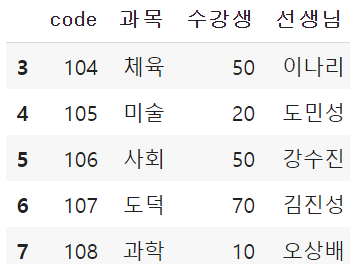
앞으로 자주쓴다. 왜냐하면 어떤 데이터를 불러와서 분석을 시작할때 데이터 안에 뭐가 들어있는지 보기 위해서
3) sample() : 데이터프레임의 행들 중에서 무작위로 괄호 안에 들어가 있는 개수 만큼 행을 출력하라는 명령어
# sample(숫자)를 하면 랜덤으로 2개의 행만 출력
df.sample(2)
df라는 이름으로 데이터 프레임을 만들었으니 df2로 만들기.
items2 = {'code' : [109, 110],
'과목': ['컴퓨터', '한자'],
'수강생':[10, 12],
'선생님': ['이철민', '김영우']}
df2 = pd.DataFrame(items2)
df2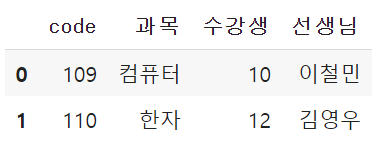
4) *concat → concatenate; 합치다
# 데이터프레임 2개를 연결
total_df = pd.concat([df, df2])
total_df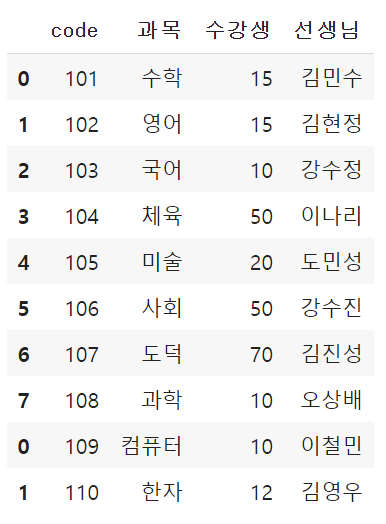
데이터 프레임은 어쨌든 파이썬 상에서 표 형태로 출력되는 데이터인데, 만약에 데이터프레임을 저장해놓고 나중에 또 사용하고 싶은 경우.
6) 저장하는 방법
- 데이터프레임 -> csv (저장)
csv는 엑셀파일의 한 종류# 데이터프레임을 csv 파일로 저장 total_df.to_csv('data.csv', index=False)
# 데이터프레임을 csv 파일로 저장
total_df.to_csv('data.csv')저장된 것 확인함.
그런데 이렇게 하면 unnamed 라는 어떤 열이 하나가 추가됨. 왜냐면 저장할때, 그냥 to_csv라고 하면 인덱스, 이 행의 번호까지도 같이 저장되서 표시 안하고 싶어서,
7) 다시 불러오기
- csv -> 데이터프레임 (저장)
- sep 이 부분은 어떤 것 (,) 을 기준으로 열을 나누겠다.
# csv 파일을 읽어서 데이터프레임에 저장 new_df = pd.read_table('data.csv', sep=',') new_df
