데이터 분석
1.데이터 분석 커리큘럼

데이터분석 종합반은 파이썬 기초 문버부터 데이터를 수집하고, 정제하고, 분석하고, 시각화하는 데이터 분석 과정 전반에 대해 먼저 익숙해지고, 다양한 예제를 통해 데이터로부터 통찰을 얻는 방법 그 자체에 집중했습니다. Python, Pandas , HTML, Beaut
2.웹 크롤링이란?

🐼 Pandas : 파이썬의 대표적인 데이터 분석 도구로 금융 데이터 분석을 위해 만들어졌습니다.🧮 Numpy : 파이썬의 수치계산 도구입니다.📊 matplotlib : 파이썬의 대표적인 데이터 시각화 도구입니다.📊 seaborn : matplotlib을 사용
3.데이터 분석 1주차 정리
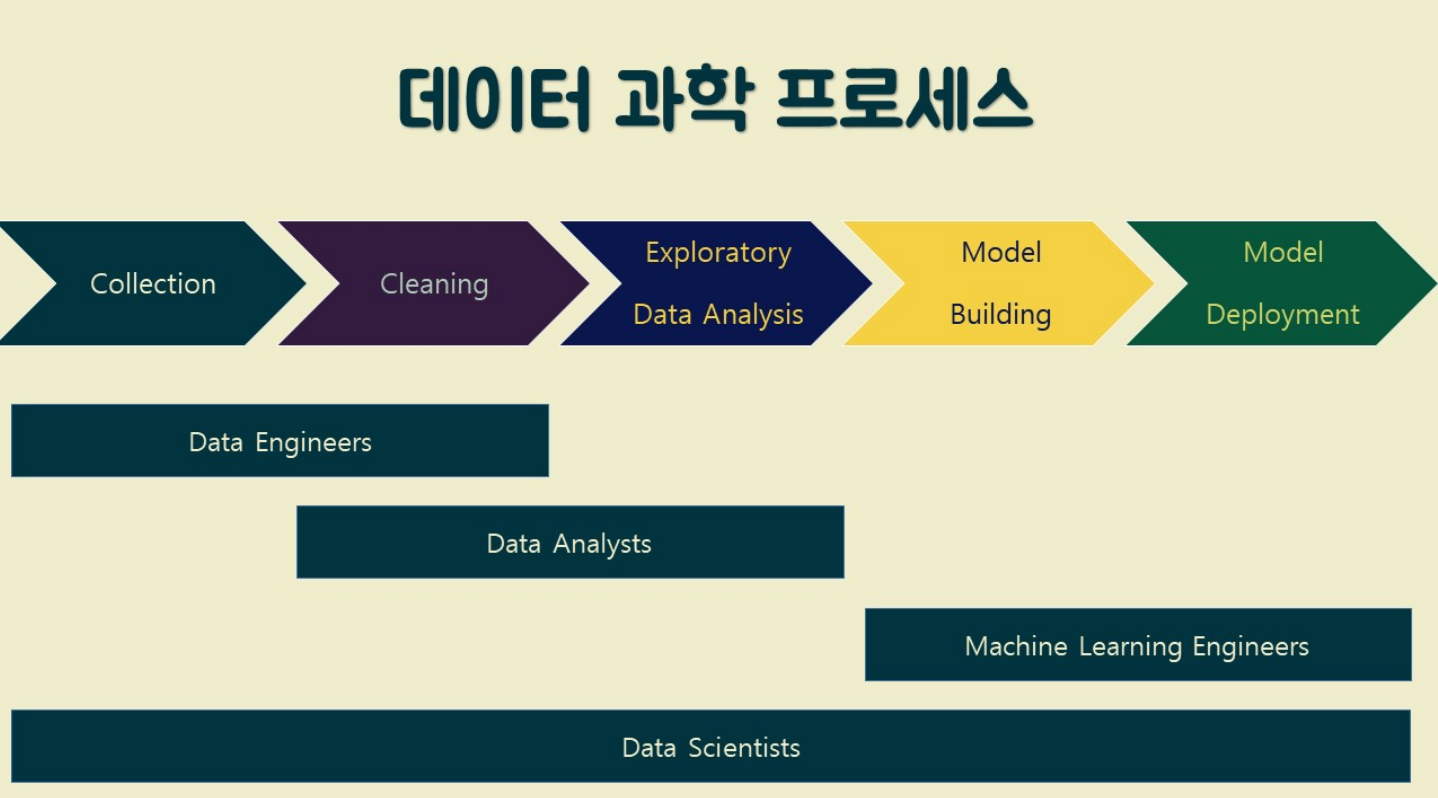
수업목표1\. HTML 문서의 개념에 대하여 이해한다. 2\. 구글 Colab 사용방법을 익힌다. 3\. 태그의 형식에 대해서 이해한다. 4\. 크롤링을 위한 패키지 BeautifulSoup4의 사용법을 이해한다. 1) 데이터 분석이란?현실에 존재하는 실제 문제에 대해
4.데이터 분석 1-2 엑셀로 데이터 분석 맛보기
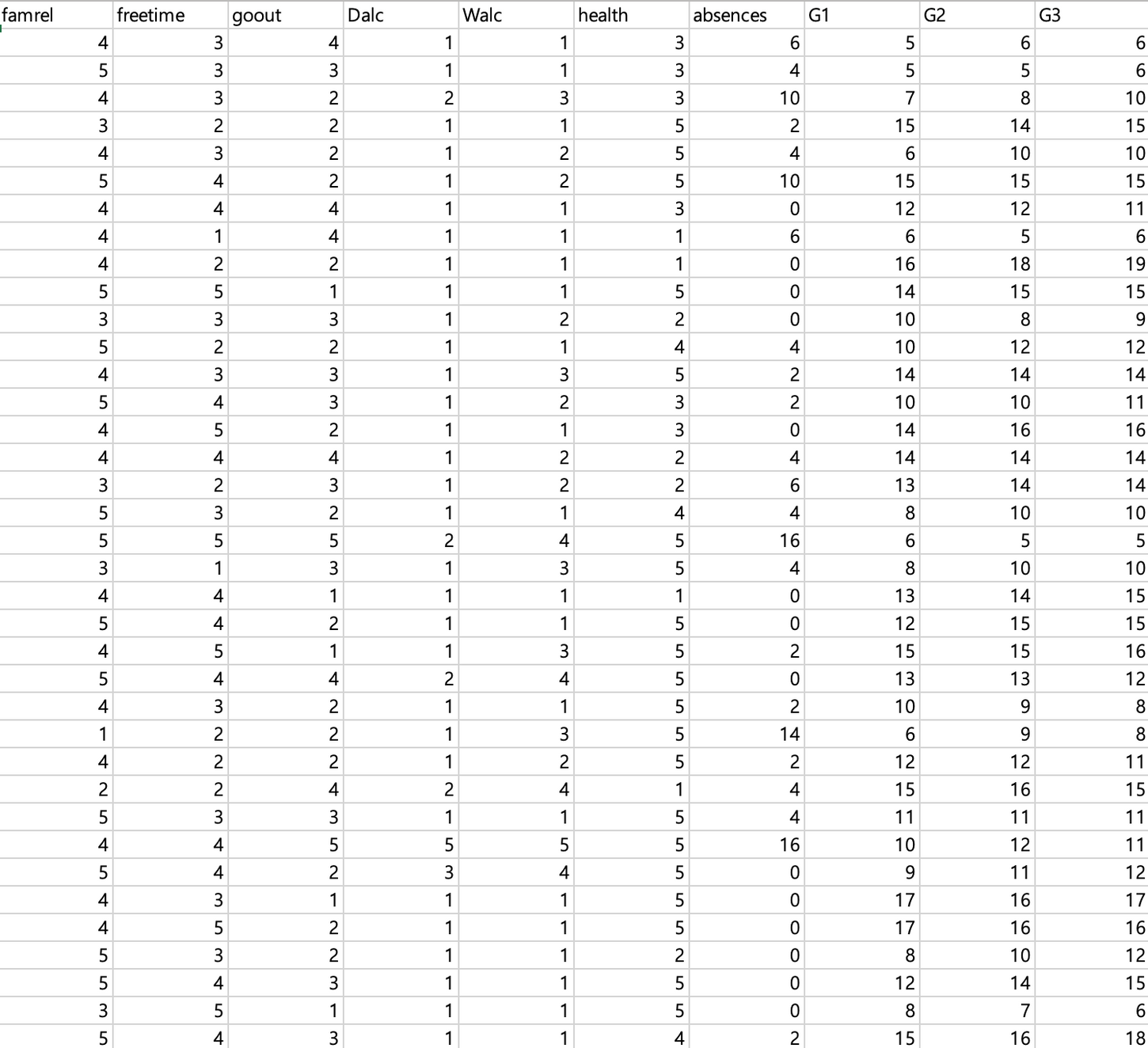
성적과 다른 요소들의 상관관계 ? \-> 가설 : 성적과 다른 요소들(공부 시간, 노는 시간 등)의 관계가장 먼저 해야할 것 : 어떤 데이터를 통해서 분석할 수 있을지 생각.필요한 데이터 무엇인지 찾기. ex) 출처: https://www.kaggle.com/
5.데이터분석 1-1~3 엑셀로 데이터 분석 맛보기
판다스와 데이터프레임
6.데이터 분석 1-4~9 Python 기초(1)~(6)
스파르타 코딩클럽 참조자료(https://teamsparta.notion.site/1-8348e94d2e7e45a7bedce7c37619ee06패키지 (package) 는 누군가가 이미 만들어놓은 함수, 클래스 덩어리를 말합니다. 우리가 어떤 기능을 직접 구현
7.데이터 분석 1-10~11 웹과 웹스크래핑 패키지 이해
지니뮤지의 1~50위 곡을 스크래핑 해보세요
8.데이터 분석 1-12~13 네이버 뉴스 구조 파악하기, 가져오기

2) 데이터 저장하기
9.데이터 분석 4-13 4주차 끝 & 숙제 설명
📄 앞서 배운 다양한 회귀 분석을 통해서 보스턴 주택 가격을 예측해봅시다.https://www.rdocumentation.org/packages/spdep/versions/0.6-15/topics/boston각 변수의 의미는 다음과 같습니다: ( 저희 데이터
10.데이터 분석 1-14 1주차 끝& 숙제 설명
실전. 직접해보기. 고민하면서 강의 보면서 하기.
11.데이터 분석 1-HW. 1주차 숙제 해설
12.데이터 분석 2주차 정리

수업목표1\. 판다스와 데이터프레임 사용법에 대해 복습한다. 2\. 형태소 분석과 워드 클라우드를 실습해본다. 3\. 머신러닝 기법을 이용해 분류하기를 실습해 본다. 목차01\. 2주차 배울 것 02\. 텍스트 마이닝 03\. 데이터 시각화 - 워드 클라우드 04\.
13.데이터 분석 2-1~2 데이터 마이닝을 위한 기본 세팅

수업 목표1\. 판다스와 데이터프레임 사용법에 대해 복습한다. 2\. 형태소 분석과 워드 클라우드를 실습해본다. 3\. 머신러닝 기법을 이용해 분류하기를 실습해본다. 한글 세팅 코드 : Colab 연결 할때마다 세팅해야 함 -> 한글 폰트가 코랩에 등록 됨.런타임-런타
14.데이터 분석 2-3~5 텍스트 마이닝 (1)~(3)
2) 뉴스 데이터의 카테고리별 빈도수 파악하기
15.스파르타 코딩클럽 데이터분석 2-6 머신러닝, 번외(2)

불용어 제거
16.데이터 분석 2-10~14 영화 줄거리를 이용해서 장르 분류해보기 (1)~(5) - 기초 개념, 데이터, 벡터화, 머신러닝, 번외
2-5 영화 줄거리를 이용한 장르 분류해보기 (1) - 기초개념, 데이터, 벡터화 머신러닝 원리 맛보기 줄거리만 보고 장르를 예측할 수 있을까? IMDB 줄거리 데이터 탐색하기 데이터 전처리 DTM(Document-Term Matrix) TF-IDF(Term
17.데이터 분석 2-15 2주차 끝 & 숙제 설명
📄 네이버 쇼핑 리뷰 데이터를 이용해 각각 긍정/부정 리뷰의 워드 클라우드를 만들어보고, 긍정/부정을 분류할 수 있는 모델을 만들어보세요.▶ \[코드스니펫] 네이버 쇼핑 리뷰 데이터
18.데이터 분석 2-HW
▶코드스니펫 - 2주차 숙제 정답 코드https://colab.research.google.com/drive/1nLJc_QJiRl7DWB8ALQojxTIgzh06s-dW?usp=sharing
19.데이터 분석 3주차
수업 목표1\. 데이터프레임의 사용법을 익힌다. 2\. 파이썬을 이용해서 데이터를 각종 차트로 시각화해본다. 3\. 상관 관계 분석에 대해서 이해한다.
20.데이터 분석 3-1~2 주류 데이터 분석 - 데이터 프레임 익숙해지기 (1)

데이터 프레임 사용법을 익힌다. 파이썬을 이용해서 데이터를 각종 차트로 시각화해본다. 상관 관계 분석에 대해서 이해한다. 👨🏫1~2차는 처음 파이썬을 접하기도 했고 처음 나오는 개념들도 많아서 처음 접하시는 분들은 되게 생소하고 어려웠을 수도 있어요. 3주차에는
21.데이터 분석 3-3 주류 데이터 분석 - 데이터 프레임 익숙해지기 (2)
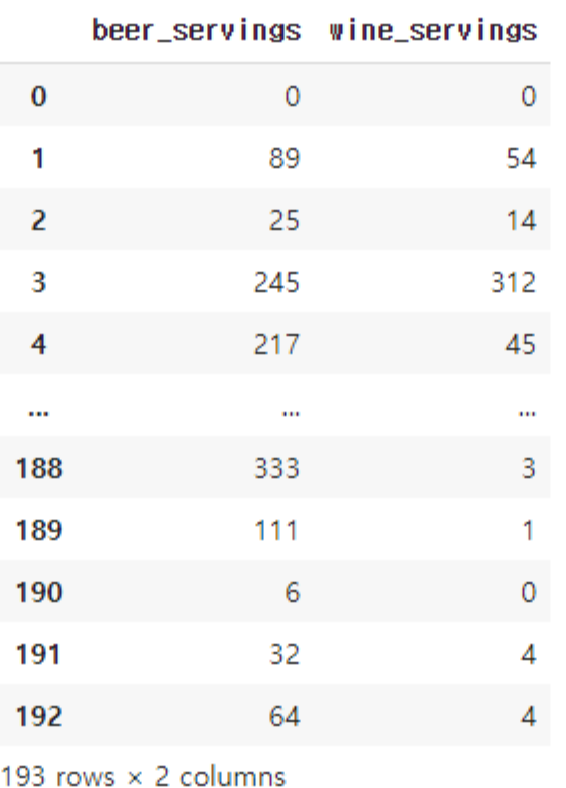
데이터프레임의 특정 열에 접근하는 가장 쉬운 방법은데이터프레임의 이름.열의 이름과 같은 방식으로 접근하는 것입니다. 다시 말해, 데이터프레임의 이름을 적고, 온점을 찍은 후에 열의 이름을 적으면 해당 열만을 불러옵니다.또 다른 방법은데이터프레임의 이름\['해당 열의 이
22.데이터 분석 3-4 주류 데이터 분석 - 데이터 파악하기

isnull().sum()은 해당 데이터프레임의 각 열에서 Null 데이터가 총 몇 개인지를 출력합니다.continent라는 열에서 총 23개의 Null(결측) 데이터가 있음을 확인할 수 있습니다.이러한 결측 데이터가 포함된 행은 dropna() 라는 함수를 통해서 제
23.데이터 분석 3-5 주류 데이터 분석 - 원하는 데이터 찾기
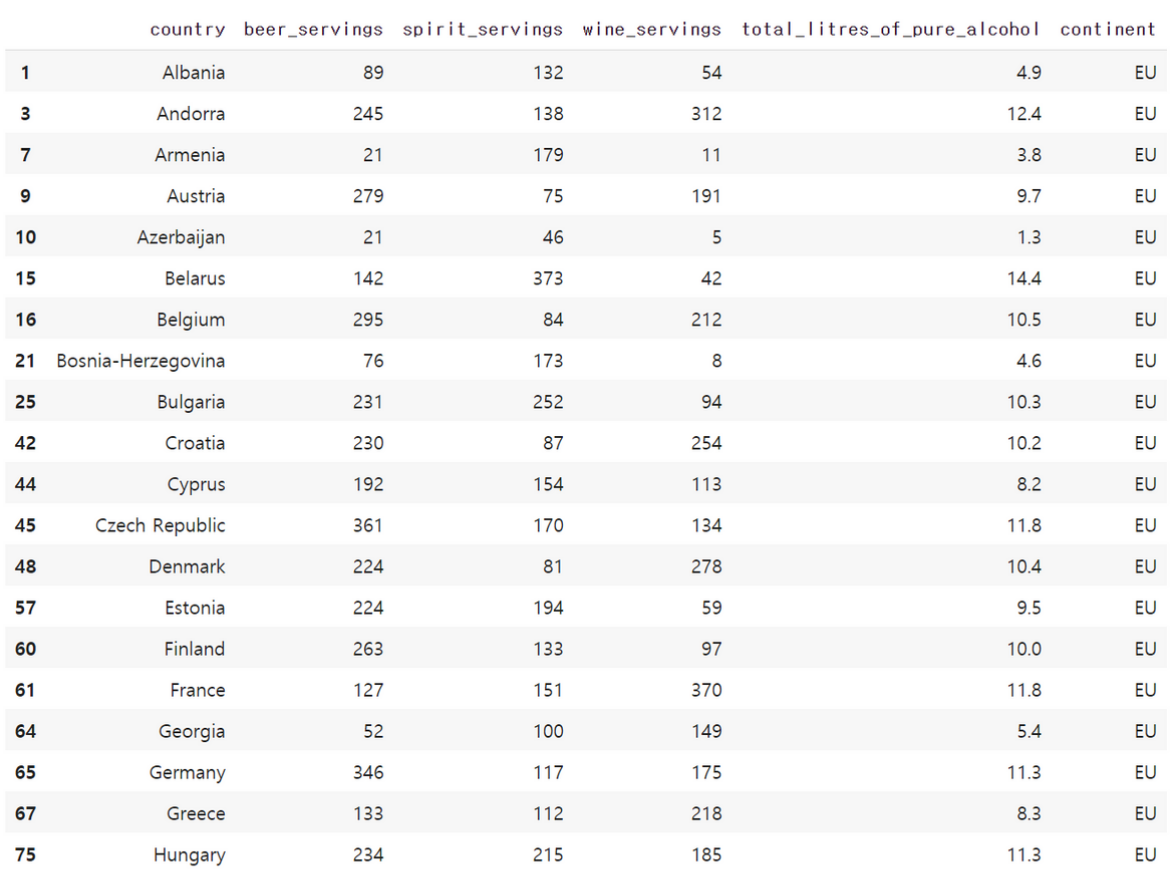
데이터프레임에 우리가 원하는 조건을 걸어서 해당 조건을 충족하는 값들만을 뽑아오는 것도 가능합니다. 우선 특정 열에 대해서 조건을 걸었을 때 어떤 값을 반환하는지를 봅시다.데이터프레임의 이름.특정 열의 이름 == '특정값'이라는 코드는 각 행에서 해당 조건을 만족하는지
24.데이터 분석 3-6 주류 데이터 분석 - 정렬과 로직과 수치 정보의 결합
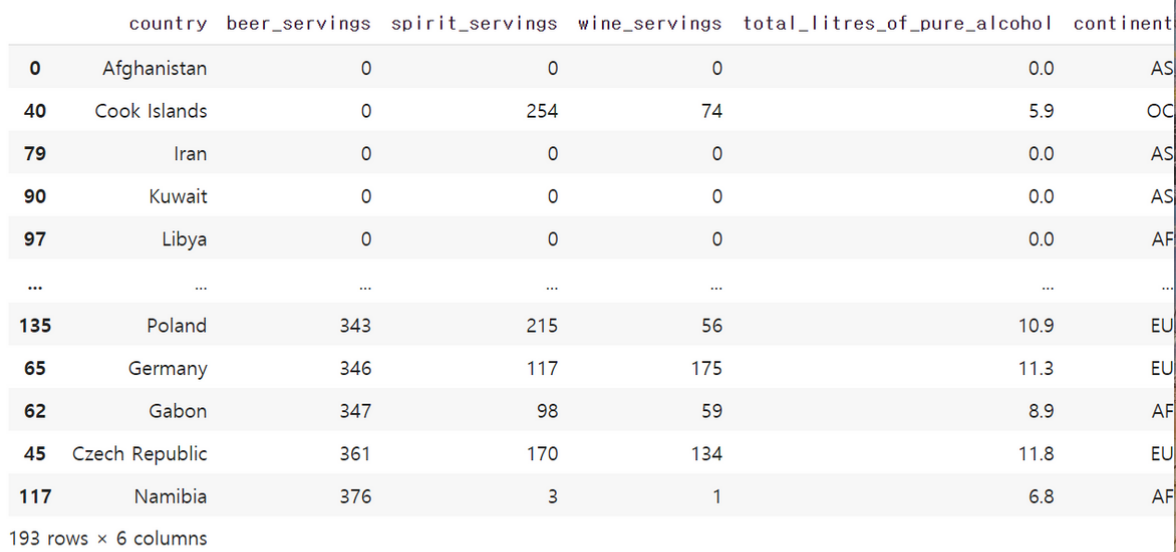
drink_df에서 total_litres_of_pure_alchohol의 값이 최대값인 경우의 country 열을 출력해봅시다. 이를 구현하기 위해서 고려해야할 것은 총 두 가지입니다.특정 열의 최대값을 구하는 방법이 무엇이었는지특정 열만을 출력하는 방법이 무엇이었는
25.데이터 분석 3-7 탐색적 데이터 분석 - 상관관계 분석

상관 분석이란 두 변수 간의 선형적 관계를 상관 계수로 표현하는 것을 말합니다. 상관 계수를 구하는 것은 공분산의 개념을 포함하는데, 공분산은 2개의 변수에 대한 상관 정도. 2개의 변수 중 하나의 값이 상승하는 경향을 보이면 다른 값도 상승하는 경향을 수치로 표현한
26.데이터 분석 3-8 탐색적 데이터 분석 - 시각화 기초
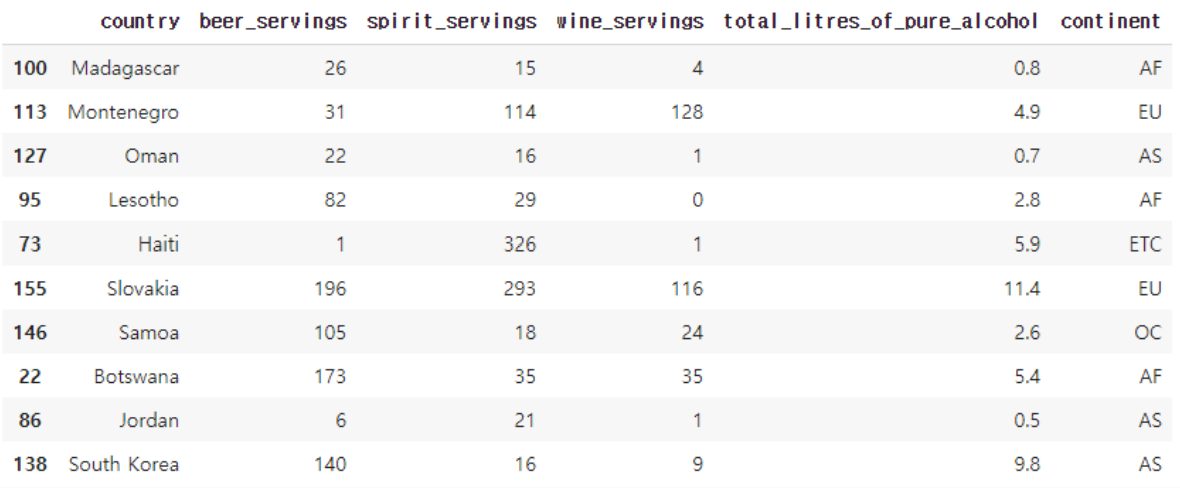
결측값은 탐색적 데이터 분석에서도, 그 후 더 나아가 머신 러닝 알고리즘을 통해 분석을 할 때에도 성능에 영향을 줄 수 있는 값입니다. 결측값은 아예 제거를 해주거나, 특정 값으로 채워주거나 크게 두 가지 선택을 해줄 수 있습니다.제거할 때는 주로 dropna()를 쓰
27.데이터 분석 3-9 탐색적 데이터 분석 - Bar Chart 시각화

1) 바 차트 튜토리얼(bar chart) 2) 주류 데이터(bar chart)
28.데이터 분석 3-11 코로나 데이터 분석 - 차트 그리기

첫 확진자가 발생한 날부터 현재 데이터상 존재하는 가장 최근 날짜까지 코로나 확진자 발생 추이를 그래프로 나타내보겠습니다. 확진자 데이터는 PatientInfo.csv에 존재하므로 이전에 저장한 p_info 데이터프레임을 사용할 수 있습니다.우선 데이터프레임의 크기를
29.데이터 분석 3-12 코로나 데이터 분석 - 지도 시각화
1) 탐색적 데이터 분석 - folium으로 지도 시각화 해보기
30.데이터 분석 3-13 코로나 데이터 분석 - 히트맵 그리기
1) 탐색적 데이터 분석 - 지도와 히트맵
31.데이터 분석 3-14 3주차 끝 & 숙제 설명
📄 붓꽃 데이터의 탐색적 데이터 분석을 진행하고, 여러가지 차트들을 그려주세요.iris 데이터셋의 각 열은 다음과 같습니다.Sepal Length : 꽃받침의 길이 정보Sepal Width : 꽃받침의 너비 정보Petal Length : 꽃잎의 길이 정보Petal W
32.데이터 분석 3-HW 3주차 숙제 해설
33.데이터 분석 - 4주차 정리
수업 목표1\. 선형 회귀에 대한 개념을 익힌다. 2\. 선형 회귀를 학습하는 패키지 사용법을 익힌다. 3\. 1주차에서 배웠던 크롤링에 좀 더 익숙해진다. 4\. 선형 회귀를 통해서 값을 예측하는 머신 러닝 모델을 구현한다. 목차 \-01.
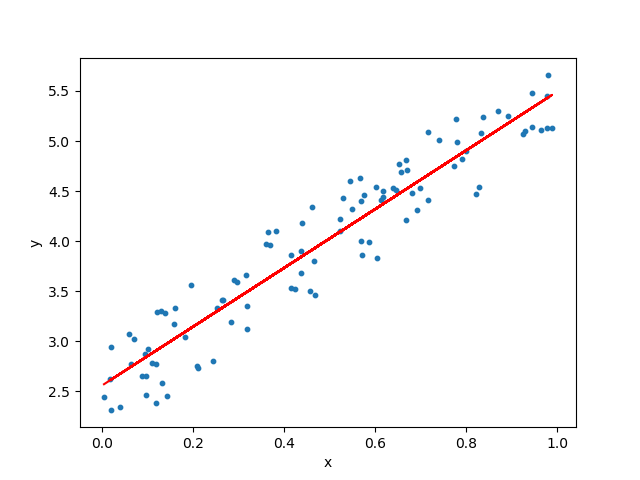
34.스파르타 코딩클럽 데이터분석 4-2~3 선형 회귀란?
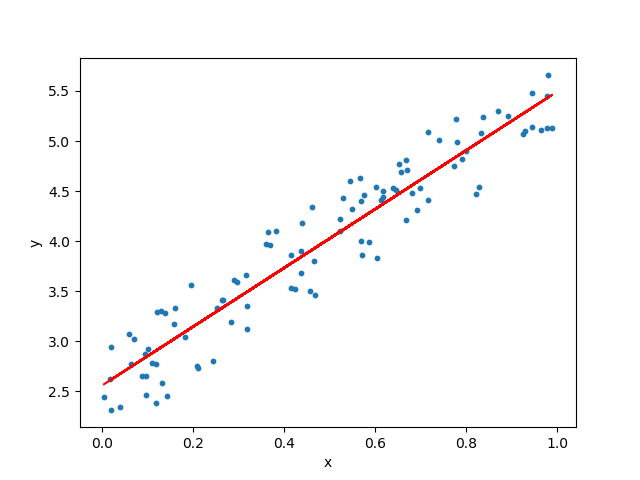
무언가를 예측할때 ex) 시험 공부하는 시간을 늘리면 늘릴 수록 성적이 잘 나옵니다. 하루에 걷는 횟수를 늘릴 수록, 몸무게는 줄어듭니다. 집의 평수가 클수록, 집의 매매 가격은 비쌉니다.다른 변수의 값을 변하게하는 변수를 x, : 독립 변수변수 x에 의해서 값이 종속
35.데이터 분석 4-8 자전거 수요 예측 프로젝트(1) - MSE
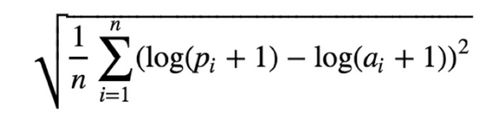
자전거 수요 예측 경진 대회의 주최 측에서는 모델의 성능을 예측하는 지표로 RMSLE(Root Mean Squared Log Error)를 사용했습니다. 회귀 문제에서 성능을 평가하기 위해 사용되는 여러 유명한 지표 중 하나입니다. RMSLE 외에도 MAE, MSE,
36.데이터 분석 4-9 자전거 수요 예측 프로젝트(2) - linear regression
이제 사이킷런 패키지의 선형 회귀를 수행해봅시다.이번에는 데이터를 train 이라는 이름으로 불러오겠습니다. 그리고 parse_dates="datetime" 이라고 해주시면, 자동으로 데이터에서 날짜 부분을 datetime 타입으로 변환해줍니다.굳이 apply(pd.t
37.데이터 분석 4-9 자전거 수요 예측 프로젝트(3) 범주형 변수 → 더미형 변수

데이터를 회귀 모델의 입력으로 사용할 때, 범주형 변수들(Categorical variable)에 대해서는 범주형 변수임을 알려주는 전처리를 해줄 필요가 있습니다.범주형 변수(Categorical Variable) : 몇 개의 범주(경우의 수)가 있어 중 하나에 속하
38.데이터 분석 4-11 자전거 수요 예측 프로젝트(4) 다른 종류의 회귀 분석(Regression)
우리가 model 이라는 어떤 모델을 구축했다고 가정하겠습니다. score 함수는 x 데이터와 y 데이터를 넣으면 정확도를 자동으로 계산해주는 함수입니다.테스트 데이터에 대한 정확도, 훈련 데이터에 대한 정확도를 각각 계산하였다고 가정해보겠습니다.결과 그런데 정확도를
39.데이터 분석 4-12 자전거 수요 예측 프로젝트(5) - 수정 후 실험하기

정규화 방법에는 Log 변환 외에도 다음과 같은 정규화 방법이 존재합니다.코드스니펫 참고자료) 스케일링을 통한 데이터의 정규화https://mkjjo.github.io/python/2019/01/10/scaler.html사이킷런에서는 다양한 종류의 스케일러를
40.데이터 분석 4-13 4주차 끝 & 숙제 설명
1) 숙제 설명Sparta_CodingClub_Boston.csv해당 데이터의 각 열에 대한 설명 원문(영어)은 아래의 링크에서 확인 가능합니다.▶코드스니펫 - 보스턴 주택 가격 칼럼 설명 원문https://www.rdocumentation.org/packag
41.데이터 분석 4-HW 보스턴 주택 가격 예측
▶\[코드스니펫] - 4주차 숙제 답안 코드
42.데이터 분석 - 5주차 정리
수업 목표 1\. 실전을 가정하고 고객 데이터를 다뤄본다. 2\. 다수의 테이블을 동시에 다루는 것에 익숙해진다. 3\. 고객 데이터로부터 고객의 행동을 예측해본다. 4\. 고객 데이터로부터 회원의 탈퇴를 예측한다. 5주차 오늘 배울 것 탐색적 데이터 분석 (1) -
43.데이터 분석 5-1~2 탐색적 데이터 분석(1)
customer.zip회원 데이터 탐색적 데이터 분석선형 회귀를 이용한 회원 행동 예측K-Means를 사용하여 회원 데이터를 클러스터링결정 트리 모델을 이용한 회원 탈퇴 예측 여러분들은 데이터 분석가이고, 대형 스포츠 센터로부터 데이터 분석 의뢰를 받았습니다. 고객
44.데이터 분석 5-4 탐색적 데이터 분석(3)
탐색적 데이터 분석 (3)4) 이용 이력 데이터로부터 정기 이력 플래그 작성5) 고객 데이터와 이용 이력 데이터의 결합6) 회원 기간을 계산해서 열로 추가하기
45.데이터 분석 5-3 탐색적 데이터 분석(2) - 데이터 집계
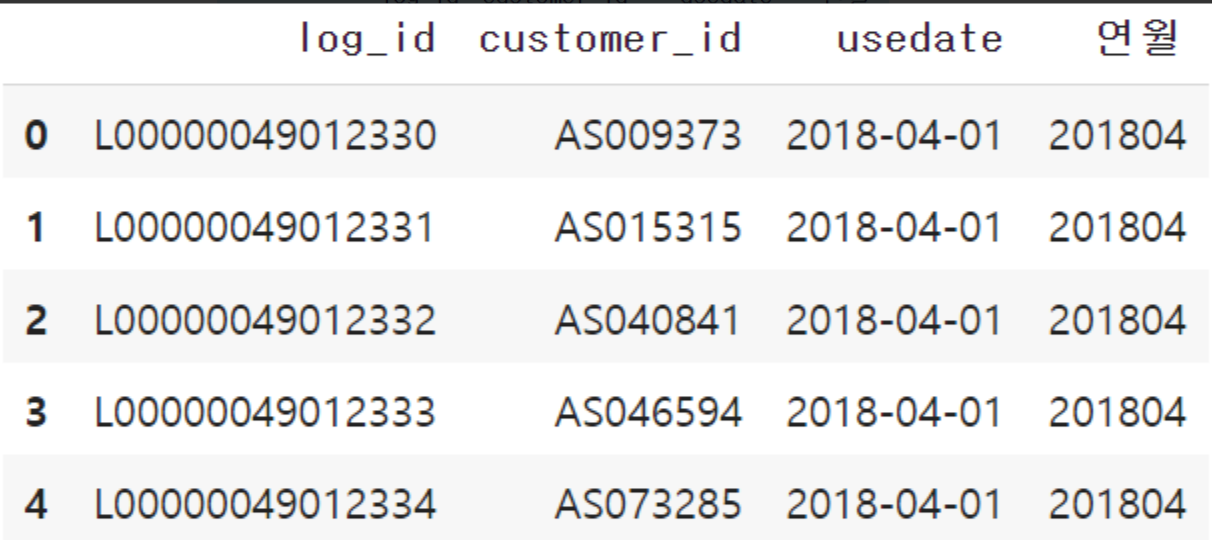
2) 데이터 집계 - 가설 발견 3) 데이터 집계 - 통계량 파악
46.데이터 분석 5-6 고객 행동 예측(1) - 클러스터링 개념
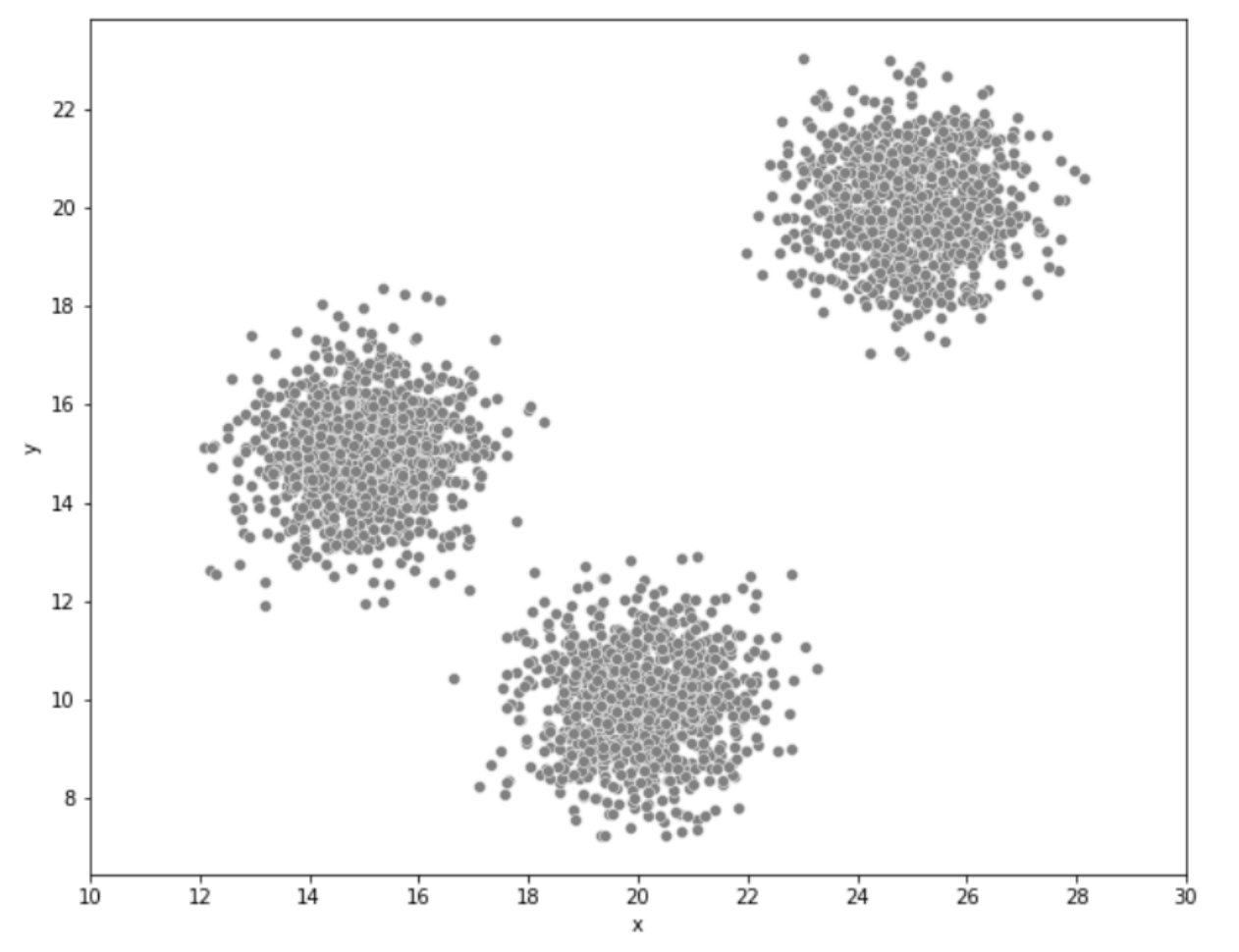
스파르타 코딩클럽 참고자료현재 알고있는 데이터들은 다음과 같습니다.use_log.csv : 스포츠 센터의 이용 이력 데이터. 기간은 2018년 4월 ~ 2019년 3월customer_master.csv : 2019년 3월 말의 회원 데이터class_master.csv
47.데이터 분석 5-7~8 고객 행동 예측(2)~(3) - 클러스터링/시각화

customer 데이터를 사용해서 회원 그룹화를 진행합니다. 필요한 변수를 추출해봅시다. 클러스터링에 이용하는 변수는 고객의 한 달 이용 이력 데이터인 mean, median, max, min, mambership_period로 합니다.이제 클러스터링을 진행합니다. 이
48.데이터 분석 5-9 고객 행동 예측(4) - 예측 모델 만들기

고객의 과거 행동 데이터로부터 다음 달의 이용 횟수를 예측해봅시다.여기서는 과거 6개월의 이용 데이터를 사용해 다음 달의 이용 횟수를 예측해 봅니다.과거 데이터로부터 다음 달 이용 횟수를 예측하는 경우에 어떤 데이터를 준비하면 좋을지 생각 해봅시다. 이번 달이 2018