1) 일별 확진자와 누적 확진자 시각화 (line chart)
첫 확진자가 발생한 날부터 현재 데이터상 존재하는 가장 최근 날짜까지 코로나 확진자 발생 추이를 그래프로 나타내보겠습니다. 확진자 데이터는 PatientInfo.csv에 존재하므로 이전에 저장한 p_info 데이터프레임을 사용할 수 있습니다.
import matplotlib.pyplot as plt
import seaborn as sns우선 데이터프레임의 크기를 확인해봅시다.
p_info.shape
>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>
(5165, 14)행은 5,165개, 그리고 열은 14개가 존재합니다.
상위 5개의 행을 출력해봅시다.
p_info.head()
상위 5개의 행만을 출력했음에도 infected_by, symptom_onset_date, deceased_date 열에 이미 NaN이 보입니다. 즉, Null 값(결측값)이 존재하는 것을 확인할 수 있습니다. 해당 데이터프레임의 정보를 확인해봅시다.
p_info.info()
>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5165 entries, 0 to 5164
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 patient_id 5165 non-null int64
1 sex 4043 non-null object
2 age 3785 non-null object
3 country 5165 non-null object
4 province 5165 non-null object
5 city 5071 non-null object
6 infection_case 4246 non-null object
7 infected_by 1346 non-null object
8 contact_number 791 non-null object
9 symptom_onset_date 690 non-null object
10 confirmed_date 5162 non-null object
11 released_date 1587 non-null object
12 deceased_date 66 non-null object
13 state 5165 non-null object
dtypes: int64(1), object(13)
memory usage: 565.0+ KB
non-null 데이터의 수를 통해 일부 열에는 Null 값(결측값)이 존재하는 것을 확인할 수 있으며, patient_id는 정수형 타입의 데이터지만 그 외의 모든 열은 문자열 타입의 데이터입니다.
각 날짜에 확진자가 몇 명인지를 알려면 어떻게 해야할까요? 현재 데이터프레임에는 환자 개개인의 확진 날짜가 기재되어져 있으므로 확진 날짜 별로 그룹핑하여 카운트를 하면 됩니다.
# confirmed_date를 기준으로 그룹핑
# 각 confirmed_date별로 patient_id 열에 데이터가 몇 개 존재하는지 카운트
daily_count = p_info.groupby(p_info.confirmed_date).patient_id.count()
daily_count
>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
confirmed_date
2020-01-20 1
2020-01-23 1
2020-01-26 1
2020-01-27 1
2020-01-30 4
..
2020-06-26 40
2020-06-27 48
2020-06-28 38
2020-06-29 25
2020-06-30 7
Name: patient_id, Length: 148, dtype: int64결과는 위와 같습니다. 2020년 1월 20일부터 2020년 6월 30일까지 데이터가 존재하며, 총 148일간의 데이터가 있는 것을 확인할 수 있습니다. 위의 출력 결과는 길어서 중략되어져 있으며 좌측의 날짜가 확진 날짜, 우측의 카운트가 확진자의 수가 됩니다.
여기서 주의할 점은 위의 결과는 데이터프레임이 아니라 시리즈(Series)입니다. 시리즈는 데이터프레임처럼 2차원 테이블 형태의 데이터가 아니라, 데이터프레임에서 특정 하나의 열만을 뽑았을 경우에 생기는 데이터인데요.
type(daily_count)
----------------
pandas.core.series.Series그렇다면 열이 1개밖에 없는데, 어떻게 좌쪽에는 날짜, 우측에는 확진자 수와 같이 데이터가 두 종류나 있는 것일까요? 그 이유는 좌측의 날짜는 열이 아니라 해당 데이터의 인덱스(index)이기 때문입니다. 인덱스는 데이터프레임에만 존재하는 개념이 아니라 시리즈에도 존재하는 개념입니다. 시리즈에서 인덱스를 출력하는 방법은 다음과 같습니다.
시리즈 이름.index
한 번 출력해볼까요?
daily_count.index
>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
Index(['2020-01-20', '2020-01-23', '2020-01-26', '2020-01-27', '2020-01-30',
'2020-01-31', '2020-02-01', '2020-02-02', '2020-02-03', '2020-02-05',
...
'2020-06-21', '2020-06-22', '2020-06-23', '2020-06-24', '2020-06-25',
'2020-06-26', '2020-06-27', '2020-06-28', '2020-06-29', '2020-06-30'],
dtype='object', name='confirmed_date', length=148)
148개의 날짜가 출력되는 것을 확인할 수 있습니다. 그렇다면 인덱스가 아니라 실제 시리즈의 데이터에 해당하는 부분은 어떻게 출력할 수 있을까요?
시리즈 이름.values
를 통해서 출력이 가능합니다.
daily_count.values
>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
array([ 1, 1, 1, 1, 4, 3, 1, 3, 1, 5, 2, 1, 3,
1, 2, 9, 28, 42, 37, 72, 75, 57, 93, 122, 112, 137,
103, 133, 68, 113, 116, 145, 99, 57, 54, 69, 95, 51, 35,
35, 34, 37, 53, 44, 57, 50, 73, 38, 31, 23, 57, 47,
49, 49, 67, 55, 46, 78, 48, 59, 48, 43, 27, 22, 34,
24, 23, 16, 12, 18, 17, 20, 14, 11, 13, 5, 7, 6,
10, 7, 5, 8, 9, 5, 10, 6, 1, 4, 4, 9, 3,
2, 3, 8, 22, 30, 27, 28, 21, 29, 24, 10, 10, 7,
14, 27, 15, 11, 22, 20, 17, 14, 37, 77, 57, 37, 23,
32, 46, 44, 33, 39, 53, 52, 28, 38, 50, 38, 44, 49,
38, 25, 24, 40, 50, 42, 52, 41, 20, 15, 38, 25, 33,
40, 48, 38, 25, 7])
마찬가지로 148개의 데이터가 순차적으로 출력됩니다. 앞서 출력한 인덱스와 각각 맵핑되는 값이라고 볼 수 있겠습니다. 그런데 만약, 알고 싶은 것이 각 날짜별로 확진자가 몇 명이 나온지가 아니라 각 날짜에 누적 확진자 수가 몇 명인지 알고 싶은 거라면 어떻게 계산할까요?
이는 현재 가지고 있는 시리즈에 cumsum() 이라는 함수를 사용해서 계산가능합니다.
시리즈의 이름.cumsum()
이라는 파이썬 코드는 현재 갖고 있는 각 행의 값으로부터 누적값을 계산합니다.
# 누적합을 수행. 즉, 누적 확진자 수를 구한다.
accumulated_count = daily_count.cumsum()
accumulated_count
>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
confirmed_date
2020-01-20 1
2020-01-23 2
2020-01-26 3
2020-01-27 4
2020-01-30 8
...
2020-06-26 5044
2020-06-27 5092
2020-06-28 5130
2020-06-29 5155
2020-06-30 5162
Name: patient_id, Length: 148, dtype: int64
누적값이니까 최근 데이터일수록 숫자가 무조건 더 커질 수 밖에 없습니다. 2020년 6월 30일 한국의 누적 확진자 수는 5,162명임을 알 수 있습니다. 이제 daily_count에는 일 별 확진자 수, accumulated_count에는 누적 확진자 수 데이터가 존재합니다. 두 데이터 모두 인덱스는 확진 날짜입니다. 이제 이 데이터들을 각각 그래프로 시각화하려고 합니다.
그런데 한 가지 팁을 드리자면, 사실 시리즈를 시각화 하는 것은 정말 정말 쉽습니다.
시리즈의 이름.plot()
을 사용하면 인덱스를 x축으로 실제 값을 y축으로 사용하여 그래프를 그려줍니다.
plt.rcParams['figure.figsize'] = (15, 5) # 그래프 비율 조정
daily_count.plot()
plt.title('Number of Daily Confirmed Patients')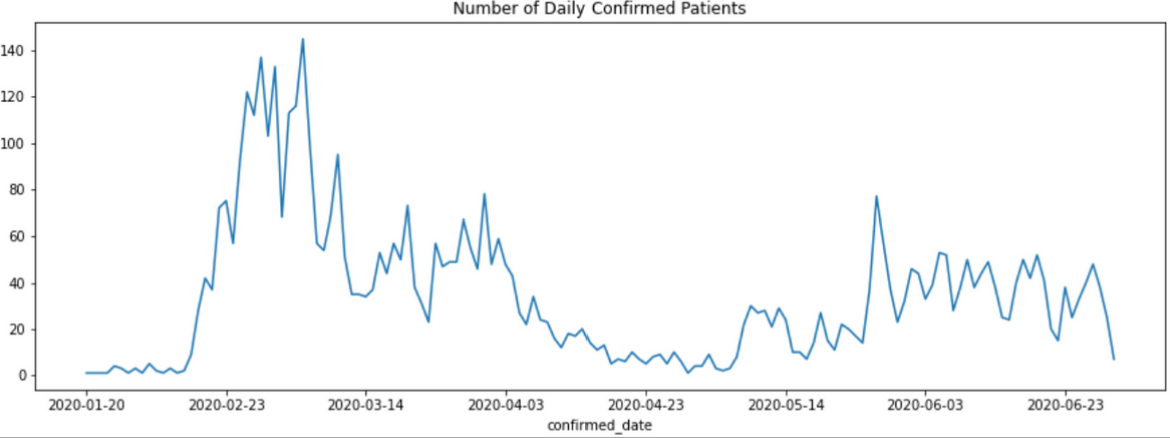
위 코드에서 plt.rcParams['figure.figsize'] = (15, 5) 는 그래프의 비율을 정하는 코드이고, plt.title은 그래프 상단에 그래프의 제목을 위한 코드입니다.
실질적으로 그래프를 그리고 있는 코드는 daily_count.plot()에 해당됩니다.
위 그래프를 보면 2020년 2월 말과 3월 초에는 확진자가 100명을 넘어가면서 폭증하고 있다가 점차적으로 줄어들어서 2020년 4월 중순에는 극히 줄어 20명 이하로 떨어지고 있습니다. 2020년 5월 말과 6월 초 사이에는 약 70명까지 치솟았고, 다시 6월에 접어들어서는 다소 안정되어 4-50명대에 접어들었습니다. 이번에는 누적 확진자 수 그래프를 봅시다.
plt.rcParams['figure.figsize'] = (15, 5) # 그래프 비율 조정
accumulated_count.plot()
plt.title('Accumulated Number of Daily Confirmed Patients')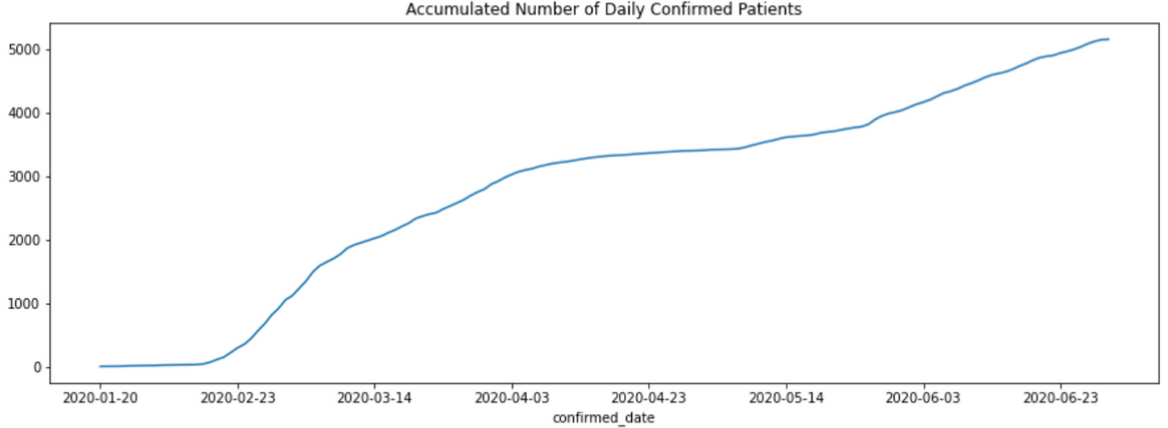
2) 주요 도시별 확진자 통계 (bar chart)
이번에는 도시별 확진자 통계를 확인해봅시다. 도시에 대한 정보는 Case 데이터프레임의 'city'열을 참조하면 됩니다. 우선 'province'의 값이 'Daegu'인 경우를 봅시다.
case[case['province']=='Daegu']
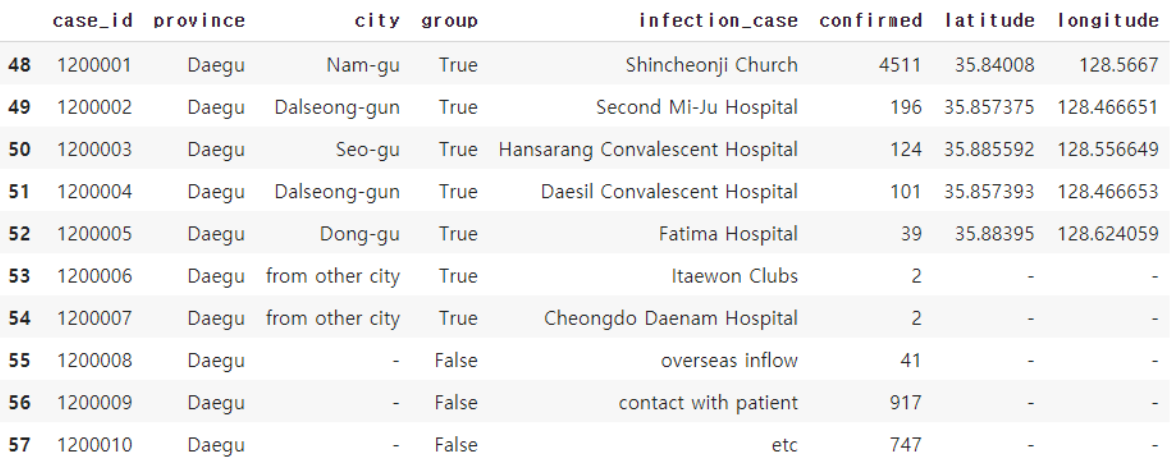
위의 데이터프레임에서 'city'열과 여러가지 값들이 들어가 있는 것을 확인할 수 있습니다.
seaborn에서 barplot()이란 기능을 통해서 바 차트를 그려보겠습니다!
sns.barplot(x=열의 이름, y=열의 이름, data=데이터프레임, ci=None)
.set(xlabel='x축에 대한 레이블', ylabel='y축에 대한 레이블', title='차트의 타이틀')
기본적인 사용 방법은 위와 같습니다.
province 값이 Daegu인 경우에 대해서 바 차트를 그려봅시다.
sns.barplot(x='confirmed', y='city', data=case[case['province']=='Daegu'], ci=None).set(xlabel='Confirmed', ylabel='Districts', title='Case in Daegu')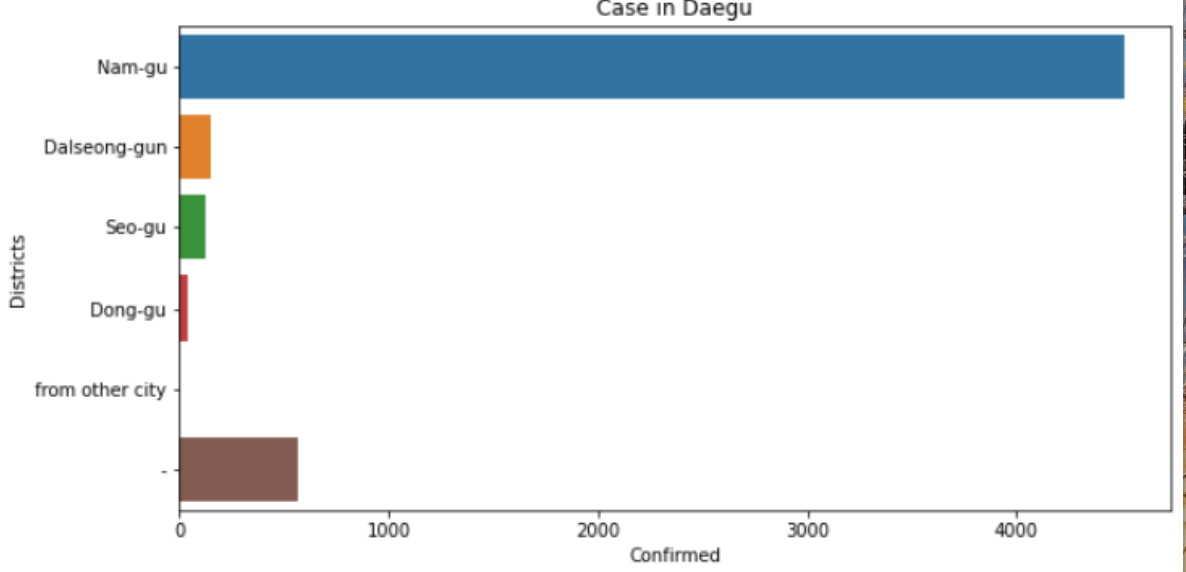
합계를 한다고 하더라도 Namgu가 압도적으로 많습니다.
이번에는 'province'의 값이 'Seoul'인 경우를 봅시다.
# 결과가 길어서 상위 10개행만 출력
case[case['province']=='Seoul'].head(10)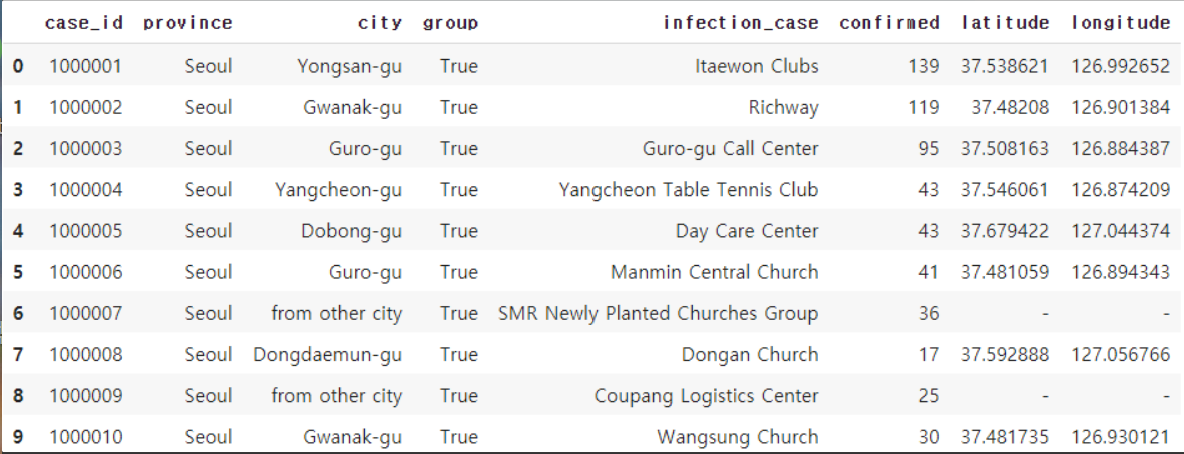
상위 10개의 행만을 출력해봤는데, 여러 도시(city)가 출력됩니다.
도시별 확진자를 출력해봅시다.
sns.barplot(x='confirmed', y='city', data=case[case['province']=='Seoul'], ci=None).set(xlabel='Confirmed', ylabel='Districts', title='Case in Seoul')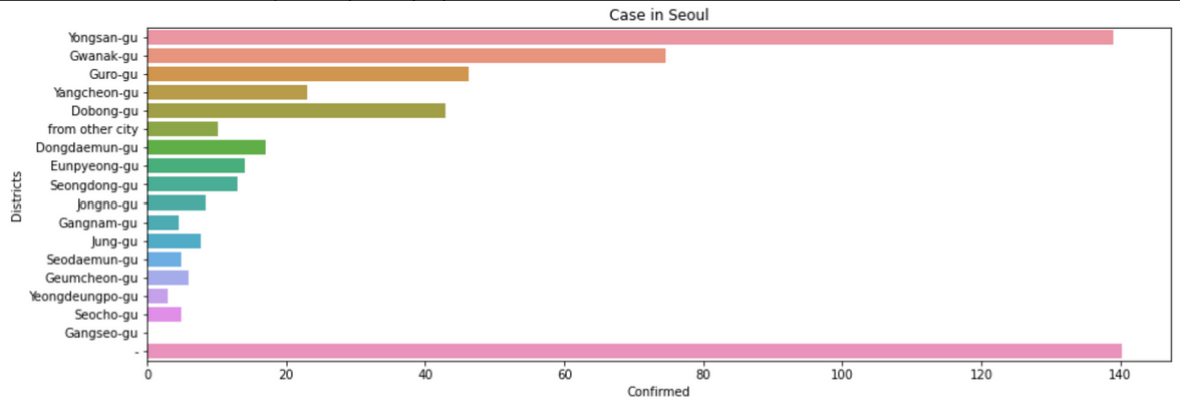
3) 성별과 연령대 별 확진자 통계 (pie chart)
이번에는 성별과 연령대 별 확진자 통계를 파이 차트를 통해 시각화해봅시다.
t_gender 데이터프레임에는 날짜별 여성과 남성의 누적 확진자 수가 기록되어져 있습니다.
tail()을 통해 하위 5개의 행을 출력하여 이 데이터에서의 마지막 날짜를 확인해봅시다.
t_gender.tail()
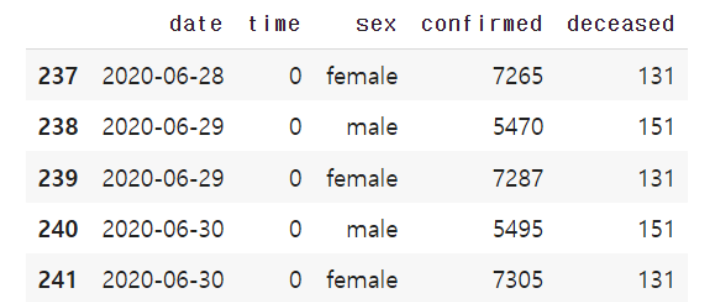
이 데이터는 2020년 6월 30일까지의 데이터를 가지고 있습니다. 결국 우리가 필요한 데이터는 맨 끝 데이터 2개입니다. 2020년 6월 30일의 male 데이터와 female 데이터가 각각 최근 날짜의 남성 확진자 수와 여성 확진자 수이기 때문입니다.
조건을 줘서 데이터프레임을 필터링한 후에 confirmed 열만 접근해서 데이터를 가져오도록 하겠습니다.
t_gender[t_gender.date=='2020-06-30'].confirmed
>>>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>
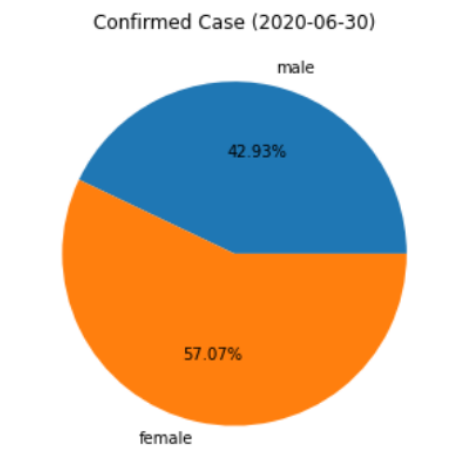
240 5495
241 7305
Name: confirmed, dtype: int64
파이 차트를 그리려면
- 파이 차트로 사용할 데이터의 이름이 담긴 리스트(레이블),
- 그리고 해당 이름에 해당하는 데이터의 값이 담긴 리스트(실질적 데이터)
이 두 가지가 필요합니다.
현재는 남성과 여성에 대해서 파이 차트를 구하는 것이므로 male과 female이라는 값을 가진 레이블 리스트를 만들고, 데이터에 대한 리스트 또한 준비합니다.
# 데이터의 레이블 리스트
pie_labels = ['male', 'female']
# 데이터의 실질적인 값 리스트
pie_values = t_gender[t_gender.date=='2020-06-30'].confirmed.values.tolist()사용 방법은 다음과 같습니다.
plt.pie(데이터의 실질적인 값, labels=데이터의 레이블 리스트)
autopct는 소수점을 몇 개까지 출력할지를 정하기 위한 값입니다.
plt.pie(pie_values, labels=pie_labels, autopct='%.02f%%')
plt.title('Confirmed Case (2020-06-30)')
plt.show()
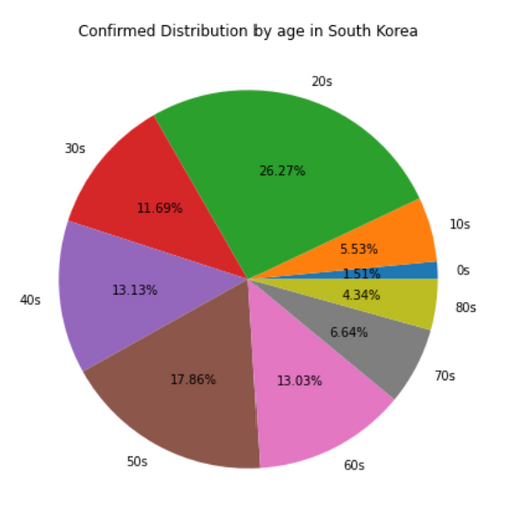
연령대 별 확진자 통계를 파이 차트를 통해 시각화해봅시다.
t_age
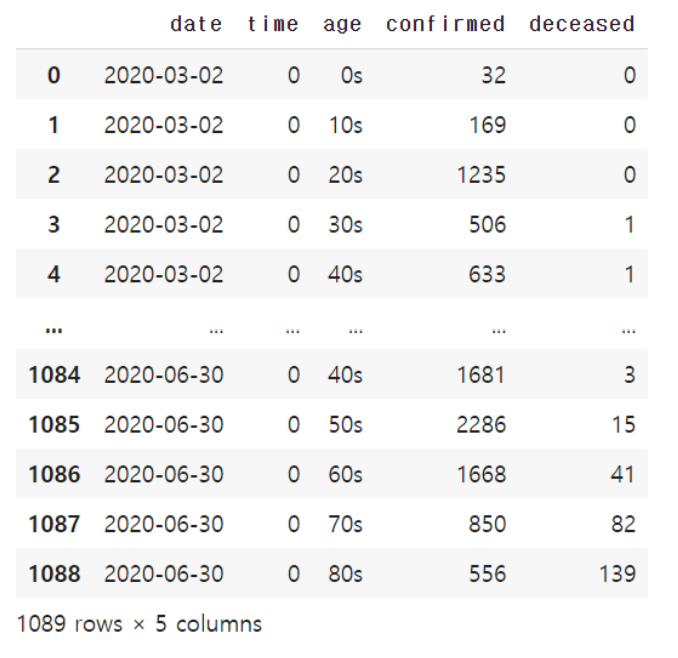
마찬가지로 누적 확진자이기 때문에 마지막 날짜에 대해서만 데이터를 불러와야 합니다.
population_by_age = t_age[t_age['date']=='2020-06-30']
population_by_age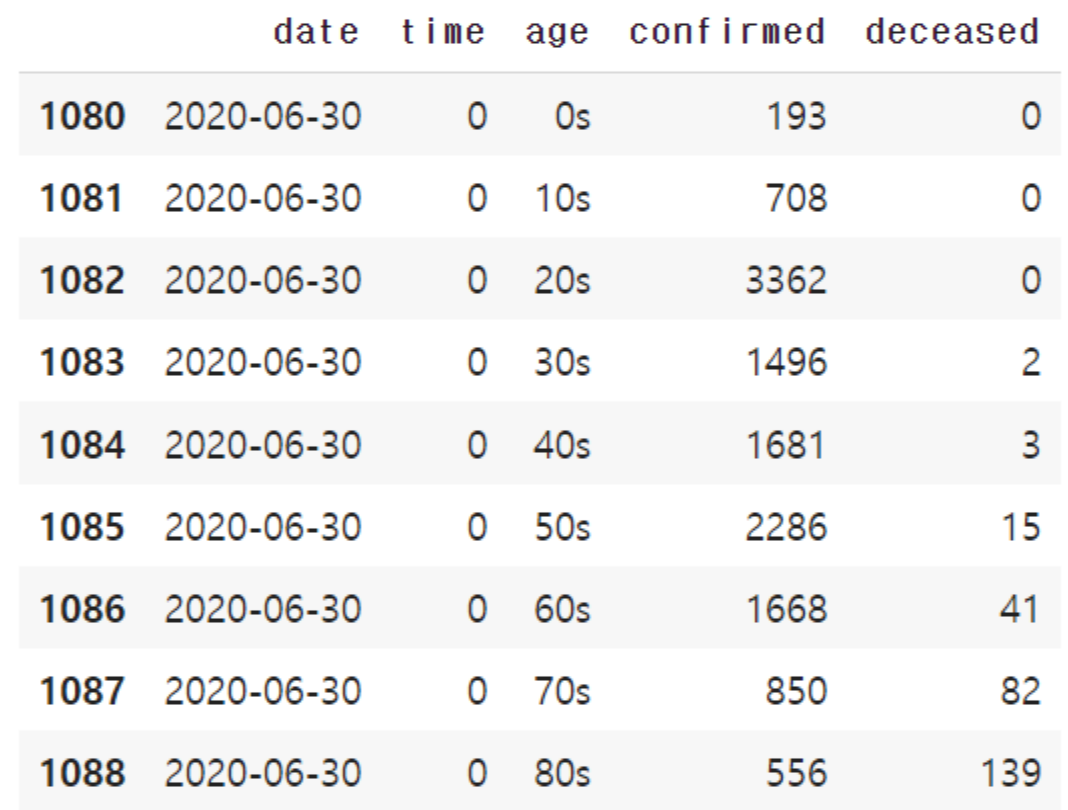
다음과 같이 파이 차트를 위한 두 개의 준비물을 준비합니다.
pie_labels = population_by_age.age.values.tolist()
pie_values = population_by_age.confirmed.values.tolist()
print(pie_labels)
print(pie_values)
>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
['0s', '10s', '20s', '30s', '40s', '50s', '60s', '70s', '80s']
[193, 708, 3362, 1496, 1681, 2286, 1668, 850, 556]이제 파이 차트를 그려봅시다.
plt.figure(figsize=(10, 7))
plt.title('Confirmed Distribution by age in South Korea')
plt.pie(pie_values, labels=pie_labels, autopct='%.02f%%')
plt.show()