1) 결측값 처리하기
결측값은 탐색적 데이터 분석에서도, 그 후 더 나아가 머신 러닝 알고리즘을 통해 분석을 할 때에도 성능에 영향을 줄 수 있는 값입니다. 결측값은 아예 제거를 해주거나, 특정 값으로 채워주거나 크게 두 가지 선택을 해줄 수 있습니다.
제거할 때는 주로 dropna()를 쓰는 반면, 채워줄 때는 주로 fillna()를 사용합니다.
앞서 continent열에 결측값이 23개가 있는 것을 확인했었습니다.
여기서는 특정값으로 채우는 fillna()를 사용해보겠습니다.
# 결측 데이터를 특정값으로 채우는 방법은 .fillna()를 사용하는 것이다.
# 이 경우 기타 값이라는 의미에서 'ETC'를 넣어준다.
drink_df['continent'] = drink_df['continent'].fillna('ETC')
drink_df.sample(10)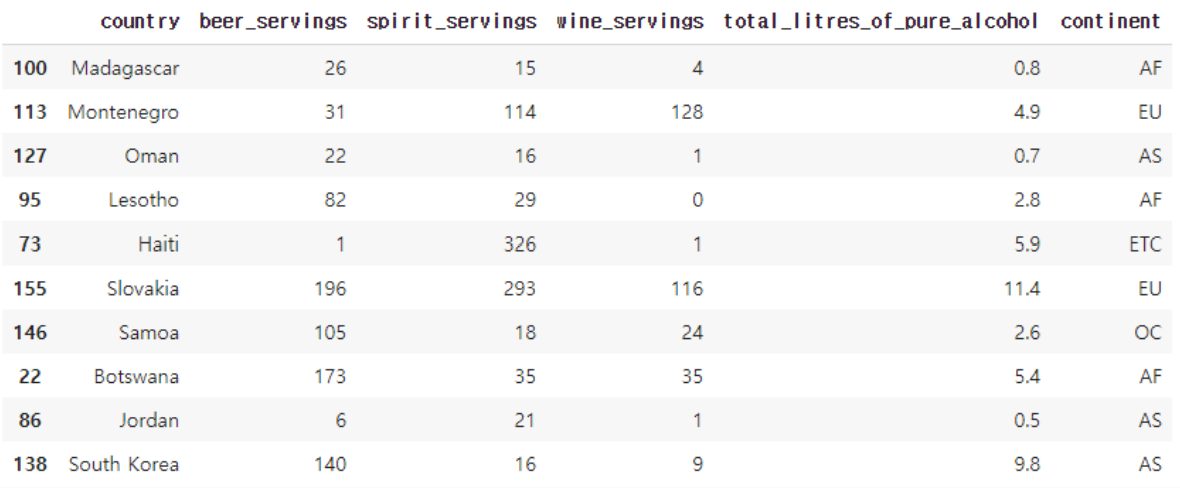
continent열에 결측값이 있을 경우 'ETC'라는 값으로 채우도록 했습니다. 기타라는 의미인데요. 정확한 대륙값이 없으니 기타 등등의 대륙으로 간주하겠다는 의미입니다. 채우고 나서 랜덤으로 10개를 출력하도록 해보았는데, ETC란 값이 중간에 보입니다.
이제 결측값이 사라졌는지 앞서 배운 코드인 isnull().sum()으로 확인해봅시다.
drink_df.isnull().sum()
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>
country 0
beer_servings 0
spirit_servings 0
wine_servings 0
total_litres_of_pure_alcohol 0
continent 0
dtype: int64이제 continent 열에는 결측값이 존재하지 않습니다.
2) 파이 차트(pie chart)
파이 차트(pie chart)는 원 모양의 그래프를 의미합니다. 파이 차트는 원그래프는 전체에 대한 각 부분의 비율을 부채꼴 모양으로 백분율로 나타낸 그래프입니다. 각 부채꼴의 중심각이 전체에서 차지하는 비율을 나타내며, 비율을 한눈에 볼 수 있다는 장점이 있습니다.
다음은 파이 차트의 예시입니다.
파이 차트를 그리려면
- 파이 차트로 사용할 데이터의 이름이 담긴 리스트(레이블),
- 그리고 해당 이름에 해당하는 데이터의 값이 담긴 리스트(실질적 데이터)
이 두 가지가 필요합니다.
여기서는 continent에 대해서 파이차트를 그려보고자 합니다.
파이 차트의 값으로는 continent에 있는 각 값들을 카운트한 개수를 사용하겠습니다.
우선, 특정 열에 대해서 value_counts()를 사용하였을 때의 결과를 봅시다.
# 해당 열에 존재하는 각 종류의 값에 대해서 카운트를하여 시리즈로 리턴.
drink_df['continent'].value_counts()
>>>>>>>>>>>>>>실행>>>>>>>>>>>>
AF 53
EU 45
AS 44
ETC 23
OC 16
SA 12
Name: continent, dtype: int64인덱스에는 continents의 이름, 그리고 실실적 값 부분에는 해당 continents 열에 존재하는 각 종류의 값들을 카운트한 값이 들어가있습니다. 좌측의 AF, EU, AS, ETC, OC, SA는 이 시리즈(series)의 인덱스에 해당하며, 53, 45, 44, 23, 16, 12는 이 시리즈의 값에 해당됩니다.
인덱스는 .index로 접근하고 값에 대해서는 .values로 접근하므로
각각 접근 후에 리스트로 값을 변환하는 tolist()를 사용해줍니다.
pie_labels = drink_df['continent'].value_counts().index.tolist()
pie_values = drink_df['continent'].value_counts().values.tolist()
print(pie_labels)
print(pie_values)
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>
['AF', 'EU', 'AS', 'ETC', 'OC', 'SA']
[53, 45, 44, 23, 16, 12]이제 파이 차트를 그리기 위해 필요한 두 가지를 얻었습니다. 파이 차트를 그리는 방법은 Matplotlib의 pyplot을 plot로 임포트하였다면, plt.pie()를 사용합니다.
사용 방법은 다음과 같습니다.
plt.pie(데이터의 실질적인 값, labels=데이터의 레이블 리스트)
autopct는 소수점을 몇 개까지 출력할지를 정하기 위한 값입니다.
plt.pie(pie_values, labels=pie_labels, autopct='%.02f%%')
plt.title('Percentage of each continent')
plt.show()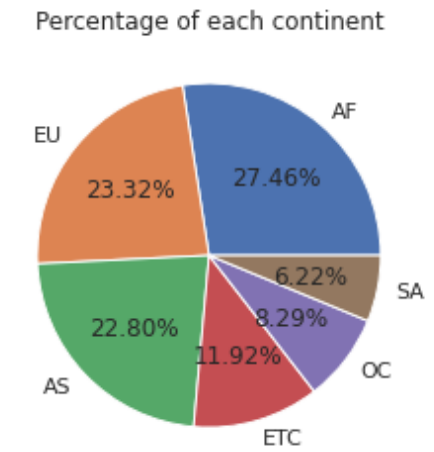
3) Group By 활용하기
Group By는 특정 값을 기준으로 그룹핑한 후에 그룹 별로 통계적인 수치 정보를 구할 수 있도록 하는 방법입니다. 사용 방법은 다음과 같습니다.
데이터프레임의 이름.groupby('그룹핑 기준이 되는 열')['보고자 하는 열'].통계 함수
Group By를 통해서 수치 정보를 계산해봅시다.
- 대륙 별 평균 맥주 소비량은 어떻게 될까?
대륙에 대한 열은 continent에 있습니다. 그리고 맥주의 소비량은 beer_servings 열입니다.
평균을 구하는 함수는 mean()이므로 다음과 같이 사용합니다.
# groupby('그룹핑 기준이 되는 열')['보고자 하는 열'].통계 함수
drink_df.groupby('continent')['beer_servings'].mean()
>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>
continent
AF 61.471698
AS 37.045455
ETC 145.434783
EU 193.777778
OC 89.687500
SA 175.083333
Name: beer_servings, dtype: float64열이 1개밖에 없으므로 결과의 타입은 시리즈(series)입니다.
type(drink_df.groupby('continent')['beer_servings'].mean())
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>실행
pandas.core.series.Series
각 대륙 별 모든 종류의 알콜의 평균 소비량을 보고싶다면?
보고자하는 열을 별도로 명시해주지 않으면 모든 열이 출력됩니다. 앞서 'beer_servings'를 명시해주었을 때와는 다른 결과입니다.
# groupby('그룹핑 기준이 되는 열').통계 함수
drink_df.groupby('continent').mean()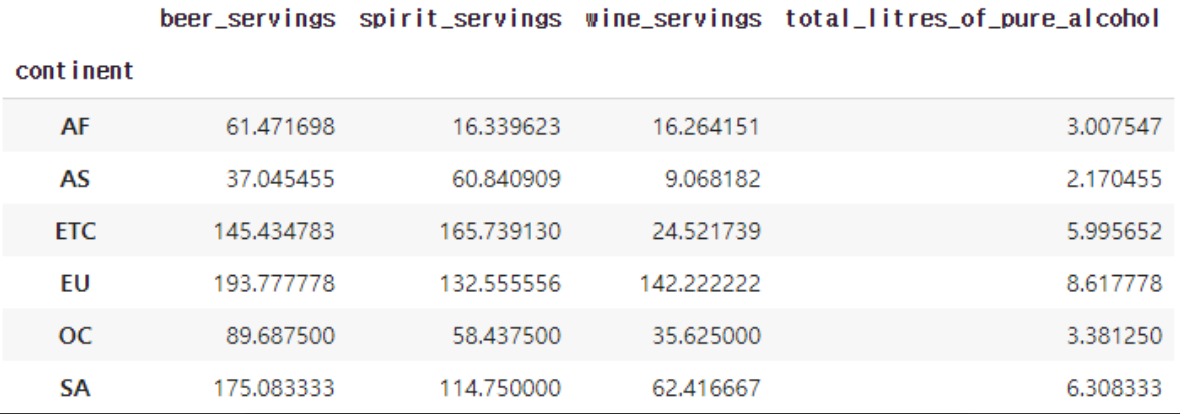
- 총 알코올 소비량 평균보다 더 많이 알콜을 섭취하는 대륙은?
총 알코올 소비량에 대한 열은 total_litres_of_pure_alcohol입니다. 우선, 데이터프레임으로부터 total_litres_of_pure_alcohol의 전체 평균을 구합니다.
그리고 각 대륙별 total_litres_of_pure_alcohol의 소비량을 계산해준 뒤에, 전체 평균보다 크도록 조건을 걸어주면 되겠습니다.
# 전체 평균
total_mean = drink_df.total_litres_of_pure_alcohol.mean()
# 각 대륙별 total_litres_of_pure_alcohol 소비량 계산
continent_mean = drink_df.groupby('continent')
['total_litres_of_pure_alcohol'].mean()
# 전체 평균으로 조건을 걸어준다.
continent_over_mean = continent_mean[continent_mean >= total_mean]
print(continent_over_mean)
>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>
continent
ETC 5.995652
EU 8.617778
SA 6.308333
Name: total_litres_of_pure_alcohol, dtype: float64
- 평균
wine_servings이 가장 높은 대륙은?
.idxmax()를 사용하면 시리즈(series)에서 가장 높은 값을 가진 데이터를 콕집어서 리턴해줍니다. 대륙별 평균 와인소비량을 구한 뒤에 여기에 idxmax()를 사용해주면, 평균 와인소비량이 가장 큰 대륙의 이름을 리턴해줄 것입니다.
# 평균 wine_servings이 가장 높은 대륙을 구합니다.
beer_continent = drink_df.groupby('continent').wine_servings.mean().idxmax()
print(beer_continent)
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>
EU
agg를 사용하면 여러 통계 함수를 동시에 사용할 수 있습니다.
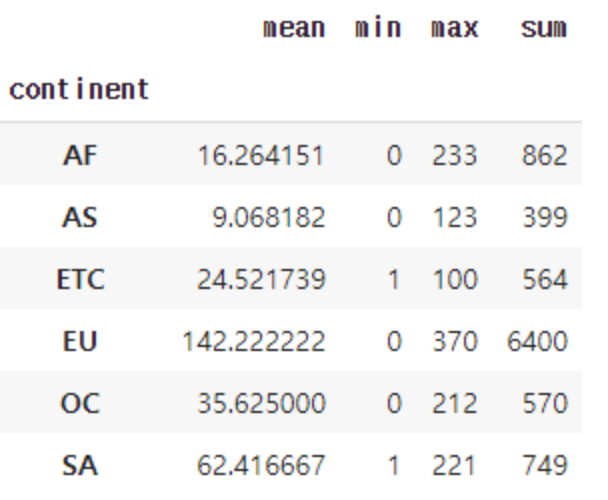
- 각 대륙 별로
wine_servings소비에 대해서평균, 최소, 최대값, 합을 출력해보자.
drink_df.groupby('continent').wine_servings.agg(['mean', 'min', 'max', 'sum'])