01. 5주차 배울 것
👻 5주차 수업을 진행하기 위해서는 아래 있는 [customer.zip](http://customer.zip) 안에 있는 데이터들이 꼭 필요합니다! 수강을 시작하기 전에 꼭 다운로드를 진행해주세요 😄- 회원 데이터 탐색적 데이터 분석
- 선형 회귀를 이용한 회원 행동 예측
- K-Means를 사용하여 회원 데이터를 클러스터링
- 결정 트리 모델을 이용한 회원 탈퇴 예측
02 탐색적 데이터 분석 (1)
1) 데이터 로드
여러분들은 데이터 분석가이고, 대형 스포츠 센터로부터 데이터 분석 의뢰를 받았습니다.
고객은 근 1년 간(2018년 4월 ~ 2019년 3월) 회원 수가 크게 늘지 않고 있어서 그 원인을 파악하고 싶어합니다. 이 대형 스포츠 센터에는 하루 종일 사용할 수 있는 종일 회원, 낮에만 사용하는 주간 회원, 밤에만 사용하는 야간 회원이 있습니다. 또한, 가끔 입회비 반액 할인이나 입회비 무료와 같은 행사도 종종 진행하여 회원 수를 늘리고자 시도합니다. 탈퇴를 신청하면 다음 달 말에 탈퇴가 됩니다.
처음 고객에게 받은 데이터는 총 4개입니다.
👨🏫 데이터 파일을 이용해서 유기적으로 분석하는 그런 과정을 해볼 것.
- 3주차때 코로나 데이터 도식화 된 것을 보며 어떤 선을 기준으로 데이터가 연결 될 수도 있다. 파일이 나눠져 있어서 따로따로 분석할 것이 아니라 그 두개를 합쳐서 유기적으로 분석하는 분석을 진행하기도 한다. 그 과정을 진행해 볼 것임.
- 어떤 열을 기준으로 데이터를 결합하는 것을
조인이라 함.
use_log.csv: 센터 이용 이력. (2018년 4월 ~ 2019년 3월)customer_master.csv: 2019년 3월 말 시점의 회원 데이터, 이전 탈퇴 회원 데이터 포함.class_master.csv: 회원 구분campaign_master.csv: 가입 시 행사 종류 데이터
(1) use_log.csv
우선 use_log.csv를 데이터프레임으로 로드합니다.
👨🏫 데이터를 드레그 해서 업로드 함. 원이 없어질때 까지 기다리자. 업로드 중.
- 판다스를 이용해서 데이터 프레임을 한번 출력해보면 좋겠죠?^^
import pandas as pd uselog = pd.read_csv('use_log.csv') uselog >>>>>>>> 실행>>>>>>>>>>> 총 197428개의 데이터가 있다. 그래프 뜸. < uselog 경우 센터의 이용 이력을 담은 데이터다. 2018년4월부터~ 총 1년. 우리가 하려는 것이, 관통하는 주제가 이 스포츠 센터의 데이터를 이용해서 우리가 어떤 인사이트, 어떤 결론을 도출해 낼 수 있는지.
import pandas as pd
uselog = pd.read_csv('use_log.csv')
print(len(uselog))
uselog.head()
>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>..
197428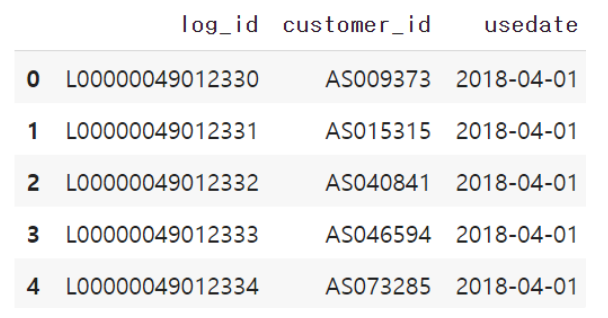
샘플의 개수가 총 197,428개인 uselog는 고객 ID, 이용일을 포함한 간단한 데이터로 고객이 언제 센터를 이용했는지를 알 수 있는 데이터입니다.
(2) customer_master.csv
다음은 customer_master.csv 파일을 데이터프레임으로 로드합니다.
👨🏫 이름(실제로 데이터분석을 진행할때도 이름같은 개인 정보로 특정사람을 식별할수 있는 정보들은 가려져 있는 경우가 많다.)
customer = pd.read_csv('customer_master.csv') customer >>>>>>>> 실행>>>>>>>>>>> 4192 rows * 8 columns 그래프 뜸. < 고객별 특수 아이디와 이름, 클레스(회원반), 성별, 등록일, 탈퇴시점. (NaN은 아직 탈퇴안했다는 뜻), 탈퇴여부. 행사의 종류, 그런데 class나 campaig_id 경우에는 다른 데이터 파일이 있다.
customer = pd.read_csv('customer_master.csv')
print(len(customer))
customer.head()
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>
4192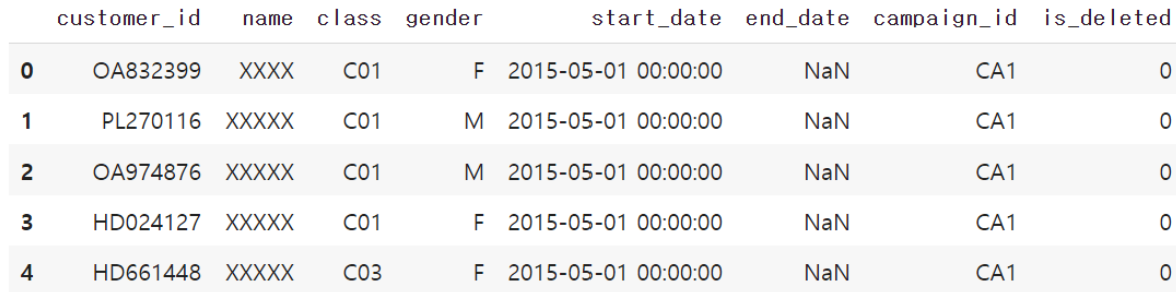
총 4,192개의 샘플이 있는 customer 데이터는 회원 데이터로 고객 ID, 이름, 회원 클래스, 성별, 등록일 정보가 들어가있습니다. 이름은 XXX 내지는 XXXXX 처리가 되어있는데, 고객 정보 보호를 위해 비공개처리가 된 것으로 보입니다.
is_deleted 열은 2019년 3월 시점에 탈퇴한 유저를 시스템에서 빨리 찾기 위한 열입니다. customer_id 열이 존재하는데, 이는 uselog에서도 동일하게 있었던 열로 이 두 가지 열은 두 데이터가 공통적으로 가지고 있는 열입니다. (두 데이터를 연결시킬 수 있다는 의미입니다.) 또한 is_deleted 열을 통해 알 수 있는 점은 customer 데이터에는 현재 이미 탈퇴한 회원들에 대한 정보도 포함되어져 있다는 겁니다.
(3) class_master.csv
👨🏫
class_master = pd.read_csv('class_master.csv') class_mater >>>>>>>> 실행>>>>>>>>>>> 데이터뜸. 해볼수 있는 것. class 라는 열을 기준으로 저기에 정보를 추가해 줄수 있따 - join
다음은 class_master.csv를 데이터프레임으로 로드합니다.
class_master = pd.read_csv('class_master.csv')
print(len(class_master))
class_master.head()
>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>
3
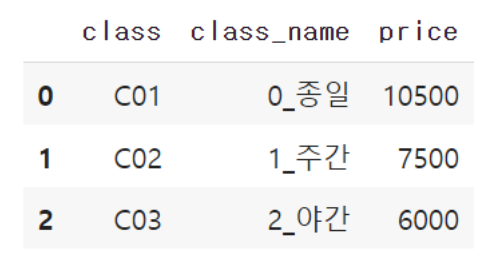
class_master는 총 3개의 샘플이 존재합니다. 바로 종일, 주간, 야간이며 가격은 각각 다릅니다.
(4) campaign_master.csv
다음은 campaign_master.csv를 데이터프레임으로 로드합니다.
👨🏫
campaign_master = pd.read_csv('campaign_master.csv') campaign_mater >>>>>>>> 실행>>>>>>>>>>> 데이터뜸. 해볼수 있는 것. 캡페인의 이름도 열을 기준으로 저기에 정보를 추가해 줄수 있따 - join
campaign_master = pd.read_csv('campaign_master.csv')
print(len(campaign_master))
campaign_master.head()
>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>
3

행사의 종류를 담고 있는 데이터인 campaign_master는 총 3개의 샘플이 존재합니다. 바로 일반, 입회비반액할인, 입회비무료입니다.
2) 레프트 조인
▶ [코드스니펫] 데이터의 Join에 대한 참고 자료
https://programmerpsy.tistory.com/17오늘 강의에서는 조인이라는 두 가지 데이터를 결합하는 테크닉을 사용합니다. 조인에도 여러가지 종류가 있는데, 오늘 강의에서는 그 중에서 레프트 조인이라는 것을 사용합니다.
예시를 통해서 간단히 레프트 조인에 대해서 이해해봅시다.
import pandas as pd임의의 데이터프레임 DF1과 DF2를 만듭니다.
DF1 = pd.DataFrame([["싸이",180,75],["덕구",160,65],["또치",170,75]], columns = ["이름","키","몸무게"])
DF1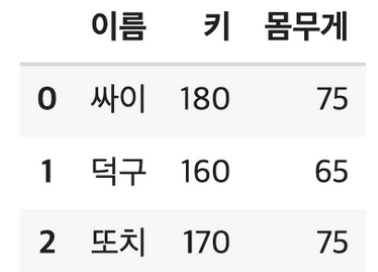
DF2 = pd.DataFrame([["싸이","포워드","잘함"],["덕구","미드필더","못함"],
["똥갈","수비수","잘함"]], columns = ["이름","포지션","실력"])
DF2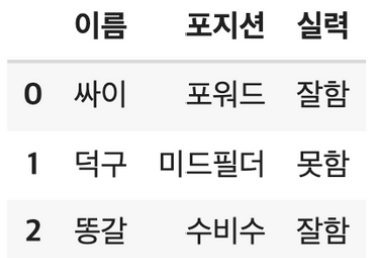
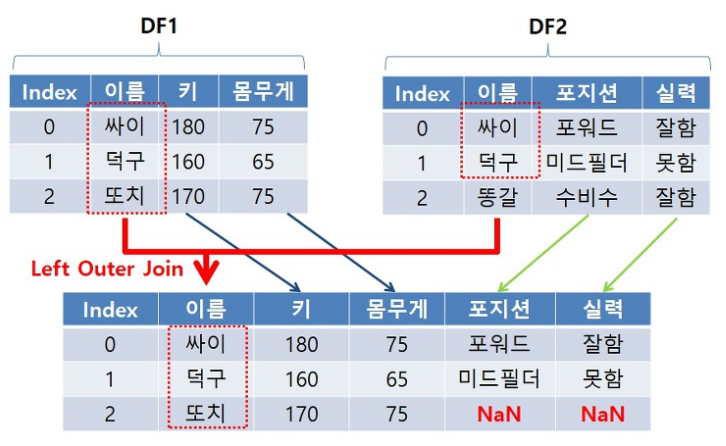
레프트 조인은 좌측에 있는 데이터는 모두 사용하되, 우측에 있는 데이터를 좌측에 있는 데이터에 맞추어서 결합하는 것을 말합니다.
- 왼쪽 DataFrame의 모든 데이터는 출력! 즉, 최종 데이터의 개수는 왼쪽 DataFrame의 개수와 일치
- 오른쪽 DataFrame 중 왼쪽 DataFrame에 있는 Data는 출력
- 오른쪽 DataFrame 중 왼쪽 DataFrame에 없는 Data는 Null 값 처리
pd.merge(left = DF1 , right = DF2, how = "left", on = "이름")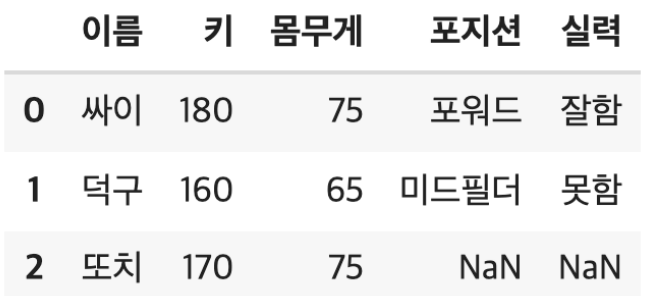
결과가 만들어지는 과정을 그림으로 본다면 다음과 같습니다
3) 데이터 가공
이렇게 갖고있는 데이터가 여러 개로 분리되어서 관리가 되고 있을 때, 이 데이터들이 서로 결합이 가능한 부분이 있고, 통합해서 추가적으로 분석이 가능한 부분이 있어보인다면 실제로 데이터를 통합하여 분석을 진행할 수 있습니다. 여러분들이 데이터를 유심히 관찰한다면 아래와 같은 결론을 얻어낼 수 있습니다.
- customer에는 'class'열이 존재하고, class 데이터에도 'class'열이 존재한다. 이 둘을 결합한다면, 고객들이 어떤 종류, 그리고 어떤 가격의 class를 듣고 있는지 알 수 있을 것이다.
- customer에는 'campaign_id'열이 존재하고, campaign_master 데이터에도 'campaign_id'열이 존재한다. 이 둘을 결합한다면 고객들이 어떤 이름의 campaign을 듣고 있는지를 알 수 있을 것이다.
customer 데이터에 회원 구분 class_master 데이터와 캠페인 구분 campaign_master 데이터를 결합해서 새로운 데이터를 만들어보겠습니다.
고객 데이터를 기준으로 가로로 결합하는 레프트 조인입니다. 결합 후 상위 5개의 행을 출력해봅시다.
# 회원 구분 데이터 class_master를 결합
customer_join = pd.merge(customer, class_master, on="class", how="left")
# 캠페인 구분 campaign_master를 결합
customer_join = pd.merge(customer_join, campaign_master, on="campaign_id", how="left")
customer_join.head()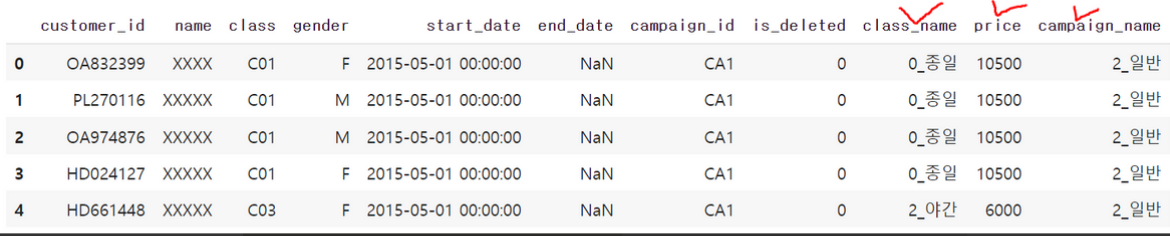
결합 후 처음 5행의 출력 결과를 보면 class_name, price, campaign_name 열이 추가되었습니다. 위의 출력 결과에서 제가 새로 추가된 열에 임의로 빨간색 체크를 해놓았습니다. 이로서 각 회원이 어떤 이름의 클래스(class_name)를 듣고, 클래스 가격(price)은 어떤지, 그리고 어떤 행사(campaign_name)에 속했는지를 알 수 있습니다.
이렇게 조인 후에는 혹시 데이터에 어떤 문제가 생기지 않았는지 한 번 확인해주시는 게 좋습니다. 혹시 데이터의 개수가 바뀌지는 않았는지 확인해봅시다.
print(len(customer))
print(len(customer_join))
>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>.
4192
4192
결측값이 존재하는지 확인해줍니다.
customer_join.isnull().sum()
>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>.
customer_id 0
name 0
class 0
gender 0
start_date 0
end_date 2842
campaign_id 0
is_deleted 0
class_name 0
price 0
campaign_name 0
dtype: int64
end_date 외에는 결측치가 0으로 이번 조인에서 추가한 class_name, price, campaign_name에는 데이터가 정확하게 들어가 있는 것을 확인했습니다. 그리고 end_date에 결측치가 포함된 것 이외에는 비교적 깨끗한 데이터인 것을 알 수 있습니다. end_date에 결측이 있는 이유는 탈퇴하지 않은 회원은 탈퇴일이 존재하지 않기 때문임을 추측할 수 있습니다.
